node的
http模块有两个作用:
- 使node作为服务器使用(这里不做赘述)
- 使node作为客户端从别的服务器请求数据
node作为中间层
从前端向服务器请求数据会有很多跨域显示,而别人的服务器我们不进行修改,不能说让人家返回jsonp或者打开cors访问权限,所以我们可以使用node来获取数据(因为服务器之间是没有跨域访问的限制的),然后通过node将获取到的数据传递给浏览器。
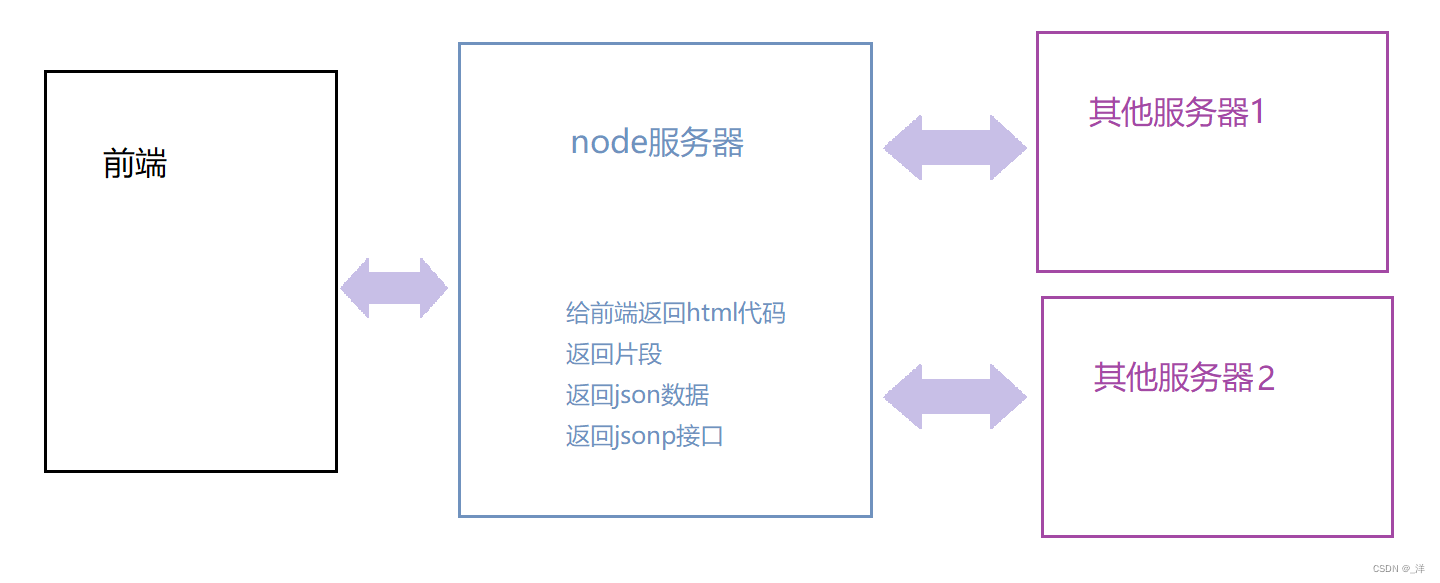
get请求
eg:获取猫眼网站的数据
get.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<script type='text/javascript'>
fetch("http://localhost:3000/hello").then(res=>res.text()).then(res=>{
console.log(res)
})
</script>
</body>
</html>
get.js
var http = require("http")
var https = require("https")
const {
Http2ServerRequest } = require("http2")
var url = require("url")
http.createServer((req, res) => {
var urlobj = url.parse(req.url, true)
res.writeHead(200, {
"Content-Type": "application/json;charset=utf-8",
// cors头,允许跨域
"access-control-allow-origin":"*"
})
switch (urlobj.pathname) {
case "/hello":
// 拿数据
httpget(res)
break;
default:
res.end("404")
}
}).listen(3000, () => {
console.log("服务器启动成功")
})
function httpget(response) {
var data = ""
// http还是https视请求的网站而定
https.get(`https://i.maoyan.com/`, (res) => {
// 获取数据的过程
res.on("data", (chunk) => {
data+=chunk
})
// end是获取的最终数据
res.on("end", ()=>{
console.log(data)
// 将数据返回给前端
response.end(data)
})
})
}
网页输出:
小问题:httpget(res)直接将res对象传递过去,不太好不利于解耦。
所以做如下改进:将参数写成回调函数,传递过去。
即:
var http = require("http")
var https = require("https")
const {
Http2ServerRequest } = require("http2")
var url = require("url")
http.createServer((req, res) => {
var urlobj = url.parse(req.url, true)
res.writeHead(200, {
"Content-Type": "application/json;charset=utf-8",
// cors头,允许跨域
"access-control-allow-origin":"*"
})
switch (urlobj.pathname) {
case "/hello":
// 拿数据
httpget((data) => {
res.end(data)
})
break;
default:
res.end("404")
}
}).listen(3000, () => {
console.log("服务器启动成功")
})
function httpget(cb) {
var data = ""
// http还是https视请求的网站而定
https.get(`https://i.maoyan.com/`, (res) => {
// 获取数据的过程
res.on("data", (chunk) => {
data+=chunk
})
// end是获取的最终数据
res.on("end", ()=>{
console.log(data)
// 将数据返回给前端
cb(data)
})
})
}
post请求
post请求比get请求更安全
post.js
var http = require("http")
var https = require("https")
var url = require("url")
const {
createBrotliCompress } = require("zlib")
http.createServer((req, res) => {
var urlobj = url.parse(req.url, true)
res.writeHead(200, {
"Content-Type": "application/json;charset=utf-8",
// cors头,允许跨域
"access-control-allow-origin":"*"
})
switch (urlobj.pathname) {
case "/hello":
// 拿数据
httppost((data) => {
res.end(data)
})
break;
default:
res.end("404")
}
}).listen(3000, () => {
console.log("服务器启动成功")
})
function httppost(cb) {
var data = ""
var options = {
hostname: "m.xiaomiyoupin.com",
port: "443",
// http的默认端口号是80,https的默认端口号是443
path: "/mtop/mf/resource/data/batchList",
method: "POST",
Headers: {
"Content-Type":"application/json"
}
}
// 没有直接.post,使用request进行配置
var req = https.request(options, (res) => {
res.on("data", (chunk) => {
data+=chunk
})
res.on("end", () => {
cb(data)
})
})
// POST请求一般都是安全的,一般要携带数据,这里就是把携带的数据发送出去
req.write(JSON.stringify([{
}, ["newer_popup_ad", "download_options"]]))
req.end()
}
post.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<script type='text/javascript'>
fetch("http://localhost:3000/hello").then(res=>res.text()).then(res=>{
console.log(res)
})
</script>
</body>
</html>
启动post.js,打开前端页面,页面输出如下:

post请求需要配置比get请求更麻烦:
var options = {
hostname: "m.xiaomiyoupin.com",
port: "443",
// http的默认端口号是80,https的默认端口号是443
path: "/mtop/mf/resource/data/batchList",
method: "POST",
Headers: {
"Content-Type":"application/json"
}
hostname:要请求网址的域名
port:请求的端口号。http的默认端口号是80,https的默认端口号是443
path:请求的详细路径
method:请求方式
Headers:请求头。
Content-Type代表的是请求的数据类型,有两种取值:
- application/json:代表json数据
- x-www-form-urlencoded :代表格式化url类型,即a=1&b=2这种类型
爬虫
爬虫:将get或post请求获取到的数据进行过滤。
爬虫需要使用cheerio工具:
下载:
npm init :初始化
npm i --save cheerio下载安装
cheerio的使用和jQuery很想,可以直接通过类名、id名获取数据。
eg:
var http = require("http")
var https = require("https")
var cheerio = require("cheerio")
const {
Http2ServerRequest } = require("http2")
var url = require("url")
http.createServer((req, res) => {
var urlobj = url.parse(req.url, true)
res.writeHead(200, {
"Content-Type": "application/json;charset=utf-8",
// cors头,允许跨域
"access-control-allow-origin":"*"
})
switch (urlobj.pathname) {
case "/hello":
// 拿数据
httpget((data) => {
res.end(spider(data))
})
break;
default:
res.end("404")
}
}).listen(3000, () => {
console.log("服务器启动成功")
})
function httpget(cb) {
var data = ""
// http还是https视请求的网站而定
https.get(`https://www.kuaikanmanhua.com/`, (res) => {
// 获取数据的过程
res.on("data", (chunk) => {
data+=chunk
})
// end是获取的最终数据
res.on("end", ()=>{
console.log(data)
// 将数据返回给前端
cb(data)
})
})
}
function spider(data) {
// 使用cheerio将有用的数据进行过滤
// cheerio是一个第三方模块
// 获取数据
let $ = cheerio.load(data)
let $name = $(".likeList .tabLink .itemTitle")
let names = []
$name.each((index, value) => {
names.push($(value).find(".itemTitle").text())
})
console.log(names)
return JSON.stringify(names)
}