大家好,今天和各位分享一下如何使用 Pytorch 构建 Vision Transformer 网络模型,并使用 权重迁移学习方法 训练模型并预测。
Vision Transformer 的原理和 TensorFlow2 的实现方法可以看我下面这篇博文:https://blog.csdn.net/dgvv4/article/details/124792386
1. 引言
经典的 Transformer 由 Encoder 和 Decoder 组成,其中,最重要的就是多头注意力机制(Multi-head attention)。在 Vision Transformer 中,作者通过 Transformer 的 Encoder 部分直接进行分类任务,与 NLP 中的处理方式类似,在图片序列中加入分类 token,图片序列则由原始图像切割成若干个图像块(Patch)得到,如下图所示。
主要通过以下步骤进行转换:
(1)假设一张输入图片的形状为(B,C,H,W),其中 B 代表 Batch 大小,C 表示输入图片通道个数,H 和 W 表示输入图片的高和宽。
(2)那么,通过矩阵变换,可以将其转化为 ,其中,P 代表 Patch 的大小,N 的值为
。
(3)将切分为若干个 Patch 的图片分别送到 TransFormer Layer 中处理,在此过程中通过注意力机制进行输入特征的提取。

2. 模型构建
接下来构建 Vision Transformer 的主干模型,本小节的代码都写在 VisionTransformer_model.py 文件中。先导入模型构建过程中需要用到的工具包。
import torch
from torch import nn
from functools import partial2.1 Patch Embedding
首先对输入图像 [b,3,224,224] 做Patch Embedding 操作。首先进行图像分块,将图片切分成14*14个图像块(Patch),每个 Patch 的尺寸为 16*16。通过提取输入图片中的平坦像素向量,将每个输入 Patch 送入线性投影层,得到 Patch Embeddings。

在代码中其流程如上图,先经过一个 kernel=(16,16),strides=16 的卷积层划分图像块,再将 h和w 维度整合为 num_patches 维度,代表一共有 196 个 patch,每个 patch 为 16*16
代码如下:
# --------------------------------------- #
#(1)patch embedding
'''
img_size=224 : 输入图像的宽高
patch_size=16 : 每个patch的宽高,也是卷积核的尺寸和步长
in_c=3 : 输入图像的通道数
embed_dim=768 : 卷积输出通道数
'''
# --------------------------------------- #
class patchembed(nn.Module):
# 初始化
def __init__(self, img_size=224, patch_size=16, in_c=3, embed_dim=768):
super(patchembed, self).__init__()
# 输入图像的尺寸224*224
self.img_size = (img_size, img_size)
# 每个patch的大小16*16
self.patch_size = (patch_size, patch_size)
# 将输入图像划分成14*14个patch
self.grid_size = (img_size//patch_size, img_size//patch_size)
# 一共有14*14个patch
self.num_patches = self.grid_size[0] * self.grid_size[1]
# 使用16*16的卷积切分图像,将图像分成14*14个
self.proj = nn.Conv2d(in_channels=in_c, out_channels=embed_dim,
kernel_size=patch_size, stride=patch_size)
# 定义标准化方法,给LN传入默认参数eps
norm_layer = partial(nn.LayerNorm, eps=1e-6)
self.norm = norm_layer(embed_dim)
# 前向传播
def forward(self, inputs):
# 获得输入图像的shape
B, C, H, W = inputs.shape
# 如果输入图像的宽高不等于224*224就报错
assert H==self.img_size[0] and W==self.img_size[1], 'input shape does not match 224*224'
# 卷积层切分patch [b,3,224,224]==>[b,768,14,14]
x = self.proj(inputs)
# 展平 [b,768,14,14]==>[b,768,14*14]
x = x.flatten(start_dim=2, end_dim=-1) # 将索引为 start_dim 和 end_dim 之间(包括该位置)的数量相乘
# 维度调整 [b,768,14*14]==>[b,14*14,768]
x = x.transpose(1, 2) # 实现一个张量的两个轴之间的维度转换
# 标准化
x = self.norm(x)
return x2.2 类别标签和位置编码
为了输出融合了全局语义信息的向量表示,在第一个输入张量前添加可学习分类变量。经过编码器编码后,在最后一层输出中,该位置对应的输出张量就可以用于分类任务。与其他位置对应的输出向量相比,该向量可以更好的融合图像中各个图像块之间的依赖关系。
在 Transformer 更新的过程中,输入序列的顺序信息会丢失。Transformer 本身并没有办法学习这个信息,所以需要一种方法将位置表示聚合到模型的输入嵌入中。我们对每个 Patch 进行位置编码,该位置编码采用随机初始化,之后参与模型训练。与传统三角函数的位置编码方法不同,该方法是可学习的。
最后,将 Patch-Embeddings 和 class-token 进行堆叠,和 Position-Embeddings 进行叠加,得到最终嵌入向量,该向量输入给 Transformer 层进行后续处理。
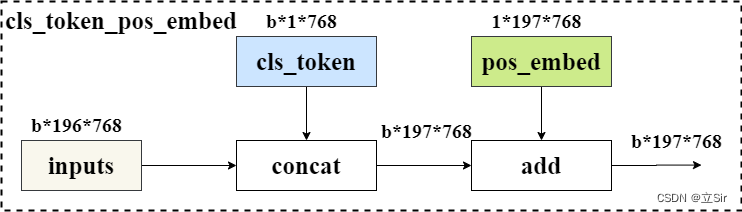
在代码中,要注意 cls_token 和 inputs 做堆叠 torch.cat() 时,需要将类别标签 cls_token 放在最前面。
代码如下:
# --------------------------------------- #
#(2)类别标签和位置标签
'''
embed_dim : 代表patchembed层输出的通道数
'''
# --------------------------------------- #
class class_token_pos_embed(nn.Module):
# 初始化
def __init__(self, embed_dim):
super(class_token_pos_embed, self).__init__()
# patchembed层将图像划分的patch个数==14*14
num_patches = patchembed().num_patches
self.num_tokens = 1 # 类别标签
# 创建可学习的类别标签 [1,1,768]
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
# 创建可学习的位置编码 [1,196+1,768]
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches+self.num_tokens, embed_dim))
# 权重以正态分布初始化
nn.init.trunc_normal_(self.pos_embed, std=0.02)
nn.init.trunc_normal_(self.cls_token, std=0.02)
# 前向传播
def forward(self, x): # 输入特征图的shape=[b,196,768]
# 类别标签扩充维度 [1,1,768]==>[b,1,768]
cls_token = self.cls_token.expand(x.shape[0], -1, -1)
# 将类别标签添加到特征图中 [b,1,768]+[b,196,768]==>[b,197,768]
x = torch.cat((cls_token, x), dim=1)
# 添加位置编码 [b,197,768]+[1,197,768]==>[b,197,768]
x = x + self.pos_embed
return x2.3 多头自注意力模块
Transformer 层中,主要包含多头注意力机制和多层感知机模块,下面先介绍多头自注意力模块。
单个的注意力机制,其每个输入包含三个不同的向量,分别为 Query向量(Q),Key向量(K),Value向量(V)。他们的结果分别由输入特征图和三个权重做矩阵乘法得到。
接着为每一个输入计算一个得分
为了使梯度稳定,对 Score 的值进行归一化处理,并将结果通过 softmax 函数进行映射。之后再和 v 做矩阵相乘,得到加权后每个输入向量的得分 v。计算完后再乘以一个权重张量 W 提取特征。
计算公式如下,其中 代表 K 向量维度的平方根
代码如下:
# --------------------------------------- #
#(3)多头注意力模块
'''
dim : 代表输入特征图的通道数
num_heads : 多头注意力中heads的个数
qkv_bias : 生成qkv时是否使用偏置
atten_drop_ratio :qk计算完之后的dropout层
proj_drop_ratio : qkv计算完成之后的dropout层
'''
# --------------------------------------- #
class attention(nn.Module):
# 初始化
def __init__(self, dim, num_heads=12, qkv_bias=False, atten_drop_ratio=0., proj_drop_ratio=0.):
super(attention, self).__init__()
# 多头注意力的数量
self.num_heads = num_heads
# 将生成的qkv均分成num_heads个。得到每个head的qkv对应的通道数。
head_dim = dim // num_heads
# 公式中的分母
self.scale = head_dim ** -0.5
# 通过一个全连接层计算qkv
self.qkv = nn.Linear(in_features=dim, out_features=dim*3, bias=qkv_bias)
# dropout层
self.atten_drop = nn.Dropout(atten_drop_ratio)
# 再qkv计算完之后通过一个全连接提取特征
self.proj = nn.Linear(in_features=dim, out_features=dim)
# dropout层
self.proj_drop = nn.Dropout(proj_drop_ratio)
# 前向传播
def forward(self, inputs):
# 获取输入图像的shape=[b,197,768]
B, N, C = inputs.shape
# 将输入特征图经过全连接层生成qkv [b,197,768]==>[b,197,768*3]
qkv = self.qkv(inputs)
# 维度调整 [b,197,768*3]==>[b, 197, 3, 12, 768//12]
qkv = qkv.reshape(B, N, 3, self.num_heads, C//self.num_heads)
# 维度重排==> [3, B, 12, 197, 768//12]
qkv = qkv.permute(2,0,3,1,4)
# 切片提取q、k、v的值,单个的shape=[B, 12, 197, 768//12]
q, k, v = qkv[0], qkv[1], qkv[2]
# 针对每个head计算 ==> [B, 12, 197, 197]
atten = (q @ k.transpose(-2,-1)) * self.scale # @ 代表在多维tensor的最后两个维度矩阵相乘
# 对计算结果的每一行经过softmax
atten = atten.softmax(dim=-1)
# dropout层
atten = self.atten_drop(atten)
# softmax后的结果和v加权 ==> [B, 12, 197, 768//12]
x = atten @ v
# 通道重排 ==> [B, 197, 12, 768//12]
x = x.transpose(1,2)
# 维度调整 ==> [B, 197, 768]
x = x.reshape(B,N,C)
# 通过全连接层融合特征 ==> [B, 197, 768]
x = self.proj(x)
# dropout层
x = self.proj_drop(x)
return x2.4 MLP 多层感知器
这个部分简单来看就是两个全连接层提取特征,流程图如下。第一个全连接层通道上升4倍,第二个全连接层通道下降为原来。

代码如下:
# --------------------------------------- #
#(4)MLP多层感知器
'''
in_features : 输入特征图的通道数
hidden_features : 第一个全连接层上升通道数
out_features : 第二个全连接层的下降的通道数
drop : 全连接层后面的dropout层的杀死神经元的概率
'''
# --------------------------------------- #
class MLP(nn.Module):
# 初始化
def __init__(self, in_features, hidden_features, out_features=None, drop=0.):
super(MLP, self).__init__()
# MLP的输出通道数默认等于输入通道数
out_features = out_features or in_features
# 第一个全连接层上升通道数
self.fc1 = nn.Linear(in_features=in_features, out_features=hidden_features)
# GeLU激活函数
self.act = nn.GELU()
# 第二个全连接下降通道数
self.fc2 = nn.Linear(in_features=hidden_features, out_features=out_features)
# dropout层
self.drop = nn.Dropout(drop)
# 前向传播
def forward(self, inputs):
# [b,197,768]==>[b,197,3072]
x = self.fc1(inputs)
x = self.act(x)
x = self.drop(x)
# [b,197,3072]==>[b,197,768]
x = self.fc2(x)
x = self.drop(x)
return x2.5 特征提取模块
Transformer 的单个特征提取模块是由 多头注意力机制 和 多层感知机模块 组合而成,encoder_block 模块的流程图如下。

输入图像像经过 LayerNormalization 标准化后,再经过我们上面定义的多头注意力模块,将输出结果和输入特征图残差连接,图像在特征提取过程中shape保持不变。
将输出结果再经过标准化,然后送入多层感知器提取特征,再使用残差连接输入和输出。
而 transformer 的特征提取模块是由多个 encoder_block 叠加而成,这里连续使用12个 encoder_block 模块来提取特征。
代码如下:
# --------------------------------------- #
#(5)Encoder Block
'''
dim : 该模块的输入特征图个数
mlp_ratio : MLP中第一个全连接层上升的通道数
drop_ratio : 该模块的dropout层的杀死神经元的概率
'''
# --------------------------------------- #
class encoder_block(nn.Module):
# 初始化
def __init__(self, dim, mlp_ratio=4., drop_ratio=0.):
super(encoder_block, self).__init__()
# LayerNormalization层
self.norm1 = nn.LayerNorm(dim)
# 实例化多头注意力
self.atten = attention(dim)
# dropout
self.drop = nn.Dropout()
# LayerNormalization层
self.norm2 = nn.LayerNorm(dim)
# MLP中第一个全连接层上升的通道数
hidden_features = int(dim * mlp_ratio)
# MLP多层感知器
self.mlp = MLP(in_features=dim, hidden_features=hidden_features)
# 前向传播
def forward(self, inputs):
# [b,197,768]==>[b,197,768]
x = self.norm1(inputs)
x = self.atten(x)
x = self.drop(x)
feat1 = x + inputs # 残差连接
# [b,197,768]==>[b,197,768]
x = self.norm2(feat1)
x = self.mlp(x)
x = self.drop(x)
feat2 = x + feat1 # 残差连接
return feat22.6 主干网络
接下来就搭建网络了,将上面所有的模块组合到一起,如下图所示。

在下面代码中要注意的是 x= x[:,0] 取出所有的类别标签。 因为在 cls_pos_embed 模块中,我们将 cls_token 和输入图像在 patch 维度上堆叠,用于学习每张特征图的类别信息。最后经过一个全连接层得出每张图片属于每个类别的得分。
代码如下:
# --------------------------------------- #
#(6)主干网络
'''
num_class: 分类数
depth : 重复堆叠encoder_block的次数
drop_ratio : 位置编码后的dropout层
embed_dim : patchembed层输出通道数
'''
# --------------------------------------- #
class VIT(nn.Module):
# 初始化
def __init__(self, num_classes=1000, depth=12, drop_ratio=0., embed_dim=768):
super(VIT, self).__init__()
self.num_classes = num_classes # 分类类别数
# 实例化patchembed层
self.patchembed = patchembed()
# 实例化类别标签和位置编码
self.cls_pos_embed = class_token_pos_embed(embed_dim=embed_dim)
# 位置编码后做dropout
self.pos_drop = nn.Dropout(drop_ratio)
# 在列表中添加12个encoder_block
self.blocks = nn.Sequential(*[encoder_block(dim=embed_dim) for _ in range(depth)])
# 定义LayerNormalization标准化方法
norm_layer = partial(nn.LayerNorm, eps=1e-6)
# 经过12个encoder之后的标准化层
self.norm = norm_layer(embed_dim)
# 分类层
self.head = nn.Linear(in_features=embed_dim, out_features=num_classes)
# 权值初始化
for m in self.modules():
# 对卷积层使用kaiming初始化
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out')
# 对偏置初始化
if m.bias is not None:
nn.init.zeros_(m.bias)
# 对标准化层初始化
elif isinstance(m, nn.LayerNorm):
nn.init.ones_(m.weight)
nn.init.zeros_(m.bias)
# 对全连接层初始化
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
if m.bias is not None:
nn.init.zeros_(m.bias)
# 前向传播
def forward(self, inputs):
# 先将输入传递给patchembed [b,3,224,224]==>[b,196,768]
x = self.patchembed(inputs)
# 对特征图添加类别标签和位置编码
x = self.cls_pos_embed(x)
# dropout层
x = self.pos_drop(x)
# 经过12个encoder层==>[b,197,768]
x = self.blocks(x)
# LN标准化层
x = self.norm(x)
# 提取类别标签的输出,因为在cat时将类别标签放在最前面
x = x[:, 0] # [b,197,768]==>[b,768]
# 全连接层分类 [b,768]==>[b,1000]
x = self.head(x)
return x3. 训练阶段
接下来对使用权重迁移学习的方法训练模型,这里用的网络是 VIT B-16 模型,patch的尺寸为16*16,patchembedding的输出通道数为768。首先导入所有的工具包,定义好所有需要的参数,找到文件路径,方便后期使用管理。
import torch
from torch import nn, optim
from torchvision import transforms, datasets
from torch.utils.data import DataLoader
from VisionTransformer_model import VIT # 导入我们之前定义的 VIT B-16 模型
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 绘图显示中文
# --------------------------------------------- #
#(0)参数设置
# --------------------------------------------- #
batch_size = 16 # 每个step处理16张图片
epochs = 10 # 训练10轮
best_loss = 1.0 # 当验证集损失小于1时才保存权重
# 数据集目录位置
filepath = 'D:/deeplearning/test/数据集/animal/'
# 预训练权重位置
weightpath = 'D:/deeplearning/imgnet/pytorchimgnet/pretrained_weights/vit_base_patch16_224.pth'
# 训练时保存权重文件的位置
savepath = 'D:/deeplearning/imgnet/pytorchimgnet/save_weights/'
# 获取GPU设备,检测到了就用GPU,检测不到就用CPU
if torch.cuda.is_available():
device = torch.device('cuda:0')
else:
device = torch.device('cpu')3.1 构造数据集
首先定义训练集和验证集的数据预处理方法 data_transform。通过 transforms.Resize() 将输入图像的尺寸缩放到模型要求的 224*224 大小,然后再通过 transforms.ToTensor() 将像素值类型从 numpy 变成 tensor 类型,并归一化处理,像素值大小从 [0,255] 变换到 [0,1],再调整输入图像的维度,从 [h,w,c] 变成 [c,h,w];接着 transforms.Normalize() 对图像的每个颜色通道做标准化处理,使像素值满足正态分布。
预处理之后就构造训练集和验证集 dataloader,指定 batch_size=16,代表训练时每个 step 训练16张图片。
接着查看数据集信息,查看分类类别及其对应的索引信息,其中 datasets['train'].class_to_idx 的结果是 {'cats':0, 'dogs':1, 'panda':2}
代码如下:
# --------------------------------------------- #
#(1)数据集处理
# --------------------------------------------- #
# 定义预处理方法
data_transform = {
# 训练集预处理方法
'train' : transforms.Compose([
transforms.Resize((224,224)), # 将原始图片缩放至224*224大小
transforms.RandomHorizontalFlip(), # 随机水平翻转
transforms.ToTensor(), # numpy类型变tensor,维度调整,数据归一化
transforms.Normalize(mean=[0.485,0.456,0.406], std=[0.229,0.224,0.225]) # 对图像的三个通道分别做标准化
]),
# 验证集预处理方法
'val' : transforms.Compose([
transforms.Resize((224,224)), # 将输入图像缩放至224*224大小
transforms.ToTensor(),
transforms.Normalize(mean=[0.485,0.456,0.406], std=[0.229,0.224,0.225])
])
}
# 加载数据集
datasets = {
'train' : datasets.ImageFolder(filepath+'train', transform=data_transform['train']), # 读取训练集
'val' : datasets.ImageFolder(filepath+'val', transform=data_transform['val']) # 读取验证集
}
# 构造数据集
dataloader = {
'train' : DataLoader(datasets['train'], batch_size=batch_size, shuffle=True), # 构造训练集
'val' : DataLoader(datasets['val'], batch_size=batch_size, shuffle=True) # 构造验证集
}
# --------------------------------------------- #
#(2)查看数据集信息
# --------------------------------------------- #
train_num = len(datasets['train']) # 查看训练集数量
val_num = len(datasets['val']) # 查看验证集数量
# 查看分类类别及其索引 {0: 'cats', 1: 'dogs', 2: 'panda'}
class_names = dict((v,k) for k,v in datasets['train'].class_to_idx.items())
print(class_names)
# 从训练集中取出一个batch,接收图片及其标签
train_imgs, train_labels = next(iter(dataloader['train']))
# 查看图像的标签及其shape [32, 3, 224, 224] [32]
print('img:', train_imgs.shape, 'labels:', train_labels.shape)3.2 数据可视化
可视化训练集中的前12张图像。由于构造数据集时使用了一系列预处理方法,因此这里要将像素类型从 tensor 变成 numpy,调整图像的维度 [b,c,h,w]==>[b,h,w,c],对图像的每个通道执行反标准化操作,恢复到0-1之间的随机分布。
标准化: 反标准化:
代码如下:
# --------------------------------------------- #
#(3)数据可视化
# --------------------------------------------- #
# 从数据集中取出12张图及其标签
frames = train_imgs[:12]
frames_labels = train_labels[:12]
# 将数据类型从tensor变回numpy
frames = frames.numpy()
# 维度调整 [b,c,h,w]==>[b,h,w,c]
frames = np.transpose(frames, [0,2,3,1])
# 对图像做反标准化处理
mean = [0.485, 0.456, 0.406] # 均值
std = [0.229, 0.224, 0.225] # 标准化
# 图像的每个通道的特征图乘标准化加均值
frames = frames * std + mean
# 将像素值限制在0-1之间
frames = np.clip(frames, 0, 1)
# 绘制12张图像及其标签
plt.figure() # 创建画板
for i in range(12):
plt.subplot(3,4,i+1)
plt.imshow(frames[i])
plt.axis('off') # 不显示坐标刻度
plt.title(class_names[frames_labels[i].item()]) # 显示每张图片的标签
plt.tight_layout() # 轻量化布局
plt.show()查看训练集中的图像

3.3 模型加载,迁移学习
首先加载预训练权重 torch.load() 到内存中。由于预训练模型的分类数有1000个,即最后一个全连接层有 1000 个神经元,因此我们只用预训练权重的特征提取部分,不需要分类层部分。
遍历预训练权重文件,删除分类层 'head.weight', 'head.bias' 的权重。
这里不冻结预训练权重,所有权重参数都能通过反向传播更新。
代码如下:
# --------------------------------------------- #
#(4)模型加载,迁移学习
# --------------------------------------------- #
# 接收VIT模型,三分类
model = VIT(num_classes=3)
# 加载预训练权重文件,文件中的分类层神经元个数是1k
pre_weights = torch.load(weightpath, map_location=device)
# 删除权重文件中不需要的层,保留除了分类层以外的所有层的权重
del_keys = ['head.weight', 'head.bias']
# 删除字典中的对应key
for k in del_keys:
del pre_weights[k]
# 将修改后的权重加载到模型上
# 当strict=True,要求预训练权重层数的键值与新构建的模型中的权重层数名称完全吻合
missing_keys, unexpected_keys = model.load_state_dict(pre_weights, strict=False)
print('miss:', len(missing_keys), 'unexpected:', len(unexpected_keys))
# model.parameters() 代表网络的所有参数
for params in model.parameters():
params.requires_grad = True # 所有权重参与训练可以更新3.4 模型训练
接下来进行网络训练,将所有需要计算的部分都搬运到 GPU 上,加快训练速度。
我这里使用每个epoch的验证集损失作为网络监控指标,如果损失小于规定值且一直在下降就保存当前 epoch 的权重。
还要注意的就是网络训练和测试的模式不一样,训练时 Dropout 层随机杀死神经元,BN 层取一个batch的均值和方差;验证时 Dropout 层不起作用,BN 层取整个训练集计算得到的均值和方差。通过 net.train() 和 net.eval() 来切换训练和验证模式。
代码如下:
# --------------------------------------------- #
#(5)网络编译
# --------------------------------------------- #
# 将模型搬运至GPU上
model.to(device)
# 定义交叉熵损失
loss_function = nn.CrossEntropyLoss()
# 获取所有需要梯度更新的权重参数
params_optim = []
# 遍历网络的所有权重
for p in model.parameters():
if p.requires_grad is True: # 查看权重是否需要更新
params_optim.append(p) # 保存所有需要更新的权重
print('训练参数:', len(params_optim))
# 定义优化器,定义学习率,动量,正则化系数
optimizer = optim.SGD(params_optim, lr=0.001, momentum=0.9, weight_decay=3e-4)
# --------------------------------------------- #
#(6)训练阶段
# --------------------------------------------- #
for epoch in range(epochs):
print('='*30) # 显示当前是第几个epoch
# 将模型设置为训练模式
model.train()
# 记录一个epoch的训练集总损失
total_loss = 0.0
# 每个step训练一个batch,每次取出一个数据集及其标签
for step, (images, labels) in enumerate(dataloader['train']):
# 将数据集搬运到GPU上
images, labels = images.to(device), labels.to(device)
# 梯度清零,因为梯度是累加的
optimizer.zero_grad()
# 前向传播==>[b,3]
logits = model(images) # 得到每张图属于3个类别的分数
#(1)损失计算
# 计算每个step的预测值和真实值的交叉熵损失
loss = loss_function(logits, labels)
# 累加每个step的损失
total_loss += loss
#(2)反向传播
# 梯度计算
loss.backward()
# 梯度更新
optimizer.step()
# 每50个epoch打印一次损失值
if step % 50 == 0:
print(f'step:{step}, train_loss:{loss}')
# 计算一个epoch的训练集平均损失
train_loss = total_loss / len(dataloader['train'])
# --------------------------------------------- #
#(7)验证训练
# --------------------------------------------- #
model.eval() # 切换到验证模式
total_val_loss = 0.0 # 记录一个epoch的验证集总损失
total_val_correct = 0 # 记录一个epoch中验证集一共预测对了几个
with torch.no_grad(): # 接下来不计算梯度
# 每个step验证一个batch
for (images, labels) in dataloader['val']:
# 将数据集搬运到GPU上
images, labels = images.to(device), labels.to(device)
# 前向传播[b,c,h,w]==>[b,3]
logits = model(images)
#(1)计算损失
# 计算每个batch的预测值和真实值的交叉熵损失
loss = loss_function(logits, labels)
# 累加每个batch的损失,得到一个epoch的总损失
total_val_loss += loss
#(2)计算准确率
# 找到预测值对应的最大索引,即该图片对应的类别
pred = logits.argmax(dim=1) # [b,3]==>[b]
# 比较预测值和标签值,计算每个batch有多少预测对了
val_correct = torch.eq(pred, labels).float().sum()
# 累加每个batch的正确个数,计算整个epoch的正确个数
total_val_correct += val_correct
# 计算一个epoch的验证集的平均损失和平均准确率
val_loss = total_val_loss / len(dataloader['val'])
val_acc = total_val_correct / val_num
# 打印每个epoch的训练集平均损失,验证集平均损失和平均准确率
print('-'*30)
print(f'train_loss:{train_loss}, val_loss:{val_loss}, val_acc:{val_acc}')
# --------------------------------------------- #
#(8)保存权重
# --------------------------------------------- #
# 保存最小损失值对应的权重文件
if val_loss < best_loss:
# 权重文件名称
savename = savepath + f'epoch{epoch}_valacc{round(val_acc.item()*100)}%_' + 'VIT.pth'
# 保存该轮次的权重
torch.save(model.state_dict(), savename)
# 切换最小损失值
best_loss = val_loss
# 打印结果
print(f'weights has been saved, best_loss has changed to {val_loss}')
训练过程如下:
==============================
step:0, train_loss:0.9088920950889587
step:50, train_loss:2.3867087364196777
step:100, train_loss:2.1412224769592285
------------------------------
train_loss:1.7520136833190918, val_loss:2.2571213245391846, val_acc:0.5276381969451904
==============================训练过程中保存权重:

4. 预测阶段
接下来我们用训练好了的权重文件来预测图像的类别。同样先导入所有需要用到的工具包。
代码如下:
import torch
from torchvision import transforms, datasets
from torch.utils.data import DataLoader
from PIL import Image
from VisionTransformer_model import VIT
import numpy as np
import matplotlib.pyplot as plt
# -------------------------------------------------- #
#(0)参数设置
# -------------------------------------------------- #
batch_size = 32 # 每次测试32张图
# 测试集文件夹所在位置
file_path = 'D:/deeplearning/test/数据集/animal/test'
# 权重参数路径
weights_path = 'D:/deeplearning/imgnet/pytorchimgnet/save_weights/epoch5_valacc59%_VIT.pth'
# 获取GPU设备
if torch.cuda.is_available(): # 如果有GPU就用,没有就用CPU
device = torch.device('cuda:0')
else:
device = torch.device('cpu')4.1 构造数据集
这里测试集的预处理采用和验证集相同的预处理方法。这部分和上面相同,就不多做介绍。
# -------------------------------------------------- #
#(1)构造测试集
# -------------------------------------------------- #
# 定义测试集的数据预处理方法
data_transforms = transforms.Compose([
transforms.Resize((224,224)), # 将输入图像的size缩放至224*224
transforms.ToTensor(), # numpy边tensor,像素归一化,维度调整
transforms.Normalize(mean=[0.485,0.456,0.406], std=[0.229,0.224,0.225]) # 对每个通道标准化
])
# 加载测试集,并预处理
datasets = datasets.ImageFolder(file_path, transform=data_transforms)
# 构造测试集
dataloader = DataLoader(datasets, batch_size=batch_size, shuffle=True)
# 查看测试集一共有多少张图
test_num = len(datasets)
# 获取测试集的分类类别及其索引 {0: 'cats', 1: 'dogs', 2: 'panda'}
class_names = dict((v,k) for k,v in datasets.class_to_idx.items())4.2 多图像预测
取测试集的每个 Batch 的前12张图片,查看其预测结果。这里也需要做一次反标准化操作,和上面第三小节中相同。
在网络前向传播之前将模型设置为验证模式 model.eval(),只做前向传播的操作,不进行梯度更新操作 with torch.no_grad() 不计算梯度。
经过前向传播后,图像的shape变成 [b,3],即图片预测属于3种类别的分数,然后经过softmax()求出图片属于每个类别的概率,通过torch.max()找出最大概率及其索引,得到图片属于哪个类别。
代码如下:
# -------------------------------------------------- #
#(2)绘图展示预测结果
# imgs:代表输入图像[b,c,h,w],labels代表图像的真实标签[b]
# cls:代表每张图属的类别索引[b],scores:代表每张图的类别概率[b]
# -------------------------------------------------- #
def im_show(imgs, labels, cls, scores):
# 从数据集中取出12张图及其标签索引、概率
frames = imgs[:12]
true_labels = labels[:12]
pred_labels = cls[:12]
pred_scores = scores[:12]
# 将数据类型从tensor变回numpy
frames = frames.numpy()
# 维度调整 [b,c,h,w]==>[b,h,w,c]
frames = np.transpose(frames, [0,2,3,1])
# 对图像做反标准化处理
mean = [0.485, 0.456, 0.406] # 均值
std = [0.229, 0.224, 0.225] # 标准化
# 图像的每个通道的特征图乘标准化加均值
frames = frames * std + mean
# 将像素值限制在0-1之间
frames = np.clip(frames, 0, 1)
# 绘制12张图像及其标签
plt.figure() # 创建画板
for i in range(12):
plt.subplot(3,4,i+1)
plt.imshow(frames[i])
plt.axis('off') # 不显示坐标刻度
# 显示每张图片的真实标签、预测标签、预测概率
plt.title('true:'+class_names[true_labels[i].item()] + '\n' +
'pred:'+class_names[pred_labels[i].item()] + '\n' +
'scores:'+str(round(pred_scores[i].item(), 3))
)
plt.tight_layout() # 轻量化布局
plt.show()
# -------------------------------------------------- #
#(3)图像预测
# -------------------------------------------------- #
# 模型构建
model = VIT(num_classes=3)
# 加载权重文件
model.load_state_dict(torch.load(weights_path, map_location=device))
# 将模型搬运到GPU上
model.to(device)
# 模型切换成测试模式,切换LN标准化和dropout的工作方式
model.eval()
# 测试阶段不计算梯度
with torch.no_grad():
# 每次测试一个batch
for step, (imgs, labels) in enumerate(dataloader):
# 将数据集搬运到GPU上
images, labels = imgs.to(device), labels.to(device)
# 前向传播==>[b,3]
logits = model(images)
# 求出图像属于哪个类别索引[b,3]==>[b]
pred_cls = logits.argmax(dim=1)
# 计算图像属于每个类别的概率[b,3]==>[b,3]
predicts = torch.softmax(logits, dim=1)
# 获取最大预测类别的概率[b,3]==>[b]
predicts_score, _ = predicts.max(dim=1)
# 绘制预测结果
im_show(imgs, labels, pred_cls, predicts_score)查看预测结果:图像标题是真实类别、预测类别、预测概率值
