文章目录
一、 顺序容器
1. vector
vector向量容器
底层数据结构:动态开辟的数组,在windows下的vs2017,2019上用vector是1.5倍扩容的,当在Linux下用gcc,g++去编译是2倍扩容的。
初始化
vector<int> v1;//向量中没有元素
vector<int> v1(10);//向量中10个元素全为0
vector<int> v1(10,1);//向量中10个元素全为1
vector<int> v1(v1);
vector<int> v1={
1,2,3};
增加:导致容器扩容
v1.push_back(20);//末尾添加元素,时间复杂度为O(1)
v1.insert(it,20);//在it迭代器指向的位置添加一个元素20,时间复杂度是O(n)
v1.insert(v1.begin(),3,9);//在首部添加3个9
删除
v1.pop_back();//末尾删除元素,O(1)
v1.erase(it);//删除it迭代器指向的元素
v1.erase(v1.begin(),v1.end()-2);//删除区间元素,其他元素前移。左闭右开
v1.clear();//删除所有元素
[ 注意 ] 对容器进行连续或插入删除操作(insert/erase),一定要更新迭代器,否则第一次insert或者erase完成,迭代器就失效了。
查询、遍历
//通过operator[],下标的随机访问
for(int i = 0; i < v1.size(); i++)
{
cout << v1[i] << " ";
}
//通过迭代器进行遍历
for(vector<int>::iterator it = v1.begin(); it != v1.end(); it++)
{
cout << *it << " ";
}
//迭代器反向输出
for(vector<int>::reverse_iterator it = v1.rbegin(); it != v1.rend(); it++)
{
cout << *it << " ";
}
//for...each..,也是通过迭代器实现的
for(int i : v1)
{
cout << i << " ";
}
//索引
for(int i = 0; i < v1.size(); i++)
{
cout << v1.at(i) << " ";
}
常用方法介绍
size():返回容器底层元素的个数
empty():判断容器是否为空
v1.swap(v2):两个容器进行元素交换
reverse(n):给容器底层预留n个元素空间,并不会添加新元素(vec.size()==0 && vec.capacity()==n)
resize(n):不仅给容器底层预留n个空间,此时容器内也会有n个元素(vec.size()==n && vec.capacity()==n)
2. deque
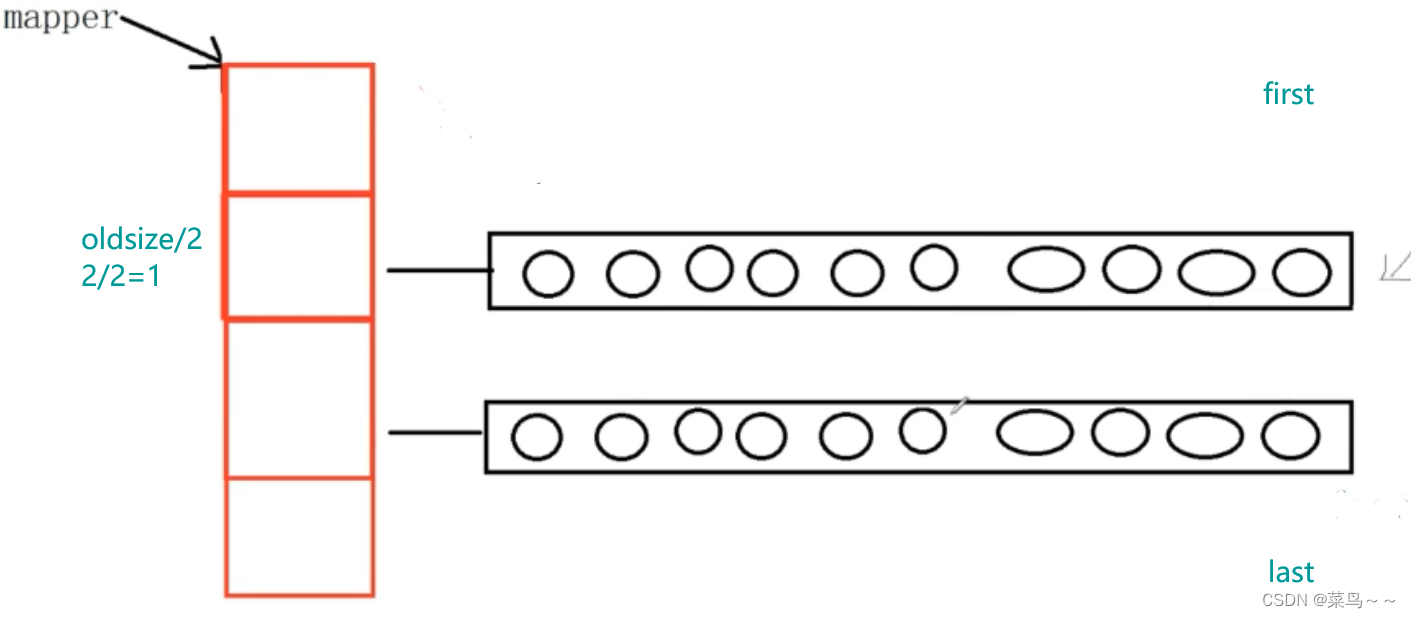
deque是双端队列容器,底层是动态开辟的二维数组。一维数组从2开始,以2倍的方式进行扩容,每次扩容后原来第二维数组从新的第一维数组下标oldsize/2开始存放,上下留出相同的空间,方便deque首尾元素添加。
由于是双端队列,所以最开始的时候,first和last都是指向相同的地方
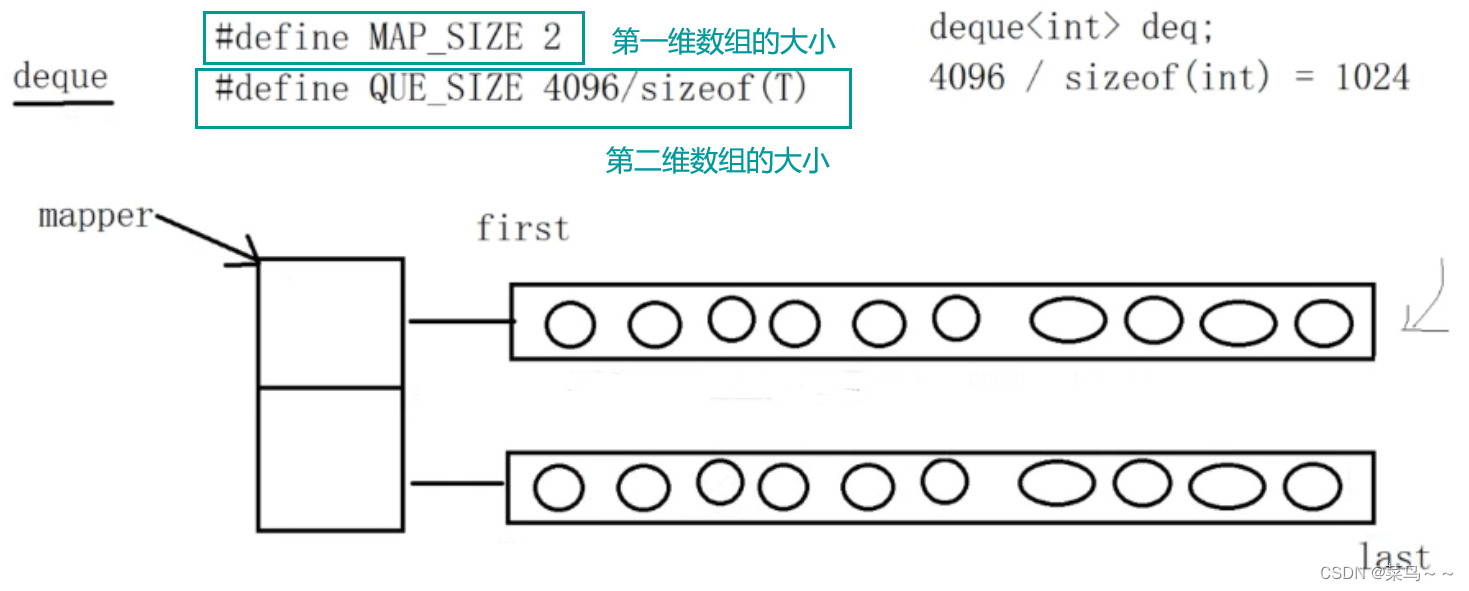
扩容后:
初始化
deque<int> deq;
增加
deq.push_back(20);//从末尾添加元素,O(1)
deq.push_front(20);//从首部添加元素,O(1)
deq.insert(it,20);//it指向的位置添加元素,O(n)
删除
deq.pop_back();//从末尾删除元素,O(1)
deq.pop_front();//从首部删除元素,O(1)
deq.erase(it);//从it指向的位置删除元素,O(1)
查询搜索:和vector一样,连续的insert和erase一定要考虑迭代器失效问题。
剩余的其他常用方法和vector一样。
3. list
双向循环列表,每一个节点都有data,next和pre。增加删除查询和deque一样。
链表的一个好处就是插入删除并不需要像数组一样涉及其他元素的移动,O(1)操作,只需要更改地址域;查询操作就比较慢。
deque和list比vector容器多出来的增加删除函数接口:push_front和pop_front
4. vector、deque和list的区别
vector的特点:动态数组,内存是连续的,2倍的方式进行扩容,0-1-2-4-8…,而扩容所带来的效率不是很高,因为它要在新的内存上拷贝构造原来老内存的对象,再把原来老内存的对象析构、内存释放。
deque的特点:动态开辟的二维数组空间,第二维是固定长度的数组空间,扩容的时候第一维的数组进行2倍扩容,扩容后原来第二维数组从新的第一维数组下标oldsize/2开始存放,上下留出相同的空间,方便deque首尾元素增加删除。
deque底层内存是否是连续的?
不是。deque每一个第二维是连续的,但是不是所有的第二维都是连续的,因为deque是一个动态开辟的二维数组,deque是分段连续的。可以画图展示为什么。
vector和deque的区别?
- 底层数据结构:vector是动态扩容的一维数组,deque是动态扩容的二维数组
- 前中后插入删除元素的时间复杂度:在中间和末尾的插入删除是一样的都是O(1),但是在最前面插入删除元素deque是O(1),因为deque是双端队列,在前面直接插入删除就可以,不涉及移动。vector是O(n),因为vector是动态开辟的一维数组,给最前面添加删除元素后面元素都必须移动。如果解决问题的应用场景里面涉及前中后元素的增加删除,选择deque更好。
- 内存的使用效率:vector需要的内存空间完全连续,deque只要求部分连续即可,可以分块进行数据存储,对内存使用效率更高。
- 在中间进行insert或erase的时候:vector由于内存完全连续,移动元素方便。而deque第二维内存空间不是连续的,所以在deque中间进行insert活erase,造成元素移动的时候比vector慢。
vector和list的区别?
vector和list区别即数组和链表的区别。
- vector底层是一个内存可以2倍扩容的数组,它提供了尾部的增删操作(push_back和pop_back),都是O(1)操作,其余地方的增删操作为O(n)。所以vector适合随机访问元素,因为内存是连续的,比如优先级队列是基于vector实现(因为优先级队列底层实现默认是一个大根堆,大根堆是把我们的节点想象成一个二叉树,而二叉树的父节点和孩子节点通过下标的偏移来访问),不适合增删,因为增删操作O(n)。
- list是一个循环的双向链表,适合增删,每个节点都是new出来的不连续,但是由于它是链表,push_back和pop_back,push_front和pop_front时间都是O(1)
二、容器适配器
容器适配器底层没有自己的数据结构,也没有实现自己的迭代器,它是另外一个容器的封装,它的方法全部由底层依赖的容器进行实现,就是一种代理。
1. stack
依赖deque适配的,底层还是deque方法,但它把deque方法封装了,给我们提供了push、pop操作。
template<typename T,typename Container = deque<T>>
class stack
{
public:
void push(const T& val)
{
con.push_back(val);
}
void pop()
{
con.pop_back();
}
T top()const
{
return con.back();
}
private:
Container con;
};
常用方法
stack<int> s;
s.push(20);//入栈
s.pop();//出栈
s.top();//查看栈顶元素
s.empty();//判断栈空
s.size();//返回栈顶元素个数
2. queue
依赖deque
常用方法
queue<int> que;
que.push(20);//入队
que.pop();//出队
que.back();//查看队尾元素
que.front();//查看队头元素
que.empty();//判断队空
que.size();//返回元素个数
stack和queue为什么依赖deque,而不依赖vector?
- vector的内存利用效率太低;vector扩容0->1->2->4->8才慢慢开始扩容,而deque默认开辟的第一个第二维4096/sizeof(T),deque无需很多内存扩容操作。
- 对于queue来说,需要支持头删尾插操作。vector只在尾部操作快,头部操作很慢,如果queue底层依赖vector出队效率很低。而deque则两头操作都是O(1)
- vector需要大片连续内存,而deque只要求内存部分连续。当存储数据较多时,deque内存效率更高。
3. priority_queue
优先级队列,实现的是一个大根堆,通过下标的计算访问每个元素,所以基于vector。
常用方法
priority_queue<int> pque;
pque.push(20);//入队
pque.pop();//出队
pque.top();//查看队顶元素
que.empty();//判断队空
que.size();//返回元素个数
priority_queue为什么依赖vector,而不依赖deque?
由于priority_queue底层是一个大根堆结构,大根堆是一颗完全二叉树,存储方式是数组,根据坐标之间的关系来区分根节点、左孩子和右孩子, 根据坐标索引来访问数据结构中的相应元素,这就需要我们每一个元素内存是绝对连续的,这样计算下标之间的关系才有意义,所以我们需要在一个内存连续的数组上构建一个大根堆或者小根堆,而deque的第二维不是连续的,vector是完全连续的。
三、关联容器

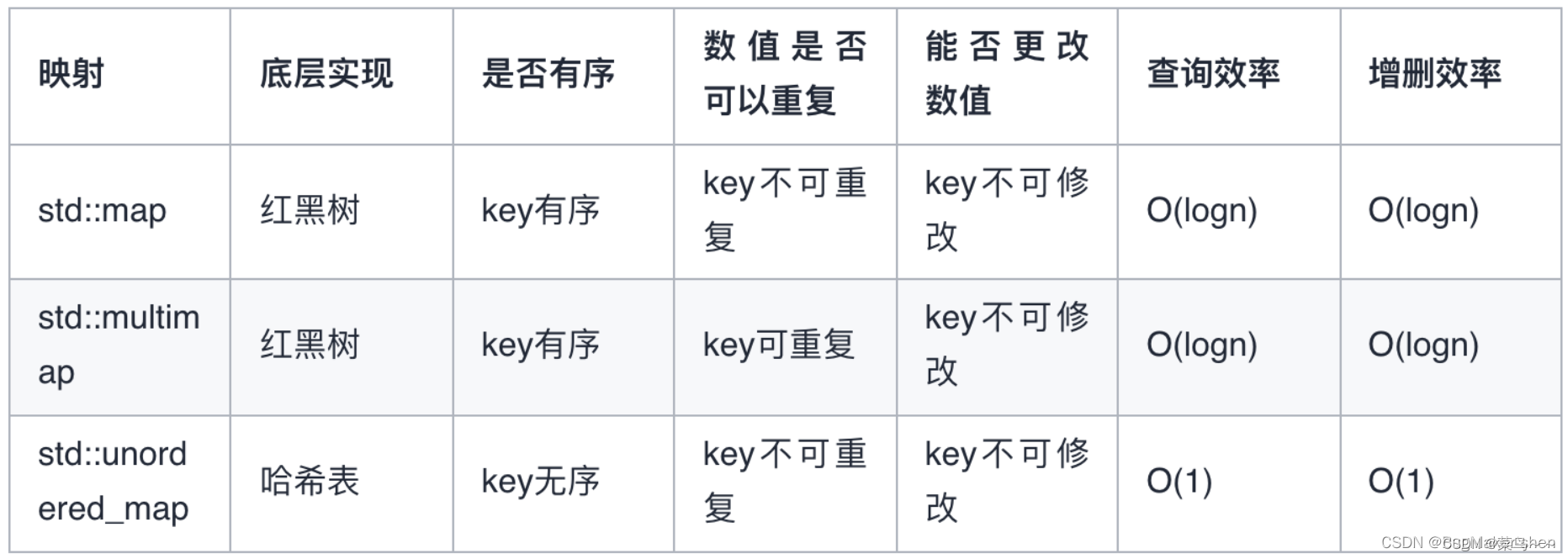
1. 无序关联容器
底层是链式哈希表,增删查是O(1)
unordered_set:可以用来海量数据去重
#include<iostream>
#include<unordered_set>
using namespace std;
int main() {
unordered_set<int> set1;//不会存储key值重复的元素
// 1. 插入
for (int i = 0; i < 20; i++) {
set1.insert(rand() % 20);
}
// cout << set1.size() << endl; // < 20
// cout << set1.count(5) << endl; // 0或1
// 2. 遍历,迭代器可访问所有容器
for (auto iter = set1.begin(); iter != set1.end(); iter++) {
cout << *iter << " ";
}
cout << endl;
// for_each,底层就是用迭代器
for (int v : set1) {
cout << v << " ";
}
cout << endl;
// 3. 删除 erase(iter), erase(key)
for (auto iter = set1.begin(); iter != set1.end(); ) {
if (*iter == 10) {
// erase后iter失效,删除后从当前位置开始比较,不用++
iter = set1.erase(iter);
}
else {
iter++;
}
}
// 4. 查找find(key),找到返回对应位置iter,否则返回end()
auto iter = set1.find(20);
if (iter != set1.end()) {
set1.erase(iter);
}
return 0;
}
unordered_map:可以用来处理海量数据查重复
map的operator[]的功能:
- 查询
- 如果key不存在,它会插入一对数据[key,value]
#include<iostream>
#include<unordered_map>
#include<string>
using namespace std;
int main()
{
unordered_map<int,string> map1;
map1.insert(make_pair(1000,"张三"));
map1.insert({
1010,"李四"});
map1.insert({
1020,"王五"});
map1.insert({
1000,"王凯"});
cout << map1.size() << endl;//3,key值不重复
cout << map1[1000] << endl;//张三
map1.erase(1020);
map1[2000];//key:2000;value:""
map1[2001]="刘硕";//map1.insert({2001,"刘硕"});
map1[1000] = "张三2";
auto it = map1.find(1030);
if(it != map1.end())
{
cout << "key:" << it->first << "value:" << it->second << endl;
}
}
unordered_multimap
#include<iostream>
#include<unordered_map>
#include<string>
using namespace std;
int main()
{
unordered_map<int,string> map1;
map1.insert(make_pair(1000,"张三"));
map1.insert({
1010,"李四"});
map1.insert({
1020,"王五"});
map1.insert({
1000,"王凯"});
cout << map1.size() << endl;//4,key值可以重复
}
2. 有序关联容器
底层是红黑树,增删查是O(logn),
用自定义类型使用有序关联容器的时候,set要给提供operator<运算符重载函数,map不用提供,使用key就可以排序。
set:有序,不可以重复
用迭代器去遍历是红黑树中序遍历的结果
#include<iostream>
#include<set> // set multiset 红黑树
using namespace std;
class Student {
public:
Student(int id, string name) :_id(id), _name(name) {
};
//用自定义类型使用有序关联容器的时候,要给提供operator<运算符重载函数
bool operator<(const Student& stu) const{
return _id < stu._id;
}
private:
int _id;
string _name;
friend ostream& operator<<(ostream& out, const Student& stu);
};
ostream& operator<<(ostream& out, const Student& stu) {
out << stu._id << " " << stu._name << endl;
return out;
}
int main() {
set<Student> set1;
set1.insert(Student(10, "张三"));
set1.insert(Student(30, "李二"));
set1.insert(Student(20, "王五"));
for (const Student& stu : set1) {
cout << stu;
}
return 0;
}
map:有序,不可以重复
#include<iostream>
#include<map> // map multimap 红黑树
using namespace std;
class Student {
public:
// 对于存放于map的元素,记得给默认构造函数(mp[key]也可能插入元素)
Student(int id=0, string name=string()) :_id(id), _name(name) {
};
private:
int _id;
string _name;
friend ostream& operator<<(ostream& out, const Student& stu);
};
ostream& operator<<(ostream& out, const Student& stu) {
out << stu._id << " " << stu._name << endl;
return out;
}
int main() {
map<int, Student> mp;
mp.insert(make_pair(10, Student(10, "张三")));
mp.insert(pair<int, Student>(30, Student(30, "李二")));
mp.insert({
20, Student(20, "王五") });
for (auto iter = mp.begin(); iter != mp.end(); iter++) {
cout << iter->first << " " << iter->second;
}
return 0;
}