简单回顾下虚拟内存技术,基于局部性原理来实现,总结起来就是两句话:
- 在程序执行过程中,当 CPU 所需要的信息不在内存中的时候,由操作系统负责将所需信息从外存(磁盘)调入内存,然后继续执行程序
- 如果调入内存的时候内存空间不够,由操作系统负责将内存中暂时用不到的信息换出到外存
整个请求调页的过程大概是这样的:
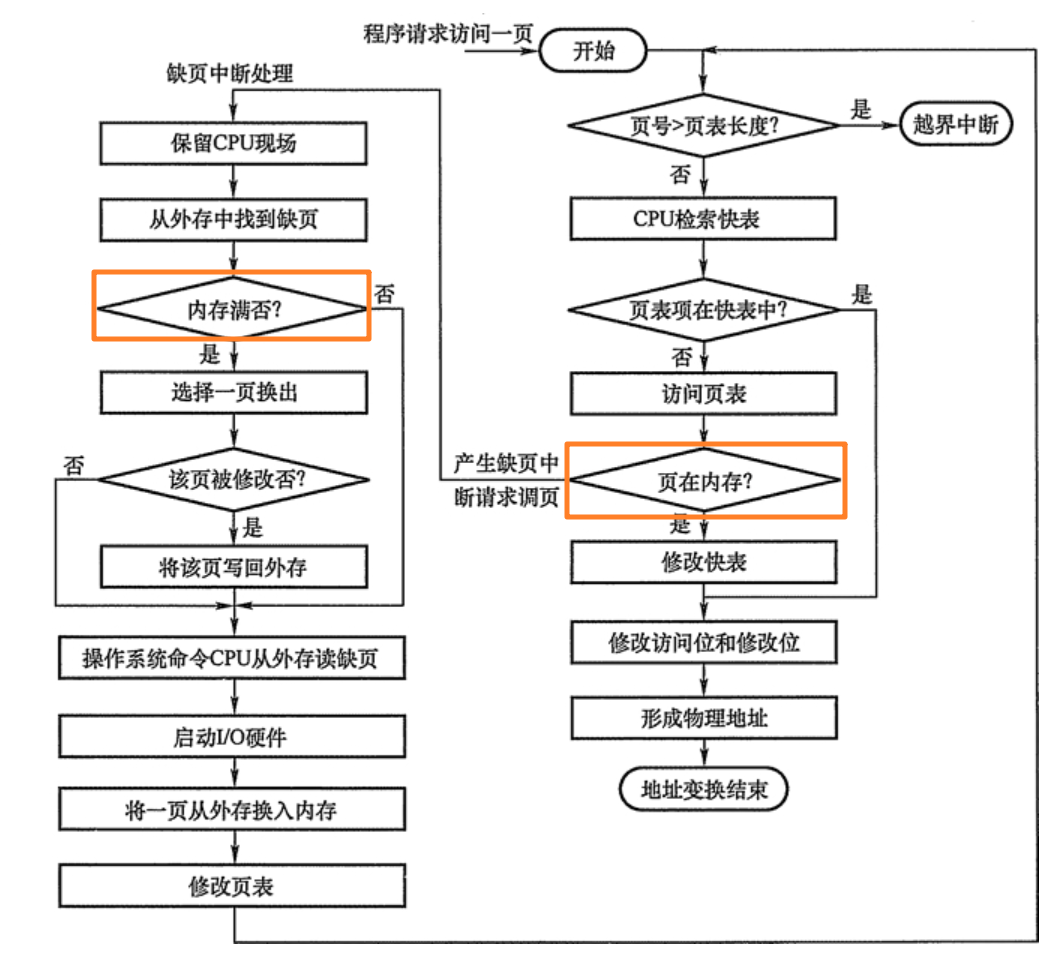
那么,到底哪些页面该被从内存中换出来,哪些页面又该被从磁盘中调入内存呢?
这就是『页面置换算法』干的事儿。
考虑这样一种情况:刚刚从内存中换出到磁盘的页面马上又要被重新换入到内存中,刚刚从磁盘中换入到内存的页面马上就要被换出来。这种频繁的页面调度行为称为抖动。这是页面置换过程中一种最糟糕的情形。
所以,一个好的页面置换算法应有较低的页面更换频率,也就是说,应将『以后不会再访问或者以后较长时间内不会再访问的页面』先调出。
常见的置换算法有以下五种:
- 最佳(Optimal, OPT)页面置换算法
- 先进先出(First-In First-Out, FIFO)页面置换算法
- 最近最久未使用(Least Recently Used, LRU)页面置换算法
- 时钟(CLOCK)页面置换算法
- 最少使用(Least Frequently Used, LFU)页面置换算法
最佳(Optimal, OPT)页面置换算法
最佳置换算法所选择的被淘汰页面将是以后永不使用的,或者是在最长时间内不再被访问的页面,这样可以保证获得最低的缺页率。
假定系统为某进程分配了三个物理块,并假设先后访问了以下这些页面号:
7, 0, 1, 2, 0, 3, 0, 4, 2, 3, 0, 3, 2, 1, 2, 0, 1, 7, 0, 1
1)进程运行时,先将 7, 0, 1 三个页面依次装入内存(下图中的**『缺页』表示内存中没有该页面,需要从磁盘中调入**)

2)进程要访问页面 2 时,页面 2 不在内存中,需要从磁盘中装入内存,但是此时内存不够了,于是产生缺页中断。根据最佳置换算法,选择第 18 次访问才需调入的页面 7 予以淘汰(最长时间内不再被访问的页面)

3)然后,访问页面 0 时,因为已在内存中所以不必产生缺页中断。访问页面 3 时又会根据最佳置换算法将页面 1 淘汰
4)......
依此类推,釆用最佳置换算法时的情况如下图所示,可以看到,发生缺页中断的次数为 9,页面置换的次数为 6(图中 【】 标识的即为发生了页面置换)

这个算法的问题就是,谁能提前预知进程在内存下的若千页面中哪个是未来最长时间内不再被访问的?我自己都不知道我接下来会干什么你一个程序都能知道了?
所以这算法目前也就是说说而已,一个理想情况,当前无法实现。现阶段呢咱们可以用最佳置换算法的结果来评价其他算法。
先进先出(First-In First-Out, FIFO)页面置换算法
优先淘汰最早进入内存的页面,亦即在内存中驻留时间最久的页面。
该算法实现简单,只需把调入内存的页面根据先后次序链接成队列,设置一个指针总指向最早的页面。但该算法与进程实际运行时的规律不适应,因为在进程中,有的页面经常被访问。
还是上面的例子:
- 进程访问页面 2 时,把最早进入内存的页面 7 换出
- 然后访问页面 3 时,再把 2, 0, 1 中最先进入内存的页 0 换出
- .......
利用 FIFO 置换算法时的置换图如下,可以看出,利用 FIFO 算法时进行了 12 次页面置换,比最佳置换算法正好多一倍。

FIFO 算法还会产生当所分配的物理块数增大而缺页次数不减反增的异常现象,这是由 Belady 于 1969 年发现,故称为 Belady 异常,如下图所示:
页面访问顺序为 1、2、3、4、1、2、5、1、2、3、4、5。当分配的物理块为 3 个时,缺页次数为 9 次;而当分配的物理块增加为 4 个时,缺页次数反而增加到了 10 次

最近最久未使用(Least Recently Used, LRU)页面置换算法
选择最近最长时间未访问过的页面予以淘汰,它认为过去一段时间内未访问过的页面,在最近的将来可能也不会被访问。
和 OPT 算法相比,LRU 算法根据各页以前的情况,是 “向前看” 的,而 OOT 算法则根据各页以后的使用情况,是 “向后看” 的。
对上面的实例釆用 LRU 算法进行页面置换,如下图所示:
- 进程第一次对页面 2 访问时,内存已满,包含 7、0、1 三个页面,将最近最久未被访问的页面 7 置换出去
- 然后访问页面 3 时,内存已满,包含 2、0、1 三个页面,将最近最久未使用的页面 1 换出
- ......

OPT 算法向前看是无法实现了,那 LRU 这个向后看的算法具体该怎么实现呢?换句话说,这个过去一段时间内最久未被访问过的页面,操作系统是如何找出来的呢?
此处参考百度百科:https://baike.baidu.com/item/LRU
LRU 的具体实现需要有两类硬件之一的支持:寄存器或栈,这两种硬件也就对应着两种不同的方法:
方法一(使用寄存器):
为了记录某进程在内存中各页的使用情况,须为每个在内存中的页面配置一个移位寄存器,可表示为
![]()
当进程访问某物理块时,要将相应寄存器的 Rn−1 位置成 1,随后,定时信号将每隔一定时间 (例如 100 ms) 将寄存器右移一位。
举个例子,假设内存中有 8 个物理块,能够装 8 个页面,假设这 8 个内存页面的序号分别定为 1~8,操作系统需要为每个内存页面配置一个 8 位寄存器 ![]() ,初始化为
,初始化为 0000 0000
- 假设某个进程访问了页面 2,那么就把 Rn−1 即 R1 寄存器的值设置为 1,得到
0000 0010 - 随后一段时间内,如果页面 2 没被访问,那么定时信号会将寄存器右移一位
0000 0001 - 如果随后页面 2 又被访问了,那么寄存器的值就会由
0000 0001变成0000 0011
所以如果某个页面最近一段时间一直不再被访问,那么这个页面对应的寄存器的值就会越来越小,具有最小数值的寄存器所对应的页面,就是最近最久未使用的页面。
看下面这张图,第 3 个内存页面的 R 值 0000 0100 最小,当发生缺页时,首先将它置换出去。

方法二(使用栈):
还可以利用一个特殊的栈来保存当前使用的各个页面的页面号。每当进程访问某页面时,便将该页面的页面号从栈中移出,将它压入栈顶。因此,栈顶始终是最新被访问页面的编号,而栈底则是最近最久未使用页面的页面号。假定现有一进程所访问的页面的页面号序列为:
4,7,0,7,1,0,1,2,1,2,6
随着进程的访问, 栈中页面号的变化情况如下图所示。 在访问页面 6 时发生了缺页,此时页面 4 是最近最久未被访问的页,应将它置换出去
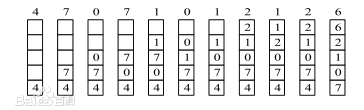
总结下,LRU 性能较好,但实现起来较为困难,需要寄存器和栈的硬件支持 ,属于堆栈类的算法,开销较大
时钟(CLOCK)置换算法
对比下上面 3 种页面置换算法:OPT、FIFO 和 LRU
- OPT 算法性能(效果)最好,但无法实现
- FIFO 算法实现简单,但性能差
- LRU 算法的性能接近于 OPT,但是实现起来比较困难,且开销大
所以操作系统的设计者尝试了很多算法,试图用比较小的开销接近 LRU 的性能,这类算法都是 CLOCK 算法的变体
简单的 CLOCK 算法
回顾下请求分页管理的页表:
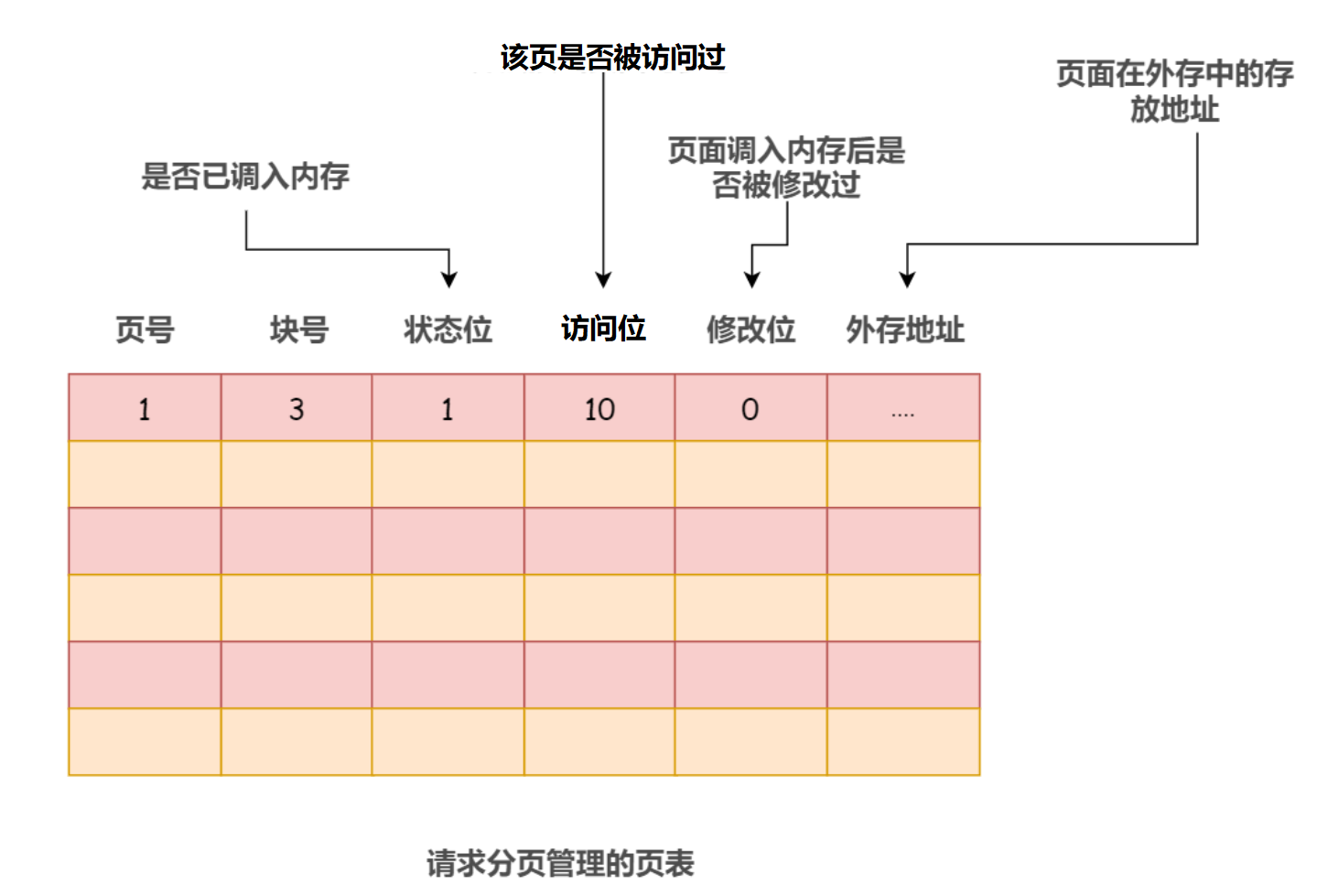
其中:
- 状态位:该页面是否已调入内存(0 表示不在内存中,访问该页面会引起缺页中断;1 表示已在内存中)
- 访问位(也称为参考位/引用位,referenced bit,简写 R):该页面是否被访问过(0 表示被访问过;1 表示未被访问过),不论是读还是写,操作系统都会在该页面被访问时将其访问位设为 1
- 修改位(modified bit,简写 M):该页面调入内存后是否被修改过(0 表示未被修改过;1 表示已经被修改过,被修改过的页面必须被写回磁盘)
- 外存地址:该页面在外存中的存放地址(通常是物理块号,供调入该页时使用)
简单的 CLOCK 算法就和这个『访问位』息息相关,也有书中称之为『使用位』(use bit)
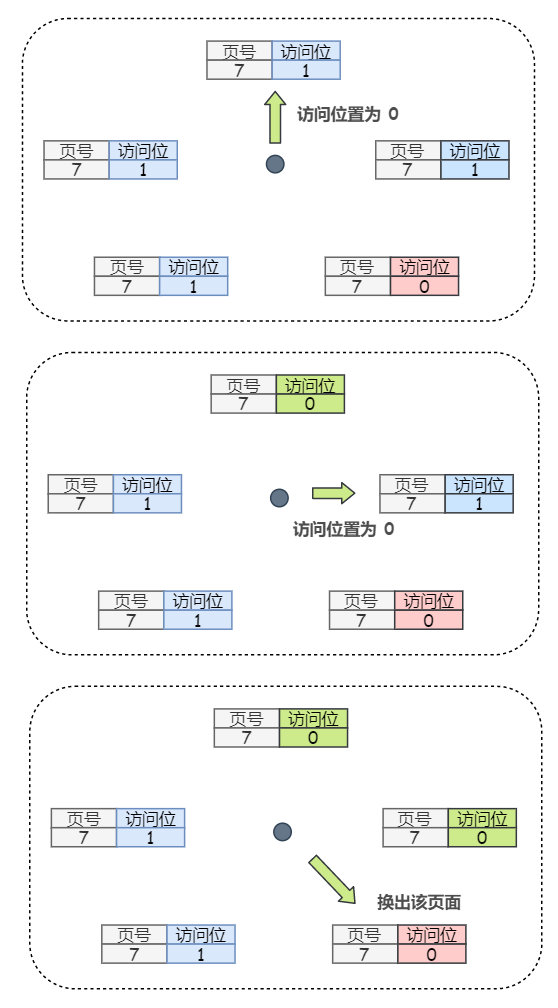
所谓简单的 CLOCK 算法到底有多简单,其实就是尽可能地淘汰掉未被访问过的页面,如下。
将内存中的页面都链接成一个『循环队列』:
1)当某页被访问时,其访问位置为 1
2)当需要从内存中换出一个页面时,只需遍历这个循环队列,依次检查页的访问位:
- 如果是 0,就选择该页换出
- 如果是 1,则将它置为 0,暂不换出,继续检查下一个页面
由于该算法循环地遍历检查各页面的情况,所以就形象地被称为 CLOCK 算法
另外,
- 如果在遍历过程开始时,缓冲区中所有页面的访问位均为 0,则选择遇到的第一个页面替换
- 如果所有页面的访问位均为 1,则指针会在循环队列中完整地循环一周,把所有使用位都置为 0,并且停留在最初的位置上,替换该页面
改进型的 CLOCK 算法
上述只使用了『访问位』的简单的 CLOCK 算法的性能比较接近 LRU,我们还可以进一步地通过『修改位』使得 CLOCK 算法更加高效。
这样,每一个页面都处于以下四种情况之一:
第 0 类:未被访问,未被修改 (Referenced bit = 0,Modified bit = 0)(最佳替换页面)
第 1 类:未被访问,被修改 (Referenced bit = 0,Modified bit = 1)(第二考虑的替换页面)
第 2 类:被访问,未被修改 (Referenced bit = 1,Modified bit = 0)(该页面可能再次被访问)
第 3 类:被访问,被修改 (Referenced bit = 1,Modified bit = 1)(该页面很有可能再次被访问)
其实
可能有小伙伴会困惑怎么会有第 1 类 “未被访问,被修改 (Referenced bit = 0,Modified bit = 1)” 这种情况,其实是这样的,一个第 3 类 “被访问,被修改 (Referenced bit = 1,Modified bit = 1)” 的页面在它的 Referenced bit 位被时钟中断清零后就成了第 1 类。时钟中断不会清除 Modified bit,因为一个被修改过的页面是需要被写回磁盘的,这就需要 Modified bit 这个信息。
改进型的 CLOCK 算法步骤如下:
1)从指针的当前位置开始,扫描循环队列。在这次扫描过程中,对访问位不做任何修改。选择遇到的第一个是第 0 类 “未被访问,未被修改 (Referenced bit = 0,Modified bit = 0)” 的页面用于替换
2)如果第 1) 步失败,则重新扫描,查找第一个是第 1 类 “未被访问,被修改 (Referenced bit = 0,Modified bit = 1)” 的页面用于替换。在这次扫描过程中,对每个跳过的页面,和简单的 CLOCK 算法一样,把它的访问位设置成 0
3)如果第 2) 步失败,指针将回到它的最初位置,并且集合中所有页面的访问位都已经被设置为 0 了。重复第 1 步,并且如果有必要,重复第 2 步。这样一定可以找到供替换的页面。
流程图如下:
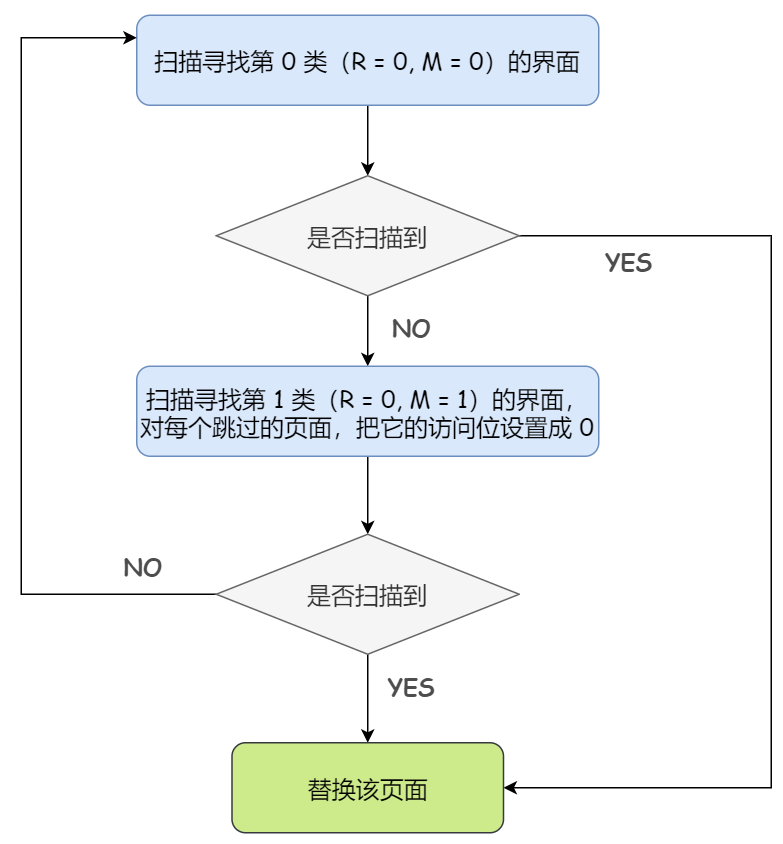
总结起来也很简单,简单 CLOCK 算法不就是尽可能地淘汰掉未被访问过的页面嘛,那改进的 CLOCK 算法就是在此基础上,对未被访问过的页面进一步细分,修改过和未被修改过,优先替换『未被修改过的页面』。因为修改过的页在被替换之前必须写回,因而这样做会节省时间。
最少使用(Least Frequently Used, LFU)页面置换算法
LFU 核心思想就是对每个页面设置一个访问计数器,每当一个页面被访问时,该页面的访问计数器就累加 1。在发生缺页中断时,淘汰计数器值最小的那个页面。
看起来很简单,但是操作系统为此需要为每个页面设定一个『计数寄存器』,显然成本是非常高的。
另外还有个问题,就是有些页在开始时使用次数很多,但最近一段时间就没有使用过了,这类页面由于计数较大,会长时间留在内存中。而当前频繁访问的页面由于没有这些页面总共访问的次数高,在发生缺页中断时,就可能会被淘汰掉
因此可以参考 LRU 的做法,定时将引用计数寄存器右移一位,形成指数衰减的平均使用次数,也就说,随着时间的增加,以前的高访问次数的页面的计数寄存器对应的值会慢慢减少,相当于加大了被淘汰的概率
作者:飞天小牛肉
链接:https://leetcode.cn/circle/discuss/Tt24Uk/