package sql
import org.apache.avro.ipc.specific.Person
import org.apache.spark
import org.apache.spark.rdd.RDD
import org.apache.spark.sql
import org.apache.spark.sql.catalyst.InternalRow
import org.apache.spark.sql.{
DataFrame,Dataset,Row,SparkSession}
import org.junit.TestclassIntro{
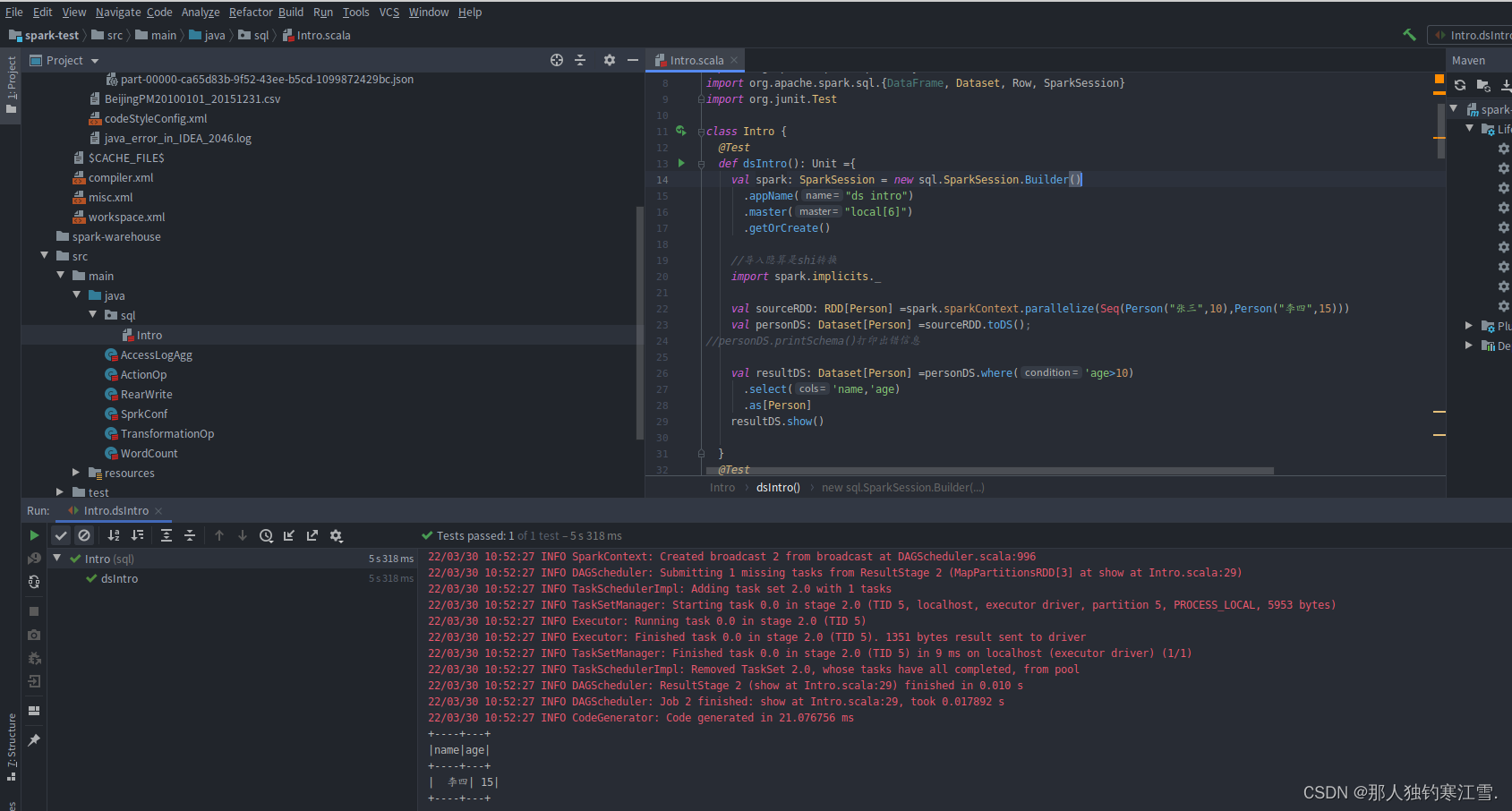
@TestdefdsIntro():Unit={
val spark:SparkSession=new sql.SparkSession.Builder().appName("ds intro").master("local[6]").getOrCreate()//导入隐算是shi转换
import spark.implicits._
val sourceRDD:RDD[Person]=spark.sparkContext.parallelize(Seq(Person("张三",10),Person("李四",15)))
val personDS:Dataset[Person]=sourceRDD.toDS();//personDS.printSchema()打印出错信息
val resultDS:Dataset[Person]=personDS.where('age>10).select('name,'age).as[Person]
resultDS.show()}@TestdefdfIntro():Unit={
val spark:SparkSession=newSparkSession.Builder().appName("ds intro").master("local").getOrCreate()
import spark.implicits._
val sourceRDD:RDD[Person]= spark.sparkContext.parallelize(Seq(Person("张三",10),Person("李四",15)))
val df:DataFrame= sourceRDD.toDF()//隐shi转换
df.createOrReplaceTempView("person")//创建表
val resultDF:DataFrame=spark.sql("select name from person where age>=10 and age<=20")
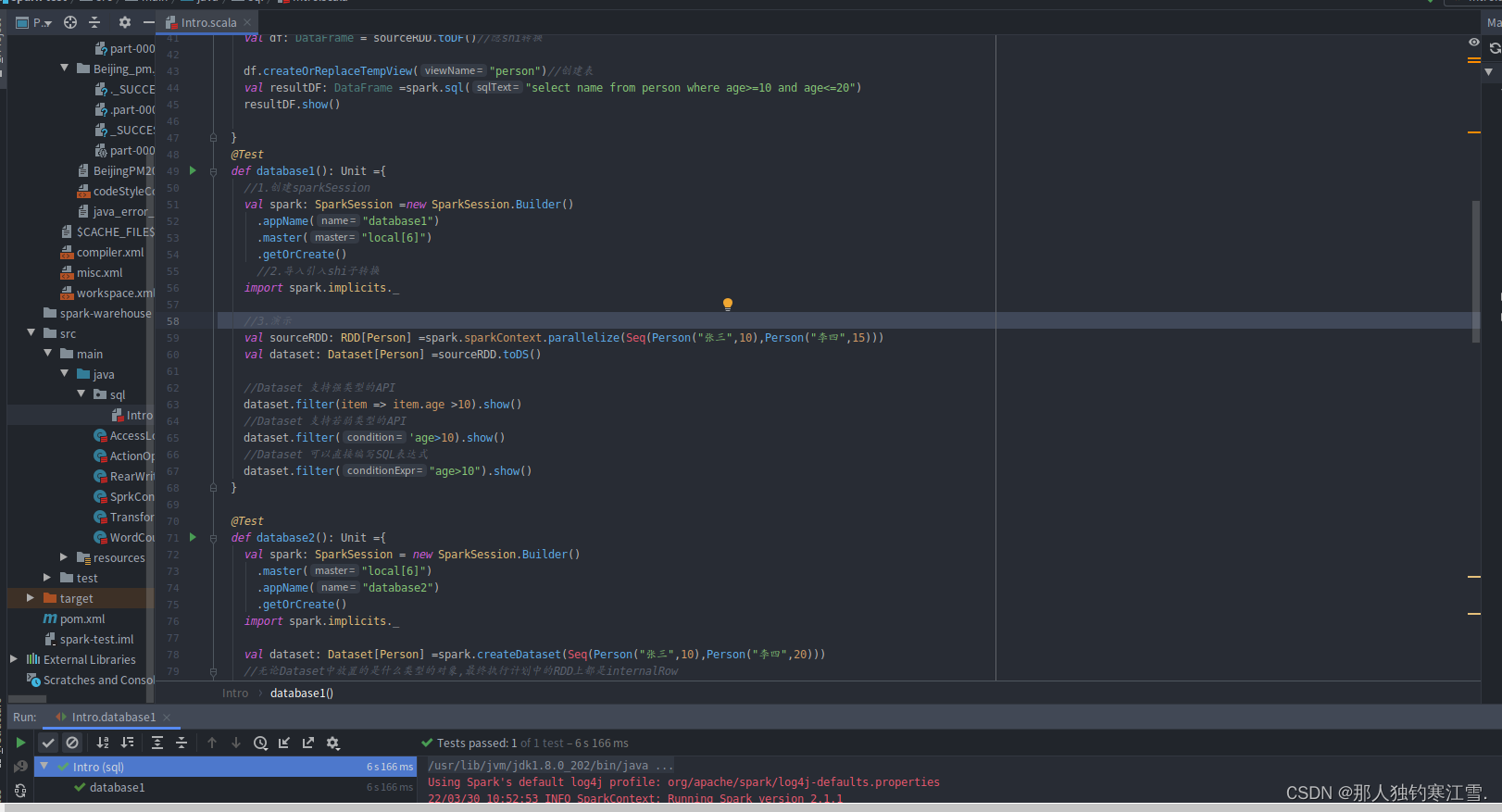
resultDF.show()}@Testdefdatabase1():Unit={
//1.创建sparkSession
val spark:SparkSession=newSparkSession.Builder().appName("database1").master("local[6]").getOrCreate()//2.导入引入shi子转换
import spark.implicits._
//3.演示
val sourceRDD:RDD[Person]=spark.sparkContext.parallelize(Seq(Person("张三",10),Person("李四",15)))
val dataset:Dataset[Person]=sourceRDD.toDS()//Dataset 支持强类型的API
dataset.filter(item => item.age >10).show()//Dataset 支持若弱类型的API
dataset.filter('age>10).show()//Dataset 可以直接编写SQL表达式
dataset.filter("age>10").show()}@Testdefdatabase2():Unit={
val spark:SparkSession=newSparkSession.Builder().master("local[6]").appName("database2").getOrCreate()
import spark.implicits._
val dataset:Dataset[Person]=spark.createDataset(Seq(Person("张三",10),Person("李四",20)))//无论Dataset中放置的是什么类型的对象,最终执行计划中的RDD上都是internalRow
//直接获取到已经分析和解析过得Dataset的执行计划,从中拿到RDD
val executionRdd:RDD[InternalRow]=dataset.queryExecution.toRdd
//通过将Dataset底层的RDD通过Decoder转成了和Dataset一样的类型RDD
val typedRdd:RDD[Person]= dataset.rdd
println(executionRdd.toDebugString)
println()
println()
println(typedRdd.toDebugString)}@Testdefdatabase3():Unit={
//1.创建sparkSession
val spark:SparkSession=newSparkSession.Builder().appName("database1").master("local[6]").getOrCreate()//2.导入引入shi子转换
import spark.implicits._
val dataFrame:DataFrame=Seq(Person("zhangsan",15),Person("lisi",20)).toDF()//3.看看DataFrame可以玩出什么花样
//select name from...
dataFrame.where('age >10).select('name).show()}//@Test//defdatabase4():Unit={
////1.创建sparkSession
// val spark:SparkSession=newSparkSession.Builder()//.appName("database1")//.master("local[6]")//.getOrCreate()////2.导入引入shi子转换
// import spark.implicits._
// val personList=Seq(Person("zhangsan",15),Person("lisi",20))//////1.toDF
// val df1:DataFrame=personList.toDF()// val df2:DataFrame=spark.sparkContext.parallelize(personList).toDF()////2.createDataFrame
// val df3:DataFrame=spark.createDataFrame(personList)//////3.read
// val df4:DataFrame=spark.read.csv("")// df4.show()//}//toDF()是转成DataFrame,toDs是转成Dataset//DataFrame就是Dataset[Row] 代表弱类型的操作,Dataset代表强类型的操作,中的类型永远是row,DataFrame可以做到运行时类型安全,Dataset可以做到 编译时和运行时都安全
@Testdefdatabase4():Unit={
//1.创建sparkSession
val spark:SparkSession=newSparkSession.Builder().appName("database1").master("local[6]").getOrCreate()//2.导入引入shi子转换
import spark.implicits._
val personList=Seq(Person("zhangsan",15),Person("lisi",20))//DataFrame代表弱类型操作是编译时不安全
val df:DataFrame=personList.toDF()//Dataset是强类型的
val ds:Dataset[Person]=personList.toDS()
ds.map((person:Person)=>Person(person.name,person.age))}@Testdefrow():Unit={
//1.Row如何创建,它是什么
//row对象必须配合Schema对象才会有列名
val p:Person=Person("zhangsan",15)
val row:Row=Row("zhangsan",15)//2.如何从row中获取数据
row.getString(0)
row.getInt(1)//3.Row也是样例类、
row match {
caseRow(name,age)=> println(name,age)}}}caseclassPerson(name:String, age:Int)