最近在写问卷星自动化刷份数的代码,查看其详细数据,发现可以查看其来源IP,短时间内频繁用用同一IP刷问卷后,会跳出滑动验证码,无论是否通过该验证码,都不会增加份数。

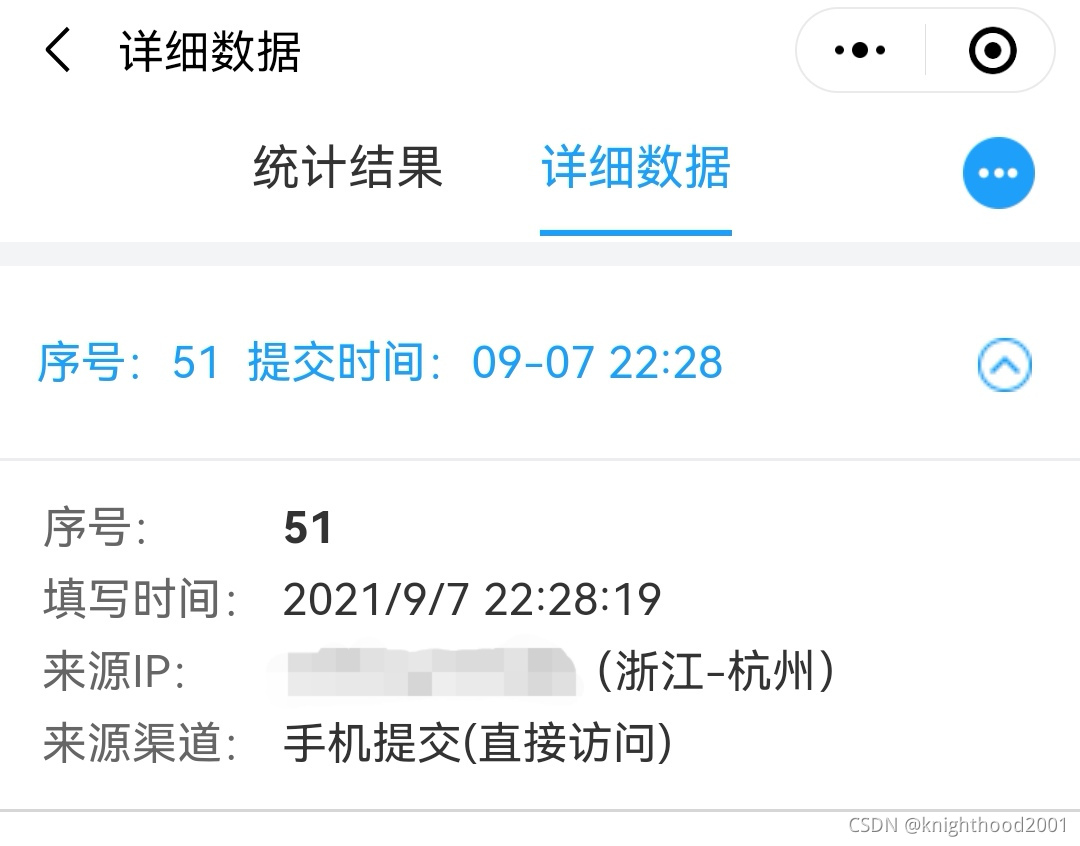
因此是否可以爬取几个免费代理IP,通过它们去刷问卷。
说干就干!!
目录
注意:本篇文章主要讲建立IP代理池,lxml的xpath解析中的问题是一个插曲,大家平时注意一下即可。
一、大致思路
对于获取IP免费的方法,可以利用网络爬虫爬取代理IP网站,获取一系列的免费代理IP地址,由于不清楚这些免费代理IP地址是否可用,也不清楚其响应时间的长短,所以需要对其进行分别校验,从中选取出响应时间较快的IP地址,存入到本地数据文件。
二、建立IP代理池
1、爬取代理IP
Ⅰ url规律寻找
首先查找了一下网上免费IP的网址,我选择的是66免费代理IP(没有具体要求),下面为网址和图片
http://www.66ip.cn/areaindex_1/1.html
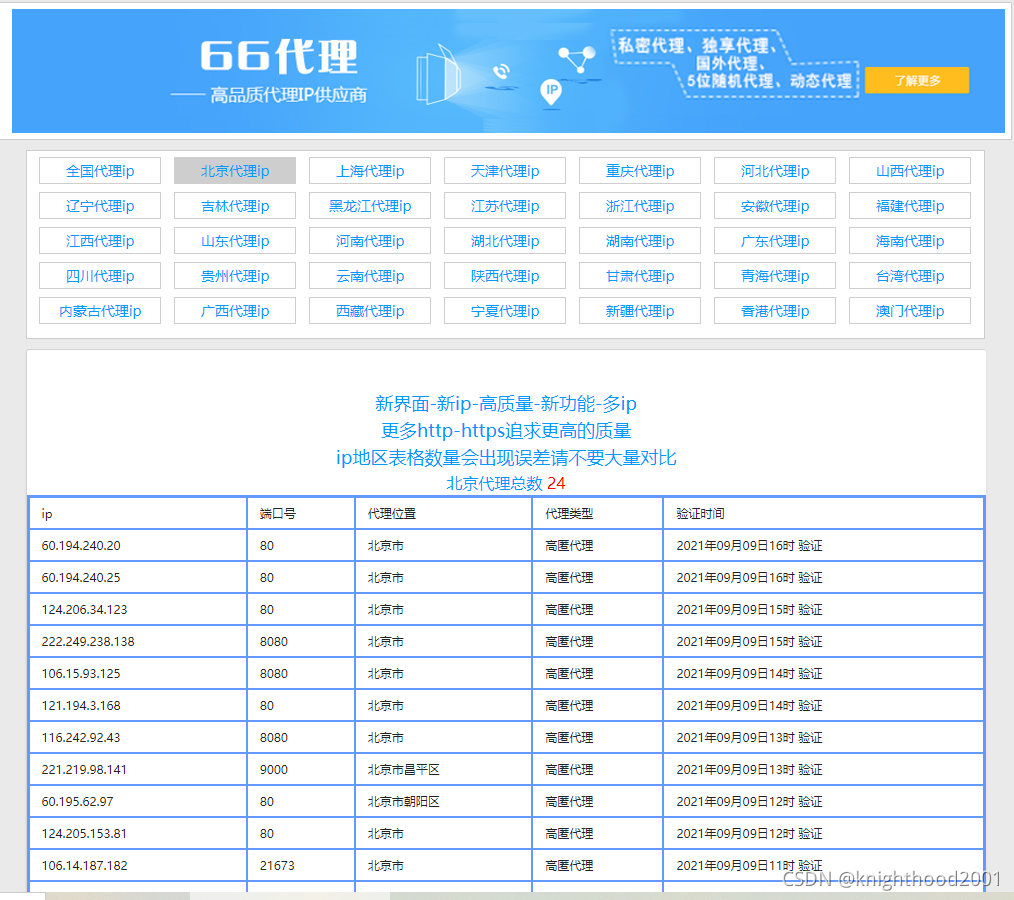
分析其网址,除了全国代理IP,其他的网址为如下形式,因此知道了url的规律。
![]()

Ⅱ lxml的xpath解析

如上图,我们需要获得的数据是ip和端口号,由于第一个tr标签为表格的标题栏,不是我们想要获取的数据,所以我们需要从第二行开始获取数据。
ips = html.xpath('//*[@id="footer"]/div/table/tbody/tr')[1:]
ips = html.xpath('//*[@id="footer"]/div/table/tr')[1:] 分析上面的xpath,第一个为浏览器中copy的xpath,其包含tbody。
首先解释一下tbody,tbody是在table中使用的,用来指明由它包括的各表格行做为表格的主体部分。它与thead(头部)和tfoot(脚注部分)在表格中形成三个“块”。
第一个xpath在浏览器中可以使用,但是用到lxml中,会导致返回的内容是一个空列表,因此需要将tbody/删除,如第二个xpath写法。
这也是标题所说的lxml的xpath解析的问题,需要注意一下!!
接下来就相对简单了,只要获取ip和端口,将他们拼接起来保存为.txt格式即可。
Ⅲ 代码展示
# 爬取代理ip.py
import requests
from lxml import etree
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
ip_list = []
url_list = []
for i in range(1, 35):
url = 'http://www.66ip.cn/areaindex_{}/1.html'.format(i)
response = requests.get(url, headers=headers)
response.encoding = 'gbk'
# print(response.text)
if response.status_code == 200:
html = etree.HTML(response.text)
# //*[@id="footer"]/div/table/tbody/tr
# ips = html.xpath('//*[@id="footer"]/div/table/tbody/tr')[1:]
ips = html.xpath('//*[@id="footer"]/div/table/tr')[1:]
# print(ips)
for ip in ips:
IP1 = ip.xpath('./td[1]/text()')[0]
IP2 = ip.xpath('./td[2]/text()')[0]
IP = IP1 + ':' + IP2
ip_list.append(IP)
print(IP)
with open('ip.txt', 'wb') as f:
f.write(','.join(ip_list).encode('utf-8'))2、验证代理IP
虽然我们将代理ip存到了ip.txt中,但是对于代理ip的可用性和访问速度,我们还不知道,所以需要进行验证。
Ⅰ 思路
这里我们用这些代理IP去访问百度,保留响应时间时间在2秒以内的IP,保存到新的.txt文件中。
Ⅱ 代码展示
# 验证代理ip.py
import requests
ip_list = open('ip.txt', encoding='utf-8').read().split(',')
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
quality_ip = []
# 用百度测试IP是否能正常连网
url = 'https://www.baidu.com'
for ip in ip_list:
response = requests.get(url, proxies={'http': 'http://' + ip}, headers=headers, timeout=2)
if response.text:
quality_ip.append(ip)
print(ip)
else:
continue
with open('quality_ip.txt', 'wb') as f:
f.write(','.join(quality_ip).encode('utf-8'))join()函数
语法: 'sep'.join(seq)
参数说明:
sep:分隔符(可以为空)。
seq:要连接的元素序列、字符串、元组、字典。
含义:以sep作为分隔符,将seq所有的元素合并成一个新的字符串。
3、使用代理IP
Ⅰ 简介
这里使用代理IP的方式是使用随机IP,url是csdn官网https://www.csdn.net/
Ⅱ 代码展示
# 使用代理ip.py
import random
import requests
ip_list = open('quality_ip.txt', encoding='utf-8').read().split(',')
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
# 这里的url为要爬取的相应网址
url = 'https://www.csdn.net/'
r = requests.get(url, proxies={'http': 'http://' + random.choice(ip_list)}, headers=headers)
# r.encoding = 'utf-8'
# print(r.text)
注:在打开文件的代码中要注意编码格式,否则会出现以下这类错误。
三、总结
注意:本篇文章主要讲建立IP代理池,lxml的xpath解析中的问题是一个插曲,大家平时注意一下即可。
说来惭愧,由于笔者不知道如何给selenium设置IP,导致通过不同IP刷问卷一直无法实现!!
如果有人知道这个的,可以滴滴我一下,这将是对我的鼓励,我将特别感谢!