github(新版):https://github.com/Whiffe/mmaction2_YF
码云(新版):https://gitee.com/YFwinston/mmaction2_YF.git
github(老版本):https://github.com/Whiffe/YF-OpenLib-mmaction2
码云(老版本):https://gitee.com/YFwinston/YF-OpenLib-mmaction2.git
mmaction2 官网:https://github.com/open-mmlab/mmaction2
平台:极链AI
b站:https://www.bilibili.com/video/BV1tb4y1b7cy#reply5831466042
之前的mmaction2项目:【mmaction2 slowfast 行为分析(商用级别)】总目录
本系列的链接
00【mmaction2 行为识别商用级别】快速搭建mmaction2 pytorch 1.6.0与 pytorch 1.8.0 版本
03【mmaction2 行为识别商用级别】使用mmaction搭建faster rcnn批量检测图片输出为via格式
04【mmaction2 行为识别商用级别】slowfast检测算法使用yolov3来检测人
08【mmaction2 行为识别商用级别】自定义ava数据集 之 将视频裁剪为帧
12【mmaction2 行为识别商用级别】X3D复现 demo实现 检测自己的视频 Expanding Architecturesfor Efficient Video Recognition
目录
前言
mmaction中采用slowfast检测人的行为,使用的是faster rcnn,这里我们也可以使用yolov3
一,在平台上搭建环境
环境:pytorch1.8.0,CUDA:11.11.1,python:3.8
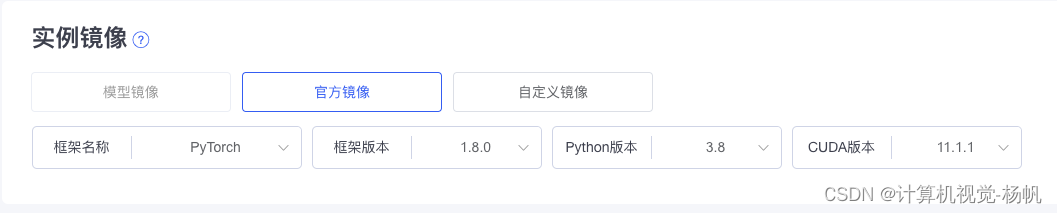
1.1 项目下载
cd home
git clone https://gitee.com/YFwinston/mmaction2_YF.git
1.2 环境搭建+权重下载
复制下面的内容到终端运行
pip install mmcv-full==1.3.8 -f https://download.openmmlab.com/mmcv/dist/cu111/torch1.8.0/index.html
pip install opencv-python-headless==4.1.2.30
pip install mmpycocotools
pip install moviepy opencv-python terminaltables seaborn decord -i https://pypi.douban.com/simple
pip install colorama
cd mmaction2_YF/
python setup.py develop
wget https://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_2x_coco/faster_rcnn_r50_fpn_2x_coco_bbox_mAP-0.384_20200504_210434-a5d8aa15.pth -P ./Checkpionts/mmdetection/
wget https://download.openmmlab.com/mmaction/recognition/slowfast/slowfast_r50_8x8x1_256e_kinetics400_rgb/slowfast_r50_8x8x1_256e_kinetics400_rgb_20200716-73547d2b.pth -P ./Checkpionts/mmaction/
1.3 测试
python demo/demo_spatiotemporal_det.py --config configs/detection/ava/slowfast_kinetics_pretrained_r50_8x8x1_20e_ava_rgb.py --checkpoint Checkpionts/mmaction/slowfast_r50_8x8x1_256e_kinetics400_rgb_20200716-73547d2b.pth --det-config demo/faster_rcnn_r50_fpn_2x_coco.py --det-checkpoint Checkpionts/mmdetection/faster_rcnn_r50_fpn_2x_coco_bbox_mAP-0.384_20200504_210434-a5d8aa15.pth --video demo/demo.mp4 --out-filename demo/demoOut.mp4 --det-score-thr 0.9 --action-score-thr 0.5 --output-stepsize 4 --output-fps 6
二,yolov3 配置文件
2.1 存在的问题
第一次做的时候,我就有以下3个问题:
1,怎么修改呢?
2,demo中的demo_spatiotemporal_det.py 又是如何调用配置文件的?
3,yolov3的配置文件怎么写出来?
我们先看看官方给的代码中,是如何调用faster rcnn的
在:mmaction2_YF/blob/main/demo/demo_spatiotemporal_det.py中
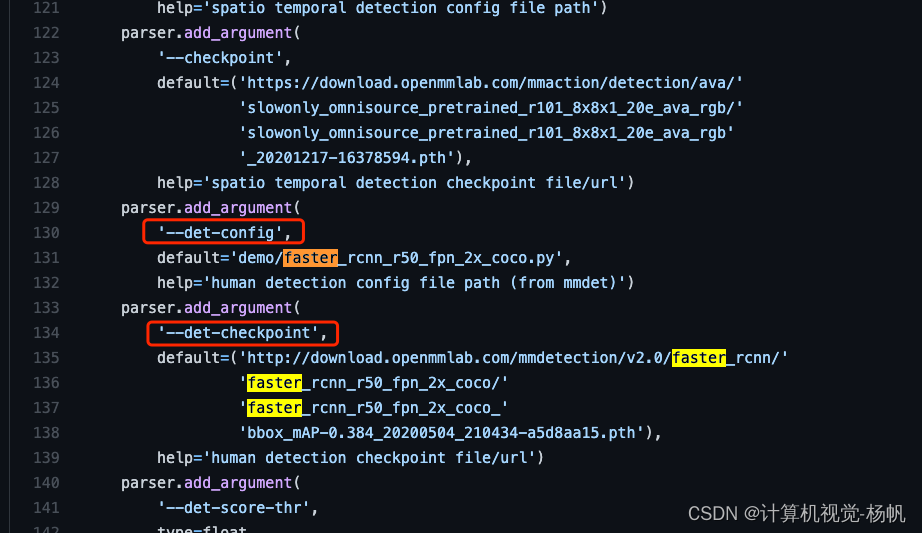
这个地方有两个东西,一个是 --det-config,另一个是 --det-checkpoint,分别夹在加载配置文件,和权重文件。
那我们要做的就是,找到yolov3相关的配置文件,但demo文件下没有,那么就需要我们自己创建一个,我们就模仿faster rcnn的方式进行创建。
2.2 拼接
首先,进入mmdetection的guthub:
https://github.com/open-mmlab/mmdetection
进入到:mmdetection/configs/yolo/
找到 yolov3_d53_320_273e_coco.py
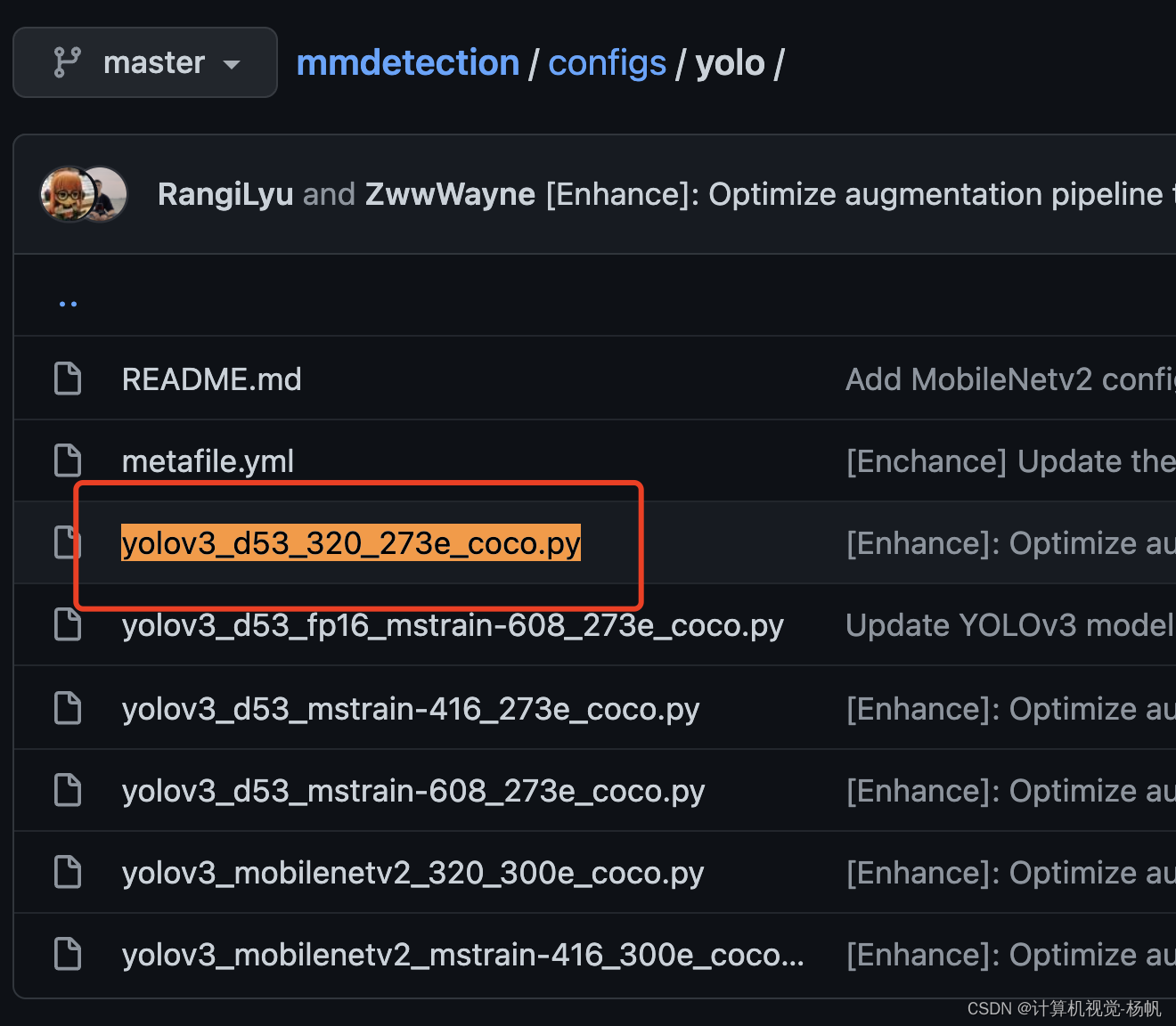
进入后:
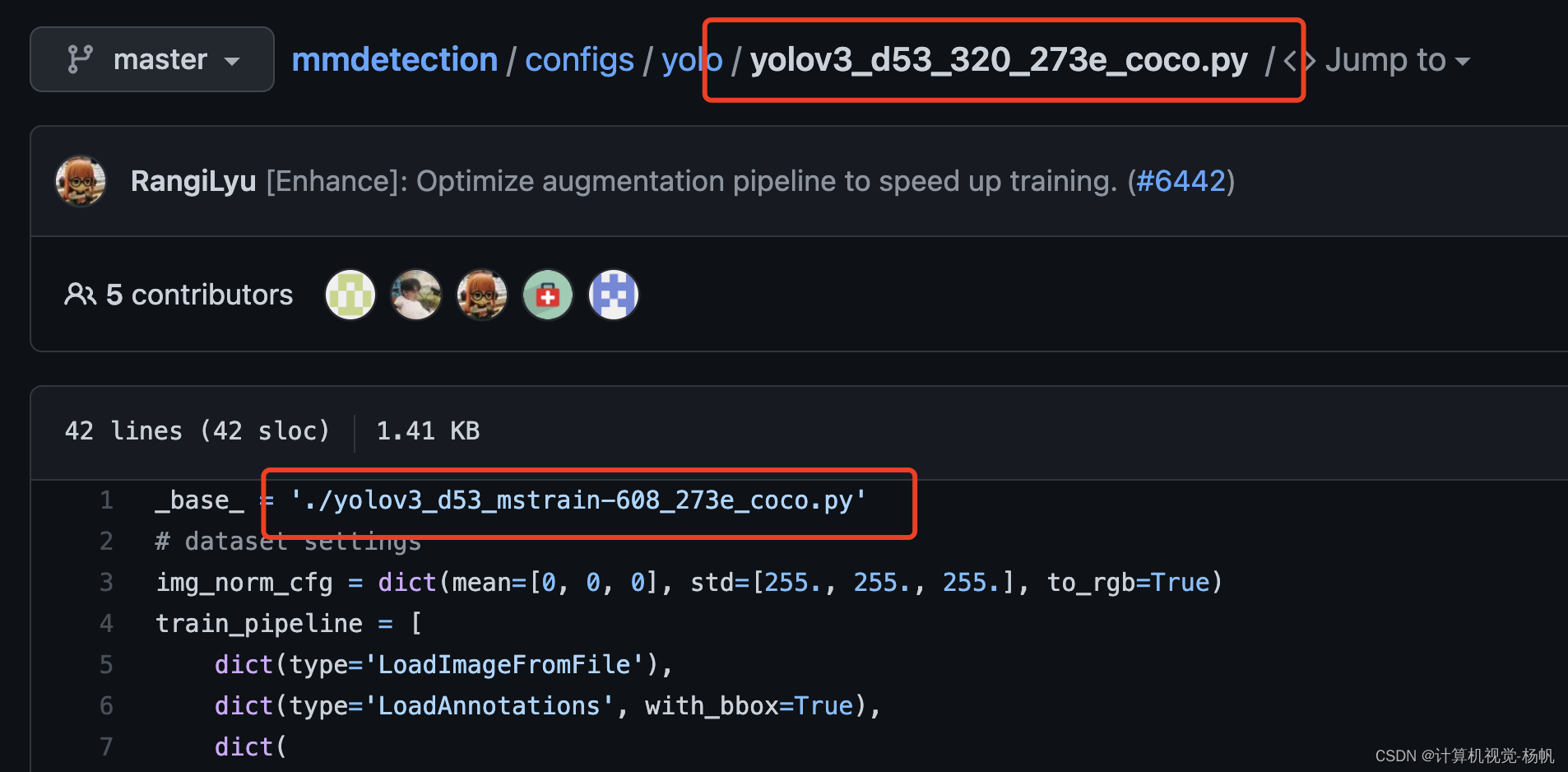
按照第一行的路径找到
mmdetection/configs/yolo/yolov3_d53_mstrain-608_273e_coco.py
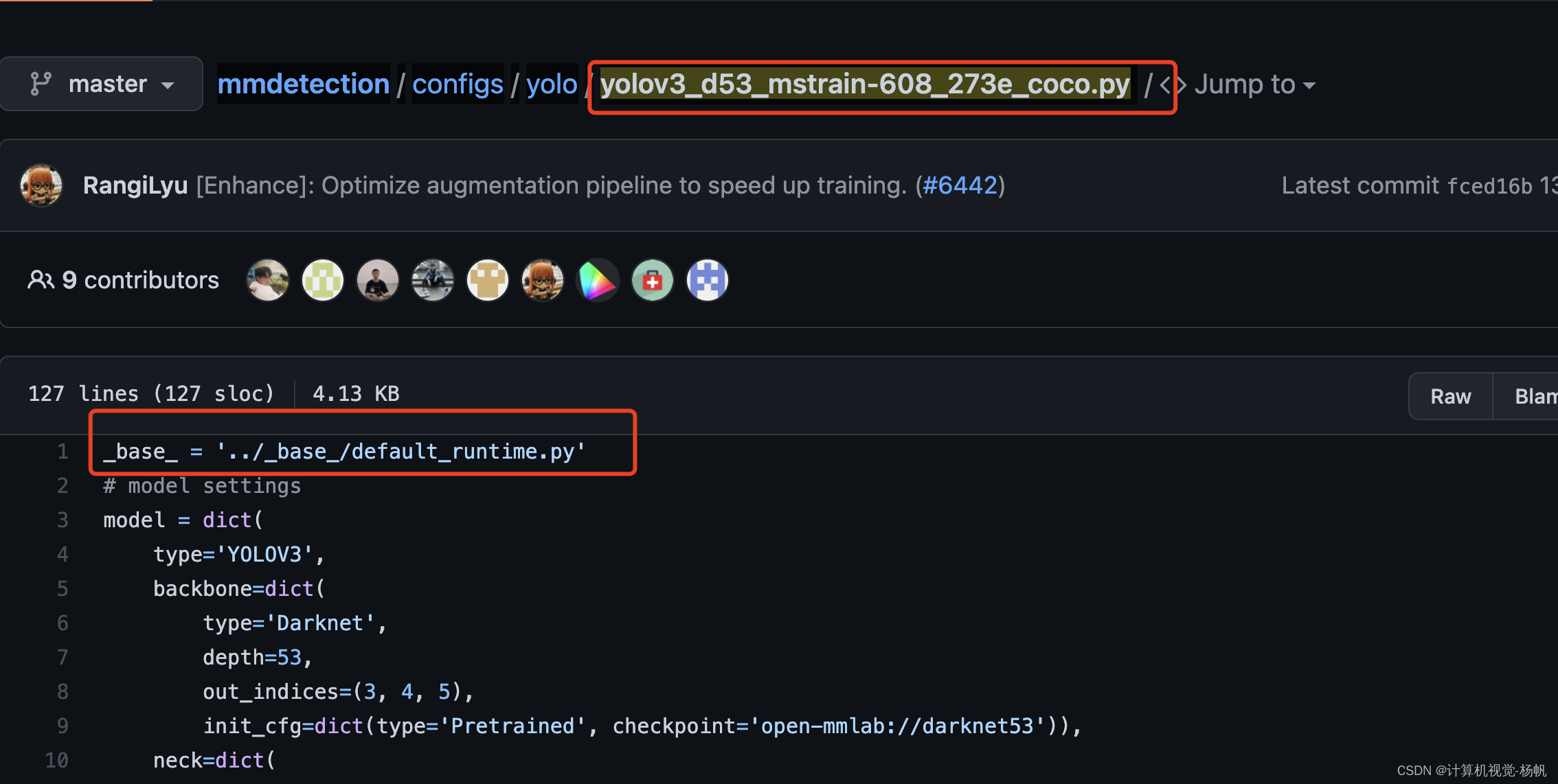
按照第一行的路径找到
http://mmdetection/configs/base/default_runtime.py
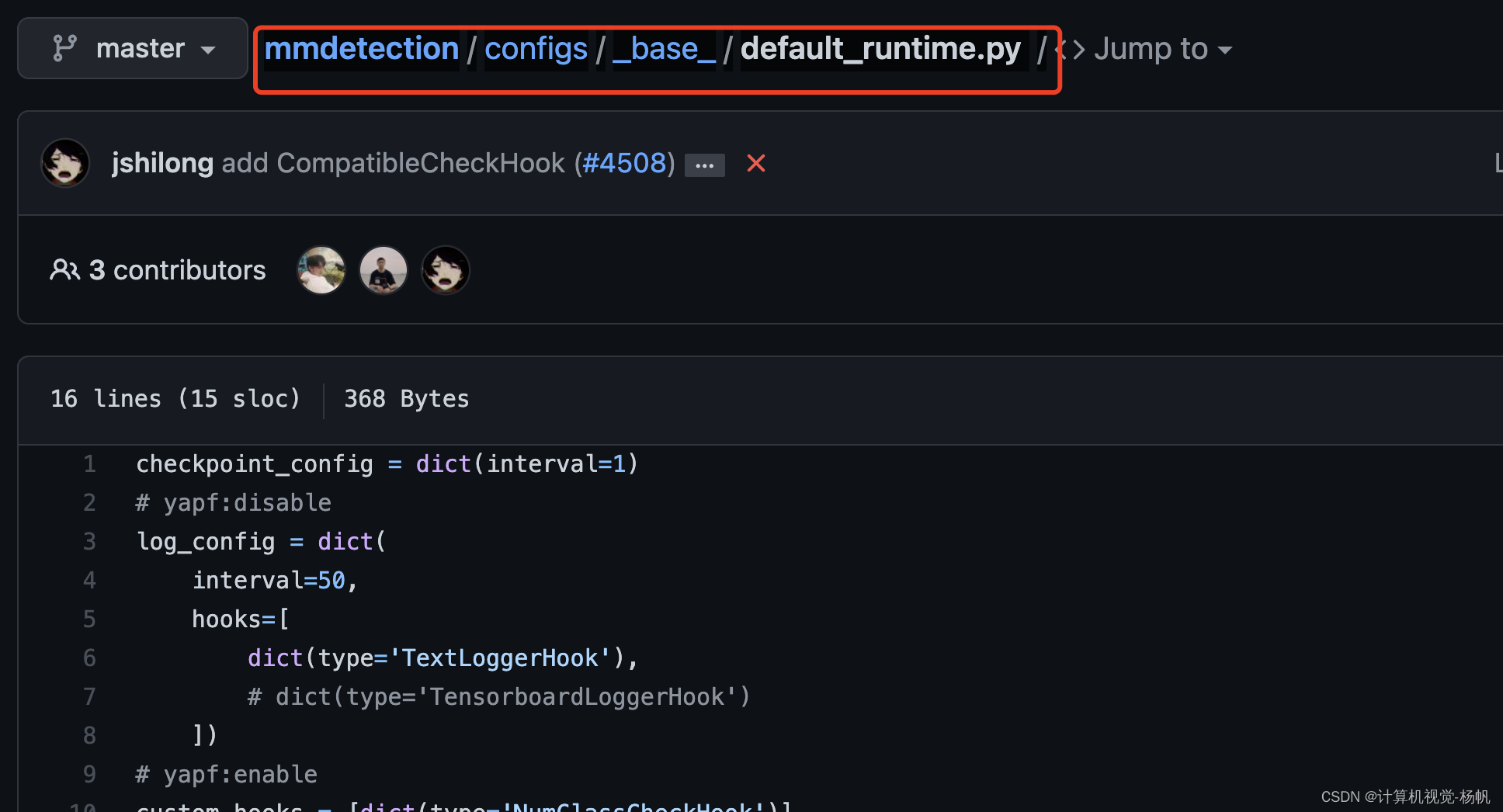
现在将上面的3个文件拼在一起(但是要删除init_cfg这一行,在type='YOLOV3’下加入)
取名为yolov3_d53_320_273e_coco.py
放在mmaction2_YF/demo中
# model settings
model = dict(
type='YOLOV3',
pretrained='open-mmlab://darknet53',
backbone=dict(
type='Darknet',
depth=53,
out_indices=(3, 4, 5)
),
neck=dict(
type='YOLOV3Neck',
num_scales=3,
in_channels=[1024, 512, 256],
out_channels=[512, 256, 128]),
bbox_head=dict(
type='YOLOV3Head',
num_classes=80,
in_channels=[512, 256, 128],
out_channels=[1024, 512, 256],
anchor_generator=dict(
type='YOLOAnchorGenerator',
base_sizes=[[(116, 90), (156, 198), (373, 326)],
[(30, 61), (62, 45), (59, 119)],
[(10, 13), (16, 30), (33, 23)]],
strides=[32, 16, 8]),
bbox_coder=dict(type='YOLOBBoxCoder'),
featmap_strides=[32, 16, 8],
loss_cls=dict(
type='CrossEntropyLoss',
use_sigmoid=True,
loss_weight=1.0,
reduction='sum'),
loss_conf=dict(
type='CrossEntropyLoss',
use_sigmoid=True,
loss_weight=1.0,
reduction='sum'),
loss_xy=dict(
type='CrossEntropyLoss',
use_sigmoid=True,
loss_weight=2.0,
reduction='sum'),
loss_wh=dict(type='MSELoss', loss_weight=2.0, reduction='sum')),
# training and testing settings
train_cfg=dict(
assigner=dict(
type='GridAssigner',
pos_iou_thr=0.5,
neg_iou_thr=0.5,
min_pos_iou=0)),
test_cfg=dict(
nms_pre=1000,
min_bbox_size=0,
score_thr=0.05,
conf_thr=0.005,
nms=dict(type='nms', iou_threshold=0.45),
max_per_img=100))
# dataset settings
dataset_type = 'CocoDataset'
data_root = 'data/coco/'
img_norm_cfg = dict(mean=[0, 0, 0], std=[255., 255., 255.], to_rgb=True)
train_pipeline = [
dict(type='LoadImageFromFile', to_float32=True),
dict(type='LoadAnnotations', with_bbox=True),
dict(
type='Expand',
mean=img_norm_cfg['mean'],
to_rgb=img_norm_cfg['to_rgb'],
ratio_range=(1, 2)),
dict(
type='MinIoURandomCrop',
min_ious=(0.4, 0.5, 0.6, 0.7, 0.8, 0.9),
min_crop_size=0.3),
dict(type='Resize', img_scale=[(320, 320), (608, 608)], keep_ratio=True),
dict(type='RandomFlip', flip_ratio=0.5),
dict(type='PhotoMetricDistortion'),
dict(type='Normalize', **img_norm_cfg),
dict(type='Pad', size_divisor=32),
dict(type='DefaultFormatBundle'),
dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels'])
]
test_pipeline = [
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=(608, 608),
flip=False,
transforms=[
dict(type='Resize', keep_ratio=True),
dict(type='RandomFlip'),
dict(type='Normalize', **img_norm_cfg),
dict(type='Pad', size_divisor=32),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img'])
])
]
data = dict(
samples_per_gpu=8,
workers_per_gpu=4,
train=dict(
type=dataset_type,
ann_file=data_root + 'annotations/instances_train2017.json',
img_prefix=data_root + 'train2017/',
pipeline=train_pipeline),
val=dict(
type=dataset_type,
ann_file=data_root + 'annotations/instances_val2017.json',
img_prefix=data_root + 'val2017/',
pipeline=test_pipeline),
test=dict(
type=dataset_type,
ann_file=data_root + 'annotations/instances_val2017.json',
img_prefix=data_root + 'val2017/',
pipeline=test_pipeline))
# optimizer
optimizer = dict(type='SGD', lr=0.001, momentum=0.9, weight_decay=0.0005)
optimizer_config = dict(grad_clip=dict(max_norm=35, norm_type=2))
# learning policy
lr_config = dict(
policy='step',
warmup='linear',
warmup_iters=2000, # same as burn-in in darknet
warmup_ratio=0.1,
step=[218, 246])
# runtime settings
runner = dict(type='EpochBasedRunner', max_epochs=273)
evaluation = dict(interval=1, metric=['bbox'])
checkpoint_config = dict(interval=1)
# yapf:disable
log_config = dict(
interval=50,
hooks=[
dict(type='TextLoggerHook'),
# dict(type='TensorboardLoggerHook')
])
# yapf:enable
custom_hooks = [dict(type='NumClassCheckHook')]
dist_params = dict(backend='nccl')
log_level = 'INFO'
load_from = None
resume_from = None
workflow = [('train', 1)]
# dataset settings
img_norm_cfg = dict(mean=[0, 0, 0], std=[255., 255., 255.], to_rgb=True)
train_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations', with_bbox=True),
dict(
type='Expand',
mean=img_norm_cfg['mean'],
to_rgb=img_norm_cfg['to_rgb'],
ratio_range=(1, 2)),
dict(
type='MinIoURandomCrop',
min_ious=(0.4, 0.5, 0.6, 0.7, 0.8, 0.9),
min_crop_size=0.3),
dict(type='Resize', img_scale=(320, 320), keep_ratio=True),
dict(type='RandomFlip', flip_ratio=0.5),
dict(type='PhotoMetricDistortion'),
dict(type='Normalize', **img_norm_cfg),
dict(type='Pad', size_divisor=32),
dict(type='DefaultFormatBundle'),
dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels'])
]
test_pipeline = [
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=(320, 320),
flip=False,
transforms=[
dict(type='Resize', keep_ratio=True),
dict(type='RandomFlip'),
dict(type='Normalize', **img_norm_cfg),
dict(type='Pad', size_divisor=32),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img'])
])
]
data = dict(
train=dict(pipeline=train_pipeline),
val=dict(pipeline=test_pipeline),
test=dict(pipeline=test_pipeline))
2.3 下载对应权重
下载权重
wget https://download.openmmlab.com/mmdetection/v2.0/yolo/yolov3_d53_320_273e_coco/yolov3_d53_320_273e_coco-421362b6.pth -P ./Checkpionts/mmdetection/
三,测试
3.1 yolov3测试
python demo/demo_spatiotemporal_det.py --config configs/detection/ava/slowfast_kinetics_pretrained_r50_8x8x1_20e_ava_rgb.py --checkpoint Checkpionts/mmaction/slowfast_r50_8x8x1_256e_kinetics400_rgb_20200716-73547d2b.pth --det-config demo/yolov3_d53_320_273e_coco.py --det-checkpoint Checkpionts/mmdetection/yolov3_d53_320_273e_coco-421362b6.pth --video /user-data/mmactionVideo/video/v2.mp4 --out-filename demo/demoOut2.mp4 --det-score-thr 0.9 --action-score-thr 0.5 --output-stepsize 4 --output-fps 6
注意修改输入视频和输出视频的路径
检测结果:

3.2 faster rcnn测试
python demo/demo_spatiotemporal_det.py --config configs/detection/ava/slowfast_kinetics_pretrained_r50_8x8x1_20e_ava_rgb.py --checkpoint Checkpionts/mmaction/slowfast_r50_8x8x1_256e_kinetics400_rgb_20200716-73547d2b.pth --det-config demo/faster_rcnn_r50_fpn_2x_coco.py --det-checkpoint Checkpionts/mmdetection/faster_rcnn_r50_fpn_2x_coco_bbox_mAP-0.384_20200504_210434-a5d8aa15.pth --video /user-data/mmactionVideo/video/v2.mp4 --out-filename demo/demoOut.mp4 --det-score-thr 0.9 --action-score-thr 0.5 --output-stepsize 4 --output-fps 6

两个视频的对比,我放在了b站上面