文章目录
三部曲
0、能看完这篇却没动手 <-洗洗睡吧
1、能看懂 Go 语言 <- 拿到钥匙了
2、能用 Go 语言写管理系统 <- 趴门墩儿上了
3、能用 Go 语言写 “生产/消费者” 模型 <- 进门了,广阔天地大有可为
咱不玩虚的,这些都行,才算入了门。
搭建环境
喜欢 Windows 呢,还是 Linux 呀?我选 VScode 哈。
1、部署 Go 环境:Go 安装包下载
Windows 的话有操作指引,Linux 的话:
tar -C /usr/local -xzf goXXXXX.tar.gz
export PATH=$PATH:/usr/local/go/bin
source /etc/profile
现在的大环境都比较好,安装个环境都很快,不想我三年前初学的时候,安装个环境就要我小命了。
如果选择 Linux 开发的到这里环境也就可以了,习惯 VScode 的咱再往下安装一步。
2、安装 Go 插件。我想不知道要安装哪个的可以去反思一下自己。
3、设置 go 的代理,然后它会自动把该安装的包给你安装上。
go env -w GOPROXY=https://goproxy.cn,direct
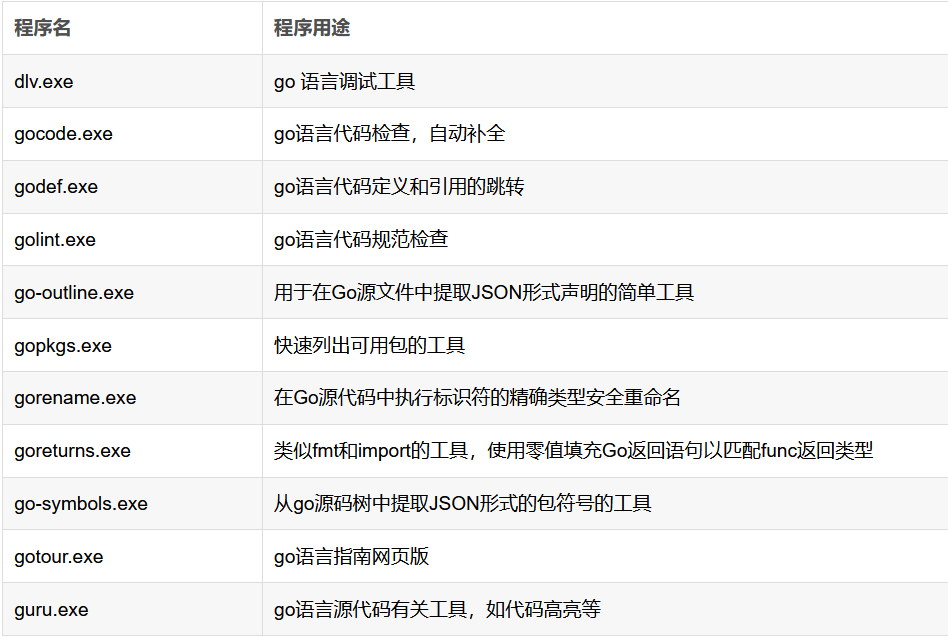
4、那么环境就安装好了,让我们来问候一下世界:
package main
import "fmt"
func main() {
fmt.Println("Hello, World!")
}
运行脚本:
go run hello.go
或者你想编译一下再运行也行:
go build hello.go
./hello
如果报了什么 mod 的错,go mod init 文件夹名
代码简要讲解
简要讲解一下上面的代码,提供一个缓冲的过程。
package main //定义了包名。你必须在源文件中非注释的第一行指明这个文件属于哪个包
//每个 Go 应用程序都包含一个名为 main 的包。
import "fmt" //导入 fmt 包
/*
程序开始执行的函数。main 函数是每一个可执行程序所必须包含的,
一般来说都是在启动后第一个执行的函数(如果有 init() 函数则会先执行该函数)。
*/
func main() {
/* 这是我的第一个简单的程序 */
fmt.Println("Hello, World!") //输出函数
/*
当标识符(包括常量、变量、类型、函数名、结构字段等等)以一个大写字母开头,那么使用这种形式的标识符的对象就可以被外部包的代码所使用
(客户端程序需要先导入这个包),这被称为导出;
标识符如果以小写字母开头,则对包外是不可见的,但是他们在整个包的内部是可见并且可用的。
*/
}
包
每个 Go 程序都是由包构成的。
导入
对于包的导入,可以用圆括号将所有要导入的包写在一起,如:
package main
import (
"fmt"
"math"
)
func main() {
fmt.Printf("Now you have %g problems.\n", math.Sqrt(7))
}
也可以依次单个导入,如:
package main
import "fmt"
import "math"
func main() {
fmt.Printf("Now you have %g problems.\n", math.Sqrt(7))
}
导出名
在 Go 中,如果一个名字以大写字母开头,那么它就是已导出的。例如,Pizza 就是个已导出名,Pi 也同样,它导出自 math 包。
pizza 和 pi 并未以大写字母开头,所以它们是未导出的。
在导入一个包时,你只能引用其中已导出的名字。任何“未导出”的名字在该包外均无法访问。
执行代码,观察错误输出:
package main
import (
"fmt"
"math"
)
func main() {
fmt.Println(math.pi)
}
然后将 math.pi 改名为 math.Pi 再试着执行一次。
标识符
标识符用来命名变量、类型等程序实体。一个标识符实际上就是一个或是多个字母(A~Z和a~z)数字(0~9)、下划线_组成的序列,但是第一个字符必须是字母或下划线而不能是数字。
关键字 和 预定义标识符


这不用去记,按我的方法来起名字(凡是起名必带 _)是不可能和这些关键字冲突的。
基本类型
Go 的基本类型有
bool
string
int int8 int16 int32 int64
uint uint8 uint16 uint32 uint64 uintptr
byte // uint8 的别名
rune // int32 的别名
// 表示一个 Unicode 码点
float32 float64
complex64 complex128
package main
import (
"fmt"
"math/cmplx"
)
var (
ToBe bool = false
MaxInt uint64 = 1<<64 - 1
z complex128 = cmplx.Sqrt(-5 + 12i)
)
func main() {
fmt.Printf("Type: %T Value: %v\n", ToBe, ToBe)
fmt.Printf("Type: %T Value: %v\n", MaxInt, MaxInt)
fmt.Printf("Type: %T Value: %v\n", z, z)
}
本例展示了几种类型的变量。 同导入语句一样,变量声明也可以“分组”成一个语法块。
int, uint 和 uintptr 在 32 位系统上通常为 32 位宽,在 64 位系统上则为 64 位宽。 当你需要一个整数值时应使用 int 类型,除非你有特殊的理由使用固定大小或无符号的整数类型。
变量与常量
变量声明
var 语句用于声明一个变量列表,格式为:
例:
var num int = 10
其中“类型”或“= 表达式”两个部分可以省略其中的一个。
1)根据初始化表达式来推导类型信息
2)默认值初始化为0。
例:
var num int // var num int = 0
var num = 10 // var num int = 10
既然说是列表,那就是可以一次性声明一串儿:
package main
import "fmt"
var c, python, java bool
func main() {
var i int
fmt.Println(i, c, python, java)
}
变量声明可以包含初始值,每个变量对应一个:
package main
import "fmt"
var i,j = 1,2
func main(){
var c,python,java=true,false,"no!"
fmt.Println(i, j, c, python, java)
}
短变量声明
在函数中,简洁赋值语句 := 可在类型明确的地方代替 var 声明。
函数外的每个语句都必须以关键字开始(var, func 等等),因此 := 结构不能在函数外使用。
package main
import "fmt"
func main() {
var i, j int = 1, 2
k := 3
c, python, java := true, false, "no!"
fmt.Println(i, j, k, c, python, java)
}
类型转换
表达式 T(v) 将值 v 转换为类型 T。
一些关于数值的转换:
var i int = 42
var f float64 = float64(i)
var u uint = uint(f)
或者,更加简单的形式:
i := 42
f := float64(i)
u := uint(f)
与 C 不同的是,Go 在不同类型的项之间赋值时需要显式转换。
常量
1、常量的声明与变量类似,只不过是使用 const 关键字。
2、常量可以是字符、字符串、布尔值或数值。
3、常量不能用 := 语法声明。
package main
import "fmt"
const Pi = 3.14
func main() {
const World = "世界"
fmt.Println("Hello", World)
fmt.Println("Happy", Pi, "Day")
const Truth = true
fmt.Println("Go rules?", Truth)
}
流程控制
for 循环
Go 只有一种循环结构:for 循环。
package main
import "fmt"
func main(){
sum := 0;
for i:=0;i<10;i++ {
sum += i
}
fmt.Println(sum)
}
如果没有初始化语句和后置语句的话,可以将那两个分号也不要:
package main
import "fmt"
func main() {
sum := 1
for ; sum < 1000; {
sum += sum
}
fmt.Println(sum)
}
如果连循环条件都省去了,该循环就不会结束,因此无限循环可以写得很紧凑:
package main
func main() {
for {
}
}
break、continue、goto 依旧是有的。
if 分支
Go 的 if 语句与 for 循环类似,表达式外无需小括号 ( ) ,而大括号 { } 则是必须的。
同 for 一样, if 语句可以在条件表达式前执行一个简单的语句。
package main
import (
"fmt"
"math"
)
func pow(x, n, lim float64) float64 {
if v := math.Pow(x, n); v < lim {
return v
}
return lim
}
func main() {
fmt.Println(
pow(3, 2, 10),
pow(3, 3, 20),
)
}
该语句声明的变量作用域仅在 if 之内。(在最后的 return 语句处使用 v 看看。)
在 if 的简短语句中声明的变量同样可以在任何对应的 else 块中使用:
package main
import (
"fmt"
"math"
)
func pow(x, n, lim float64) float64 {
if v := math.Pow(x, n); v < lim {
return v
} else {
fmt.Printf("%g >= %g\n", v, lim)
}
// 这里开始就不能使用 v 了
return lim
}
func main() {
fmt.Println(
pow(3, 2, 10),
pow(3, 3, 20),
)
}
注:注意这里的写法,else 是要和 } 在一行的,不信可以换个行试试。
switch 分支
switch 是编写一连串 if - else 语句的简便方法。它运行第一个值等于条件表达式的 case 语句。
Go 只运行选定的 case,而非之后所有的 case。 实际上,Go 自动提供了在这些语言中每个 case 后面所需的 break 语句。Go 的另一点重要的不同在于 switch 的 case 无需为常量,且取值不必为整数。
package main
import (
"fmt"
"runtime"
)
func main() {
fmt.Print("Go runs on ")
switch os := runtime.GOOS; os {
case "darwin":
fmt.Println("OS X.")
case "linux":
fmt.Println("Linux.")
default:
// freebsd, openbsd,
// plan9, windows...
fmt.Printf("%s.\n", os)
}
}
讲真,我几乎没有用过 Switch。
defer
defer 语句会将函数推迟到外层函数返回之后执行。
推迟调用的函数其参数会立即求值,但直到外层函数返回前该函数都不会被调用。
package main
import "fmt"
func main() {
defer fmt.Println("world")
fmt.Println("hello")
}
推迟的函数调用会被压入一个栈中。当外层函数返回时,被推迟的函数会按照后进先出的顺序调用。
package main
import "fmt"
func main() {
fmt.Println("counting")
for i := 0; i < 10; i++ {
defer fmt.Println(i)
}
fmt.Println("done")
}
高级结构
指针
Go 拥有指针。指针保存了值的内存地址。
类型 *T 是指向 T 类型值的指针。其零值为 nil。
var p *int
& 操作符会生成一个指向其操作数的指针。
i := 42
p = &i
* 操作符表示指针指向的底层值。
fmt.Println(*p) // 通过指针 p 读取 i
*p = 21 // 通过指针 p 设置 i
这也就是通常所说的“间接引用”或“重定向”。
与 C 不同,Go 没有指针运算。
结构体
一个结构体(struct)就是一组字段(field),结构体字段使用点号来访问。
package main
import "fmt"
type Vertex struct {
X int
Y int
}
func main() {
v := Vertex{
1, 2}
v.X = 4
fmt.Println(v.X)
}
数组
类型 [n]T 表示拥有 n 个 T 类型的值的数组。
var a [10]int
会将变量 a 声明为拥有 10 个整数的数组。
数组的长度是其类型的一部分,因此数组不能改变大小。这看起来是个限制,不过没关系,Go 提供了更加便利的方式来使用数组。
package main
import "fmt"
func main() {
var a [2]string
a[0] = "Hello"
a[1] = "World"
fmt.Println(a[0], a[1])
fmt.Println(a)
primes := [6]int{
2, 3, 5, 7, 11, 13}
fmt.Println(primes)
}
如果数组长度不确定,可以使用 … 代替数组的长度,编译器会根据元素个数自行推断数组的长度:
var balance = [...]float32{
1000.0, 2.0, 3.4, 7.0, 50.0}
或
balance := [...]float32{
1000.0, 2.0, 3.4, 7.0, 50.0}
切片
每个数组的大小都是固定的。而切片则为数组元素提供动态大小的、灵活的视角。在实践中,切片比数组更常用。
类型 []T 表示一个元素类型为 T 的切片。
切片通过两个下标来界定,即一个上界和一个下界,二者以冒号分隔:
a[low : high]
它会选择一个半开区间,包括第一个元素,但排除最后一个元素。
以下表达式创建了一个切片,它包含 a 中下标从 1 到 3 的元素:
a[1:4]
切片的底层
1、切片并不存储任何数据,它只是描述了底层数组中的一段。
2、更改切片的元素会修改其底层数组中对应的元素。
3、与它共享底层数组的切片都会观测到这些修改。
(看这个描述,如果有C语言功底,很快就能想到指针实现切片的方法吧)
package main
import "fmt"
func main() {
names := [4]string{
"John",
"Paul",
"George",
"Ringo",
}
fmt.Println(names)
a := names[0:2]
b := names[1:3]
fmt.Println(a, b)
b[0] = "XXX"
fmt.Println(a, b)
fmt.Println(names)
}
切片的默认行为
会 Python 的小伙伴对切片应该不陌生, 在进行切片时,你可以利用它的默认行为来忽略上下界。
切片下界的默认值为 0,上界则是该切片的长度。
对于数组
var a [10]int
来说,以下切片是等价的:
a[0:10]
a[:10]
a[0:]
a[:]
切片的长度与容量
切片拥有 长度 和 容量,切片的长度就是它所包含的元素个数。,切片的容量是从它的第一个元素开始数,到其底层数组元素末尾的个数,切片 s 的长度和容量可通过表达式 len(s) 和 cap(s) 来获取。
(刚刚有思考切片的实现原理的朋友很快也能反应过来吧)
package main
import "fmt"
func main() {
s := []int{
2, 3, 5, 7, 11, 13}
printSlice(s)
// 截取切片使其长度为 0
s = s[:0]
printSlice(s)
// 拓展其长度
s = s[:4]
printSlice(s)
// 舍弃前两个值
s = s[2:]
printSlice(s)
}
func printSlice(s []int) {
fmt.Printf("len=%d cap=%d %v\n", len(s), cap(s), s)
}
我们可以通过将上面的 [:4] 换成 [:40] 再探究一波。
nil 切片
切片的零值是 nil。
nil 切片的长度和容量为 0 且没有底层数组。
用 make 创建切片
切片可以用内建函数 make 来创建,这也是你创建动态数组的方式。
make 函数会分配一个元素为零值的数组并返回一个引用了它的切片:
a := make([]int, 5) // len(a)=5
要指定它的容量,需向 make 传入第三个参数:
b := make([]int, 0, 5) // len(b)=0, cap(b)=5
b = b[:cap(b)] // len(b)=5, cap(b)=5
b = b[1:] // len(b)=4, cap(b)=4
package main
import "fmt"
func main() {
a := make([]int, 5)
printSlice("a", a)
b := make([]int, 0, 5)
printSlice("b", b)
c := b[:2]
printSlice("c", c)
d := c[2:5]
printSlice("d", d)
}
func printSlice(s string, x []int) {
fmt.Printf("%s len=%d cap=%d %v\n",
s, len(x), cap(x), x)
}
切片的切片
切片可包含任何类型,甚至包括其它的切片。
package main
import (
"fmt"
"strings"
)
func main() {
// 创建一个井字板(经典游戏)
board := [][]string{
[]string{
"_", "_", "_"},
[]string{
"_", "_", "_"},
[]string{
"_", "_", "_"},
}
// 两个玩家轮流打上 X 和 O
board[0][0] = "X"
board[2][2] = "O"
board[1][2] = "X"
board[1][0] = "O"
board[0][2] = "X"
for i := 0; i < len(board); i++ {
fmt.Printf("%s\n", strings.Join(board[i], " "))
}
}
向切片追加元素
为切片追加新的元素是种常用的操作,为此 Go 提供了内建的 append 函数。
func append(s []T, vs ...T) []T
append 的第一个参数 s 是一个元素类型为 T 的切片,其余类型为 T 的值将会追加到该切片的末尾。
append 的结果是一个包含原切片所有元素加上新添加元素的切片。
当 s 的底层数组太小,不足以容纳所有给定的值时,它就会分配一个更大的数组。返回的切片会指向这个新分配的数组。
package main
import "fmt"
func main() {
var s []int
printSlice(s)
// 添加一个空切片
s = append(s, 0)
printSlice(s)
// 这个切片会按需增长
s = append(s, 1)
printSlice(s)
// 可以一次性添加多个元素
s = append(s, 2, 3, 4)
printSlice(s)
}
func printSlice(s []int) {
fmt.Printf("len=%d cap=%d %v\n", len(s), cap(s), s)
}
映射
映射将键映射到值。映射的零值为 nil 。nil 映射既没有键,也不能添加键。
make 函数会返回给定类型的映射,并将其初始化备用。
package main
import "fmt"
func main() {
var countryCapitalMap map[string]string /*创建集合 */
countryCapitalMap = make(map[string]string)
/* map插入key - value对,各个国家对应的首都 */
countryCapitalMap [ "France" ] = "巴黎"
countryCapitalMap [ "Italy" ] = "罗马"
countryCapitalMap [ "Japan" ] = "东京"
countryCapitalMap [ "India " ] = "新德里"
/*使用键输出地图值 */
for country := range countryCapitalMap {
fmt.Println(country, "首都是", countryCapitalMap [country])
}
/*查看元素在集合中是否存在 */
capital, ok := countryCapitalMap [ "American" ] /*如果确定是真实的,则存在,否则不存在 */
/*fmt.Println(capital) */
/*fmt.Println(ok) */
if (ok) {
fmt.Println("American 的首都是", capital)
} else {
fmt.Println("American 的首都不存在")
}
}
映射基操
在映射 m 中插入或修改元素:
m[key] = elem
获取元素:
elem = m[key]
删除元素:
delete(m, key)
通过双赋值检测某个键是否存在:
elem, ok = m[key]
若 key 在 m 中,ok 为 true ;否则,ok 为 false。
若 key 不在映射中,那么 elem 是该映射元素类型的零值。
同样的,当从映射中读取某个不存在的键时,结果是映射的元素类型的零值。
Range
for 循环的 range 形式可遍历切片或映射。
当使用 for 循环遍历切片时,每次迭代都会返回两个值。第一个值为当前元素的下标,第二个值为该下标所对应元素的一份副本。
package main
import "fmt"
var pow = []int{
1, 2, 4, 8, 16, 32, 64, 128}
func main() {
for i, v := range pow {
fmt.Printf("2**%d = %d\n", i, v)
}
}
可以将下标或值赋予 _ 来忽略它。
for i, _ := range pow
for _, value := range pow
若你只需要索引,忽略第二个变量即可。
for i := range pow
package main
import "fmt"
func main() {
//这是我们使用range去求一个slice的和。使用数组跟这个很类似
nums := []int{
2, 3, 4}
sum := 0
for _, num := range nums {
sum += num
}
fmt.Println("sum:", sum)
//在数组上使用range将传入index和值两个变量。上面那个例子我们不需要使用该元素的序号,所以我们使用空白符"_"省略了。有时侯我们确实需要知道它的索引。
for i, num := range nums {
if num == 3 {
fmt.Println("index:", i)
}
}
//range也可以用在map的键值对上。
kvs := map[string]string{
"a": "apple", "b": "banana"}
for k, v := range kvs {
fmt.Printf("%s -> %s\n", k, v)
}
//range也可以用来枚举Unicode字符串。第一个参数是字符的索引,第二个是字符(Unicode的值)本身。
for i, c := range "go" {
fmt.Println(i, c)
}
}
函数
函数可以没有参数或接受多个参数。
package main
import "fmt"
func add(x int,y int) int {
return x+y
}
func main() {
fmt.Println(add(42, 13))
}
当连续两个或多个函数的已命名形参类型相同时,除最后一个类型以外,其它都可以省略。
package main
import "fmt"
func add(x, y int) int {
return x + y
}
func main() {
fmt.Println(add(42, 13))
}
函数可以返回任意数量的返回值。
package main
import "fmt"
func swap(x,y string) (string,string){
return y,x
}
func main() {
a,b := swap("world","hello")
fmt.Println(a,b)
}
命名返回值
Go 的返回值可被命名,它们会被视作定义在函数顶部的变量。返回值的名称应当具有一定的意义,它可以作为文档使用。
没有参数的 return 语句返回已命名的返回值。也就是 直接 返回。
直接返回语句应当仅用在下面这样的短函数中。在长的函数中它们会影响代码的可读性:
package main
import "fmt"
func split(sum int) (x,y int){
x = sum*4
y = sum-9
return
}
func main() {
fmt.Println(split(17))
}
函数值
函数也是值。它们可以像其它值一样传递。函数值可以用作函数的参数或返回值:
package main
import (
"fmt"
"math"
)
func compute(fn func(float64, float64) float64) float64 {
return fn(3, 4)
}
func main() {
hypot := func(x, y float64) float64 {
return math.Sqrt(x*x + y*y)
}
fmt.Println(hypot(5, 12))
fmt.Println(compute(hypot))
fmt.Println(compute(math.Pow))
}
package main
import "fmt"
func adder() func(int) int {
sum := 0
return func(x int) int {
sum += x
return sum
}
}
func main() {
pos, neg := adder(), adder()
for i := 0; i < 10; i++ {
fmt.Println(
pos(i),
neg(-2*i),
)
}
}
他们管这叫“函数的闭包”,在我看来这不就是递归嘛。
方法
Go 没有类。不过你可以为结构体类型定义方法。
方法就是一类带特殊的 接收者 参数的函数。方法接收者在它自己的参数列表内,位于 func 关键字和方法名之间。
package main
import (
"fmt"
"math"
)
type Vertex struct {
X, Y float64
}
func (v Vertex) Abs() float64 {
return math.Sqrt(v.X*v.X + v.Y*v.Y)
}
func (v Vertex) Abs2() float64 {
return math.Sqrt(v.X*v.X + v.Y*v.Y)
}
func main() {
vv := Vertex{
3, 4}
fmt.Println(vv.Abs2())
}
那为什么不直接在结构体里面声明一个函数?C 语言就可以。
那偏偏这里不是 C 语言啊!!!
package main
import (
"fmt"
"math"
)
type Vertex struct {
X, Y float64
func Abs() float64 {
return math.Sqrt(X*X + Y*Y)
}
}
func main() {
vv := Vertex{
3, 4}
fmt.Println(vv.Abs())
}
可以去试一下这个。
你只能为在同一包内定义的类型的接收者声明方法,而不能为其它包内定义的类型(包括 int 之类的内建类型)的接收者声明方法。
你也可以为非结构体类型声明方法。
接口
以前画类图的时候有接触过这个概念,在 C++ 里我愿称之为“抽象基类”。
但是,Go 里面的 “接口” 相比于 C++ 里的 “抽象基类” 缺少了一种强制性,使得我暂时理解不了这个 “接口” 是要干嘛用。
package main
import (
"fmt"
"math"
)
type Abser interface {
Abs() float64
}
func main() {
var a Abser
f := MyFloat(-math.Sqrt2)
v := Vertex{
3, 4}
a = f // a MyFloat 实现了 Abser
a = &v // a *Vertex 实现了 Abser
fmt.Println(a.Abs())
}
type MyFloat float64
func (f MyFloat) Abs() float64 {
if f < 0 {
return float64(-f)
}
return float64(f)
}
type Vertex struct {
X, Y float64
}
func (v *Vertex) Abs() float64 {
return math.Sqrt(v.X*v.X + v.Y*v.Y)
}
并发
Go 程
Go 语言支持并发,我们只需要通过 go 关键字来开启 goroutine 即可。
goroutine 是轻量级线程,goroutine 的调度是由 Golang 运行时进行管理的。
goroutine 语法格式:
go 函数名( 参数列表 )
例如:
go f(x, y, z)
再开启一个新的 goroutine:
f(x, y, z)
Go 允许使用 go 语句开启一个新的运行期线程, 即 goroutine,以一个不同的、新创建的 goroutine 来执行一个函数。 同一个程序中的所有 goroutine 共享同一个地址空间,因此在访问共享的内存时必须进行同步。sync 包提供了这种能力,不过在 Go 中并不经常用到,因为还有其它的办法。
package main
import (
"fmt"
"time"
)
func say(s string) {
for i := 0; i < 5; i++ {
time.Sleep(100 * time.Millisecond)
fmt.Println(s)
}
}
func main() {
go say("world")
say("hello")
}
执行以上代码,你会看到输出的 hello 和 world 是没有固定先后顺序。因为它们是两个 goroutine 在执行:
world
hello
hello
world
world
hello
hello
world
world
hello
channel
通道可用于两个 goroutine 之间通过传递一个指定类型的值来同步运行和通讯。操作符 <- 用于指定通道的方向,发送或接收。如果未指定方向,则为双向通道。
ch <- v // 把 v 发送到通道 ch
v := <-ch // 从 ch 接收数据
// 并把值赋给 v
声明一个通道很简单,我们使用chan关键字即可,通道在使用前必须先创建:
ch := make(chan int)
注意:默认情况下,通道是不带缓冲区的。发送和接收操作在另一端准备好之前都会阻塞。这使得 Go 程可以在没有显式的锁或竞态变量的情况下进行同步。
package main
import "fmt"
func sum(s []int, c chan int) {
sum := 0
for _, v := range s {
sum += v
}
c <- sum // 将和送入 c
}
func main() {
s := []int{
7, 2, 8, -9, 4, 0}
c := make(chan int)
go sum(s[:len(s)/2], c)
go sum(s[len(s)/2:], c)
x, y := <-c, <-c // 从 c 中接收
fmt.Println(x, y, x+y)
}
-5 17 12
channel 缓冲区
通道可以设置缓冲区,通过 make 的第二个参数指定缓冲区大小:
ch := make(chan int, 100)
带缓冲区的通道允许发送端的数据发送和接收端的数据获取处于异步状态,就是说发送端发送的数据可以放在缓冲区里面,可以等待接收端去获取数据,而不是立刻需要接收端去获取数据。
不过由于缓冲区的大小是有限的,所以还是必须有接收端来接收数据的,否则缓冲区一满,数据发送端就无法再发送数据了。
注意:如果通道不带缓冲,发送方会阻塞直到接收方从通道中接收了值。如果通道带缓冲,发送方则会阻塞直到发送的值被拷贝到缓冲区内;如果缓冲区已满,则意味着需要等待直到某个接收方获取到一个值。接收方在有值可以接收之前会一直阻塞。
package main
import "fmt"
func main() {
// 这里我们定义了一个可以存储整数类型的带缓冲通道
// 缓冲区大小为2
ch := make(chan int, 2)
// 因为 ch 是带缓冲的通道,我们可以同时发送两个数据
// 而不用立刻需要去同步读取数据
ch <- 1
ch <- 2
// 获取这两个数据
fmt.Println(<-ch)
fmt.Println(<-ch)
}
遍历 channel
Go 通过 range 关键字来实现遍历读取到的数据,类似于与数组或切片。
package main
import (
"fmt"
)
func fibonacci(n int, c chan int) {
x, y := 0, 1
for i := 0; i < n; i++ {
c <- x
x, y = y, x+y
}
close(c)
}
func main() {
c := make(chan int, 10)
go fibonacci(cap(c), c)
// range 函数遍历每个从通道接收到的数据,因为 c 在发送完 10 个数据之后就关闭了通道,
// 所以这里我们 range 函数在接收到 10 个数据之后就结束了。如果上面的 c 通道不关闭,
// 那么 range 函数就不会结束,从而在接收第 11 个数据的时候就阻塞了。
for i := range c {
fmt.Println(i)
}
}
信道与文件不同,通常情况下无需关闭它们。只有在必须告诉接收者不再有需要发送的值时才有必要关闭,例如终止一个 range 循环。
select
我比较好奇有没有 epoll 哈哈…
select 语句使一个 Go 程可以等待多个通信操作。select 会阻塞到某个分支可以继续执行为止,这时就会执行该分支。当多个分支都准备好时会随机选择一个执行。
package main
import "fmt"
func fibonacci(c, quit chan int) {
x, y := 0, 1
for {
select {
case c <- x:
x, y = y, x+y
case <-quit:
fmt.Println("quit")
return
}
}
}
func main() {
c := make(chan int)
quit := make(chan int)
go func() {
for i := 0; i < 10; i++ {
fmt.Println(<-c)
}
quit <- 0
}()
fibonacci(c, quit)
}
默认选择
当 select 中的其它分支都没有准备好时,default 分支就会执行。为了在尝试发送或者接收时不发生阻塞,可使用 default 分支:
select {
case i := <-c:
// 使用 i
default:
// 从 c 中接收会阻塞时执行
}
package main
import (
"fmt"
"time"
)
func main() {
tick := time.Tick(100 * time.Millisecond)
boom := time.After(500 * time.Millisecond)
for {
select {
case <-tick:
fmt.Println("tick.")
case <-boom:
fmt.Println("BOOM!")
return
default:
fmt.Println(" .")
time.Sleep(50 * time.Millisecond)
}
}
}
sync.Mutex
熟悉的互斥锁、、
Go 标准库中提供了 sync.Mutex 互斥锁类型及其两个方法:
Lock
Unlock
那么还记得前面说到的 defer 吗?在这里就可以用 defer 来确保一定会被解锁。
package main
import (
"fmt"
"sync"
"time"
)
// SafeCounter 的并发使用是安全的。
type SafeCounter struct {
v map[string]int
mux sync.Mutex
}
// Inc 增加给定 key 的计数器的值。
func (c *SafeCounter) Inc(key string) {
c.mux.Lock()
// Lock 之后同一时刻只有一个 goroutine 能访问 c.v
c.v[key]++
c.mux.Unlock()
}
// Value 返回给定 key 的计数器的当前值。
func (c *SafeCounter) Value(key string) int {
c.mux.Lock()
// Lock 之后同一时刻只有一个 goroutine 能访问 c.v
defer c.mux.Unlock()
return c.v[key]
}
func main() {
c := SafeCounter{
v: make(map[string]int)}
for i := 0; i < 1000; i++ {
go c.Inc("somekey")
}
time.Sleep(time.Second)
fmt.Println(c.Value("somekey"))
}