分享最近精读的论文:TFT (Temporal Fusion Transformers) 一种针对多步预测任务的Transformer模型,并且具有很好的可解释性。推荐阅读:4星。

论文:2019 | Temporal fusion transformers for interpretable multi-horizon time series forecasting [1]
作者:Lim, Bryan, Sercan O. Arik, Nicolas Loeff, and Tomas Pfister.
机构:牛津大学和谷歌云AI
录播:https://www.bilibili.com/video/BV1L3411A7w4?spm_id_from=333.999.0.0
代码:https://github.com/google-research/google-research/tree/master/tft
引用量:96
TFT (Temporal Fusion Transformers)是针对多步预测任务的一种Transformer模型,并且具有很好的可解释性。
一、历史瓶颈
在时序多步预测任务中,DNN面临以下两个挑战:
1. 如何利用多个数据源?
2. 如何解释模型的预测结果?
1. 如何利用多个数据源?
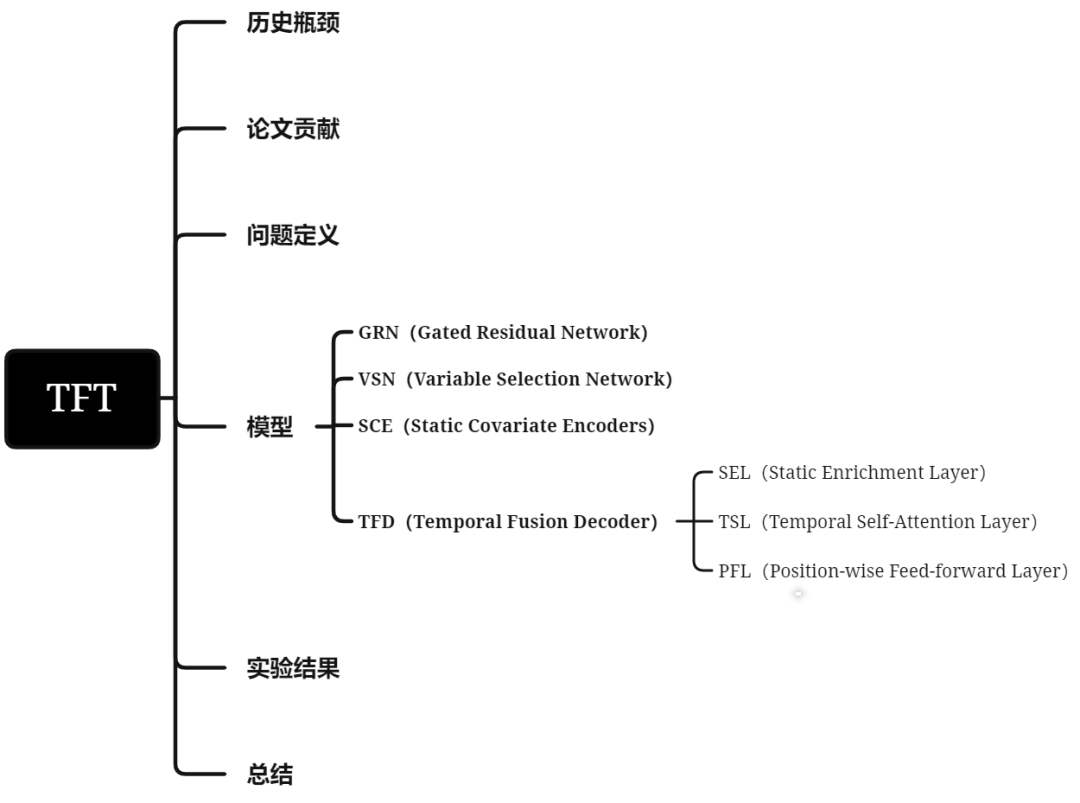
在时序任务中,有2类数据源,如图1所示:
(1)静态变量(Static Covariates):不会随时间变化的变量,例如商店位置;
(2)时变变量(Time-dependent Inputs):随时间变化的变量;
● 过去观测的时变变量(Past-observed Inputs):过去可知,但未来不可知,例如历史客流量
● 先验已知未来的时变变量(Apriori-known Future Inputs):过去和未来都可知,例如节假日;
图1:多步预测时利用的异质数据源
而很多RNN结构的变体模型,还有Transformer的变体模型,很少在多步预测任务上,认真考虑怎么去利用不同数据源的输入,只是简单把静态变量和时变变量合并在一起,但其实针对不同数据源去设计网络,会给模型带来提升。
2. 如何解释模型的预测结果?
除了不考虑常见的多步预测输入的异质性之外,大多数当前架构都是" 黑盒" 模型,预测结果是由许多参数之间的复杂非线性相互作用控制而得到的。这使得很难解释模型如何得出预测,进而让使用者难以信任模型的输出,并且模型构建者也难对症下药去Debug模型。不幸的是,DNN常用的可解释性方法不适合应用于时间序列。在它们的传统方法中,事后方法(Post-hoc Methods),例如LIME和SHAP不考虑输入特征的时间顺序。另一方面,像Transformer架构,它的自相关模块更多是能回答“哪些时间点比较重要?”,而很难回答“该时间点下,哪些特征更重要?”。
二、论文贡献
本文提出的TFT模型有如下贡献:
1. 静态协变量编码器:可以编码上下文向量,提供给网络其它部分;
2. 门控机制和样本维度的特征选择:最小化无关输入的贡献;
3. sequence-to-sequence层:局部处理时变变量(包括过去和未来已知的时变变量);
4. 时间自注意解码器:用于学习数据集中存在的长期依赖性。这也有助于模型的可解释性,TFT支持三种有价值的可解释性用例,帮助使用者识别:
● 全局重要特征;
● 时间模式;
● 重要事件。
三、问题定义
TFT支持分位数预测,对于多步预测问题的定义,可以简化成如下的公式: 其中,
● :在时间点 下,预测未来第 步下的 分位数值;
● :预测模型;
● :历史目标变量;
● :过去可观测,但未来不可知的时变变量(Past-observed Inputs);
● :先验已知未来的时变变量(Apriori-known Future Inputs);
● :静态协变量(Static Covariates)。
那怎么实现预测分位数呢?除了像DeepAR预测均值和标准差,然后对预测目标做高斯采样后,做分位数统计。TFT用了另外的方法,设计分位数损失函数,我们先看下它损失函数的样子: 其中 是包含样本的训练数据域, 表示TFT的权重, 是输出分位数的集合(我们在实验中使用的 ), 是平均单条时序且平均预测点下的分位数 的损失。这里主要是 该怎么理解,在此公式中, ,所幸看到風之千景在知乎的分析 [2],讲解的很好,这里便引用下大佬的理解,由于 和 几乎会一正一负,所以公式可以转换成:
假设我们现在拟合分位数0.9的目标值,带入上述公式便是:
那此时会有两种情况:
● 若 ,即模型预测偏小,Loss增加会更多。
● 若 ,即模型预测偏大,Loss增加会更少。
由于权重是9:1,所以训练时,模型会越来越趋向于预测出大的数字,这样Loss下降的更快,则模型的整个拟合的超平面会向上移动,这样便能很好的拟合出目标变量的90分位数值。
为了避免不同预测点下的预测量纲不一致问题,作者还做了正则化处理,2是因为这边只关注P50和P90两个分位数:
四、模型
TFT模型完整结构如下图所示:

图2:TFT结构
看起来的挺复杂的,这里先简要了解下里面各模块的功能后,我们再详细展开了解各模块细节。
1. GRN(Gated Residual Network):通过skip connections和gating layers确保有效信息的流动;
2. VSN(Variable Selection Network):基于输入,明智地选择最显著的特征。
3. SCE(Static Covariate Encoders):编码静态协变量上下文向量。
4. TFD(Temporal Fusion Decoder):学习数据集中的时间关系,里面主要有以下3大模块。
● SEL(Static Enrichment Layer):用静态元数据增强时间特征。
● TSL(Temporal Self-Attention Layer):学习时序数据的长期依赖关系并提供为模型可解释性。
● PFL(Position-wise Feed-forward Layer):对自关注层的输出应用额外的非线性处理。
如果拿Transformer的示意图来对比,我们其实能看到TFT的Variable Selection类似Transformer的Self-Attention,而Temporal Self-Attention Layer类似Encoder-Decoder Attention,这样类比Transformer去看TFT的结构,可能对理解有些帮助。
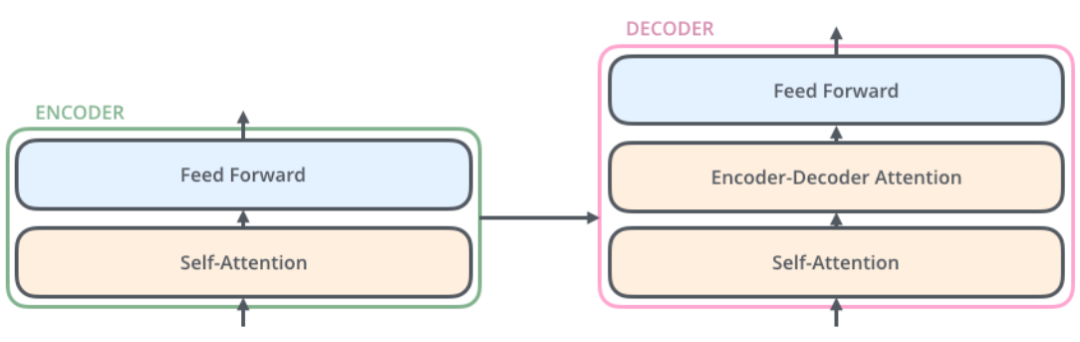
图3:Transformer的结构示意图
1. GRN(Gated Residual Network)
外生输入和目标之间的确切关系通常是事先未知的,因此很难预见哪些变量是相关的。此外,很难确定非线性处理的程度该多大,并且可能存在更简单的模型就可以满足我们需求的情况- 例如,当数据集很小或嘈杂时。为了使模型能够灵活地仅在需要时应用非线性处理,我们提出了门控残差网络(GRN):
图4:门控残差网络
GRN 接收主输入 和可选的外部上下文向量 :
我们可以把 看作线性贡献+非线性贡献,其中GLU能控制非线性贡献的程度,在TabNet中也出现GLU,它是门控线性单元,具体公式如下:
2. VSN(Variable Selection Network)
VSN是通过选择重要的特征,减少不必要的噪声输入,以提高建模性能。

图5:变量选择网络
假设我们时间点t下,有 个变量,其中如果有类别变量,我们会做entity embedding,对连续型变量,做线性变换。转换后的变量是 维度向量,转换后的变量即为 ,j为第j个变量,t为时间点t。对于历史输入,我们放平后的结果是: ,利用这些转换变量,我们可以进行变量选择: 其中, 为特征选择的权重, 为非线性处理后的特征。权重是通过以下公式获取的,其中的${c}_{s}$是静态协变量编码器提供的: 非线性处理的特征是通过以下公式获取的:
另外,需要注意的是,TFT针对静态、过去和未来输入,分别用了不同的VSN,即参数不共享,在图2中就用了不同颜色标注:

图6:3类数据源使用不同的VSN
3. SCE(Static Covariate Encoders)
与其他时间序列预测架构相比,TFT经过精心设计以集成来自静态元数据的信息,使用单独的GRN编码器生成四个不同的上下文向量 。从源码看,SCE就是GRN,它的输入是静态变量经过VSN后的结果。其中, 给了VSN(Variable Selection Network), 给了LSTM做初始化状态, 给了SEL(Static Enrichment)。
4. TFD(Temporal Fusion Decoder)
时间融合解码器是用来学习数据集中存在的时间关系,图2中,给LSTM Encoder喂入过去的特征 ,给LSTM Decoder喂入未来的特征 ,然后LSTM编码器和解码器会生成一组统一的时序特征,输入可表示为: ,n为位置索引。最后,在进入TFD前,会经过一层操作:
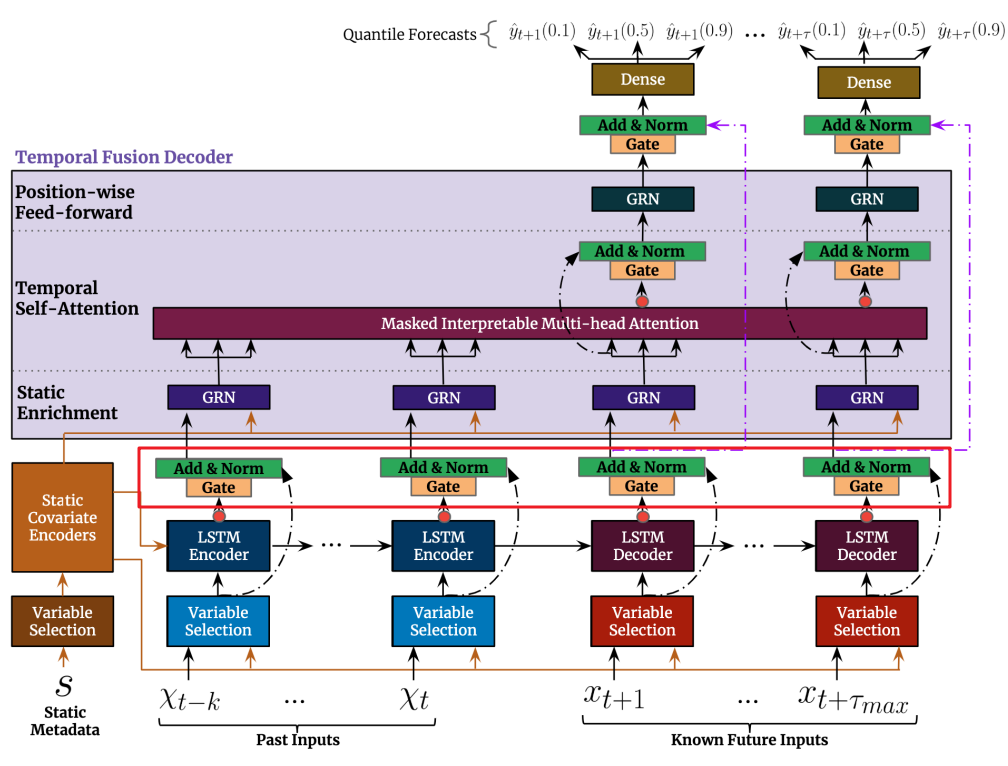
图7:特征进入TFD前的准备(红框标注内容)
进入TFD中,会流进内部3个模块:SEL(Static Enrichment Layer)、TSL(Temporal Self-Attention Layer)和PFL(Position-wise Feed-forward Layer)。
(1) SEL(Static Enrichment Layer)
静态增强层是通过引入静态协变量增强时序特征,就是简单用GRN,并输入了静态协变量编码器给的 :

图8:静态增强层
(2) TSL(Temporal Self-Attention Layer)
自关注模块可以学习时序数据的长期依赖关系,并提供为模型可解释性。在TSL中,主要是可解释性多头自关注层,再加个门控层:

图9:时序自关注层
可解释性多头自关注层比较好理解,它其实就是针对V是多头共享参数,对Q和K是多头独立参数,然后计算多头attention score加权后的V,求和平均输出即可:
(3)PFL(Position-wise Feed-forward Layer)
PFL对自关注层的输出应用额外的非线性处理。公式如下:

图10:基于位置的前馈网络层
终于讲完了各网络模块的细节了,总结一下吧,GRN用了skip-connection和GLU,主要是控制线性和非线性特征的特征信息的贡献(Gate+Add&Norm),特别是加入静态协变量c,去引导模型的学习。VSN是配合GRN和softmax,进行特征选择。TFD中的多头自关注模块提供了可解释性和时序长依赖关系的捕捉能力。
五、实验结果
图11(a)展示两行实验分别是迭代预测和直接预测多步方法的实验结果,明显TFT更好。图11(b)是单变量数据集上的实验结果,(c)和(d)分别是在丰富静态协变量或其它历史观测变量下的P50和P90 Loss表现,TFT都很好。
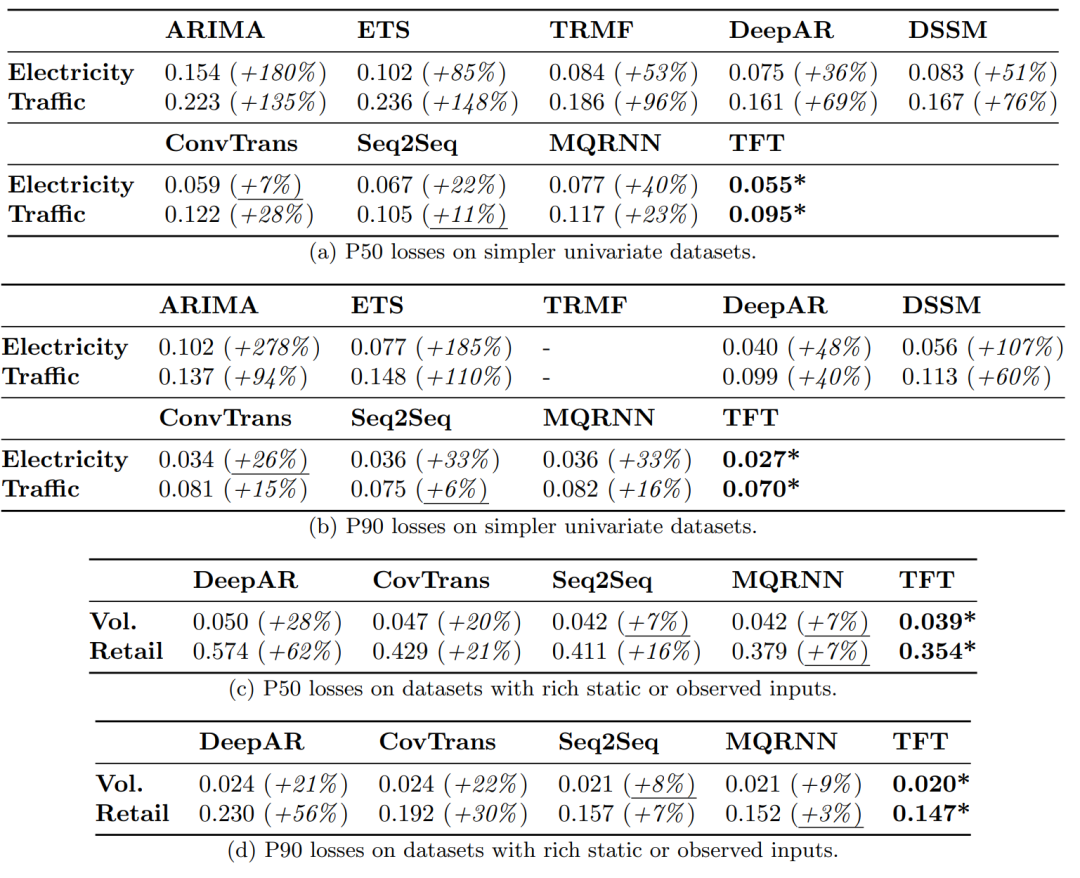
图11:真实数据集的P50和P90 Loss
另外作者对网络模块做了消融实验,如图12。从下图右侧,我们能看到Self-Attention和Local Processing(LSTM层)贡献最大,但不同数据集上,两者的贡献大小并不绝对,比如对于Traffic数据集,Local Processing更重要,作者认为是Traffic数据集得目标历史观测值更重要,所以Local Processing发挥了更大的作用。而对于Eelectricity数据集,Self-Attention更重要,作者认为是电力的周期性明显,hour-of-day特征甚至比预测目标Power Usage的历史观测值更重要,所以自关注发挥作用更大。
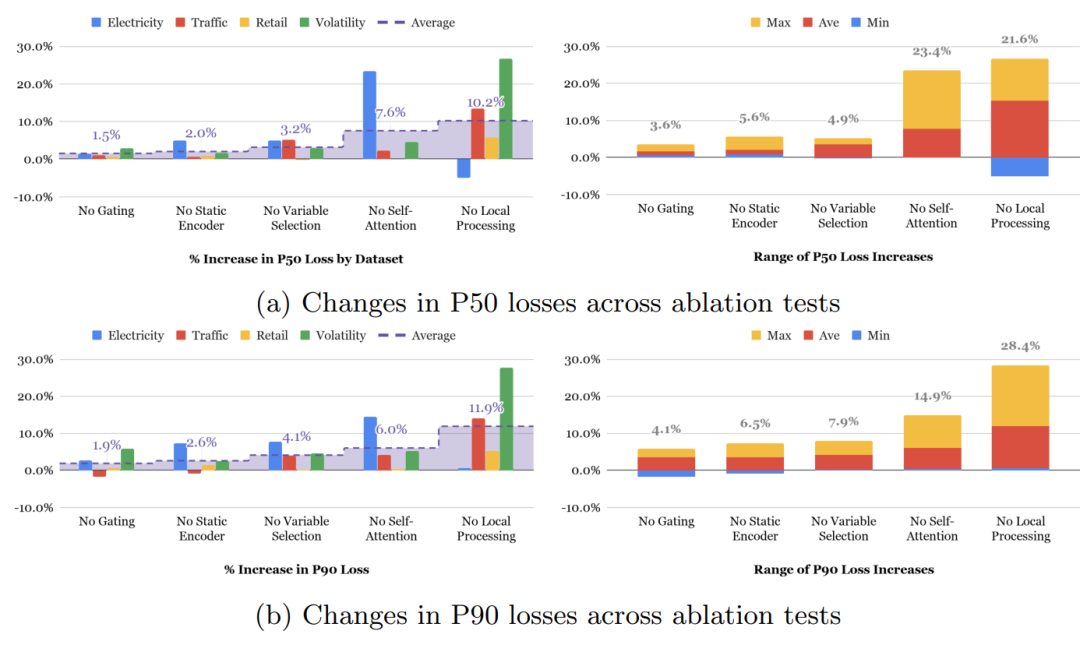
图12:消融实验结果
对TFT的解释性,作者从3方面进行展示:(1)检查每个输入变量在预测中的重要性,(2)可视化长期的时间模式,以及(3)识别导致时间动态发生重大变化的任何状态或事件。
图13是零售数据的特征重要性:
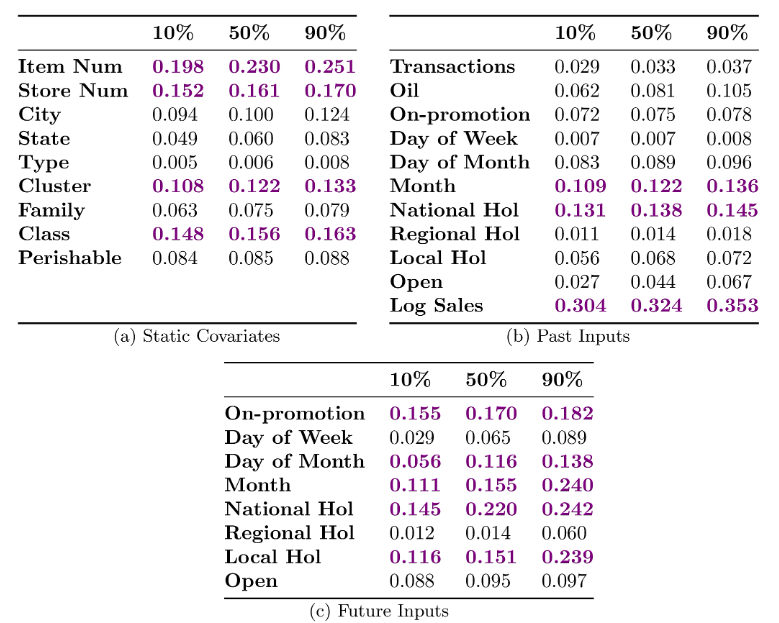
图13:零售数据的特征重要性(表内数值为变量选择权重)
图14是不同数据集的时间模式,比如电力能看到都是日间隔下的关注权重大:

图14:不同数据集的时间模式
图15是S&P500波动率的状态识别,能看到2004年到2005年关注权重的都基本相似,但2008年-2009年经融危机下,关注权重就出现显著偏差。
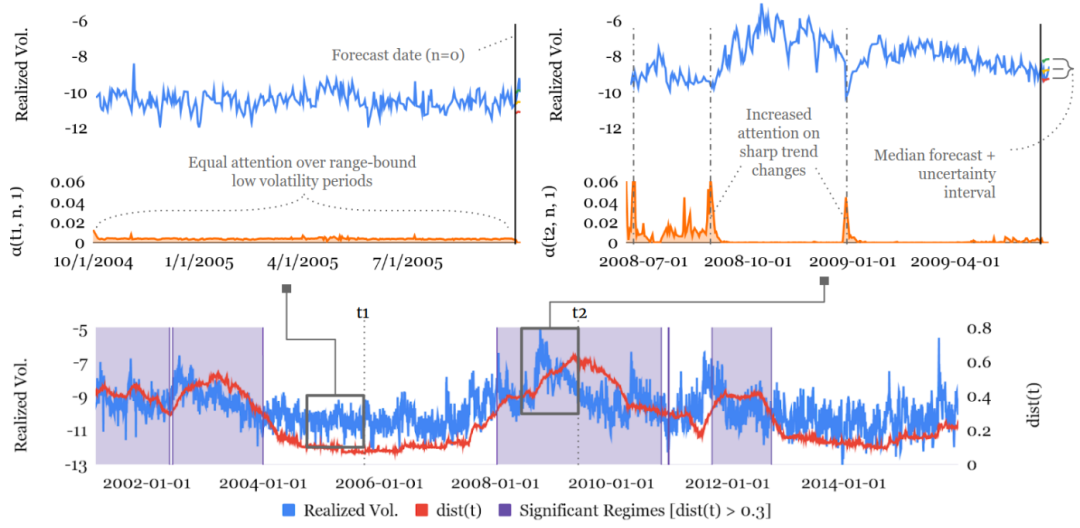
图15:S&P500波动率的状态识别
六、总结
在特征选择上,TFT有点TabNet的影子。另外对静态数据、历史和未来数据的利用,也挺好的。听不少人说TFT效果还不错,希望未来有机会可以尝试下~
参考资料
[1] Lim, B., Arik, S. O., Loeff, N., & Pfister, T. (2019). Temporal fusion transformers for interpretable multi-horizon time series forecasting. *arXiv preprint arXiv:1912.09363.*
[2] TFT时序框架理解 ****-**** 風之千景,知乎:https://zhuanlan.zhihu.com/p/461795429
推荐阅读:
公众号:AI蜗牛车
保持谦逊、保持自律、保持进步

发送【蜗牛】获取一份《手把手AI项目》(AI蜗牛车著)
发送【1222】获取一份不错的leetcode刷题笔记
发送【AI四大名著】获取四本经典AI电子书