资源下载地址:https://download.csdn.net/download/sheziqiong/85650376
任务一
1.1 伪代码


1.2 描述演化算法部件
1.2.1 解的表示
在该篇论文中,行动空间是离散化的6个动作(分为两维输入,加速度on off,方向left right straight,总共2x3=6种组合动作),同时为了性能需要,连续的L个动作被抽象成一个“宏动作”。解的表示空间就是建立在宏动作空间上的。每一个解包含N个宏动作,因此使用整数表示,是一个N维整数向量。这其中涉及到两个常亮L与N,均是在实验阶段设定的超参数。
1.2.2 种群
初始为10个随机基因。后续维护大小为10的种群。
1.2.3 交叉算子
Uniform Crossover
1.2.4 变异算子
对0-5中的每一个组合动作,一次只选择其“加速”或“方向”分量进行变异。如果选择对“加速”进行变异,则以一定概率反转加速属性,即“on”与“off”互相变化。如果选择对“方向”进行变异,“向左、向右”变异为“向前”,而向前则分别以一半的概率变异为“向左”或“向右”。
1.2.5 解的评估
引入了Score Function来进行评估,评估对象是执行完相应连续操作之后的状态。此函数包含四个分量,分别为离waypoint的距离评分、已经到达的waypoint数量评分、消耗时间评分、碰撞次数评分,这些评分分别都有对应的权重超参数来控制其影响力。
1.2.6 解的选择
第一部分,在父带节点中使用Elitism直接推荐两个最佳个体进入下一代。第二部分,采用数量为3的tournament selection选择父代个体进行繁衍,然后从子代中挑选一定数量的最优个体,以补足种群数量。
任务二
2.1 简要阐述sampleRHEA的代码结构与算法流程
2.1.1 代码结构
Individual类:实现了遗传算法中“个体”所需的元素和方法
-
元素:individual的基因型(actions)序列,individual的value(由评估函数得到)
-
crossover方法:实现了one_point与uniform两种crossover方法。
-
mutate方法:选取随机点位,变异为随机合法动作,重复执行指定次数。
-
compareTo方法:重写了比较方法,使得两个Individual的比较按照其value进行。
-
其他方法:重置、输出、复制、判断相等
Agent类:利用上述individual,实现了利用演化算法进行决策的过程
- 元素:维护了“种群”及其相关属性,同时在初始化阶段指定了演化算法的诸多超参数。
- act方法:在每次需要决策时调用,会返回当前种群所指示的最佳下一步动作。
- runIteration方法:被act方法调用,执行一轮演化算法的迭代过程。
- evaluate方法:使当前state按照individual指定的动作序列前进,并对最终到达的state根据启发式函数评价其分数。(这里的启发式函数使用的是简单的游戏输赢+游戏分数)
- crossover方法:采用tournament selection方法选取父母,然后将其crossover得到子代。
- 其他方法:初始化,重置等。
2.1.2 算法流程
sampleRHEA与RHEA论文中的算法流程基本相同,主要区别在于没有使用macro Action,因而不需要对某个动作重复执行L次。这主要影响以下两个方面:
1:评估函数中只需依次执行Individual对应的simulation_depth个动作,即可得到需要评估的状态。
2:rolling-horizon过程被改变,不再能够每L步时间进行一次决策,而要求每一步都要做决策。
此外,在变异的过程中,论文中是对子代按照一定概率变异,而sampleRHEA则是指定了变异数量。
在每一次决策过程中,agent会在时间允许范围内不断调用runIteration,来进行一轮演化算法迭代过程。迭代时父代的elite会直接保留,此外再重复执行用tournament selection挑选父母生成子代并变异,直到新种群数量达到所维护的定值。在时间即将结束时,Agent从当前种群中挑选出最优个体,并将他的第一个动作返回。
2.2 挑选5个游戏
-
0 alien:射击飞船,动态消除类游戏。需要在最大化即时奖励的同时防止全局失败。
-
4 bait:推箱子,解谜游戏。走出迷宫往往需要长远的考虑,且动作粒度小,连续操作未必好。
-
69 pacoban:上次的作业,收集、生存游戏。存在hack方法(重复吃ghost)能获得特殊高分。
-
97 towerdefence:塔防游戏。延迟奖励现象严重,且前期操作失误将有严重的延迟惩罚。
-
112 asteroids:二维平面打飞机游戏,连续状态、动作,无网格化。
2.3 实现MyRHEA
实现于src/tracks/singlePlayer/myRHEA,包含Agent、Individual、myHeuristic三个类。
实现:主要是针对sampleRHEA添加了macro Actions的实现,更改了启发式迭代的条件使其可以在决定好某次macro actions后remaining actions > 0的情况下继续搜索。同时更新了evaluate函数模拟执行的过程,改为每个action重复执行L次。超参数L在初始化阶段指定。
改进:交叉算子改为one_point_crossover,使得新生成的子代可以保留父母各自的局部信息(经过试验发现,往往连续的局部信息是有更用的)。同时修改了变异数量为2,以增强子代的探索性。最后,父代选择时tournament size增大到4,增加父代竞争性(更偏向于选择更好的父代)。
此外,更新了启发式函数,在其中加入了
1:Agent health point指标,使得可以挑选不容易是自己死亡的行动。
2:gametick指标,使得agent倾向于执行耗时较少的操作。
2.4 性能对比测试
以下对3.2中所述的5个游戏,每个算法分别在不同level下运行10轮,取平均值进行绘图。图片的横轴是游戏level,图片的纵轴为average(game_tick / score),用于反映单位得分所需时间。(为了防止除0,所有得分均加一)此性能指标应当越低越好。
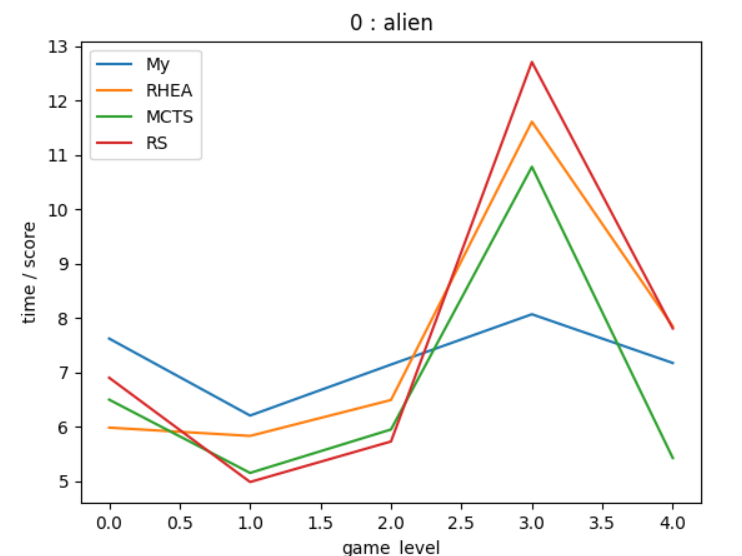
在towerdefence中,除了MCTS在level2表现较差之外,其预算法性能大致相当。使用Macro action在这里加快了agent到达所需位置的速度,但是在进行“建造”命令的时候却会产生冗余操作,导致时间的浪费。

在asteroids游戏中,myRHEA算法有着相当明显的优势。这主要是因为这个游戏环境与RHEA论文所描述的真实旅行商问题相当类似,是一个模拟的“连续行动、状态空间”环境。在这种环境下采取macro action,帮助我们将连续行动的颗粒度提升,使每一次决策产生的影响性更大,进而更好的反映不同动作间的行动值差异。可以看出myRHEA算法对这类环境有着独特的优势。
任务三
3.1 Self-Adaptive RHEA的改进
基础的RHEA中,诸如Genetic Operator, Selection Type, Crossover Type等,都是预先指定好的超参数,在代码运行过程中是不变的。而Self-Adaptive RHEA则将这些参数使用Tuner在启发式迭代过程中不断根据其性能进行调整。
在每一轮迭代之前,RHEA Agent从Tunner中得到超参数,进行一次迭代,然后Tunner根据新迭代产生的最佳子代与最佳父代适应性的差值来对超参数进行相应的调整。这样的改进好处有二,一是使得Agent具有了全局搜索最优超参数的能力而减轻初始超参数设置不妥产生的负面影响,二是能够不断跟进游戏局面的变化,选择更加适合当前环境的超参数,有点类似于在机器学习中使用动态学习率以实现更精细的调整。
资源下载地址:https://download.csdn.net/download/sheziqiong/85650376