
服务器部署
Flask
Flask是一个使用Python编写的轻量级Web应用框架。
安装Flask
pip install Flask
现在我们开始一个Hello World。
from flask import Flask, request app = Flask(__name__) @app.route("/hello") def helloword(): return "<h1>Hello World</h1>" if __name__ == '__main__': app.run(host='192.168.0.138', port=8090, debug=True)
运行后显示
* Serving Flask app "flask_web" (lazy loading)
* Environment: production
WARNING: This is a development server. Do not use it in a production deployment.
Use a production WSGI server instead.
* Debug mode: on
* Running on http://192.168.0.138:8090/ (Press CTRL+C to quit)
* Restarting with fsevents reloader
* Debugger is active!
* Debugger PIN: 235-830-661
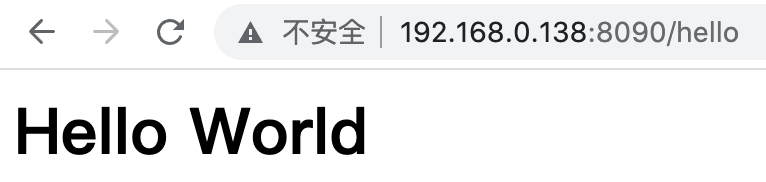
我们在浏览器中输入http://192.168.0.138:8090/hello,得到
现在我们再增加一个非常重要的方法,图片上传,提供给模型进行前向推理。
from flask import Flask, request import os app = Flask(__name__) @app.route("/hello") def helloword(): return "<h1>Hello World</h1>" @app.route("/upload", methods=['POST', 'GET']) def upload(): f = request.files.get('file') print(f) upload_path = os.path.join("/Users/admin/Documents/tmp/tmp." + f.filename.split('.')[-1]) print(upload_path) f.save(upload_path) return upload_path if __name__ == '__main__': app.run(host='192.168.0.138', port=8090, debug=True)
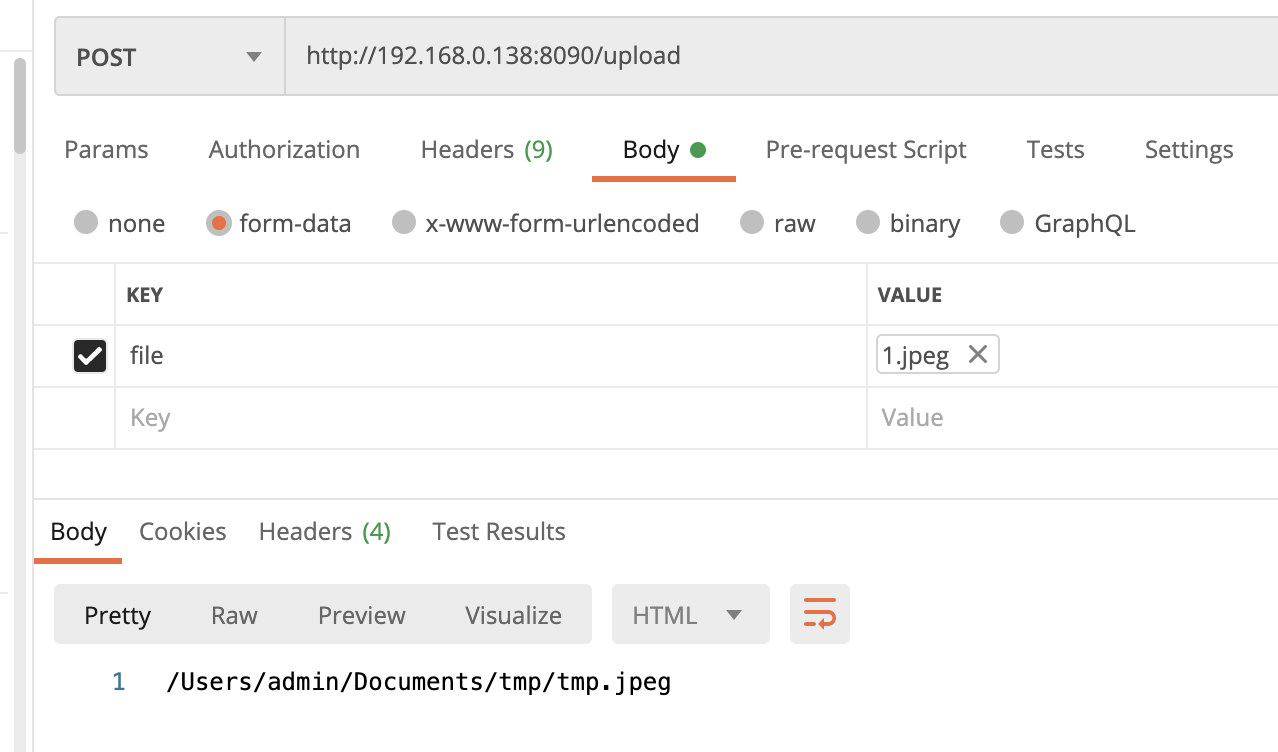
重新启动后,我们使用postman来上传文件
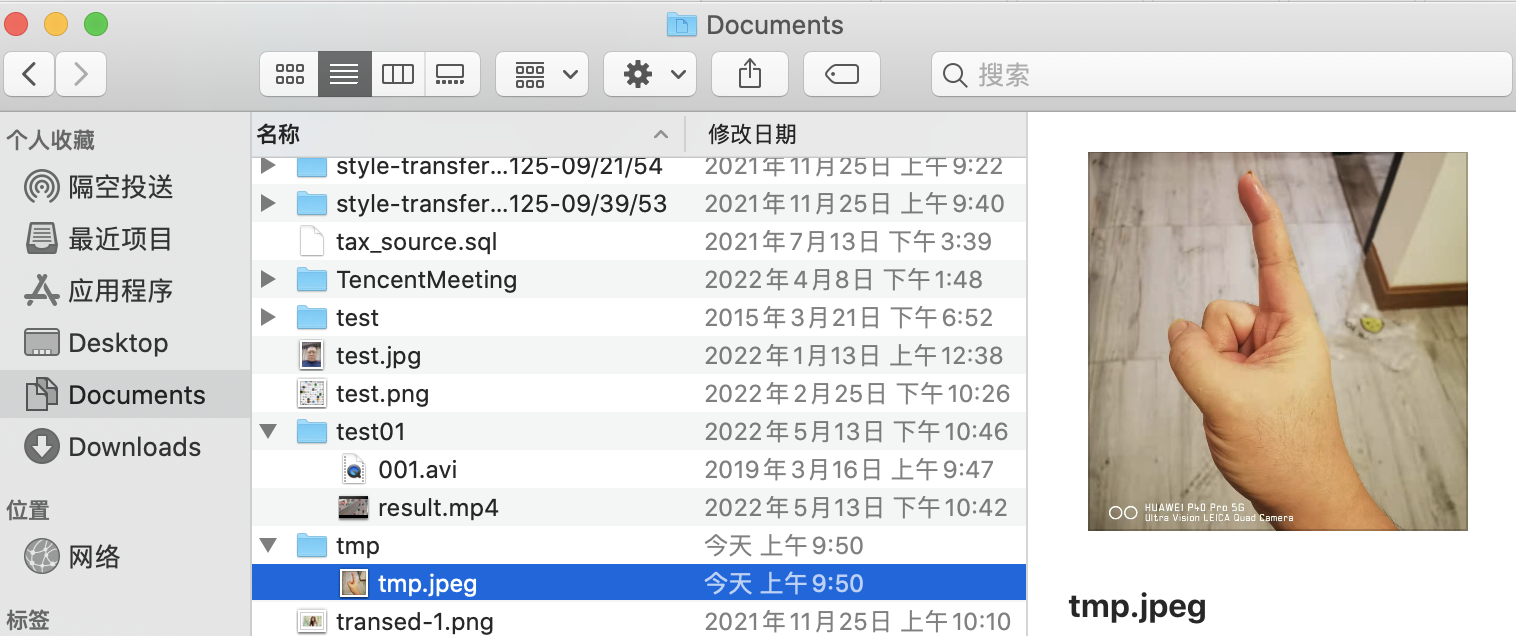
并在我们编辑的路径中找到该文件
运行结果
<FileStorage: '1.jpeg' ('image/jpeg')>
/Users/admin/Documents/tmp/tmp.jpeg
192.168.0.138 - - [02/Jun/2022 09:50:55] "POST /upload HTTP/1.1" 200 -
动态启动服务
安装gunicorn
pip install gunicorn
进入flask python文件的目录,我这里是
cd Downloads/PycharmProjects/untitled1/flask-web/
运行命令
gunicorn -b 192.168.0.138:8000 -w 2 flask_web:app
这里使用的端口号不需要跟代码中的相同,可以任意定义
运行日志
[2022-06-02 10:31:12 +0800] [1980] [INFO] Starting gunicorn 20.1.0
[2022-06-02 10:31:12 +0800] [1980] [INFO] Listening at: http://192.168.0.138:8090 (1980)
[2022-06-02 10:31:12 +0800] [1980] [INFO] Using worker: sync
[2022-06-02 10:31:12 +0800] [1983] [INFO] Booting worker with pid: 1983
[2022-06-02 10:33:40 +0800] [1980] [CRITICAL] WORKER TIMEOUT (pid:1983)
[2022-06-02 10:33:40 +0800] [1983] [INFO] Worker exiting (pid: 1983)
[2022-06-02 10:33:40 +0800] [1989] [INFO] Booting worker with pid: 1989
Android部署(MNN)
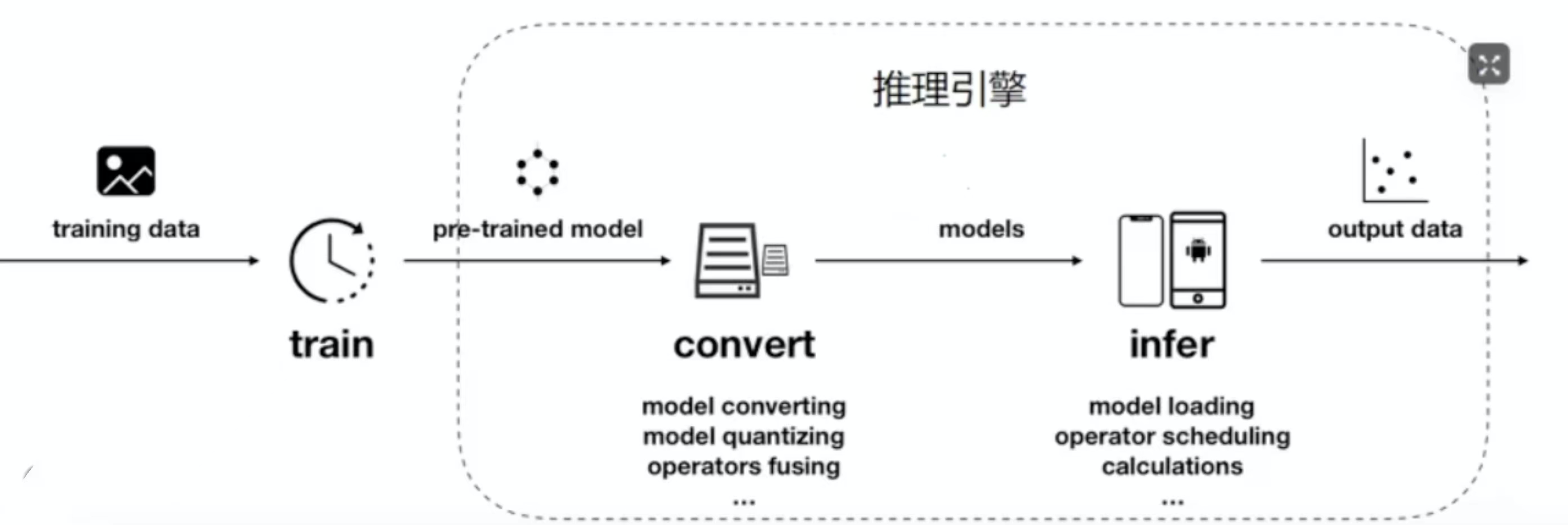
推理框架有很多,它的原理就是负责把我们训练出来的模型进行转换,然后再部署到终端上,然后我们可以在终端上使用我们训练出来的模型
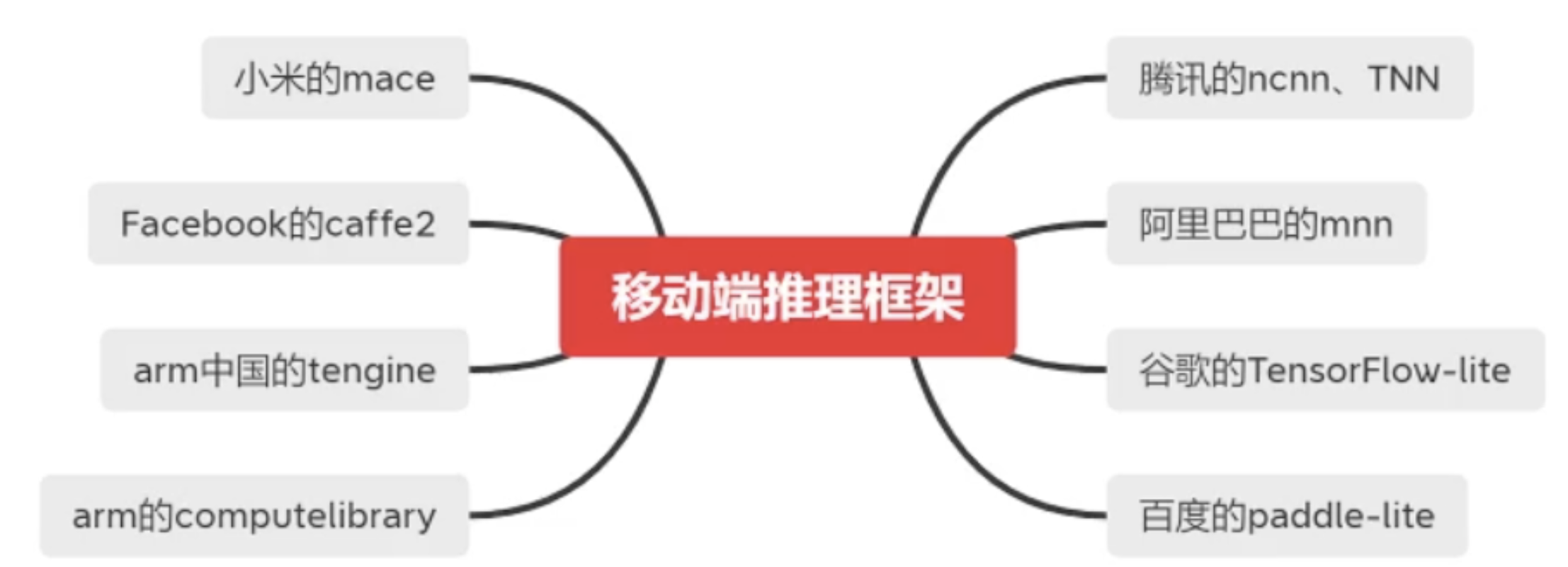
主要包括以上的种类,它们的对比如下

这里的框架支持是指的训练框架,一般现在都使用的是Pytorch。Pytorch转换出来的对应的是ONNX,具体可以参考PyTorch技术点整理 中的模型开发与部署中的ONNX。TensorFlow最擅长的就是使用Tensorflow-lite来转换自己的模型;百度的paddle-lite最擅长的也是转换自己的飞桨(PaddleFluid)模型。现在用的比较多的是MNN、ncnn、TNN。这里我们专门介绍阿里的MNN。
模型的转化与量化加速
- MNN编译
环境监察
cmake -version
要求cmake版本在3.10或以上
pip list | grep -i protobuf
要求protobuf版本在3.0或以上
gcc --version
要求gcc版本在4.9或以上
下载地址:https://github.com/alibaba/MNN
NDK下载地址:https://developer.android.com/ndk/downloads
NDK下载完成后,因为我这里是mac系统,我的安装目录是/Users/admin/Android/sdk/ndk/AndroidNDK8568313.app/自己创建的路径,然后在/etc/profile中添加
export ANDROID_NDK=/Users/admin/Android/sdk/ndk/AndroidNDK8568313.app/Contents/NDK
export PATH=$PATH:$ANDROID_NDK
保存后source一下,执行
ndk-build
出现
Android NDK: Could not find application project directory !
Android NDK: Please define the NDK_PROJECT_PATH variable to point to it.
/Users/admin/Android/sdk/ndk/AndroidNDK8568313.app/Contents/NDK/build/core/build-local.mk:151: *** Android NDK: Aborting . Stop.
说明安装成功。
SDK下载地址:https://developer.android.com/studio/releases/platform-tools
根据你自己使用的操作系统进行下载。下载完成后进行安装,我这里的安装地址为/Users/admin/Android/sdk/platform-tools。在/etc/profile中添加
export ANDROID_HOME=/Users/admin/Android/sdk
export PATH=$PATH:$ANDROID_HOME/platform-tools
source之后,打开自己的手机,我的手机为HUAWEI P40 Pro,进入设置->关于手机,连续点击版本号,进入开发者模式。再进入系统和更新,进入开发人员选项,勾选如下

在mac终端中输入
adb get-state
出现
device
说明连接成功。
打开MNN的代码,找到CMakeLists.txt,修改如下内容
option(MNN_BUILD_CONVERTER "Build Converter" ON)
option(MNN_OPENCL "Enable OpenCL" ON)
option(MNN_OPENGL "Enable OpenGL" ON)
option(MNN_VULKAN "Enable Vulkan" ON)
option(MNN_ARM82 "Enable ARM82" ON)
大概解释一下是什么意思
- MNN_BUILD_CONVERTER:默认关闭,对训练模型进行转化的工具
- MNN_OPENCL:默认关闭,可以通过指定MNN_FORWARD_OPENCL利用GPU进行推理
- MNN_OPENGL:默认关闭,可以通过指定MNN_FORWARD_OPENGL利用GPU进行推理
- MNN_VULKAN:默认关闭,可以通过指定MNN_FORWARD_VULKAN利用GPU进行推理
- MNN_ARM82:默认关闭,用Arm8.2+扩展指令集实现半精度浮点计算(fp16)和int8(sdot)加速
这里我们需要看一下自己手机的CPU型号,在终端中输入
adb shell getprop ro.product.cpu.abi
得到
arm64-v8a
以上都准备好之后就可以开始编译MNN了,进入MNN代码目录下的project/android目录下,我这里是
cd /Users/admin/Documents/MNN-master/project/android
创建编译后的目录
mkdir build_32
我们需要编译两套动态库,一套是32位的(armeabi-v7a),一套是64位的(arm64-v8a)。新建一个编译目录build_32目录,进入该目录
cd build_32
执行
../build_32.sh
编译完成后,开始编译64位的,回到上级目录,创建64位的编译后的目录
mkdir build_64
进入该目录
cd build_64
执行
../build_64.sh
编译完成后,我们可以看到有这么一些工具文件

模型转化
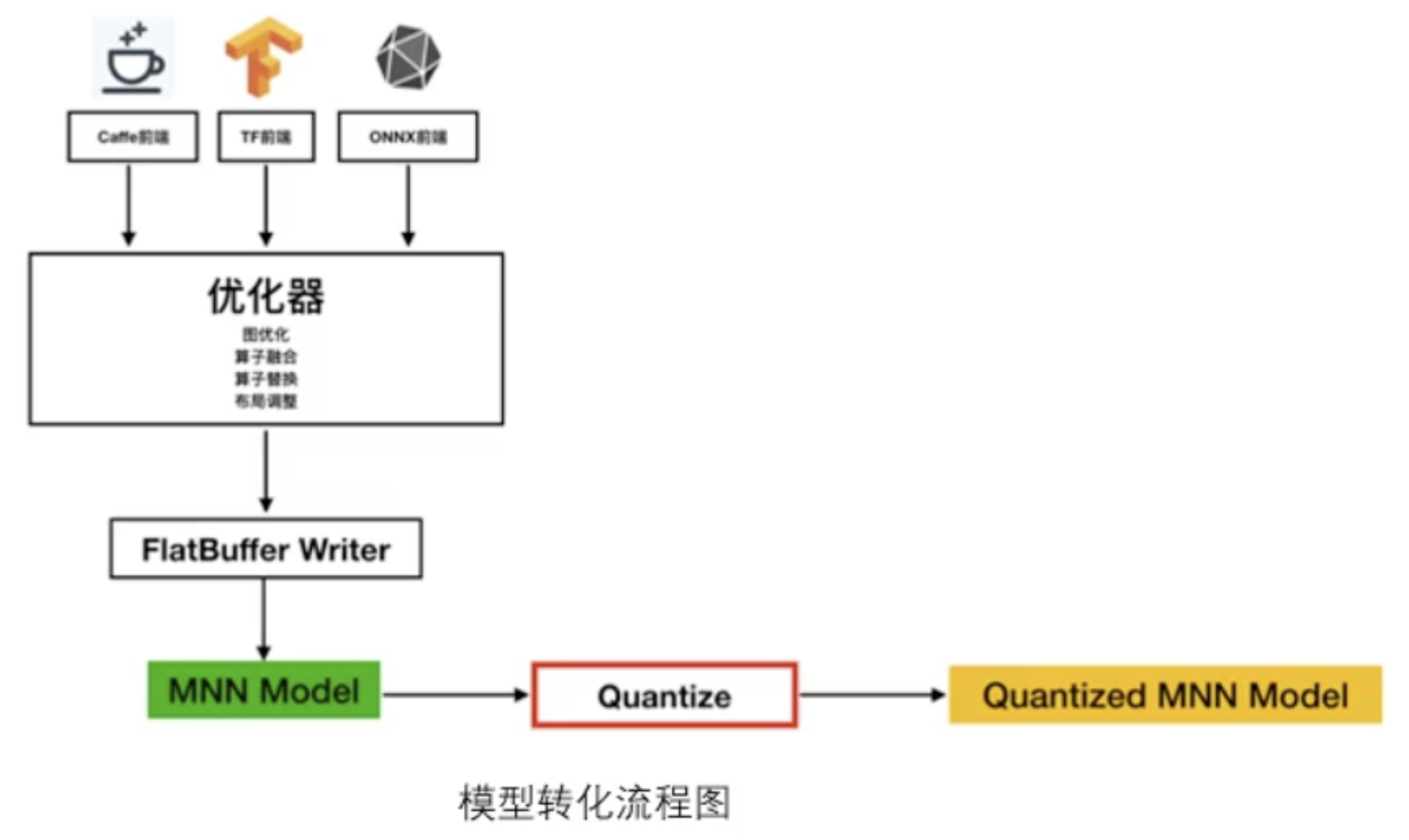
无论是Caffe、TensorFlow还是Pytorch训练出来的模型都需要转成MNN自己的模型,得到了MNN Model之后,后续还可以进行量化、剪枝的操作。
- 模型转化命令
TensorFlow -> MNN
./MNNConvert -f TF --modelFIle XXX.pb --MNNModel XXX.mnn --bizCode biz
TensorFlow Lite -> MNN
./MNNConvert -f TFLITE --modelFile XXX.tflite --MNNModel XXX.mnn --bizCode biz
Caffe -> MNN
./MNNConvert -f CAFFE --modelFile XXX.caffemodel --prototxt XXX.prototxt --MNNModel XXX.mnn --bizCode biz
ONNX -> MNN
./MNNConvert -f ONNX --modelFile XXX.onnx --MNNModel XXX.mnn --bizCode biz
Pytorch权重pth转换onnx
import torch from torch.autograd import Variable from u_net import UNet_ResNet if __name__ == '__main__': net = UNet_ResNet() net.load_state_dict(torch.load('unetv1.pth', map_location=torch.device('cpu'))) X = Variable(torch.randn(1, 3, 512, 1024)) torch.onnx.export(net, X, 'unetv1.onnx', verbose=True, opset_version=10)
这里需要注意的是,如果你的模型代码中包含了dropout的代码,需要对其设置训练标识并关闭训练标识,如
class UNet_ResNet(nn.Module): def __init__(self, in_channels=3, n_classes=N_CLASSES, dropout=0.5, start_fm=START_FRAME, is_train=False): super(UNet_ResNet, self).__init__()
if self.is_train: x = nn.Dropout2d(self.drop)(x)
模型转换可以用这个线上工具:https://convertmodel.com/
模型量化
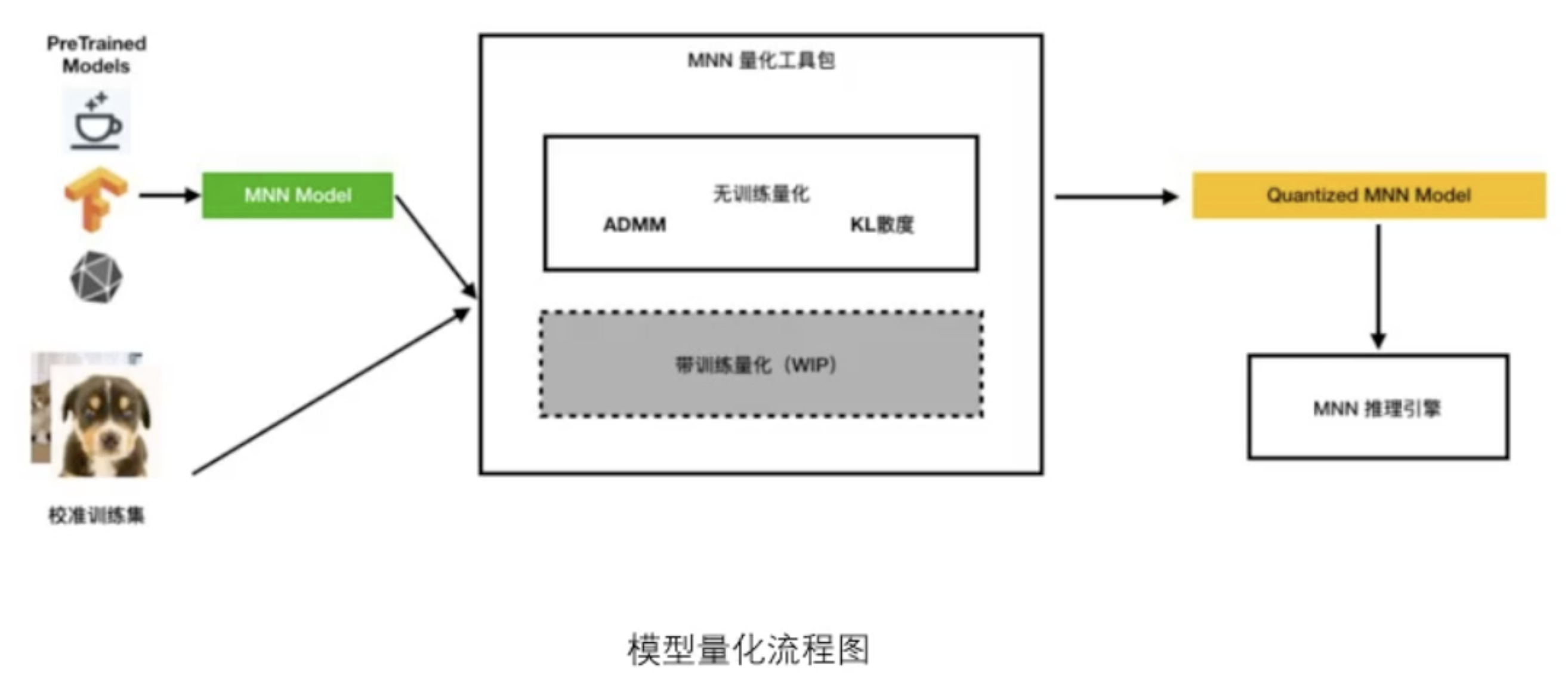
量化不光可以压缩模型的大小,它还有加速的作用。但是需要根据实际情况而定,比如对于特征提取的影响就很小,但是对于目标检测,量化之后可能会飘,识别的精度也会有一定的损失。但是提速大概可以提升20%左右。量化后的模型跟量化前的文件完全一样。
命令格式
./quantized.out ./unetv1.mnn unetv1_qua.mnn ./preprocessConfig.json
这个preprocessConfig.json是一个我们自己要配置的文件,一般文件格式如下
{"format":"RGB",
"mean":[127.5,127.5,127.5 ],
"normal":[0.00784314,0.00784314,0.00784314 ],
"width":224,
"height":224,
"path":"path/to/images/",
"used_image_num":500,
"feature_quantize_method":"KL",
"weight_quantize_method":"MAX_ABS"
}
feature_quantize_method:指定计算特征量化系数的方法,可选:
- "KL":使用KL散度进行特征量化系数的校正,一般需要100~1000张图片(若发现精度损失严重,可以适当增减样本数量,特别是检测/对齐等回归任务模型,样本建议适当减少)。
- "ADMM":使用ADMM(Alternating Direction Method of Multipliers)方法进行特征量化系数的校正,一般需要一个batch的数据。
默认:KL
weight_quantize_method:指定权值的量化方法,可选:
- "MAX_ABS":使用权值的绝对值的最大值进行对称量化。
- "ADMM":使用ADMM方法进行权值量化。
默认:MAX_ABS
上述特征量化方法和权值量化方法可进行多次测试,择优使用。
安卓部署(tf-lite)
tf-lite量化原理
在tensorflow-lite的论文里面提到,量化是将使用较高浮点数(通常是32位或64位)的神经网络近似为一个低比特宽度的神经网络的过程。通俗的说就是将float32或者float64处理成float16或者是int8格式的神经网络。
量化属于模型压缩技术的一环,但也是效果比较明显的一环。模型压缩包含:剪枝、量化、蒸馏、低秩分解、权值共享等。前三种是目前模型轻量化用的比较多的技术。
量化有训练后量化(PTQ)和量化感知训练(QAT),tf-lite训练后量化推理大概流程:
- 输入量化后的数据和权重
- 通过反量化公式计算矩阵卷积
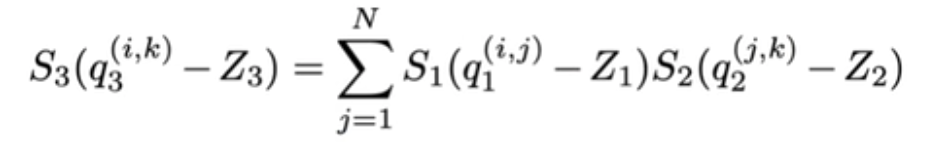
- 将int32 bias加到矩阵卷积结果,其中bias的量化参数为
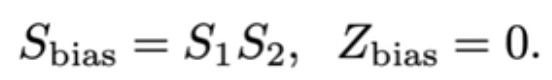
- 如果卷积之后包含bn层,则将bn层包含到卷积计算中
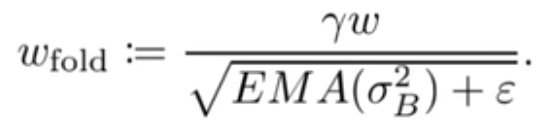
- 如果卷积/bn层之后包含激活层,比如ReLu,那么ReLu也会直接通过区间截断操作包含到对应的卷积计算中,如果不能包含的进去的,则会做相应的定点计算近似逼近。
- 最后将输出结果量化到int8。
其中4和5,是根据具体情况在导出量化模型的时候已经做好,推理的时候直接无需再多额外参数合并。
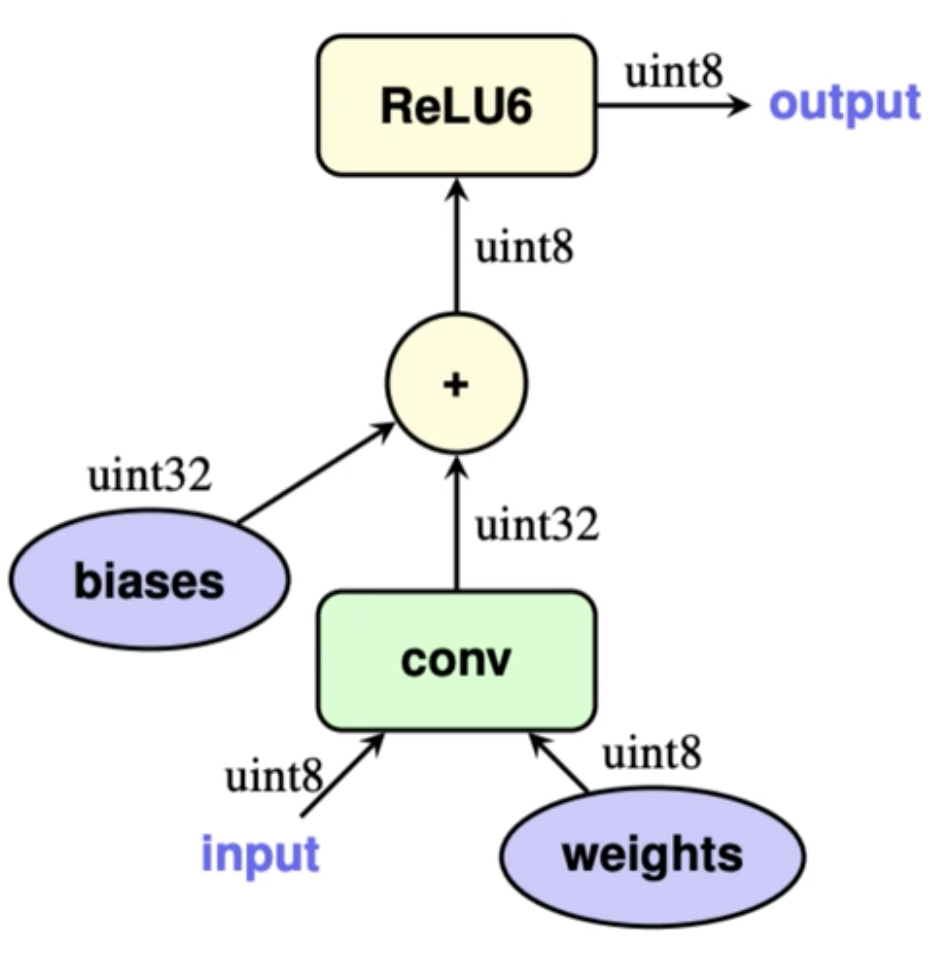
tf-lite训练后量化推理大概流程(int8为例)
1、输入量化后的数据和权重,通常都是float32/float64类型,量化模型会把float32/float64类型转化成float16/int格式
import numpy as np import tensorflow as tf def representative_dataset(): """ 模型转换时,提供represent_dataset方法帮助计算int8量化参数, 该方法根据自己数据读取提供部分即可 :return: """ for _ in range(100): data = np.random.rand(1, 244, 244, 3) yield [data.astype(np.float32)] def export_tflite(keras_model, f): # 读取keras模型 converter = tf.lite.TFLiteConverter.from_keras_model(keras_model) # 指定优化器,DEFAULT会自己权衡模型大小和延迟性能 converter.optimizations = [tf.lite.Optimize.DEFAULT] # 指定代表数据样本 converter.representative_dataset = representative_dataset() # 指定模型量化类型为int8 converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8] converter.target_spec.supported_types = [] # 指定输入和输出类型都是int8,所以才需要提供respresent_dataset converter.inference_input_type = tf.uint8 converter.inference_output_type = tf.uint8 converter.experimental_new_quantizer = False tflite_model = converter.convert() open(f, 'wb').write(tflite_model)
2、反量化公式,公式里是假定两个矩阵相乘,分别为量化后的input tensor q1和filter kernel q2,另外S1、S2、S3为缩放因子,用来缩放值域;Z1、Z2、Z3为零点,用来对齐浮点和量化值0值,在没量化前,矩阵的乘法为:![]() ,r表示浮点数,r(real value)和q(quantization value)的关系可以用下面公式表示
,r表示浮点数,r(real value)和q(quantization value)的关系可以用下面公式表示
![]()
进一步展开反量化公式可以得到最后卷积乘法的量化输出:
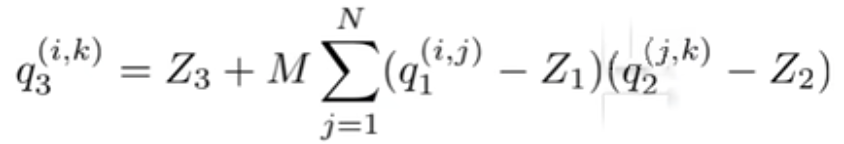
其中![]()
那么到目前为止,除了还没加上bias,tflite中int8卷积计算大概就是上面公式所示,该公式中除了M的计算设计浮点外,另外的所有计算都是在整数范围下,为了让整个计算过程能尽量减少浮点参与,tflite特地针对M的计算进行了优化,具体为将M替换为:![]()
由于S1、S2、S3都是已知,且通过大量观察得到M通常都是位于区间(0,1),这样就可以通过采用定点数![]() 以及位运算近似得到M,而定点数运算在gemmlowp库中已有高效的实现。
以及位运算近似得到M,而定点数运算在gemmlowp库中已有高效的实现。
tf-lite量化导出
tflite官方提供了4种量化方法
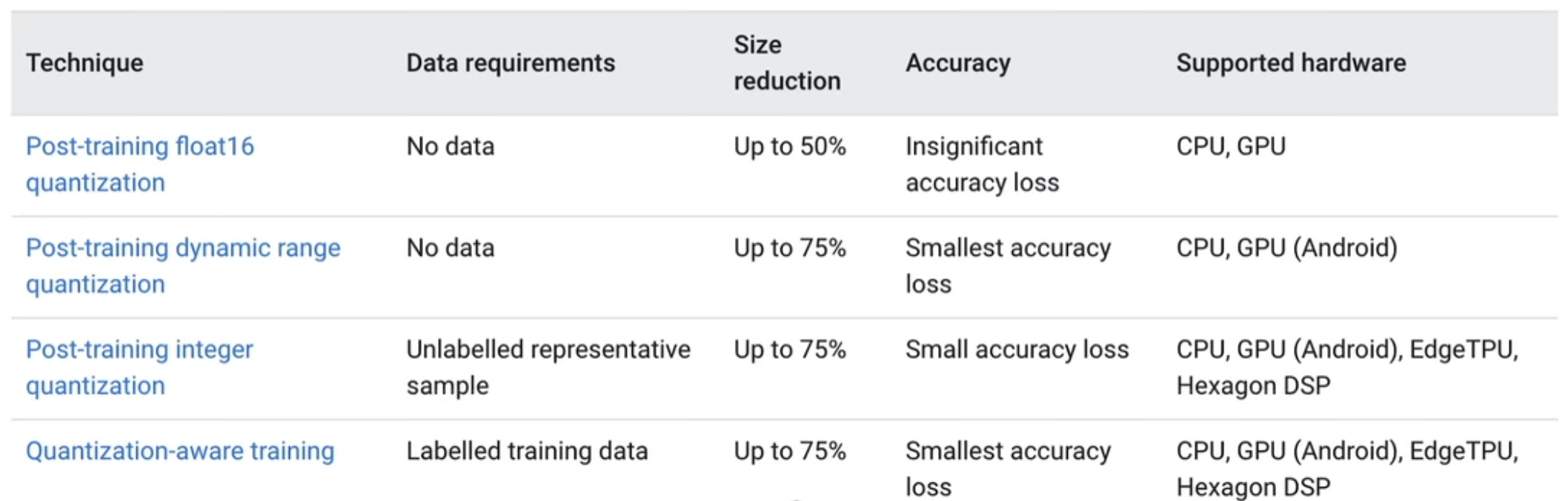
从上到下分别为
- float16量化,input/output都是float32,体积减小50%,这种能尽最大可能保留模型精度,同时又能减小模型体积。
- 动态量化,input/output都是float32,模型参数为int8,过程输入输出都是float32,体积能减小75%。
- 全整型量化,input/output,包括整型参数,过程输入输出都是int8,同样体积能减小75%,与方法2不同的是,全整型量化输入输出都是int8,对于一些只能在整型上计算的板子,这是唯一的方法,同时这种方法需要提供小批量数据,用于标定input/output的量化参数scale/zero-point。
- 量化感知训练,可以用于边量化模型边训练,提高量化后模型精度。
- float16量化导出,以YOLOV5为例
python export.py --weights yolov5s.pt --include tflite --imgsz 320
此时我们可以看见导出文件
它的主要核心功能在这个方法中,我们可以在其他框架使用时自己来写这个方法。
def export_tflite(keras_model, im, file, int8, data, ncalib, prefix=colorstr('TensorFlow Lite:')): # YOLOv5 TensorFlow Lite export try: import tensorflow as tf LOGGER.info(f'\n{prefix} starting export with tensorflow {tf.__version__}...') batch_size, ch, *imgsz = list(im.shape) # BCHW f = str(file).replace('.pt', '-fp16.tflite') converter = tf.lite.TFLiteConverter.from_keras_model(keras_model) # 指定使用哪些op作为量化时可以采用的,目前可以选择的有: # tf.lite.OpsSet.TFLITE_BUILTINS:只用tflite内置op,这是默认选项 # tf.lite.OpsSet.SELECT_TF_OPS:采用tf本身的op,但是不是所有tf方法都支持,不建议使用,除非有自己设计 # 的比较复杂的结构 # tf.lite.OpsSet.TFLITE_BUILTINS_INT8:只用tflite里面的int8的op # tf.lite.OpsSet.EXPERIMENTAL_TFLITE_BUILTINS_ACTIVATIONS_INT16_WEIGHTS_INT8:实验接口,int8权重 # int16激活值,int32 bias,建议生产环境不用,这种设计可以在牺牲一定体积压缩下取得比单纯int8更高的精度 converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS] converter.target_spec.supported_types = [tf.float16] converter.optimizations = [tf.lite.Optimize.DEFAULT] if int8: from models.tf import representative_dataset_gen dataset = LoadImages(check_dataset(data)['train'], img_size=imgsz, auto=False) # representative data converter.representative_dataset = lambda: representative_dataset_gen(dataset, ncalib) converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8] converter.target_spec.supported_types = [] converter.inference_input_type = tf.uint8 # or tf.int8 converter.inference_output_type = tf.uint8 # or tf.int8 converter.experimental_new_quantizer = True f = str(file).replace('.pt', '-int8.tflite') tflite_model = converter.convert() open(f, "wb").write(tflite_model) LOGGER.info(f'{prefix} export success, saved as {f} ({file_size(f):.1f} MB)') return f except Exception as e: LOGGER.info(f'\n{prefix} export failure: {e}')