
MTCNN是一个级联网络,包含了三个网络结构,通过不同的步骤来针对于输出的结果来进行一步又一步的精修。
- Stage1:Proposal Net(P-Net)
- stage2:Refine Net(R-Net)
- Stage3:Output Net(O-Net)
这里的每一步的网络结构都是一个多任务网络,在这个多任务网络中它同时完成了人脸分类、人脸检测以及人脸关键点的定位。这里的人脸关键点采用的是5点定位。三个网络的网络结构如下
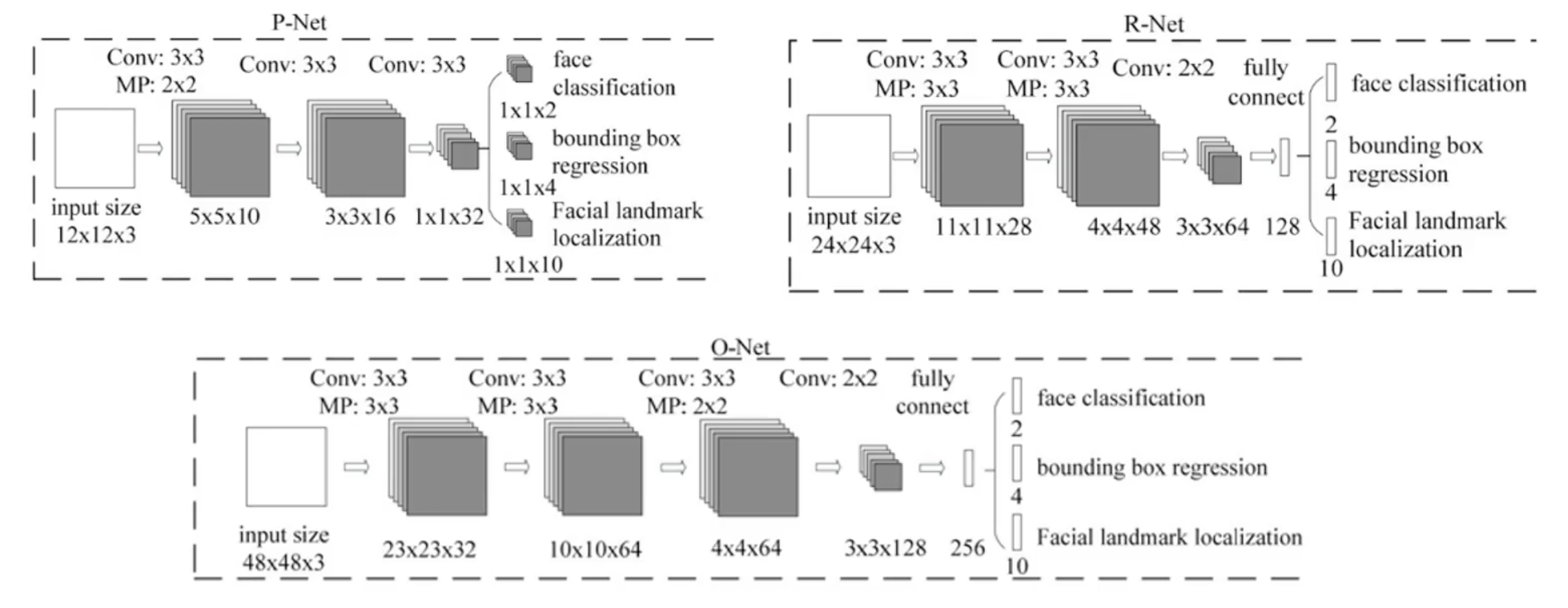
对于P-Net而言,它实际上是一个标准的卷积神经网络结构,在最后通过不同的卷积神经之后分别回归出人脸的类别,就是当前的proposal提取出来的bounding box相应框的人脸的分类。然后是bounding box坐标的回归。再就是landmark(人脸关键点)坐标的回归。从尺寸上来看人脸分类1*1*2,可知它是一个二分类(是人脸还是不是人脸)。bounding box为1*1*4可知,它是人脸矩形框的位置的回归。landmark为1*1*10可知,它是采用5个人脸关键点(一个点包含x、y坐标)来标注的关键点,所以它需要回归出10个值。针对于P-Net的输出结果,我们利用P-Net来挖掘更多的难例,利用P-Net来进行第一阶段网络的输出来作为第二阶段网络的输入,也就是R-Net网络的输入。对于P-Net而言,它输入的尺寸为12*12*3,而到第二步的R-Net的时候,从12*12扩大到了24*24。R-Net同样是回归出人脸分类,bounding box的坐标以及landmark的坐标三个任务。
而O-Net则是再一次针对于R-Net的输出来进行进一步结果的修正,而它的输入尺寸则是再一次扩大变成了48*48*3,最终输出的结果就是我们想要检测的当前的这张图片中的人脸分类、bounding box的位置以及landmark的位置。

在上图中,我们可以看到通过MTCNN将人脸的位置标了出来。通过5个点标出了landmark的位置。这里5个landmark分别表示了人眼睛的位置,鼻尖的位置以及两个嘴角的位置。
P-Net实现
import tensorflow as tf from tensorflow.keras import layers, models import numpy as np import cv2 class P_Net(models.Model): def __init__(self, weight_path, threshold, nms_threshold, factor=0.709, resize_shape=(80, 80)): super(P_Net, self).__init__() self.threshold = threshold self.nms_threshold = nms_threshold self.factor = factor self.resize_shape = resize_shape self.model = self._create_model() self.model.load_weights(weight_path, by_name=True) self.scales = self.get_scales() def _norm(self, image): """对输入的图片作归一化""" # 颜色通道转换 image = cv2.cvtColor(image.numpy().copy(), cv2.COLOR_BGR2RGB) # 对图片按用户指定的尺寸缩放 image = self.image_resize_padding(image, self.resize_shape) # 对图片作归一化处理 image = (image - 127.5) / 127.5 return image def _get_boundingbox(self, out): """这个方法主要用于判断大于阈值的坐标,并且转换成矩形框 """ classifier = out[0] boundingbox = [] for i in range(len(self.scales)): scale = self.scales[i] cls_prob = classifier[i, :, :, 1] # 获取大于阈值的分类和bounding box的索引 (x, y), bbx = self._boundingbox(cls_prob, scale) if bbx.shape[0] == 0: continue # 获取大于阈值的分类概率 scores = np.array(classifier[i, x, y, 1][np.newaxis, :].T) # 获取大于阈值的原图bounding box坐标偏移 offset = out[1][i, x, y] * 12 * (1 / scale) # 获取大于阈值的原图bounding box坐标 bbx = bbx + offset # 拼接bounding box坐标和分类概率 bbx = np.concatenate((bbx, scores), axis=1) for b in bbx: boundingbox.append(b) return np.array(boundingbox) def _boundingbox(self, cls_prob, scale): # 返回行索引和列索引 x, y = np.where(cls_prob > self.threshold) # 获取列跟行的索引组合 bbx = np.array((y, x)).T # 获取原图的bounding box的左上角坐标索引 left_top = np.fix(((bbx * 2) + 0) * (1 / scale)) # 获取原图的bounding box的右下角坐标索引 right_down = np.fix(((bbx * 2) + 11) * (1 / scale)) return (x, y), np.concatenate((left_top, right_down), axis=1) def get_scales(self): """这个函数用于获得缩放比例 将原始图片进行缩放,保存缩放系数,保证缩小成最小值 后,长和宽仍然大于12,否则无法传入pnet网络 """ i = 0 scales = [] while True: scale = self.factor**i tmp_width = self.resize_shape[0] * scale tmp_height = self.resize_shape[1] * scale # 如果缩放成小于12,则不符合要求 if min(tmp_width, tmp_height) <= 12: break scales.append(scale) # 符合要求的值放入__scale中 i += 1 # i的值每次加一,以便减小scale的值 print(scales) return scales def image_resize_padding(self, image, size): """缩放函数 """ width = image.shape[0] # 获得图像的宽 height = image.shape[1] # 获得图像的高 # 选择大的边作为resize后的边长 side_length = image.shape[0] if width > height else height mask = self.mask_template((side_length, side_length)) mask[0:width, 0:height] = image # 获取padding后的图像 image = self.image_resize(mask, size) return image def get_pnet_need_imgs(self, image): """获得pnet输入需要的一系列图片 通过scales对原始图片进行缩放,被 缩放的图片填充回原图大小,打包返回 """ # 获取原图的宽高 image_width = image.shape[0] image_height = image.shape[1] image_list = [] for scale in self.scales: sss_ = self.mask_template(self.resize_shape) # 将原图的宽高进行比例缩放 width = int(scale * image_width) height = int(scale * image_height) size = (width, height) img_tmp = self.image_resize(image.numpy().copy(), size) # 将缩放后的图像放入原图大小中 sss_[0:width, 0:height] = img_tmp image_list.append(sss_) return np.array(image_list) def mask_template(self, shape): """图片掩码模板 根据用户输入resize图片的尺寸, 制作模板,方便获取不同大小的pnet 图片的需求 """ sss = np.zeros([shape[0], shape[1]], dtype=np.uint8) sss = cv2.cvtColor(sss, cv2.COLOR_GRAY2RGB) sss = (sss - 127.5) / 127.5 return sss def image_resize(self, image, size): """图像缩放""" image = tf.image.resize(image.copy(), size) return image def _rect2square(self, rectangles): """将矩形框修整为正方形 """ rectangles = np.array(rectangles) w = rectangles[:, 2] - rectangles[:, 0] h = rectangles[:, 3] - rectangles[:, 1] l = np.maximum(w, h) # 修剪bounding box左上角的横坐标 rectangles[:, 0] = rectangles[:, 0] + w * 0.5 - l * 0.5 # 修剪bounding box左上角的纵坐标 rectangles[:, 1] = rectangles[:, 1] + h * 0.5 - l * 0.5 # 更新bounding box右下脚的坐标为左上角的坐标加上l rectangles[:, 2:4] = rectangles[:, 0:2] + np.repeat([l], 2, axis=0).T return rectangles def _trimming_frame(self, rectangles, width, height): '''限制在原图范围内''' for j in range(len(rectangles)): # 对每一个bounding box左上角的坐标值必须大于0 rectangles[j][0] = max(0, int(rectangles[j][0])) rectangles[j][1] = max(0, int(rectangles[j][1])) # 对每一个bounding box右下角的坐标值必须小于宽和高 rectangles[j][2] = min(width, int(rectangles[j][2])) rectangles[j][3] = min(height, int(rectangles[j][3])) # 如果该bounding box左上角的坐标值大于右下角的坐标值则更新 # 左上角的坐标值为0 if rectangles[j][0] >= rectangles[j][2]: rectangles[j][0] = 0 elif rectangles[j][1] > rectangles[j][3]: rectangles[j][1] = 0 return rectangles def _nms(self, rectangles, threshold): """非极大值抑制 """ if len(rectangles) == 0: return rectangles boxes = np.array(rectangles) x1 = boxes[:, 0] y1 = boxes[:, 1] x2 = boxes[:, 2] y2 = boxes[:, 3] s = boxes[:, 4] # 获取所有bounding box的面积 area = np.multiply(x2 - x1 + 1, y2 - y1 + 1) # 将bounding box的分类概率按照从小到大排序并获得排序后的索引 I = np.array(s.argsort()) pick = [] while len(I) > 0: # 将bouding box所有非分类概率最大的左上角的坐标值小于分类概率最大的左上角坐标值的坐标 # 全部改成分类概率最大的左上角坐标值 xx1 = np.maximum(x1[I[-1]], x1[I[0:-1]]) yy1 = np.maximum(y1[I[-1]], y1[I[0:-1]]) # 将bouding box所有非分类概率最大的右下角的坐标值大于分类概率最大的右下角坐标值的坐标 # 全部改成分类概率最大的右下角坐标值 xx2 = np.minimum(x2[I[-1]], x2[I[0:-1]]) yy2 = np.minimum(y2[I[-1]], y2[I[0:-1]]) # 将获取到的坐标值计算宽高 w = np.maximum(0.0, xx2 - xx1 + 1) h = np.maximum(0.0, yy2 - yy1 + 1) # 根据宽高计算面积 inter = w * h # 计算IOU o = inter / (area[I[-1]] + area[I[0:-1]] - inter) # 获取分类概率最大的索引值 pick.append(I[-1]) # 获取IOU小于等于阈值的索引值 I = I[np.where(o <= threshold)[0]] result_rectangle = boxes[pick].tolist() return result_rectangle def _create_model(self): """定义PNet网络的架构""" input = layers.Input(shape=[None, None, 3]) x = layers.Conv2D(10, (3, 3), strides=1, padding='valid', name='conv1')(input) x = layers.PReLU(shared_axes=[1, 2], name='PReLU1')(x) x = layers.MaxPooling2D()(x) x = layers.Conv2D(16, (3, 3), strides=1, padding='valid', name='conv2')(x) x = layers.PReLU(shared_axes=[1, 2], name='PReLU2')(x) x = layers.Conv2D(32, (3, 3), strides=1, padding='valid', name='conv3')(x) x = layers.PReLU(shared_axes=[1, 2], name='PReLU3')(x) classifier = layers.Conv2D(2, (1, 1), activation='softmax', name='conv4-1')(x) bbox_regress = layers.Conv2D(4, (1, 1), name='conv4-2')(x) model = models.Model([input], [classifier, bbox_regress]) print(model.summary()) return model def call(self, x): img = self._norm(x) imgs = self.get_pnet_need_imgs(img) width = imgs.shape[1] height = imgs.shape[2] out = self.model.predict(imgs) bounding_box = self._get_boundingbox(out) rectangles = self._rect2square(bounding_box) bounding_box = self._trimming_frame(rectangles, width, height) bounding_box = self._nms(bounding_box, 0.3) bounding_box = self._nms(bounding_box, self.nms_threshold) return bounding_box if __name__ == '__main__': pnet = P_Net('../weight_path/pnet.h5', 0.5, 0.7) img = cv2.imread("/Users/admin/Documents/2123.png") imgc = img.copy() print(img.shape) print(pnet(imgc))
运行结果(部分)
Model: "model"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) [(None, None, None, 0
__________________________________________________________________________________________________
conv1 (Conv2D) (None, None, None, 1 280 input_1[0][0]
__________________________________________________________________________________________________
PReLU1 (PReLU) (None, None, None, 1 10 conv1[0][0]
__________________________________________________________________________________________________
max_pooling2d (MaxPooling2D) (None, None, None, 1 0 PReLU1[0][0]
__________________________________________________________________________________________________
conv2 (Conv2D) (None, None, None, 1 1456 max_pooling2d[0][0]
__________________________________________________________________________________________________
PReLU2 (PReLU) (None, None, None, 1 16 conv2[0][0]
__________________________________________________________________________________________________
conv3 (Conv2D) (None, None, None, 3 4640 PReLU2[0][0]
__________________________________________________________________________________________________
PReLU3 (PReLU) (None, None, None, 3 32 conv3[0][0]
__________________________________________________________________________________________________
conv4-1 (Conv2D) (None, None, None, 2 66 PReLU3[0][0]
__________________________________________________________________________________________________
conv4-2 (Conv2D) (None, None, None, 4 132 PReLU3[0][0]
==================================================================================================
Total params: 6,632
Trainable params: 6,632
Non-trainable params: 0
__________________________________________________________________________________________________
None
[1.0, 0.709, 0.5026809999999999, 0.3564008289999999, 0.25268818776099994, 0.17915592512254896]
(1440, 1080, 3)
[[9.0, 19.0, 46.0, 56.0, 0.9998825788497925], [17.0, 34.0, 30.0, 47.0, 0.9575949907302856], [25.0, 29.0, 43.0, 47.0, 0.9383312463760376], [23.0, 43.0, 39.0, 59.0, 0.7974936962127686], [48.0, 49.0, 59.0, 60.0, 0.7760439515113831], [35.0, 30.0, 47.0, 41.0, 0.6201214790344238], [24.0, 18.0, 42.0, 37.0, 0.5720170140266418]]我们来看一下这里的整体流程,先获取一张图片,然后将其resize到80*80,然后根据缩放因子缩放到不同尺寸的图片并恢复成原图尺寸形成一个图片列表。将该图片列表送入到卷积神级网络中返回像素级别的粗分类和bounding box的坐标偏移。挑选出大于阈值的分类和bounding box坐标,再将bounding box的框转成正方形。再将转成正方形的bounding box进行原图像大小范围的限制,最后进行非极大值抑制进行输出。
R-Net实现
import tensorflow as tf from tensorflow.keras import layers, models import numpy as np from src.P_Net import P_Net import cv2 class R_Net(models.Model): def __init__(self, weight_path, threshold, nms_threshold, pnet_got_rects, resize_shape=(80, 80)): super(R_Net, self).__init__() self.threshold = threshold self.nms_threshold = nms_threshold self.model = self._create_model() self.model.load_weights(weight_path, by_name=True) self.pnet_got_rects = pnet_got_rects self.resize_shape = resize_shape def _norm(self, image): """对输入的图片作归一化""" # 颜色通道转换 image = cv2.cvtColor(image.numpy().copy(), cv2.COLOR_BGR2RGB) # 对图片按用户指定的尺寸缩放 image = self.image_resize_padding(image, self.resize_shape) # 对图片作归一化处理 image = (image - 127.5) / 127.5 return image def image_resize_padding(self, image, size): """缩放函数 """ width = image.shape[0] # 获得图像的宽 height = image.shape[1] # 获得图像的高 # 选择大的边作为resize后的边长 side_length = image.shape[0] if width > height else height mask = self.mask_template((side_length, side_length)) mask[0:width, 0:height] = image # 获取padding后的图像 image = self.image_resize(mask, size) return image def mask_template(self, shape): """图片掩码模板 根据用户输入resize图片的尺寸, 制作模板,方便获取不同大小的rnet 图片的需求 """ sss = np.zeros([shape[0], shape[1]], dtype=np.uint8) sss = cv2.cvtColor(sss, cv2.COLOR_GRAY2RGB) sss = (sss - 127.5) / 127.5 return sss def _get_net_need_imgs(self, rects, image): """获取输入网络图像的通用方法 """ need_imgs = [] for rect in rects: tmp_roi = image.numpy().copy()[int(rect[1]): int(rect[3]), \ int(rect[0]): int(rect[2])] if tmp_roi.shape[0] > 0 and tmp_roi.shape[1] > 0: tmp_roi = tf.image.resize(tmp_roi, (24, 24)).numpy() need_imgs.append(tmp_roi) return np.array(need_imgs) def image_resize(self, image, size): """图像缩放""" image = tf.image.resize(image.copy(), size) return image def _get_boundingbox(self, outs, pnet_got_rects): """这个函数用于得到加上偏移后的矩形框坐标 """ # 人脸概率 classifier = outs[0] # 偏移量 offset = outs[1] # 获取大于阈值分类的索引 x = np.where(classifier[:, 1] > self.threshold) # 获得相应位置的offset值,并扩展维度 offset = offset[x, None] # 获取偏移量的值 dx1 = np.array(offset[0])[:, :, 0] dy1 = np.array(offset[0])[:, :, 1] dx2 = np.array(offset[0])[:, :, 2] dy2 = np.array(offset[0])[:, :, 3] # P-Net输出的Bounding box pnet_got_rects = np.array(pnet_got_rects) # 获取相应位置的bounding box的坐标值 x1 = np.array(pnet_got_rects[x][:, 0])[np.newaxis, :].T y1 = np.array(pnet_got_rects[x][:, 1])[np.newaxis, :].T x2 = np.array(pnet_got_rects[x][:, 2])[np.newaxis, :].T y2 = np.array(pnet_got_rects[x][:, 3])[np.newaxis, :].T # bounding box的宽高 w = x2 - x1 h = y2 - y1 # 根据偏移量以及P-Net的bounding box生成新的bounding box的坐标 new_x1 = np.fix(x1 + dx1 * w) new_x2 = np.fix(x2 + dx2 * w) new_y1 = np.fix(y1 + dy1 * h) new_y2 = np.fix(y2 + dy2 * h) # R-Net大于阈值的人脸概率 score = np.array(classifier[x, 1]).T # 拼接新的bounding box(带分类概率) boundingbox = np.concatenate((new_x1, new_y1, new_x2, new_y2, score), axis=1) return boundingbox def _rect2square(self, rectangles): """将矩形框修整为正方形 """ rectangles = np.array(rectangles) w = rectangles[:, 2] - rectangles[:, 0] h = rectangles[:, 3] - rectangles[:, 1] l = np.maximum(w, h) # 修剪bounding box左上角的横坐标 rectangles[:, 0] = rectangles[:, 0] + w * 0.5 - l * 0.5 # 修剪bounding box左上角的纵坐标 rectangles[:, 1] = rectangles[:, 1] + h * 0.5 - l * 0.5 # 更新bounding box右下脚的坐标为左上角的坐标加上l rectangles[:, 2:4] = rectangles[:, 0:2] + np.repeat([l], 2, axis=0).T return rectangles def _trimming_frame(self, rectangles, width, height): '''限制在原图范围内''' for j in range(len(rectangles)): # 对每一个bounding box左上角的坐标值必须大于0 rectangles[j][0] = max(0, int(rectangles[j][0])) rectangles[j][1] = max(0, int(rectangles[j][1])) # 对每一个bounding box右下角的坐标值必须小于宽和高 rectangles[j][2] = min(width, int(rectangles[j][2])) rectangles[j][3] = min(height, int(rectangles[j][3])) # 如果该bounding box左上角的坐标值大于右下角的坐标值则更新 # 左上角的坐标值为0 if rectangles[j][0] >= rectangles[j][2]: rectangles[j][0] = 0 elif rectangles[j][1] > rectangles[j][3]: rectangles[j][1] = 0 return rectangles def _nms(self, rectangles, threshold): """非极大值抑制 """ if len(rectangles) == 0: return rectangles boxes = np.array(rectangles) x1 = boxes[:, 0] y1 = boxes[:, 1] x2 = boxes[:, 2] y2 = boxes[:, 3] s = boxes[:, 4] # 获取所有bounding box的面积 area = np.multiply(x2 - x1 + 1, y2 - y1 + 1) # 将bounding box的分类概率按照从小到大排序并获得排序后的索引 I = np.array(s.argsort()) pick = [] while len(I) > 0: # 将bouding box所有非分类概率最大的左上角的坐标值小于分类概率最大的左上角坐标值的坐标 # 全部改成分类概率最大的左上角坐标值 xx1 = np.maximum(x1[I[-1]], x1[I[0:-1]]) yy1 = np.maximum(y1[I[-1]], y1[I[0:-1]]) # 将bouding box所有非分类概率最大的右下角的坐标值大于分类概率最大的右下角坐标值的坐标 # 全部改成分类概率最大的右下角坐标值 xx2 = np.minimum(x2[I[-1]], x2[I[0:-1]]) yy2 = np.minimum(y2[I[-1]], y2[I[0:-1]]) # 将获取到的坐标值计算宽高 w = np.maximum(0.0, xx2 - xx1 + 1) h = np.maximum(0.0, yy2 - yy1 + 1) # 根据宽高计算面积 inter = w * h # 计算IOU o = inter / (area[I[-1]] + area[I[0:-1]] - inter) # 获取分类概率最大的索引值 pick.append(I[-1]) # 获取IOU小于等于阈值的索引值 I = I[np.where(o <= threshold)[0]] result_rectangle = boxes[pick].tolist() return result_rectangle def _create_model(self): """定义RNet网络的架构""" input = layers.Input(shape=[24, 24, 3]) x = layers.Conv2D(28, (3, 3), strides=1, padding='valid', name='conv1')(input) x = layers.PReLU(shared_axes=[1, 2], name='prelu1')(x) x = layers.MaxPooling2D((3, 3), strides=2, padding='same')(x) x = layers.Conv2D(48, (3, 3), strides=1, padding='valid', name='conv2')(x) x = layers.PReLU(shared_axes=[1, 2], name='prelu2')(x) x = layers.MaxPooling2D((3, 3), strides=2)(x) x = layers.Conv2D(64, (2, 2), strides=1, padding='valid', name='conv3')(x) x = layers.PReLU(shared_axes=[1, 2], name='prelu3')(x) x = layers.Permute((3, 2, 1))(x) x = layers.Flatten()(x) x = layers.Dense(128, name='conv4')(x) x = layers.PReLU(name='prelu4')(x) classifier = layers.Dense(2, activation='softmax', name='conv5-1')(x) bbox_regress = layers.Dense(4, name='conv5-2')(x) model = models.Model([input], [classifier, bbox_regress]) print(model.summary()) return model def call(self, x): img = self._norm(x) imgs = self._get_net_need_imgs(self.pnet_got_rects, img) outs = self.model.predict(imgs) boundingbox = self._get_boundingbox(outs, self.pnet_got_rects) rectangles = self._rect2square(boundingbox) bounding_box = self._trimming_frame(rectangles, img.shape[0], img.shape[1]) return self._nms(bounding_box, self.nms_threshold) if __name__ == '__main__': pnet = P_Net('../weight_path/pnet.h5', 0.5, 0.7) img = cv2.imread("/Users/admin/Documents/2123.png") print(img.shape) p_out = pnet(img) rnet = R_Net('../weight_path/rnet.h5', 0.6, 0.7, p_out) print(rnet(img))
运行结果(部分)
Model: "model_1"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_2 (InputLayer) [(None, 24, 24, 3)] 0
__________________________________________________________________________________________________
conv1 (Conv2D) (None, 22, 22, 28) 784 input_2[0][0]
__________________________________________________________________________________________________
prelu1 (PReLU) (None, 22, 22, 28) 28 conv1[0][0]
__________________________________________________________________________________________________
max_pooling2d_1 (MaxPooling2D) (None, 11, 11, 28) 0 prelu1[0][0]
__________________________________________________________________________________________________
conv2 (Conv2D) (None, 9, 9, 48) 12144 max_pooling2d_1[0][0]
__________________________________________________________________________________________________
prelu2 (PReLU) (None, 9, 9, 48) 48 conv2[0][0]
__________________________________________________________________________________________________
max_pooling2d_2 (MaxPooling2D) (None, 4, 4, 48) 0 prelu2[0][0]
__________________________________________________________________________________________________
conv3 (Conv2D) (None, 3, 3, 64) 12352 max_pooling2d_2[0][0]
__________________________________________________________________________________________________
prelu3 (PReLU) (None, 3, 3, 64) 64 conv3[0][0]
__________________________________________________________________________________________________
permute (Permute) (None, 64, 3, 3) 0 prelu3[0][0]
__________________________________________________________________________________________________
flatten (Flatten) (None, 576) 0 permute[0][0]
__________________________________________________________________________________________________
conv4 (Dense) (None, 128) 73856 flatten[0][0]
__________________________________________________________________________________________________
prelu4 (PReLU) (None, 128) 128 conv4[0][0]
__________________________________________________________________________________________________
conv5-1 (Dense) (None, 2) 258 prelu4[0][0]
__________________________________________________________________________________________________
conv5-2 (Dense) (None, 4) 516 prelu4[0][0]
==================================================================================================
Total params: 100,178
Trainable params: 100,178
Non-trainable params: 0
__________________________________________________________________________________________________
None
[[11.0, 20.0, 49.0, 58.0, 0.9978736639022827], [15.0, 31.0, 33.0, 49.0, 0.7061299681663513]]现在我们来看一下R-Net的整体流程,获取一张图片,先通过P-Net的整体流程。同样这张图片,在R-Net的过程中,也是先Resize到80*80,然后在Resize后的图片中裁剪出所有P-Net中输出的bounding box的范围的一系列图片,再将裁减后的所有的图片resize到24*24,再将所有的图片送入到R-Net的卷积神级网络中返回像素级别的粗分类和bounding box的坐标偏移。挑选出大于阈值的分类和bounding box坐标,再将bounding box的框转成正方形。再将转成正方形的bounding box进行原图像大小范围的限制,最后进行非极大值抑制进行输出。
O-Net实现
import tensorflow as tf from tensorflow.keras import layers, models import numpy as np from src.P_Net import P_Net from src.R_Net import R_Net import time import cv2 class O_Net(models.Model): def __init__(self, weight_path, threshold, rnet_got_rects, save_dirt, resize_shape=(80, 80), max_face=False): super(O_Net, self).__init__() self.threshold = threshold self.model = self._create_model() self.model.load_weights(weight_path, by_name=True) self.rnet_got_rects = rnet_got_rects self.save_dirt = save_dirt self.resize_shape = resize_shape self.max_face = max_face def _norm(self, image): """对输入的图片作归一化""" # 颜色通道转换 image = cv2.cvtColor(image.numpy().copy(), cv2.COLOR_BGR2RGB) # 对图片按用户指定的尺寸缩放 image = self.image_resize_padding(image, self.resize_shape) # 对图片作归一化处理 image = (image - 127.5) / 127.5 return image def image_resize_padding(self, image, size): """缩放函数 """ width = image.shape[0] # 获得图像的宽 height = image.shape[1] # 获得图像的高 # 选择大的边作为resize后的边长 side_length = image.shape[0] if width > height else height mask = self.mask_template((side_length, side_length)) mask[0:width, 0:height] = image # 获取padding后的图像 image = self.image_resize(mask, size) return image def mask_template(self, shape): """图片掩码模板 根据用户输入resize图片的尺寸, 制作模板,方便获取不同大小的rnet 图片的需求 """ sss = np.zeros([shape[0], shape[1]], dtype=np.uint8) sss = cv2.cvtColor(sss, cv2.COLOR_GRAY2RGB) sss = (sss - 127.5) / 127.5 return sss def get_message(self, image): width = image.shape[0] height = image.shape[1] big_side = width if width > height else height self.width_scale = big_side / self.resize_shape[0] self.height_scale = big_side / self.resize_shape[1] def image_resize(self, image, size): """图像缩放""" image = tf.image.resize(image.copy(), size) return image def _get_net_need_imgs(self, rects, image): """获取输入网络图像的通用方法 """ need_imgs = [] for rect in rects: tmp_roi = image.numpy().copy()[int(rect[1]): int(rect[3]), \ int(rect[0]): int(rect[2])] if tmp_roi.shape[0] > 0 and tmp_roi.shape[1] > 0: tmp_roi = tf.image.resize(tmp_roi, (48, 48)).numpy() need_imgs.append(tmp_roi) return np.array(need_imgs) def _get_boundingbox(self, outs, rnet_got_rects): """这个函数用于得到加上偏移后的矩形框坐标 """ # 人脸概率 classifier = outs[0] # 偏移量 offset = outs[1] # 获取大于阈值分类的索引 x = np.where(classifier[:, 1] > self.threshold) # 获得相应位置的offset值,并扩展维度 offset = offset[x, None] # 获取偏移量的值 dx1 = np.array(offset[0])[:, :, 0] dy1 = np.array(offset[0])[:, :, 1] dx2 = np.array(offset[0])[:, :, 2] dy2 = np.array(offset[0])[:, :, 3] # R-Net输出的Bounding box pnet_got_rects = np.array(rnet_got_rects) # 获取相应位置的bounding box的坐标值 x1 = np.array(pnet_got_rects[x][:, 0])[np.newaxis, :].T y1 = np.array(pnet_got_rects[x][:, 1])[np.newaxis, :].T x2 = np.array(pnet_got_rects[x][:, 2])[np.newaxis, :].T y2 = np.array(pnet_got_rects[x][:, 3])[np.newaxis, :].T # bounding box的宽高 w = x2 - x1 h = y2 - y1 # 根据偏移量以及R-Net的bounding box生成新的bounding box的坐标 new_x1 = np.fix(x1 + dx1 * w) new_x2 = np.fix(x2 + dx2 * w) new_y1 = np.fix(y1 + dy1 * h) new_y2 = np.fix(y2 + dy2 * h) # R-Net大于阈值的人脸概率 score = np.array(classifier[x, 1]).T # 拼接新的bounding box(带分类概率) boundingbox = np.concatenate((new_x1, new_y1, new_x2, new_y2, score), axis=1) return boundingbox def _rect2square(self, rectangles): """将矩形框修整为正方形 """ rectangles = np.array(rectangles) w = rectangles[:, 2] - rectangles[:, 0] h = rectangles[:, 3] - rectangles[:, 1] l = np.maximum(w, h) # 修剪bounding box左上角的横坐标 rectangles[:, 0] = rectangles[:, 0] + w * 0.5 - l * 0.5 # 修剪bounding box左上角的纵坐标 rectangles[:, 1] = rectangles[:, 1] + h * 0.5 - l * 0.5 # 更新bounding box右下脚的坐标为左上角的坐标加上l rectangles[:, 2:4] = rectangles[:, 0:2] + np.repeat([l], 2, axis=0).T return rectangles def _trimming_frame(self, rectangles, width, height): '''限制在原图范围内''' for j in range(len(rectangles)): # 对每一个bounding box左上角的坐标值必须大于0 rectangles[j][0] = max(0, int(rectangles[j][0])) rectangles[j][1] = max(0, int(rectangles[j][1])) # 对每一个bounding box右下角的坐标值必须小于宽和高 rectangles[j][2] = min(width, int(rectangles[j][2])) rectangles[j][3] = min(height, int(rectangles[j][3])) # 如果该bounding box左上角的坐标值大于右下角的坐标值则更新 # 左上角的坐标值为0 if rectangles[j][0] >= rectangles[j][2]: rectangles[j][0] = 0 elif rectangles[j][1] > rectangles[j][3]: rectangles[j][1] = 0 return rectangles def _get_landmark(self, outs, rnet_got_rects): '''获取人脸关键点''' # 人脸概率 classifier = outs[0] # 获取大于阈值分类的索引 x = np.where(classifier[:, 1] > self.threshold) # 人脸关键点位置 onet_pts = outs[2] # 获取大于阈值分类的人脸关键点的坐标偏移 offset_x1 = onet_pts[x, 0] offset_y1 = onet_pts[x, 5] offset_x2 = onet_pts[x, 1] offset_y2 = onet_pts[x, 6] offset_x3 = onet_pts[x, 2] offset_y3 = onet_pts[x, 7] offset_x4 = onet_pts[x, 3] offset_y4 = onet_pts[x, 8] offset_x5 = onet_pts[x, 4] offset_y5 = onet_pts[x, 9] # 获取R-Net输出概率最大的bounding box坐标 x1 = rnet_got_rects[0][0] y1 = rnet_got_rects[0][1] x2 = rnet_got_rects[0][2] y2 = rnet_got_rects[0][3] # 获取R-Net输出概率最大的bounding box宽高 w = x2 - x1 h = y2 - y1 # 获取大于阈值分类的人脸关键点的坐标 onet_pts_x1 = np.array(offset_x1 * w + x1) onet_pts_x2 = np.array(offset_x2 * w + x1) onet_pts_x3 = np.array(offset_x3 * w + x1) onet_pts_x4 = np.array(offset_x4 * w + x1) onet_pts_x5 = np.array(offset_x5 * w + x1) onet_pts_y1 = np.array(offset_y1 * h + y1) onet_pts_y2 = np.array(offset_y2 * h + y1) onet_pts_y3 = np.array(offset_y3 * h + y1) onet_pts_y4 = np.array(offset_y4 * h + y1) onet_pts_y5 = np.array(offset_y5 * h + y1) # 将所有人脸关键点坐标点的横坐标纵坐标拼接 onet_left_eye = np.concatenate((onet_pts_x1, onet_pts_y1), axis=1) onet_right_eye = np.concatenate((onet_pts_x2, onet_pts_y2), axis=1) onet_nose = np.concatenate((onet_pts_x3, onet_pts_y3), axis=1) onet_left_mouth = np.concatenate((onet_pts_x4, onet_pts_y4), axis=1) onet_right_mouth = np.concatenate((onet_pts_x5, onet_pts_y5), axis=1) return (onet_left_eye, onet_right_eye, onet_nose, onet_left_mouth, onet_right_mouth) def fix_rects(self, rects): '''将得到的边界还原到原图合适的比例''' for rect in rects: width = rect[2] - rect[0] height = rect[3] - rect[1] rect[0] = rect[0] * self.width_scale rect[1] = rect[1] * self.height_scale rect[2] = rect[0] + width * self.width_scale rect[3] = rect[1] + height * self.height_scale def to_save_face(self, rects, image, dirt): name = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()) + str(time.clock()) if self.max_face == True: img_ = self.to_get_max_face(rects, image.copy()) if (cv2.imwrite(dirt + "/" + name + ".jpg", img_)): self.print_messages("成功保存人脸到{}".format(dirt + "/" + name + ".jpg")) else: for i in range(len(rects)): # 获取每个矩形框 rect = rects[i] img_ = self.to_get_all_faces(rect, image) if img_.shape[0] > 0 and img_.shape[1] > 0: # show_img(img_) if (cv2.imwrite(dirt + "/" + name + ".jpg", img_)): self.print_messages("成功保存人脸到{}".format(dirt + "/" + name + ".jpg")) def to_get_max_face(self, rects, image): """获取图像中的最大人脸""" areas = [] for rect in rects: width = rect[2] - rect[0] height = rect[3] - rect[1] area = width * height areas.append(area) index = np.argmax(np.array(areas), axis=0) # 竖着比较,返回行号 img_ = self.to_get_all_faces(rects[index], image) return img_ def to_get_all_faces(self, rect, image): """获得图像中的所有人脸""" img_ = image.numpy().copy()[int(rect[1]): int(rect[3]), int(rect[0]): int(rect[2])] return img_ def print_messages(self, mess): print(mess) print("*" * 10) def _create_model(self): """定义ONet网络的架构""" input = layers.Input(shape=[48, 48, 3]) # 48,48,3 -> 23,23,32 x = layers.Conv2D(32, (3, 3), strides=1, padding='valid', name='conv1')(input) x = layers.PReLU(shared_axes=[1, 2], name='prelu1')(x) x = layers.MaxPool2D((3, 3), strides=2, padding='same')(x) # 23,23,32 -> 10,10,64 x = layers.Conv2D(64, (3, 3), strides=1, padding='valid', name='conv2')(x) x = layers.PReLU(shared_axes=[1, 2], name='prelu2')(x) x = layers.MaxPool2D((3, 3), strides=2)(x) # 8,8,64 -> 4,4,64 x = layers.Conv2D(64, (3, 3), strides=1, padding='valid', name='conv3')(x) x = layers.PReLU(shared_axes=[1, 2], name='prelu3')(x) x = layers.MaxPool2D((2, 2))(x) # 4,4,64 -> 3,3,128 x = layers.Conv2D(128, (2, 2), strides=1, padding='valid', name='conv4')(x) x = layers.PReLU(shared_axes=[1, 2], name='prelu4')(x) # 3,3,128 -> 128,12,12 x = layers.Permute((3, 2, 1))(x) # 1152 -> 256 x = layers.Flatten()(x) x = layers.Dense(256, name='conv5') (x) x = layers.PReLU(name='prelu5')(x) # 鉴别 # 256 -> 2 256 -> 4 256 -> 10 classifier = layers.Dense(2, activation='softmax', name='conv6-1')(x) bbox_regress = layers.Dense(4, name='conv6-2')(x) landmark_regress = layers.Dense(10, name='conv6-3')(x) model = models.Model([input], [classifier, bbox_regress, landmark_regress]) print(model.summary()) return model def call(self, x): self.get_message(x) img = self._norm(x) imgs = self._get_net_need_imgs(self.rnet_got_rects, img) outs = self.model.predict(imgs) boundingbox = self._get_boundingbox(outs, self.rnet_got_rects) rectangles = self._rect2square(boundingbox) boundingbox = self._trimming_frame(rectangles, img.shape[0], img.shape[1]) landmark = self._get_landmark(outs, self.rnet_got_rects) self.fix_rects(boundingbox) self.to_save_face(boundingbox, x, self.save_dirt) return boundingbox, landmark if __name__ == '__main__': pnet = P_Net('../weight_path/pnet.h5', 0.5, 0.7) img = cv2.imread("/Users/admin/Documents/2123.png") imgp = img.copy() print(img.shape) p_out = pnet(imgp) rnet = R_Net('../weight_path/rnet.h5', 0.6, 0.7, p_out) imgr = img.copy() r_out = rnet(imgr) onet = O_Net('../weight_path/onet.h5', 0.7, r_out, '../output') imgo = img.copy() print(onet(imgo))
运行结果
Model: "model_2"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_3 (InputLayer) [(None, 48, 48, 3)] 0
__________________________________________________________________________________________________
conv1 (Conv2D) (None, 46, 46, 32) 896 input_3[0][0]
__________________________________________________________________________________________________
prelu1 (PReLU) (None, 46, 46, 32) 32 conv1[0][0]
__________________________________________________________________________________________________
max_pooling2d_3 (MaxPooling2D) (None, 23, 23, 32) 0 prelu1[0][0]
__________________________________________________________________________________________________
conv2 (Conv2D) (None, 21, 21, 64) 18496 max_pooling2d_3[0][0]
__________________________________________________________________________________________________
prelu2 (PReLU) (None, 21, 21, 64) 64 conv2[0][0]
__________________________________________________________________________________________________
max_pooling2d_4 (MaxPooling2D) (None, 10, 10, 64) 0 prelu2[0][0]
__________________________________________________________________________________________________
conv3 (Conv2D) (None, 8, 8, 64) 36928 max_pooling2d_4[0][0]
__________________________________________________________________________________________________
prelu3 (PReLU) (None, 8, 8, 64) 64 conv3[0][0]
__________________________________________________________________________________________________
max_pooling2d_5 (MaxPooling2D) (None, 4, 4, 64) 0 prelu3[0][0]
__________________________________________________________________________________________________
conv4 (Conv2D) (None, 3, 3, 128) 32896 max_pooling2d_5[0][0]
__________________________________________________________________________________________________
prelu4 (PReLU) (None, 3, 3, 128) 128 conv4[0][0]
__________________________________________________________________________________________________
permute_1 (Permute) (None, 128, 3, 3) 0 prelu4[0][0]
__________________________________________________________________________________________________
flatten_1 (Flatten) (None, 1152) 0 permute_1[0][0]
__________________________________________________________________________________________________
conv5 (Dense) (None, 256) 295168 flatten_1[0][0]
__________________________________________________________________________________________________
prelu5 (PReLU) (None, 256) 256 conv5[0][0]
__________________________________________________________________________________________________
conv6-1 (Dense) (None, 2) 514 prelu5[0][0]
__________________________________________________________________________________________________
conv6-2 (Dense) (None, 4) 1028 prelu5[0][0]
__________________________________________________________________________________________________
conv6-3 (Dense) (None, 10) 2570 prelu5[0][0]
==================================================================================================
Total params: 389,040
Trainable params: 389,040
Non-trainable params: 0
__________________________________________________________________________________________________
None
成功保存人脸到../output/2022-03-12 08:32:254.123246.jpg
**********
(array([[1.80000000e+02, 3.42000000e+02, 9.18000000e+02, 1.08000000e+03,
9.91783977e-01]]), (array([[24.401913, 35.82986 ]], dtype=float32), array([[37.303265, 35.25456 ]], dtype=float32), array([[30.276049, 43.805367]], dtype=float32), array([[25.850449, 51.50006 ]], dtype=float32), array([[35.98294, 51.31109]], dtype=float32)))保存的图片效果如下

现在我们来看一下O-Net的整体流程,获取一张图片,先通过P-Net的整体流程,再通过R-Net的整体流程。同样这张图片,在O-Net的过程中,先获取宽高的最大值除以原宽高,得到宽高的比例。再resize到80*80,然后在Resize后的图片中裁剪出所有R-Net中输出的bounding box的范围的一系列图片,再将裁减后的所有的图片resize到48*48,再将所有的图片送入到O-Net的卷积神级网络中返回像素级别的粗分类和bounding box的坐标偏移以及5点人脸关键点的坐标偏移。挑选出大于阈值的分类和bounding box坐标,再将bounding box的框转成正方形。再将转成正方形的bounding box进行原图像大小范围的限制。挑选出大于阈值的分类和5点人脸关键点坐标。通过之前得到的宽高比例将bounding box还原到原图的范围,对原图进行裁剪并保存到硬盘中。最后对bounding box(带分类概率)以及人脸关键点坐标进行输出。