研究英语把上次看的文献写的报告翻成英文,当文摘吧
目录
Video Preprocessing and Filtering
Photometric Stereo and 3D Reconstruction
Against Printed Photograph Attack
FaceRevelio compared to existing face liveness detection methods
Abstract
Nowadays, traditional 2D face recognition technologies are vulnerable to various spoofing attacks. With the smartphone industry’s desire to maximize screen space, a new liveness detection system, FaceRevelio, was designed for commodity smartphones with a single front camera. It uses photometric stereo, light passcode and so on. It illuminates faces from multiple directions, and captures the facial images under varying illumination. Via photometric stereo we can recover the face surface normal. Then it can be integrated into a 3D shape. FaceRevelio with 30 users trying to authenticate under various lighting conditions and with a series of 2D spoofing attacks. The results show that using a passcode of 1s, FaceRevelio achieves a mean EER of 1.4% and 0.15% against photo and video attacks, respectively.
Introduction
Recently, some smartphone manufacturers have introduced liveness detection features to some of their high-end products, e.g. iPhone X/XR/XS and HUAWEI Mate 20 Pro. These phones are embedded with specialized hardware components on their screens to detect the 3D structure of the user’s face. For example, Apple’s TrueDepth system [1] employs an infrared dot projector coupled with a dedicated infrared camera beside its traditional front camera. For example, Samsung recently launched S10 as its first phone with face authentication and an Infinity-O hole-punch display. However, S10’s lack of any specialized hardware for capturing facial depth, made it an easy target for 2D photo or video attacks [2]. Therefore, in this paper we ask the following question: How can we enable liveness detection on smartphones only relying on a single front camera?
FaceRevelio recovers four stereo images of the face from the recorded video via a least squared method and uses these images to build a normal map of the face. Finally, the 3D model of the face is reconstructed from the normal map using a quadratic normal integration approach [3]. From this reconstructed model, they analyze how the depth changes across a human face compared to model reconstructed from a photograph or video and train a deep neural network to detect various spoofing attacks. To secure our system from replay attacks, the term designed the novel idea of a light passcode, which is a random combination of patterns in which the screen intensity changes during the process of authentication, such that an attacker would be unable to correctly guess the random passcode. As shown in
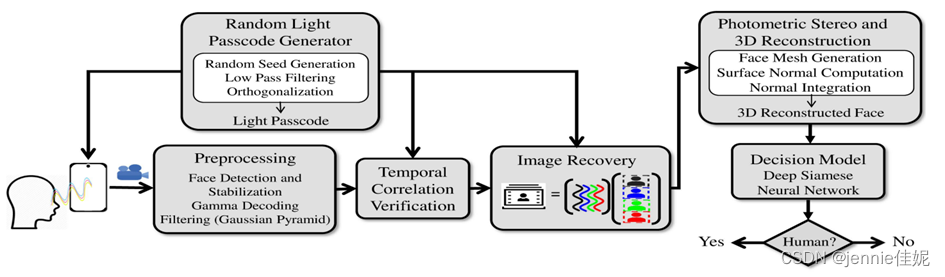
Figure 1 system overview
BACKGROUND
photometric stereo: A technique for recovering the 3D surface via varying lighting conditions on the same object.
Given three point light sources under known lighting conditions, the surface normal vectors S can be computed:
where I=I1,I2,I3 is the stacked three stereo images exposed to different illumination, and L=L1,L2,L3 is the lighting direction.
When the lighting conditions are unknown, the matrix of intensity is M, which is of size m×n where m is the number of images and n is the number of pixels in each image.
We use Singular Value Decomposition (SVD) [38] for solving this approximation.
FACEREVELIO SYSTEM DESIGN
Light Passcode Generator
They divide the screen into four quarters where each quarter is assumed a light source. During the video recording, each of these quarters is illuminated alternately, while the other three quarters are dark. As shown in Figure 2.

Figure 2 An example of 3D reconstruction using four basics
Random Passcode Generator: It is prone to replay attack. We can change the screen lighting randomly.
They apply an ideal low-pass filter with a frequency threshold of 3Hz. Although current smartphone screens support a refreshing rate of 60Hz, there is a delay when the screen is gradually updated that the intensity may not be consistent and make it uncomfortable for eyes. These filtered patterns are then normalized such that each pattern is zero-mean.
The recorded video has a mixture of reflections of the four lights. They introduce orthogonality via Gram-Schmidt [4] to ensure their independence. Figure 3 shows the FFT of these four patterns before and after the application of Gram-Schmidt process.
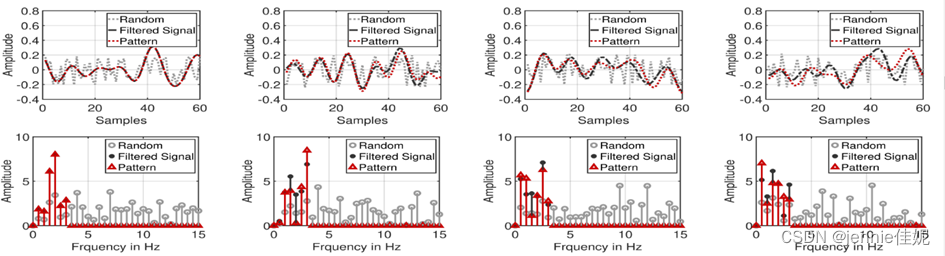
Figure 3 An example of a random passcode
They obtain four orthogonal zero mean light patterns, forming a passcode. Each value is multiplied with an amplitude of 60 and finally the passcode is added on top of a constant base pixel intensity value of 128.
Video Preprocessing and Filtering
They convert each frame from the color space to the HSV space [5]. Only the V component will be kept.
Image Recovery
G is a f×n matrix representing the light intensity values received on each pixel, where f is the number of frames and n is the number of pixels in one frame. W represents the f × 4 light patterns P1;P2;P3;P4. X (= I1;I2;I3;I4) is a n×4 matrix representing the four stereo images that we aim to recover.
In order to have a smoother camera response, we use the camera in manual mode, which smartphone camera APIs[1] started supporting recently.
Otherwise, cameras apply Gamma calibration on the raw camera sensor data. Gamma calibration is where non-linearity arises between the pixel values and the light intensity. In order to make use of linear relationship between these two, they apply an inverse of the gamma calibration to the recorded video frames. This relationship can be formulated as the linear model, y=kx+b. We get
where K is the video frames. By substituting the definition of G into Equation 5, we get
Finally, we use the least square method to solve
which can be written as
B is a constant matrix and since each of the four patterns in the passcode W are zero-mean, the term WTB will be eliminated. Hence Equation 8 becomes:
X will have an uncertainty of a scale factor. Let X'=αX, X'=αX. X ′, k ′ will also minimize the above function. After using SVD, the decompositions are
After set k = 1, we can solve for X ′ by
Considering the ambient light present as well as the base intensity value of the screen, Equation 5 now becomes
C is the constant light present. Because of the orthogonal and zero-mean, W, WTC will become 0.
To ensure that we fine alignment between these two, we first compute the average brightness of each frame and then apply a low pass filter on the average brightness. The peaks and valleys in the average brightness are matched with those of the passcode and finally, DTW [6] is used to align. These video frames are then given as input to Equation 12 to get X.
The top 4 images in Figure 4 are the recovered stereo images. The bottom images are the binary representation. If the pixel is larger than the mean value of the same pixel in the other three images, a pixel value will be 1. It is just to emphasize how different these images are and that they are illuminated from lighting in four different directions.

Figure 4 The recovered stereo images
Photometric Stereo and 3D Reconstruction

They use a generalized template, Nt, to solve for A without any ambiguity. They also have a 2D wired triangulated mesh, Mt, connecting the facial landmarks (vertices), for this template. A representation of this mesh can be seen in Figure 5(left).
Finally, we should make the normal map symmetric. This is needed to reduce noise in the recovered stereo images and hence the surface normals. We find the center axis through the face contour, nose tip and mouth and adjust eyes, eyebrow corner etc. to get a symmetric mesh. As shown in Figure 5(right).

Figure 5 Normal map calculation
After recovering the surface normals, we use the quadratic normal integration to reconstruct the 3D surface. The results are shown in Figure 6. Side and top view are shown for each model.

Figure 6 Examples of 3D reconstruction from human faces.
Liveness Detection
This system is against 2D printed photograph attack and video replay.
2D Printed Photograph Attack
Photograph lacks depth details in facial features, e.g. nose, mouth and eyes, as is clear in the examples in Figure 7.

Figure 7 Examples of 3D reconstruction
They train a Siamese neural to classify it as a human face or a spoofing attempt. The Siamese network consists of two parallel neural networks whose architecture is the same, however, their inputs are different. One takes in a depth map of a human face while the other is given the candidate depth map. Both output a feature vector and then compared. Figure 8 shows the architecture of the Siamese network.

Figure 8 Architecture of the Siamese neural network.
Suppose we have N depth maps collected from human subjects and N depth maps. We obtain N(N-1)/2 pairs of positive samples where both the depth maps are from human and N2 pairs where one is of a human while the other is from a photo/video. We randomly select samples from the negative pairs.
Since Siamese network uses the concept of one-shot learning [7] and takes pairs as input for training, the amount of data required for training is much smaller than traditional convolutional neural networks.
If we train the model with the raw images/videos, it will be influenced by the ambient lighting and data is more, resulting in higher storage and computation costs.
Video Replay Attacks
The first line of defense is to utilize the randomness of the passcode.
The average brightness of the video frames across time has a high correlation with the passport. Figure 9(right) shows the percentage of passcode with a correlation higher than threshold values 0.84, 0.85 and 0.86 for passcode lengths of 1, 2 and 3s. The correlation between the two passcodes is higher than 0.85 for more than 99.9% of the cases. For a passcode duration of 3s, only 0.0003% of the pairs will have a correlation greater than 0.84.

Figure 9 Video Replay Attack: (left) shows the distribution of correlation between recorded passcodes from human face and the original passcode. (right) shows the percentage of passcodes which have a correlation with another random passcode higher than a threshold for different thresholds.
The second line of defense is using the reconstructed 3D model.
First, it is hard to accurately synchronize playing the attack video with the start. Second, differences in the replayed passcode will cause that the X obtained by solving equation 12 do not capture the 3D features of the face.
Performance Results
Overall Performance
Against Printed Photograph Attack
Figure 10 shows the ROC curve for detecting photo attack in dark and daylight setting with a passcode of 1s.
For dark setting, with a true accept rate of 98%, the false accept rate is only 0.33%. This means that a photo attack is detected with an accuracy of 99.7% when the real user is rejected in 2% of the trials. The EER for the dark setting is 1.4%.
In daylight, the photo attack is detected with an accuracy of 99.3% when the true accept rate is 97.7%. The EER in this case is also 1.4%.
FaceRevelio performs better in dark, and the signal-to-noise ratio is higher, resulting in a better 3D reconstruction.
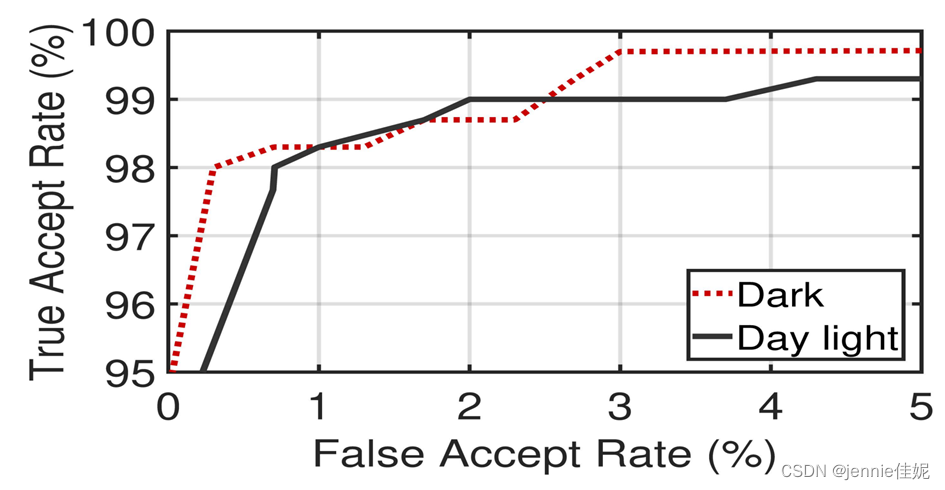
Figure 10 ROC curve for detecting photo attack
Against Video Replay Attacks
The video was played on a Lenovo Thinkpad laptop, with a screen resolution of 1920 x 1080. The system detected an EER of 0% in dark and 0.3% in daylight settings. Figure 11 shows a histogram of the correlation between the passcode displayed on the phone and the camera response with 1s long passcode. The correlation is all less than 0.9. And 99.8% of the videos from real human users have a correlation higher than 0.9.
Figure 11 Distribution of the correlation between the pass code on the phone and the camera response from real human and video attack combined for dark and daylight setting.
Total Time
Figure 12 shows the processing time of the different modules of the system. The liveness detection process only takes 0.13s in total. The stereo images recovery only takes 3.6ms. The most expensive computation step is the normal map computation, taking 56ms, since it involves two 2D warping transformations. 3D reconstruction and feature extraction and comparison via the Siamese network take 38.1 and 35.4 ms respectively.
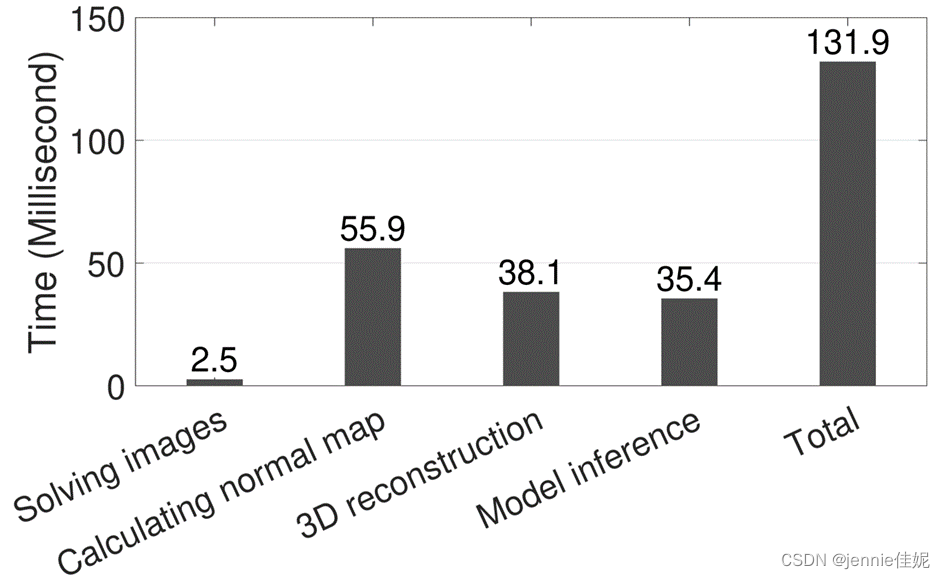
Figure 12 Processing time of the different modules of the system for a passcode of 1s duration.
FaceRevelio compared to existing face liveness detection methods
Table 1 gives an overview of the existing methods for face liveness detection on smartphones. It shows the type of attacks these methods can defend against and if they require any extra hardware or user interaction for doing so. Among the commercial solutions, Samsung’s face recognition is vulnerable to simple 2D photo attacks and needs to be combined with other authentication methods [8]. Apple’s FaceID [1] is the most secure method against 2D and 3D spoofing attacks, owing to the TrueDepth camera [1] system. Among liveness detection methods that do not rely on any extra specialized hardware [9][10][11][12], FaceRevelio achieves the highest accuracy in detecting 2D photo and video attacks with the fastest response time of 1s. Tang et al. [12] use a challenge-response protocol to achieve a high detection accuracy, however, their approach relies on the user to make facial expressions as instructed and takes 6s or more. In contrast, FaceRevelio detects the spoofing attempts in 1s, without requiring any user interaction. Another important comparison metric is the performance variation in different lighting conditions. EchoFace [13] achieves a good accuracy however their sound (owing to smartphones’ speaker limitation [14]) makes it less user friendly.
| Algorithm |
Attack Resistance |
Special Hardware? |
User Interaction Required? |
Limitation |
Accuracy |
| FaceID [1] |
2D & 3D |
TrueDepth |
No |
3D head mask attack |
> 99.9% |
| Samsung FR [8] |
None |
No |
No |
Photo Attack |
- |
| EchoFace [13] |
2D photo |
No |
No |
Audible sound |
96% |
| FaceCloseup [11] |
2D photo/video |
No |
Requires moving the phone |
Slow response |
99.48% |
| EchoPrint [17] |
2D photo/video |
No |
No |
Audible sound, low accuracy in low illumination |
93.75% |
| Face Flashing [12] |
2D photo/video |
No |
Requires expression |
Slow response |
98.8% |
| FaceHeart [16] |
2D photo/video |
No |
Place fingertip on back camera |
Low accuracy in low illumination |
EER 5.98% |
| FaceLive [10] |
2D photo/video |
No |
Requires moving the phone |
Slow, low accuracy in low illumination |
EER 4.7% |
| Patel et al. [18] |
2D photo/video |
No |
No |
Device dependent, low accuracy in low illumination |
96% |
| Chen et al. [15] |
2D photo/video |
No |
Requires moving the phone |
Slow response |
97% |
Table 1 Summary of existing face liveness detection methods
Conclusions
This paper proposes FaceRevelio, a face liveness detection system for smartphones with a single front camera. It aims to defend against spoofing attacks. We use the front camera of the smartphone to record a video of the user’s face. Then we reconstruct the 3D structure of the face and input it to a Siamese neural network model. It will declare the 3D face as a real human face if this score is above a threshold and detects a spoofing attack otherwise. Among this process, we will detect the 2D printed photograph attack and video replay attacks.
References
- [n. d.]. About Face ID advanced technology.
- [n. d.]. You should probably turn off the Galaxy S10’s face unlock if you value basic security.
- Yvain Quéau, Jean-Denis Durou, and Jean-François Aujol. 2017. Variational Methods for Normal Integration. CoRR abs/1709.05965 (2017). arXiv:1709.05965 http://arxiv.org/abs/1709.05965
- Kimberly A. Dukes. 2014. Gram–Schmidt Process. American Cancer Society.
- Max K Agoston. 2005. Computer Graphics and Geometric Modeling: Implementation and Algorithms. Springer London.
- Donald J Berndt and James Clifford. 1994. Using dynamic time warping to find patterns in time series.. In KDD workshop, Vol. 10. Seattle, WA, 359–370.
- Li Fei-Fei, Rob Fergus, and Pietro Perona. 2006. One-shot learning of object categories. IEEE transactions on pattern analysis and machine intelligence 28, 4 (2006), 594–611.
- [n. d.]. How does Face recognition work on Galaxy Note10, Galaxy Note10+, and Galaxy Fold?
- Y. Chen, J. Sun, X. Jin, T. Li, R. Zhang, and Y. Zhang. 2017. Your face your heart: Secure mobile face authentication with photoplethysmograms. In IEEE INFOCOM 2017 - IEEE Conference on Computer Communications. 1–9.
- Yan Li, Yingjiu Li, Qiang Yan, Hancong Kong, and Robert H Deng. 2015. Seeing your face is not enough: An inertial sensor-based liveness detection for face authentication. In Proceedings of the 22nd ACM SIGSAC Conference on Computer and Communications Security. ACM, 1558–1569.
- Yan Li, Zilong Wang, Yingjiu Li, Robert Deng, Binbin Chen, Weizhi Meng, and Hui Li. 2019. A Closer Look Tells More: A Facial Distortion Based Liveness Detection for Face Authentication. In Proceedings of the 2019 ACM Asia Conference on Computer and Communications Security (Asia CCS âĂŹ19). Association for Computing Machinery, New York, NY, USA, 241âĂŞ246.
- Di Tang, Zhe Zhou, Yinqian Zhang, and Kehuan Zhang. 2018. Face Flashing: a Secure Liveness Detection Protocol based on Light Reflections. arXiv preprint arXiv:1801.01949 (2018).
- H. Chen, W. Wang, J. Zhang, and Q. Zhang. 2020. EchoFace: Acoustic SensorBased Media Attack Detection for Face Authentication. IEEE Internet of Things Journal 7, 3 (March 2020), 2152–2159. EchoFace: Acoustic Sensor-Based Media Attack Detection for Face Authentication | IEEE Journals & Magazine | IEEE Xplore
- Patrick Lazik and Anthony Rowe. 2012. Indoor pseudo-ranging of mobile devices using ultrasonic chirps. In Proceedings of the 10th ACM Conference on Embedded Network Sensor Systems. 99–112.
- Shaxun Chen, Amit Pande, and Prasant Mohapatra. 2014. Sensor-assisted facial recognition: an enhanced biometric authentication system for smartphones. In Proceedings of the 12th annual international conference on Mobile systems, applications, and services. ACM, 109–122.
- Y. Chen, J. Sun, X. Jin, T. Li, R. Zhang, and Y. Zhang. 2017. Your face your heart: Secure mobile face authentication with photoplethysmograms. In IEEE INFOCOM 2017 - IEEE Conference on Computer Communications. 1–9.
- Bing Zhou, Jay Lohokare, Ruipeng Gao, and Fan Ye. 2018. EchoPrint: Two-factor Authentication using Acoustics and Vision on Smartphones. In Proceedings of the 24th Annual International Conference on Mobile Computing and Networking. ACM, 321–336.
- Keyurkumar Patel, Hu Han, and Anil K Jain. 2016. Secure face unlock: Spoof detection on smartphones. IEEE Transactions on Information Forensics and Security 11, 10 (2016), 2268–2283.
[1] Android supports manual camera mode starting from Android Lollipop 5.1