1.下载地址:这里下载的是spark-2.0.1-bin-hadoop2.7.tgz ,别的版本可以自行选择
https://archive.apache.org/dist/spark/spark-2.0.1/

前提:Linux需配置jdk环境,比较简单,自行百度
Local模式的使用
1.解压:
tar -xvf spark-2.0.1-bin-hadoop2.7.tgz
2.编辑文件
//进入zookeeper目录下的conf目录下
cd /home/software/spark-2.0.1-bin-hadoop2.7/conf
mv spark-env.sh.template spark-env.sh
vim spark-env.sh
修改:
SPARK_LOCAL_IP=本机ip地址(或者主机名)
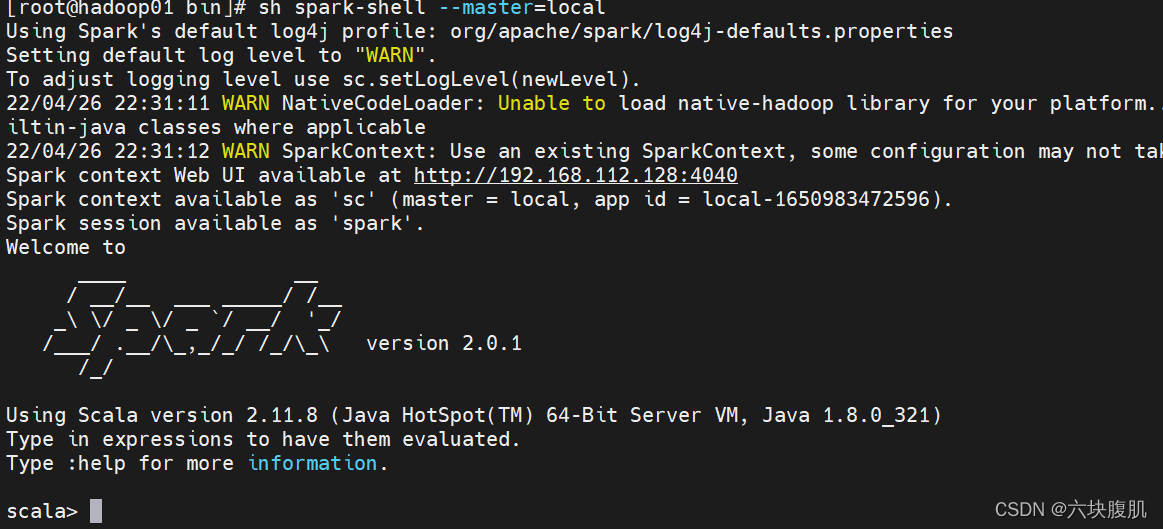
3.进入spark命令行
cd …/bin
sh spark-shell --master=local
4.单机下的页面查看
Spark的集群模式的配置和使用
1.编辑配置文件文件spark-env.sh
cd /home/software/spark-2.0.1-bin-hadoop2.7/conf
vim spark-env.sh
添加:
SPARK_LOCAL_IP=hadoop01
#shuffle产生临时文件的地方
SPARK_LOCAL_DIRS=/home/software/spark-2.0.1-bin-hadoop2.7/tmp
export JAVA_HOME=/home/software/jdk1.8.0_321
2.编辑配置文件文件slaves
mv slaves.template slaves
vim slaves
添加worker的主机名:(需要在vim /etc/hosts配置ip对应主机名)
hadoop01
hadoop02
hadoop03
3.拷贝至两外两台主机
返回到software目录下
cd /home/software
scp -r zookeeper-3.6.3 root@hadoop02:/home/software/
scp -r zookeeper-3.6.3 root@hadoop03:/home/software/
4.修改另外两台主机的配置文件的主机名
cd /home/software/spark-2.0.1-bin-hadoop2.7/conf
vim spark-env.sh
SPARK_LOCAL_IP=第二台和第三台自己的主机名
5.启动
cd /home/software/spark-2.0.1-bin-hadoop2.7/sbin
sh start-all.sh

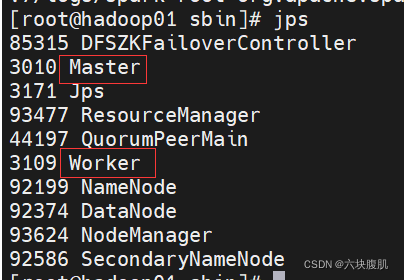
记录了启动机器和角色,注意在哪台机器起的集群哪个主机就是Master
6.jps查看进程
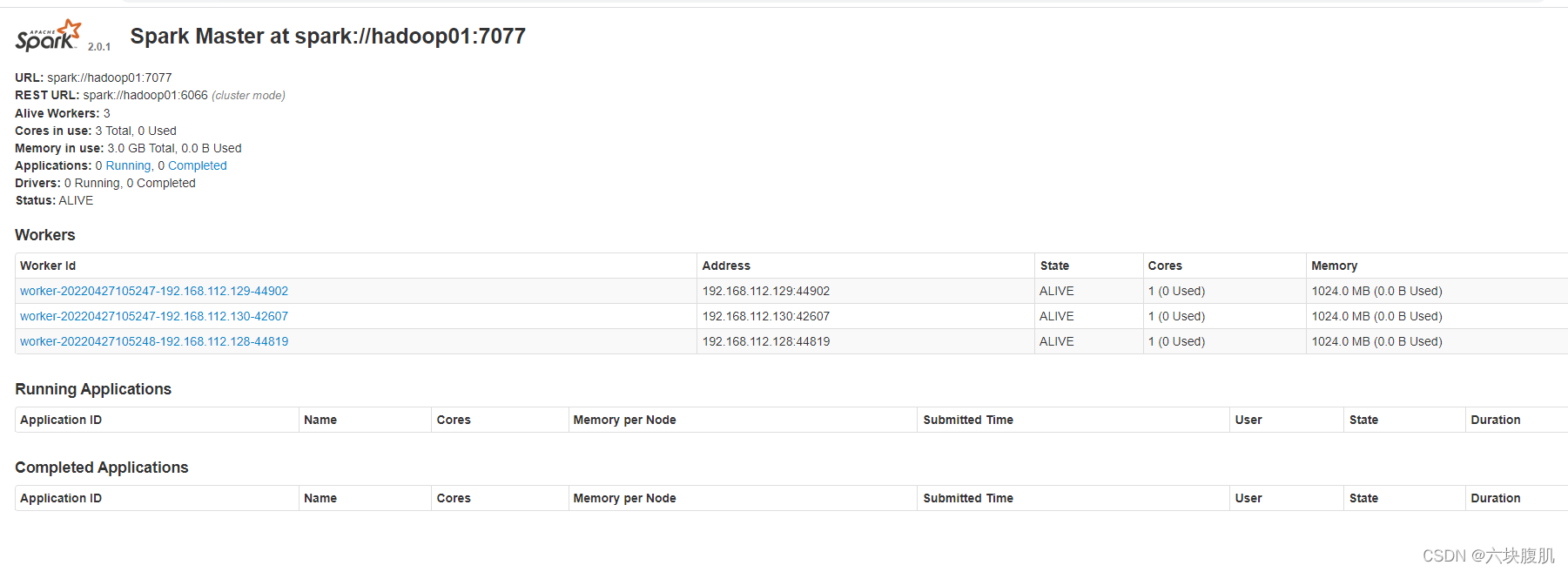
7.页面查看
hadoop01:8080(hadoop01是master所在主机的ip地址)
8.停止集群
sh stop-all.sh
测试集群:
1.进入客户端
/home/software/spark-2.0.1-bin-hadoop2.7/bin
sh spark-shell --master spark://hadoop01:7077
2.启动hdfs服务,上传1.txt文件至/text目录下
1.txt的内容
hello world
hello hadoop scala
haddop scala
hdfs dfs -put 1.txt /text/
3.在客户端一次输入指令
val data=sc.textFile("hdfs://hadoop01:9000/text/1.txt",3)
val wc=data.flatMap{
_.split(" ")}.map{
(_,1)}.reduceByKey{
_+_}
wc.collect
最终结果:
