表现SOTA!并提出局部-全局训练策略(LoGo),进一步提高性能,优于Res-UNet、U-Net++等网络,代码刚刚开源!
Medical Transformer: Gated Axial-Attention for Medical Image Segmentation

- 作者单位:JHU, 新泽西州立大学
- 代码:https://github.com/jeya-maria-jose/Medical-Transformer
- 论文下载链接:https://arxiv.org/abs/2102.10662
在过去的十年中,深度卷积神经网络已被广泛用于医学图像分割,并显示出足够的性能。

但是,由于卷积架构中存在固有的inductive biases,因此他们对图像中的远程依存关系缺乏了解。最近提出的利用自注意力机制的基于Transformer的体系结构对远程依赖项进行编码,并学习高度表达的表示形式。
这促使我们探索基于Transformer的解决方案,并研究将基于Transformer的网络体系结构用于医学图像分割任务的可行性。提出用于视觉应用的大多数现有的基于Transformer的网络体系结构都需要大规模的数据集才能正确地进行训练。但是,与用于视觉应用的数据集相比,对于医学成像而言,数据样本的数量相对较少,从而难以有效地训练用于医学应用的Transformer。
为此,我们提出了Gated Axial-Attention模型,通过在自注意力模块中引入附加的控制机制来扩展现有体系结构。此外,为了有效地在医学图像上训练模型,我们提出了局部-全局训练策略(LoGo),可以进一步提高性能。具体来说,我们对整个图像和patch进行操作以分别学习全局和局部特征。
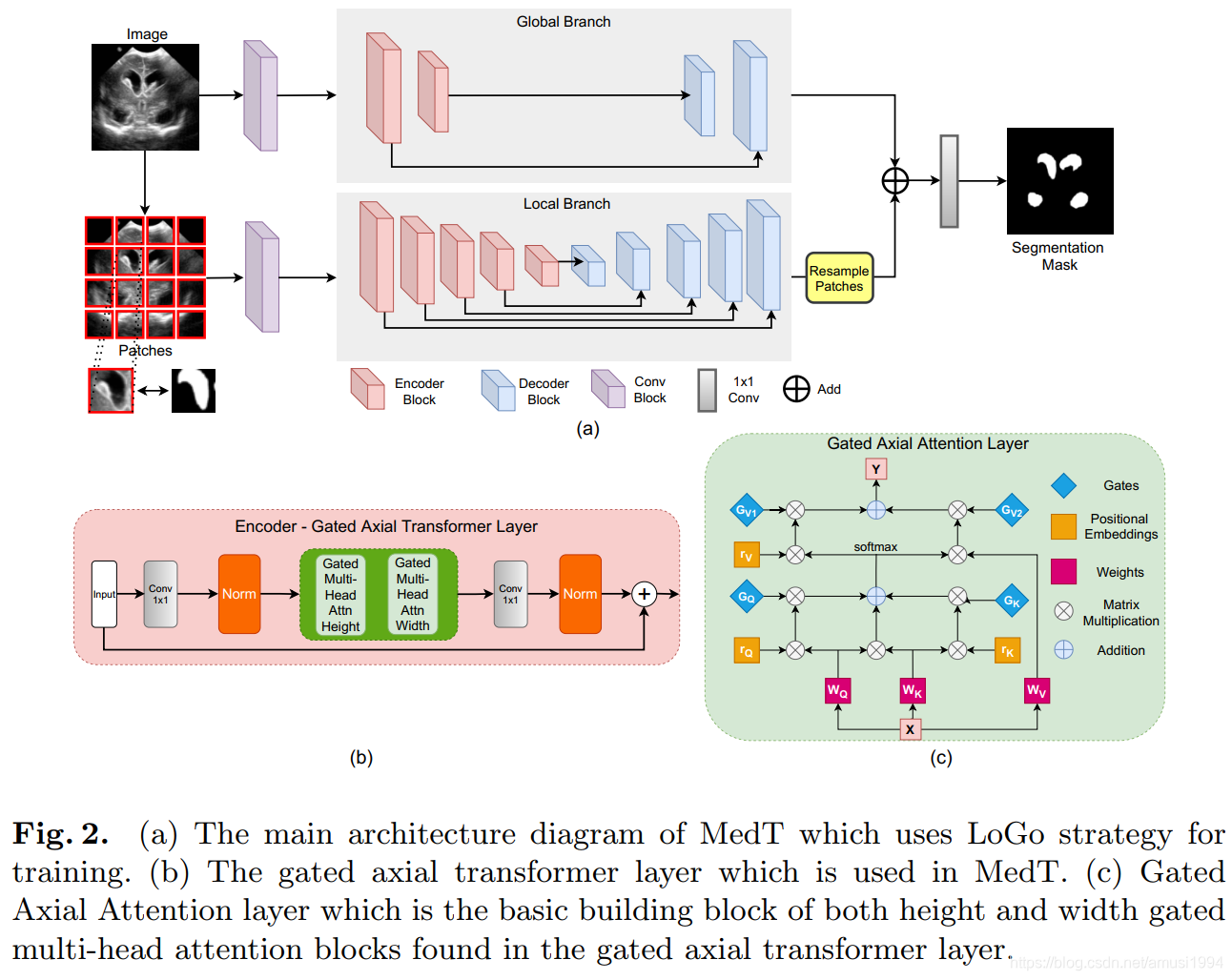




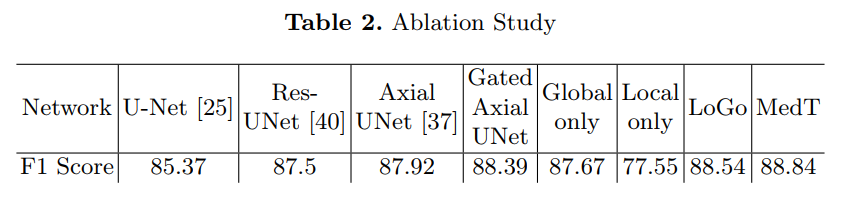
实验结果
在三个不同的医学图像分割数据集上对提出的Medical Transformer(MedT)进行了评估,结果表明,与基于卷积和其他基于transformer的其他架构相比,它具有更好的性能。




CVer-Transformer交流群
建了CVer-Transformer交流群!想要进Transformer学习交流群的同学,可以直接加微信号:CVer9999。加的时候备注一下:Transformer+学校+昵称,即可。然后就可以拉你进群了。
