文章目录
写在前面:研一的机器学习课程需要针对UCI的一个数据集进行分析。所以就有了这篇文章。也是第一次好好学习机器学习了。
[P5]
1 前期准备
本次实验基于spyder,python3.7,数据集 heart.csv
1.1 安装数据分析+可视化第三方工具包
- 首先打开
anaconda prompt,然后输入下面一行代码即可。
pip install numpy pandas matplotlib seaborn wheel pandas_profiling jupyter notebook -i https://pypi.tuna.tsinghua.edu.cn/simple
- 介绍一下每一个库
- Numpy:是python语言的一个扩展程序库;支持大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库。
- pandas:是python语言的一个扩展程序库;用于数据分析;可以从各种格式文献比如CSV、JSON、SQL、Microsoft Excel导入数据。
- matploylib:是python在绘图领域最常用的套件。它能让使用者很轻松地将数据图形化,并且提供多样化的输出格式。
- seaborn:是基于matplotlib的图形可视化python包。它可以让用户能够做出各种有吸引力的统计图表。
- wheel:取代了之前的打包格式.egg文件。
- 最后是清华大学的镜像网站,是为了加速下载的。
https://pypi.tuna.tsinghua.edu.cn/simple
1.2 安装辅助工具包
pip install graphviz pydotplus -i https://pypi.tuna.tsighua.edu.cn/simple
将graphviz的bin目录加在环境变量PATH中。
1.3 安装机器学习第三方工具包
pip install scikit-learn -i https://pypi.tunasinghua.edu.cn/simple
1.4 安装机器学习可解释性第三方工具包
pip install pdpbox eli5 -i https://pypi.tunasinghua.edu.cn/simple
2 对于数据集进行导入、查看及简单分析
2.1 代码及注释
import pandas as pd
df = pd.read_csv("heart.csv")
print(df.head())
import pandas as pd
# 导入pandas库,用于读取数据
df = pd.read_csv("heart.csv")
# read_csv函数,可以读取csv文件,括号内的csv文件是在当前.py文件同一目录下
print(df.head())
# df.head() 输出前5行的数据
# df.tail() 输出最后5行的数据
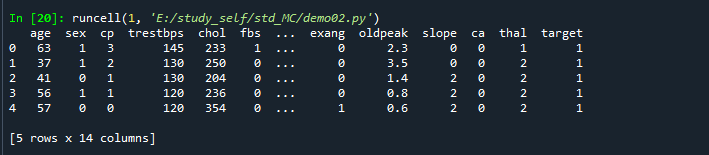
下面是输出结果:
2.2 简单分析属性的相关系数关系
corr()方法:返回数据类型的相关系数矩阵(每两个类型之间的相关性)
# data是一个DataFrame类型的数据
data.corr() #相关系数矩阵,即给出了任意两个变量之间的相关系数
data.corr()[u’好’] #只显示“好”与其他感情色彩的相关系数
data[u’好’].corr(data[u’哭’]) #两个感情色彩的相关系数