资源下载地址:https://download.csdn.net/download/sheziqiong/85824219
资源下载地址:https://download.csdn.net/download/sheziqiong/85824219
1. 原理及实现
1.1. 模块 1 Harris 角点检测
原理简介:
Harris 角点检测算子是于 1988 年由 Chris Harris & Mike Stephens 提出来的角点检测方法,实质上是对 Moravec 算子的改良和优化。算法基本思想是使用一个固定窗口在图像上进行任意方向上的滑动,比较滑动前与滑动后窗口中的像素灰度变化程度,如果存在任意方向上的滑动,都有着较大灰度变化,那么我们可以认为该窗口中存在角点。
当窗口发生移动时,滑动前与滑动后对应的窗口中的像素点灰度变化描述如下:
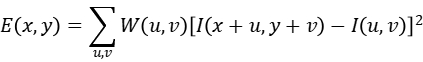
即:
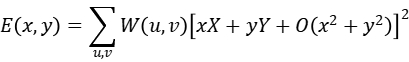
其中:
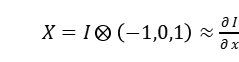
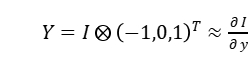
所以 E 可表示为:
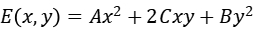
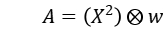
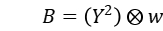
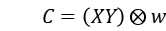
由于采用了正方形窗口,E 的响应比较容易受到干扰,所以要对 E 做一次高斯平滑增加抗噪能力。接着将 E 变为二次型:

然后 Harris 定义了一个角点响应函数:
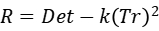
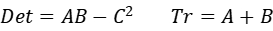
至此,可以求得每个点的角点响应值。然后用阈值过滤掉一部分的角点,再用非极大值抑制进行细化,即可得到图像的角点。
函数实现:
harris_corners.m
输入:
image:需要检测角点的(HW3)图像。
window_size:检测窗口的大小。
k:角点响应方程参数。
border:我们对图像边界上的角点并不感兴趣,忽略边界的角点。
输出:
corners:检测出的角点结果。(H*W)的 0/1 值图像,认为是角点处的值置为 1,不是的置为 0。
步骤:
- 将 RGB 图像转化为灰度图;
- 计算图像
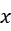 方向和
方向和 方向的梯度值;
方向的梯度值; - 计算角点响应函数中的 A、B、C(梯度乘积结果),并对得到的结果做一次高斯平滑增加抗噪能力;
- 根据角点响应函数计算每个像素点的角点响应值;
- 找出图像的最大响应值
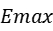 ,将阈值设为
,将阈值设为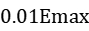 ,根据阈值过滤角点;
,根据阈值过滤角点; - 非极大值抑制;
- 剔除边界上的无效角点;
8.输出结果。
具体实现请见 Matlab 代码及代码注释。
当检测窗口大小取 3*3,参数 k 取 0.04,边界 border 取 10 像素时,对于图像 sudoku.png 能检测出 1249 个角点,耗时大约在 0.3-0.5 秒之间,如图所示。

1.2. 模块 2 关键点的描述及其匹配
1.2.1. 生成描述向量
原理简介:
利用 Harris 角点检测算法定位两张图片中的关键点后,接下来需要对检测到的关键点进行匹配,确定好两张图片中哪些点是一一对应的。这就需要先对关键点进行描述。一个简单的方法是,选取关键点周围的一个固定区域(patch),并利用该区域的信息生成一组描述向量(descriptors)。由于用于测试的两张实例比较简单,可以直接用像素值当描述向量(即展开成一维向量)。为了增加光照稳定性,需要将这个向量进行标准正态化。
函数实现:
describe_keypoints.m
simple_descriptor.m
describe_keypoints.m 输入:
image:(HW3)图像,用于提取 patch 中的像素值,生成描述向量。
corners:(H*W)图像,Harris 角点检测函数 harris_corners( )检测出的角点图。
patch_size:patch 的大小(patch_size*patch_size)。
describe_keypoints.m 输出:
keypoints:(m*2)矩阵,行数为角点索引,即第 i 行存储的内容(x,y)就是第 i 个角点在原图中的 x 坐标和 y 坐标。
descriptors:m*(patch_sizepatch_size)矩阵,行数为角点索引,即第 i 行存储的(1(patch_size*patch_size))数列就是第 i 个角点的描述子。
simple_descriptor.m
输入:
patch:(patch_size*patch_size)矩阵。
simple_descriptor.m
输出:
out:(1*(patch_size*patch_size))向量,展开后的标准正态化 patch。
步骤:
- 将 RGB 图像转化为灰度图;
- 得出角点图 corners 中角点在原图中的坐标;
- 计算每个角点的特征向量 v;
4.输出描述子矩阵 descriptors。
具体实现请见 Matlab 代码及代码注释。
当检测窗口大小取 3*3,参数 k 取 0.04,边界 border 取 20 时,img1 和 img2 的 Harris 角点检测结果如图所示:

img1 能检出 1440 个角点,img2 能检出 1585 个角点,当 patch_size 取 16 时,每个角点拥有一个 1256 的描述子,img1 像素值特征描述 descriptors1 为(1440256)矩阵,img2 像素值特征描述 descriptors1 为(1585*256)矩阵,耗时大约在 0.05-0.1 秒之间。
1.2.2. 匹配描述子
原理简介:
得到了 descriptors1(1440256),descriptors2(1585256)后,需要根据这些描述子将角点进行匹配,即计算向量的相似性。向量相似性有多种方法进行度量,如欧氏距离,曼哈顿距离,切比雪夫距离等,这里的匹配策略可以使用特征向量的欧氏距离来作为两幅图像中关键点的相似性判定度量。
主要方法是:取 img1 中的某个关键点,并找出其与 img2 中欧氏距离最近的前两个关键点,在这两个关键点中,如果最近的距离除以次近的距离少于某个比例阈值,则接收这一对匹配点。
函数实现:
match_descriptors.m
输入:
descriptors1:m*d 描述子矩阵。
descriptors2:n*d 描述子矩阵。
k:比例阈值。
输出:
count:匹配上的角点对数。
matched_points:(count*2)矩阵,保存匹配上的角点的坐标。
步骤:
- 计算欧式距离矩阵 dist。dist 是一个(m*n)的矩阵,保存了任意两个角点之间的欧氏距离;
- 判断角点是否匹配。首先在 descriptors1 中取一个角点 i 的描述子,然后对于 descriptors1 中的角点 i,找出 descriptors2 中与它欧氏距离最小的两个角点 j1 和 j2,记(i,j1)的欧氏距离为 dist_min1,记(i,j2)的欧氏距离为 dist_min2,计算 dist_min1 和 dist_min2 的比值 q,然后根据阈值 k 判断(i,j1)是否是一对被接受匹配的角点——如果比值 q 小于阈值 k,则接收这一对匹配点;
- 输出 matched_points 和匹配点对数 count;
具体实现请见 Matlab 代码及代码注释。当比例阈值 k 取 0.8(论文给的参数)时,在 img1 和 img2 中能匹配 327 对点,如图所示:

调整参数可以发现,降低比例阈值,匹配点数目会减少,但更加稳定。当把 k 调整为 0.7 时(PPT 老师给的参数),在 img1 和 img2 中能匹配 239 对点,匹配效果更好,如图所示:

k=0.8

k=0.7
1.3. 模块 3 转换矩阵的估计
原理简介:
经过匹配函数的计算,可以得到一组匹配点的对应坐标。仿射变换(Affine Transformation)是一种二维坐标到二维坐标之间的线性变换,保持二维图形的“平直性”和“平行性”,可以描述图像的平移、旋转、缩放效果。
设 img1 和 img2 中的一对匹配点为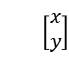 和
和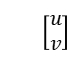 ,即需要计算一个矩阵
,即需要计算一个矩阵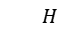 使
使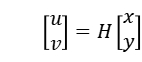 ,仿射变换可以由多个基础平移、旋转、缩放矩阵复合而成,即
,仿射变换可以由多个基础平移、旋转、缩放矩阵复合而成,即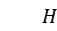 的计算又可以写成:
的计算又可以写成:
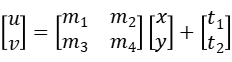
对每个点的残差可以定义为:
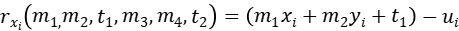
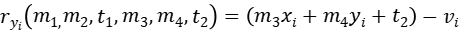
损失函数可以定义为:
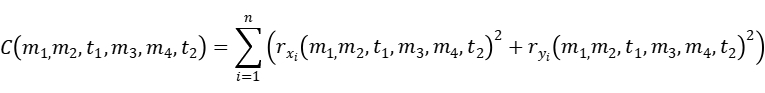
可以将仿射变换写成矩阵形式:
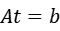
即

然后可以根据最小二乘法方程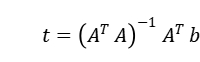 拟合出所需要的仿射变换矩阵。(这里用的是论文上的排列方式,在 PPT 上
拟合出所需要的仿射变换矩阵。(这里用的是论文上的排列方式,在 PPT 上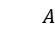 、
、 矩阵有另一种排列方式,计算结果是相同的。)
矩阵有另一种排列方式,计算结果是相同的。)
函数实现:
fit_affine_matrix.m
输入:
x、y、u、v:角点坐标集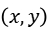 ,角点坐标集
,角点坐标集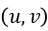 。
。
输出:
H:拟合的仿射变换矩阵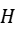 。
。
步骤:
- 根据最小二乘法公式
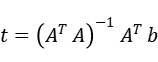 构造出对应的矩阵
构造出对应的矩阵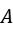 和
和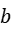 ,计算结果,
,计算结果,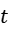 即为仿射变换矩阵
即为仿射变换矩阵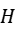 ;
; - 有时候由于噪声影响会使得最后一列不是精确的
 ,此时可以手动将它置为
,此时可以手动将它置为 ;
; - 输出仿射变换矩阵 H。
需要注意的是,(x,y)应输入 img2 中匹配点的坐标,(u,v)应输入 img1 中匹配点的坐标,否则拟合出来的是 img1 变换成 img2 的变换矩阵。
具体实现请见 Matlab 代码及代码注释。
为了使后文的 RANSAC 算法效果看起来更明显,这里的变换矩阵是用比例阈值 k 取 0.8 时匹配出来的角点所拟合的。此时图像变换以及拼接结果如图所示:


1.4. 模块 4 RANSAC
原理简介:
直接求解仿射变换矩阵的结果并不是很理想,这是因为在确定对应点时,我们的限制条件并不算精确,导致引入了许多无效数据。我们可以利用 RANSAC 方法来进一步对数据进行筛选,求解变换矩阵。
RANSAC 是“RANdom SAmple Consensus(随机抽样一致)”的缩写。它可以从一组包含“外点”的观测数据集中,通过迭代方式估计数学模型的参数。它是一种不确定的算法——它有一定的概率得出一个合理的结果;为了提高概率必须提高迭代次数。
这里滤除误匹配对采用 RANSAC 算法寻找一个最佳变换矩阵 H,矩阵大小为 3×3。RANSAC 目的是找到最优的参数矩阵使得满足该矩阵的数据点个数最多。由于仿射变换矩阵有 6 个未知参数,至少需要 6 个线性方程求解,对应到点位置信息上,一组点对可以列出两个方程,则至少包含 3 组匹配点对。同理透视变换就需要找 4 对点。作业中的 RANSAC 的主要步骤包括了:
- 随机选取对应点;
- 计算变换矩阵;
- 在给定的阈值范围内计算有效数据点数(inliers);
- 重复步骤 1-3,记录下最多的有效点数;
- 利用有效的数据点和最小二乘法重新计算变换矩阵。
函数实现:
ransac.m
输入:
keypoints1:(m*2)img1 角点坐标索引矩阵。
keypoints2:(n*2)img2 角点坐标索引矩阵。
matched_points:(p*2)矩阵,保存匹配上的角点的坐标。
iterations:RANSAC 迭代次数。
thres:RANSAC 误差阈值。
num_inliers:取 num_inliers 对点估计模型。
输出:
ransac_matched_points:(q*2)矩阵,保存 RANSAC 方法剔除误匹配后的匹配点坐标。
count_inliers:RANSAC 方法剔除误匹配后的匹配点个数。
步骤:
- 随机打乱匹配点顺序,计算打乱后的匹配点坐标 sub_matched1 和 sub_matched2;
- 取前 num_inliers 个随机点对拟合仿射变换矩阵 H;
- 根据拟合出来的变换矩阵计算 img1 中的角点的变换结果 sub_transed;
- 计算误差,这里误差的描述取 sub_transed 和 sub_matched2 的比值-1 的绝对值;
- 计算 sub_transed 中小于误差的点的个数;
- 重复步骤 1-4 至设置好的迭代次数,记录下最多的内点数;
- 输出最多内点时的内点集合以及内点个数;
- 根据输出的内点集合重新拟合仿射变换矩阵。
误差描述好像还有其他方法,例如计算前后两个矩阵的范数等,可以采取一些扩大误差的方法得到更精确的内点集合。RANSAC 迭代一定次数后计算结果不会变的更好。RANSAC 方法迭代 500 次,误差阈值取 0.003,比例阈值 k 取 0.8 时,一般会剔除 220 对左右的匹配点,效果如下:

匹配对比如下:



另外,关于取计算估计模型的随机点的对数也会对结果产生影响,前面是取 3 对点估算仿射变换矩阵模型的结果,而 3 对点只能刚好解算模型,一般不能发现粗差(即局外点),一般来讲,数据应该远大于 3 对,取 10 对点估计模型的结果如下,可以看到效果比取 3 对要好一些:

3 对点估计模型

10 对点估计模型
为了缩短 RANSAC 方法的计算时间,还可以输入一个“置信度”阈值,在计算过程中计算一个匹配错误率以衡量 RANSAC 估计出的模型(即我们的仿射变换矩阵)的好坏,如果这个模型已经足够令人满意,那么可以直接跳出循环并输出结果,而不用继续参加剩下的迭代。具体实现请见 Matlab 代码及代码注释。
2.5. 模块 5 梯度方向直方图
原理简介:
在前面的生成描述向量函数中,直接用关键点周围的一个固定区域(patch)的经过标准正态化的像素值作为描述向量(即展开成一维向量)。在这一模块里将会利用 HOG 来描述特征点的特征。
HOG 即 Histogram Of Gradient(方向梯度直方图),梯度的方向分布将会被用作特征。计算方向梯度直方图的主要步骤是:
- 选取角点周围的一个固定区域(patch);
- 使用 Sobel 算子与 patch 卷积计算 patch 梯度;
- 计算梯度幅值
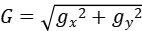 和梯度方向
和梯度方向 ;
; - 计算梯度直方图,将 patch 分为若干个 n*n 的方格(cell),然后根据每个方格内的点的梯度方向将梯度幅值按权重分配到直方图的每个 bin 中;
- 将所有 cell 的梯度直方图数据合并在一起并进行归一化后可以将这个 patch 描述为一个向量,将这个向量作为该角点的描述子。
函数实现:
hog_descriptor.m
输入:
patch:(m*m)矩阵,角点周围的一个固定区域。
输出:
hog_descriptors:(1*d)向量,HOG 梯度直方图描述子。
步骤:
- 计算
 方向和
方向和 方向的梯度;
方向的梯度; - 计算梯度幅值和梯度角度;
- 设置直方图 bin 的数量,这里将 45 度为一个 bin,将 360 度分为 8 个 bin;
- 根据梯度方向分类(代码里写了一个分类器 sorter);
- 计算 patch 梯度直方图。先计算每个 cell 的梯度直方图,然后合并在一起作为 patch 的梯度直方图;
- 归一化 patch 的梯度直方图,得到该 patch 所属的角点的 HOG 描述子。
当比例阈值 k 取 0.8 时,HOG 特征描述子的匹配结果如图所示,共匹配了 92 对点:

RANSAC 方法迭代 500 次,误差阈值取 0.02 时,一般会剔除大约 20 对点,结果如图所示:


可以发现用 HOG 描述角点所拟合出来的变换矩阵比直接用像素值描述角点要好一些。具体实现请见 Matlab 代码及代码注释。
2.6. 模块 6 更佳的图片融合策略(线性融合)
原理解释:
前面的图像拼接直接将两张图上下叠加在了一起,导致最终的输出图片里融合区域存在明显的分界线。可以将重合区域的强度值除以 2,其他部分除以 1,但这其实表示的是左右两张图片的比重相同(equally weighted),这样输出的拼接结果分界还是比较明显。
实际上,重合区域左右两边的比重并不应该相同——靠近左边图片的部分,左边图片的比重应该更大;靠近右边图片的部分,右边图片的比重应该更大。我们可以利用线性融合的方法来提升拼接结果的质量。
主要步骤是:
- 确定融合区域的左边界和右边界;
- 给图片 1 确定一个权重矩阵:从图片 1 的最左边到融合区域的最左边,weight 为 1-从融合区域的最左边到图片 1 的最右边,weight 从 1 到 0 进行分布;
- 给图片 2 确定一个权重矩阵:从融合区域的最右边到图片 2 的最右边,weight 为 1-从融合区域的最左边到图片 1 的最右边,weight 从 0 到 1 进行分布;
- 分别对左右两张图片应用权重矩阵;
- 将两张图相加。
函数实现:
linear_blend.m
输入:
img1:(HW3)经过仿射变换过后的图 1。
img2:(HW3)经过仿射变换过后的图 2。
输出:
temp_mask:img1 和 img2 的重合区域。
linear_blended_img:(HW3)重合区域比重相同融合结果。
equally_weighted_blended_img:(HW3)重合区域线性融合结果。
步骤:
- 根据 img1 和 img2 有无像素值确定融合区域 temp_mask;
- 确定融合区域的左边界和右边界;
- 创建比重相同融合 mask1 和线性融合 mask2;
- 根据 mask 计算每张图的重合区域像素值;
- 将两张图相加,输出结果。
具体实现请见 Matlab 代码及代码注释。
这里采用了前面 HOG 描述子拟合变换后的 img1 和 img2,直接融合和线性融合结果如下:


以下是截止时间延长后的添加内容:
2.7. 模块 7 函数封装
这个模块没什么新内容,只是把写完的函数放在了一块儿为全景拼接作准备。
步骤:
1.角点检测;2.生成描述子;3.匹配角点;4.RANSAC;5.拟合矩阵;6.线性融合。
函数实现:
stitch.m
输入:
img1:(HW3)的图 1。
img2:(HW3)的图 2。
输出:
out:img1 和 img2 线性融合的拼接结果。
2.8. 模块 8 Matlab 自带的 SURF 实现
来不及自己写 SIFT 了,但是发现 Matlab 封装好了 SURF,这个模块是用 Matlab 自带函数实现的图像拼接。
Matlab 进行图像拼接的具体步骤和以上步骤相同,主要用到的函数有:
- detectSURFFeatures();
- extractFeatures();
- matchFeatures();
- estimateGeometricTransform();
- imwarp();
6.linear_blend();
函数实现:
my_surf.m
输入:
img1:(HW3)的图 1。
img2:(HW3)的图 2。
输出:
out:img1 和 img2 线性融合的拼接结果。
用 Matlab 自带的函数拼接结果如下:

可见效果比自己写的要更好一点儿。
2.9. 模块 9 基于 Matlab 自带的 SURF 写的“全景拼接”
原理解释:
从上面的结果可以看出自己写的函数实现效果没有 Matlab 的好,而且由于自己写的函数有各种各样的小问题,在截止时间之前完全自己实现全景拼接不太可能了,所以只能基于 Matlab 的代码加工一个全景拼接。
主要原理就是添加一个循环,每次拼接两张图片 img1 和 img2,经过一次循环后 img1 是每次的拼接结果,最后可以实现顺序输入图片的拼接。由于用的是 Matlab 已经封装好的函数,所以在变换矩阵拟合方面比较优秀。
但是最后研究了半天也不知道为啥最后结果右边有这么多黑边。拼接结果如下:


2.10. 其他图片的匹配
用了其他图片测试,拼接效果如下:



如果匹配效果不佳的话(如雪山),也许可以通过调整参数使匹配效果变好,由于时间关系没有继续研究参数了。
资源下载地址:https://download.csdn.net/download/sheziqiong/85824219
资源下载地址:https://download.csdn.net/download/sheziqiong/85824219