Mmdetection3d集成了大量3D深度学习算法,其中很大一部分可以在智能驾驶KITTI数据集上运行。在算法应用KITTI数据之前,mmdetection3d提供了相应的预处理程序。关于kitti的详细介绍请参考本博客之前的文章,例如:【Mini KITTI】KITTI数据集简介 — Mini KITTI_Coding的叶子的博客-CSDN博客。部分介绍内容会持续更新和补充。
1 mmdetection3d 环境安装
mmdetection3d环境详细安装和调试请参考:【mmdetection3d】mmdetection3d安装详细步骤_Coding的叶子的博客-CSDN博客。
2 kitti原始数据集准备
mmdetection3d的kitti原始数据集主要由三部份组成,即ImageSets、training、testing。ImageSets主要是定义训练、验证和测试的样本名称。training文件夹下包含校准数据(calib)、图像数据(image_2)、标签数据(label_2)、激光雷达数据(velodyne)。testing文件夹下包含校准数据(calib)、图像数据(image_2)、激光雷达数据(velodyne)。kitti文件夹在mmdetection3d/data/目录下,其自身构成如下图所示:

KITTI数据集是三维点云算法常用的数据集之一,网络上有大量介绍资料,这里再不进行赘述。 为了快速进行算法调试、训练、评估和验证,以及快速下载,我制作了一个mini kitti数据集,数据集的文件目录结构与完整KITTI数据集保持一致。其中,小型的KITTI数据集,即 mini kitti保存了20个训练样本和5个测试样本。下载地址为:minikitti数据集_kittimini数据包-深度学习文档类资源-CSDN下载。
下载的数据包含4个部分,即激光雷达数据velodyne、图像数据image_2、校准数据calib和标注数据label_2。如果需要对应的ImageSets,请下载:train_val_testforminikitti-深度学习文档类资源-CSDN下载,将下载的文件夹重名为ImageSets即可。
3 kittie预处理程序
mmdetection3d针对各个数据集由专门的处理脚本。针对KITTI数据集,mmdetection3d 通过运行下述脚本完成数据集基本的预处理。
mmdetection3d针对各个数据集由专门的处理脚本。针对KITTI数据集,mmdetection3d 通过运行下述脚本完成数据集基本的预处理。
python tools/create_data.py kitti --root-path ./data/kitti --out-dir ./data/kitti --extra-tag kitti运行上述脚本之后,会在data/kitti/目录下生成4个pkl文件和4个json文件,即: kitti_infos_train.pkl、 kitti_infos_val.pkl、 kitti_infos_trainval.pkl、 kitti_infos_test.pkl、kitti_infos_train_mono3d.coco.json、kitti_infos_val_mono3d.coco.json、kitti_infos_trainval_mono3d.coco.json、kitti_infos_test_mono3d.coco.json。除pkl文件和json文件外还会生成velodyne_reduced和kitti_gt_database 文件夹。下面分别进行介绍。
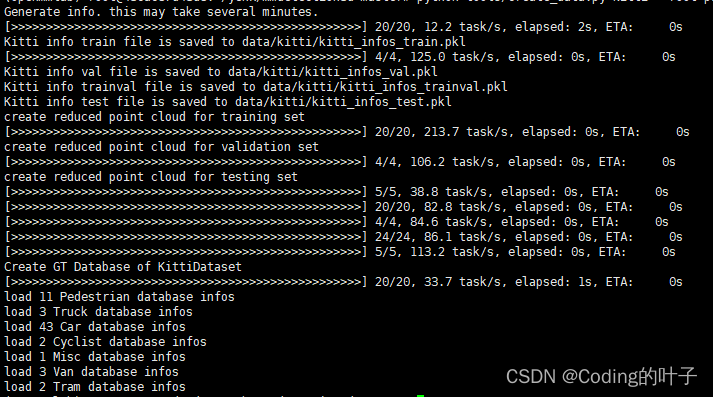
3.1 pkl文件
pkl文件主要是将ImageSets中定义的用于训练、验证和测试中的文件列表进一步细化。以训练文件来说,ImageSets中train.txt只是简单定义了用于训练的样本序号,如下图所示。
与之相对应的pkl文件名称为kitti_infos_train.pkl。pkl文件主要存储的是各个样本的详细信息,格式为字典组成的列表。列表中每个样本的信息不仅仅包含样本序号,还需要包含其他信息,统一存储在一个字典info中。该字典的key包含image(图片数据信息)、point_cloud(激光雷达数据信息)、calib(校准数据信息)、annos(标签标注数据信息)四个。
info[‘image’]:本身也是一个字典格式,主要包含image_idx(样本序号)、image_path(图片路径)、image_shape(图片尺寸)等三个部分,如下图所示。

info[‘point_cloud’]:本身也是一个字典格式,主要包含num_features(点云特征维度s数量xyzr)和velodyne_path(激光雷达路径)两个部分,如下图所示。
{'num_features': 4, 'velodyne_path': 'training/velodyne/000000.bin'}info[‘calib’]:本身也是一个字典格式,主要包含P0、P1、P2、P3、R0_rect、Tr_velo_to_cam、Tr_imu_to_velo等7个部分,如下图所示,校准数据各个参数的意义和示例请参考本专栏之前的博客。

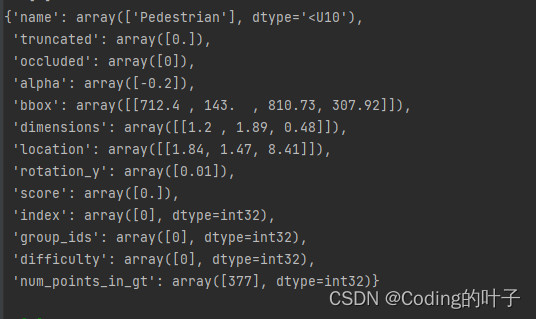
info[‘annos’]:本身也是一个字典格式,主要包含name、truncated、occlude、alpha、bbox、dimensions、location、rotation_y、score、index、group_ids、difficulty、num_points_in_gt等13个部分,如下图所示,标签标注数据各个参数的意义和示例请参考本专栏之前的博客。可以看到,每个数据都由numpy矩阵组成,矩阵的第一个维度与目标个数相关。
3.2 velodyne_reduced文件夹
在training和testing文件目录下会分别生成velodyne_reduced文件夹,该文件夹下存储的是经过裁剪的激光雷达数据,被裁剪的部分是图像视野范围之外的点云数据。
3.3 json文件
json文件存储了coco格式的标注信息,仍然是以字典列表的形式来存储各个标注,每一个目标占用一个列表元素,不再是每一个样本占用一个元素。一个样本可以拥有多个目标,因此json中annotations字典列表长度大于pkl中的字典列表长度。字典中包含了annotations、images和categories三个部分。
3.3.1 annotations
annotations是存储标注信息的字典,含14个关键字,各个字段介绍如下:
file_name:图片路径,如training/image_2/000000.png
image_id:样本序号,如0
area:三维目标在相机坐标系下的投影面积
category_name:目标名称,如Car
category_id:类别标签序号,如2
bbox:二维标注框,list:4
iscrowd:0
bbox_cam3d:相机坐标系下三维标注,list:7,即xyzwhl+rotation
Velo_cam3d:速度,-1
ceter2d:三维目标中心在相机坐标系下的投影,list:3
attribute_name:-1
attribute_id:-1
segmenation:[]3.3.2 images
images是图片和校准信息的字典,含8个关键字,即file_name、id、Tri2v、Trv2c、rect、cam_intrinsic、width、height,包含了图片路径、样本序号、相机校准参数和尺寸。
3.3.3 categories
categories中存储了算法关注的标签名称及其标签ID,如下所示:
[{'id': 0, 'name': 'Pedestrian'},
{'id': 1, 'name': 'Cyclist'},
{'id': 2, 'name': 'Car'}]3.4 kitti_gt_database 文件夹
kitti_gt_database文件夹下存储的是每个目标所占据的点云,并且点云的中心点平移到了坐标原点。这相当于中心位于坐标原点的各个目标的三维点云。存储格式按照sampleid_classname_i.bin。Sampleid表示样本序号,classname为目标名称,i表示样本中的第i个目标。各个文件运行结果如下图所示。

4 【python三维深度学习】python三维点云从基础到深度学习_Coding的叶子的博客-CSDN博客_python 三维点云
更多三维、二维感知算法和金融量化分析算法请关注“乐乐感知学堂”微信公众号,并将持续进行更新。