互信息主要是过滤掉那些内部结合不紧密的片段,但只过滤掉了3%的无意义片段,而我们会发现,大量的不是词的片段是这样的形式:
informa、informat、informati,informatio这样的,属于information这个高频词一部分的片段。这些片段因为是某个词的一部分,因此,有这样一个明显的特点,就是其后续的一个字母或者几个字母非常固定。
如informa,后续的一个字母只有l和t两种,后续的两个字母只有ti和ll两种,而作为一个独立的词,如information,其后续的一个字母有十几种,两个字母形式的后继就更多了,而显然,如果要成为一个词,其前后的搭配都应该足够的丰富和自由,这才能成为一个词,我们一般用边界熵,也就是边界稳定性来衡量一个片段搭配的分丰富程度。
边界的长度如果取1个字母,可能误删率会很高,如果取的过长,则大部分片段的边界都可能会很丰富,因此,这里取1到6个字母,分别看下效果。还有一种方案,就是利用现有的片段直接对语料进行分词,然后统计每个片段的后继词的丰富的。这几种方案都测试下。
首先是取1个字母的边界,如取边界熵大于0作为特征,则词的边界熵中,所有的边界熵都是大于0的,而非词的边界熵中,有大概7%的边界熵是等于0的,其它的是大于0的。可以看到,边界熵对分辨词和非词还是非常有效的,
当然,我们还可以取一个更大的边界熵阈值,过滤掉更多的非词片段,如取边界熵大于1作为特征,则词的边界熵中,只有2%左右是小于1的,而非词中有37%的都是小于1的,显然如果取边界熵的阈值为1作为过滤条件,显然比取0要好一些。但如果阈值取的过大,显然会造成误删除过多,而如果过小的话,过滤掉的词又太少,因此我们可以按照特性选取的方法,如信息增益来衡量特征的优劣。
信息增益应用到我们的场景中,类别C包含两个类别,记C1为是词的类别,C2是非词的类别,t为阈值特征,即为大于一个边界熵阈值,而!t表示小于边界熵阈值,这里取阈值为1作为例子计算,其公式可以表示为:
IG = H(C) - H(C|T),其中:H(C)就是分类系统的概率
也就是H(C) = -P(C1)logP(C1)+-P(C1)logP(C2), P(C1)就是C1出现的概率,也就是词的数目,除以所有片段的数目
这里H(C) = -0.0222log(0.0222)+ 0.9778log( 0.9778)=0.1537
H(C|T) = H(C|t) + H(C|!t)
其中H(C|t) = P(t)[ H(C1|t)+H(C2|t) ]=P(t)[ -P(C1|t)logP(C1|t) + -P(C2|t)logP(C2|t) ]
而H(C|!t) = P(!t)[ H(C1|!t)+H(C2|!t) ]=P(!t)[ -P(C1|!t)logP(C1|!t) + -P(C2|t)logP(C2|!t) ]
其中,P(t)就是大于阈值的所有的片段的概率,就是大于阈值的片段数目除以全部的片段数据,P(!t)就是小于阈值的片段数目除以全部的片段数目:
P(t) = 0.6367,P(!t) = 0.3633
而P(C1|t)就是t中属于类别C1的概率,也就是大于阈值的片段中是词的概率,P(C1|!t)的含义类似
P(C1|t) = 0.0341,P(C2|t) = 0.9659
P(C1|!t) = 0.0013,P(C2|!t) = 0.9987
则H(C|t) =0.6367*0.2145 = 0.1366
H(C|!t) =0.3633*0.0144 = 0.0052
可以得到,H(C|T) = 0.1366 + 0.0052 = 0.1418
而信息增益为:H(C)-H(C|T) = 0.1537-0.1418 = 0.0119
同样的,我们如果取阈值为0,则信息增益为0.0022(注意,这里假设任何情况下,词或者非词片段至少出现1次,否则可能出现log0的情况),显然不如取1效果好,这里取阈值从0到4,分别看信息增益,然后取一个效果最好的,也就是信息增益的最大值时对应的阈值:
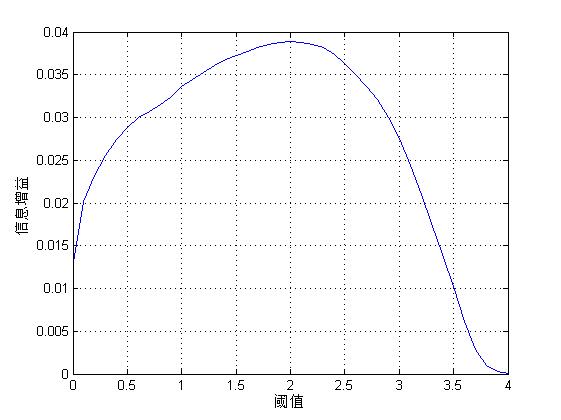
根据上图,可以确定去阈值为2.6左右时,信息增益最大,这时,词的边界熵中,有18%左右是小于2.6的,而非词中有69%的都是小于2.6的,相当于过滤掉了将近70%的非词片段,而词的片段有18%是误删除的,这个比例是否合适,需要由我们的应用效果,也就是分词的准确率和覆盖率来确定,这就要不断的做实验,看效果。
在中文处理中,一般取边界宽度为一个词即可,但英文中字母非常少,因此边界到底取多长其实相对比较难确定,这就需要不断的实验,这也是非监督方法的一个主要困难。
此外,我们还可以先用初始词典对语料进行分词,然后边界宽度设置为一个词,这样也是可以的。
在我们的测试中,如果取边界宽度为1,阈值为1.3,用30万的候选词进行过滤,这时候的效果是最好的,其准确率和覆盖率都达到了43%左右。我们的基线大概是40%左右,虽然提高的不是很多,但是已经去掉了一多半以上的不是词的片段,而是词的片段只删掉了不到10%。这就为后续的处理提供了很多的便利。