文章目录
前言
最近各种事情…这个finally lab也算是拖得比较久,好在最后也是赶在实习前完成这个lab。
一、实验背景
对于这个实验算是整个lab1~4做下来综合性最强的了,因为他没有paper进行指导,且需要lab2的raft共识算法+lab3的分片控制器,共同在lab4中构造出一个分片的容错数据库。
对于整体的实验架构可以参考笔者所画的图:
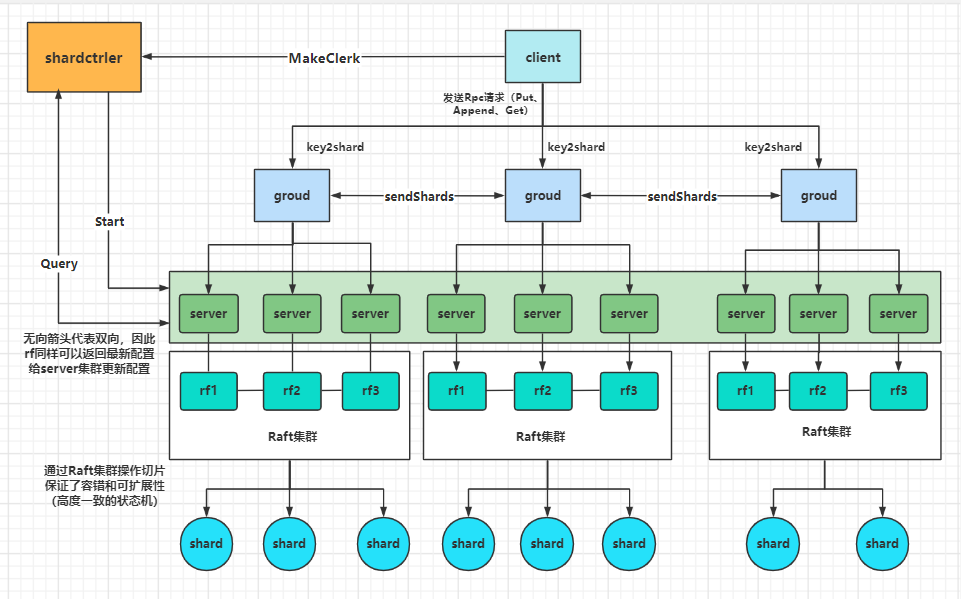
client客户端,将发送的请求利用Key2Shard进行分片,分到具体某个组下的server,然后这个server如果是leader则再利用自身的raft组进行共识,利用共识对整个server集群同步当前组对分片的操作,保持容错,而整个系统的集群则是通过lab3的分片控制器来保证。这里的图也是根据笔者的思路与能力尽可能的去复现这个架构,也希望能够帮助读者,当然这些也都仅供参考。
二、client端
对于client端跟前几个lab要求的其实差不多,这次的lab客户端也完善了大部分的代码。只需要在原有基础上加上seqId序列号保证去重就行。
// Get GetType
// fetch the current value for a key.
// returns "" if the key does not exist.
// keeps trying forever in the face of all other errors.
// You will have to modify this function.
//
func (ck *Clerk) Get(key string) string {
ck.seqId++
for {
args := GetArgs{
Key: key,
ClientId: ck.clientId,
RequestId: ck.seqId,
}
shard := key2shard(key)
gid := ck.config.Shards[shard]
if servers, ok := ck.config.Groups[gid]; ok {
// try each server for the shard.
for si := 0; si < len(servers); si++ {
srv := ck.make_end(servers[si])
var reply GetReply
//fmt.Printf("[ ++++Client[%v]++++] : send a GetType,args:%+v,serverId[%v]\n", ck.clientId, args, si)
ok := srv.Call("ShardKV.Get", &args, &reply)
if ok {
//fmt.Printf("[ ++++Client[%v]++++] : receive a GetType,args:%+v ,replys:%+v ,serverId[%v]\n", ck.clientId, args, reply, si)
} else {
//fmt.Printf("[ ++++Client[%v]++++] : Ask Err:args:%+v\n", ck.clientId, args)
}
if ok && (reply.Err == OK || reply.Err == ErrNoKey) {
return reply.Value
}
if ok && (reply.Err == ErrWrongGroup) {
break
}
// ... not ok, or ErrWrongLeader
}
}
time.Sleep(100 * time.Millisecond)
// ask controler for the latest configuration.
ck.config = ck.sm.Query(-1)
}
}
// PutAppend
// shared by Put and Append.
// You will have to modify this function.
//
func (ck *Clerk) PutAppend(key string, value string, op string) {
ck.seqId++
for {
args := PutAppendArgs{
Key: key,
Value: value,
Op: Operation(op),
ClientId: ck.clientId,
RequestId: ck.seqId,
}
shard := key2shard(key)
gid := ck.config.Shards[shard]
if servers, ok := ck.config.Groups[gid]; ok {
for si := 0; si < len(servers); si++ {
srv := ck.make_end(servers[si])
var reply PutAppendReply
//fmt.Printf("[ ++++Client[%v]++++] : send a Put,args:%+v,serverId[%v]\n", ck.clientId, args, si)
ok := srv.Call("ShardKV.PutAppend", &args, &reply)
if ok {
//fmt.Printf("[ ++++Client[%v]++++] : receive a Put,args:%+v ,replys:%+v ,serverId[%v]\n", ck.clientId, args, reply, si)
} else {
//fmt.Printf("[ ++++Client[%v]++++] : Ask Err:args:%+v\n", ck.clientId, args)
}
if ok && reply.Err == OK {
return
}
if ok && reply.Err == ErrWrongGroup {
break
}
// ... not ok, or ErrWrongLeader
}
}
time.Sleep(100 * time.Millisecond)
// ask controler for the latest configuration.
ck.config = ck.sm.Query(-1)
}
}
- tips:这里其实还是可以优化的,就是按照之前的传统去记录下leaderId这样WrongLeader的次数就会变少。
三、server端
3.1、 初始化
这部分与之前没什么变化
func StartServer(servers []*labrpc.ClientEnd, me int, persister *raft.Persister, maxraftstate int, gid int, masters []*labrpc.ClientEnd, make_end func(string) *labrpc.ClientEnd) *ShardKV {
// call labgob.Register on structures you want
// Go's RPC library to marshall/unmarshall.
labgob.Register(Op{
})
kv := new(ShardKV)
kv.me = me
kv.maxRaftState = maxraftstate
kv.makeEnd = make_end
kv.gid = gid
kv.masters = masters
// Your initialization code here.
kv.shardsPersist = make([]Shard, shardctrler.NShards)
kv.SeqMap = make(map[int64]int)
// Use something like this to talk to the shardctrler:
// kv.mck = shardctrler.MakeClerk(kv.masters)
kv.sck = shardctrler.MakeClerk(kv.masters)
kv.waitChMap = make(map[int]chan OpReply)
snapshot := persister.ReadSnapshot()
if len(snapshot) > 0 {
kv.DecodeSnapShot(snapshot)
}
kv.applyCh = make(chan raft.ApplyMsg)
kv.rf = raft.Make(servers, me, persister, kv.applyCh)
go kv.applyMsgHandlerLoop()
go kv.ConfigDetectedLoop()
return kv
}
3.2、Loop部分
对于此次lab相对于之前的applyMsg还需要一个检测配置更新的Loop,先来看之前的applyMsgLoop。
// applyMsgHandlerLoop 处理applyCh发送过来的ApplyMsg
func (kv *ShardKV) applyMsgHandlerLoop() {
for {
if kv.killed() {
return
}
select {
case msg := <-kv.applyCh:
if msg.CommandValid == true {
kv.mu.Lock()
op := msg.Command.(Op)
reply := OpReply{
ClientId: op.ClientId,
SeqId: op.SeqId,
Err: OK,
}
if op.OpType == PutType || op.OpType == GetType || op.OpType == AppendType {
shardId := key2shard(op.Key)
//
if kv.Config.Shards[shardId] != kv.gid {
reply.Err = ErrWrongGroup
} else if kv.shardsPersist[shardId].KvMap == nil {
// 如果应该存在的切片没有数据那么这个切片就还没到达
reply.Err = ShardNotArrived
} else {
if !kv.ifDuplicate(op.ClientId, op.SeqId) {
kv.SeqMap[op.ClientId] = op.SeqId
switch op.OpType {
case PutType:
kv.shardsPersist[shardId].KvMap[op.Key] = op.Value
case AppendType:
kv.shardsPersist[shardId].KvMap[op.Key] += op.Value
case GetType:
// 如果是Get都不用做
default:
log.Fatalf("invalid command type: %v.", op.OpType)
}
}
}
} else {
// request from server of other group
switch op.OpType {
case UpConfigType:
kv.upConfigHandler(op)
case AddShardType:
// 如果配置号比op的SeqId还低说明不是最新的配置
if kv.Config.Num < op.SeqId {
reply.Err = ConfigNotArrived
break
}
kv.addShardHandler(op)
case RemoveShardType:
// remove operation is from previous UpConfig
kv.removeShardHandler(op)
default:
log.Fatalf("invalid command type: %v.", op.OpType)
}
}
// 如果需要snapshot,且超出其stateSize
if kv.maxRaftState != -1 && kv.rf.GetRaftStateSize() > kv.maxRaftState {
snapshot := kv.PersistSnapShot()
kv.rf.Snapshot(msg.CommandIndex, snapshot)
}
ch := kv.getWaitCh(msg.CommandIndex)
ch <- reply
kv.mu.Unlock()
}
if msg.SnapshotValid == true {
if kv.rf.CondInstallSnapshot(msg.SnapshotTerm, msg.SnapshotIndex, msg.Snapshot) {
// 读取快照的数据
kv.mu.Lock()
kv.DecodeSnapShot(msg.Snapshot)
kv.mu.Unlock()
}
continue
}
}
}
}
对于追加的部分就是对于一个group内对进行对切片操作(增加与GC)的共识,以及配置更新的共识。
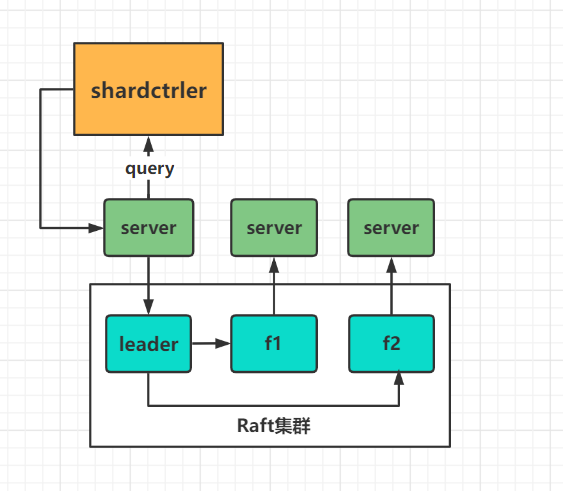
- 接下来就是检测最新配置的Loop的:
对于配置更新的流程可以看作如下的图:
- 而对于整个集群的切片迁移可以看做如下:
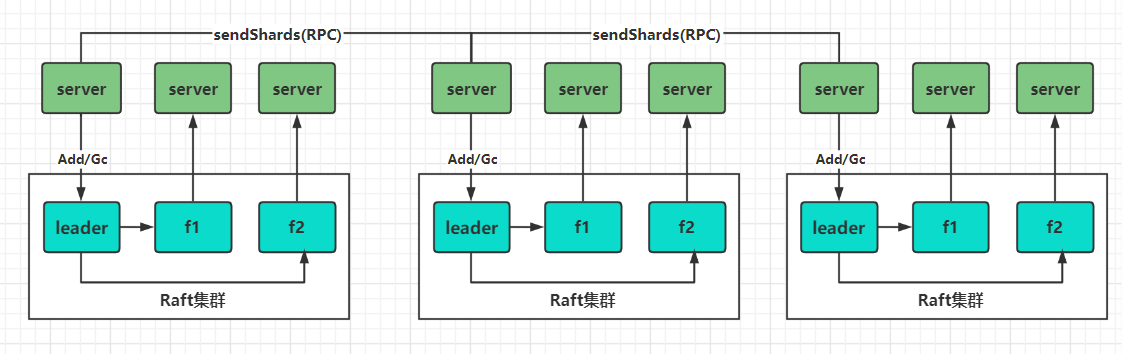
更新配置后发现有配置更新: - 1、那么则通过不属于自己的切片
- 2、收到别的group的切片后进行AddShards同步更新组内的切片
- 3、成功发送不属于自己的切片或者超时则进行Gc
// ConfigDetectedLoop 配置检测
func (kv *ShardKV) ConfigDetectedLoop() {
kv.mu.Lock()
curConfig := kv.Config
rf := kv.rf
kv.mu.Unlock()
for !kv.killed() {
// only leader needs to deal with configuration tasks
if _, isLeader := rf.GetState(); !isLeader {
time.Sleep(UpConfigLoopInterval)
continue
}
kv.mu.Lock()
// 判断是否把不属于自己的部分给分给别人了
if !kv.allSent() {
SeqMap := make(map[int64]int)
for k, v := range kv.SeqMap {
SeqMap[k] = v
}
for shardId, gid := range kv.LastConfig.Shards {
// 将最新配置里不属于自己的分片分给别人
if gid == kv.gid && kv.Config.Shards[shardId] != kv.gid && kv.shardsPersist[shardId].ConfigNum < kv.Config.Num {
sendDate := kv.cloneShard(kv.Config.Num, kv.shardsPersist[shardId].KvMap)
args := SendShardArg{
LastAppliedRequestId: SeqMap,
ShardId: shardId,
Shard: sendDate,
ClientId: int64(gid),
RequestId: kv.Config.Num,
}
// shardId -> gid -> server names
serversList := kv.Config.Groups[kv.Config.Shards[shardId]]
servers := make([]*labrpc.ClientEnd, len(serversList))
for i, name := range serversList {
servers[i] = kv.makeEnd(name)
}
// 开启协程对每个客户端发送切片(这里发送的应是别的组别,自身的共识组需要raft进行状态修改)
go func(servers []*labrpc.ClientEnd, args *SendShardArg) {
index := 0
start := time.Now()
for {
var reply AddShardReply
// 对自己的共识组内进行add
ok := servers[index].Call("ShardKV.AddShard", args, &reply)
// 如果给予切片成功,或者时间超时,这两种情况都需要进行GC掉不属于自己的切片
if ok && reply.Err == OK || time.Now().Sub(start) >= 5*time.Second {
// 如果成功
kv.mu.Lock()
command := Op{
OpType: RemoveShardType,
ClientId: int64(kv.gid),
SeqId: kv.Config.Num,
ShardId: args.ShardId,
}
kv.mu.Unlock()
kv.startCommand(command, RemoveShardsTimeout)
break
}
index = (index + 1) % len(servers)
if index == 0 {
time.Sleep(UpConfigLoopInterval)
}
}
}(servers, &args)
}
}
kv.mu.Unlock()
time.Sleep(UpConfigLoopInterval)
continue
}
if !kv.allReceived() {
kv.mu.Unlock()
time.Sleep(UpConfigLoopInterval)
continue
}
// current configuration is configured, poll for the next configuration
curConfig = kv.Config
sck := kv.sck
kv.mu.Unlock()
newConfig := sck.Query(curConfig.Num + 1)
if newConfig.Num != curConfig.Num+1 {
time.Sleep(UpConfigLoopInterval)
continue
}
command := Op{
OpType: UpConfigType,
ClientId: int64(kv.gid),
SeqId: newConfig.Num,
UpConfig: newConfig,
}
kv.startCommand(command, UpConfigTimeout)
}
}
- tips:这里同样是会涉及到一个去重的问题,相比客户端RPC通过在client端进行seqId自增,关于的配置的自增,只要利用配置号进行就可以,只要配置更新,那么一系列的操作就都会与最新的配置号有关。
3.3、raft部分Rpc
这部分与之前的lab的实现差不多,利用raft达到group组内的切片配置共识。
//------------------------------------------------------RPC部分----------------------------------------------------------
func (kv *ShardKV) Get(args *GetArgs, reply *GetReply) {
shardId := key2shard(args.Key)
kv.mu.Lock()
if kv.Config.Shards[shardId] != kv.gid {
reply.Err = ErrWrongGroup
} else if kv.shardsPersist[shardId].KvMap == nil {
reply.Err = ShardNotArrived
}
kv.mu.Unlock()
if reply.Err == ErrWrongGroup || reply.Err == ShardNotArrived {
return
}
command := Op{
OpType: GetType,
ClientId: args.ClientId,
SeqId: args.RequestId,
Key: args.Key,
}
err := kv.startCommand(command, GetTimeout)
if err != OK {
reply.Err = err
return
}
kv.mu.Lock()
if kv.Config.Shards[shardId] != kv.gid {
reply.Err = ErrWrongGroup
} else if kv.shardsPersist[shardId].KvMap == nil {
reply.Err = ShardNotArrived
} else {
reply.Err = OK
reply.Value = kv.shardsPersist[shardId].KvMap[args.Key]
}
kv.mu.Unlock()
return
}
func (kv *ShardKV) PutAppend(args *PutAppendArgs, reply *PutAppendReply) {
shardId := key2shard(args.Key)
kv.mu.Lock()
if kv.Config.Shards[shardId] != kv.gid {
reply.Err = ErrWrongGroup
} else if kv.shardsPersist[shardId].KvMap == nil {
reply.Err = ShardNotArrived
}
kv.mu.Unlock()
if reply.Err == ErrWrongGroup || reply.Err == ShardNotArrived {
return
}
command := Op{
OpType: args.Op,
ClientId: args.ClientId,
SeqId: args.RequestId,
Key: args.Key,
Value: args.Value,
}
reply.Err = kv.startCommand(command, AppOrPutTimeout)
return
}
// AddShard move shards from caller to this server
func (kv *ShardKV) AddShard(args *SendShardArg, reply *AddShardReply) {
command := Op{
OpType: AddShardType,
ClientId: args.ClientId,
SeqId: args.RequestId,
ShardId: args.ShardId,
Shard: args.Shard,
SeqMap: args.LastAppliedRequestId,
}
reply.Err = kv.startCommand(command, AddShardsTimeout)
return
}
3.5、Handler部分
主要是给applyMsgHandlerLoop中切片、配置更新等操作做的handler。
//------------------------------------------------------handler部分------------------------------------------------------
// 更新最新的config的handler
func (kv *ShardKV) upConfigHandler(op Op) {
curConfig := kv.Config
upConfig := op.UpConfig
if curConfig.Num >= upConfig.Num {
return
}
for shard, gid := range upConfig.Shards {
if gid == kv.gid && curConfig.Shards[shard] == 0 {
// 如果更新的配置的gid与当前的配置的gid一样且分片为0(未分配)
kv.shardsPersist[shard].KvMap = make(map[string]string)
kv.shardsPersist[shard].ConfigNum = upConfig.Num
}
}
kv.LastConfig = curConfig
kv.Config = upConfig
}
func (kv *ShardKV) addShardHandler(op Op) {
// this shard is added or it is an outdated command
if kv.shardsPersist[op.ShardId].KvMap != nil || op.Shard.ConfigNum < kv.Config.Num {
return
}
kv.shardsPersist[op.ShardId] = kv.cloneShard(op.Shard.ConfigNum, op.Shard.KvMap)
for clientId, seqId := range op.SeqMap {
if r, ok := kv.SeqMap[clientId]; !ok || r < seqId {
kv.SeqMap[clientId] = seqId
}
}
}
func (kv *ShardKV) removeShardHandler(op Op) {
if op.SeqId < kv.Config.Num {
return
}
kv.shardsPersist[op.ShardId].KvMap = nil
kv.shardsPersist[op.ShardId].ConfigNum = op.SeqId
}
3.6、快照部分
这部分跟之前lab实现一样,可以参考之前笔者lab,此处不在赘述。
// PersistSnapShot Snapshot get snapshot data of kvserver
func (kv *ShardKV) PersistSnapShot() []byte {
w := new(bytes.Buffer)
e := labgob.NewEncoder(w)
err := e.Encode(kv.shardsPersist)
err = e.Encode(kv.SeqMap)
err = e.Encode(kv.maxRaftState)
err = e.Encode(kv.Config)
err = e.Encode(kv.LastConfig)
if err != nil {
log.Fatalf("[%d-%d] fails to take snapshot.", kv.gid, kv.me)
}
return w.Bytes()
}
// DecodeSnapShot install a given snapshot
func (kv *ShardKV) DecodeSnapShot(snapshot []byte) {
if snapshot == nil || len(snapshot) < 1 {
// bootstrap without any state?
return
}
r := bytes.NewBuffer(snapshot)
d := labgob.NewDecoder(r)
var shardsPersist []Shard
var SeqMap map[int64]int
var MaxRaftState int
var Config, LastConfig shardctrler.Config
if d.Decode(&shardsPersist) != nil || d.Decode(&SeqMap) != nil ||
d.Decode(&MaxRaftState) != nil || d.Decode(&Config) != nil || d.Decode(&LastConfig) != nil {
log.Fatalf("[Server(%v)] Failed to decode snapshot!!!", kv.me)
} else {
kv.shardsPersist = shardsPersist
kv.SeqMap = SeqMap
kv.maxRaftState = MaxRaftState
kv.Config = Config
kv.LastConfig = LastConfig
}
}
四、lab杂谈
对于Lab的challenge:
- 其实对于整个分布式并发流程来说,我觉得保持正确结果的目的就是尽量多次一组的操作不同次数调用能够使这组操作序列不会因为外部因素(时间等)发生影响按照预期的进行,就像最近在重温Java并发编程的艺术,其中的happen-before其实就是为程序员创造了一个幻境:正确同步的多线程程序是按happens-before指定的而顺序来执行的。 即使你编译器、处理器怎么重排序优化trap的时间,最后结果也是如你预期结果一样。而结合整个lab下来我更愿意称之为,尽可能的保持整个系统流程的线性化(Linearization)。只要提高了线性化,那么系统即使看起来宏观是并发的,但是实际上还是串行的。
对于此时的实验challenge我们只要定义好这个切片的具体迁移过程即可:
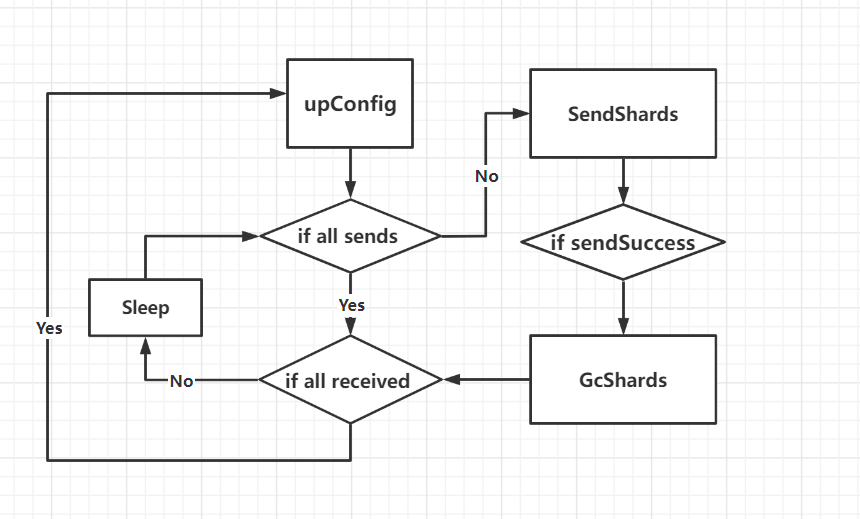
定义出一个线性的控制流程,challenge也就迎刃而解。
func (kv *ShardKV) allSent() bool {
for shard, gid := range kv.LastConfig.Shards {
// 如果当前配置中分片中的信息不匹配,且持久化中的配置号更小,说明还未发送
if gid == kv.gid && kv.Config.Shards[shard] != kv.gid && kv.shardsPersist[shard].ConfigNum < kv.Config.Num {
return false
}
}
return true
}
func (kv *ShardKV) allReceived() bool {
for shard, gid := range kv.LastConfig.Shards {
// 判断切片是否都收到了
if gid != kv.gid && kv.Config.Shards[shard] == kv.gid && kv.shardsPersist[shard].ConfigNum < kv.Config.Num {
return false
}
}
return true
}
总结
做完这次的lab整个6.824的lab就正式做完了,看看后面有没时间,写写对分布式系统理解的杂谈。不得不说一套下来的lab实验难度还是很大的,并且每每感到头疼时,就会更加佩服设计出这个Lab的人。其实对于这一系列的Lab的初心其实有一部分是为了自己后续方便自己看,但是最近做lab6.824的同学也越来越多(画图到是越来越有经验了,也希望自己写的博客能够帮助各位读者,当然这些都是笔者浅薄的见解,仅供参考,也会有一定误区,欢迎指正~
- 测试截图:
(这次的test倒是与实验介绍的100s差的不是很多,而且clientd代码也没重写,还可以优化,但是最近实在是没时间了orz…各种事情忙着。对于并发下的测试unreliable有的时候会fail,这个也暂时没时间看了。后面想起再来解决。
附上gitee仅供参考:Mit6.824-2022