资源下载地址:https://download.csdn.net/download/sheziqiong/85884349
资源下载地址:https://download.csdn.net/download/sheziqiong/85884349
HTTPCORE源码分析
1.HTTP初步了解
1 概念
超文本传输协议(英语:HyperText Transfer Protocol,缩写:HTTP)是一种用于分布式、协作式和超媒体信息系统的应用层协议[1]。HTTP是万维网的数据通信的基础。
2 目的
设计HTTP最初的目的是为了提供一种发布和接收HTML页面的方法。通过HTTP或者HTTPS协议请求的资源由统一资源标识符(Uniform Resource Identifiers,URI)来标识。
3 详细内容
HTTP是一个客户端终端(用户)和服务器端(网站)请求和应答的标准(TCP)。通过使用网页浏览器、网络爬虫或者其它的工具,客户端发起一个HTTP请求到服务器上指定端口(默认端口为80)。我们称这个客户端为用户代理程序(user agent)。应答的服务器上存储着一些资源,比如HTML文件和图像。我们称这个应答服务器为源服务器(origin server)。在用户代理和源服务器中间可能存在多个“中间层”,比如代理服务器、网关或者隧道(tunnel)。
4 消息(报文)格式
客户端发送一个HTTP请求到服务器的请求消息包括以下格式:请求行(request line)、请求头部(header)、空行和请求数据四个部分组成,下图给出了请求报文的一般格式。
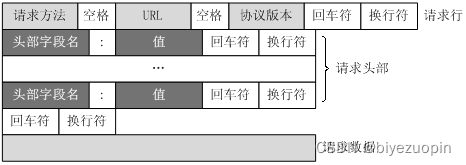
服务器端返回的报文格式与上图类似,除了请求行变为状态行之外其他与上图大致相同。
5 HTTP实体
在执行带有附加内容的请求时或者请求成功并且使用响应主体将结果发送回客户端时,将创建实体。实体会在下面提到的八种方法的 POST和PUT方法中传递的数据。实体作为消息传递时携带的“货物”,包含了实体头部和实体主体,存储在消息主体内。
实体的种类根据来源分为:
-
流实体:内容从流中接收,或在运行中生成。特别是,此类别包括从连接接收的实体。流实体通常不可重复。
-
自包含实体:内容在内存中或通过独立于连接或其他实体的方式获得。自包含实体通常是可重复的。
-
包装实体:内容从另一个实体中获得。
6 种方法
6.1 GET
向指定的资源发出“显示”请求。使用GET方法应该只用在读取数据,而不应当被用于产生“副作用”的操作中,例如在Web Application中。
6.2 HEAD
与GET方法一样,都是向服务器发出指定资源的请求。只不过服务器将不传回资源的本文部分。它的好处在于,使用这个方法可以在不必传输全部内容的情况下,就可以获取其中“关于该资源的信息”。
6.3 POST
向指定资源提交数据,请求服务器进行处理(例如提交表单或者上传文件)。数据被包含在请求本文中。这个请求可能会创建新的资源或修改现有资源,或二者皆有。
6.4 PUT
向指定资源位置上传其最新内容。
6.5 DELETE
6.6 TRACE
6.7 OPTIONS
6.8 CONNECT
7 安全方法
对于GET和HEAD方法而言,除了进行获取资源信息外,这些请求不应当再有其他意义。也就是说,这些方法应当被认为是“安全的”。 客户端可能会使用其他“非安全”方法,例如POST,PUT及DELETE,应该以特殊的方式(通常是按钮而不是超链接)告知客户可能的后果(例如一个按钮控制的资金交易),或请求的操作可能是不安全的(例如某个文件将被上传或删除)。
但是,不能想当然地认为服务器在处理某个GET请求时不会产生任何副作用。事实上,很多动态资源会把这作为其特性。这里重要的区别在于用户并没有请求这一副作用,因此不应由用户为这些副作用承担责任。
8 关于HTTPcore(摘自HTTPcore官网)
HttpCore是一组底层HTTP传输组件,可用于以最小的占用空间构建自定义客户端和服务器端HTTP服务。HttpCore支持两种I / O模型:基于经典Java I / O的阻塞I / O模型和基于Java NIO的非阻塞,事件驱动的I / O模型。
8.1 HTTPcore的范围
构建客户端/代理/服务端的一致API;构建同步和异步HTTP服务的一致API;基于阻塞(经典)和非阻塞(NIO)I/O模型的一组低级组件。
8.2 HTTP core的目标
实现大多数的基本HTTP传输方面;平衡API的性能和清晰性和可表达性;低内存消耗(可预测);独立的库(除JRE外,没有外部依赖)
8.3 HTTPcore不是什么
不是HttpClient的替代品;不是Servlet API的替代品。
本次分析选取的版本为HTTPcore中4.4.10版本的源代码,具体包含了HTTP方法中的GET等通信方法。还未具体确定要选择的功能分析,代码结构仍然在学习阶段。
2.源代码文件结构解析
文件目录下一共有4个主要的文件夹,分别是httpcore、httpcore-ab、httpcore-nio、httpcore-osgi。
1 httpcore
该文件下存储了4.4版本下的httpcore的主要的核心代码。具体分析其中main文件夹下的文件内容。
Annotation是注释文件夹;concurrent是并发(使用未来模式)的文件夹;config是配置文件夹;entity是http消息的实体类文件夹;impl是实现类文件夹;io是输入输出类文件夹;message是消息类文件夹;params是参数文件夹,但是多被注释掉,不考虑使用;pool的内容还不清楚;protocol为协议处理器文件夹;ssl为HTTPS以安全为目标建立的HTTP通道文件;util包含集合框架、遗留的 collection 类、事件模型、日期和时间设施、国际化和各种实用工具类(字符串标记生成器、随机数生成器和位数组、日期Date类、堆栈Stack类、向量Vector类等)。集合类、时间处理模式、日期时间工具等各类常用工具包(摘自百度)。
另外有多个独立的Java文件表示部分具体操作行为,具体操作将在后面分析。
2 httpcore-ab
该文件下存储的是用于测试httpcore执行的benchmark。
3 httpcore-nio
该文件下存储了Java NIO的详细代码,用于实现非阻塞驱动模型。
4 httpcore-osgi
这里详细代码用途不清楚,看内容是存储了OSGI框架注释,用来区别一个叫做IT的变量。
3.代码具体功能解析
1 以request和response message为例分析源码中的数据结构。
两种模式都连接了HttpMessage接口。可以看到定义的方法。

1.1 request message
如下图的一次HTTP请求消息(报文),输入包含了使用消息的方法、标识符和协议版本。
HttpRequest request = new BasicHttpRequest("GET", "/",
HttpVersion.HTTP_1_1);
System.out.println(request.getRequestLine().getMethod());
System.out.println(request.getRequestLine().getUri());
System.out.println(request.getProtocolVersion());
System.out.println(request.getRequestLine().toString());
可以看到输出流的结果
GET
/
HTTP / 1.1
GET / HTTP / 1.1
方法和标识符的类型均为串类型,协议版本类型类包含了版本UID、协议名和协议版本号。
BasicHTTPRequest中类BasicHTTPRequest继承了抽象类AbstractHttpMessage,两者又同时与接口HTTPMessage相连,HTTPMessage中包含了如下的一些方法。下图是消息请求过程中可以用到的方法:
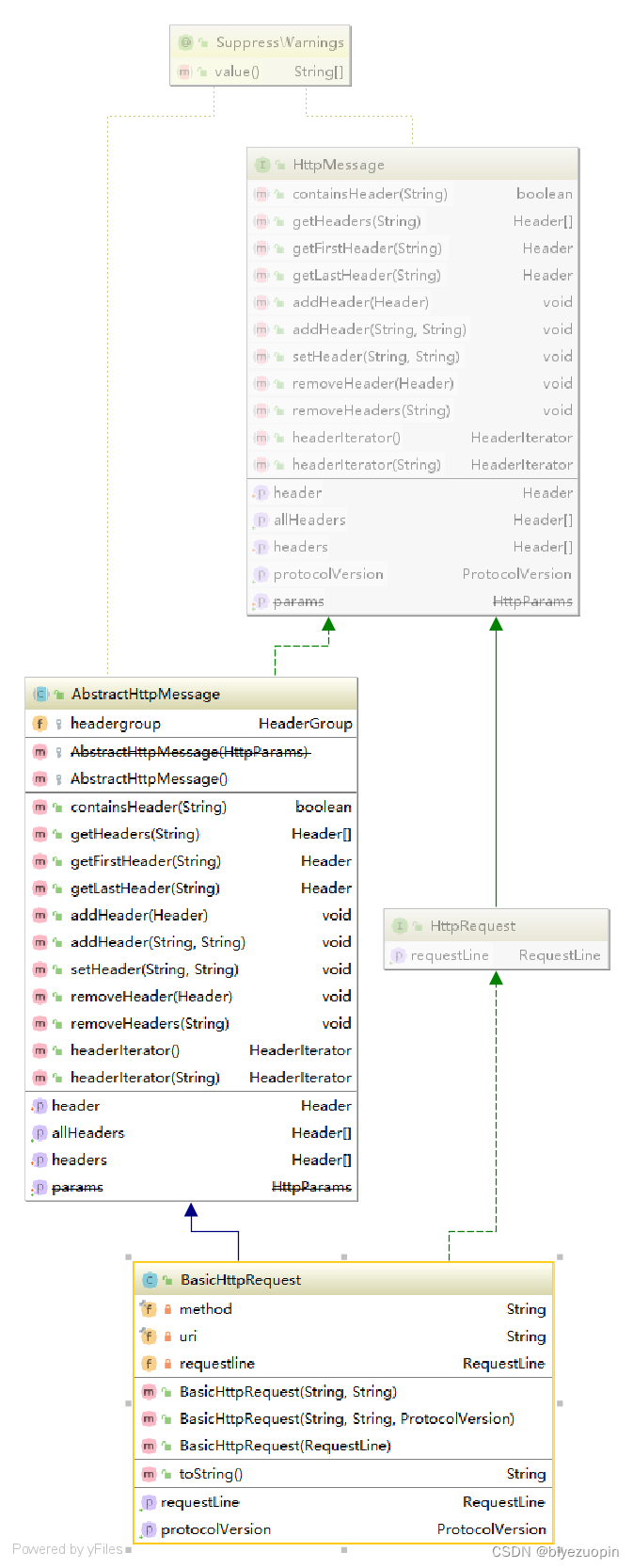
根据命名可以推断出方法的目的以及作用。
1.2 response message
下图表示HTTP响应是服务器在接收并解释请求消息后发送回客户端的消息。该消息的第一行包括协议版本,后跟数字状态代码及其相关的文本短语。
HttpResponse response = new BasicHttpResponse(HttpVersion.HTTP_1_1,
HttpStatus.SC_OK, "OK");
System.out.println(response.getProtocolVersion());
System.out.println(response.getStatusLine().getStatusCode());
System.out.println(response.getStatusLine().getReasonPhrase());
System.out.println(response.getStatusLine().toString());
输出流如下
HTTP/1.1
200
OK
HTTP/1.1 200 OK
总的类输入内容包含了状态行、协议版本、数字状态代码、文本短语、
不同于请求消息时输入的参数是满的,这里只输入了ProtocolVersion,code,reasonPhrase.
BasicHttpResponse的结构依然是继承了AbstractHttpMessage,连接了HttpResponse接口(继承了HttpMessage)。这里消息(报文)的header内可以包含多个,用于表示消息的具体属性,包括请求内容的长度和类型等。
2 分析三种实体的创建和数据结构
2.1 BasicHttpEntity
此类用于从HTTP消息接收的实体。该实体具有空构造函数。构建后,它表示没有内容,并且具有负内容长度。
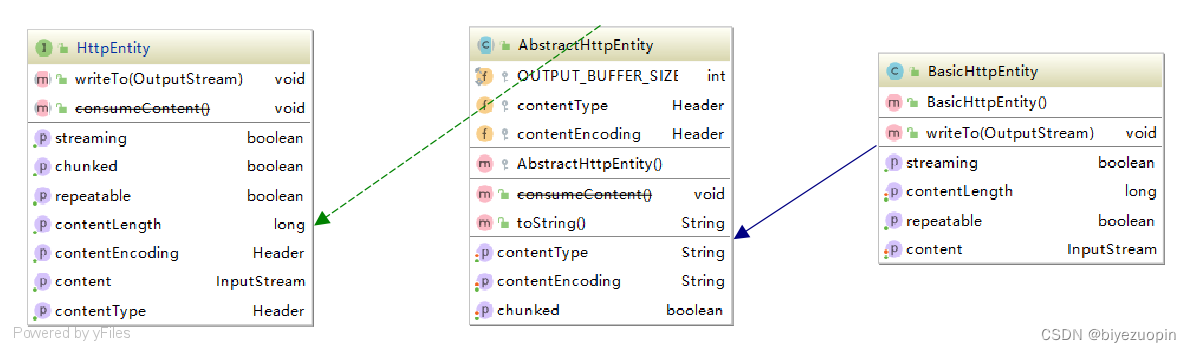
从类图中可以明显的看到该类的继承关系,Basic类继承了抽象类HTTPEntity,并连接接口HTTPEntity,从而实现了其中判断流、是否可重复、是否数据分块传递,以及请求返回内容长度和类型的方法。尽管Basic中实现了设置流长度、类型,但是根据注释该方法已被重载,这里不再记录。
2.2 ByteArrayEntity
ByteArrayEntity是一个自包含,可重复的实体,从给定的字节数组中获取其内容。将字节数组提供给构造函数。
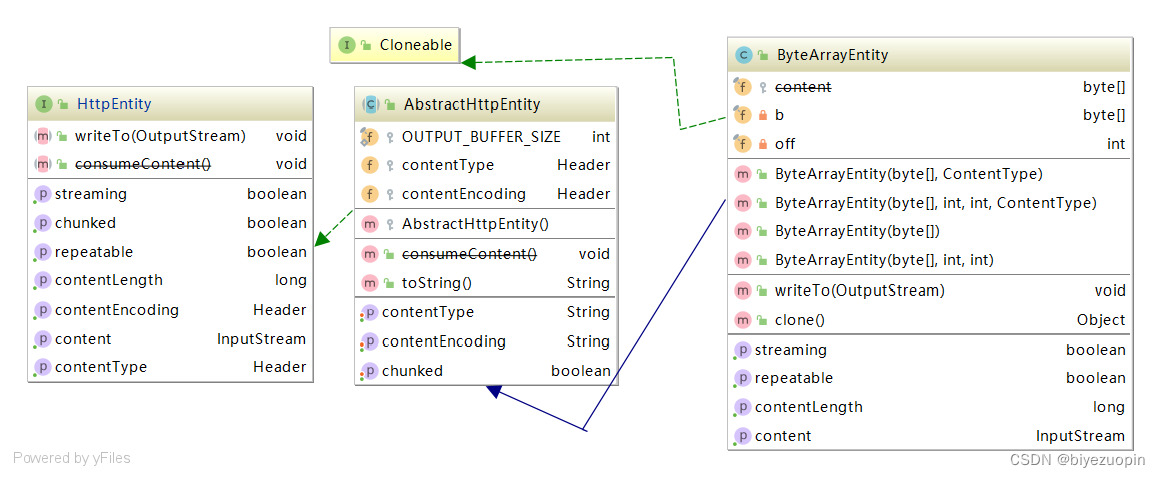
相较于Basic类,ByteArray类创建的是一个自包含可重复的实体,这就要求ByteArray还要连接可重复的接口Cloneable,方法中实现了重复的方法(clone),另外该类的作用是根据输入的字节数组中创建实体,因此实现的方法中包含了针对不同输入情况下的方法处理,包括只输入字节数组或者内容类型的方法。
2.3 StringEntity
StringEntity是一个自包含,可重复的实体,从java.lang.String对象中获取其内容。它有三个构造方法,一个是用给定的java.lang.String 对象构造; 第二个也对字符串中的数据进行字符编码; 第三个允许指定mime类型。(Multipurpose Internet Mail Extensions)
按照构造方法输入可见上图中StringEntity中三个构造方法自上至下依次为用给定的String类型构造,对字符串编码构造,接收MIME类型的构造。其余部分与Byte的关系相同。
4.阻塞I/O模型分析
前面的功能分析基于HTTP报文的产生和拦截器的使用过程分析,并未涉及真正的HTTP报文传输,下面将基于实际模型分析整个过程中的一些具体实现。这里根据官方教程研究阻塞I/O模型,若仍有时间可继续研究。
1 模型简介
阻塞(或典型)I/O在Java中有高效方便的I/O模型,在并发量不是很大的情况下非常适合高性能的应用程序。现代JVM虚拟机能够有效进行上下文切换,并且在并发连接低于1000,大多数连接都在忙着传送数据这种情况下,阻塞I/O模型应该提供最好的性能(事实它做到了)。可是,对于某些应用程序来说,大多数的连接都会被闲置,那么上下文切换的代价会很大,消耗大量资源,此时用非阻塞I/O模型可能是更好的选择。
阻塞就是要排队执行,连接闲置了都不能断开,如连接后等了好久都不见报文来,可是又不能保证报文不来,所以一直等待。
2 阻止HTTP连接
HTTP连接的作用是为了HTTP报文的序列化和反序列化。一般很少直接使用HTTP connection对象,因为有更高层次的协议部分可以用来执行和处理HTTP请求。可是有些时候还是需要直接用到这种HTTP连接,举个例子,访问某些属性如连接状态,套接字超时或者本地和远程IP地址。谨记HTTP连接不是线程安全的。所以限制所有HTTP连接对象只用在一个线程上。唯一可以在不同进程中安全调用的方法是 HttpConnection接口和其子接口中的HttpConnection.shutdown()。
HTTP报文的序列化和反序列化,其中序列化的目的是将对象的字节序列永久保存在硬盘中,通常存放在一个文件中,或者在网络上传输的通常是对象的字节序列。接收端一般接收到字节序列后反序列化就可以将其转化为对象。
资源下载地址:https://download.csdn.net/download/sheziqiong/85884349
资源下载地址:https://download.csdn.net/download/sheziqiong/85884349