资源下载地址:https://download.csdn.net/download/sheziqiong/85896663
资源下载地址:https://download.csdn.net/download/sheziqiong/85896663
感知机PLSA
1. 算法原理
感知机针对二分类问题进行学习。输入为样本的特征向量 x ∈ R n \bold x\in R^n x∈Rn,输出为类别 y ∈ { + 1 , − 1 } y\in\{+1,-1\} y∈{ +1,−1}。
感知机的预测结果为 f ( x ) = s i g n ( w ⋅ x + b ) f(x)=sign(w\cdot x+b) f(x)=sign(w⋅x+b),其中 s i g n sign sign为符号函数,在自变量大于0时为1,自变量小于0时为-1。 w w w为权值向量,和x的维度相同。b是偏置,为标量。线性方程 w ⋅ x + b w\cdot x+b w⋅x+b对应着特征空间的一个分离超平面,将特征空间分成两个部分,位于两部分的点分别对应正样本和负样本。
感知机利用损失函数对模型参量w和b进行更新学习。将误分类点 ( x i , y i ) (x_i,y_i) (xi,yi)到分离超平面的距离定义为:
1 ∣ ∣ w ∣ ∣ ∣ ∣ w ⋅ x + b ∣ ∣ = − 1 ∣ ∣ w ∣ ∣ ( w ⋅ x i + b ) y i \frac{1}{||w||}||w\cdot x+b||=-\frac{1}{||w||}(w\cdot x_i+b)y_i ∣∣w∣∣1∣∣w⋅x+b∣∣=−∣∣w∣∣1(w⋅xi+b)yi
假设误分类点的集合为M,且不考虑 − 1 ∣ ∣ w ∣ ∣ -\frac{1}{||w||} −∣∣w∣∣1则损失函数为:
L ( w , b ) = − ∑ x i ∈ M y i ( w ⋅ x i + b ) L(w,b)=-\sum_{x_i\in M}y_i(w\cdot x_i+b) L(w,b)=−xi∈M∑yi(w⋅xi+b)
可以采用随机梯度下降的方式来优化损失函数。w和b的损失函数梯度分别为:
∇ w L ( w , b ) = − ∑ x i ∈ M y i x i \nabla_wL(w,b)=-\sum_{x_i\in M}y_ix_i ∇wL(w,b)=−xi∈M∑yixi
∇ b L ( w , b ) = − ∑ x i ∈ M y i \nabla_bL(w,b)=-\sum_{x_i\in M}y_i ∇bL(w,b)=−xi∈M∑yi
选择某个误分类点对参数进行更新即可:
w = w + η y i x i w=w+\eta y_ix_i w=w+ηyixi
b = b + η y i b=b+\eta y_i b=b+ηyi
其中 η \eta η表示学习率,由自己定值。
2. 流程图和伪代码
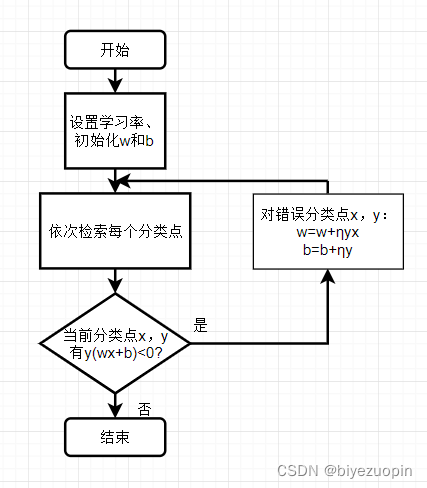
从csv文件读取样本的过程不再赘述。训练集存在列表trainSet中,每个元素为一个样本,每个样本为一个向量,有41维,前40维为40个不同特征的特征值,第41维为标签0或1。为了方便训练过程,我将标签0在读入数据时改为了-1。
设置学习率和初始化w和b:
w = [ 0 for i in range(40)]
b = 0
learningRate = 1
在训练过程中,对每个分类点进行检索并找出误分类点:
/*
input: 数据集trainSet 学习率learningRate 模型参量w和b
output: 训练好的w和b
*/
def train(trainSet, learningRate, w, b){
times = 0
while (times <= 最大迭代次数)
times += 1
w, b = PLA(trainSet, learningRate, w, b)
end
return w, b
}
需要注意的是,当训练集线性不可分时,PLA算法不可能将所有的分类点准确地分成两个部分,每次必然会出现误分类点。如果训练到不出现误分类点时才停止,程序将不会停止。所以需要设置最大迭代次数,即上面代码设定的times。每次迭代时,times加一,当递归次数达到最大值时停止训练。
每次迭代过程的操作如下:
/*
input: 数据集trainSet 学习率learningRate 模型参量w和b
output: 每次迭代后的的w和b
*/
def PLA(trainSet, learningRate, w, b){
for eachSample in trainSet:
num = w和eachSample的向量乘积 + b
/* 出现误分类点,更新参量后直接返回 */
if 当前点为误分类点 then
w = w + learningRate*x*y
b = b + learningRate*y
return w, b
end
/* 没有出现误分类点,返回训练好的w和b */
return w, b
}
验证和测试过程只需要用向量w乘以特征向量x后加上b,依据结果的正负判断预测值即可,这里不再赘述。
3. 代码展示
首先是对训练集的读取:
4. 创新点
在上述的PLA算法中,我尝试在每次出现误分类点时,输出当前误分类点的编号。我发现,在几千条数据样本中,总是在第几十条或是几百条的时候碰到误分类点。每次更新后重新迭代,又要从首个样本开始判断,这就导致了一个问题:在整个数千条的训练样本中,只有前几百条被反复训练了,直到达到最大迭代次数,之后的几千条样本完全都不会训练到。对此,我进行了改进。
经测试,这种方法的耗时远大于设置最大迭代次数的耗时。实际上,即便设置较大的最大迭代次数,在我的测试中,在两三百次迭代后w和b的值就会基本收敛。而设置误分类最大次数会极大增加迭代次数。然而,我的改进方法的准确率的确要比原来的算法高。详细的数据分析见下面的实验结果及分析。
5. 实验结果及分析
在7000条样本中,我选取了前6000条作为训练集,后1000条作为验证集。
首先说明实验要求的PLA算法下的结果。有两个参数可以进行调整:学习率和迭代次数。其中,迭代次数决定了模型是否精确地贴合了训练集的分布。在每次w和b更新后输出二者的值,如果二者几乎没有变化则说明参数已经收敛,更多的迭代次数也几乎没用。而迭代次数过少则模型会欠拟合,显然不利于模型的精度。理论上迭代次数越大越好,尽管过大没有必要。所以下面只讨论学习率对结果的影响,保证在不同的学习率下,迭代次数为10000。
针对不同的学习率,我测试了最后的准确率,结果如下:
| 学习率 | 10 | 1 | 0.1 | 0.01 | 0.001 | 0.0001 | 0.00001 |
|---|---|---|---|---|---|---|---|
| 准确率 | 58.8% | 58.0% | 58.8% | 58.8% | 58.0% | 58.8% | 58.8% |
可以看出,在这种情况下,学习率对准确率的影响不大,几乎是没有影响。原因我认为正如之前分析的,在每次遇到误分类点之后更新权值,重新迭代时又从头开始找误分类点,之后的多数样本都训练不到。少量的样本的学习导致了欠拟合,不管学习率如何,模型本身就不能很好地反映样本的分布,准确率自然也就反常。不过考虑到验证集中有51%的1标签,49%的-1标签,准确率也已经高于了随机值,也就是说模型训练的确还是起到了一定效果的。
接着是我的创新算法的分析,有两个参数可以进行调整:学习率和最大误分类次数。
先设置学习率为1,对不同的最大误分类次数,准确率如下:
| 最大误分类次数 | 1 | 2 | 3 | 4 | 5 | 7 | 10 | 20 |
|---|---|---|---|---|---|---|---|---|
| 准确率 | 75.4% | 76.0% | 77.1% | 76.2% | 76.4% | 76.3% | 76.2% | 76.5% |
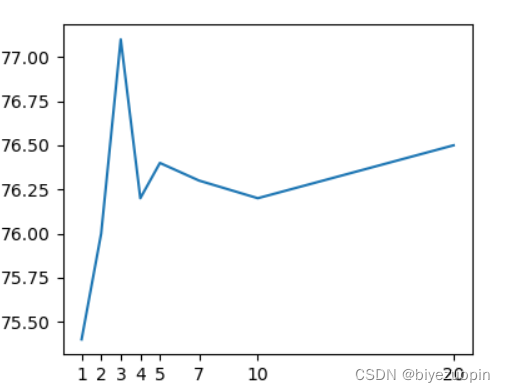
可以看到,在最大误分类次数较小时,出现了明显的准确率峰值,在之后准确率几乎不变。这种结果可以想见:在次数较小时,某些不是比较异常的点被剔除,造成了模型的不准确,而次数较大时,异常点已经多次用于更新模型参数,异常点已经对模型因产生了较大影响,同样也使得模型不精确。
在误分类次数为3时准确率达到最大值。在改次数下,对不同的学习率进行测试:
| 学习率 | 10 | 1 | 0.1 | 0.01 | 0.001 |
|---|---|---|---|---|---|
| 准确率 | 77.1% | 77.1% | 77.1% | 77.1% | 77.1% |
某些不是比较异常的点被剔除,造成了模型的不准确,而次数较大时,异常点已经多次用于更新模型参数,异常点已经对模型因产生了较大影响,同样也使得模型不精确。
在误分类次数为3时准确率达到最大值。在改次数下,对不同的学习率进行测试:
| 学习率 | 10 | 1 | 0.1 | 0.01 | 0.001 |
|---|---|---|---|---|---|
| 准确率 | 77.1% | 77.1% | 77.1% | 77.1% | 77.1% |
在误分类次数为3的前提下改变学习率,在上述的学习率下准确率居然完全没有改变。我觉得应该是在不同的学习率下,剔除的异常点每次都相同,剩下的样本相同且能够被线性分类。考虑到模型参数必然会收敛,小学习率只是会影响收敛快慢,而不会影响模型参数结果,从而导致了相同的结果。
资源下载地址:https://download.csdn.net/download/sheziqiong/85896663
资源下载地址:https://download.csdn.net/download/sheziqiong/85896663