本文是接着上一篇深度学习之 4 深度学习框架_水w的博客-CSDN博客
目录
深度学习框架
PyTorch入门-nn
Torch.nn模块是构建于autograd之上的神经网络模块。
(1)nn.Module:
torch.nn的核心数据结构是Module,它是一个抽象的概念,既可以表示神经网络中的某个层,也可以表示一个包含很多层的
神经网络
。最常见的做法就是继承
nn.Module
,编写自己的网
络。
✓ 能够自动检测到自己的parameter,并将其作为学习参数。
✓ 主Module能够递归查找子Module中的parameter。
为了方便用户使用,PyTorch实现了神经网络中绝大多数的layer,这些layer都继承于nn.Module,封装了可学习参数parameter,并实现了forward函数,且专门针对GPU运算进行了CuDNN优化,其速度和性能都十分优异。
(2)
nn.functional:
nn中还有一个很常用的模块:
nn.funcitonal
。nn中的大多数layer在functional中都有一个与之对应的函数。
nn.functional中的函数和nn.Module的主要区别:✓ nn.Module实现的layers是一个特殊的类,都是由class Layer(nn.Module)定义,会自动提取可学习的参数;✓ 而nn.functional中的函数更像是纯函数,由def function(input)定义。下面举例说明两者之间的区别:示例代码:import torch as t import torch.nn as nn from torch.autograd import Variable as V input=V(t.randn(2,3)) # 一个2x3的输入矩阵 model=nn.Linear(3,4) # 线性变化,一个3x4(按右乘来说)的权重矩阵 output1=model(input) #得到输出方式1,mode已经封装好了weight和bias,相当于y=wx+b #得到输出方式2,自己定义weight和bias ,相当于y=wx+b output2=nn.functional.linear(input,model.weight,model.bias) print(output1==output2)输出结果:tensor([[1, 1, 1, 1],[1, 1, 1, 1]], dtype=torch.uint8) # 得到一个2x4的矩阵注意:
✓ 如果模型有可学习的参数时,最好使用nn.Module;✓ 激活函数(ReLu、sigmoid、Tanh)、池化(MaxPool)等层没有可学习的参数, 可以使用对应的functional函数;✓ 卷积、全连接等有可学习参数的网络建议使用nn.Module;✓ dropout没有可学习参数,建议使用nn.Dropout而不是 nn.functional.dropout;具体层可参照官方文档(https://pytorch.org/docs/stable/index.html),但阅读文档时应主要关注以下几点:• 构造函数的参数,如nn.Linear(in_features, out_features, bias),需关注这三个参数的作用。• 属性、可学习参数和子Module。如nn.Linear中有 weight 和 bias 两个可学习参数,不包含子Module。• 输入输出的形状,如nn.linear的输入形状是(N, input_features),输出(N,output_features),N是batch_size。
(3)
要实现一个自定义层大致分以下几个主要的步骤:
1)自定义一个类,继承自
Module类
,并且一定要实现两个基本的函数
✓ 构造函数__init__
✓ 前向计算函数forward函数
2)在构造函数_init__中实现层的参数定义
。
✓ 例如:Linear层的权重和偏置
✓ Conv2d层的in_channels, out_channels, kernel_size, stride=1,padding=0, dilation=1, groups=1,bias=True, padding_mode='zeros'这一系列参数
3)在前向传播forward函数里面实现前向运算。
✓ 通过torch.nn.functional函数来实现
✓ 自定义自己的运算方式。
如果该层含有权重,那么权重必须是nn.Parameter类型
4)补充:一般情况下,我们定义的参数是可以求导的,但是自定义操作如不可导, 需要实现backward函数。
(4)
优化器:
PyTorch将深度学习中常用的优化方法全部封装在
torch.optim
中,其设计十分灵活,能够很方便地扩展成自定义的优化方法。 所有的优化方法都是继承基类
optim.Optimizer
,并实现了自己的优化步骤。
最基本的优化方法是
随机梯度下降法(SGD)
。需要重点关注的是,优化时如何调整学习率。
PyTorch还能动态修改学习率参数,有以下两种方式:
✓ 修改optimizer.param_groups中对应的学习率。
✓ 新建优化器,由于optimizer十分轻量级,构建开销很小,故可以构建新的optimizer。
◼ 随机梯度下降法(SGD)如果我们的样本非常大,比如数百万到数亿,那么计算量异常巨大。因此,实用的算法是SGD算法。在SGD算法中,每次更新的迭代,只计算一个样本。这样对于一个具有数百万样本的训练数据,完成一次遍历就会对更新数百万次,效率大大提升。代码:#调整学习率,新建一个optimizer old_lr = 0.1 optimizer=optim.SGD([ {'param':net.features.parameters()}, {'param':net.classifiers.parameters(),'lr':old_lr*0.5}],lr=1e-5)
PyTorch入门-常用工具
(1)数据处理:
在PyTorch中,数据加载可通过自定义的数据集对象实现。数据集对象被抽象为 Dataset类 ,实现自定义的数据集需要继承Dataset,并实现两个Python方法。• __getitem__:返回一条数据或一个样本。obj[index]等价于obj.__getitem__(index)。• __len__:返回样本的数量。len(obj)等价于obj.__len__()。Dataset只负责数据的抽象, 一次调用__getitem__ 只返回一个样本。在训练神经网络时,是对一个batch的数据进行操作,同时还需要对数据进行并行加速等。因此,PyTorch提供了 DataLoader 帮助实现这些功能。
◼
DataLoader函数基本处理流程:
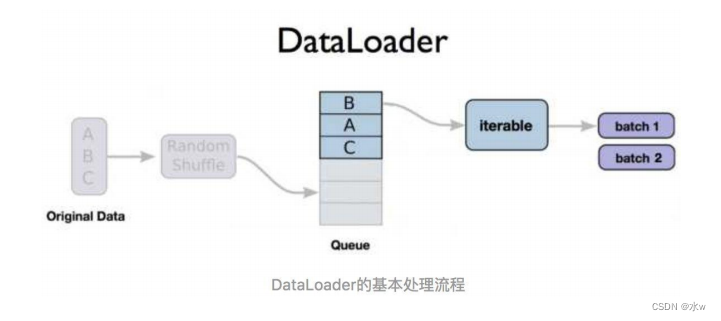
◼ DataLoader函数定义如下:
DataLoader(dataset, batch_size=1, shuffle=False, sampler=None, num_workers=0,
collate_fn=default_collatem, pin_memory=False, drop_last=False)其中,参数解释如下:✓ dataset: 加载的数据集(Dataset对象),✓ batch_size: batch size(批大小),✓ shuffle: 是否将数据打乱,✓ sampler: 样本抽样,✓ num_workers: 使用多进程加载的进程数,0代表不使用多进程,✓ collate_fn: 如何将多个样本数据拼接成一个batch,一般使用默认的拼接方式即可,✓ pin_memory: 是否将数据保存在pin memory区,pin memory中的数据转到GPU会快一些,✓ drop_last: dataset中的数据个数可能不是batch_size的整数倍,drop_last为True会将多出来不足一个batch的数据丢弃。
代码示例:
class MyDataset(Dataset):
# Initialize your data, download, etc.
def __init__(self):
# 读取csv文件中的数据
xy = np.loadtxt('data-diabetes.csv', delimiter=',', dtype=np.float32)
self.len = xy.shape[0] # 除去最后一列为数据位,存在x_data中
self.x_data = torch.from_numpy(xy[:, 0:-1]) # 最后一列作为标签,存在y_data中
self.y_data = torch.from_numpy(xy[:, [-1]])
def __getitem__(self, index):
# 根据索引返回数据和对应的标签
return self.x_data[index], self.y_data[index]
def __len__(self):
# 返回文件数据的数目
return self.len
# 调用自己创建的Dataset
dataset = Mydataset()
# num_workers:使用多进程加载的进程数,与cpu有关。如果此行代码报错,可以尝试改小该变量
train_loader = DataLoader(dataset=dataset, batch_size=32, shuffle=True,num_workers=2)
#循环来迭代来高效地获取数据
for i, data in enumerate(train_loader, 0):
# get the inputs
inputs, labels = data
# wrap them in Variable,变量化
inputs, labels = Variable(inputs), Variable(labels)
# Run your training process
print(step, i, "inputs", inputs.data, "labels", labels.data)(2)计算机视觉工具包:torchvision:
视觉工具包torchvision独立于PyTorch,需要通过pip install torchvision安装。torchvision主要包含以下三个部分:✓ models:提供深度学习中各种经典网络的网络结构及预训练好的模型,包括Net、VGG系列、ResNet系列、Inception系列等。✓ datasets:提供常用的数据集加载,设计上都是继承torch.utils.data.Dataset,主要包括MNIST、CIFAR10/100、ImageNet、COCO等。✓ transforms:提供常用的数据预处理操作,主要包括对Tensor以及PIL Image对象的操作。
◼
torchvision.models
这个包中包含alexnet、densenet、inception、resnet、squeezenet、vgg等常用的网络结构,并且提供了预训练模型,可以通过简单调用来读取网络结构和预训练模型。
代码示例:
#导入了resnet50的预训练模型
import torchvision
model = torchvision.models.resnet50(pretrained=True)
# 如果只需要网络结构,不需要用预训练模型的参数来初始化,那么就是:
model = torchvision.models.resnet50(pretrained=False)
◼
torchvision.datasets
这个包中包含MNIST、FakeData、COCO、LSUN、ImageFolder、 DatasetFolder、ImageNet、CIFAR等一些常用的数据集,并且提供了数据集设置的一些重要参数设置,可以通过简单数据集设置来进行数据集的调用。
◼
数据集的接口
基本上很相近。它们至少包括两个公共的参数
transform
和
target_transform
,以便
分别对输入和目标做变换。所有数据集的子类torch.utils.data.Dataset采用 __getitem__和 __len__方法来实现。
代码示例:
imagenet_data = torchvision.datasets.ImageNet('path/to/imagenet_root/')
data_loader = torch.utils.data.DataLoader(imagenet_data, batch_size=4, shuffle=True, num_workers=args.nThreads)
◼
以MNIST数据集为例:
torchvision.datasets.MNIST(root,train = True,transform = None,target_transform = None,download = False )➢ 参数介绍:✓ root(string) - 数据集的根目录在哪里MNIST/processed/training.pt 和 MNIST/processed/test.pt存在;✓ train(bool,optional) - 如果为True,则创建数据集training.pt,否则创建数据集test.pt;✓ download(bool,optional) - 如果为true,则从Internet下载数据集并将其放在根目录中。如果已下载数据集,则不会再次下载;✓ transform(callable ,optional) - 一个函数/转换,它接收PIL图像并返回转换后的版本。例如, transforms.RandomCrop;✓ target_transform(callable ,optional) - 接收目标并对其进行转换的函数/转换。
(3)使用GPU加速:
在PyTorch中以下数据结构分为CPU和GPU两个版本。➢ Tensor➢ nn.Module(包括常用的layer、loss function,以及容器sequential等)它们都带有一个.cuda方法,调用此方法即可将其转化为对应的GPU对象。如果服务器具有多个GPU, tensor.cuda() 方法会将tensor保存到第一块GPU上,等价于 tensor.cuda(0) 。此时如果想使用第二块GPU,需要手动指定 tensor.cuda(1) ,而这需要修改大量代码很繁琐。这里有两种替代方式。
GPU的使用:
✓ 调用
t.cuda.set_device(1)
指定使用第二块GPU,后续的.cuda()都无需更改,切换GPU只需修改这一行代码。
✓ 设置环境变量CUDA_VISIBLE_DEVICES,如:
export CUDA_VISIBLE_DEVICE=1时(下标是从0开始,1代表第二块GPU)
✓ CUDA_VISIBLE_DEVICES还可以指定多个GPU,如:
export CUDA_VISIBLE_DEVICES = 0,2,3(下标是从0开始,0代表第一块GPU,2代表第三块GPU,3代表第四块GPU)(4)保存和加载:
在PyTorch中,需要将Tensor、Variable等对象保存到硬盘,以便后续能通过相应的方法加载到内存中。✓ 这些信息最终都是保存成Tensor。✓ 使用t.save和t.load即可完成Tensor保存和加载的功能。✓ 在save/load时可指定使用的pickle模块,在load时还可以将GPU tensor映射到CPU或其他GPU上。✓ 使用方式:t.save(obj, file_name) # 保存任意可序列化的对象。 obj = t.load(file_name) # 方法加载保存的数据。
自定义的简单例子: ➢ y=w*sqrt(X²+bias)
1)定义一个自定义层MyLayer
"""1、定义一个自定义层MyLayer"""
class MyLayer(torch.nn.Module):
def __init__(self, in_features, out_features, bias=True):
super(MyLayer, self).__init__() # 和自定义模型一样,第一句话就是调用父类的构造函数
self.in_features = in_features
self.out_features = out_features
self.weight = torch.nn.Parameter(torch.Tensor(in_features, out_features)) # 由于weights是可以训练的,所以使用Parameter来定义
if bias:
# 由于bias是可以训练的,所以使用Parameter来定义
self.bias = torch.nn.Parameter(torch.Tensor(in_features))
else:
self.register_parameter('bias', None)
def forward(self, input):
input_=torch.pow(input,2)+self.bias
y=torch.matmul(input_,self.weight)
return y
2)自定义模型并且训练
"""2、自定义模型并且训练"""
import torch
from my_layer import MyLayer # 自定义层
N, D_in, D_out = 10, 5, 3 # 一共10组样本,输入特征为5,输出特征为3
# 先定义一个模型
class MyNet(torch.nn.Module):
def __init__(self):
super(MyNet, self).__init__() # 第一句话,调用父类的构造函数
self.mylayer1 = MyLayer(D_in,D_out)
def forward(self, x):
x = self.mylayer1(x)
return x
model = MyNet()
print(model)
运行结果为:
MyNet(
(mylayer1): MyLayer() # 这就是自己定义的一个层
)3)开始训练
# 创建输入、输出数据
x = torch.randn(N, D_in) #(10,5)
y = torch.randn(N, D_out) #(10,3)
loss_fn = torch.nn.MSELoss(reduction='sum') #定义损失函数
learning_rate = 1e-4 #定义学习率
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate) #构造一个optimizer对象
for t in range(10): # 10代表迭代10次
# 第一步:数据的前向传播,计算预测值p_pred
y_pred = model(x)
# 第二步:计算预测值p_pred与真实值的误差,输出损失
loss = loss_fn(y_pred, y)
print(f"第 {t} 个epoch, 损失是 {loss.item()}")
# 在反向传播之前,将模型的梯度归零
optimizer.zero_grad()
# 第三步:反向传播误差。
loss.backward() # loss已经是标量了,所以backward()不需要传参
# 梯度更新:直接通过梯度一步到位,更新完整个网络的训练参数
optimizer.step()PyTorch入门-例子
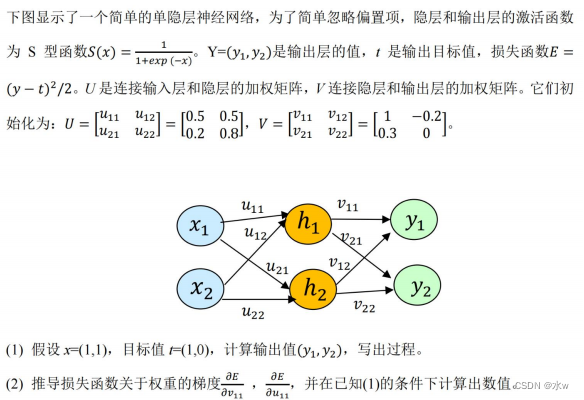

后续学习可以参考书籍和博客:
1、参考博客: https://blog.csdn.net/qq_27825451/article/details/90705328
2、参考博客: https://blog.csdn.net/weixin_38664232/article/details/94662534
3、参考博客: https://blog.csdn.net/sinat_42239797/article/details/93916790
4、参考博客: https://blog.csdn.net/u014380165/article/details/79119664
5、参考书籍: 深度学习框架PyTorch:入门与实践_陈云(著)
6、参考书籍: python深度学习(基于Pytorch),吴茂贵著。
7、参考书籍: 深入浅出Pytorch—从模型到源码,张校捷著。