前后端编程语言杂谈
参考文献链接
https://mp.weixin.qq.com/s/NfkPxf-3gJURE2TIbM6InA
https://mp.weixin.qq.com/s/jjT0x99ht8xtfWmzL-0R1A
https://mp.weixin.qq.com/s/YAhX5895meSHENZSAe184w
https://mp.weixin.qq.com/s/DJzKXDYz4fD8zc1Ln_dK7g
C++20 以 Bazel & Clang 开始
C++20 如何以 Bazel & Clang 进行构建呢?
本节将介绍:
• Bazel[1] 构建系统的安装
• LLVM[2] 编译系统的安装
Clang[3] is an “LLVM native” C/C++/Objective-C compiler
• Bazel Clang 工具链的配置
• C++20 库与应用的构建
示例可见:https://github.com/ikuokuo/start-cpp20
Ubuntu 20 上进行的实践,Windows 可以用 WSL 准备环境。
安装 Bazel,以二进制方式
Bazelisk[4] 是安装 Bazel 的推荐方式,安装二进制发布[5]即可:
cd ~
wget https://github.com/bazelbuild/bazelisk/releases/download/v1.12.0/bazelisk-linux-amd64 -O bazelisk-1.12.0-linux-amd64
chmod a+x bazelisk-*
sudo ln -s $(pwd)/bazelisk-1.12.0-linux-amd64 /usr/local/bin/bazel
touch WORKSPACE
国内下载 Bazel 可能遇到如下问题,配置 .bazeliskrc 解决
could not resolve the version ‘latest’ to an actual version number
https://github.com/bazelbuild/bazelisk/issues/220
cat <<-EOF > .bazeliskrc
BAZELISK_BASE_URL=https://github.com/bazelbuild/bazel/releases/download
USE_BAZEL_VERSION=5.2.0
EOF
bazel version
更多方式,可见官方文档[6]。进一步,推荐安装 buildtools[7],下载后软链一下:
sudo ln -s $(pwd)/buildifier-5.1.0-linux-amd64 /usr/local/bin/buildifier
sudo ln -s $(pwd)/buildozer-5.1.0-linux-amd64 /usr/local/bin/buildozer
Bazel 如何构建 C++ 项目,可见 Start Bazel[8] 笔记。
安装 LLVM,以源码方式
Clang 有关 std::fromat 文本格式化的特性,默认未开启:
The paper is implemented but still marked as an incomplete feature (the feature-test macro is not set and the libary is only available when built with LIBCXX_ENABLE_INCOMPLETE_FEATURES). Not yet implemented LWG-issues will cause API and ABI breakage.
C++20 特性,编译器支持情况:
• C++ compiler support[9]
• libc++ C++20 Status[10]
因此,这里以源码方式安装 LLVM,需要构建 Clang & libc++:
• Building Clang[11]
• Building libc++[12]
git clone -b llvmorg-14.0.6 --depth 1 https://github.com/llvm/llvm-project.git
cd llvm-project
mkdir _build
cd _build
llvm install path, such as /usr/local/llvm
LLVM_PREFIX=$HOME/Apps/llvm-14.0.6
cmake -DCMAKE_BUILD_TYPE=Release
-DCMAKE_INSTALL_PREFIX=$LLVM_PREFIX
-DLLVM_ENABLE_PROJECTS=clang
-DLLVM_ENABLE_RUNTIMES=“libcxx;libcxxabi”
-DLIBCXX_ENABLE_INCOMPLETE_FEATURES=ON
…/llvm
make -jnproc
make install
sudo ln -s $LLVM_PREFIX /usr/local/llvm
cat <<-EOF >> ~/.bashrc
llvm
export LLVM_HOME=/usr/local/llvm
export PATH=$LLVM_HOME/bin:$PATH
export LD_LIBRARY_PATH=$LLVM_HOME/lib/x86_64-unknown-linux-gnu:$LD_LIBRARY_PATH
EOF
llvm-config --version
clang --version
LLVM_PREFIX 安装路径自己决定。最后,编译测试:
cat <<-EOF > hello.cc
#include
#include
int main() {
std::string message = std::format(“The answer is {}.”, 42);
std::cout << message << std::endl;
}
EOF
clang++ -std=c++20 -stdlib=libc++ hello.cc -o hello
./hello
安装 LLVM,以二进制方式
可省略该节。本节实践未用此方式,因为想开启更多 C++20 特性。这里仅作记录,有需要可参考。
方式 1. 安装二进制发布[13]:
cd ~
wget https://github.com/llvm/llvm-project/releases/download/llvmorg-13.0.0/clang+llvm-13.0.0-x86_64-linux-gnu-ubuntu-20.04.tar.xz
tar -xf clang+llvm-*.tar.xz
sudo ln -s $(pwd)/clang+llvm-13.0.0-x86_64-linux-gnu-ubuntu-20.04 /usr/local/llvm
cat <<-EOF >> ~/.bashrc
llvm
export LLVM_HOME=/usr/local/llvm
export PATH=$LLVM_HOME/bin:$PATH
EOF
llvm-config --version
clang --version
方式 2. 用 apt 进行安装:https://apt.llvm.org/
方式 3. 用已配好的工具链:LLVM toolchain for Bazel[14]
配置 Clang 工具链
本节依照 Bazel Tutorial: Configure C++ Toolchains[15] 步骤配置的 Clang 工具链,最后项目根目录会多如下文件:
• WORKSPACE[16]
• .bazelrc[17]
• toolchain/BUILD[18]
• toolchain/cc_toolchain_config.bzl[19]
WORKSPACE 表示 Bazel 工作区,内容空。
.bazelrc 允许 --config=clang_config 启用 Clang 工具链:
Use our custom-configured c++ toolchain.
build:clang_config --crosstool_top=//toolchain:clang_suite
Use --cpu as a differentiator.
build:clang_config --cpu=linux_x86_64
Use the default Bazel C++ toolchain to build the tools used during the build.
build:clang_config --host_crosstool_top=@bazel_tools//tools/cpp:toolchain
toolchain/BUILD 配置 Clang 工具链信息:
load(“:cc_toolchain_config.bzl”, “cc_toolchain_config”)
package(default_visibility = [“//visibility:public”])
#filegroup(name = “clang_suite”)
cc_toolchain_suite(
name = “clang_suite”,
toolchains = {
“linux_x86_64”: “:linux_x86_64_toolchain”,
},
)
filegroup(name = “empty”)
cc_toolchain(
name = “linux_x86_64_toolchain”,
toolchain_identifier = “linux_x86_64-toolchain”,
toolchain_config = “:linux_x86_64_toolchain_config”,
all_files = “:empty”,
compiler_files = “:empty”,
dwp_files = “:empty”,
linker_files = “:empty”,
objcopy_files = “:empty”,
strip_files = “:empty”,
supports_param_files = 0,
)
#filegroup(name = “linux_x86_64_toolchain_config”)
cc_toolchain_config(name = “linux_x86_64_toolchain_config”)
toolchain/cc_toolchain_config.bzl 配置 Clang 工具链规则:
C++ Toolchain Configuration
https://bazel.build/docs/cc-toolchain-config-reference
https://github.com/bazelbuild/bazel/blob/master/tools/build_defs/cc/action_names.bzl
load(“@bazel_tools//tools/build_defs/cc:action_names.bzl”, “ACTION_NAMES”)
load(
“@bazel_tools//tools/cpp:cc_toolchain_config_lib.bzl”,
“feature”,
“flag_group”,
“flag_set”,
“tool_path”,
)
all_compile_actions = [
ACTION_NAMES.c_compile,
ACTION_NAMES.cpp_compile,
ACTION_NAMES.linkstamp_compile,
ACTION_NAMES.assemble,
ACTION_NAMES.preprocess_assemble,
ACTION_NAMES.cpp_header_parsing,
ACTION_NAMES.cpp_module_compile,
ACTION_NAMES.cpp_module_codegen,
]
all_link_actions = [
ACTION_NAMES.cpp_link_executable,
ACTION_NAMES.cpp_link_dynamic_library,
ACTION_NAMES.cpp_link_nodeps_dynamic_library,
]
def _impl(ctx):
llvm_version = “14.0.6”
llvm_prefix = “/home/john/Apps/llvm-{}”.format(llvm_version)
llvm_bindir = llvm_prefix + “/bin”
tool_paths = [
tool_path(
name = "gcc",
path = llvm_bindir + "/clang",
),
tool_path(
name = "ld",
path = llvm_bindir + "/ld.lld",
),
tool_path(
name = "ar",
path = llvm_bindir + "/llvm-ar",
),
tool_path(
name = "cpp",
path = llvm_bindir + "/clang-cpp",
),
tool_path(
name = "gcov",
path = llvm_bindir + "/llvm-cov",
),
tool_path(
name = "nm",
path = llvm_bindir + "/llvm-nm",
),
tool_path(
name = "objdump",
path = llvm_bindir + "/llvm-objdump",
),
tool_path(
name = "strip",
path = llvm_bindir + "/llvm-strip",
),
]
features = [
feature(
name = "default_compiler_flags",
enabled = True,
flag_sets = [
flag_set(
actions = all_compile_actions,
flag_groups = ([
flag_group(
flags = [
"-O2", "-DNDEBUG",
"-Wall", "-Wextra", "-Wpedantic", "-fPIC",
"-std=c++20", "-stdlib=libc++",
],
),
]),
),
],
),
feature(
name = "default_linker_flags",
enabled = True,
flag_sets = [
flag_set(
actions = all_link_actions,
flag_groups = ([
flag_group(
flags = [
"-lc++", "-lc++abi",
"-lm", "-ldl", "-lpthread",
],
),
]),
),
],
),
]
return cc_common.create_cc_toolchain_config_info(
ctx = ctx,
features = features,
cxx_builtin_include_directories = [
llvm_prefix + "/lib/clang/{}/include".format(llvm_version),
llvm_prefix + "/include/x86_64-unknown-linux-gnu/c++/v1",
llvm_prefix + "/include/c++/v1",
"/usr/local/include",
"/usr/include/x86_64-linux-gnu",
"/usr/include",
],
toolchain_identifier = "local",
host_system_name = "local",
target_system_name = "local",
target_cpu = "linux_x86_64",
target_libc = "unknown",
compiler = "clang",
abi_version = "unknown",
abi_libc_version = "unknown",
tool_paths = tool_paths,
)
cc_toolchain_config = rule(
implementation = _impl,
attrs = {},
provides = [CcToolchainConfigInfo],
)
llvm_prefix 给到自己的 LLVM 安装路径。
构建 C++20 库与应用
本节示例的 code/00/[20] 路径下准备了 C++20 的库与应用:
code/00/
├── BUILD
├── greet
│ ├── BUILD
│ ├── greet.cc
│ └── greet.h
└── main.cc
编写 binary
main.cc:
#include
#include
#include
#include <string_view>
#include “greet/greet.h”
template <typename… Args>
std::string dyna_print(std::string_view rt_fmt_str, Args&&… args) {
return std::vformat(rt_fmt_str, std::make_format_args(args…));
}
int main() {
std::cout << greet::hello(“world”) << std::endl;
std::string fmt;
for (int i{}; i != 3; ++i) {
fmt += "{} “; // constructs the formatting string
std::cout << fmt << " : “;
std::cout << dyna_print(fmt, “alpha”, ‘Z’, 3.14, “unused”);
std::cout << ‘\n’;
}
}
BUILD:
load(”@rules_cc//cc:defs.bzl”, “cc_binary”)
cc_binary(
name = “main”,
srcs = [“main.cc”],
deps = [
“//code/00/greet:greet”,
],
)
编写 library
greet.h:
#pragma once
#include
#include <string_view>
namespace greet {
std::string hello(std::string_view who);
} // namespace greet
greet.cc:
#include “greet.h”
#include
#include
namespace greet {
std::string hello(std::string_view who) {
return std::format(“Hello {}!”, std::move(who));
}
} // namespace greet
BUILD:
load(“@rules_cc//cc:defs.bzl”, “cc_library”)
package(default_visibility = [“//visibility:public”])
cc_library(
name = “greet”,
srcs = [
“greet.cc”,
],
hdrs = [
“greet.h”,
],
)
Bazel 构建
bazel build --config=clang_config //code/00:main
运行测试
$ bazel-bin/code/00/main
Hello world!
{} : alpha
{} {} : alpha Z
{} {} {} : alpha Z 3.14
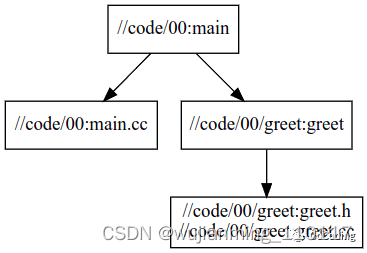
查看依赖
sudo apt update && sudo apt install graphviz xdot -y
view
xdot <(bazel query --notool_deps --noimplicit_deps “deps(//code/00:main)” --output graph)
to svg
dot -Tsvg <(bazel query --notool_deps --noimplicit_deps “deps(//code/00:main)” --output graph) -o 00_main.svg
参考
• Bazel Tutorial
Configure C++ Toolchains[21]
Build a C++ Project[22]
• Bazel Issue
Support C++20 modules #4005[23]
• Project Example
How to Use C++20 Modules with Bazel and Clang[24]
bazel-cpp20: Template for bazel with C++20[25]
Clang toolchain[26]
脚注
[1]
Bazel: https://bazel.build/
[2]
LLVM: https://llvm.org/
[3]
Clang: https://clang.llvm.org/
[4]
Bazelisk: https://github.com/bazelbuild/bazelisk
[5]
二进制发布: https://github.com/bazelbuild/bazelisk/releases
[6]
官方文档: https://bazel.build/install
[7]
buildtools: https://github.com/bazelbuild/buildtools/releases
[8]
Start Bazel: https://github.com/ikuokuo/start-cpp20/blob/main/tutorials/start-bazel/README.md
[9]
C++ compiler support: https://en.cppreference.com/w/cpp/compiler_support
[10]
libc++ C++20 Status: https://libcxx.llvm.org/Status/Cxx20.html
[11]
Building Clang: https://clang.llvm.org/get_started.html
[12]
Building libc++: https://libcxx.llvm.org/BuildingLibcxx.html
[13]
二进制发布: https://github.com/llvm/llvm-project/releases
[14]
LLVM toolchain for Bazel: https://github.com/grailbio/bazel-toolchain
[15]
Bazel Tutorial: Configure C++ Toolchains: https://bazel.build/tutorials/cc-toolchain-config
[16]
WORKSPACE: https://github.com/ikuokuo/start-cpp20/blob/main/WORKSPACE
[17]
.bazelrc: https://github.com/ikuokuo/start-cpp20/blob/main/.bazelrc
[18]
toolchain/BUILD: https://github.com/ikuokuo/start-cpp20/blob/main/toolchain/BUILD
[19]
toolchain/cc_toolchain_config.bzl: https://github.com/ikuokuo/start-cpp20/blob/main/toolchain/cc_toolchain_config.bzl
[20]
code/00/: https://github.com/ikuokuo/start-cpp20/tree/main/code/00
[21]
Configure C++ Toolchains: https://bazel.build/tutorials/cc-toolchain-config
[22]
Build a C++ Project: https://bazel.build/tutorials/cpp
[23]
Support C++20 modules #4005: https://github.com/bazelbuild/bazel/issues/4005
[24]
How to Use C++20 Modules with Bazel and Clang: https://buildingblock.ai/cpp20-modules-bazel
[25]
bazel-cpp20: Template for bazel with C++20: https://github.com/jwmcglynn/bazel-cpp20
[26]
Clang toolchain: https://github.com/hlopko/clang_toolchain
深度学习的IR“之争”
熟悉编译器的同学应该对上图并不陌生。就是大名鼎鼎的LLVM的logo。Google Tensorflow XLA (Accelerated Linear Algebra)就使用了LLVM IR(Intermediate Representation)。而“竞争对手”,发布的TVM/NNVM/RELAY,则是“Tensor IR Stack for Deep Learning Systems”。IR是什么?为什么重要?
看到这样的新闻“Facebook and Microsoft introduce new open ecosystem for interchangeable AI frameworks”。这也让Framework之争更加热闹。简单来说,ONNX也是为了解决目前多个Framework互操作的问题。但有趣的是,这个“开放”的系统看起来更像是微软和FB连合对抗Google。目前Tensorflow的占有率已经领先不少,其它的Framework肯定也不希望看到Tensorflow一家独大,毕竟Framework是做deep learning的一个“入口”。最近PyTorch的势头不错,Caffe2, PyTorch和Cognitive Toolkit通过这种方式“联合”,似乎也是个不错的选择。
“An Intermediate representation (IR) is the data structure or code used internally by a compiler or virtual machine to represent source code. An IR is designed to be conducive for further processing, such as optimization and translation. A “good” IR must be accurate – capable of representing the source code without loss of information – and independent of any particular source or target language. An IR may take one of several forms: an in-memory data structure, or a special tuple- or stack-based code readable by the program. In the latter case it is also called an intermediate language.” - Wikipedia
还是从目前Deep Learning的一个现实问题说起吧。
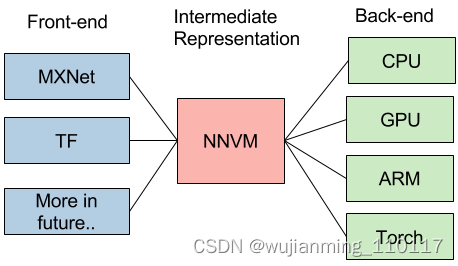
上图来自介绍NNVM的一篇文章[1]。文中在谈到NNVM的目标的时候,是这么说的:
“This is a new interesting era of deep learning, with emergence trend of new system, hardware and computational model. The usecase for deep learning is more heterogeneous, and we need tailored learning system for our cars, mobiles and cloud services. The future of deep learning system is going to be more heterogeneous, and we will find emergence need of different front-ends, backends and optimization techniques. Instead of building a monolithic solution to solve all these problems, how about adopt unix philosophy, build effective modules for learning system, and assemble them together to build minimum and effective systems?”
简单来说,现在Deep Learning有这么多不同前端(framework),有这么多不同的后端(hardware),是否能找到一个桥梁更有效实现之间的优化和影射呢?
实际上这个问题并不新鲜。当年,随着不同的应用场景和需求,出现了大量不同的编程语言和不同的处理器架构,软件产业也遇到过类似的问题。
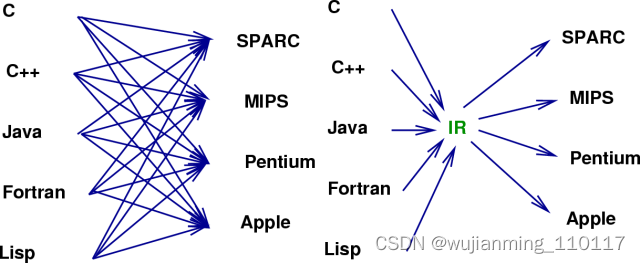
换句话说,这也正是重演了LLVM出现时的场景:大量不同的编程语言和越来越多的硬件架构之间需要一个桥梁。LLVM的出现,让不同的前端后端使用统一的 LLVM IR ,如果需要支持新的编程语言或者新的设备平台,只需要开发对应的前端和后端即可。同时基于 LLVM IR 可以很快的开发自己的编程语言。比如,LLVM创建者Chris Lattner后来加入了Apple,又创建了Swift语言,可以看作是LLVM的前端。
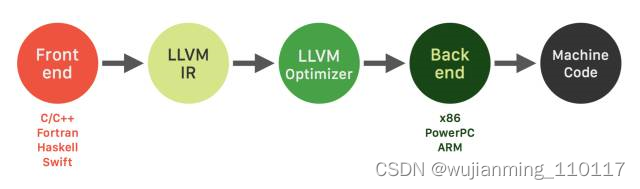
由此也可以看出,LLVM统一的IR是成功的关键之一,也充分说明了一个优秀IR的重要性。
当然,IR本质上是一种中间表示形式,是一个完整编译工具的一部分。而下面讨论的TVM,XLA都是围绕特定IR构建的优化和编译工具。
陈天奇在另一篇文章中提到:“…对于深度学习,需要类似的项目。学习 LLVM 的思想,将其取名 NNVM”。(2016年10月)
8月17号,陈天奇的团队又发布了TVM:An End to End IR Stack for Deploying the Deep Learning Workloads to Hardwares[2],其架构如下图所示:
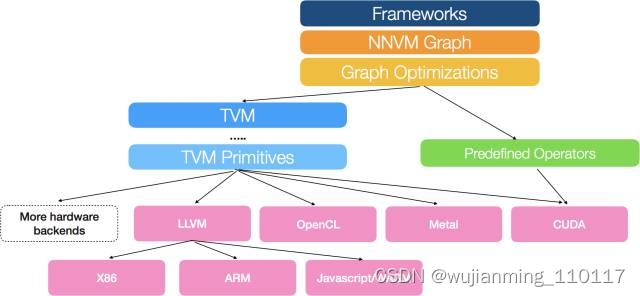
We adopt a common philosophy from the compiler community and provide two intermediate representation layers to efficiently lower high-level deep learning algorithms down to a multitude of hardware back-ends.
可以看出,在之前的NNVM之外上增加了一个新的IR Stack,TVM,试图解决下图所示的Gap,“A lot of powerful optimizations can be supported by the graph optimization framework. …However we find that the computational graph based IR alone is not enough to solve the challenge of supporting different hardware backends. ”这里的graph based IR则是指NNVM。
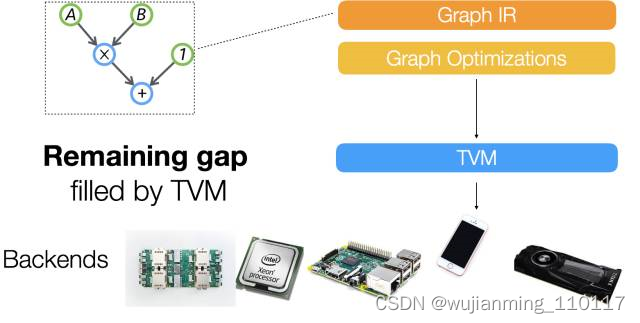
在LLVM环境中,只有一个统一的IR。那么,为什么Deep Learning环境中graph based IR还不够呢?在随后的一篇知乎文章中[3],陈天奇提到了去年10月知乎上关于“如何评价陈天奇的模块化深度学习系统NNVM?”的讨论[4]。而这个讨论中王健飞的回答似乎是TVM产生的灵感之一。
同样在这篇文章当中,陈天奇还提到,“TVM和已有的解决方案不同,以XLA作为例子,TVM走了和目前的XLA比更加激进的技术路线,TVM可以用来使得实现XLA需要的功能更加容易 ”。
既然TVM的作者点了对手的名,就来看看Google的XLA吧。
XLA (Accelerated Linear Algebra) is a domain-specific compiler for linear algebra that optimizes TensorFlow computations. The results are improvements in speed, memory usage, and portability on server and mobile platforms. Initially, most users will not see large benefits from XLA, but are welcome to experiment by using XLA via just-in-time (JIT) compilation or ahead-of-time (AOT) compilation. Developers targeting new hardware accelerators are especially encouraged to try out XLA.
下图左半部分来自“2017 EuroLLVM Deveopers’ Meeting”上的一个报告[6],比较清楚介绍了XLA的目标,其基本功能也是优化和代码生成。
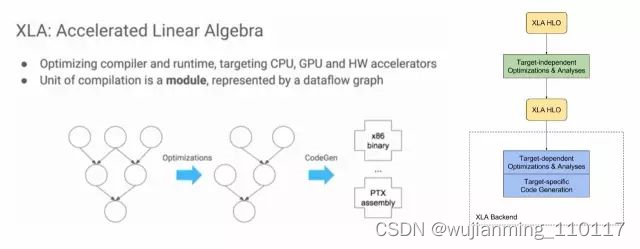
XLA具体的架构如图右半部分所示,可以看出,也是两层优化的结构[5],使用LLVM用作low-level IR, optimization, and code-generation。由于使用了LLVM IR, 他可以比较容易的支持不同的后端(Backend)。下图就是使用GPU Backend的例子。
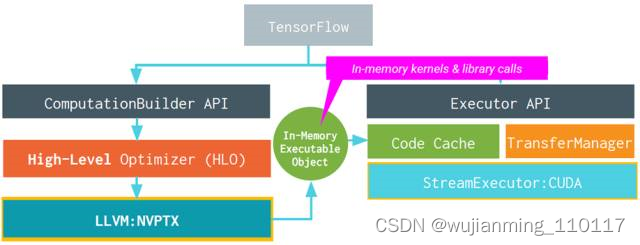
对于目前不直接支持的后端,XLA给出了三种场景的开发方法。包括:
- Existing CPU architecture not yet officially supported by XLA, with or without an existing LLVM backend.
- Non-CPU-like hardware with an existing LLVM backend.
- Non-CPU-like hardware without an existing LLVM backend.
总的来说,XLA和TVM试图解决的问题类似。但XLA只是针对Google的Tensorflow的。而TVM/NNVM虽然是MxNe阵营,但试图作为一个开发和公共的接口。
这里插播一个新闻,Chris Lattner最近加入了Google Brain。虽然还不知道主要工作是不是会放在XLA这里,但是他和Jeff Dean配合,确实是令人生畏。
由于自己并没有亲自使用过这两个工具,所以也不能给出更准确的评价和对比。对具体细节感兴趣的读者可以好好看看Reference的内容,并且亲自尝试一下。
其实,类似的想法还包括:Intel’s NGraph(如下图),HP的Cognitive Computing Toolkit (CCT), IBM的SystemML。
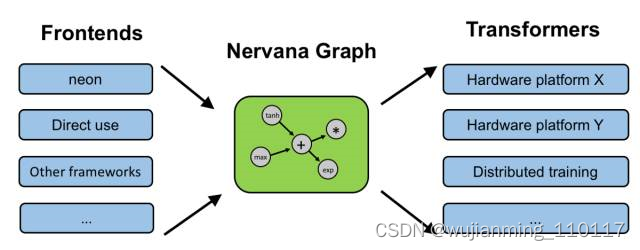
而在刚刚结束的Hot Chips会议上,Microsoft发布了Project Brainwave,Cloud的AI FPGA加速平台。工具链是这样的,是不是又看到了两层IR?
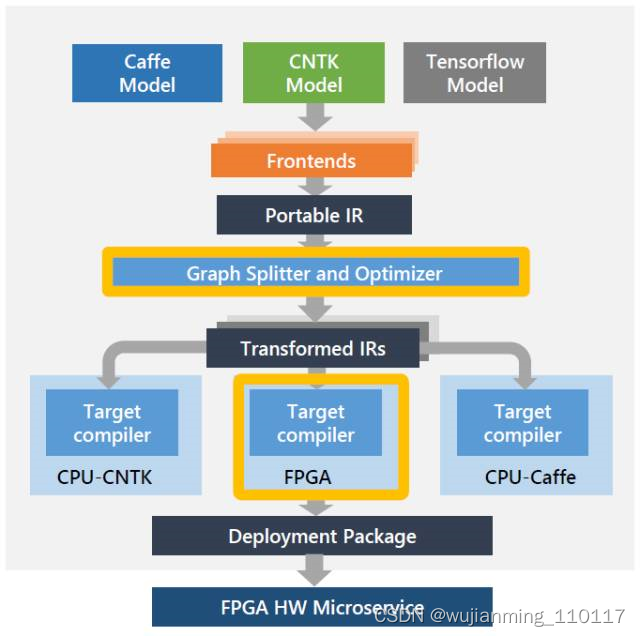
最后,最近还看到另一个有趣的尝试:Khronos Neural Network Exchange Format (NNEF),试图定义一种标准的数据交换格式。“The NNEF standard encapsulates neural network structure, data formats, commonly used operations (such as convolution, pooling, normalization, etc.) and formal network semantics. ”
T.S.:
随着Deep Learning的应用越来越广,大家越来越关心DNN在不同硬件架构上Training和Inference的实现效率。参考传统编译器(compiler)设计的经验,XLA和TVM/NNVM都开始了很好的尝试。而“IR”的竞争,将是未来Framework之争的重要一环。
Reference:
[1]陈天奇, “Build your own TensorFlow with NNVM and Torch”, http://tqchen.github.io/2016/10/01/build-your-own-tensorflow-with-nnvm-and-torch.html
[2]陈天奇, “TVM: An End to End IR Stack for Deploying the Deep Learning Workloads to Hardwares”,http://tvmlang.org/2017/08/17/tvm-release-announcement.html
[3]陈天奇, “如何评价陈天奇团队新开源的TVM?”, https://www.zhihu.com/question/64091792/answer/217722459
[4] 王健飞,“如何评价陈天奇的模块化深度学习系统NNVM?”,https://www.zhihu.com/question/51216952/answer/124708405
[5]“XLA Overview”, https://www.tensorflow.org/performance/xla/
[6]“2017 EuroLLVM Developers’ Meeting: D. Majnemer “XLA: Accelerated Linear Algebra””,https://www.youtube.com/watch?v=2IOPpyyuLkc
[7]“A Brief Introduction to LLVM”, https://www.youtube.com/watch?v=a5-WaD8VV38"
[8]“XLA: TensorFlow Compiled!”,https://www.youtube.com/watch?v=kAOanJczHA0
An NVPTX To LLVM IR Frontend
CAUTION 1:大家好,其实并没有学过CUDA和NVPTX,连LLVM IR也才刚学了三天,所以请大家批判地看这篇总结,有条件建议还是去看原始资料;
CAUTION 2:因为作者讲的很简略,缺少很多实现细节,所以他没有讲到的也不知道,以目前的水平脑补不出来。。。。。。
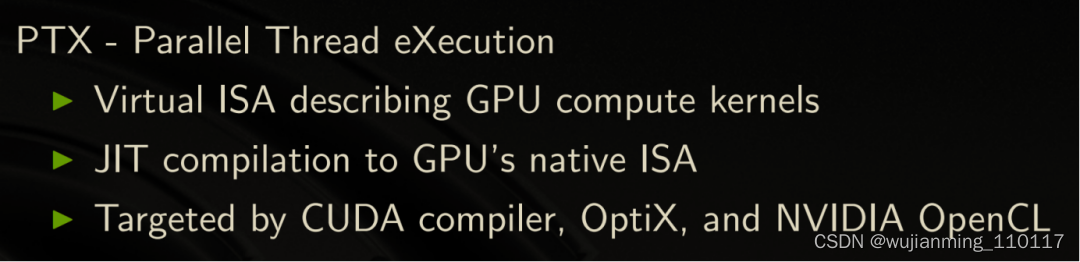
NVPTX是描述NVIDIA GPU核函数计算的虚拟的指令集,类似于机器指令,但不是真实的指令,会以JIT编译的方式生成GPU native ISA,是NVCC要生成的Target。
动机:
LLVM IR是平台无关的中间表示,正常情况下NVCC编译是把.cu转成.ll再转成NVPTX的二进制文件,可是如果可以把NVPTX转成IR再把IR编译成X86指令集或是Vega指令集的目标文件,就可以在X86平台或是AMDGPU上跑已经得不到源码的NVPTX二进制程序。PLANG就是把NVPTX转换成LLVM IR的工具。
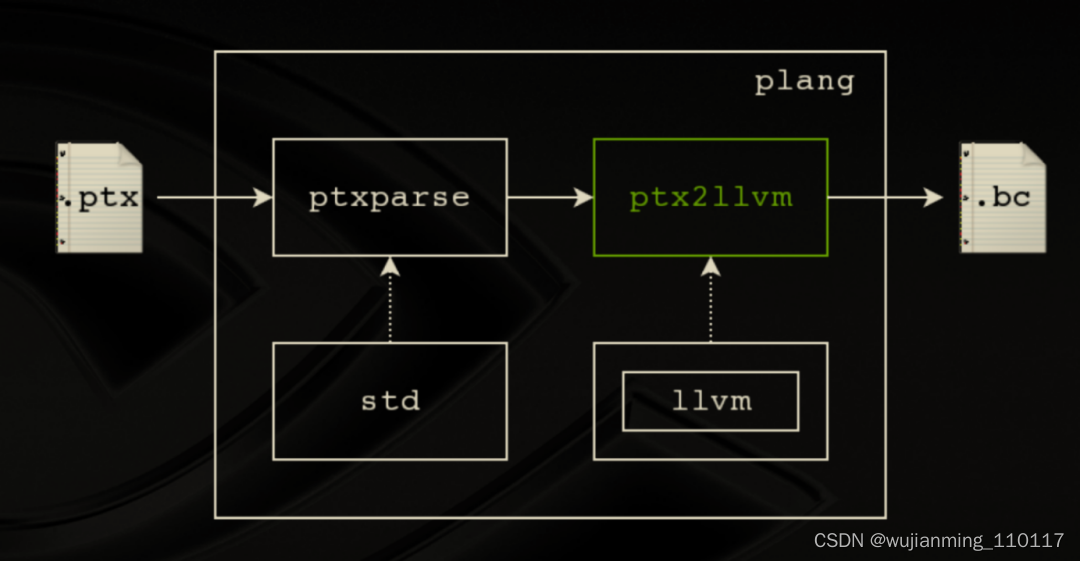
实现方法:
NVPTX和LLVM IR两种Assembly存在语言特性上的差异,所以需要对不一样的地方进行转换。
- Non-SSA to SSA
因为NVPTX是非SSA的,所以NVPTX对虚拟寄存器的分配对应于LLVM IR的alloca分配内存对象;
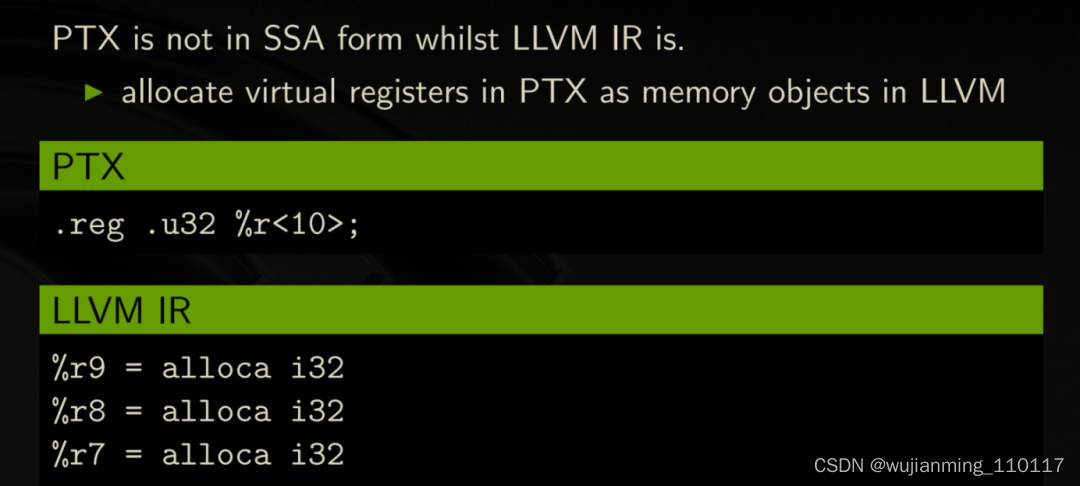
并且涉及寄存器赋值的运算指令需要翻译成LLVM IR的load至临时变量、临时变量静态单赋值的运算、然后再store回内存对象的多条LLVM IR指令;

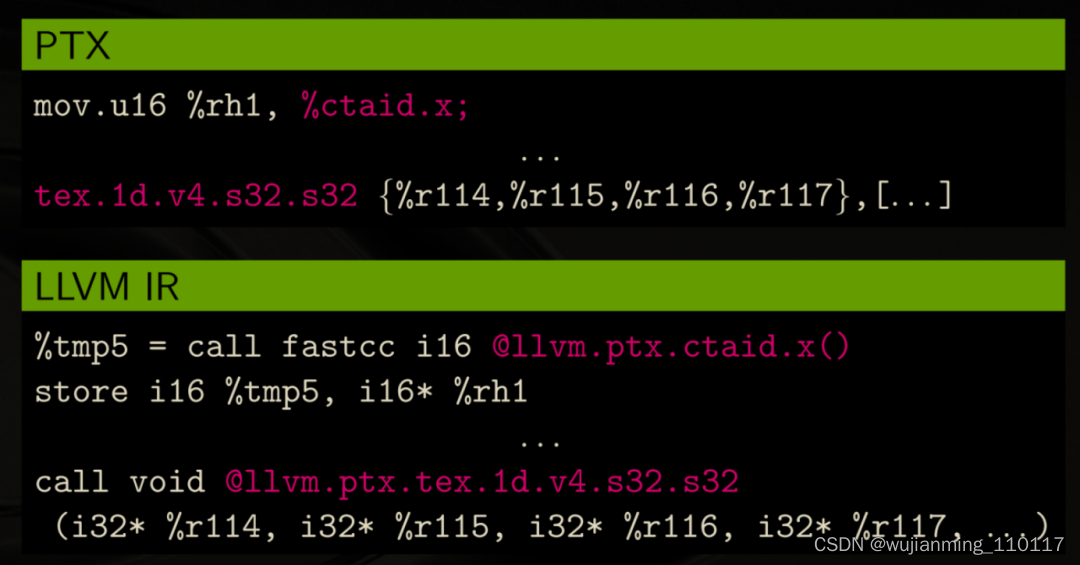
- 特殊NVPTX寄存器/指令 to LLVM Intrinsics
这类的NVPTX特殊寄存器/指令包含有特殊的功能,所以先转成LLVM Intrinsics,然后将来在LLVM IR去生成特定目标代码时(例如Vega GPU)再基于特定的目标平台去实现其功能。

例如,把在ptx level下(特殊寄存器:ctaid)的register move转换成一条Intrinsic call赋值到临时变量再把临时变量store进memory object中;
另一个例子是把在ptx level下texture unit的内容一次性加载进4个register中,转换成一条形参包含4个指针变量的Intrinsic call;
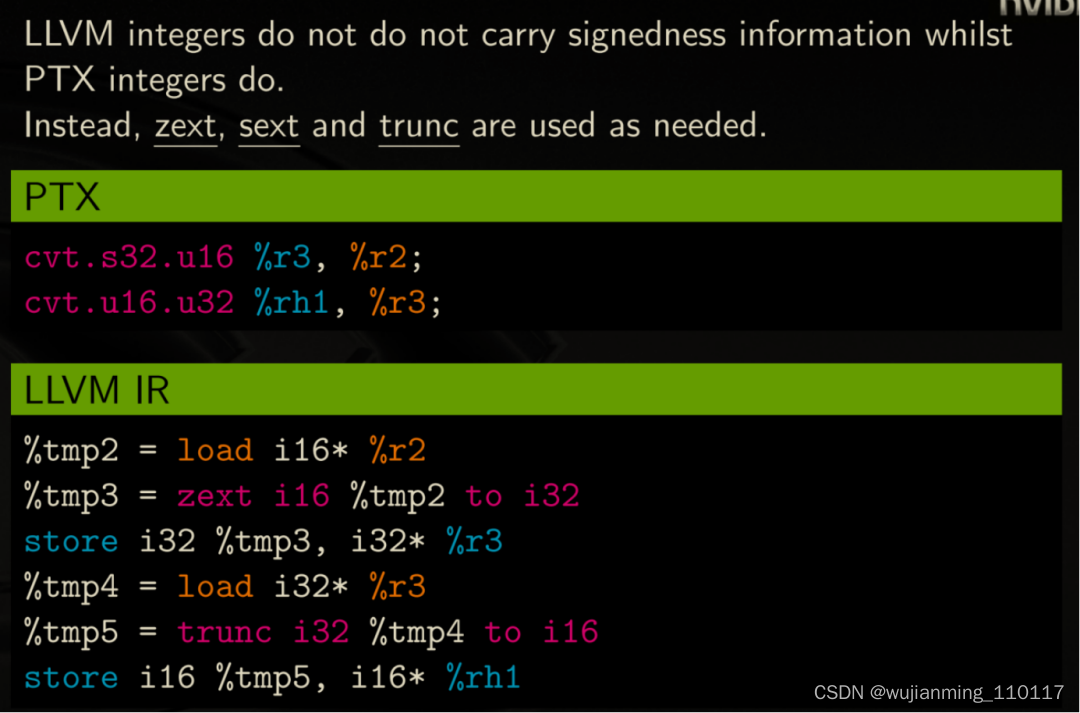
-
类型的转换
因为LLVM IR的整型数不支持符号信息,所以在翻译NVPTX Signed和Unsigned数类型转换操作时要进行正确的符合程序语义的有符号扩展/无符号扩展/截断等操作。
-
执行模型的翻译
因为CUDA执行模型中定义的核函数是对single thread执行过程的描述,这跟CPU或是LLVM IR的执行模型是不一样;以及CUDA是显示地声明memory space是shared还是private的,这个memory space的概念在LLVM IR中也要想办法去对应;以及CUDA中线程的同步__syncthreads()如何在LLVM IR中对应;

对于核函数的翻译,对策是Thread Loop placement,做法是Take the section between sink threads barriers,然后put a thread loop around it,然后Within a thread block we go sequential and then go wide;
对于任何scalar variable across the barrier必须have an array of those即scalar expansion;另外对于隐式包含有thread.id 信息的thread-local变量也必须用同样的方法进行scalar expansion。

下面以具体的例子讲解什么是Thread Loop placement和Scalar expansion。
注意:实际上应该展示的是从NVPTX Assembly Code到LLVM IR Code的转换,但为了更简洁易懂地传达转换过程的思想,实际展示的是从.cu(CUDA源代码)到.cpp(等价的CPU侧执行程序)的转换。
[demo.cu]

[demo.cpp]
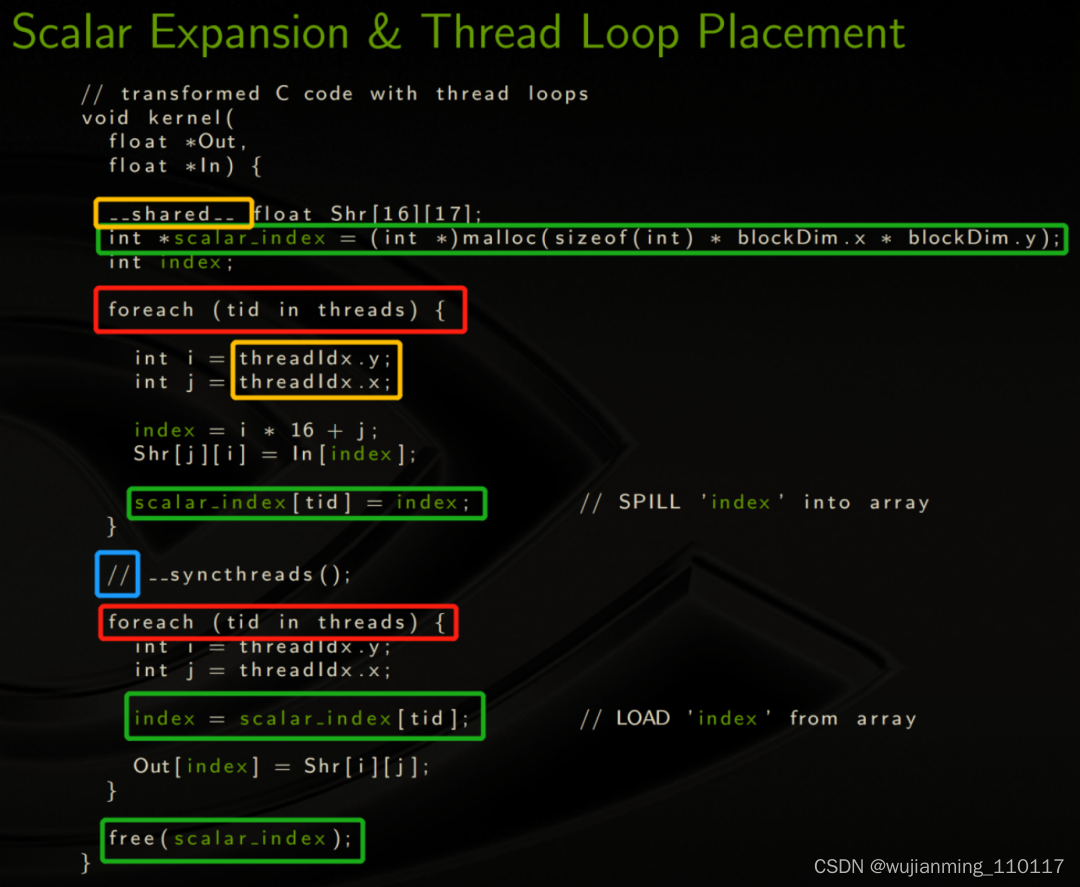
如上所示在转换过程中进行了如下操作:
1)如红色所示,被sink threads barriers分隔的代码被切成一个个section并用循环包起来;
2)如蓝色所示,注释掉__syncthreads(),因为已经翻译LLVM IR中如上的每个section的代码在所有thread上是顺序执行的,不再需要线程的同步;
3)如绿色所示,对于会跨越同步点的scalar(这里是变量index)需要按thread block维数扩展成向量,因为Thread Loop placement后这些标量会在Loop中不断被覆盖,所以需要用向量的方式进行存储;
4)如黄色所示,是作者没有提到但认为还需要做的两点:把CUDA独有的thread.Idx替换成LLVM Intrinsic(然后再映射到平台的具体实现),以及__shared__的attribute应该也不再需要了。
小结(把大象塞进冰箱一共需要几步):
- 既然NVPTX是前端,就一定需要NVPTX的Parser,包括Token的解析和识别每个Instruction到产生式;
- 然后是语法的制导翻译,为产生式设计语义动作,这涉及到上面提到以及没提到的:Non-SSA to SSA、特殊寄存器/指令 to LLVM Intrinsics、类型的转换、执行模型的翻译等;
- 另外为了目标平台执行时性能的可扩展性,需要考虑LLVM IR并行化执行的可能,应该如何正确高效地去调用Thread Library。


测试:
正确性的测试可以使用CUDA的测试程序将NVIDIA GPU的结果作为golden与目标平台进行对比。
番外:
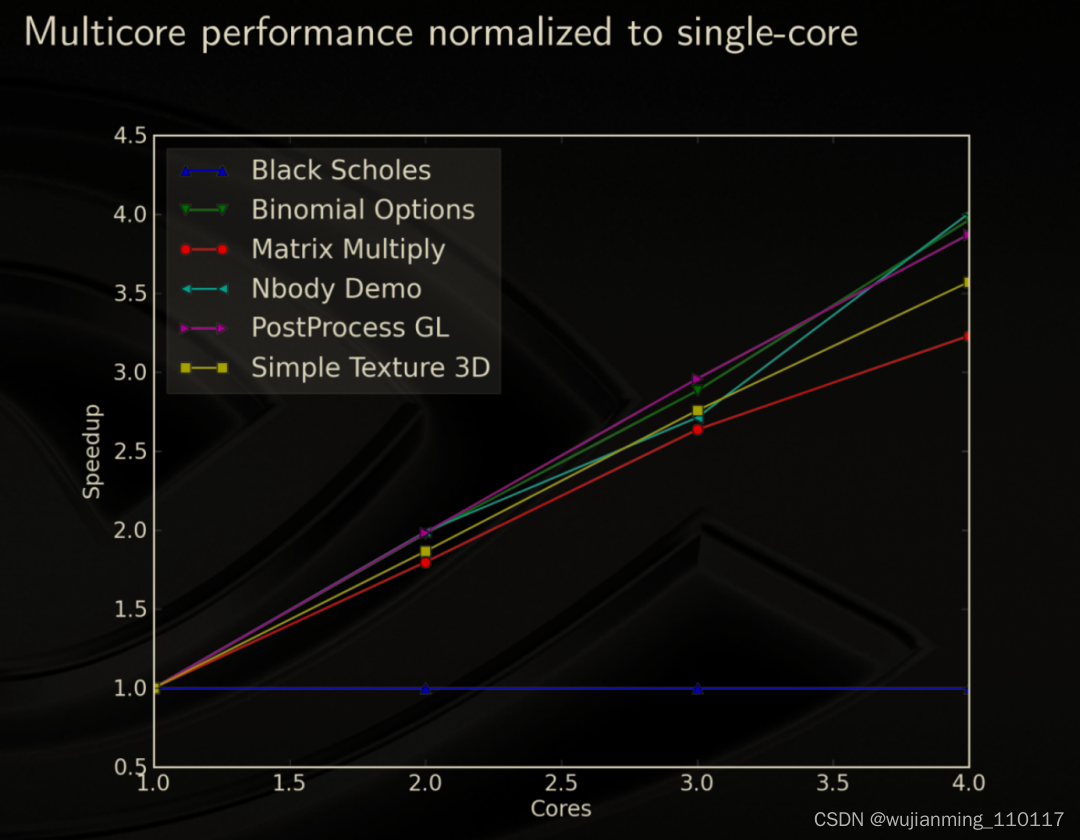
作者测试可扩展性的时候有一条躺平的直线,有金工狗知道Black Scholes是干嘛的吗[手动狗头]
跨语言编程的探索
前言
无疑,Java 是目前工业界最流行的应用编程语言之一。除了主流实现上(OpenJDK Hotspot)不俗的性能表现和成熟的研发生态(Spring 等)外,其成功的背后离不开语言本身较低(相比于 C/C++)的学习门槛。一个初学者可以利用现有的项目脚手架快速地搭建出一个初具规模的应用程序,但也因此许多 Java 程序员对程序底层的执行原理并不熟悉。本节将探讨一个在大部分 Java 相关的研发工作中不太涉及到的技术 — 跨语言编程。
回想起多年前第一次用 Java 在控制台上打印出 “Hello World” 时,出于好奇便翻阅 JDK 源码想一探实现的究竟 (在 C 语言中可以使用 printf 函数,而 printf 在具体实现上又依赖操作系统的接口),再一次次跳转后最终停留在了一个“看不到实现”的 native 方法上,额,然后就没有然后了。
想有不少 Java 初级程序员对 native 方法的调用机制仍一知半解,毕竟在大部分研发工作中,直接实现一个自定义 native 方法的需求并不多,简单来说 native 方法是 Java 进行跨语言调用的接口,这也是 Java Native Interface 规范的一部分。
Java 跨语言编程技术的应用场景
常见场景
在介绍 Java 跨语言编程技术之前,首先简单地分析下实际编程过程中需要使用跨语言编程技术的场景,在这里罗列了以下四个场景:
1、依赖字节码不支持的能力
换个角度看,目前标准的字节码提供了哪些能力呢?根据 Spec 规范,已有的字节码可以实现创建 Java 对象、访问对象字段和方法、常规计算(加减乘除与或非等)、比较、跳转以及异常、锁操作等等,但是像前言中提到的打印字符串到控制台这样的高阶功能,字节码并不直接支持,此外,像获取当前时间,分配堆外内存以及图形渲染等等字节码也都不支持,很难写出一个纯粹的 Java 方法(组合这些字节码)来实现这类能力,因为这些功能往往需要和系统资源产生交互。在这些场景下,就需要使用跨语言编程技术通过其他语言的实现来集成这些功能。
2、使用系统级语言(C、C++、Assembly)实现系统的关键路径
不需要显示释放对象是 Java 语言学习门槛低的原因之一,但因此也引入了 GC 的机制来清理程序中不再需要的对象。在主流 JVM 实现中,GC 会使得应用整体暂停,影响系统整体性能,包括响应与吞吐。
所以相对于 C/C++ ,Java 虽然减轻了程序员的研发负担,提高了产品研发效率,但也引入了运行时的开销。(Software engineering is largely the art of balancing competing trade-offs. )
当系统关键路径上的核心部分(比如一些复杂算法)使用 Java 实现会出现性能不稳定的情况下,可以尝试使用相对底层的编程语言来实现这部分逻辑,以达到性能稳定以及较低的资源消耗目的。
3、其他语言实现调用 Java
这个场景可能给大部分 Java 程序员的第一感觉是几乎没有遇到过,但事实上几乎每天都在经历这样的场景。
举个例子:通过 java 跑一个 Java 程序就会经过 C 语言调用 Java 语言的过程,后文还会对此做提及。
4、历史遗留库
公司内部或者开源实现中存在一些 C/C++ 写的高性能库,用 Java 重写以及后期维护的成本非常大。当 Java 应用需要使用这些库提供的能力时,需要借助跨语言编程技术来复用。
Alibaba Grape
再简单谈谈阿里内部的一个场景:Alibaba Grape 项目,也是在跨语言编程技术方向上与团队合作的第一个业务方。
Grape 本身是一个并行图计算框架的开源项目(相关论文获得了 ACM SIGMOD Best Paper Award),主要使用 C++ 编写,工程实现上应用了大量的模板特性。对 Grape 项目感兴趣的同学可以参考 Github 上的相关文档,这里不再详细介绍。
该项目在内部应用中,存在很多使用 Java 作为主要编程语言的业务方,因此需要开发人员把 Grape 库封装成 Java SDK 供上层的 Java 应用调用。在实践过程中,遇到的两个显著问题:
• 封装 SDK 的工作非常繁琐,尤其对于像 Grape 这样依赖模板的库,在初期基于手动的封装操作经常出错
• 运行时性能远低于 C++ 应用
为了解决这些问题,两个团队展开了合作,Alibaba FFI 项目正式开始演进,该项目的实现目前也主要针对 Java 调用 C++ 场景。
Java 跨语言编程技术下面介绍一些在工业界中相对成熟、应用较多的 Java 跨语言调用技术。Java Native Interface谈到 Java 跨语言编程,首先不得不提的就是 Java Native Interface,简称 JNI。后面提到的 JNA/ JNR、JavaCPP 技术都会依赖 JNI。首先,通过两个例子来简单回顾一下。控制台输出的例子
System.out.println(“hello ffi”);
通过 System.out 可以快速地实现控制台输出功能,相信会有不少好奇的同学会关心这个调用到底是如何实现输出功能的,翻阅源码后,最终会看见这样一个 native 方法:
private native void writeBytes(byte b[], int off, int len, boolean append) throwsIOException;
(该方法由 JDK 实现,具体实现可以参考这里:https://github.com/openjdk/jdk/blob/master/src/java.base/share/native/libjava/io_util.c)那么是否可以自己实现这样的功能呢?答案是肯定的,大致步骤如下(省略了一些细节):a. 首先定义一个 Java native 方法,需要使用 native 关键字,同时不提供具体的实现(native 方法可以被重载)
static native void myHelloFFI();
b. 通过 javah 或者 javac -h (JDK 10)命令生成后续步骤依赖的头文件(该头文件可以被 C 或者 C++ 程序使用)
/* DO NOT EDIT THIS FILE - it is machine generated /#include <jni.h>/ Header for class HelloFFI */
#ifndef _Included_HelloFFI#define _Included_HelloFFI#ifdef __cplusplusextern “C” {#endif/* * Class: HelloFFI * Method: myHelloFFI * Signature: ()V */JNIEXPORT void JNICALL Java_HelloFFI_myHelloFFI (JNIEnv *, jclass);
#ifdef __cplusplus}#endif#endif
c. 实现头文件中的函数,在这里直接使用 printf 函数在控制台输出 “hello ffi”
JNIEXPORT void JNICALL Java_HelloFFI_myHelloFFI (JNIEnv * env, jclass c) { printf(“hello ffi”);}
d. 通过 C/C++ 编译器(gcc/llvm 等)编译生成库文件e. 使用 -Djava.library.path=… 参数指定库文件路径并在运行时调用 System.loadLibrary 加载上个步骤中生成的库,之后 Java 程序就可以正常调用自己实现的 myHelloFFI 方法了。C 程序调用 Java 方法上面是 Java 方法调用 C 函数的例子,通过 JNI 技术,还可以实现 C 程序中调用 Java 方法,这里面会涉及到 2 个概念:Invocation API 与 JNI function,在下面代码示例中省略了初始化虚拟机的步骤,仅给出最终实现调用的两个步骤。
// Init jvm …// Get method idjmethodID mainID = (env)->GetStaticMethodID(env, mainClass, “main”, “([Ljava/lang/String;)V”);/ Invoke */(*env)->CallStaticVoidMethod(env, mainClass, mainID, mainArgs);
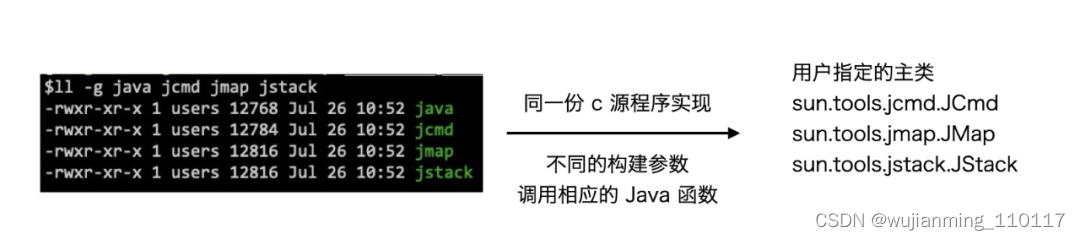
示例中首先通过 GetStaticMethodID 获取方法的 “id”,之后通过 CallStaticVoidMethod 实现方法的调用,这两个函数都是 JNI function。前面提到过,当 java 运行 Java 程序时是其他语言调用 Java 语言的场景,事实上 Java 命令在实现上就是应用类似上述代码的流程完成主类 main 方法的调用。顺带提一点,日常研发过程中常用的一些诊断命令,比如 jcmd、jmap、jstack,和 java 命令是同一份源码实现(可以从图中看出这几个二进制文件的大小差不多),只是在构建过程中使用了不同的构建参数。
那么 JNI 到底是什么呢?以下是理解。
• 首先,JNI 是 Java 跨语言访问的接口规范,主要面向 C、C++、Assembly(为什么没有其他语言?个人认为是由于这几种语言在当时规范设计之初足以覆盖绝大部分场景)
• 规范本身考虑了主流虚拟机的实现(hotspot),但本身不和任何具体的实现绑定,换句话说,Java 程序中跨语言编程的部分理论上可以跑在任何实现这个规范的虚拟机上
• 规范定义了其他语言如何访问 Java 对象、类、方法、异常,如何启动虚拟机,也定义了Java 程序如何调用其他语言(C、C++、Assembly)
• 在具体使用和实际运行效果的表现用一句话总结:Powerful, but slow, hard to use, and error-prone

Java Native Access & Java Native Runtime
通过前面对 Java Native Interface 的介绍,可以认识到使用 JNI 技术实现 Java 方法调用 C 语言的步骤是非常麻烦的,因此为了降低 Java 跨语言编程(指 Java 调用 C/C++ 程序)的难度,开源社区诞生了 Java Native Access(JNA) 和 Java Native Runtime(JNR)这两个项目。本质上,这两个技术底层仍然是基于 JNI,因此在运行时性能上不会优于 JNI。通过 JNA/JNR 进行 C/C++ 程序的封装,开发者就不需要主动生成或者编写底层的胶水代码,快速地实现跨语言的调用。此外两者还提供了其他优化,比如 Crash Protection(后文会有介绍)等。在实现上,JNR 会动态生成一些 Stub 优化运行时的性能。JNA/JNR 和 JNI 的关系如下入:
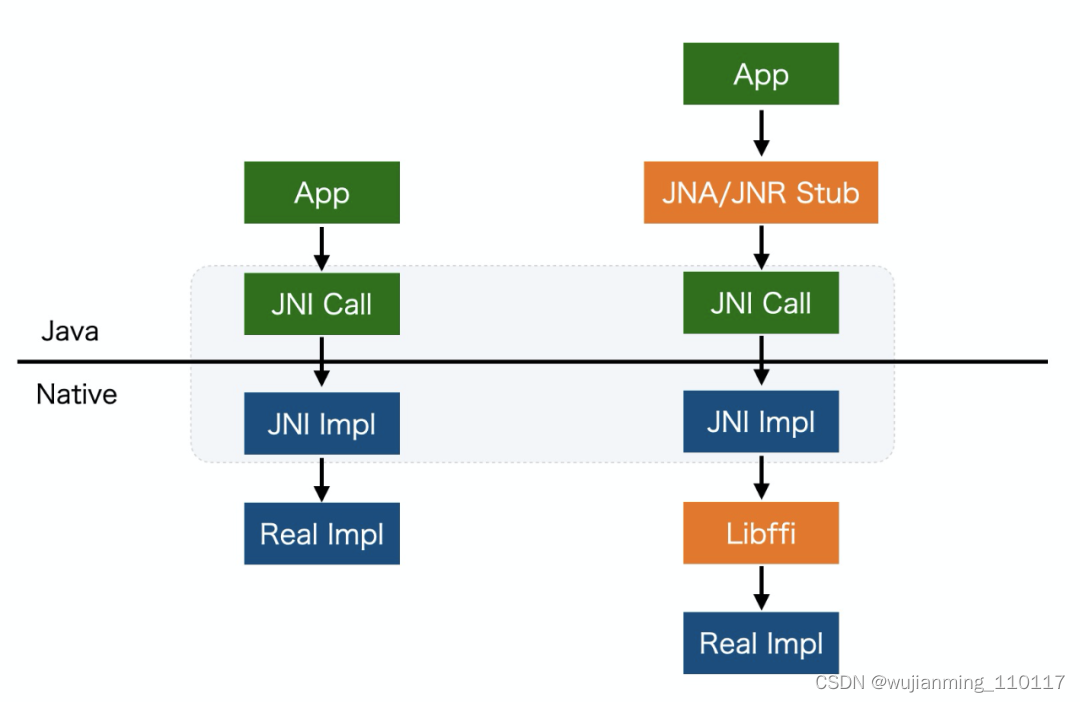
下面是 JNR 官方给出的示例。首先创建 LibC 接口封装目标 C 函数,然后调用 LibraryLoader 的 API 创建 LibC 的具体实例,最后通过接口完成调用:
public class HelloWorld { public interface LibC { // A representation of libC in Java int puts(String s); // mapping of the puts function, in C int puts(const char *s); }
public static void main(String[] args) { LibC libc = LibraryLoader.create(LibC.class).load("c"); // load the "c" library into the libc variable
libc.puts("Hello World!"); // prints "Hello World!" to console }}
遗憾的是,JNA 和 JNR 对 C++ 的支持并不友好,因此在调用 C++ 库的场景中使用受限。JavaCPPThe missing bridge between Java and native C++如果说 JNA/JNR 优化了 Java 调用 C 的编程体验,那么 JavaCPP 的目标则是优化 Java 调用 C++ 的编程体验,目前该项目也是工业界用得较多的SDK。JavaCPP 已经支持大部分 C++ 特性,比如 Overloaded operators、Class & Function templates、Callback through function pointers 等。和 JNA/JNR 类似,JavaCPP 底层也是基于 JNI,实现上通过注解处理等机制自动生成类似的胶水代码以及一些构建脚本。此外,该项目也提供了利用 JavaCPP 实现的一些常用 C++ 库的 Preset,如 LLVM、Caffe 等。下面是使用 JavaCPP 封装 std::vector 的的示例:
@Platform(include=“”)public class VectorTest {
@Name("std::vector<std::vector<void*> >") public static class PointerVectorVector extends Pointer { static { Loader.load(); } public PointerVectorVector() { allocate(); } public PointerVectorVector(long n) { allocate(n); } public PointerVectorVector(Pointer p) { super(p); } // this = (vector<vector<void*> >*)p /** other methods .... */ public native @Index void resize(long i, long n); // (*this)[i].resize(n)
public native @Index Pointer get(long i, long j); // return (*this)[i][j] public native void put(long i, long j, Pointer p); // (*this)[i][j] = p }
public static void main(String[] args) { PointerVectorVector v = new PointerVectorVector(13); v.resize(0, 42); // v[0].resize(42) Pointer p = new Pointer() { { address = 0xDEADBEEFL; } }; v.put(0, 0, p); // v[0][0] = p
PointerVectorVector v2 = new PointerVectorVector().put(v); Pointer p2 = v2.get(0).get(); // p2 = *(&v[0][0]) System.out.println(v2.size() + " " + v2.size(0) + " " + p2);
v2.at(42); }}
Graal & PanamaGraal 和 Panama 是目前两个相对活跃的社区项目,与跨语言编程有直接的联系。但这两项技术还未在生产环境中大规模使用验证,在这里不做具体的描述,有机会的话会单独介绍这两个项目。FBJNIFBJNI(https://github.com/facebookincubator/fbjni)是 Facebook 开源的一套辅助 C++ 开发人员使用 JNI 的框架。前面提到的大多是如何让Java用户快速的访问Native方法,实际在跨语言调用场景下,也存在 C++ 用户需要安全便捷的访问 Java 代码的场景。Alibaba FFI 目前关注的是如何让 Java 快速的访问 C++,例如假设一个需求是让 C++ 用户访问 Java 的 List 接口,那么 Alibaba FFI的做法是与其通过 JNI 接口函数来操作 Java 的 List 对象,不如将 C++的 std::vector 通过 FFI 包转成 Java 接口。JNI 的开销内联JVM 高性能的最核心原因是内置了强大的及时编译器(Just in time,简称 JIT)。JIT 会将运行过程中的热点方法编译成可执行代码,使得这些方法可以直接运行(避免了解释字节码执行)。在编译过程中应用了许多优化技术,内联便是其中最重要的优化之一。简单来说,内联是把被调用方法的执行逻辑嵌入到调用者的逻辑中,这样不仅可以消除方法调用带来的开销,同时能够进行更多的程序优化。但是在目前 hotspot 的实现中,JIT 仅支持Java 方法的内联,所以如果一个 Java 方法调用了 native 方法,则无法对这个 native 方法应用内联优化。 
说到这里,肯定有人疑惑难道经常使用的一些 native 方法,比如 System.currentTimeMillis,没有办法被内联吗?实际上,针对这些在应用中会被经常使用的 native 方法,hotspot 会使用 Intrinsic 技术来提高调用性能(非 native 方法也可以被 Intrinsic)。个人认为 Intrinsic 有点类似 build-in 的概念,当 JIT 遇到这类方法调用时,能够在最终生成的代码中直接嵌入方法的实现,不过方法的 Intrinsic 支持通常需要直接修改 JVM。参数传递JNI 的另一个开销是参数传递(包括返回值)。由于不同语言的方法/函数的调用规约(Calling Convention)不同,因此在 Java 方法在调用 native 方法 的时候需要涉及到参数传递的过程,如下图(针对 x64 平台):

根据 JNI 规范,JVM 首先需要把 JNIEnv* 放入第一个参数寄存器(rdi)中,然后把剩下的几个参数包括 this(receiver)分别放入相应的寄存器中。为了让这一过程尽可能地快, hotspot 内部会根据方法签名动态生成转换过程的高效 stub。状态切换从 Java 方法进入 native 方法,以及 native 方法执行完成并返回到 Java 方法的过程中会涉及到状态切换。如下图: 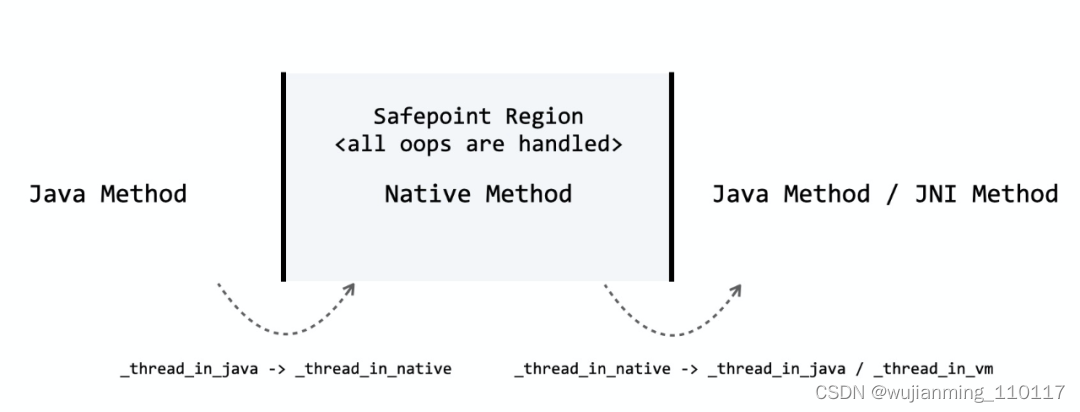
在实现上,状态切换需要引入 memory barrier 以及 safepoint check。对象访问JNI 的另一个开销存在于 native 方法中访问 Java 对象。设想一下,需要在一个 C 函数中访问一个 Java 对象,最暴力的方式是直接获取对象的指针然后访问。但是由于 GC 的存在,Java 对象可能会被移动,因此需要一个机制让 native 方法中访问对象的逻辑与地址无关。All problems in CS can be solved by another level of indirection在具体的实现上,通过增加一个简介层 JNI Handle,同时使用 JNI Functions 进行对象的访问来解决这个问题,当然这个方案也势必引入了开销。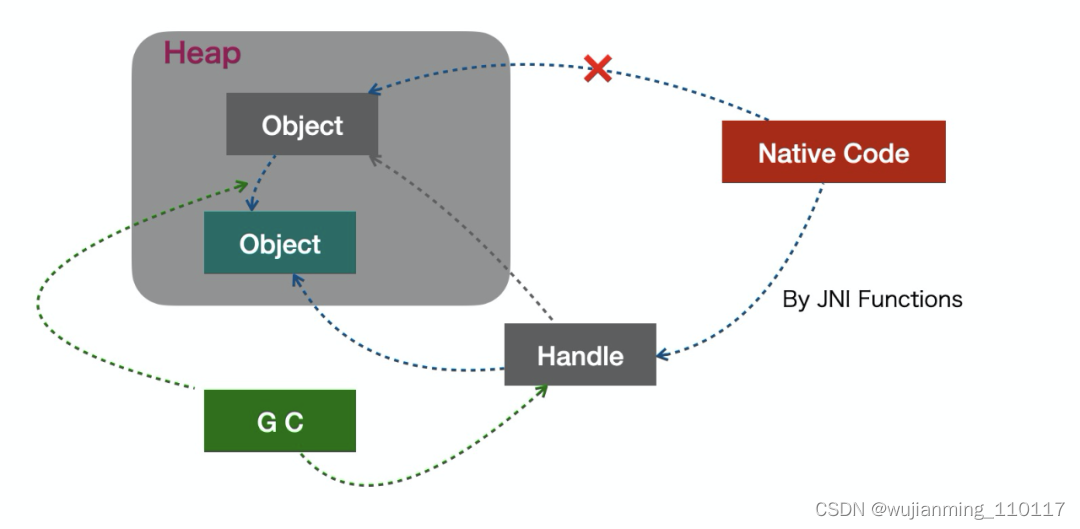
通过前面的介绍,知道现在主流的 Java 跨语言编程技术主要存在两个问题:1、编程难度2、跨语言通信的开销针对问题 1,可以利用 JNA/JNR 、JavaCPP 这样技术来解决。那么针对问题 2,有相应的优化方案么?下面正式介绍 Alibaba FFI 项目Alibaba FFI概览Alibaba FFI 项目致力于解决 Java 跨语言编程中遇到的问题,从整体上看项目分为以下两个模块:a. FFI (解决编程难度问题)
• 一套 Java 注解和类型
• 包含一个注解处理器,用于生成胶水代码
• 运行时支持
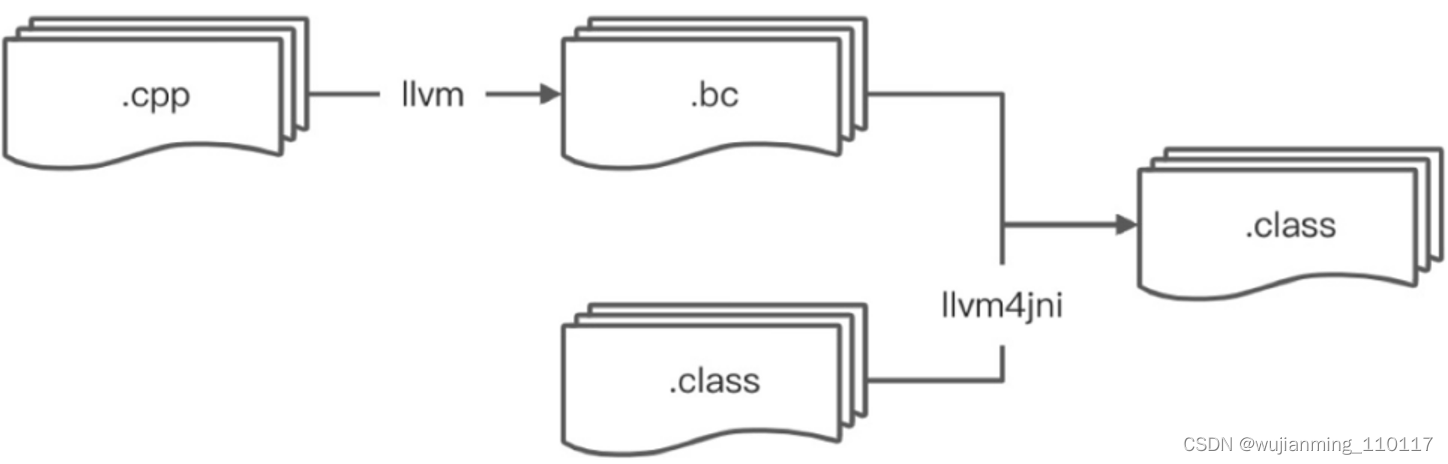
b. LLVM4JNI(解决运行时开销问题)
• 实现 bitcode 到 bytecode 的翻译,打破 Java 方法与 Native 函数的边界
• 基于FFI的纯 Java 接口定义,底层依赖 LLVM,通过 FFI 访问 LLVM 的 C++ API
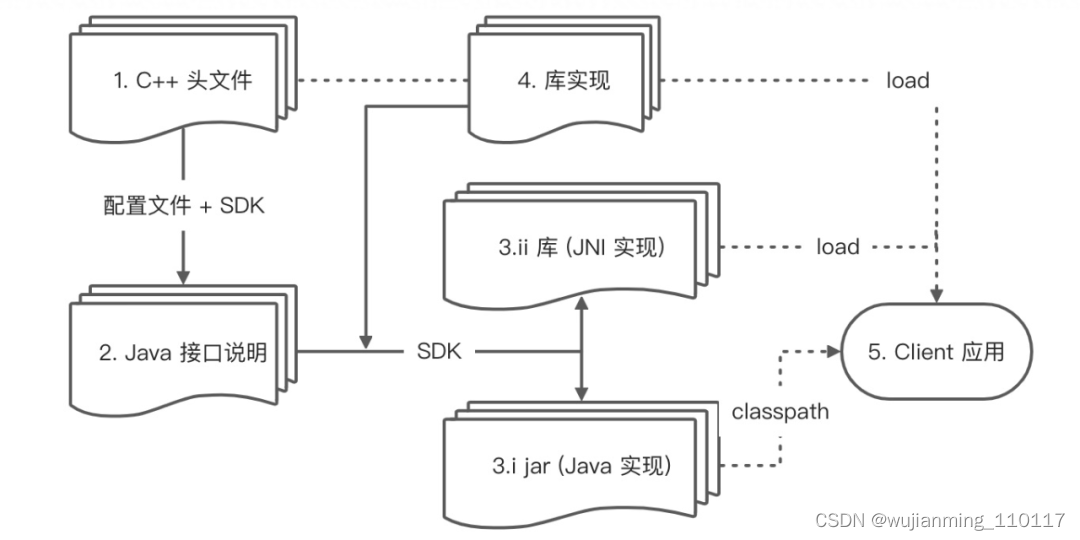
目前 Alibaba FFI 主要针对 C++ ,下文也主要以 C++ 作为目标通信语言。通过 Alibaba FFI 进行跨语言编程的 workflow:1、包含用户需要使用的 C++ API 声明的头文件2、用 Java 语言封装 C++ API,目前这个步骤仍需要手动进行,在未来会提供 SDK,用户仅需手动编写配置文件即可生成这部分代码3、通过 FFI 中的注解处理器生成的胶水代码:包括 Java 层和 native 层的代码4、库的具体实现5、Clinet 应用在运行阶段会 load 上述过程的产物注:实线表示运行前阶段源码与产物之间的关系,虚线表示运行阶段应用与库和产物之间的关系
FFIFFI 模块提供了一套注解和类型,用于封装其他语言的接口,可以在下图中看到最顶层是一个 FFIType(FFI -> Foreign function interface)接口。在面向 C++ 的具体实现中,一个底层的 C++ 对象会映射到一个 Java 对象,因此需要在Java 对象中包含 C++ 对象的地址。由于 C++ 对象不会被移动,所以可以在 Java 对象中直接保存裸指针。
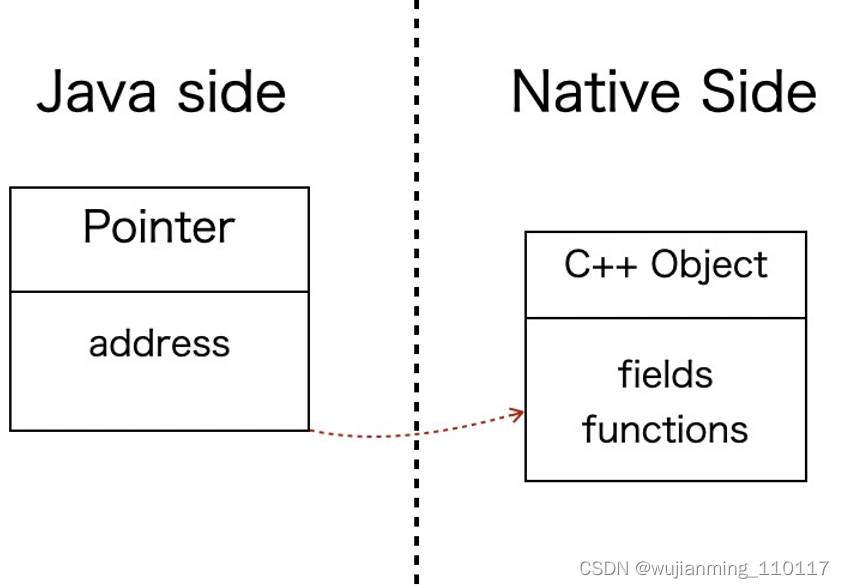
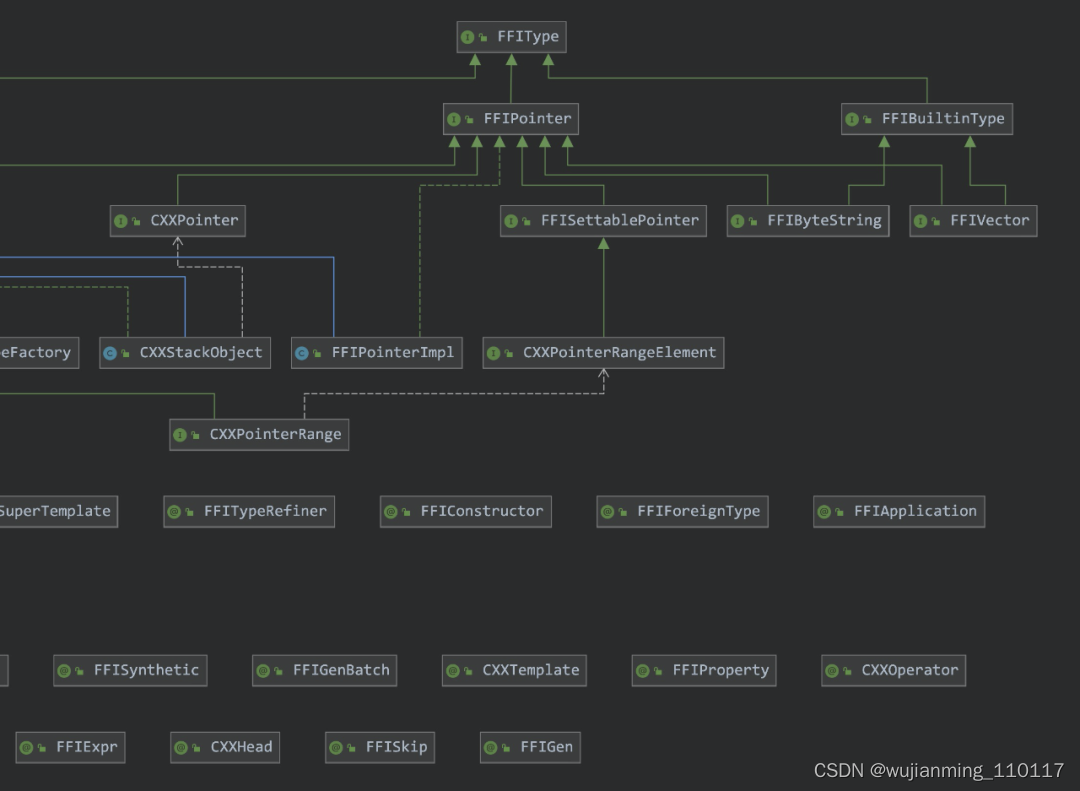
类层次图(不完整)本质上 FFI 模块是通过注解处理器生成跨语言调用中需要的相关代码,用户仅需要依赖 FFI 的相关库(插件),并用 FFI 提供的 api 封装需要调用的目标函数即可。示例下面是一个封装 std::vector 的过程。a. 通过注解和类型封装需要调用的底层函数
@FFIGen(library = “stdcxx-demo”)@CXXHead(system = {“vector”, “string”})@FFITypeAlias(“std::vector”)@CXXTemplate(cxx=“jint”, java=“Integer”)@CXXTemplate(cxx=“jbyte”, java=“Byte”)public interface StdVector extends CXXPointer {
@FFIFactory interface Factory<E> { StdVector<E> create(); }
long size();
@CXXOperator("[]") @CXXReference E get(long index); @CXXOperator("[]") void set(long index, @CXXReference E value); void push_back(@CXXValue E e);
long capacity(); void reserve(long size); void resize(long size);}
FFIGen:指定最终生成库的名称
CXXHead:胶水代码中依赖的头文件FFITypeAlias:C++ 的类名CXXTemplate:实现 C++ 模板参数具体类型到 Java 类型的映射,相对于 JavaCPP,Alibaba FFI 提供了更灵活的配置b. 编译过程中,注解处理器会生成最终调用过程中依赖的组件接口的真实实现:
public class StdVector_cxx_0x6b0caae2 extends FFIPointerImpl implements StdVector { static { FFITypeFactory.loadNativeLibrary(StdVector_cxx_0x6b0caae2.class, “stdcxx-demo”); }
public StdVector_cxx_0x6b0caae2(final long address) { super(address); }
public long capacity() { return nativeCapacity(address); }
public static native long nativeCapacity(long ptr);
…
public long size() { return nativeSize(address); }
public static native long nativeSize(long ptr);
}
JNI 的胶水代码:
#include <jni.h>#include #include #include #include “stdcxx_demo.h”
#ifdef __cplusplusextern “C” {#endif
JNIEXPORTjbyte JNICALL Java_com_alibaba_ffi_samples_StdVector_1cxx_10x6b0caae2_nativeGet(JNIEnv* env, jclass cls, jlong ptr, jlong arg0 /* index0 */) { return (jbyte)((reinterpret_cast<std::vector>(ptr))[arg0]);}
JNIEXPORTjlong JNICALL Java_com_alibaba_ffi_samples_StdVector_1cxx_10x6b0caae2_nativeSize(JNIEnv* env, jclass cls, jlong ptr) { return (jlong)(reinterpret_cast<std::vector*>(ptr)->size());}
…
#ifdef __cplusplus}#endif
Crash Protection在演进过程中,引入了一些优化机制,比如针对 C++ 函数返回临时对象的处理、异常的转换等。在这里介绍一下 Crash Protection,也是针对客户在实际场景遇到的问题的解决方案,在 JNA 和 JNR 中也有相应的处理。有时候,Java 应用依赖的 C++ 库需要进行版本升级,为了防止 C++ 库中的 Bug 导致整个应用 Crash(对于 Java 中的 Bug 通常会表现为异常,多数情况下不会导致应用整体出现问题),需要引入保护机制。如下:
JNIEXPORT void JNICALL Java_Demo_crash(JNIEnv* env, jclass) { void* addr = 0; (int)addr = 0; // (Crash)}
在第 3 行会出现内存访问越界的问题,如果不做特殊处理应用会 Crash。为了”隔离“这个问题,引入在保护机制,以下是 Linux 上的实现:
PROTECTION_START // 生成胶水代码中插入宏void* addr = 0;(int)addr = 0;PROTECTION_END // 宏 // 宏展开后的实现如下
// Pseudo code// register signal handlerssignal(sig, signal_handler);
int sigsetjmp_rv;sigsetjmp_rv = sigsetjmp(acquire_sigjmp_buf(), 1);if (!sigsetjmp_rv) { void* addr = 0; (int)addr = 0;}release_sigjmp_buf();// restore handler …if (sigsetjmp_rv) { handle_crash(env, sigsetjmp_rv);}
通过实现自己的信号处理函数和 sigsetjmp/siglongjmp 机制来实现 Crash 的保护,需要注意的是由于 Hotspot 有自定义的信号处理器(safepoint check,implicit null check 等),为了防止冲突,需要在启动是 preload libjsig.so(Linux 上)这个库。最后在 handle_crash 中可以抛出 Java 异常供后续排查分析。
相关项目的对比
友好地支持 C++ 不需要生成和编译源码 不需要运行时生成额外的 Stub 支持 c++ 模板映射 Java 泛型
JNA/JNR ❌ ✅ ❌ N.A.
JavaCPP ✅ ❌ ✅ ❌
Alibaba FFI ✅ ❌ ✅ ✅
LLVM4JNI
LLVM4JNI 实现了 bitcode 到 bytecode 的翻译,这样一个 Native 函数就是被转换成一个 Java 方法,从而消除前面提到的一系列开销问题。翻译过程是在应用运行前完成的,其核心就是将 bitcode 的语义用 bytecode 来实现,本节不会介绍具体的实现细节(待项目开源后做详细介绍)。下面演示几例简单过程的翻译结果。1、简单的四则运算:
• source
int v1 = i + j; int v2 = i - j; int v3 = i * j; int v4 = i / j; return v1 + v2 + v3 + v4;
• bitcode
%5 = sdiv i32 %2, %3 %6 = add i32 %3, 2 %7 = mul i32 %6, %2 %8 = add nsw i32 %5, %7 ret i32 %8
• bytecode
Code: stack=2, locals=6, args_size=3 0: iload_1 1: iload_2 2: idiv 3: istore_3 4: iload_2 5: ldc #193 // int 2 7: iadd 8: iload_1 9: imul 10: istore 5 12: iload_3 13: iload 5 15: iadd 16: ireturn
2、JNI Functions 的转换,目前已经支持 90+ 个。未来该功能会和fbjni等类似框架集成,打破Java和Native的代码边界,消除方法调用的额外开销。
• source
jclass objectClass = env->FindClass(“java/util/List");
return env->IsInstanceOf(arg, objectClass);
• bytecode
Code: stack=1, locals=3, args_size=2 0: ldc #205 // class java/util/List 2: astore_2 3: aload_1 4: instanceof #205 // class java/util/List 7: i2b 8: ireturn
3、C++ 对象访问。Alibaba FFI的另外一个好处是可以以面向对象的方式(C++是面向对象语言)来开发 Java off-heap 应用。当前基于Java的大数据平台大多需要支持 off-heap 的数据模块来减轻垃圾回收的压力,然而人工开发的 off-heap 模块需要小心仔细处理不同平台和架构的底层偏移和对齐,容易出错且耗时。通过 Aliabba FFI,可以采用 C++开发对象模型,再通过 Alibaba FFI 暴露给 Java 用户使用。
• source
class Pointer { public: int _x; int _y;
Pointer(): _x(0), _y(0) {}
const int x() { return _x; } const int y() { return _y; }};
JNIEXPORTjint JNICALL Java_Pointer_1cxx_10x4b57d61d_nativeX(JNIEnv*, jclass, jlong ptr) { return (jint)(reinterpret_cast<Pointer*>(ptr)->x());}
JNIEXPORTjint JNICALL Java_Pointer_1cxx_10x4b57d61d_nativeY(JNIEnv*, jclass, jlong ptr) { return (jint)(reinterpret_cast<Pointer*>(ptr)->y());}
• bitcode
define i32 @Java_Pointer_1cxx_10x4b57d61d_nativeX %4 = inttoptr i64 %2 to %class.Pointer* %5 = getelementptr inbounds %class.Pointer, %class.Pointer* %4, i64 0, i32 0 %6 = load i32, i32* %5, align 4, !tbaa !3 ret i32 %6
define i32 @Java_Pointer_1cxx_10x4b57d61d_nativeY
%4 = inttoptr i64 %2 to %class.Pointer* %5 = getelementptr inbounds %class.Pointer, %class.Pointer* %4, i64 0, i32 1 %6 = load i32, i32* %5, align 4, !tbaa !8 ret i32 %6
• bytecode
public int y(); descriptor: ()I flags: ACC_PUBLIC Code: stack=2, locals=1, args_size=1 0: aload_0 1: getfield #36 // Field address:J 4: invokestatic #84 // Method nativeY:(J)I 7: ireturn LineNumberTable: line 70: 0
public static int nativeY(long); descriptor: (J)I flags: ACC_PUBLIC, ACC_STATIC Code: stack=4, locals=2, args_size=1 0: lload_0 1: ldc2_w #85 // long 4l 4: ladd 5: invokestatic #80 // Method com/alibaba/llvm4jni/runtime/JavaRuntime.getInt:(J)I 8: ireturn
• JavaRuntime
public class JavaRuntime {
public static final Unsafe UNSAFE;
...
public static int getInt(long address) { return UNSAFE.getInt(address); }
...}
在访问 C++ 对象的字段实现中,使用 Unsafe API 完成堆外内存的直接访问,从而避免了 Native 方法的调用。
性能数据Grape 在应用 Alibaba FFI 实现的 SSSP(单源最短路径算法)的性能数据如下:
SSSP (单源最短路径算法) 归一化后的 Job Time
Grape C++ 1
Alibaba FFI (without LLVM4JNI) 8.3
Alibaba FFI (with LLVM4JNI) 2.4

这里比较三种模式:
• 纯粹的 C++ 实现
• 基于 Aibaba FFI 的 Java 实现,但是关闭 LLVM4JNI,JNI 的额外开销没有任何消除
• 基于 Alibaba FFI 的 Java 实现,同时开启 LLVM4JNI,一些 native 方法的额外开销被消除
这里以算法完成的时间(Job Time)为指标,将最终结果以 C++ 的计算时间为单位一做归一化处理。结语跨语言编程是现代编程语言的一个重要方向,在社区中存在许多方案来实现针对不同语言的通信过程。
Reference:
[1] Video: https://www.youtube.com/watch?v=o-T8Dn8WX9E
[2] Slides: https://www.youtube.com/redirect?event=video_description&redir_token=QUFFLUhqbnBsTVZoaVJic3pxRUU4cExLb0kxT3RkaE16QXxBQ3Jtc0trVGFjT0RwMjdsdW5Qc2dyRUY4TkNBZXFHd0hqdXVubW1uYXBpSnlIVzVONWk3RzBkR3hFTm85VmlnaVRIN3NFaW5lcjJaX0daWG5oSTdDaVNVWE16QW1RM0VwVGhoVlVwT1AyRlJpa2RnNzg1VXp3WQ&q=https%3A%2F%2Fllvm.org%2Fdevmtg%2F2009-10%2FGrover_PLANG.pdf
参考文献链接
https://mp.weixin.qq.com/s/NfkPxf-3gJURE2TIbM6InA
https://mp.weixin.qq.com/s/jjT0x99ht8xtfWmzL-0R1A
https://mp.weixin.qq.com/s/YAhX5895meSHENZSAe184w
https://mp.weixin.qq.com/s/DJzKXDYz4fD8zc1Ln_dK7g