文章目录
学习目标:
(1)了解 Transformer的作用
(2)学会构建 Transformer 的各个部件!提升代码能力
(3)学习完Transformer的模型架构之后,用于自己任务的迁移学习!
第一节:transformer的架构介绍 + 输入部分的实现
链接:https://editor.csdn.net/md/?articleId=124648718
第二节 编码器部分实现(一)
链接:https://editor.csdn.net/md/?articleId=124648718
第三节 编码器部分实现(二)
链接:https://editor.csdn.net/md/?articleId=124724264
第四节 编码器部分实现(三)
链接:https://editor.csdn.net/md/?articleId=124746022
第五节 解码器部分实现
链接:https://editor.csdn.net/md/?articleId=124750632
第六节 输出部分实现
链接:https://editor.csdn.net/md/?articleId=124757450
声明:
(1) Embedding 层:文本嵌入层
(2)Embedding 层产生的张量: 词嵌入张量
(3)它的最后一维称作词向量
1 transformer架构介绍
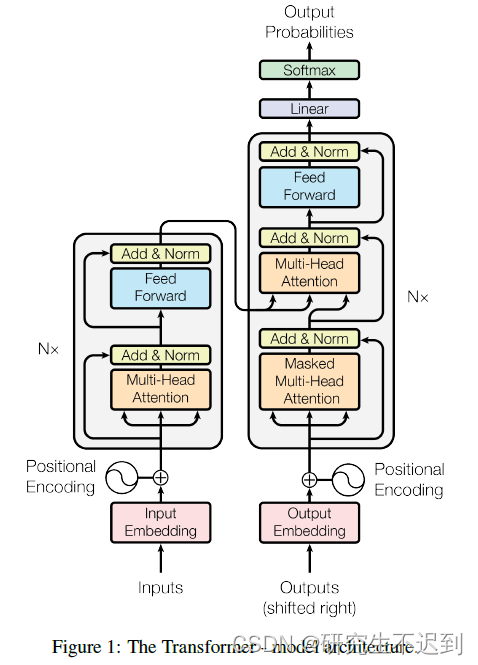
- Transformer的总体架构:
(1)输入部分
(2)输出部分
(3)编码器部分(Encoder)
(4)解码器部分(Decoder)
-
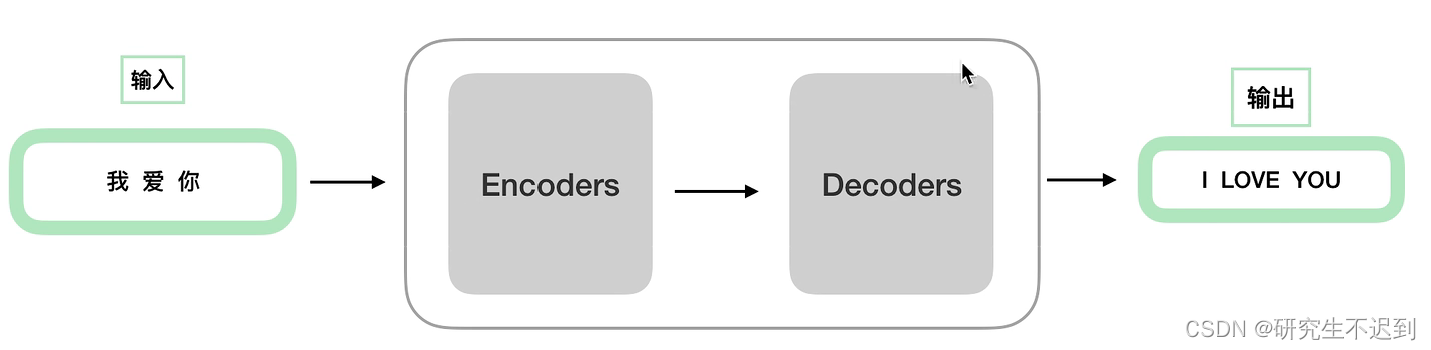
transformer可以分成两个部分,左边是encoders右边是decoders -
可以说,Encoder + Decoder就是transformer,是一个完全脱离RNN 的模型,目前已经横扫NLP领域。
-
6个
encoder的结构是完全相同的,但是只是结构相同,参数不同;6个decoder同理。
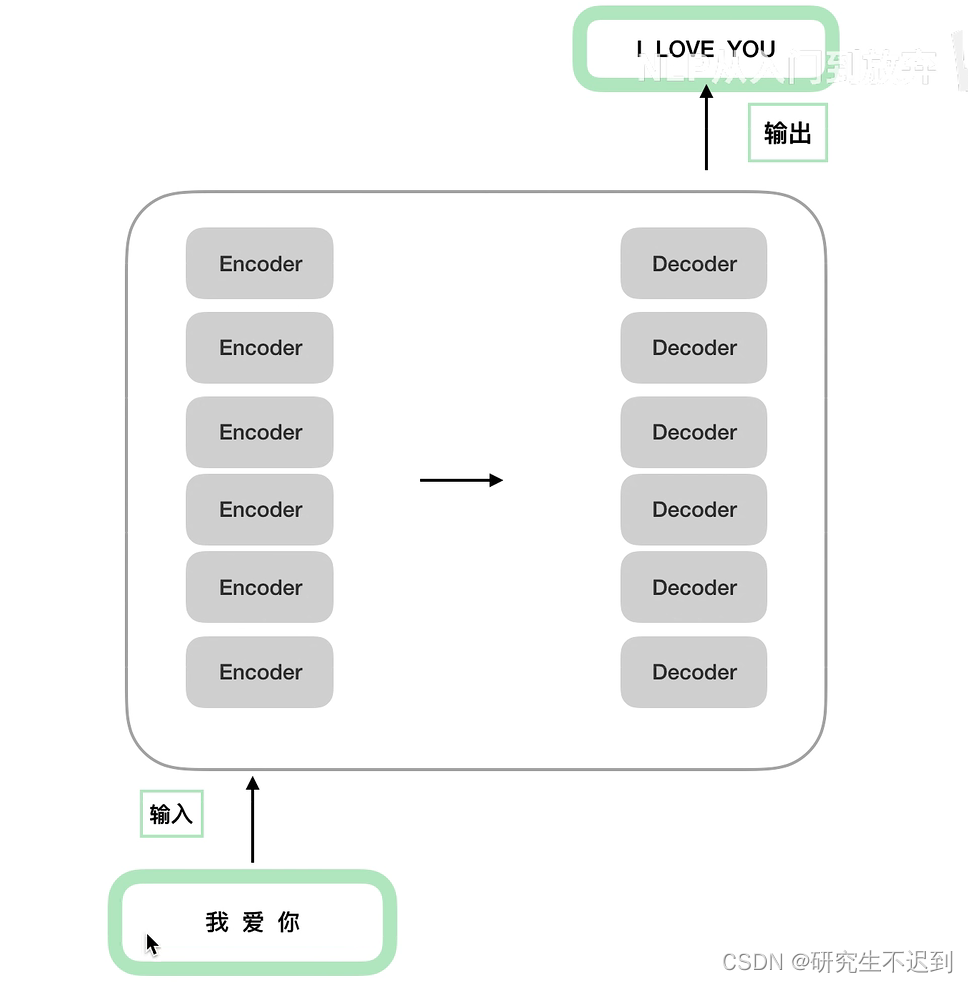
-
decoder 中多了一个交互层。
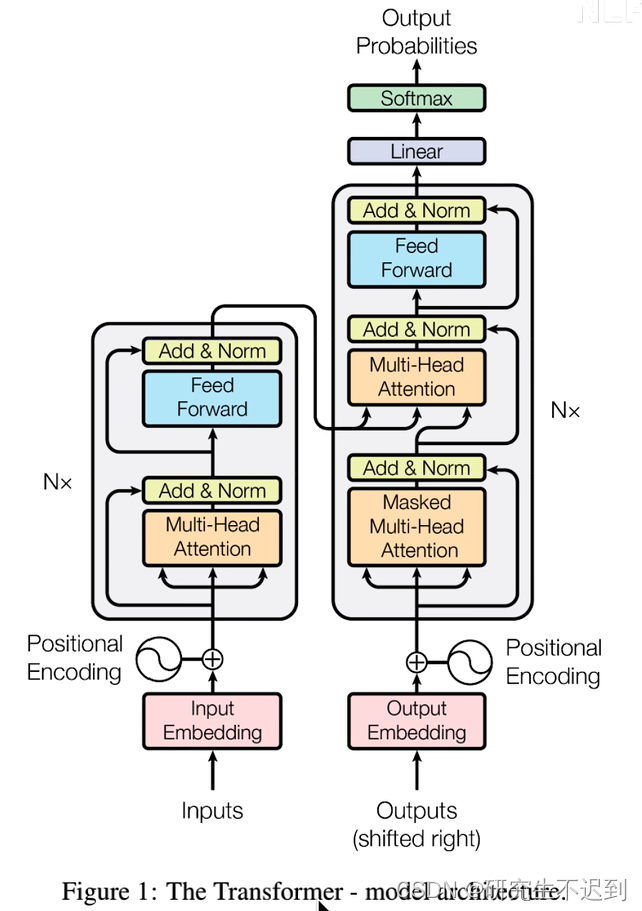
- 相比之前占领市场的LSTM和GRU模型,Transformer有两个显著的优势:
(1) Transformer 能够利用分布式GPU进行并行计算,提升模型训练效率;
(2)在分析预测更长的文本时,捕捉间隔较长的语义关联效果更好。
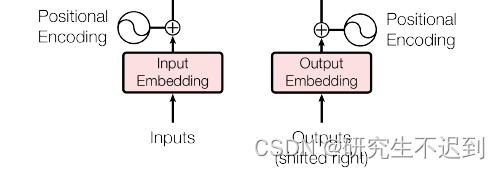
1.1 简单介绍输入部分
- 包括两个部分:
(1)Embedding
(2)位置编码
1.2 简单介绍输出部分
- 包括两个部分:
(1)一个全连接层 Linear
(2)一个softmax分类

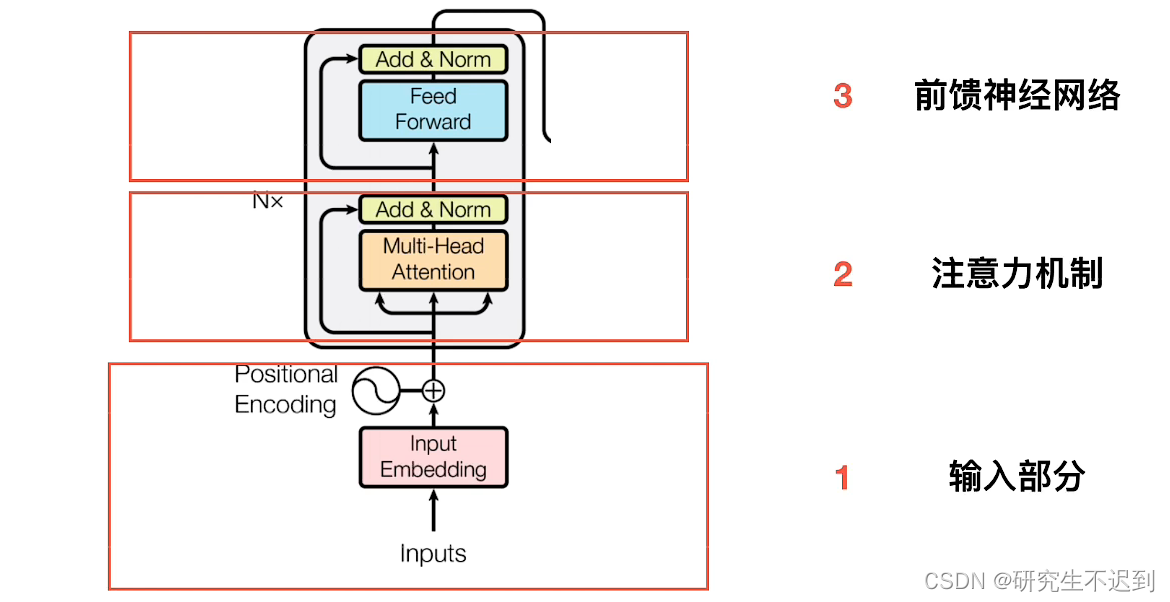
1.3 简单介绍编码器部分
- 包括四个部分:
(1)由N个编码器堆叠而成,(N×)
(2)每个编码器由两个子层连接结构组成
(3)第一个子层连接结构,包括一个多头自注意力子层+规范化层+一个残差连接
(4)第二个子层连接结构,包括一个前馈全连接子层+规范化层+一个残差连接
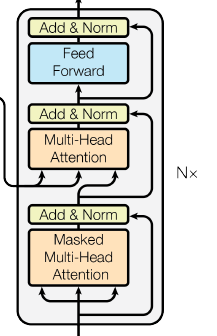
1.4 简单介绍解码器部分
- 包括五个部分:
(1)由N个解码器堆叠而成
(2)每个解码器有三个子层连接结构组成
(3)第一个子层连接结构,包括一个多头自注意力子层(有掩码Mask) + 规范化子层 + 一个残差连接
(4)第二个子层连接结构,包括一个多头注意力子层(跟上面不一样) + 规范化子层 + 一个残差连接
(5)第三个子层连接结构,包括一个前馈全连接子层 + 规范化子层 + 一个残差连接
2 输入部分实现
包括:
(1)原文本的嵌入(Embedding) + 位置嵌入
(2)目标文本的嵌入(Embedding) + 位置嵌入
2.1 Embedding 的介绍
一共介绍两种方式 : 随机初始化 、 word2vec
2.1.1 采用随机初始化
- 注意:
vocab:词表的大小
d_model : 词嵌入的维度
- 代码1
embedding = nn.Embedding(10, 3)
# 词表的大小10, 词嵌入的维度3
input1 = torch.LongTensor([[1, 2, 4, 5], [4, 3, 2, 9]])
print(input1)
print("***********")
print(embedding(input1))
- 输出
tensor([[1, 2, 4, 5],
[4, 3, 2, 9]])
***********
tensor([[[-1.1630, 2.8922, -0.5683],
[-0.8624, 1.6620, 0.2009],
[-0.5450, -1.9818, -0.1903],
[-0.0881, -0.7342, 0.5417]],
[[-0.5450, -1.9818, -0.1903],
[ 0.0551, -0.5700, -0.3047],
[-0.8624, 1.6620, 0.2009],
[-0.7385, -1.4200, 0.1704]]], grad_fn=<EmbeddingBackward0>)
- 代码2
**from torch import nn
import torch
embedding = nn.Embedding(10, 3, padding_idx=0)
input1 = torch.LongTensor([0, 2, 0, 8])
print(embedding(input1))**
- 输出:
tensor([[ 0.0000, 0.0000, 0.0000],
[ 1.7297, 0.3309, -0.8999],
[ 0.0000, 0.0000, 0.0000],
[-0.6649, 2.0290, 0.4459]], grad_fn=<EmbeddingBackward0>)
Process finished with exit code 0
2.1.2 采用word2vec
2.1.3 采用随机初试化的实战代码
代码介绍:
1. 输入x: [[100, 2, 421, 508], [491, 998, 1, 221]]
代表的是两组数据(batch_size=2)
每组数据都是一个4d的向量表示
2. 期望输出 :对于两个4d的向量, 通过词嵌入,映射成512d的向量
最后的shape组成 [batch_size, 4, 512],也就是[2, 4, 512]
3. Embedding层的介绍
只有一层nn.Embedding()
返回的时候。注意 × math.sqrt(self.d_model)
- 完整代码如下(可以直接运行):
import math
from torch.autograd import Variable
from torch import nn
import torch
# 构建 Embedding 类来实现文本嵌入层
class Embedding(nn.Module):
def __init__(self, vocab, d_model):
# vocab: 词表的大小
# d_model : 词嵌入的维度
super(Embedding, self).__init__()
# 定义 Embedding 层
self.lut = nn.Embedding(vocab, d_model)
# 将参数传入类中国
self.d_model = d_model
def forward(self, x):
# x: 代表的是输入进模型的文本,通过词汇映射后的数字张量
return self.lut(x) * math.sqrt(self.d_model)
# 词表: 1000*512, 共是1000个词,每一行是一个词,每个词是一个512d的向量表示
vocab = 1000
d_model = 512
x = Variable(torch.LongTensor([[100, 2, 421, 508], [491, 998, 1, 221]]))
emb = Embedding(vocab, d_model)
embr = emb(x)
print("ember:", embr, "\n*********\n", embr.shape)
- 输出的shape 是
[2, 4, 512]:
ember: tensor([[[ -1.5284, 8.9630, -28.1908, ..., 8.9494, -30.8598, 25.3919],
[ -6.2146, -12.5481, 6.0884, ..., -7.7220, 61.5759, 2.7136],
[ 16.2398, -4.2148, 7.3554, ..., 25.9346, -23.0663, -3.7351],
[ 2.1319, 50.7419, -17.3968, ..., 4.0045, -38.6387, -0.0956]],
[[-16.8649, 9.5925, 6.0954, ..., -43.2856, -13.5794, -2.5090],
[ 2.2715, 10.9802, 17.8983, ..., -23.2544, -53.0442, 3.8845],
[ 19.2986, -20.5505, 31.6046, ..., 21.5987, -2.3912, -3.8113],
[ 6.6228, -26.5737, 19.1182, ..., 18.1940, 9.9820, 35.8124]]],
grad_fn=<MulBackward0>)
*********
torch.Size([2, 4, 512])
2.2 位置编码器实现
- 为什么要添加位置编码器?
在RNN是串行输入的,而在Transformer中是并行输入的,所以位置信息是确实的。
因此需要在Embedding层之后加入位置编码器,将词汇位置不同可能会产生不同的语义的信息加入到词嵌入的张量之中,以弥补位置信息的缺失。
代码介绍:
位置编码矩阵
绝对位置矩阵
输入: Embedding层的输入,shape = [2, 4, 512]
- 实例化参数:
# 词嵌入的维度是512维
d_model = 512
# 置0比率为0.1
dropout = 0.1
# 句子最大长度
max_len = 60
- 将
Embedding层的输出x(shape=24512),作为位置编码层的输入。 - 可以选择像我一样:
from embedding_layer import Embedding,也可以把刚刚的代码复制一份放在这个代码上面。
import math
from torch.autograd import Variable
from torch import nn
import torch
from embedding_layer import Embedding
# 构建位置编码器的类
class PositionalEncoding(nn.Module):
def __init__(self, d_model, dropout, max_len=5000):
# d_model : 代表词嵌入的维度
# dropout : 代表Dropout层的置零比率
# max_len : 代表每个句子的最大长度
super(PositionalEncoding, self).__init__()
# 实例化 Dropout层
self.dropout = nn.Dropout(p=dropout)
# 初始化一个位置编码矩阵,大小是 max_len * d_model
pe = torch.zeros(max_len, d_model)
# 初始化一个绝对位置矩阵, max_len * 1
position = torch.arange(0, max_len).unsqueeze(1)
print(position)
# 定义一个变化矩阵,div_term, 跳跃式的初始化
div_term = torch.exp(torch.arange(0, d_model, 2) * -(math.log(10000.0) / d_model))
print("\ndiv_term", div_term)
# 将前面定义的变化矩阵 进行技术,偶数分别赋值
pe[:, 0::2] = torch.sin(position * div_term) # 用正弦波给偶数部分赋值
pe[:, 1::2] = torch.cos(position * div_term) # 用余弦波给奇数部分赋值
# 将二维张量,扩充为三维张量
pe = pe.unsqueeze(0) # 1 * max_len * d_model
# 将位置编码矩阵,注册成模型的buffer,这个buffer不是模型中的参数,不跟随优化器同步更新
# 注册成buffer后,就可以在模型保存后 重新加载的时候,将这个位置编码器和模型参数
self.register_buffer('pe', pe)
def forward(self, x):
# x : 代表文本序列的词嵌入表示
# 首先明确pe的编码太长了,将第二个维度,就是max_len对应的维度,缩小成x的句子的同等的长度
x = x + Variable(self.pe[:, : x.size(1)], requires_grad=False) # 表示位置编码是不参与更新的
return self.dropout(x)
d_model = 512
dropout = 0.1
max_len = 60
vocab = 1000
x = Variable(torch.LongTensor([[100, 2, 421, 508], [491, 998, 1, 221]]))
emb = Embedding(vocab, d_model)
embr = emb(x)
x = embr # shape: [2, 4, 512]
pe = PositionalEncoding(d_model, dropout, max_len)
pe_result = pe(x)
print(pe_result)
print("\n*********\n", pe_result.shape)
2.3 输出位置矩阵
由于这里的x传入的是一个zeros,全零矩阵,那么在PositionalEncoding 模型 的forward 中,就只保留了位置向量(相当于展示pe),而且在调用时,dropout=0
- 代码如下:
import matplotlib.pyplot as plt
from position import PositionalEncoding
import math
from torch.autograd import Variable
from torch import nn
import torch
import numpy as np
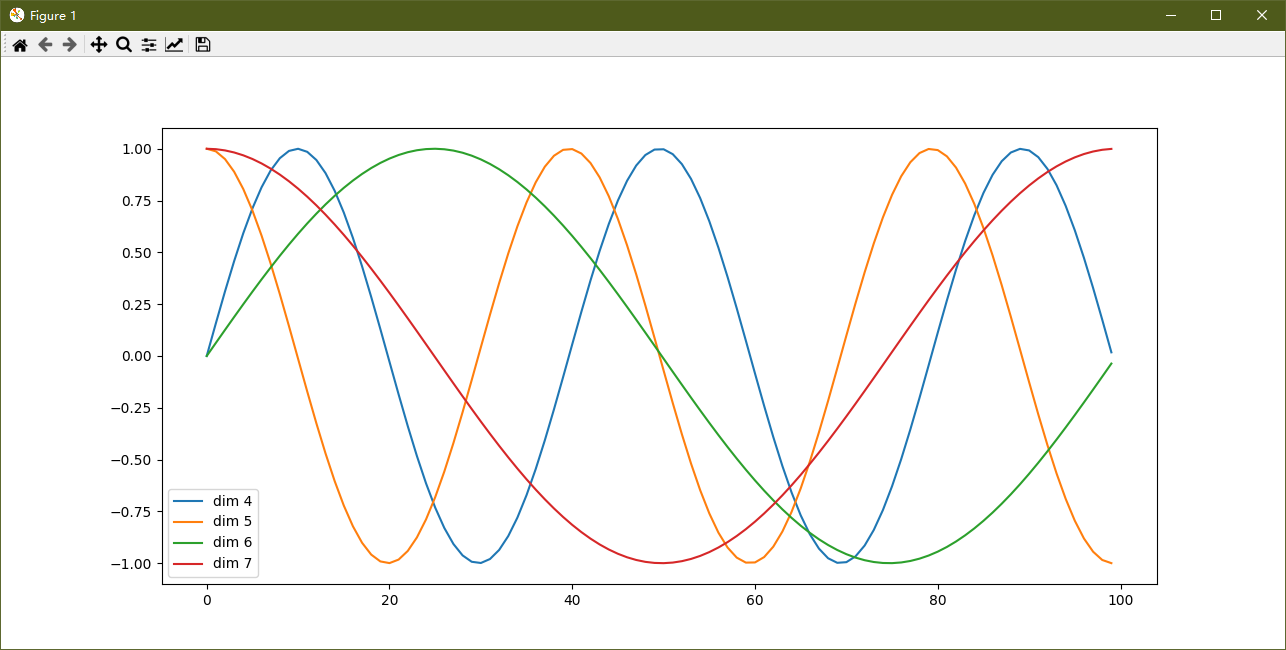
plt.figure(figsize=(15, 5))
pe = PositionalEncoding(20, 0) # 实例化这个模型,d_model = 20, dropout = 0
y = pe(Variable(torch.zeros(1, 100, 20))) # 相当于只看位置矩阵
plt.plot(np.arange(100), y[0, :, 4:8].data.numpy())
# 在画布上填写维度提示信息
plt.legend(["dim %d" %p for p in [4, 5, 6, 7]])
plt.show()
-
输出如下:
-
分析:
(1)每条颜色的曲线代表某一个词汇中的特征在不同位置的含义;
(2)保证同一词汇随着所在位置不同,它对应位置嵌入向量会发生变化
(3)sin和cos函数使得输入都在 [-1, 1] 之间,方面模型计算。
2.4 总结
- 学习了文本嵌入层的作用(Embedding)
(1)无论是源文本还是目标文本嵌入,都是为了将文本转换为向量表示,希望在高维空间捕捉词汇间的关系。
(2)位置编码器:因为transformer是并行输入的,忽略了位置信息,所以要在Embedding层后加入位置编码器。将词汇位置不同可能会产生的不同语义的信息加入到词嵌入张量中,以弥补位置信息的缺失。
3 多头注意力机制解读
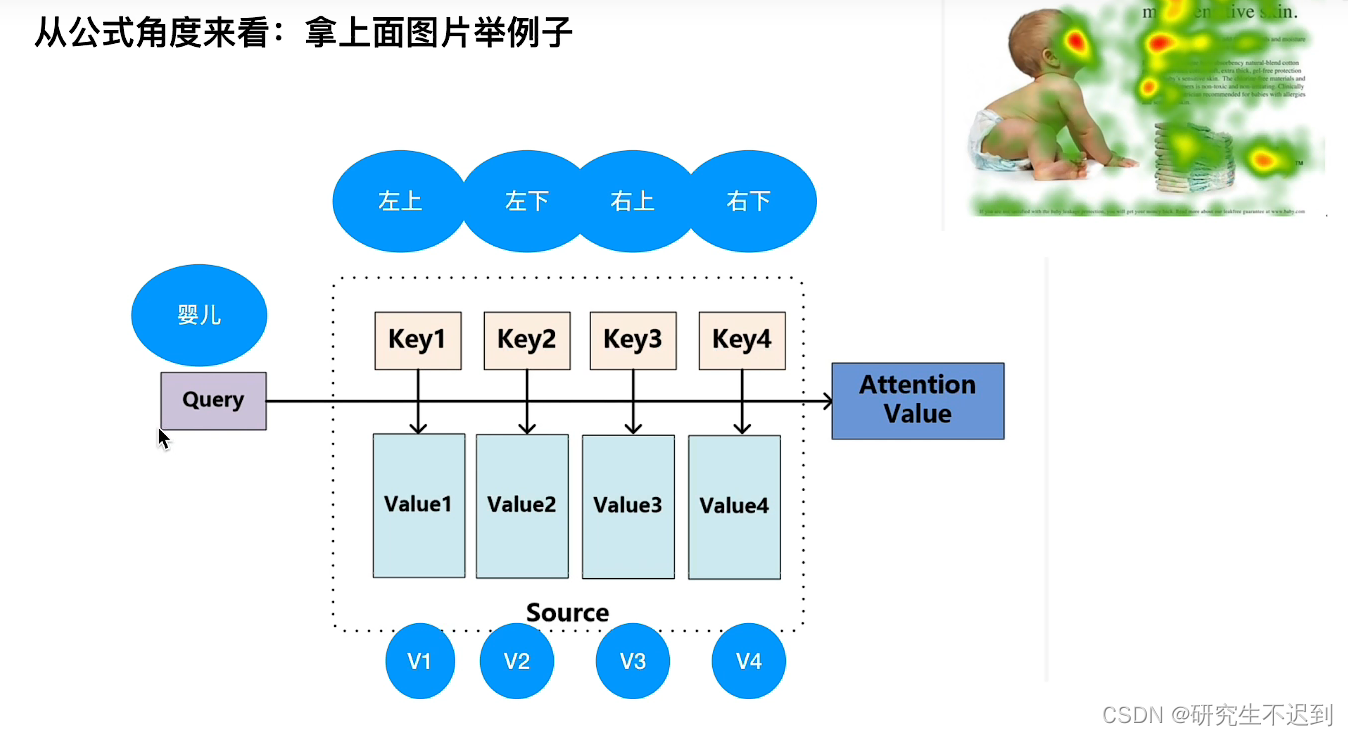
考虑 “ 婴儿在干嘛” 这句话和图片上哪些特征有关。

3.1 公式
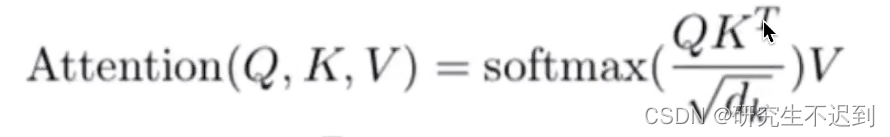
3.2 例1
相似度计算: 点乘的结果是一个向量在另外一个向量的投影长。
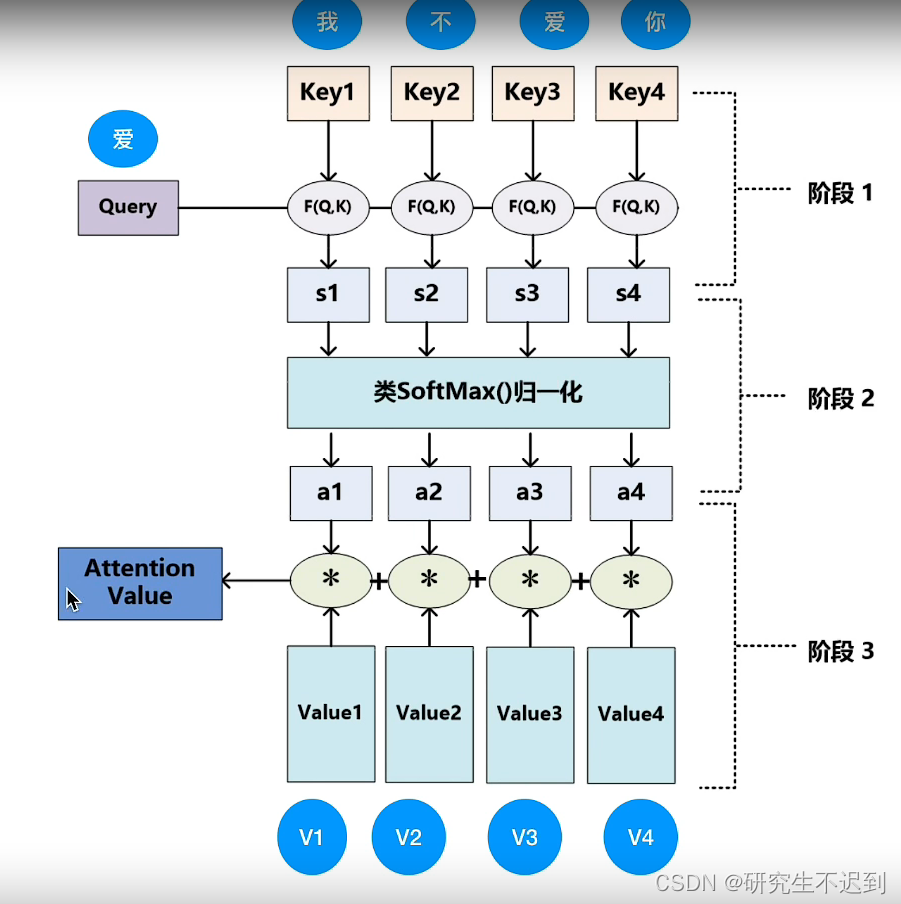

4 Layer Normalization
- 优于BN
- BN 在NLP中效果很差 (这里不说现在研究对于BN的改进)
4.1 BN 的缺点
- batch_size 比较小的时候,效果差。(而NLP中,batch_size确实不是很大)
5 介绍Decoder
Encoder的输出是要和每一个Decoder做交互的。
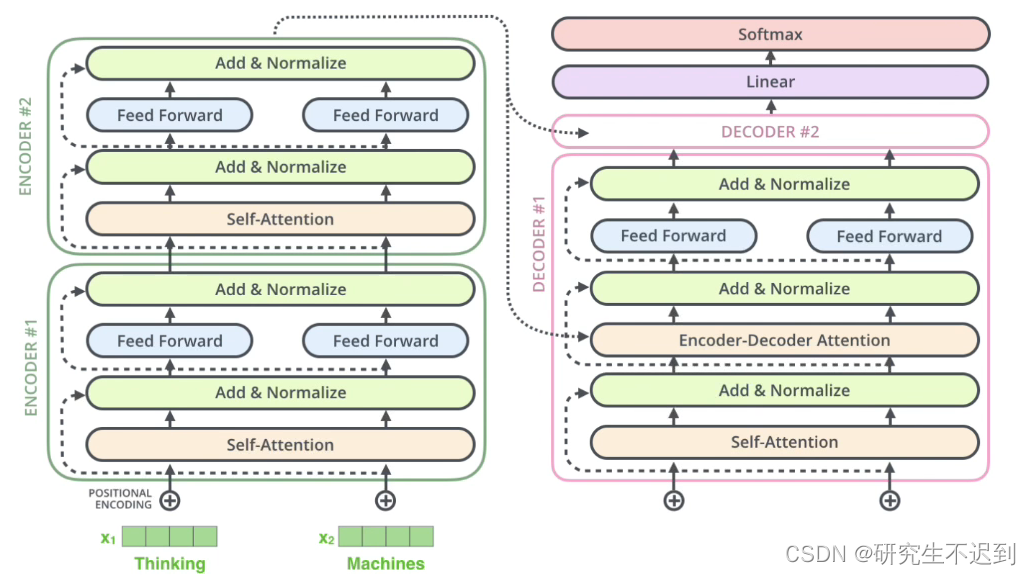
6 Seq2Seq模型
- 可以解决序列长度不对等的情况,但是如果句子太长,就不太行了
7 写在最后
transformer的代码解读:
还在写…
参考:
https://www.bilibili.com/video/BV1Di4y1c7Zm?spm_id_from=333.999.0.0