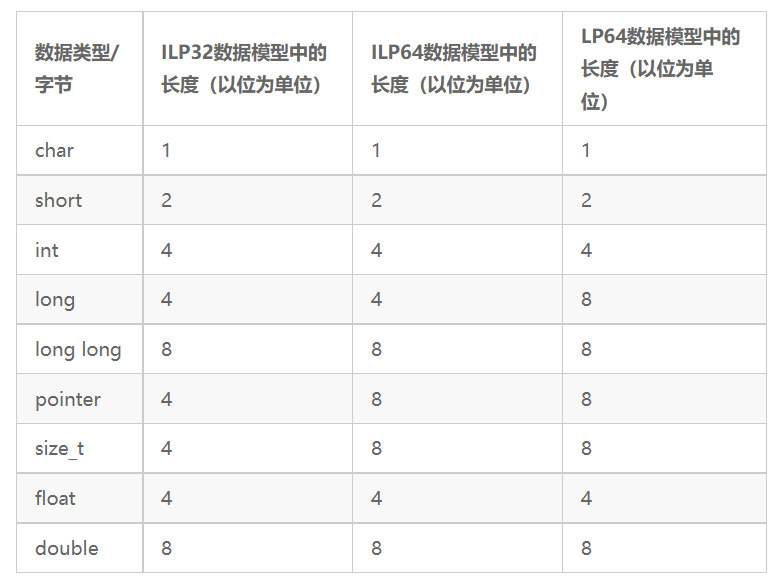
在ARM32下通常采用ILP32数据模型,而在ARM64下可以采用LP64和ILP64数据模型。在Linux系统下默认采用LP64数据模型,在Windows系统下采用ILP64数据模型。在64位机器上,若int类型是32位,long类型为64位,指针类型也是64位,那么该机器就是LP64的。其中,L表示Long,P表示Pointer。而ILP64表示int类型是32位,long类型是32位,long long类型是64位,指针类型是64位。ILP32、ILP64、LP64数据模型中不同数据类型的长度如表21.1所示。
表21.1 ILP32、ILP64、LP64数据模型中不同数据类型的长度
在32位系统里,由于整型和指针长度相同,因此某些代码会把指针强制转换为int或unsigned int来进行地址运算。
【例21-1】在下面的代码中,get_pte()函数根据PTE基地址pte_base和offset来计算PTE的地址,并转成指针类型。
1 char * get_pte(char *pte_base, int offset)
2 {
3 int pte_addr, pte;
4
5 pte_addr = (int)pte_base;
6 pte = pte_addr + offset;
7
8 return (char *)pte;
9 }第5行使用int类型把pte_base指针转换成地址,在32位系统中没有问题,因为int类型和指针类型都占用4字节。但是在64位系统中就有问题了,int类型占4字节,而指针类型占8字节。在跨系统的编程中,推荐使用C99标准定义intptr_t和uintptr_t类型,根据系统的位数来确定二者的大小。
示例代码如下。
#if __WORDSIZE == 64
typedef long int intptr_t;
typedef unsigned long int uintptr_t;
#else
typedef int intptr_t;
typedef unsigned int uintptr_t;
#endif上述代码可以修改成以下形式。
pte_addr = (intptr_t)pte_base;在Linux内核中,通常内存地址使用unsigned long来转换,这利用了指针和长整型的字节大小是相同的这个事实。
【例21-2】下面的代码利用了指针和长整型的字节大小是相同的这个事实,来实现类型转换。
1 unsigned long __get_free_pages(gfp_t gfp_mask, unsigned int order)
2 {
3 struct page *page;
4
5 page = alloc_pages(gfp_mask & ~__GFP_HIGHMEM, order);
6 if (!page)
7 return 0;
8 return (unsigned long) page_address(page);
9 }在第8行中,把page的指针转换成地址,使用unsigned long,这样保证了在32位系统和64位系统中都能正常工作。
2 数据类型转换与整型提升
C语言有隐式的数据类型转换,它很容易出错。下面是隐式数据类型转换的一般规则。
- 在赋值表达式中,右边表达式的值自动隐式转换为左边变量的类型。
- 在算术表达式中,占字节少的数据类型向占字节多的数据类型转换,如图21.1所示。例如,在ARM64系统中,当对int类型和long类型的值进行运算时,int类型的数据需要转换成long类型。
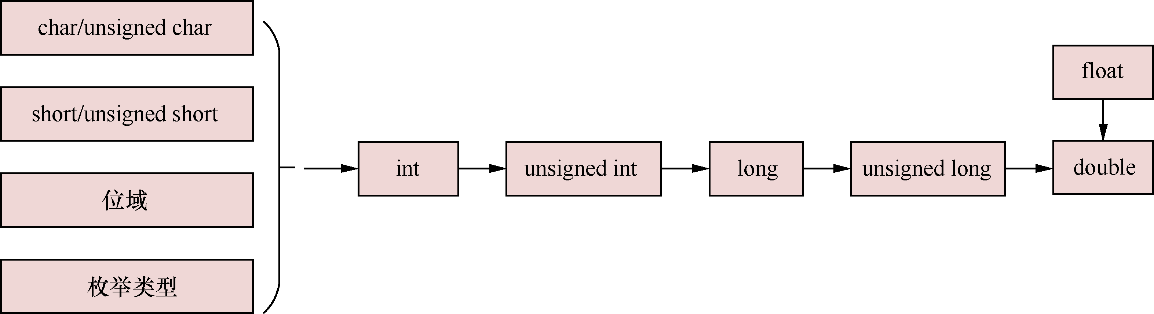
▲图21.1 数据类型转换
- 在算术表达式中,当对有符号数据类型与无符号数据类型进行运算时,需要把有符号数据类型转换为无符号数据类型。例如,若表达式中既有int类型又有unsigned int类型,则所有的int类型数据都被转化为unsigned int类型。
- 整数常量通常是int类型。例如,在ARM64系统里,整数8会使用Wn寄存器来存储,8LL则会使用Xn寄存器来存储。
【例21-3】在下面的代码中,最终输出值是多少?
1 #include <stdio.h>
2
3 void main()
4 {
5 unsigned int i = 3;
6
7 printf("0x%x\n", i * -1);
8 }首先−1是整数常量,它可以用int类型表达,而变量i是unsigned int类型。根据上述规则,当对int类型和unsigned int类型数据进行计算时,需要把int类型转换成unsigned int类型。所以,数据−1转成unsigned int类型,即0xFFFFFFFF。表达式“i −1”变成“3 0xFFFFFFFF”,计算结果会溢出,最后变成0xFFFFFFFD。
C语言规范中有一个整型提升(integral promotion)的约定。
- 在表达式中,当使用有符号或者无符号的char、short、位域(bit-field)以及枚举类型时,都应该提升到int类型。
- 如果上述类型可以使用int类型来表示,则使用int类型;否则,使用unsigned int类型。
整型提升的意义是,使CPU内部的ALU充分利用通用寄存器的长度,例如,ARM64处理器的通用寄存器支持32位宽和64位宽,而int类型和unsigned int类型正好是32位宽。对于两个char类型值的运算,CPU难以直接实现字节相加的运算,在CPU内部要先转换为通用寄存器的标准长度。在ARM64处理器里,通用寄存器最小的标准长度是32位,即4字节。因此,两个char类型值需要存储到32位的Wn通用寄存器中,然后再进行相加运算。
【例21-4】在下面的代码中,a、b、c的值分别是多少?
1 #include <stdio.h>
2
3 void main()
4 {
5 char a;
6 unsigned int b;
7 unsigned long c;
8
9 a = 0x88;
10 b = ~a;
11 c = ~a;
12
13 printf("a=0x%x, ~a=0x%x, b=0x%x, c=0x%lx\n", a, ~a, b, c);
14 }在QEMU+ARM64系统中,运行结果如下。
benshushu:mnt# ./test
a=0x88, ~a=0xffffff77, b=0xffffff77, c=0xffffffffffffff77有读者认为~a的值应该为0x77,但是根据整型提升的规则,表达式“~a”会转换成int类型,所以最终值为0xFFFFFF77。
C语言里还有一个符号扩展问题,当要把一个带符号的整数提升为同一类型或更长类型的无符号整数时,它首先被提升为更长类型的带符号等价值,然后转换为无符号值。
【例21-5】在下面的代码中,最终输出值分别是多少?
1 #include <stdio.h>
2
3 struct foo {
4 unsigned int a:19;
5 unsigned int b:13;
6 };
7
8 void main()
9 {
10 struct foo addr;
11
12 unsigned long base;
13
14 addr.a = 0x40000;
15 base = addr.a <<13;
16
17 printf("0x%lx, 0x%lx\n", addr.a <<13, base);
18 }addr.a为位域类型,根据整型提升的规则,它首先会被提升为int类型。表达式“addr.a <<13” 的类型为int类型,但是未发生符号扩展。在给base赋值时,根据带符号和无符号整数提升规则,会先转换为long,然后转换为unsigned long。从int转换为long时,会发生符号扩展。
上述程序最终的执行结果如下。
benshushu:mnt# ./test
0x80000000, 0xffffffff80000000如果想让base得到正确的值,可以先把addr.a从int类型转换成unsigned long类型。
base = (unsigned long)addr.a <<13;【例21-6】在下面的代码中,最终输出值是多少?
#include <stdio.h>
void main()
{
unsigned char a = 0xa5;
unsigned char b = ~a>>4 + 1;
printf("b=%d\n", b);
}在表达式“~a>>4 + 1”中,按位取反的优先级最高,因此首先计算“~a”表达式。根据整型提升的规则,a被提升到int类型,最终得到0xFFFFFF5A。加法的优先级高于右移运算的优先级,表达式变成0xFFFFFF5A >> 5,得到0xFFFFFFFA。最终b的值为0xFA,即250。
3 移位操作
在C语言中,移位操作是很容易出错的地方。整数常量通常被看成int类型。如果移位的范围超过int类型,那么就会出错了。
【例21-7】下面的代码片段有什么问题?
#include <stdio.h>
void main()
{
unsigned long reg = 1 << 33;
printf("0x%lx\n", reg);
}上面代码片段在编译过程中会提示如下编译警告。
benshushu:mnt# gcc test.c -o test
test.c: In function ‘main’:
test.c:5:24: warning: left shift count >= width of type [-Wshift-count-overflow]
5 | unsigned long reg = 1 << 33;
| ^~虽然编译能通过,但是程序执行结果不正确。因为整数常量1被看成int类型,在ARM64处理器中会使用Wn寄存器来存储。若左移33位,则超过了Wn寄存器的范围。正确的做法是使用“1ULL”,这样编译器会这个整数常量看成unsigned long long类型,在ARM64处理器内部使用Xn寄存器。正确的代码如下。
unsigned long reg = 1ULL << 33;以上内容摘自《ARM64体系结构编程与实践》

基于树莓派4B开发板系统介绍arm64体系结构,讲解通俗,大量实战经验与高频面试题,丰富资源随书赠送,更有配套教学视频助您快速上手。
本书旨在详细介绍ARM64体系结构的相关技术。本书首先介绍了ARM64体系结构的基础知识、搭建树莓派实验环境的方法,然后讲述了ARM64指令集中的加载与存储指令、算术与移位指令、比较与跳转等指令以及ARM64指令集中的陷阱,接着讨论了GNU汇编器、链接器、链接脚本、GCC内嵌汇编代码、异常处理、中断处理、GIC-V2,最后剖析了内存管理、高速缓存、缓存一致性、TLB管理、内存屏障指令、原子操作、操作系统等内容。
本书适合嵌入式开发人员阅读。