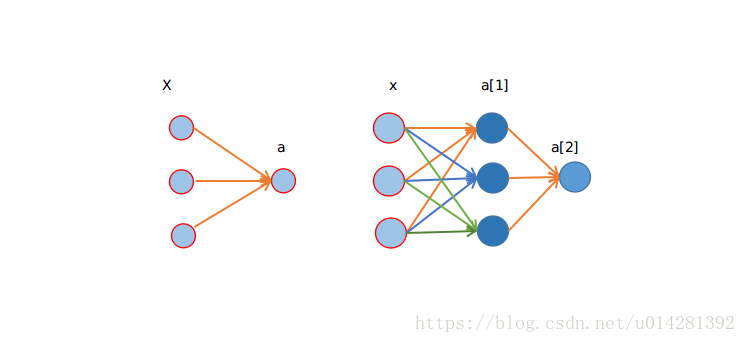
Logistic Regression to Neural Network
- Logistic Regression 可以看作是一个没有隐藏层的 Neural Network
- Neural Network 可以看作是有多个Logistic Regression 堆叠而成的
-
- Logistic Regression
-
- Neural Network with one hidden layer
1.Logistic Regression
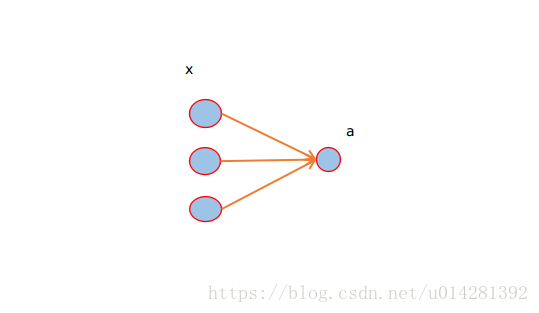
上图是一个Logistic Regression模型的结构图
-
x
: 模型的输入,是一个样本的特征向量,shape=(3,1)
-
w
: 连接输入和输出之间的权值矩阵,shape=(3,1)
-
b
:偏置,shape(1,)
-
a
:模型的最终输出,要经过非线性函数
σ
的'激活'
-
σ
:
σ=11+e−(wx+b)
1.1 Forward propagate
z=wTx+b(1)
y^=a=σ(z)(2)
1.2 Object function(cost function)
J=−(ylog(y^)+(1−y)log(1−y^))(3)
1.3 Backward propagate
1,
dw=∂J∂a.∂a∂z.∂z∂w=?
2,
db=∂J∂a.∂a∂z=?
-
∂Ja=−ya+1−y1−a=a−ya(1−a)
-
∂az=a(1−a)
-
∂zw=x
dw=(a−y)x(4)
db=a−y(5)
w=w−αdw(6)
b=b=αdb(7)
1.4 Explanation Cost Function
关于cost function 我们约定:
y^=p(y=1|x)
-
y^
: 在给定训练样本
x
的条件下,y = 1的概率,
1−y^
: y = 0的概率
-
y=1:p(y|x)=y^
-
y=0:p(y|x)=1−y^
在2分类问题当中,
p(y|x)
,包含两种情况 y = 0 或 y = 1,所以两个条件概率合并如下:
p(y|x)=y^y(1−y^)(1−y)(8)
-
y=1,y^y=y^,(1−y^)(1−y)=1,p(y|x)=y^
-
y=0,y^y=1,(1−y^)(1−y)=1−y^,p(y|x)=1−y^
-
log()
是严格的单调递增函数,最大化
log(p(y|x))
等价与最大化
p(y|x)
.
log(p(y|x))=log(y^y(1−y^)(1−y))(9)
- 化简后:
ylog(y^)+(1−y)log(1−y^)
J=−L(y^,y)
加负号的原因:
扫描二维码关注公众号,回复:
1439867 查看本文章

- 训练模型时需要输出的概率值最大
- 逻辑回归中要最小化损失函数
2. Neural Network
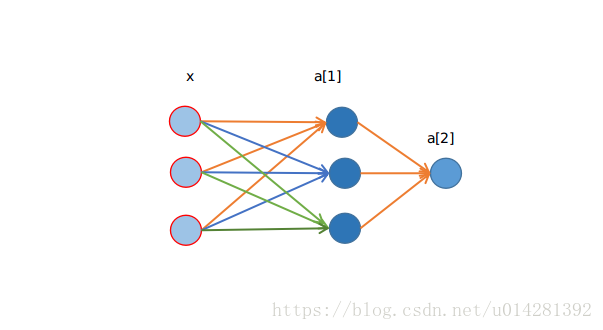
上图所示,是一个三层的网络结构,输入层神经元数量为
n[0]
,隐藏层为
n[1]
,输出层为
n[2]
.
-
n[0]
: 3
-
n[1]
: 3
-
n[2]
: 1
-
x=a[0]
: 输入样本的特征向量
a[0]
,shape=(
n[0]
,1)
-
w[1]
: 连接输入层和隐藏层之间的权值矩阵,shape=(
n[0]
,
n[1]
)
-
b[1]
: 偏置,可以是一个标量,numpy中的'广播'机制会传递给矩阵或向量中的每一个元素,shape=(1,)
-
a[1]
: 隐藏层的输出,shape=(
n[1]
, 1)
-
w[2]
: 连接隐藏层和输出层之间的权值矩阵,shape=(
n[1]
,
n[2]
)
-
b[2]
: 偏置
-
a[2]
: 输出层的输出
-
σ
:
σ=11+e−(wx+b)
2.1 Forward propagate
x
为一个样本的特征向量,shape=(3, 1)
z[1]=w[1]Tx+b[1](1)
a[1]=σ(z[1])(2)
z[2]=w[2]Ta[1]+b[2](3)
a[2]=y^=σ(z[2])(4)
J=−(ylog(a[2])+(1−y)log(1−a[2]))(5)
2.2 Backward propagate
dw[2]=∂J∂a[2].∂a[2]∂z[2].∂z[2]w[2]
db[2]=∂J∂a[2].∂a[2]∂z[2]
∂J∂a[2]=−ya[2]+1−y1−a[2]=a[2]−ya[2](1−a[2])
∂a[2]∂z[2]=a[2](1−a[2])
∂z[2]w[2]=a[1]
dw[2]=a[2]−ya[2](1−a[2]).a[2](1−a[2]).a[1]=(a[2]−y)a[1](6)
db[2]=a[2]−ya[2](1−a[2]).a[2](1−a[2])=a[2]−y(7)
dw[1]=∂J∂a[2].∂a[2]∂z[2].∂z[2]a[1].∂a[1]∂z[1].∂z[1]w[1]
db[1]=∂J∂a[2].∂a[2]∂z[2].∂z[2]a[1].∂a[1]∂z[1]
∂z[2]a[1]=w[2]
∂a[1]∂z[1]=a[1](1−a[1])
∂z[1]w[1]=x
dw[1]=x⊙(((a[2]−y)w[2])⊙(a[1](1−a[1])))T(8)
db[1]=a[2]−ya[2](1−a[2]).a[2](1−a[2]).w[2].a[1](1−a[1])=((a[2]−y)w[2])⊙(a[1](1−a[1]))(9)
w[1]=w[1]−αdw[1](10)
b[1]=b[1]−αdb[1](11)
w[2]=w[2]−αdw[2](12)
b[2]=b[2]−αdb[2](13)