目录
前言
在我开始学习c语言时,"+-*/...."这类我都不知他是叫操作符的,说来也确实惭愧,代码写了许久也是知道了一些简单的用法,但是感觉还是不够全面。这篇文章会让你对操作符有更深的理解,更加完善你对操作符的知识储备。
注释符号
首先c语言有两种注释符,单行注释符://注释内容;多行注释:/* 注释内容 */
下面我们通过代码来理解他的使用:
#include <stdio.h>
#include <windows.h>
int main()
{
int /* */ i; //正确int i
char *s = "abcdefgh //hijklmn"; //正确"abcdefgh "
//Is it a\
valid comment? //正确
in/* */t j; //报错 in t j;
system("pause");
return 0;
}
//预处理-->编译-->汇编-->链接
//在预处理的时候,就会将这些注释清理掉,预处理后还是c语言。![]()
代码在linux中的预处理阶段显示如下:
结论:注释被替换,本质是替换成空格
# 和 define之间可以带空格吗?
#include <stdio.h>
/*这是*/#/*一条*/define/*合法的*/ID/*预处理*/10/*指令*/
//#define ID 10
int main()
{
printf("%d", ID);
return 0;
}
结论:# define中间是可以有空格的,但是不推荐
注释的嵌套问题
#include <stdio.h>
#include <windows.h>
int main()
{
/*
/*printf("hello world");
printf("hello world");*/
*/
system("pause");
return 0;
}
结论:C风格注释无法嵌套,/*总是与离它最近的*/匹配
容易的书写错误
#include <stdio.h>
#include <windows.h>
int main()
{
int x = 10;
int y = 0;
int z = 5;
int *p = &z;
y = x/*p;
system("pause");
return 0;
}

解决方法:y = x/(*p); 明确出对指针的解引用
基于条件编译,代码编译期间处理
#include <stdio.h>
#include <windows.h>
int main()
{
#if 0
printf("for test1\n"); //test1
printf("for test2\n"); //test2
#endif
system("pause");
return 0;
}
基于if判断,代码运行期间处理。严重不推荐
#include <stdio.h>
#include <windows.h>
int main()
{
if (0){
printf("for test1\n"); //test1
printf("for test2\n"); //test2
}
system("pause");
return 0;
}
接续符和转义符
在c语言中'\'具有两个作用:1.接续符,编译器的指示符这一行尚未结束,一下行接着上一行。 2.转义符,无显示符,平时经常用到的如'\t','\n','\r'等
续行功能
#include <stdio.h>
#include <windows.h>
int main()
{
int a = 1;
int b = 2;
int c = 3;
//试试在\之后带上空格,行不行?
//试试在\之前带上空格,行不行?
//建议:不要带
if (a == 1 &&\
b == 2 &&\
c == 3){
printf("hello world!\n");
}
system("pause");
return 0;
}
//这是可以的
转义
#include <stdio.h>
#include <windows.h>
int main()
{
//printf("\""); //特殊转字面
printf("h\tello b\nit!\n"); //字面转特殊
system("pause");
return 0;
}
'\r'与'\n'
回车:光标回到当前的最开始的地方
换行:光标移到到下一行
'\r': 回车,'\n':换行+回车

用'\r'编写\在[]中旋转
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include <windows.h>
int main()
{
int index = 0;
const char *lable = "|/-\\";
while (1)
{
index %= 4;
printf("[%c]\r", lable[index]);
index++;
Sleep(1000);
}
return 0;
}用'\r'编写一分钟倒计时
#include <stdio.h>
#include <windows.h>
int main()
{
int i = 60;
while (i >= 0){
Sleep(1000);
printf("%2d\r", i--);
}
printf("\n倒计时结束!\n");
system("pause");
return 0;
}单引号和双引号
基本概念
单引号是字符,双引号是字符串
#include <stdio.h>
#include <windows.h>
//不同编译器,会有细微的差别
int main()
{
printf("%d\n", sizeof(1)); //4 1做的是一个int
printf("%d\n", sizeof("1"));//2 双引号代表的是字符串,"1,/0",2个char
//C99标准的规定,'a'叫做整型字符常量(integer character constant),被看成是int型
printf("%d\n", sizeof('1')); //4
char c = '1';
printf("%d\n", sizeof(c));1 1个char
system("pause");
return 0;
}

特殊情况
#include <stdio.h>
#include <windows.h>
int main()
{
printf("%d\n", sizeof('')); //报错
printf("%d\n", sizeof('a')); //4
printf("%d\n", sizeof("")); //大小为1
system("pause");
return 0;
}
//这里有一个概念,在""中是一个元素都没有的,在字符串中"\0"不算有效元素,
//它应该算字符串结束的标识符为何计算机需要字符
计算机本质只认识二进制,那么计算机为何需要字符呢?直接全部二进制不香吗?
因为计算机是为了解决人的问题,可是,人怎么知道计算机解决了人的问题??你输出二进制结果,人能直接看懂吗?
所以,为何计算机需要需要字符,本质是为了让人能看懂。
那为什么又是英文的呢?中文不香吗?
最早的计算机是美国人发明的,他们的语言是英语,大家想想,英语,不就是26个英文字母+一大堆标点符号组成的吗?
另外,计算机刚刚开始发明,人美国人只要能解决他们的问题就行,所以就有了现在的简单字符
计算机只认识二进制,而人只认识字符。所以,一定要有一套规则,用来进行二进制和字符的转化,这个就叫做ASCII码 ---来自蛋哥

-----来自百度
逻辑运算符
&&
&&为界将表达式分为两部分,他会先算前一部分,如果前一部分为假,他将停止运算,如果为真,他才会算第二部分,你这里第一部分就为假了,第二部分当然也就不会算了。
以下代码打印结果?
#include <stdio.h>
#include <windows.h>
int main()
{
int i = 0;
int j = 0;
if ((++i < 0) && (++j > 0))
{
printf("enter if!\n");
}
printf("%d, %d\n", i, j); //1, 1
system("pause");
return 0;
}
//结果是1, 1 ,因为a&&b都为真才继续执行,后置++为假||
|| 为界将表达式分为两部分,他会先算前一部分,如果前一部分为真,他将停止运算,如果为假,他才会算第二部分,你这里第一部分就为真了,第二部分当然也就不会算了。
以下代码打印结果?
#include <stdio.h>
#include <windows.h>
int main()
{
int i = 0;
int j = 0;
if ((++i > 0) || (++j > 0)){ //注意更改条件
printf("enter if!\n");
}
printf("%d, %d\n", i, j); // 1, 0
system("pause");
return 0;
}
//结果:enter if! 1, 0
//a||b只要一个为真就执行短路问题
上面的一个条件不满足,已经不需要在看后续的条件的情况,就叫做短路
上面代码实现了什么功能呢?
#include <stdio.h>
#include <windows.h>
#pragma warning(disable:4996) //对scanf报错,特殊处理安全问题的方法
int show()
{
printf("you can see me!\n");
return 1;
}
int main()
{
int a = 0;
scanf("%d", &a);
a == 10 && show();
a == 10 || show();
system("pause");
return 0;
} 在a == 10 && show()中,如果输入a不等于10则就会短路,在 a == 10 || show()中,如果输入a不等于10则就会短路
位运算符
基本概念
‘&’:按位与操作,按二进制位进行"与"运算;
‘|’:按位或操作,按二进制位进行"或"运算;
‘^’:按位异或操作,按二进制位进行"异或"运算;
‘~’:按位取反操作,按二进制位进行"取反"运算;
#include <stdio.h>
#include <windows.h>
int main()
{
printf("%d\n", 2 | 3); //0010 | 0011 -->0011 --->3 (只展示了有效的4比特为)
printf("%d\n", 2 & 3); //0010 & 0011 -->0010 --->2
printf("%d\n", 2 ^ 3); //0010 ^ 0011 -->0001 --->1
printf("%d\n", ~0); //0000 0000 0000 0000 0000 0000 0000 0000 --->取反
//1111 1111 1111 1111 1111 1111 1111 1111 原
//1000 0000 0000 0000 0000 0000 0000 0000 反+1
//1000 0000 0000 0000 0000 0000 0000 0001 补
//结果为-1
system("pause");
return 0;
}
&&,|| vs &,|的区别
&&,||:级联的是多个逻辑表达式,需要的是真假结果
& ,|:级联的是多个数据,逐比特位进行位运
关于^
^:逐比特位,相同为假,相异为真
^:支持结合律和交换律
交换两个数的三种方法
#include <stdio.h>
#include <windows.h>
//dome1 增加了变量
int main()
{
int x = 10;
int y = 20;
printf("before: %d,%d\n", x, y);
int temp = 0;
temp = x;
x = y;
y = temp;
system("pause");
printf("after: %d,%d\n", x, y);
return 0;
}
//dome2 数值过大会出现栈溢出
int main()
{
int x = 10;
int y = 20;
printf("before: %d,%d\n", x, y);
x = x + y;
y = x - y;
x = x - y;
printf("after: %d,%d\n", x, y);
system("pause");
return 0;
}
//dome3 利用^的交换律,不增加变量也不会出现栈溢出
int main()
{
int x = 10;
int y = 20;
printf("before: %d,%d\n", x, y);
x ^= y;
y ^= x;
x ^= y;
printf("after: %d,%d\n", x, y);
system("pause");
return 0;
}合用位运算符知识
指定比特位置为1
#include <stdio.h>
#include <windows.h>
#define SETBIT(x, n) ((x)|=(1<<(n-1))) //指定比特位置为1
void ShowBits(int x)
{
int num = sizeof(x)* 8 - 1;
while (num >= 0){
if (x & (1 << num)){
printf("1 ");
}
else{
printf("0 ");
}
num--;
}
printf("\n");
}
int main()
{
int x = 0;
//设置指定比特位为1
SETBIT(x, 5);//0000 0000 0000 0000 0000 0000 0000 0000
//显示int的所有比特位
ShowBits(x);
system("pause");
return 0;
}指定比特位置为0
#include <stdio.h>
#include <windows.h>
#define CLRBIT(x, n) ((x) &= (~(1<<(n-1)))) //将指定比特位置零
void ShowBits(int x)
{
int num = sizeof(x)* 8 - 1;
while (num >= 0){
if (x & (1 << num)){
printf("1 ");
}
else{
printf("0 ");
}
num--;
}
printf("\n");
}
int main()
{
int x = 0xFF;
CLRBIT(x, 7);
ShowBits(x);
system("pause");
return 0;
}整形提升的问题
#include <stdio.h>
#include <windows.h>
int main()
{
char c = 0;
printf("sizeof(c): %d\n", sizeof(c)); //1
printf("sizeof(c): %d\n", sizeof(~c)); //4
printf("sizeof(c): %d\n", sizeof(c << 1)); //4
printf("sizeof(c): %d\n", sizeof(c >> 1)); //4
system("pause");
return 0;
}
通过反汇编观察:

无论任何位运算符,目标都是要计算机进行计算的,而计算机中只有CPU具有运算能力(先这样简单理解),但计算的数据,
都在内存中。故,计算之前(无论任何运算),都必须将数据从内存拿到CPU中,拿到CPU哪里呢?毫无疑问,在CPU 寄存器
中。
而寄存器本身,随着计算机位数的不同,寄存器的位数也不同。一般,在32位下,寄存器的位数是32位。
可是,你的char类型数据,只有8比特位。读到寄存器中,只能填补低8位,那么高24位呢?
就需要进行“整形提升”。结论:列子中,c只要参与表达式运算,就会发生整形提升
左移和右移
<<(左移): 最高位丢弃,最低位补零
>>(右移):
1. 无符号数:最低位丢弃,最高位补零[逻辑右移]
2. 有符号数:最低位丢弃,最高位补符号位[算术右移]
#include <stdio.h>
void ShowBits(int x)
{
int num = sizeof(x)* 8 - 1;
while (num >= 0){
if (x & (1 << num)){
printf("1 ");
}
else{
printf("0 ");
}
num--;
}
printf("\n");
}
int main()
{
signed int x = 0x0FFFFFFF;
ShowBits(x);
x = x << 1; //左移
// x = x >> 1; //右移
ShowBits(x);
return 0;
}左移结果如下:

右移结果如下:
如何理解"丢弃"
基本理解链:
<< 或者 >> 都是计算,都要在CPU中进行,可是参与移动的变量,是在内存中的。
所以需要先把数据移动到CPU内寄存器中,在进行移动。
那么,在实际移动的过程中,是在寄存器中进行的,即大小固定的单位内。那么,左移右移一定会有位置跑到"外边"的情况

深度理解左移右移
#include <stdio.h>
#include <windows.h>
int main()
{
//左移
unsigned int a = 1;
printf("%u\n", a << 1); //2
printf("%u\n", a << 2); //4
printf("%u\n", a << 3); //8
//int a = -1;
//printf("%d\n", a << 1);//-2
//在正负数数情况下 向左移一位是乘2
//逻辑右移
unsigned int b = 100;
printf("%u\n", b >> 1);//50
printf("%u\n", b >> 2);//25
printf("%u\n", b >> 3);//12
//在正数情况下,向右移一位是除2
//算术右移,最高位补符号位1, 虽然移出了最低位1,但是补得还是1
int c = -1;
printf("%d\n", c >> 1);//-1
printf("%d\n", c >> 2);//-1
printf("%d\n", c >> 3);//-1
//这里因为有符号位,最高位补的符号位
//是算术右移,还是逻辑右移?最高位补0,为何?
unsigned int d = -1;
printf("%d\n", d >> 1);//2147483647
printf("%d\n", d >> 2); //1073741823
printf("%d\n", d >> 3);//536870911
//这因为定义为无符号数,就相当于一个很大的正数,符号位为0,右移就相当于除2
system("pause");
return 0;
}
结论:
左移,无脑补0
右移,先判定是算术右移还是逻辑右移,判定依据:看自身类型,和变量的内容无关。判定了是算术,还是逻辑,才能决定最高位补什么。
一个问题
int a = 10;
a << 1; //有没有影响a本身的值,为什么?怎么样做能影响a的值答案:没有影响,因为这里根本就没有赋值,就好比 a+1;它只是在数据面进行操作了,当进行预处理的时候,没有申请内存空间的数据将会被清理掉。
解决:a=<<1;
++、--操作
基本操作
//demo1
#include <stdio.h>
#include <windows.h>
int main()
{
int a = 10;
int b = ++a; //前置++, 先自增在使用
printf("%d, %d\n", a, b); //11,11
system("pause");
return 0;
}
//demo2
#include <stdio.h>
#include <windows.h>
int main()
{
int a = 10;
int b = a++; //后置++, 先使用在自增
printf("%d, %d\n", a, b); //11, 10
system("pause");
return 0;
}
深刻理解 a++
#include <stdio.h>
#include <windows.h>
int main()
{
int a = 0xDD;
int b = a++; //有b接收,那么a的先使用是将a的值(内容),放到b中
int c = 0xEE;
c++; //没有接收方,那么"先使用",如何理解?
system("pause");
return 0;
}
通过汇编代码(核心部分)的角度来理解
int a = 0xDD;
00CA13DE mov dword ptr [a],0DDh //dword ptr [a]: 就是内存中的a,定义a变量
int b = a++; //有b接收,那么a的先使用是将a的值(内容),放到b中
00CA13E5 mov eax,dword ptr [a] //将内存中的a,放入eax寄存器
00CA13E8 mov dword ptr [b],eax //将eax寄存器中的内容,放入b。完成"先使用"
00CA13EB mov ecx,dword ptr [a] //将内存中的a,放入ecx寄存器
00CA13EE add ecx,1 //对ecx的内容(就是a的值0xDD),进行自增
00CA13F1 mov dword ptr [a],ecx //将计算结果,写回a变量.完成"再自增"
int c = 0xEE;
00CA13F4 mov dword ptr [c],0EEh //定义c变量
c++; //没有接收方,那么"先使用",如何理解?
00CA13FB mov eax,dword ptr [c] //将C变量的内容(内存中),读入eax寄存器
00CA13FE add eax,1 //完成自增
00CA1401 mov dword ptr [c],eax //将结果写回c变量。完成"自增"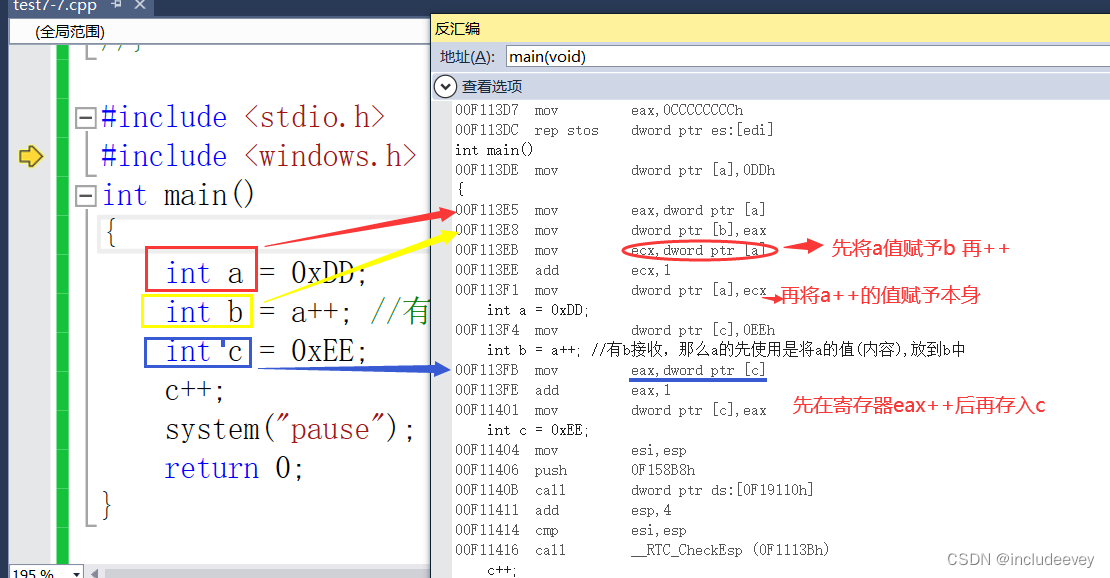
结论:a++完整的含义是先使用,在自增。如果没有变量接收,那么直接自增(或者所谓使用,就是读取进寄存器,然后没有然后)。
复杂表达式
#include <stdio.h>
#include <windows.h>
int main()
{
int i = 1;
int j = (++i)+(++i)+(++i);//2+3
printf("%d\n", j); //12
system("pause");
return 0;
}
//为什么结果是12呢?
通过汇编给你答案

在linux下观察


这里为什么linux下会是10呢?
linux汇编下汇编给你答案:

结论:本质:是因为上面表达式的"计算路径不唯一"(为什么?编译器识别表达式,是同时加载至寄存器,还是分批加载,完全不确定)导致的
-------这种写法一律不推荐使用或者编写
贪心算法
在对问题求解时,总是做出在当前看来是最好的选择。也就是说,不从整体最优上加以考虑,算法得到的是在某种意义上的局部最优解 。
贪心算法不是对所有问题都能得到整体最优解,关键是贪心策略的选择 。
-------来自百度
举个列子
#include <stdio.h>
int main()
{
int i=1;
printf("%d",i+++10);
return 0;
}
//在vs环境下,这里是i++ + 10,它是尽可能先将+读取到不能执行了再进行下一个读取
//它将++变成了一个操作符
错误!
#include <stdio.h>
int main()
{
int a = 1;
int b = 1 ;
printf("%d", a++++ + b);
return 0;
}
自己的正确断句!
#include <stdio.h>
int main()
{
int a=1;
int b=1;
printf("%d", a++ + ++b);
return 0;
}2/(-2) 的值是多少,深度理解取余/取模运算
关于“取整”:有四种,我们下面一一接受
向0取整:
int main()
{
//本质是向0取整
int i = -2.9;
int j = 2.9;
printf("%d\n", i); //结果是:-2
printf("%d\n", j); //结果是:2
system("pause");
return 0;
}
向-∞取整:
#include <stdio.h>
#include <math.h> //因为使用了floor函数,需要添加该头文件
#include <windows.h>
int main()
{
//本质是向-∞取整,注意输出格式要不然看不到结果
printf("%.1f\n", floor(-2.9)); //-3
printf("%.1f\n", floor(-2.1)); //-3
printf("%.1f\n", floor(2.9)); //2
printf("%.1f\n", floor(2.1)); //2
system("pause");
return 0;
}

向+∞取整:
#include <stdio.h>
#include <math.h>
#include <windows.h>
int main()
{
//本质是向+∞取整,注意输出格式要不然看不到结果
printf("%.1f\n", ceil(-2.9)); //-2
printf("%.1f\n", ceil(-2.1)); //-2
printf("%.1f\n", ceil(2.9)); //3
printf("%.1f\n", ceil(2.1)); //3
system("pause");
return 0;
}

四舍五入:
#include <stdio.h>
#include <math.h>
#include <windows.h>
int main()
{
//本质是四舍五入
printf("%.1f\n", round(2.1));
printf("%.1f\n", round(2.9));
printf("%.1f\n", round(-2.1));
printf("%.1f\n", round(-2.9));
system("pause");
return 0;
}
汇总例子
#include <stdio.h>
#include <math.h>
#include <windows.h>
int main()
{
const char * format = "%.1f \t%.1f \t%.1f \t%.1f \t%.1f\n";
printf("value\tround\tfloor\tceil\ttrunc\n");
printf("-----\t-----\t-----\t----\t-----\n");
printf(format, 2.3, round(2.3), floor(2.3), ceil(2.3), trunc(2.3));
printf(format, 3.8, round(3.8), floor(3.8), ceil(3.8), trunc(3.8));
printf(format, 5.5, round(5.5), floor(5.5), ceil(5.5), trunc(5.5));
printf(format, -2.3, round(-2.3), floor(-2.3), ceil(-2.3), trunc(-2.3));
printf(format, -3.8, round(-3.8), floor(-3.8), ceil(-3.8), trunc(-3.8));
printf(format, -5.5, round(-5.5), floor(-5.5), ceil(-5.5), trunc(-5.5));
system("pause");
return 0;
}

取模
取模概念:
如果a和d是两个自然数,d非零,可以证明存在两个唯一的整数 q 和 r,满足 a = q*d + r 且0 ≤ r < d。其中,q 被称为商,r 被称为余数。
#include <stdio.h>
#include <windows.h>
int main()
{
int a = 10;
int d = 3;
printf("%d\n", a%d); //结果是1
//因为:a=10,d=3,q=3,r=1 0<=r<d(3)
//所以:a = q*d+r -> 10=3*3+1
system("pause");
return 0;
}
那么如下代码的值又是多少呢?
int main()
{
int a = -10;
int d = 3;
//printf("%d\n", a/d); //C语言中是-3,很好理解
printf("%d\n", a%d);
system("pause");
return 0;
}
在vs2013下
![]()
C语言 gcc 4.8.5中
[whb@VM-0-3-centos code]$ gcc test.c
[whb@VM-0-3-centos code]$ ./a.out
-1
在Python 3.7.3中
C:\Users\whb>python --version
Python 3.7.3
C:\Users\whb>python
Python 3.7.3 (v3.7.3:ef4ec6ed12, Mar 25 2019, 22:22:05) [MSC v.1916 64 bit (AMD64)] on
win32
Type "help", "copyright", "credits" or "license" for more information.
>>> print(-10%3)
2
>>>
这里我们发现在不同编译器下他们的结果不同,这又是为什么呢?
其实我们发现他们取余,是跟取整是有关系的,
当我在vs2013中它是向0取整。-10%3=-1,首先-10/3=-3(取整后),那么-10=-3*3+-1,故余数都为-1。
在Python中它是向-∞取整,-10%3=2;首先-10/3=-4(取整后);那么-10=-4*3+2,故余数为2
所以,在不同语言,同一个计算表达式,负数“取模”结果是不同的。我们可以称之为分别叫做正余数 和 负余数
是什么决定了这种现象?
由上面的例子可以看出,具体余数r的大小,本质是取决于商q的。
而商,又取决谁呢?取决于除法计算的时候,取整规则。
取余和取模一样吗?
取余或者取模,都应该要算出商,然后才能得出余数。
本质 1 取整:
取余:尽可能让商,进行向0取整。
取模:尽可能让商,向-∞方向取整。
故:
C中%,本质其实是取余。
Python中%,本质其实是取模。(后面不考虑python,减少难度)
理解链:
对任何一个大于0的数,对其进行0向取整和-∞取整,取整方向是一致的。故取模等价于取余
对任何一个小于0的数,对其进行0向取整和-∞取整,取整方向是相反的。故取模不等价于取余
同符号数据相除,得到的商,一定是正数(正数vs正整数),即大于0!
故,在对其商进行取整的时候,取模等价于取余。
本质 2 符号:
参与取余的两个数据,如果同符号,取模等价于取余
练习
#include <stdio.h>
#include <windows.h>
int main()
{
printf("%d\n", 10 / 3); //3
printf("%d\n\n", 10 % 3); //1
printf("%d\n", -10 / -3); //3
printf("%d\n\n", -10 % -3); //-1
system("pause");
return 0;
}
在vs中

在Python中
>>> print(10//3)
3
>>> print(10%3)
1
>>> print(-10//-3)
3
>>> print(-10%-3)
-1
题外话:
注意:python中 / 默认是浮点数除法,//才是整数除法,并进行-∞取整
//听听就可以了
>>> print(10/3)
3.3333333333333335
>>> print(-10/3)
-3.3333333333333335
>>> print(10//3)
3
>>> print(-10//3)
-4
结论:通过对比试验,更加验证了,参与取余的两个数据,如果同符号,取模等价于取余
如果参与运算的数据,不同符号呢?
#include <stdio.h>
#include <windows.h>
int main()
{
printf("%d\n", -10 / 3); //-3
printf("%d\n\n", -10 % 3); //-1
printf("%d\n", 10 / -3); //-3
printf("%d\n\n", 10 % -3); //1
system("pause");
return 0;
}
//如果还不理解,其实就是
//在数学中,被除数除以除数等于商加余数,余数+除数*商=被除数
//这里商会被取整,具体看是在那个编译器下,一般就是向0或者向负无穷
//如果是商为正数取整方向一样都是向0
//如果商为负数,向0方向取整值>向负无穷取整值
//所以造成了取余的结果不同
明显结论:如果不同符号,余数的求法,参考之前定义。而余数符号,与被除数相同
总结
浮点数(或者整数相除),是有很多的取整方式的。
如果a和d是两个自然数,d非零,可以证明存在两个唯一的整数 q 和 r,满足 a = q*d + r , q 为整数,且0 ≤ |r|< |d|。其中,q 被称为商,r 被称为余数。
在不同语言,同一个计算表达式,“取模”结果是不同的。我们可以称之为分别叫做正余数 和 负余数
具体余数r的大小,本质是取决于商q的。而商,又取决于除法计算的时候,取整规则。
取余vs取模: 取余尽可能让商,进行向0取整。取模尽可能让商,向-∞方向取整。
参与取余的两个数据,如果同符号,取模等价于取余
如果参与取余的两个数据符号不同,在C语言中(或者其他采用向0取整的语言如:C++,Java),余数符号,与被除数相同。(因为采用的向0取整)
运算符优先级

-----来自百度
最后还是需要说一句感谢大家支持!!!!!!!!!