-
-
- Word2vec前提
-
首先说明一下神经网络的运作规则。
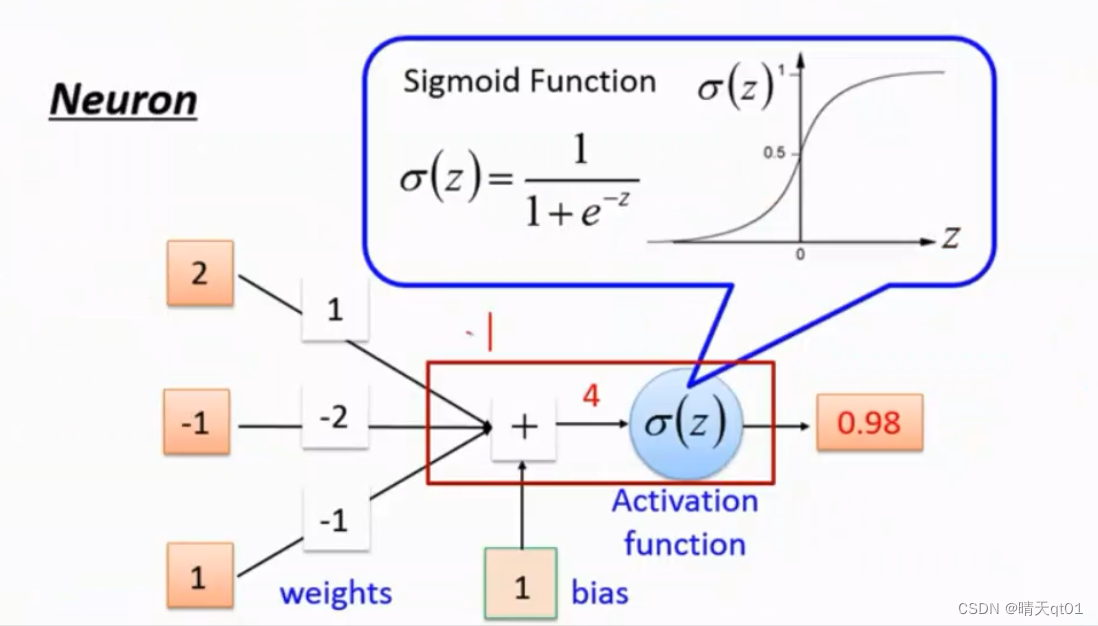
最左边是输入字段(3个神经元),中间weights是权重隐藏层,bias是偏权值,中间是累加
这里面是乘积。Z=4是神经元乘以权重,加上bias得到,然后经过激活函数(activation function)加工,左边部分是函数处理
把这些部分作为基础单元,进行练习就会得到下面的神经网络

神经元会结合到另一个神经元,连接的关系就是激活函数。
-
-
- XOR问
-

线性不可分,不能用多元线性回归计算,因为最后的结果肯定有有一些预测失败。

输入层有4个数值,异常层有两个节点,输出结果1或0,进行训练500次

这500次会调整权重值,然后调整得到隐藏层里的值
我们发现错误值会不断随着500次的次数error下降。
最终调整结果为:

我们来看看结果表格
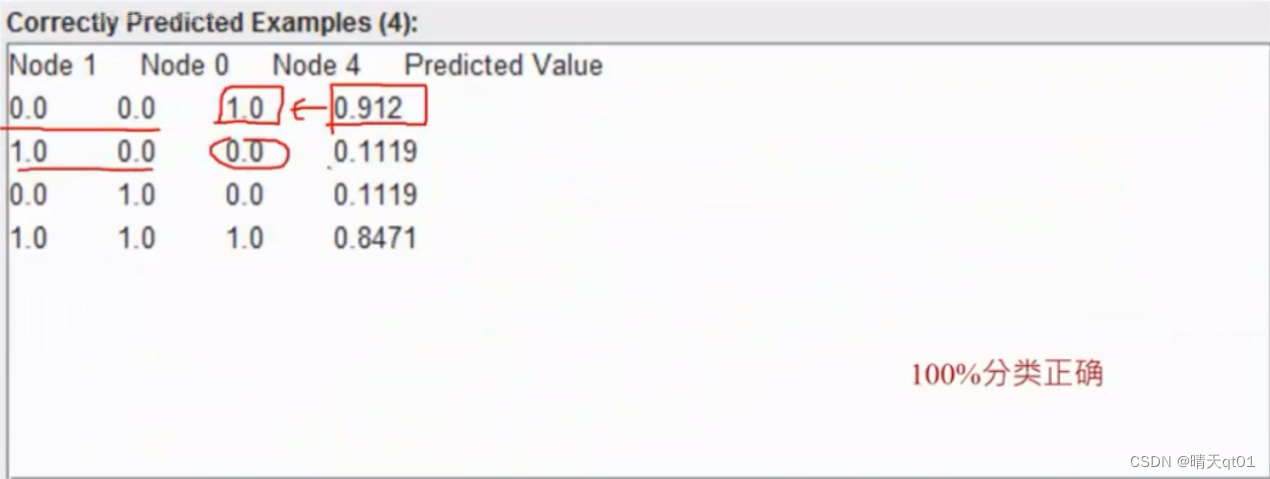
我们就开始怀疑,原本线性不可分的数值,现在出现了隐藏层,就可以分类成功了
所以我们就怀疑隐藏层的作用是什么。
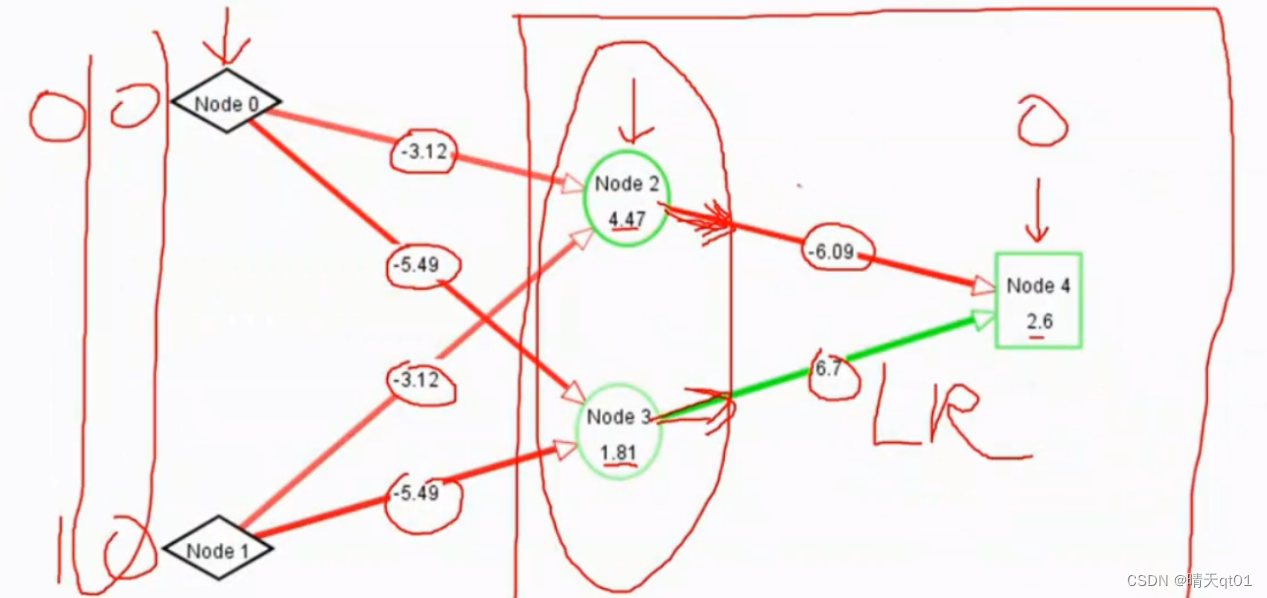
我们就可以输入,0,0。看看隐藏层输出了什么,得到结果,进行逻辑LR回归模型(这里就是上面说的神经网络框架流程。),我们发现输入字段经过隐藏层,就变成线性可分的数值了。
观察隐藏层的输出。
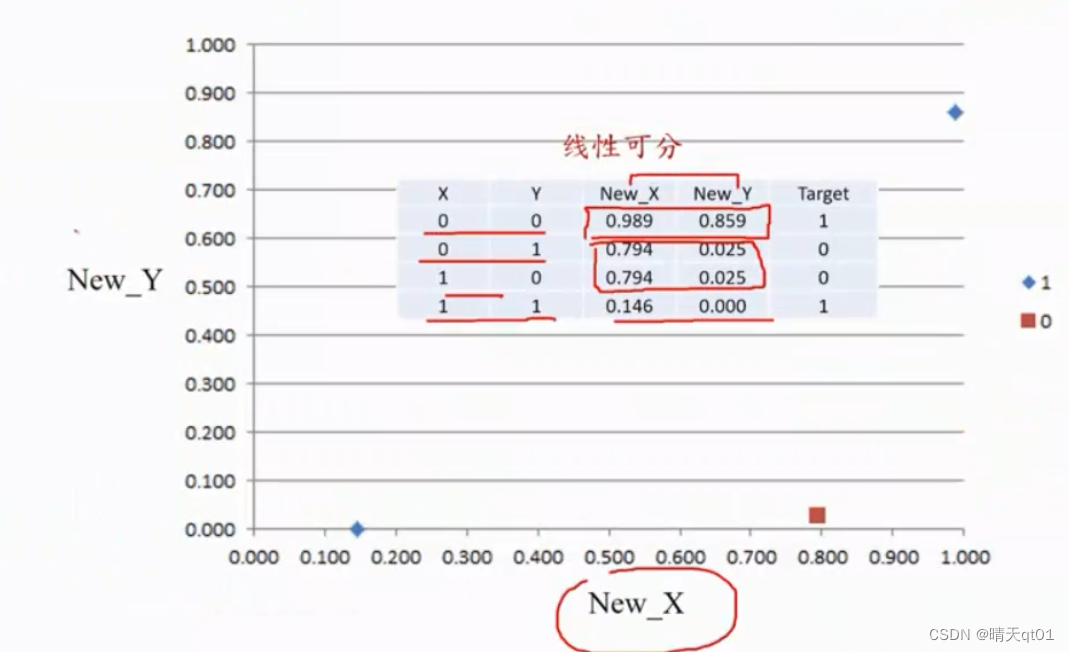
我们可以发现由输入层(input Layer)到隐藏层(Hidden Layer)的过程是为了进行目标转化,降低分析维度。
因为我们的输入层只有2个,所以本案例没有进行降维。但是如果你去用New_X进行神经网络,也可以发现,准确率为百分百。
神经网络可以帮助我们产生新特征
有个这里基础,我们就进行word2Vec
-
-
- Word2Vec(有监督模型)
-
字模型1(Skip -gram)
CBOW
输入层是关键词,输出层是结果

隐藏层有两个矩阵,矩阵1代表的是词嵌入矩阵,矩阵2代表的是
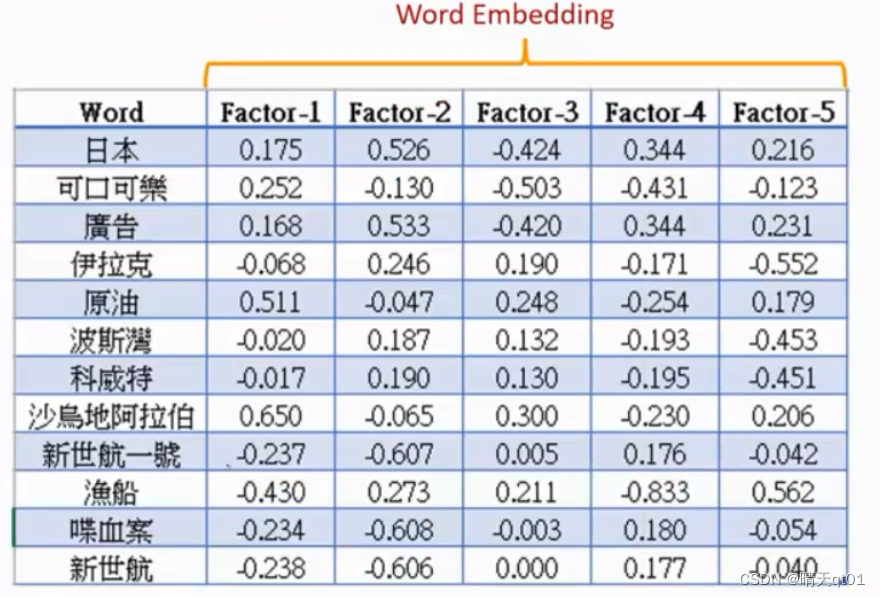
我们把之前的5篇文章,进行训练得到嵌入,word,embedding

距离远是因为前后用词完全不一样。
方法CBOW
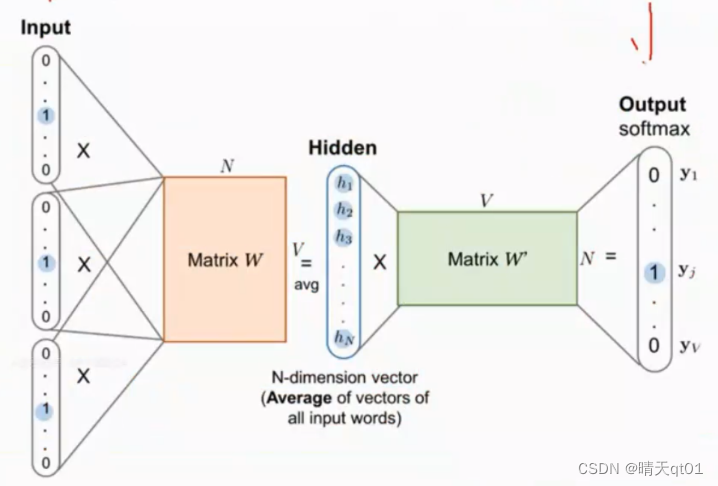
因为词的前后词很多,所以我们就可以吧,每个词的one hot encoding作为输入结果,然后我们将各自的隐藏层结果做平均值,得到我们就可以得到结果该新闻是哪类模型
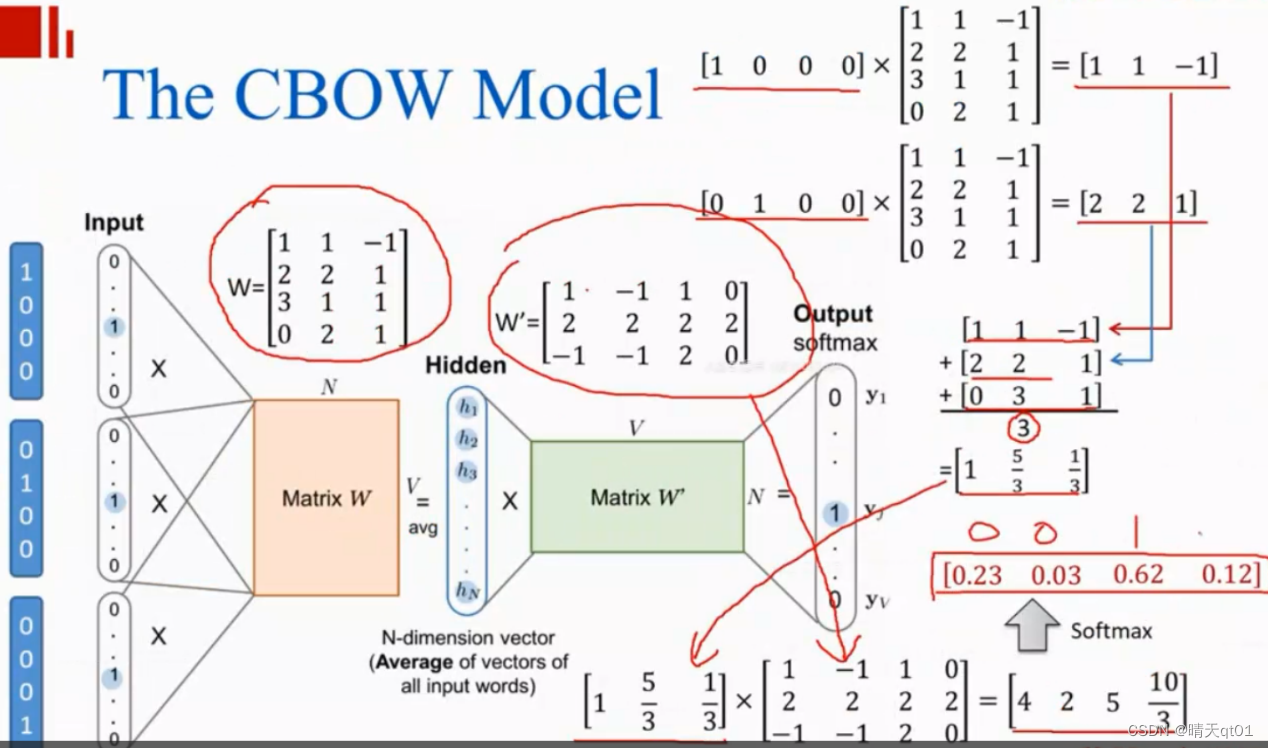
MATRIW矩阵如下

同样,我们把文章六输入进去,也可以预测到合适结果。
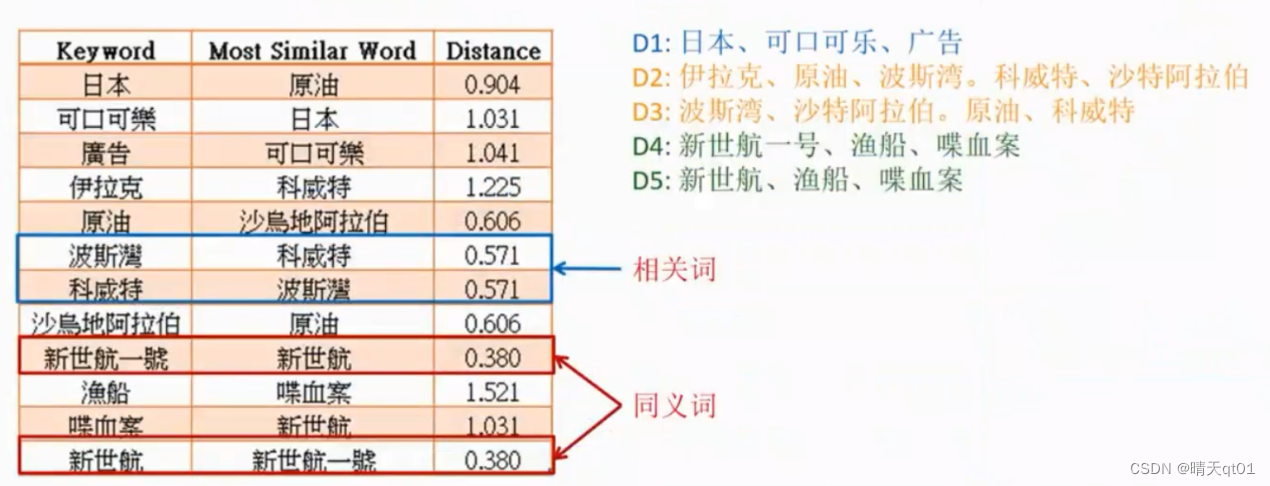
同样我们做距离可以得到相关词和同义词。