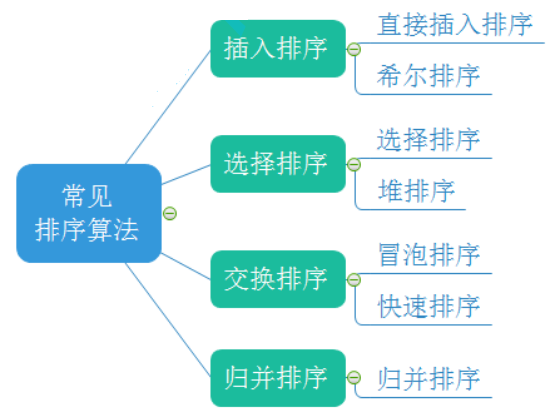
目录
扫描二维码关注公众号,回复:
14445618 查看本文章

1.前言
- 稳定性:假定在待排序的记录序列中,存在多个具有相同的关键字的记录,若经过排序,这些记录的相对次序保持不变,即在原序列中,r[i]=r[j],且r[i]在r[j]之前,而在排序后的序列中,r[i]仍在r[j]之前,则称这种排序算法是稳定的;否则称为不稳定的。
- 内部排序:数据元素全部放在内存中的排序。
- 外部排序:数据元素太多不能同时放在内存中,根据排序过程的要求不能在内外存之间移动数据的排序。
-
2.直接插入排序:
- 当插入第i(i>=1)个元素时,前面的array[0],array[1],…,array[i-1]已经排好序,此时用array[i]的排序码与array[i-1],array[i-2],…的排序码顺序进行比较,找到插入位置即将array[i]插入,原来位置上的元素顺序后移
-

-

- 如果要排降序,只需将内层循环条件改为大于比较即可:key > arr[index]
- 1.时间复杂度O(N^2)
-
- 2.插入排序应用场景:元素集合越接近有序,直接插入排序算法的时间效率越高
- 3.空间复杂度:O(1),它是一种稳定的排序算法
- 4. 稳定性:稳定

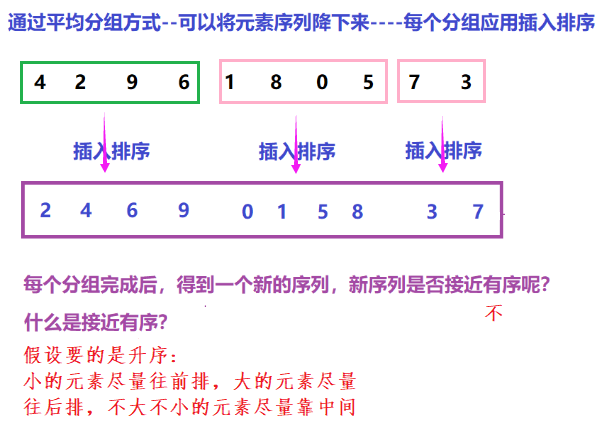
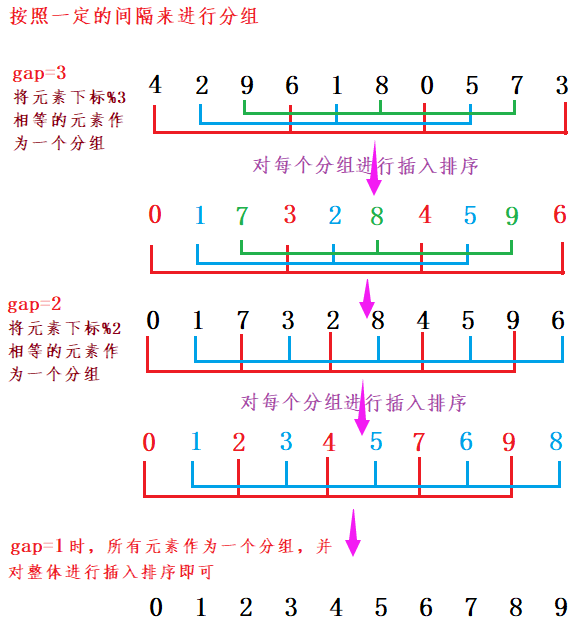
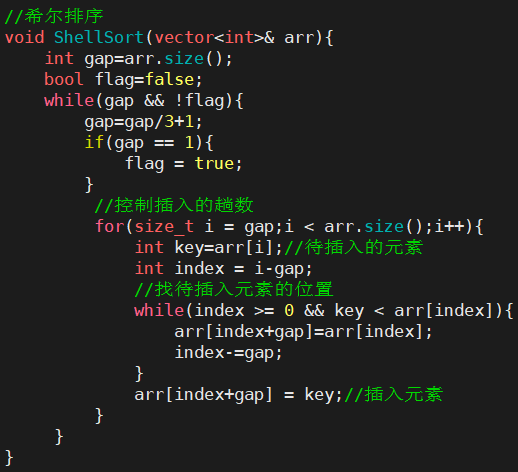
3.希尔排序( 缩小增量排序 )
- 场景:元素序列比较随机(不是接近有序),而且元素数量比较大,要求:按照插入排序方式来排序
-
-
-
- 稳定性:不稳定,只要是隔着区间交换或这插入都不稳定
- 时间复杂度:
- 希尔排序的时间复杂度不好计算,因为gap的取值方法很多,导致很难去计算,因此在好些树中给出的希尔排序的时间复杂度都不固定:
- 《数据结构(C语言版)》--- 严蔚敏
-
- 《数据结构-用面相对象方法与C++描述》--- 殷人昆
-
- 代码实现时,gap是按照Knuth提出的方式取值的,而且Knuth进行了大量的试验统计,时间复杂度按照O(N^1.25) ~O(1.6*N^1.25)来计算
- 空间复杂度:O(1)


4.选择排序
- 基本思想:
- 每一次从待排序的数据元素中选出最小(或最大)的一个元素,存放在序列的起始(或末尾)位置,直到全部待排序的数据元素排完 。
-
4.1直接选择排序:
- 在元素集合array[i]--array[n-1]中选择关键码最大(小)的数据元素
- 若它不是这组元素中的最后一个(第一个)元素,则将它与这组元素中的最后一个(第一个)元素交换
- 在剩余的array[i]--array[n-2](array[i+1]--array[n-1])集合中,重复上述步骤,直到集合剩余1个元素
-
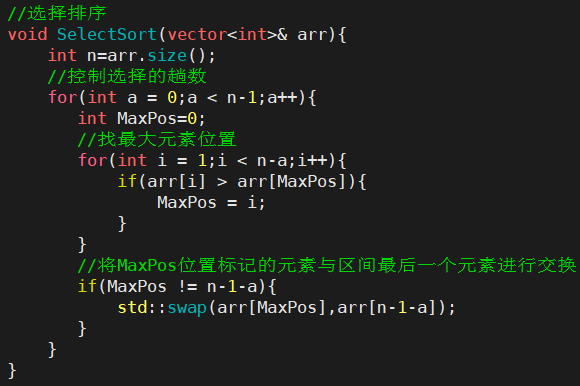
- 1. 直接选择排序思考非常好理解,但是效率不是很好。实际中很少使用
- 2. 时间复杂度:O(N^2)
- 3. 空间复杂度:O(1)
- 4. 稳定性:不稳定
- 直接选择排序优化
- 在一次选择过程中,既然可以找到最大元素的位置,那必然也可以找到最小元素位置
- maxPos标记的最大元素与区间最后一个位置元素进行交换
- minPos标记的最小元素与区间第一个元素进行交换
- 每趟选择就可以将两个元素处理好
-
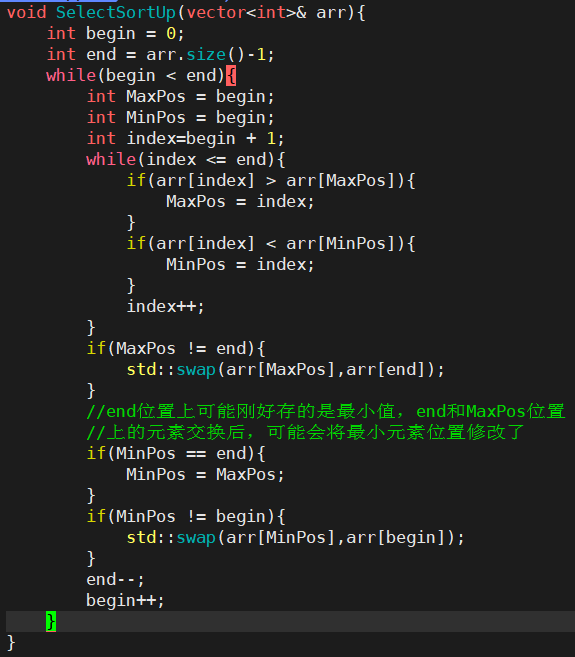
- 缺陷:部分元素可能存在重复比较
-
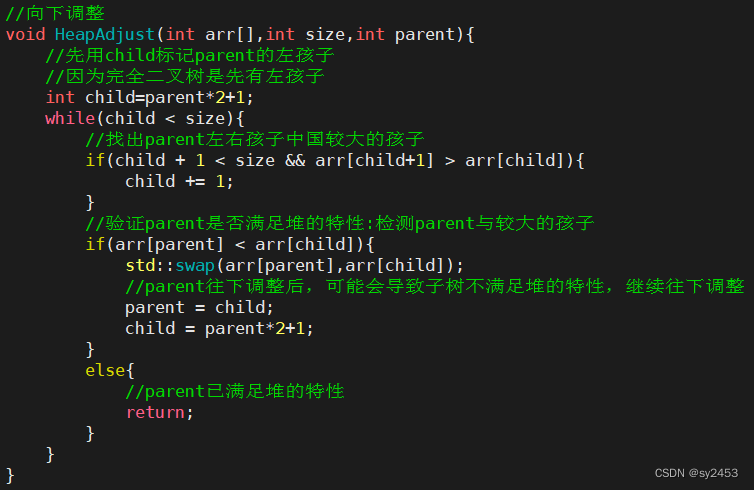
4.2堆排序
- 排升序要建大堆,排降序建小堆。
-
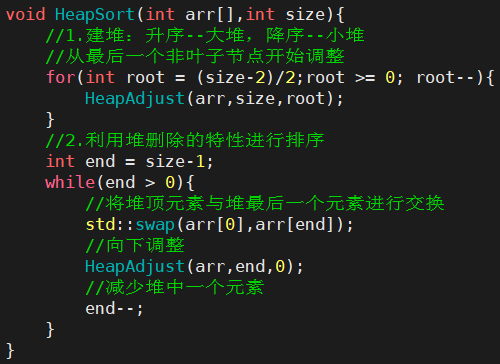
- 1. 堆排序使用堆来选数,效率就高了很多。
- 2. 时间复杂度:O(N*logN)
- 3. 空间复杂度:O(1)
- 4. 稳定性:不稳定
5.交换排序
-
5.1冒泡排序
-
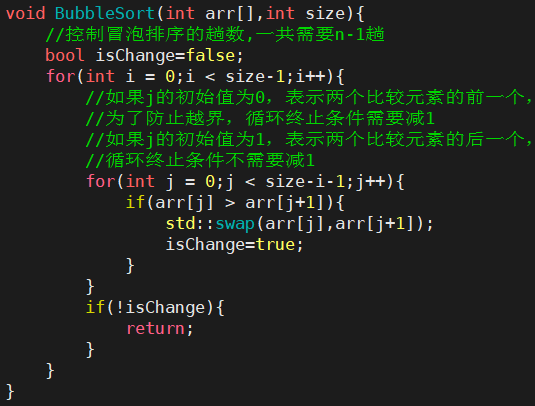
- 1. 冒泡排序是一种非常容易理解的排序
- 2. 时间复杂度:O(N^2)
- 3. 空间复杂度:O(1)
- 4. 稳定性:稳定
-
-
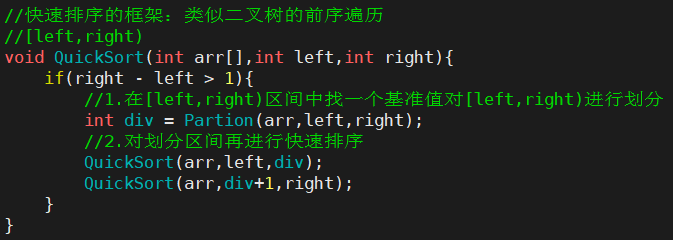
5.2.快速排序
- 快排大的思想:
- 1.从区间中找一个元素作为基准值,然后按照基准值将区间划分成两部分
- 2.递归:使用快排对基准值的左侧进行排序,使用快排对基准值的右侧进行排序
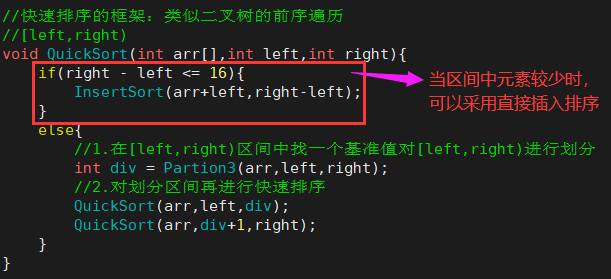
- 快速排序主体框架
-
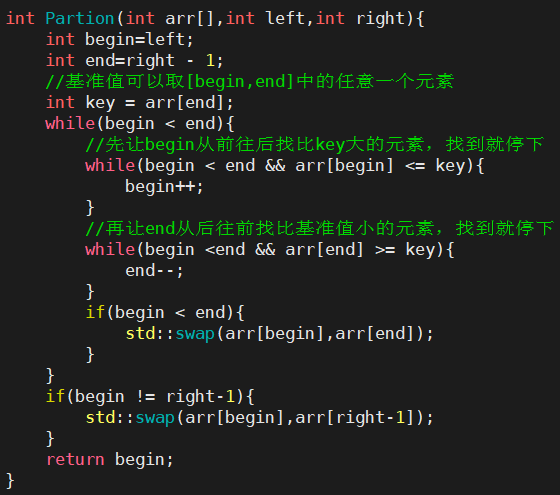
- 划分的方式:
- hoare版本:提出快速排序的大佬
-
- 挖坑法
-
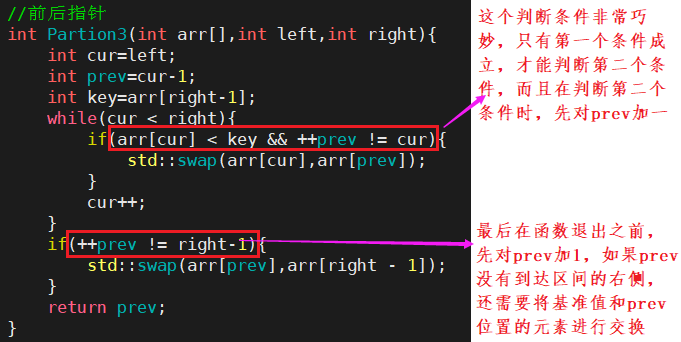
- 前后指针法
-
- hoare版本:提出快速排序的大佬
- 空间复杂度:O(logN)
- 稳定性:不稳定
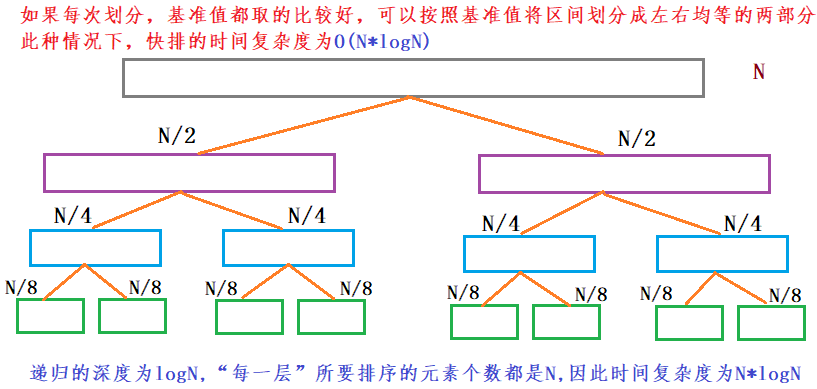
- 快排时间复杂度法分析:
- 基准值取得好,划分区间比较均匀
-
- 最糟糕的情况
-
- 快排不适合排:序列有序或者接近有序----数据越杂乱越好
- 基准值取得好,划分区间比较均匀
- 快排优化:
- 1.基准值选择问题
- 一般情况下不会直接拿区间最左侧或者最右侧的数据作为基准值,因为按照这种方式获取基准值,拿到最大或者最小值的概率可能会非常高,严重影响快排的效率
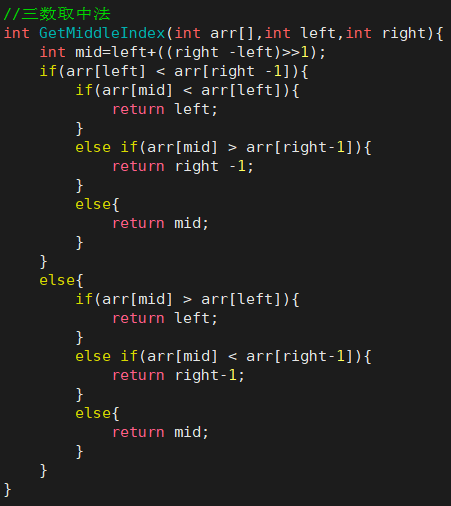
- 三数取中法:最左侧、最中间、最右侧位置的数据,取这三个数据最中间的数据作为基准值
-
- 假设:待排序集合中元素非常多,将来就会导致平衡二叉树的高度非常高---递归的深度:即递归到某个区间中只有一个元素时,递归才会回退
- 存在的问题:
- 1.递归深度达到一定程度---可能会导致栈溢出
- 2.越往下递归,区间中数据越来越少,当区间中元素越来越少时,快排就不是最理想的排序算法了
- 2.递归时区间中元素过少时可以采用插入排序优化
-
- 3.待排序数据如果非常多,递归深度会非常深,在没有达到递归出口时,栈溢出?
- 方式一:
- 1.可以算递归深度----n个元素-->H = log2N,如果超过程序中涉及的递归总次数阈值,采用堆排序方法(时间复杂度相等)
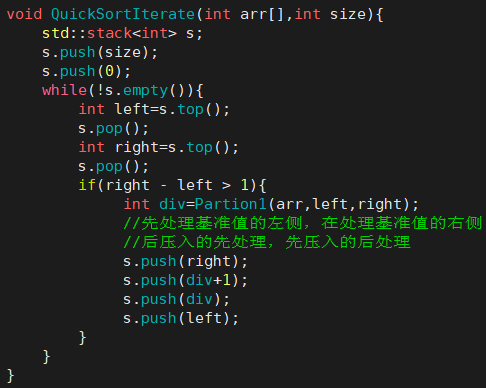
- 2.递归转循环
- 方式1
-
- 方式2:
-
- 方式1
- 方式一:
- 1.基准值选择问题
- 快排大的思想:






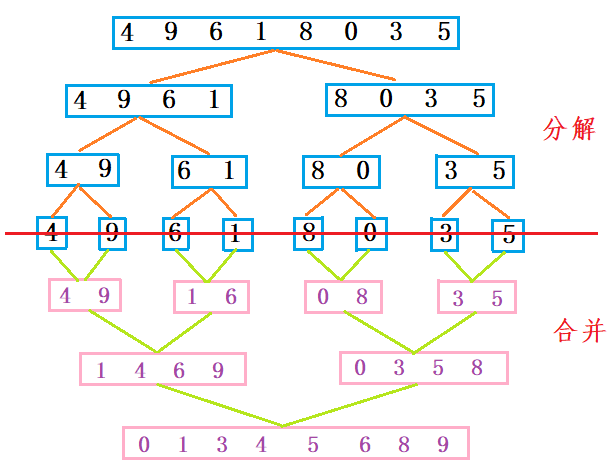
6.归并排序
- 主要步骤:
- 1.划分,对区间进行均分
- 2.递归处理左区间,递归处理右区间
- 3.合并,将两个有序的区间进行合并
-
-

-

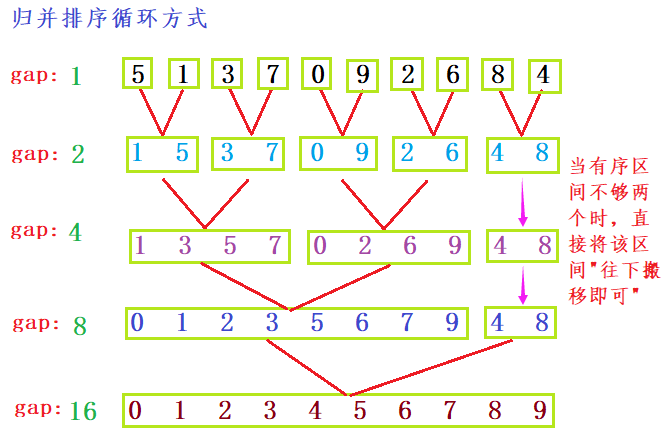
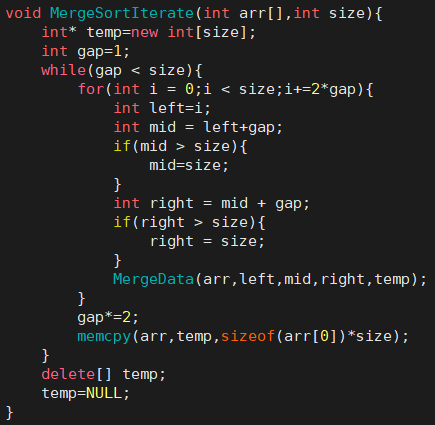
- 归并排序循环方式:
-
- 总结:
- 1. 归并的缺点在于需要O(N)的空间复杂度,归并排序的思考更多的是解决在磁盘中的外排序问题(外部排序)。
- 2. 时间复杂度:O(N*logN)
- 3. 空间复杂度:O(N)
- 4. 稳定性:稳定
- 归并排序应用于海量数据:
- 假设现在有100G的数据,且当前能够的使用的内存只有1G
-
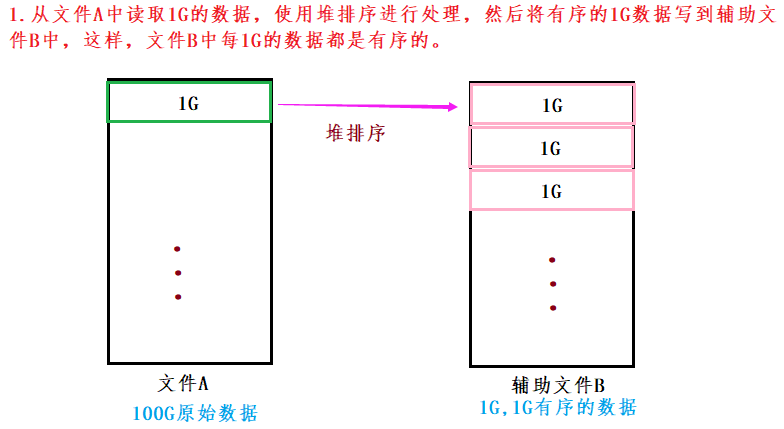
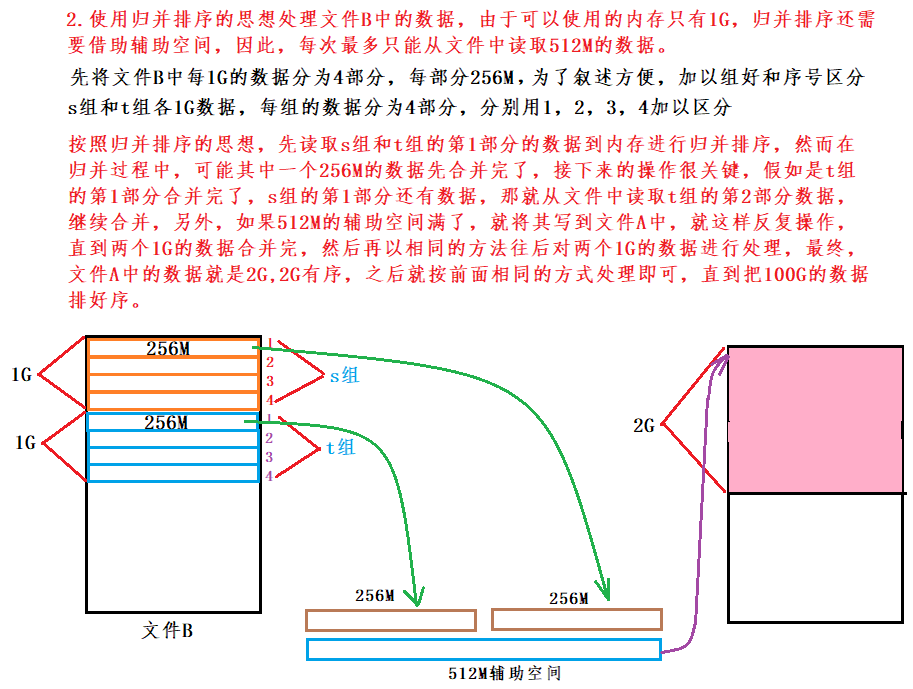
-
7.非比较类排序
- 计数排序
- 应用场景:数据密集集中在某个范围中
- 步骤:
- 1.求范围,找到数据中的最大值和最小值,range=MaxValue - MinValue+1;
- 2.统计区间中每个元素出现的次数
- 3.数据回收:按照计数数组的下标来进行回收
-

- 基数排序:
- LSD:低关键码优先:循环处理,个位--->十位--->百位·····
- 对于每个数据,每一位上的数字都在0~9范围内
- 1.划分:按照对应位上的数字将元素放入到对应的桶中
- 2.回收:按照桶号由小到大的顺序,每个桶中按照先放先回收----回收数据
-
