文章目录
前言介绍
Sequential Graph Convolutional Network for Active Learning
是由Razvan Caramalau1, Binod Bhattarai1and Tae-Kyun Kim1,2发表在CVPR2021上的一篇文章。
文献链接https://arxiv.org/pdf/2006.10219.pdf
代码https://github.com/razvancaramalau/Sequential-GCN-for-Active-Learning
下面就来进行详解这篇文章:用于主动学习的顺序图卷积网络
Abstract
主要贡献:提出了一种在顺序图卷积网络(GCN)上构建的基于池的主动学习框架。
数据池中的每个图像特征表示图中的一个节点,边编码它们的相似性。以少量随机采样的图像作为种子标记样本,通过最小化二进制交叉熵损失来学习图的参数来区分标记节点和未标记节点。

GCN作用:在节点之间执行消息传递操作,因此归纳出强关联节点的相似表示。利用GCN的这些特性来选择与已标注实例有很大差异的未标注实例。
选择标准:利用图的节点嵌入及其置信度,并采用采样技术。如CoreSet和基于不确定性的方法来查询节点。
过程:将新查询节点的标签从未标注改为已标注,重新训练学习器以优化下游任务和图以最小化其修改后的目标。
实验:我们在6个不同的基准上对我们的方法进行了评估:4个真实图像分类,1个基于深度的手势估计和1个合成RGB图像分类数据集。我们的方法超过了Vaal、Learning Lost、CoreSet等几个竞争基准,并在多个应用程序上获得了新的最先进的性能。
Introduction
主动学习可以解决深度学习需要大量标注且标注困难的数据的难题。
任何主动学习框架都有三个不同的组成部分(学习模型、采样器和注释者)
- 学习模型是被训练成最小化目标任务目标的模型。
- 采样器设计用于在固定预算内选择有代表性的未标记示例,以提供最高性能。
- 注释器对查询的数据进行标记,以供学习模型重新培训。
具体过程:总得来说就是输入一部分已标注的数据给系统进行初始化,训练后系统会在未标注数据集中挑选出一部分它自己认为需要标注的数据给我们,我们送给专家进行标注后将这部分标注好的数据加入到我们的已标注数据集中继续训练我们的模型,如此反复迭代到模型性能逐步提升。
基于模型与样本的关系可知,AL框架可以分为两大类:任务相关和任务无关
任务相关:那些采样器是专门为学习者的特定任务设计的,采样函数取决于学习者的目标。
缺点:限制了模型对于特定类型的任务而言是最优的,同时还存在可伸缩性问题
任务无关:基于模型
1、Vaal:训练变分自动编码器(VAE),它学习潜在空间,以便以对抗的方式更好地区分标记图像和未标记图像。
2、Learning loss:引入了一个单独的损失预测模块,与学习模型一起进行训练。
缺点:缺乏利用标记图像和未标记图像之间的相关性的机制;Vaal无法在学习者和采样者之间进行交流。
Motivation:提出图卷积网络(GCNS)能够通过消息传递操作在节点之间共享信息
Framework
我们以任务无关的方式提出了一个有序的主动学习GCN。

任务1:训练学习者最小化【Phase I 】
Phase I :训练学习者最小化来自可用注释的下游任务的目标,给模型用少量的标注数据进行训练,这里做的是提取标记和未标注数据集的特征。
任务2:采用基于池的场景进行主动学习,挑选时从“池”【未标注数据集】里选一批数据[Phase II 、Phase III 、 Phase IV]
Phase II:进行标注构建一个图,其中从学习者提取的图像表示作为顶点,它们的相似性作为边
Phase III:应用GCN层最小化标记和未标记之间的二进制交叉熵,也就是让损失函数最小化。
Phase IV:应用不确定性采样选择未标记的示例来查询它们的标签
任务3:选择未标记数据给专家进行标注【Phase V】
Phase V:注释选择,填充标记示例的数量并重复该循环。
在初始阶段,学习模型用少量种子标记的例子进行训练。我们从学习参数中提取标记和未标记图像的特征。在第二阶段,我们构建一个图,其中特征用于初始化图的节点,相似性表示边。该图通过GCN层(第三阶段),并且学习该图的参数以识别标记与未标记示例的节点。
我们根据置信度得分,应用不确定性抽样方法(第四阶段),并发送所选示例以查询其标签(第五阶段),我们称这种取样方法为不确定性。如图1所示,从第一阶段穿越到第五阶段完成了一个周期。在下一个迭代中,我们将注释示例的标签从未标记翻转到标记,并重新训练整个框架。
Related Works
基于模型的方法
训练来自学习模型的单独模型来选择最具代表性的数据的子集。
Learning loss :附加了一个损失学习模块,这样就可以离线预测未标记样本的损失
Vaal:部署了一个变分自动编码器(VAE)来将可用数据映射到一个潜在空间。鉴别器以对抗的方式被训练来将标记的与未标记的进行分类。
GCN 优势:通过在GCN的消息传递操作共享信息来利用示例之间的相对关系
在主动学习的GCNs
GCNs [18]开启了新的主动学习方法,与这些方法相比,我们的方法区分了学习者和样本。它使我们的方法与任务无关,并且也受益于前面提到的基于模型的方法。
吴月新[38]提出了用于标记和未标记节点之间的特征传播的K-medods聚类
Roy Abel[1]将PageRank [27]算法推广到主动学习问题,提出了一种区域不确定性算法
Hongyun Cai[6]将节点不确定性与图中心组合以选择新样本
然而,这些方法都没有以顺序训练,而且它们的选择机制是基于一个图学习者的假设。这并不能使它们直接与我们的提出来的相比较,在我们的建议中,GCN是针对与学习者不同的目标函数单独训练的。
基于不确定性的方法
在[9]中引入的贝叶斯近似通过蒙特卡罗脱离(MC脱离)适配架构的变分推断产生有意义的不确定性测量。
基于几何的方法
CoreSet:关键原则取决于通过几何定义的界限,最小化标记集和小的未标记子集之间的损失差异(ΔLoss最小)
GCN优点:我们在实验中表示了这个基线,因为它成功地超过了基于不确定性的基线。
Method
在本节中,我们将详细描述所提出的方法。
1、我们简要介绍了基于池的主动学习场景下的图像分类和回归任务的学习模型。
2、我们讨论了我们的两种新的采样方法:UncertainGCN和CoreGCN
UncertainGCN:基于标准AL方法的不确定抽样,跟踪设计的图节点的置信度得分。
CoreGCN:此外,CoreGCN 改编了非常成功的 CoreSet ,[31]通过顺序训练的 GCN 诱导图嵌入网络。
学习模型
在图1中,I阶段我描绘了学习者。其目标是最大限度地减少下游任务的目标。我们考虑了分类和回归任务。这个学习模型的目标随着我们正在处理的任务的性质而异
分类
对于分类任务,学习模型是CNN图像分类器
我们分类器的目标函数是同学定义如下:
L M c ( x , y ; θ ) = − 1 N l ∑ i = 1 N l y i log ( f ( x i , y i ; θ ) ) \mathcal{L}_{\mathcal{M}}^{c}(\mathbf{x}, \mathbf{y} ; \theta)=-\frac{1}{N_{l}} \sum_{i=1}^{N_{l}} \mathbf{y}_{i} \log \left(f\left(\mathbf{x}_{i}, \mathbf{y}_{i} ; \theta\right)\right) LMc(x,y;θ)=−Nl1i=1∑Nlyilog(f(xi,yi;θ))其中Nl是标记的训练例子的数量和f(xi,yi;θ)为模型M的后验概率;
回归
J是构造手姿势的关节的数量,
L M r ( x , y ; θ ) = 1 N l ∑ i = 1 N l ( 1 J ∑ j = 1 J ∥ y i , j − f ( x i , j , y i , j ; θ ) ∥ 2 ) \mathcal{L}_{\mathcal{M}}^{r}(\mathbf{x}, \mathbf{y} ; \theta)=\frac{1}{N_{l}} \sum_{i=1}^{N_{l}}\left(\frac{1}{J} \sum_{j=1}^{J}\left\|\mathbf{y}_{i, j}-f\left(\mathbf{x}_{i, j}, \mathbf{y}_{i, j} ; \theta\right)\right\|^{2}\right) LMr(x,y;θ)=Nl1i=1∑Nl(J1j=1∑J∥yi,j−f(xi,j,yi,j;θ)∥2)
要使方法适应任何其他类型的任务,只需要修改学习模型的目标函数
采样器
我们采用基于池的方案进行主动学习,主要的目标是优化采样器的数据采集方法,有序以最少的批数达到最小的损失Dn。
min n min L M A ( L M ( x , y ; θ ) ∣ D 0 ⊂ ⋯ ⊂ D n ⊂ D U ) \min _{n} \min _{\mathcal{L}_{\mathcal{M}}} \mathcal{A}\left(\mathcal{L}_{\mathcal{M}}(\mathbf{x}, \mathbf{y} ; \theta) \mid \mathbf{D}_{0} \subset \cdots \subset \mathbf{D}_{n} \subset \mathbf{D}_{U}\right) nminLMminA(LM(x,y;θ)∣D0⊂⋯⊂Dn⊂DU)
我们的目标是最小化阶段的数量,以便更少的样本(x,y)需要注释。
顺序GCN选择过程
在采样期间,如图1所示,从II期到IV,我们的贡献依赖于顺序训练GCN
在每个主动学习阶段用从学习者提取的用于标记和未标记图像的特征进行初始化。如前所述,类似于VAAL[33],我们认为这种方法是基于模型的,需要单独的体系结构进行采样。
我们引入图的动机主要是在样本(节点)之间的学习器特征空间上传播继承的不确定性。因此,在对图应用卷积之后,节点之间的消息传递导致节点的更高阶表示,最后,我们的GCN将作为一个二进制分类器来决定对哪些图像进行标注。
Phase II
进行标注构建一个图,其中从学习者提取的图像表示作为顶点,它们的相似性作为边

Graph Convolutional Network:边缘捕获节点之间的关系并以邻接矩阵A编码;图形的节点V∈R(m×n)编码图像特定信息,并用从学习者提取的功能进行初始化【n表示标记和未标记示例的总数,而m表示每个节点的特征的维度】
v ∈ R ( m × n ) \mathbf{v} \in \mathbb{R}^{(m \times n)} v∈R(m×n) ( S i j = v i ⊤ v j , { i , j } ∈ N ) \left(S_{i j}=\mathbf{v}_{i}^{\top} \mathbf{v}_{j},\{i, j\} \in N\right) (Sij=vi⊤vj,{
i,j}∈N)
我们从S中减去单位矩阵I,然后通过乘以它的度数d来归一化,我们将自连接添加回来,这样最紧密的关联就是节点本身。
A = D − 1 ( S − I ) + I A=D^{-1}(S-I)+I A=D−1(S−I)+I
Phase III
应用GCN层最小化标记和未标记之间的二进制交叉熵,也就是让损失函数最小化。
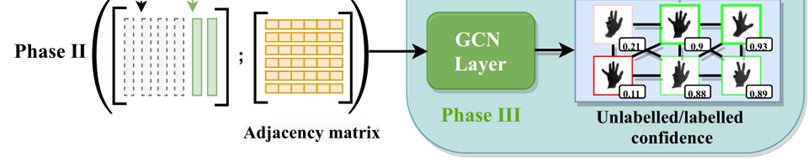
为了避免GCN[18]中的特征过度平滑,我们采用了两层体系结构。
第一GCN层可以描述为函数: f G 1 ( A , V ; Θ 1 ) : R N × N × R m × N → f_{\mathcal{G}}^{1}\left(A, \mathcal{V} ; \Theta_{1}\right): \mathbb{R}^{N \times N} \times \mathbb{R}^{m \times N} \rightarrow fG1(A,V;Θ1):RN×N×Rm×N→ R h × N \mathbb{R}^{h \times N} Rh×N
其中h是隐藏单元的数量,θ1是参数,在第一层之后施加整流的线性单元激活[24]以最大化特征贡献,然而,为了将节点映射为标记的或未标记的,通过sigmoid函数激活最终层。
最后输出:fG的输出是一个长度为N的向量,值在0和1之间(其中0被认为是未标记的,1是标记的)。
可以进一步将整个网络功能定义为: f G = σ ( Θ 2 ( ReLU ( Θ 1 A ) A ) f_{\mathcal{G}}=\sigma\left(\Theta_{2}\left(\operatorname{ReLU}\left(\Theta_{1} A\right) A\right)\right. fG=σ(Θ2(ReLU(Θ1A)A)
我们的损失函数将被定义为: L G ( V , A ; Θ 1 , Θ 2 ) = − 1 N l ∑ i = 1 N l log ( f G ( V , A ; Θ 1 , Θ 2 ) i ) − λ N − N l ∑ i = N l + 1 N log ( 1 − f G ( V , A ; Θ 1 , Θ 2 ) i ) \begin{array}{r} \mathcal{L}_{\mathcal{G}}\left(\mathcal{V}, A ; \Theta_{1}, \Theta_{2}\right)=-\frac{1}{N_{l}} \sum_{i=1}^{N_{l}} \log \left(f_{\mathcal{G}}\left(\mathcal{V}, A ; \Theta_{1}, \Theta_{2}\right)_{i}\right) -\frac{\lambda}{N-N_{l}} \sum_{i=N_{l}+1}^{N} \log \left(1-f_{\mathcal{G}}\left(\mathcal{V}, A ; \Theta_{1}, \Theta_{2}\right)_{i}\right) \end{array} LG(V,A;Θ1,Θ2)=−Nl1∑i=1Nllog(fG(V,A;Θ1,Θ2)i)−N−Nlλ∑i=Nl+1Nlog(1−fG(V,A;Θ1,Θ2)i)
其中λ作为标记和未标记交叉熵之间的加权因子。
Phase IV
应用不确定性采样选择未标记的示例来查询它们的标签
UncertainGCN:GCN上的不确定性抽样
一旦GCN的训练结束,我们就开始选拔。从剩余的未标记样本DU中,我们可以得出它们的置信度得分fG(VI;Du)作为GCN的输出。
D L = D L ∪ arg max i − 1 … h ∣ s margin − f G ( v i ; D U ) ∣ \mathbf{D}_{L}=\mathbf{D}_{L} \cup \underset{i-1 \ldots h}{\arg \max }\left|s_{\text {margin }}-f_{\mathcal{G}}\left(\mathbf{v}_{i} ; \mathbf{D}_{U}\right)\right| DL=DL∪i−1…hargmax∣smargin −fG(vi;DU)∣
为了选择最不确定的未标记样本,Smargin应更接近0
模拟采样器进行采样:

每个节点由从学习者中提取的特征初始化,并且边缘捕获它们的关系。每个同心圆表示一组强连接的节点,在图中,具有相似性的一组图像处于同心圆中,在第一选择阶段,将两个标记样本作为种子标记样本,在已标记数据同心圆以外的另一个非分布的同心圆中选择样本,而不是从最里面的圆中选择需要标注的样本。类似地,在第二阶段,我们的采样器选择位于另一个外同心圆中的图像,这与之前选择的图像完全不同,类似地,在第二阶段,我们的采样器选择位于另一个外同心圆中的图像,这与之前选择的图像完全不同。
下面算法1用不确定性GCN抽样方法总结了GCN顺序训练
算法1 不确定GCN主动学习算法
1:参数定义(D0:初始标记集合,Du:未标记的集合 ,b:选择样本数量)
2: (xL,yL)标记图像和label ; (xU)未标记图像
3:重复下面操作
4:通过标记图像训练模型
5:提取标记和未标记图像的特征
6:计算得到邻接矩阵A
7: 通过特征和邻接矩阵A来训练GCN,得到theta参数
8:通过置信度得分,从未标记的样本中选择置信度得分小的样本,作为添加节点。
11:通过专家标注得到标签

CoreGCN:GCN上的Coreset采样,为了在标记和未标记的图形表示之间集成几何信息,我们在我们的采样阶段接近Coreset技术,与基于不确定性的方法相比,这表明了更好的性能,显示了界定未标记的样品的损失与标记之一的差异类似于[37]中所述的K中心最小化问题。
采样基于从训练分类器中提取的特征之间的L2距离,取而代之的是,我们将通过在图的第一层之后表示的特征上应用CoreSet方法来利用我们的GCN架构。
D L = D L arg max i ∈ D U min j ∈ D L δ ( f G 1 ( A , v i ; Θ 1 ) , f G 1 ( A , v j ; Θ 1 ) ) , \mathbf{D}_{L}=\mathbf{D}_{L} \underset{i \in \mathbf{D}_{U}}{\arg \max } \min _{j \in \mathbf{D}_{L}} \delta\left(f_{\mathcal{G}}^{1}\left(A, \mathbf{v}_{i} ; \Theta_{1}\right), f_{\mathcal{G}}^{1}\left(A, \mathbf{v}_{j} ; \Theta_{1}\right)\right), DL=DLi∈DUargmaxj∈DLminδ(fG1(A,vi;Θ1),fG1(A,vj;Θ1)),
其中δ是标记节点vi的图形特征和来自未标记节点vj的图形特征之间的欧几里德距离
Experiments
主要是对用于分类的子采样RGB和灰度真实图像、用于回归的深度真实图像和用于分类任务的合成生成的RGB进行了实验。

分类
数据集和实验设置:四个具有挑战性的图像分类基准上评估了所提出的人工智能方法。
数据集:三个RGB图像数据集【CIFAR-10、CIFAR-100和SVHN】和灰度数据集【fashimnist】
实验设置:CIFAR 10 、SVHN 和FashionMNIST ,标记为示例的种子大小为1000;CIFAR 100 ,我们选择2,000 是因为它们的类数量相对较多(100对10)
实施细节:ResNet-18 [15]是学习模型最喜欢的选择,因为它具有相对较高的准确性和更好的训练稳定性。batchsize = 128 ;使用随机梯度下降(SGD)
采样器:dropout = 0.3 ;Adam优化器;learning rate = 0.001,Smargin = 0.1
比较方法和评估度量:Vaal 和Learning loss 两个最先进的基线,Temprop【基于GCN的框架的代表性基准】
对于定量评估,我们在测试集上报告了5个试验的平均平均准确性。

我们使用每个数据集上所有可用的训练示例分别训练ResNet 18 ,并在测试集上报告性能。我们的实现在CIFAR 10 上获得93.09%,在CIFAR 100 上获得73.02%,在FashionMNIST 上获得93.74%,在SVHN 上获得95.35%
定性比较
为了进一步分析我们方法的采样行为,我们与现有方法进行定性比较
我们对CiFar-10进行了这种比较。对于这两个算法,我们在第一和第四选择阶段生成来自学习者的标记和未标记的提取特征的TSNE 曲线。
第一采样阶段,所选择的样品分布是均匀的,这对于两种技术类似

用少量种子注释的示例训练的学习者是次优的,因此标记和未标记的特征不是足够的差异。这使得两种方法的采样行为在随机附近。

在第四选择阶段,学习模型变得相对较为辨别,这可以从代表每类CiFar-10的集群中注意到。现在,这些功能是强大的,可以捕获我们在邻接矩阵中编码的标记和未标记的示例之间的关系。
回归
数据集和实验设置:采用深度图像的3D手姿势估计数据集
训练集16,004个手深图像 ,测试集1,600个手深图像
标记数:10%=1600
DeepPrior 学习模型,batchsize = 128 ,Learning rate = 0.001
比较方法和评估度量:一个是随机采样,另一个是Coreset
平均5种不同试验和标准偏差方面的平均方形误差方面报告了表现
定量评估:从第二个选择阶段开始,我们的采样方法CoreGCN和UncertainGCN的性能始终优于CoreSet和Random采样,从第二个选择阶段到第五个选择阶段,我们的方法的误差下降斜率急剧下降。当我们的预算非常有限时,这使我们比其他方法更有优势。选择阶段结束时,CoreGCN给出的误差最小,为12.3 mm

Experiments(补充)
在实验部分,我们对四个图像分类数据集上的主动学习方法进行了系统的定量评估。
尽管在选择之前,我们将未标记的样本随机分成一个子集,但数据集对于每个类别分布来说仍然相对平衡,然而,在没有与数据空间相关的先验信息的情况下,这种情况并不常见。因此,我们在定量实验中模拟一个不平衡的CIFAR-10。

我们提出的方法,不确定核心网和11核心网,再次突出了其他基于模型的选择,如AAL和学习损失。在10,000个标记样本中,不确定性评分比平均准确率为80.05%的方法高2%。同时,CoreGCN与CoreSet一起实现了84.5%的顶级性能。因此,几何信息在数据集不平衡的情况下更有用。

Conclusions
我们提出了一种新的方法,在图像分类和回归使用图形卷积网络主动学习。经过系统和全面的实验,我们采用的采样技术,不确定采样和核心采样,在6个基准上产生了最先进的结果。我们通过定性分布表明,我们的选择函数最大化了数据空间中的信息量。