- 文件的使用
文件时存储辅助存储器上的一组数据序列,可以包含任何数据内容。概念上,文件时数据的集合和抽象。文件包括文本文件和二进制文件两类。
文本文件一般由单一特定编码的字符组成,如UTF-8编码,内容容易同意展示和阅读,大部分文本文件都可以通过文本编辑处理软件创建、修改和阅读。由于文本文件存在编码,所以它也可以被看作是存储在磁盘上的字符串,如一个txt格式的文本文件。
二进制文件直接由01序列组成,没有同意的字符编码,文件内部数据的组织格式与文件用途有关。二进制是信息按照非字符但有特定格式形成的文件,如png格式的图片文件、avi格式的视频文件。二进制文件和文本文件最主要的区别在于是否有统一的字符编码。二进制文件由于没有统一的字符编码,只能当作字节流,而不能看作是字符串。
无论文件创建为文本文件或者二进制文件,都可以用文本文件方式和二进制文件方式打开,但打开后的操作不同。
Pyton对文本文件和二进制文件采用统一的操作步骤,即“打开一操作一关闭”。操作系统巾的文件默认处于存储状态,首先需要将其打,使得当前程序有权操作这个文件,打开不存在的文系统可以创建这个文件。打开后的文件处于占用状态,此时,另一个进程不能操这个文件。可以通过一红方读文件的内容或向文件与入内容,操作之后需要将文件关闭,关闭将释放对文件的控制使文复存储状态,此时,另一个进程将能够操作这个文件。

Python通过open()函数打开一个文件,并返回一个操作这个文件的变量,语法形式如下:
<变量名> = open(<文件路径及文件名>,<打开模式>)
open()函数有两个参数:文件名和打开模式。文件名可以是文件的实际名字,也可以是包含完整路径的名字。打开模式用于控制使用何种当时打开文件,open()函数提供7中基本的打开模式,如下表:
| 打开模式 |
含义 |
| ‘r’ |
只读模式,如果文件不存在,返回异常FileNotFoundError,默认值 |
| ‘w’ |
覆盖写模式,文件不存在则创建新文件 |
| ‘x’ |
创建写模式,文件不存在则创建,存在则返回异常FileExistsError |
| ‘a’ |
追加写模式,文件不存在则创建,存在则在源文件末尾最后追加内容 |
| ‘b’ |
二进制文件模式 |
| ‘t’ |
文本文件模式,默认值 |
| ‘+’ |
于r/w/x/a一同使用,在原功能基础上增加同时读写功能 |
打开模式使用字符串方式表示,根据字符串定义,单引号或者双引号均可。打开模式中,’r’、’w’、‘x’、‘a’可以和‘b’、‘t’、‘+’组合使用,形成既表达读写又表达文件模式的方式。
打开了文件之后,便是要对文件进行基础的读写操作。根据打开方式不同,文件读写也会根据文本文件和二进制打开方式有所不同。下表为常用文件读取方法:
| 方法 |
含义 |
| f.read(size=-1) |
从文件中读取整个文件的内容。参数可选,如果给出,则读入前size长度的字符串或字节流 |
| f.readline(size=-1) |
从文件中读入一行内容。参数可选,如果给出,读入改行前size长度的字符串或字节流 |
| f.readlines(hint=-1) |
从文件中读入所有行,以每行为元素形成一个列表。参数可选,如果给出,读入hint行 |
| f.seek(offset) |
改变当前文件操作指针的文职,offset的值:0问文件开头,2为文件结尾。 |
如果文件以文本文件方式打开,则读入字符串;如果文件以二进制方式打开,则读入字节流。我们以包含完整路径的文件名为“C:\\Users\\Durova\\Desktop\\demo.txt”,内容如图所示的文本文件来演示文件的打开和读取:
Path = "C:\\Users\\Durova\\Desktop\\demo.txt"#文件名和地址
f = open(Path,"rt",encoding = "UTF-8")#设置打开模式为只读文本文件模式
ls = f.read()#一次性全部读取
print(ls)
ls = f.readline()#此时文件指针已在末尾,读取为空
print(ls)#无输出
f.seek(0)#指针重回带开头
ls = f.readline()#读取一行,此时为第一行
print(ls)
f.seek(0)
ls = f.readlines()#读取所有行,返回一个行为元素的列表
print(ls)
f.close()#关闭程序的文件的控制,文件回到存储的状态
#输出结果如下:
我真TMD帅!
你说是吧?
我真TMD帅!
['我真TMD帅!\n', '你说是吧?']值得注意,当文件关闭后,再对文件进行读写将产生I/O操作错误。
从文本文件中逐行读入内容并进行处理是一个基本的文件操作需求。文本文件可以看作是由行组成的组合类型,因此可以使用遍历循环逐行便利文件,以上例文件为例演示如下:
Path = "C:\\Users\\Durova\\Desktop\\demo.txt"#文件名和地址
f = open(Path,"rt",encoding = "UTF-8")#设置打开模式为只读文本文件模式
for line in f:
print(line)
f.close()
#输出结果为:
我真TMD帅!
你说是吧?注意,上例中明显表现出一个问题,即“我真TMD帅!”与“你说是吧?”两行之间多了一个换行符。这是因为在读取第一行时,本就包含一个换行符,而使用print()函数自身也会带有一个换行符。可以使用strip()方法去掉。
下表给出一些常用的文件写入方法:
| 方法 |
含义 |
| f.write(s) |
向文件写入一个字符串或字节流 |
| f.writelines(lines) |
将一个元素为字符串的列表整体写入文件 |
代码演示如下:
Path = "C:\\Users\\Durova\\Desktop\\demo.txt"#文件名和地址
f = open(Path,"+at",encoding = "UTF-8")#设置打开模式为同时读写、追加写、文本文件模式
a = "看来是没人反驳啦\n"
b = ["我这举手投足之间\n","都尽显风流潇洒\n","无奈!优雅就是我摆脱不掉的宿命\n"]
f.write(a)
f.writelines(b)
f.seek(0)
for line in f:
print(line)
f.close()#用完就关掉,养成好习惯
#输出结果为:
我真TMD帅!
你说是吧?
看来是没人反驳啦
我这举手投足之间
都尽显风流潇洒
无奈!优雅就是我摆脱不掉的宿命
原文件的内容变为:

- 数据组织的维度
一组数据在被计算机处理前需要进行一定的组织,表明数据之间的基本关系和逻辑,进而形成“数据的维度”。根据数据的关系不同,数据组织可以分为:一维数据、二维数据和高维数据。
一维数据由对等关系的有序或无序数据构成,采用线性房室组织,对应于数学中数组的概念。一维数据十分常见,任何表现为序列或集合的内容都可以看做是一维数据。
二维数据也成为表格数据,由关联关系数据构成,采用二维表格方式组织,对应于数学中的矩阵,常见的表格都属于二维数据。
高维数据由键值对类型的数据构成,采用对象方式组织,可以多层嵌套。高维数据在Web系统中十分常用,作为当今Internet组织内容的主要方式,高维数据衍生出HTML、XML、JSON等具体数据组织的语法结构。计算机二级对此不做要求,因此简单介绍。
- 一维数据的处理
一维数据是最简单的数据组织类型,由于是线性结构,在Python语言中主要采用列表形式表示。一维数据的文件存储有多种方式,总体思路是采用特殊字符分隔各数据。常用存储方法包括四种:采用空格分隔元素、采用逗号分隔元素、采用换行符分隔元素、采用其他特殊符号分隔元素。
在四种方法中,逗号分隔的存储格式叫做SCV格式(Comma-Separated Values,即逗号分隔值),它是一种通用的、相对简单的文件格式,在商业和科学上广泛应用,大部分编辑器都支持直接读入或保存文件为CSV格式,存储的文件一般采用.csv为拓展名。
一维数据保存成CSV个时候,个元素采用逗号分隔,形成一行,这里的逗号是英文逗号。从Python表示到数据存储需要将列表对象输出为CSV格式以及将CSV格式读入成列表对象。
列表对象输出为CSV格式的文件方法如下,采用字符串的join()方法非常方便:
f = open("C:/Users/Durova/Desktop/demo.csv","w")
ls = ["小米","华为","OV"]
f.write(','.join(ls)+'\n')
f.close()程序执行后,生成的demo.csv文件内容如下:

对一维数据进行处理需要从CSV格式文件读入一维数据,并将其表示为列表对象。
需要注意,从CSV文件或的内容时,最后一个元素后面包含一个换行符。对于数据的表达和使用来说,这个换行符时多余的,需要采用字符串的strip()方法去掉数据尾部的换行符,进一步使用split()方法以逗号进行分隔。
演示如下:
f = open("C:/Users/Durova/Desktop/demo.csv","r")
ls = f.read().strip('\n').split(',')
f.close()
print(ls)
#输出结果为:
['小米', '华为', 'OV']将一维数据映射为序列对象后,就可以按照处理序列的方法处理数据。
- 二维数据的处理
二维数据由多个一维数据构成,可以看作时一维数据的组合形式。因此,二维数据可以采用二位列表来表示,即列表的每个元素对应二维数据的一行,这个元素本身也是列表类型,其内部各素对应这行中的各列值。
二维数据一般采用相同的数据类型存储数据,便于操作。
二维数据由许多一维数据构成,同样使用CSV格式的文件存储。CSV文件的每一行就是一维数据,整个CSV文件是一个二维数据。
二维数据存储为CSV格式,需要将二位列表对象写入CSV格式文件以及将CSV格式读入成二位列表对象。
演示如下:
f = open("C:/Users/Durova/Desktop/demo.csv","w")
#ls是一个二维列表
ls = [
['1','2','3','4'],
['5','6','7','8'],
['9','10','11','12']
]
for row in ls:
f.write(",".join(row)+"\n")#注意写入只能写入字符串
f.close()生成的程序内容为:
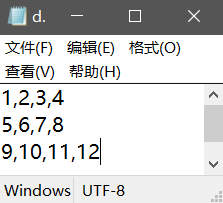
对二维数据进行处理首先需要从CSV格式文件读入二维数据,并将其表示为二位列表对象,演示如下:
f = open("C:/Users/Durova/Desktop/demo.csv","r")
ls = []#建立空列表装数据
for line in f:
ls.append(line.strip('\n').split(','))
f.close()
print(ls)
#输出结果为:
[['1', '2', '3', '4'], ['5', '6', '7', '8'], ['9', '10', '11', '12']]二维数组处理等同于二位列表的操作。与以为列表不同,二位列表一般需要借助循环遍历实现对每个数据的处理,基本代码格式如下:
for row in ls:
for item in row:
<对第row行第item列元素进行处理>