文章目录
Convolutional Neural Network (CNN)
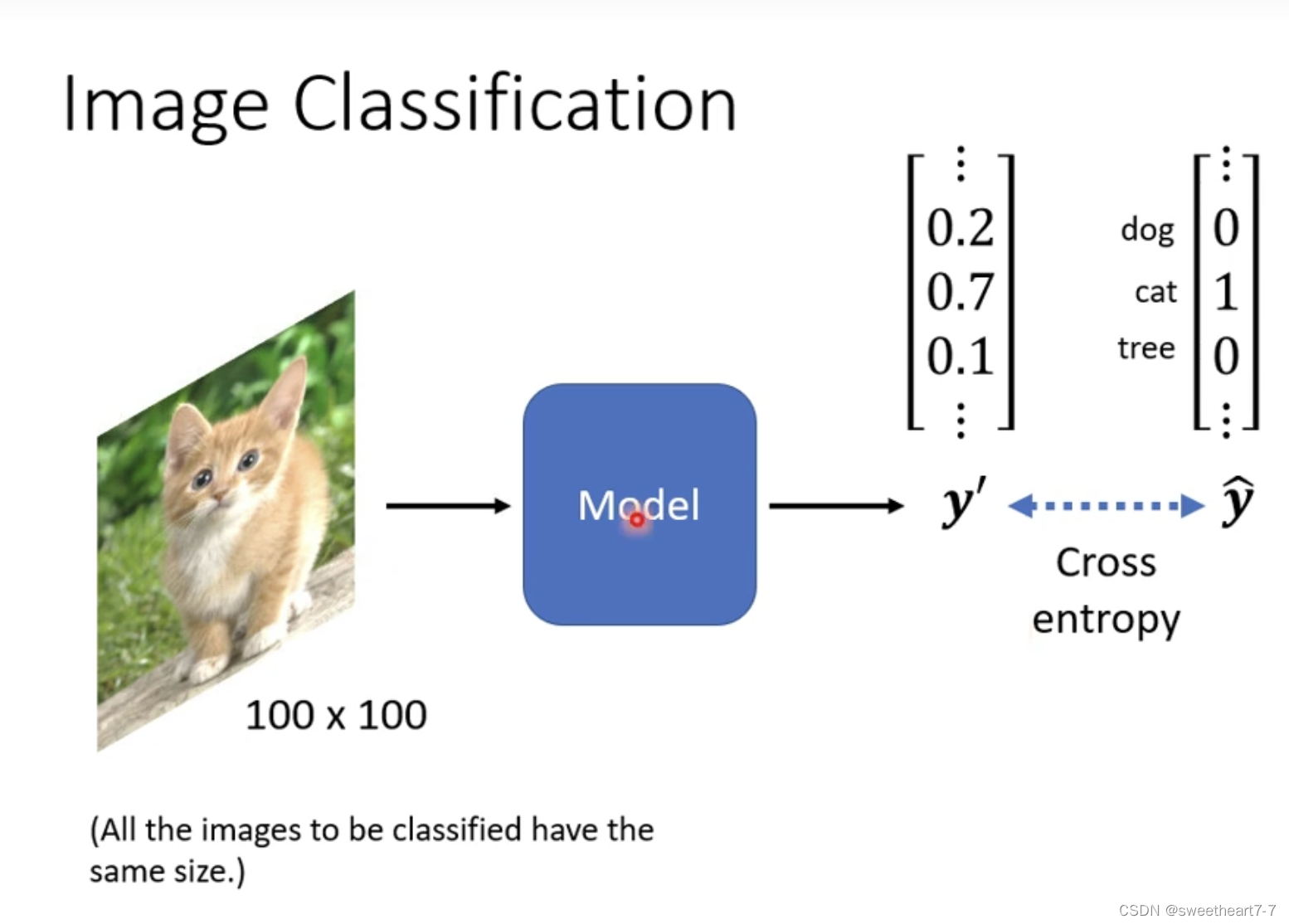
Image Classification
这类问题需要将图像的输入大小一致化
Tensor:超过二维的矩阵
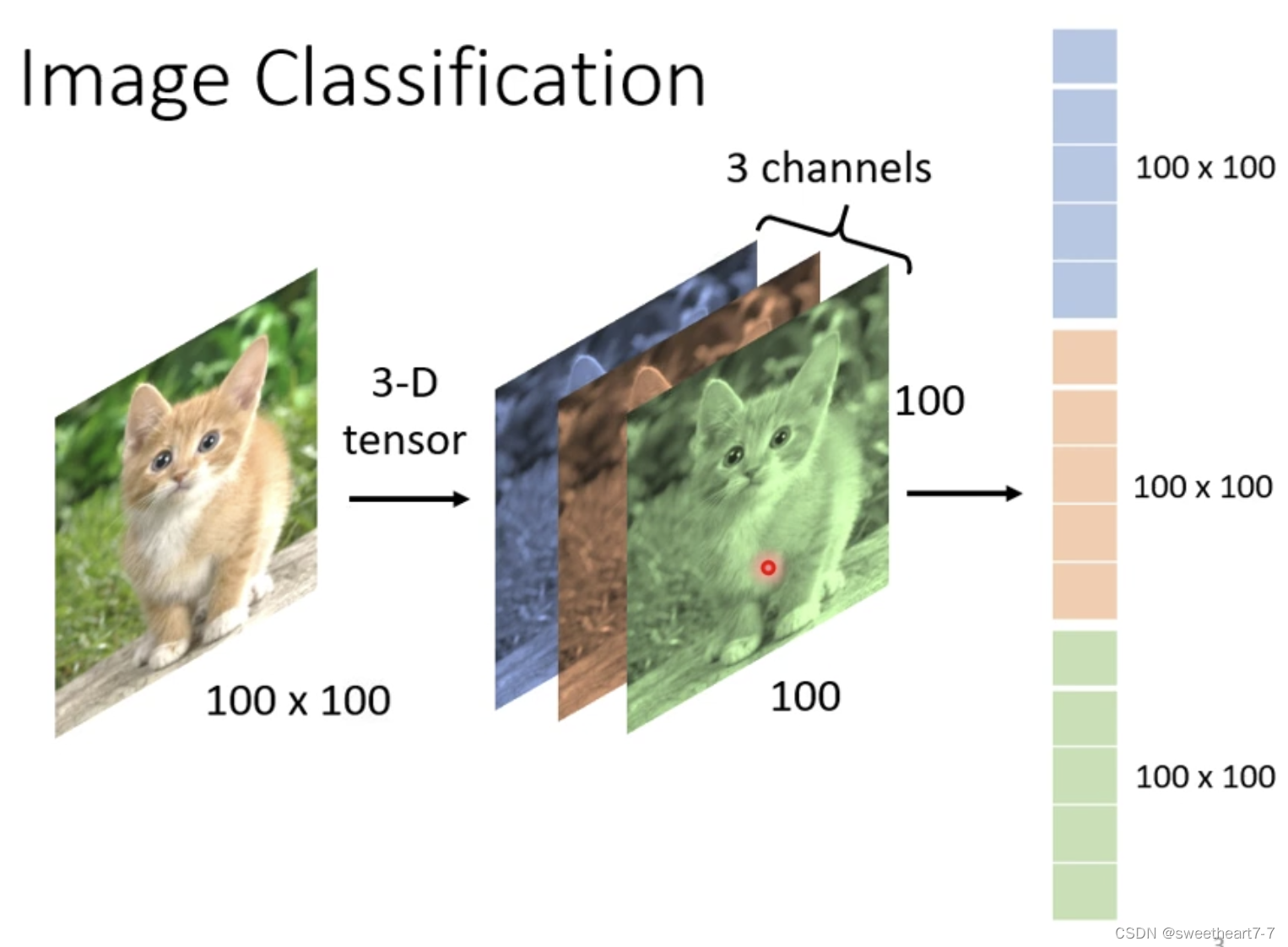
将图片打平然后作为网络的输入
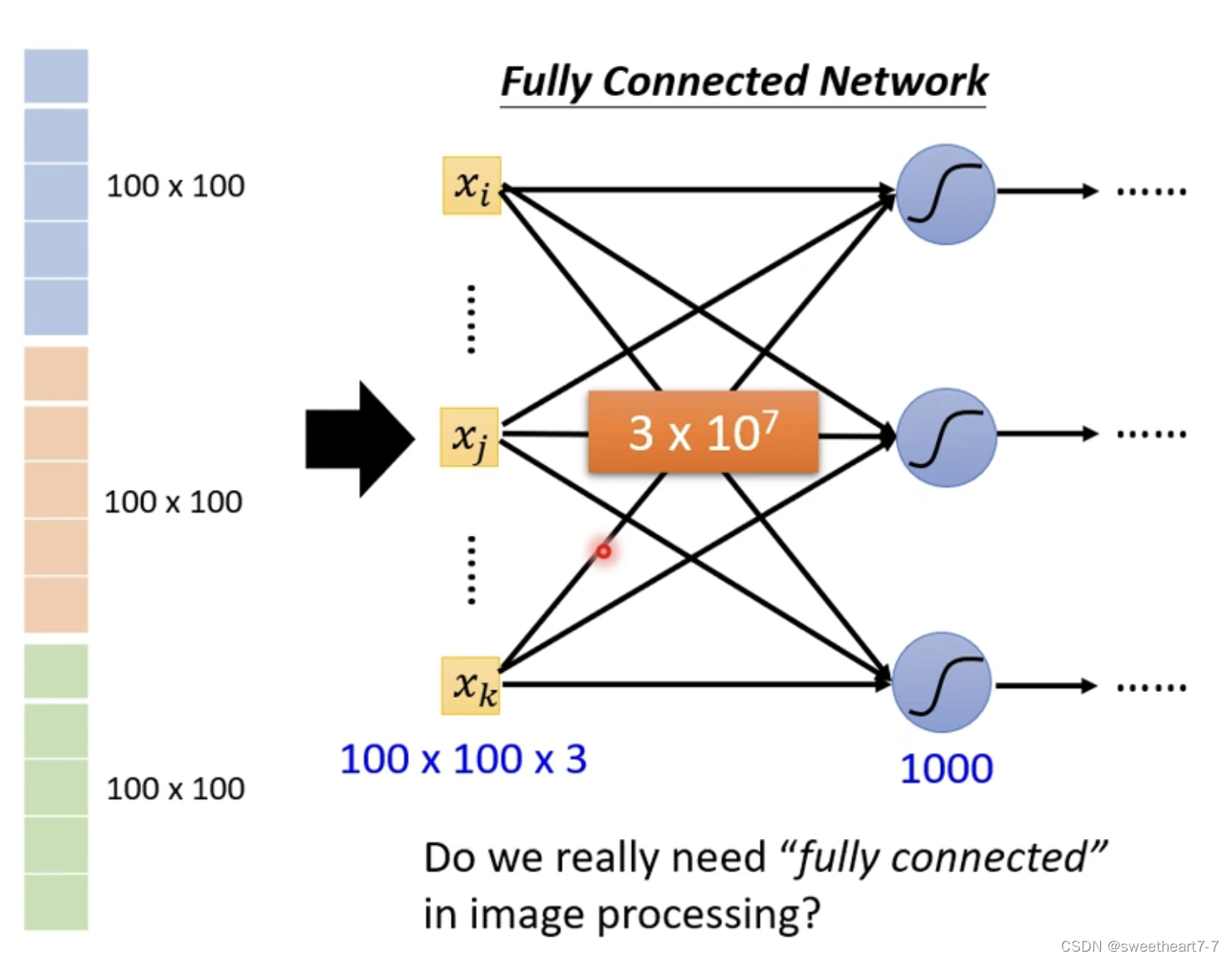
由于输出较多,如果使用 Fully connected Network 很容易出现 Overfitting。
那如何避免 Overfitting ?
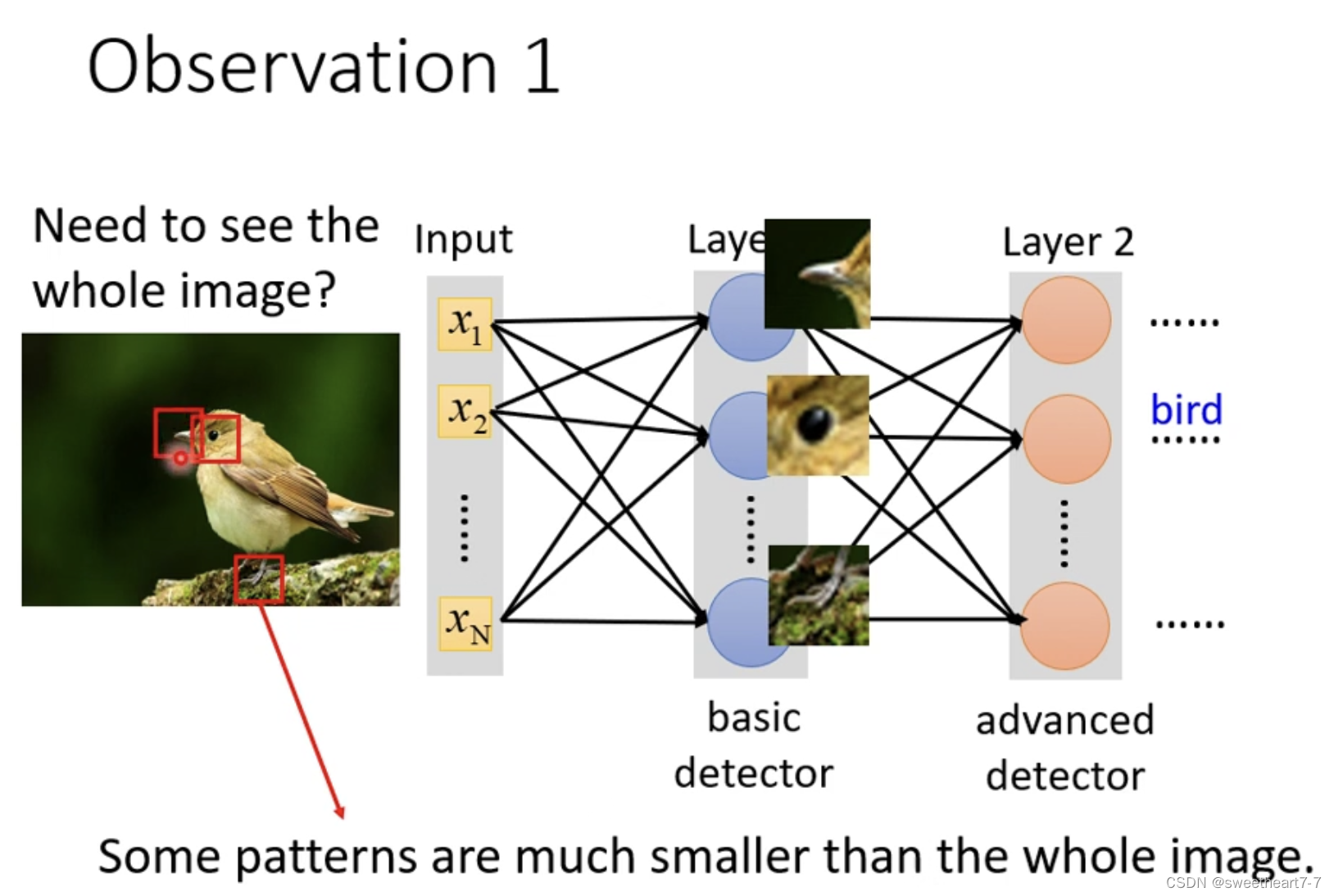
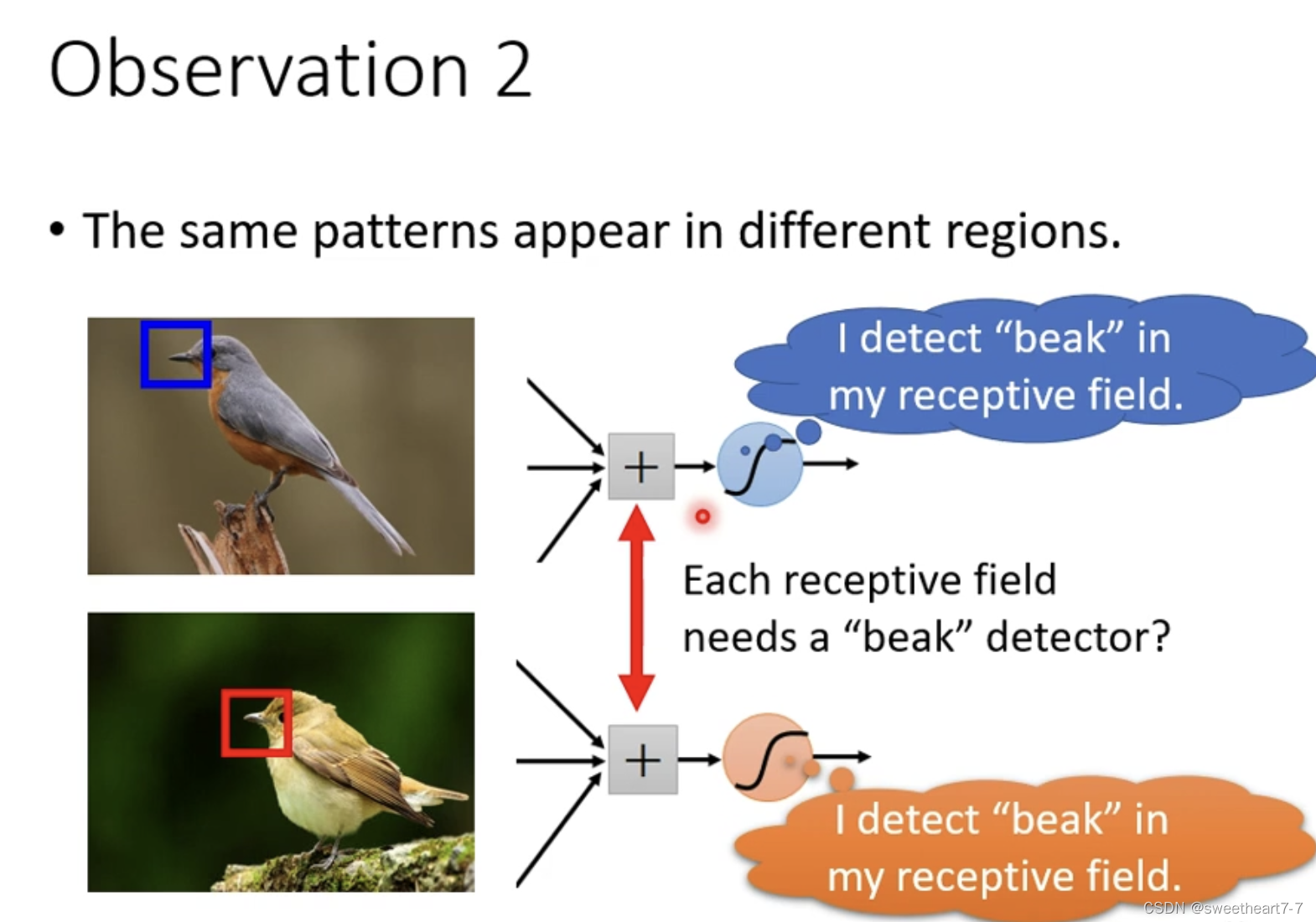
通过观察我们可以发现把图片的某些部分作为输入就够了。
将 3 ∗ 3 ∗ 3 3*3*3 3∗3∗3 的一块区域 作为一个 Receptive Field,每个 Neuron 只需要考虑自己的 Receptive Field 中的东西,再将其拉直,然后作为一个 Neuron 的输入。
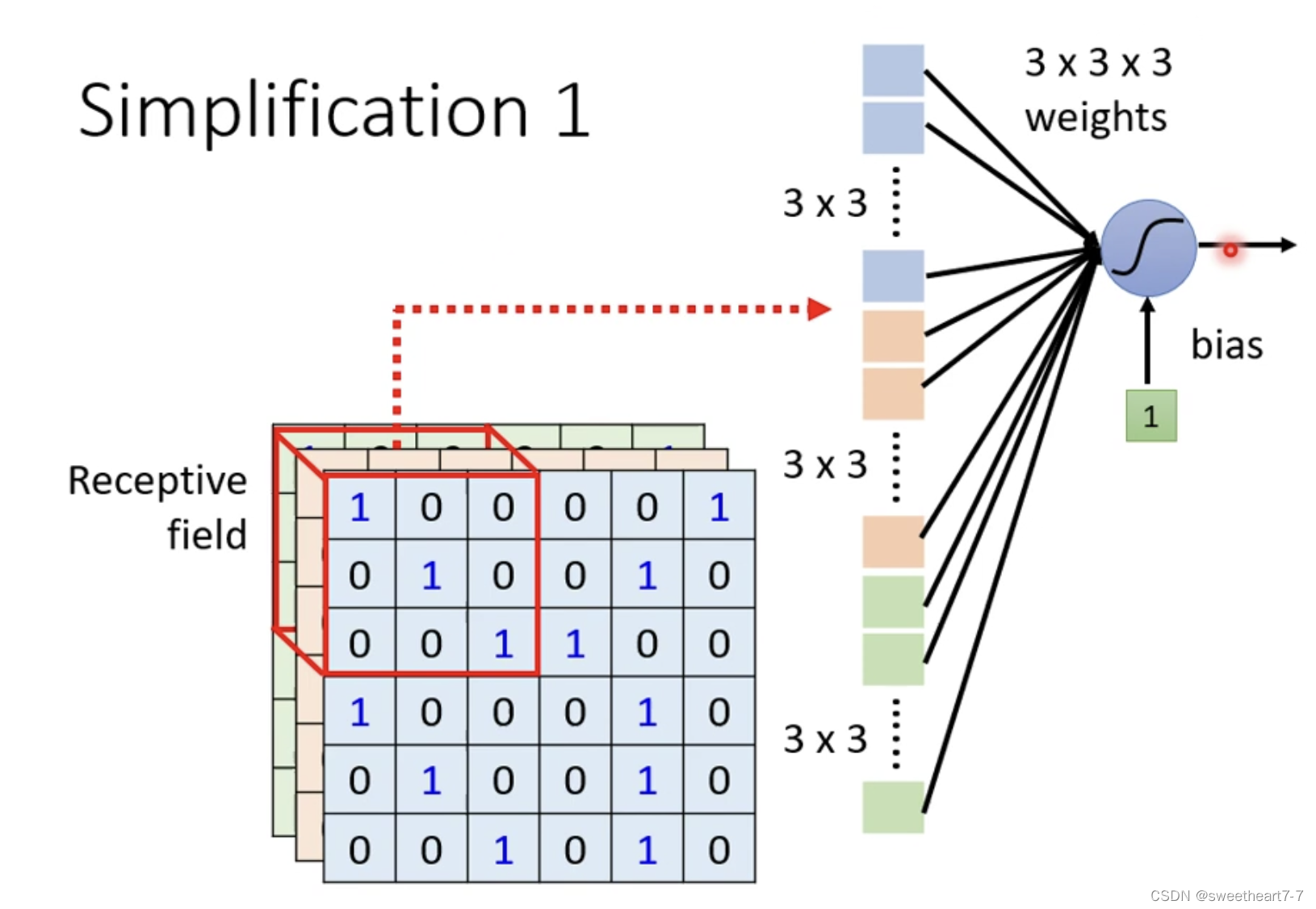
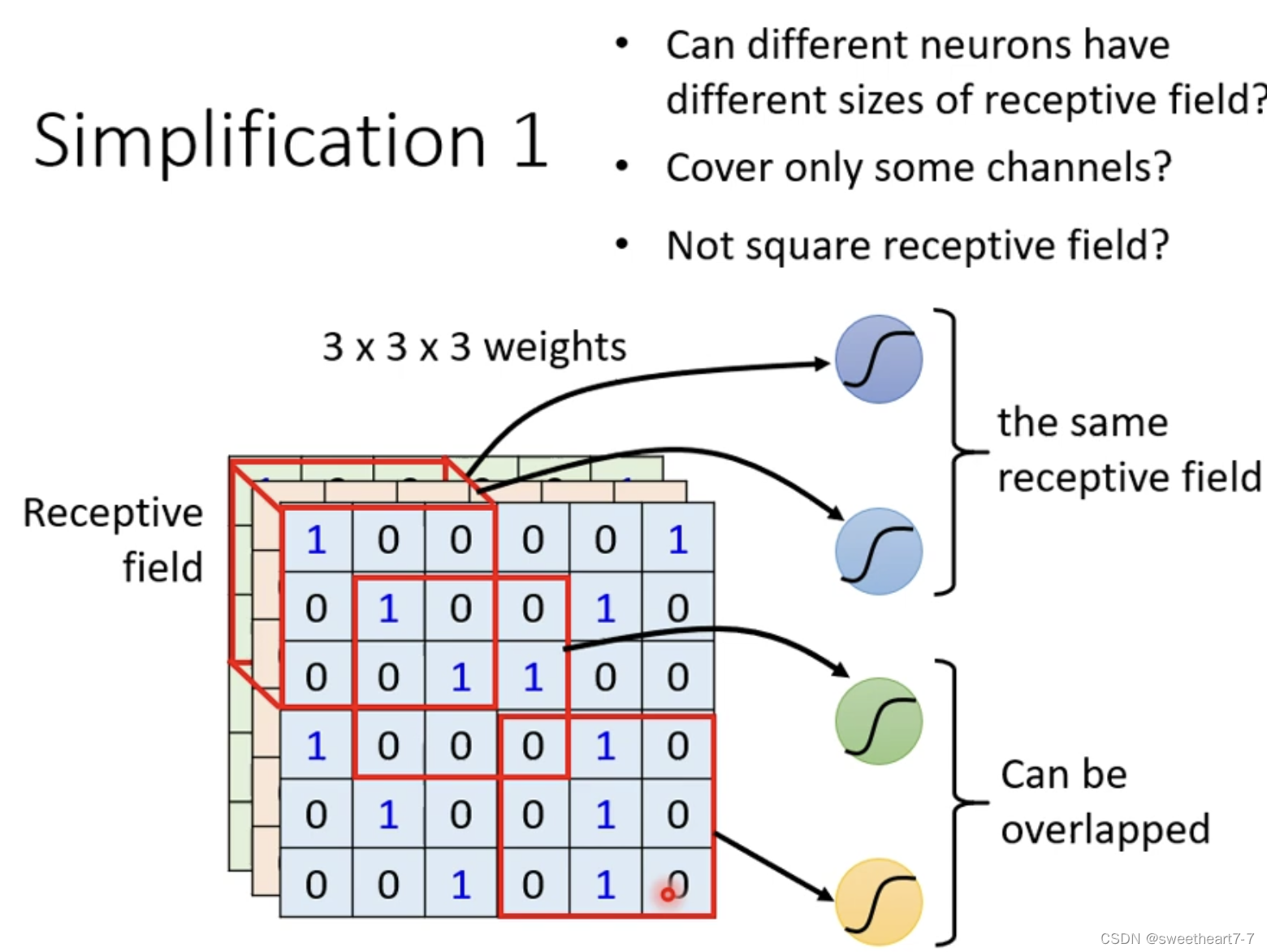
Receptive Field 大小等可以自己定义。
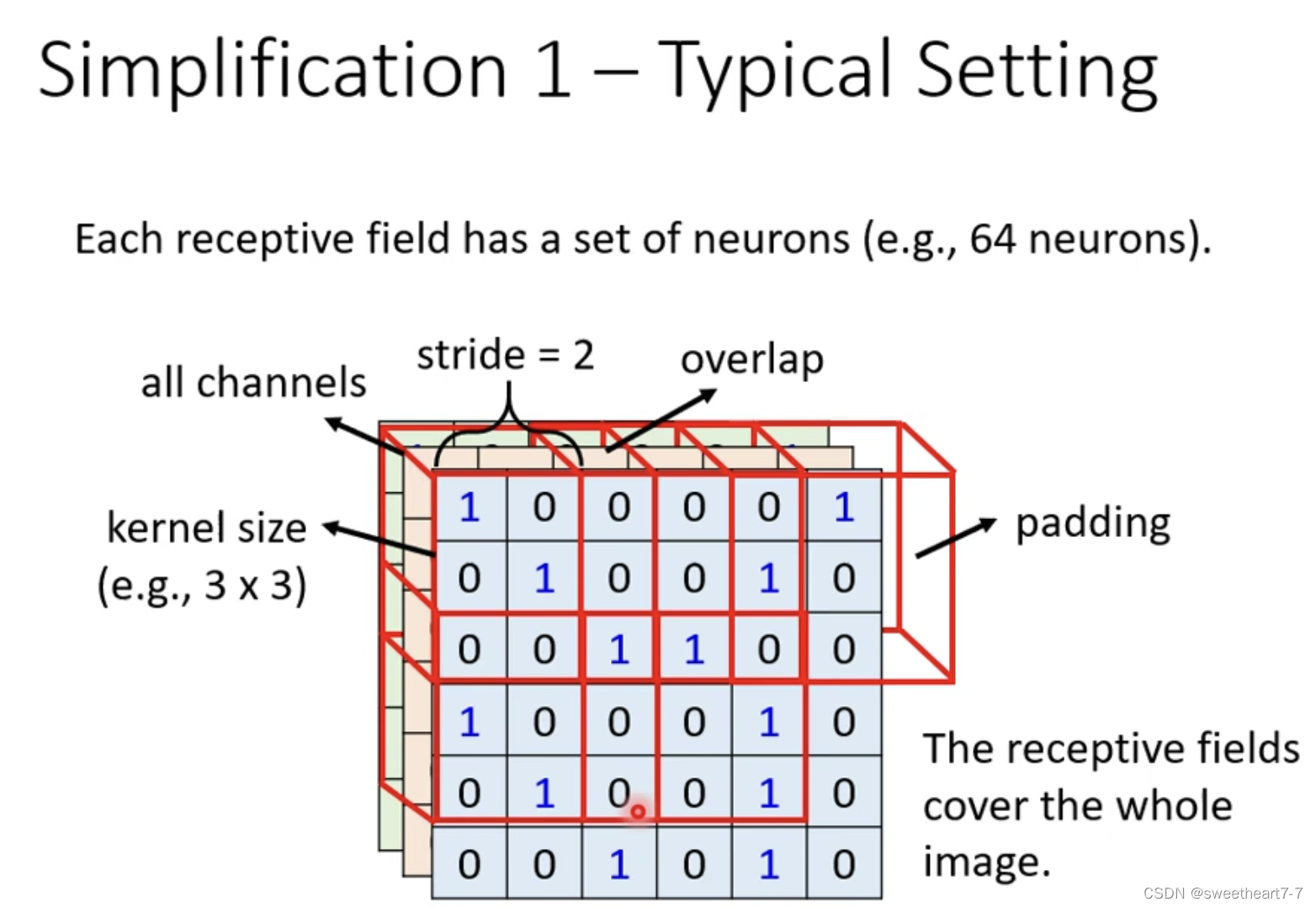
Receptive Field 典型的设置:
一般来说 Channel 都会被考虑,所以我们只需要考虑 高和宽了,也就是 Kernel Size,一般使用 3 ∗ 3 3 * 3 3∗3 的 Kernel Size。
移动的范围:Stride(步长)。
超出范围(overlap)的解决办法:padding 扩充图片。
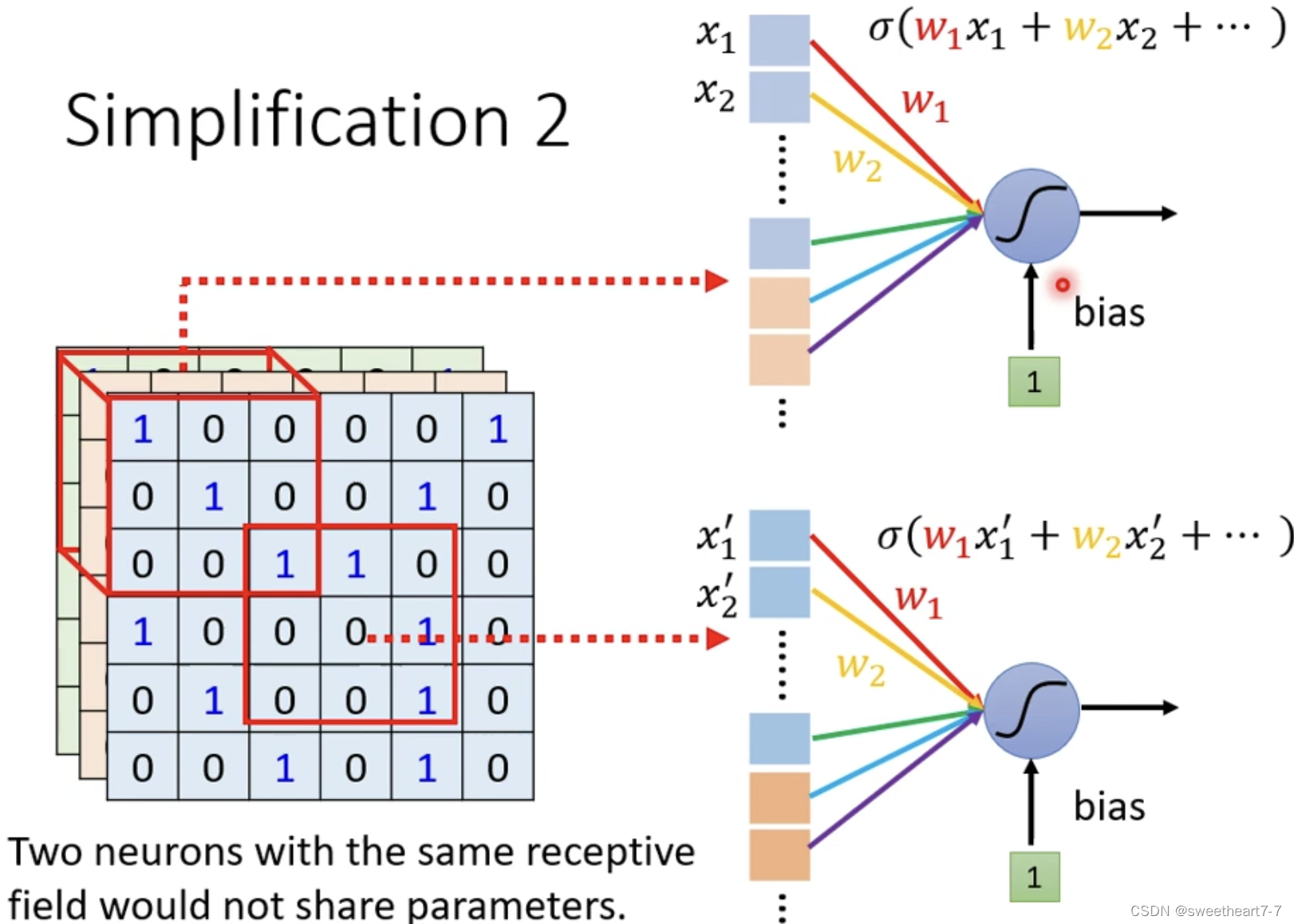
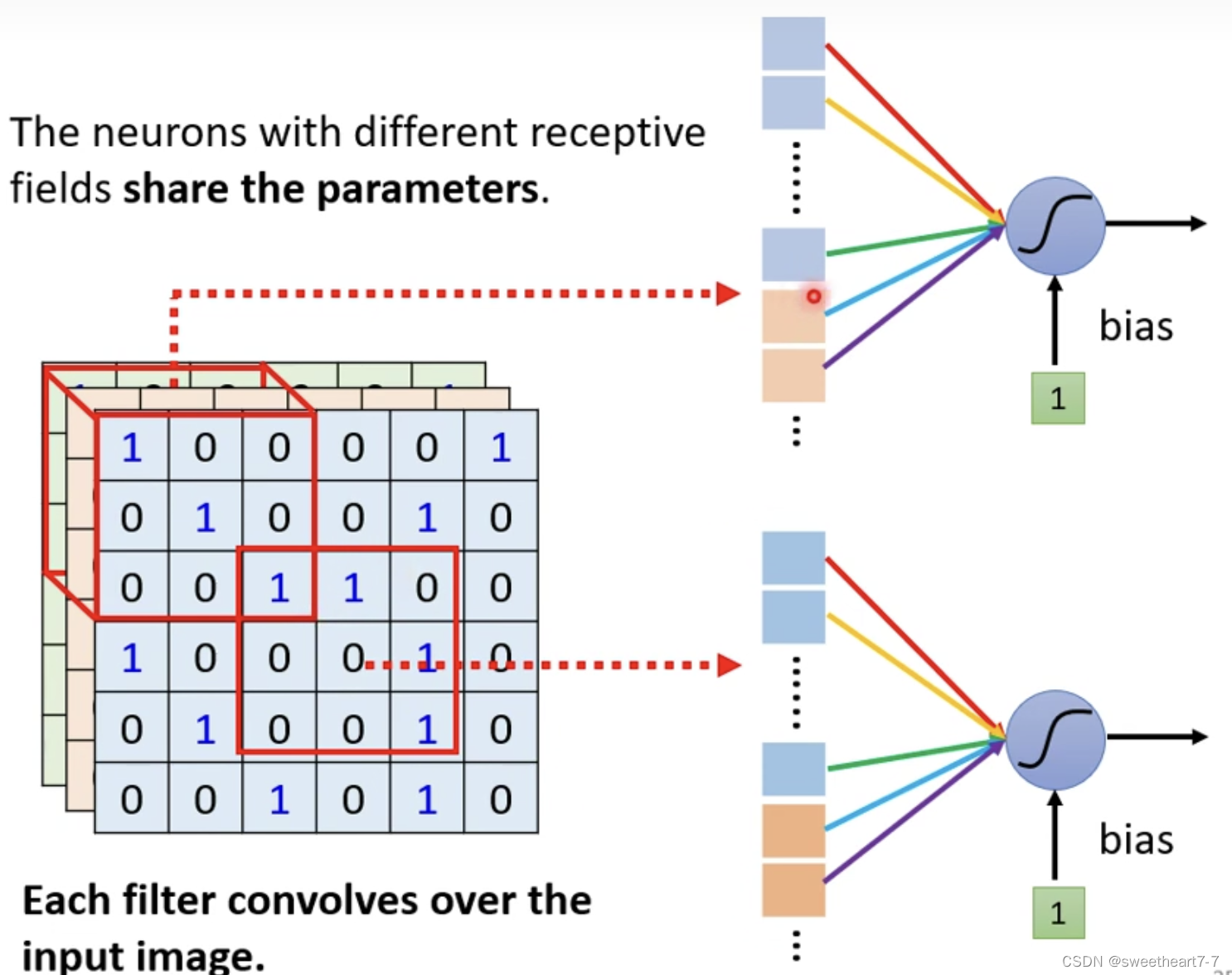
对有的 Receptive Field 共享参数,因为输入不一样,输出不一样,而如果输入一样的话,其输出就一样。
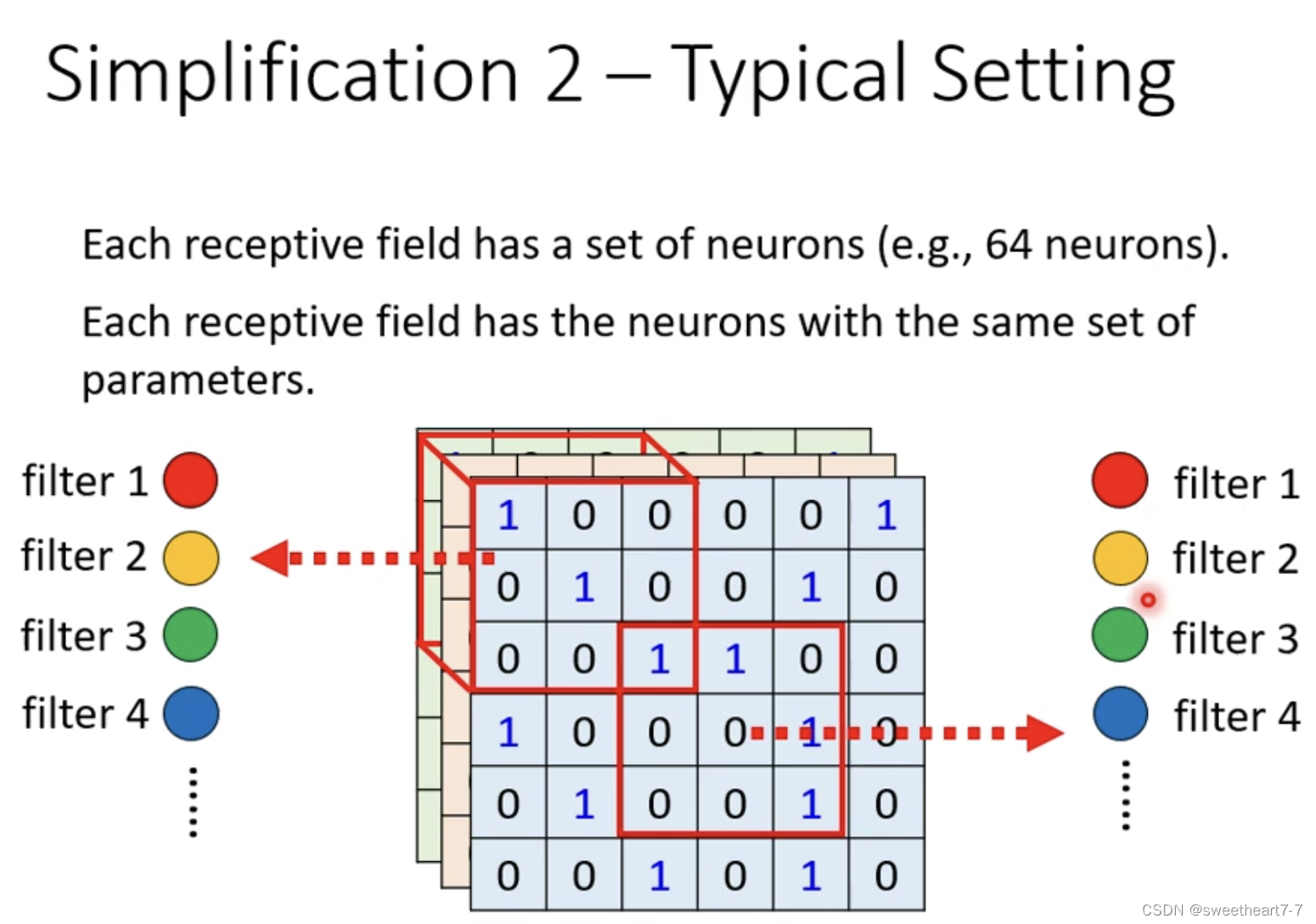
两个 Receptive Field 都具有多个 Neuron,如果他们的第一个 Neuron 共享参数,这组参数就叫做 filter 1。
由于一张图片不需要看全部而只需要看一小部分,所以出现了 Receptive Field 的概念,所以这个 Neuron 的弹性变小了,加入参数共享之后,有的 Neuron 的参数就会一模一样。
Fully Connected 的 Network 它可以自己决定 Neuron 看一张图片的全部还是一部分。
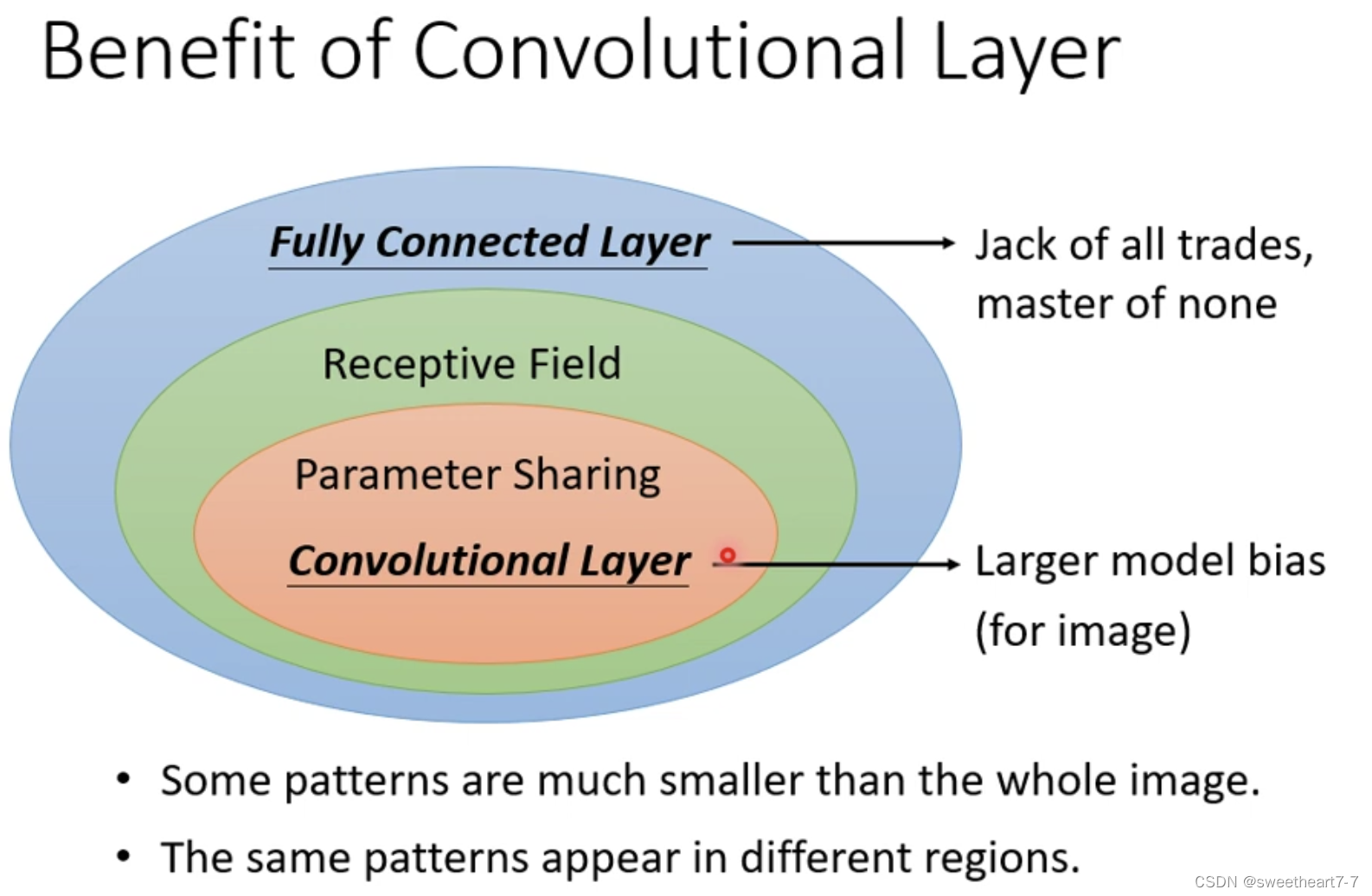
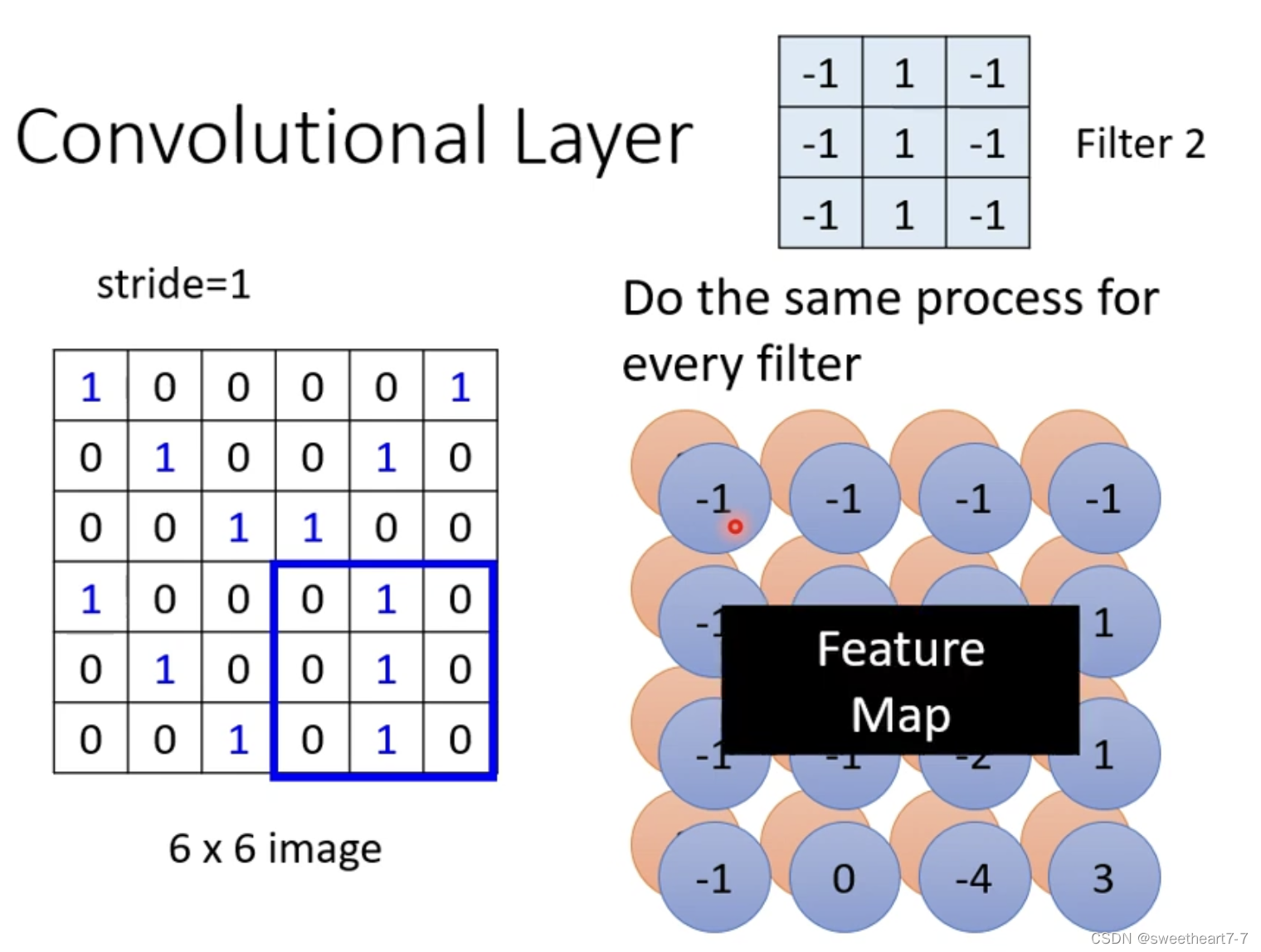
Convolutional Layer
有一排 filter,一个 filter 的大小: 3 ∗ 3 ∗ c h a n n e l 3 * 3 * channel 3∗3∗channel,filter 用于在图片里面抓取 Pattern。
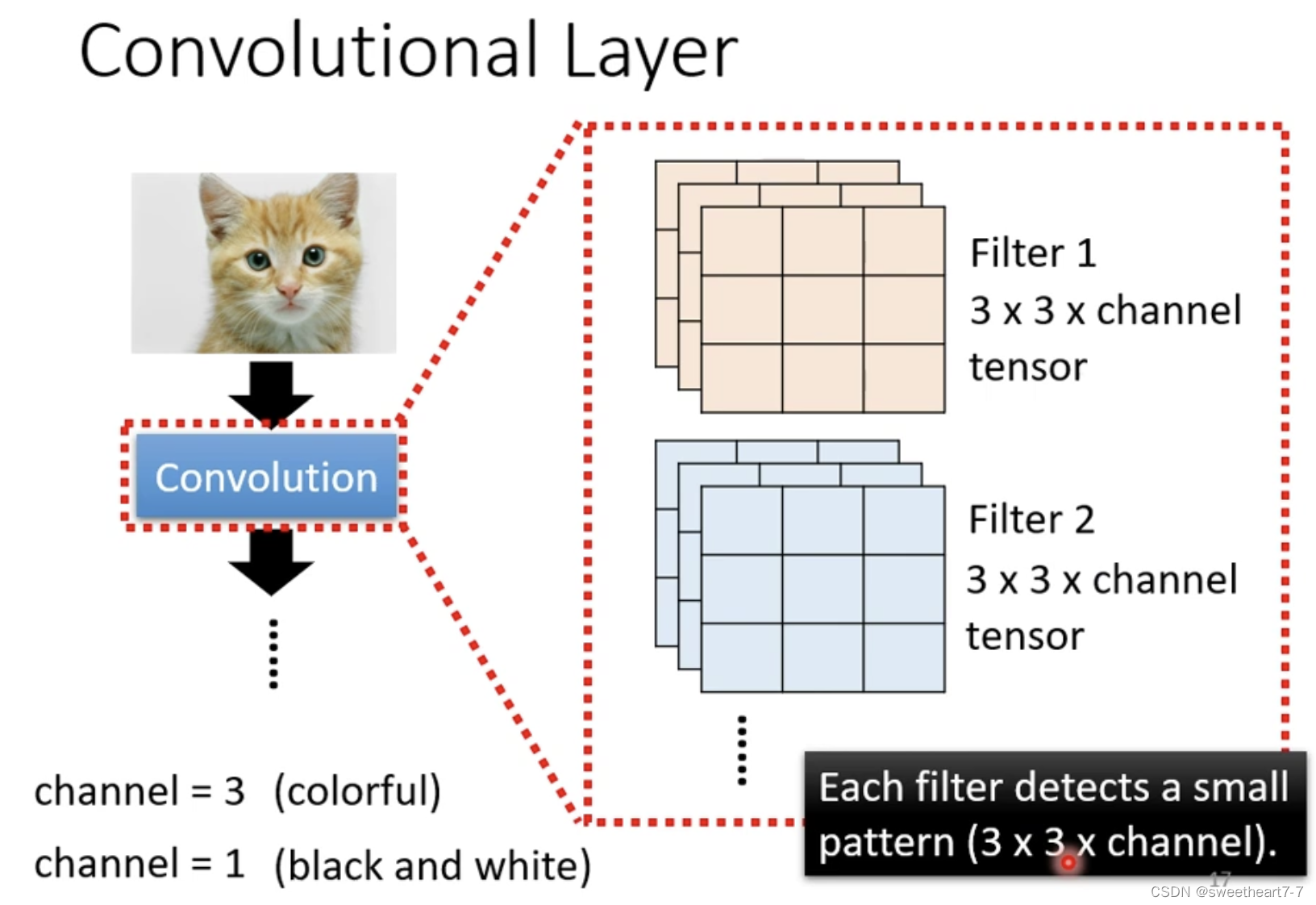
假如 channel 大小是 1,filter 是一个 3 ∗ 3 3 * 3 3∗3 的 Tensor,而 Tensor 中的数值就是 model 里面的 参数,假设这些参数已知。
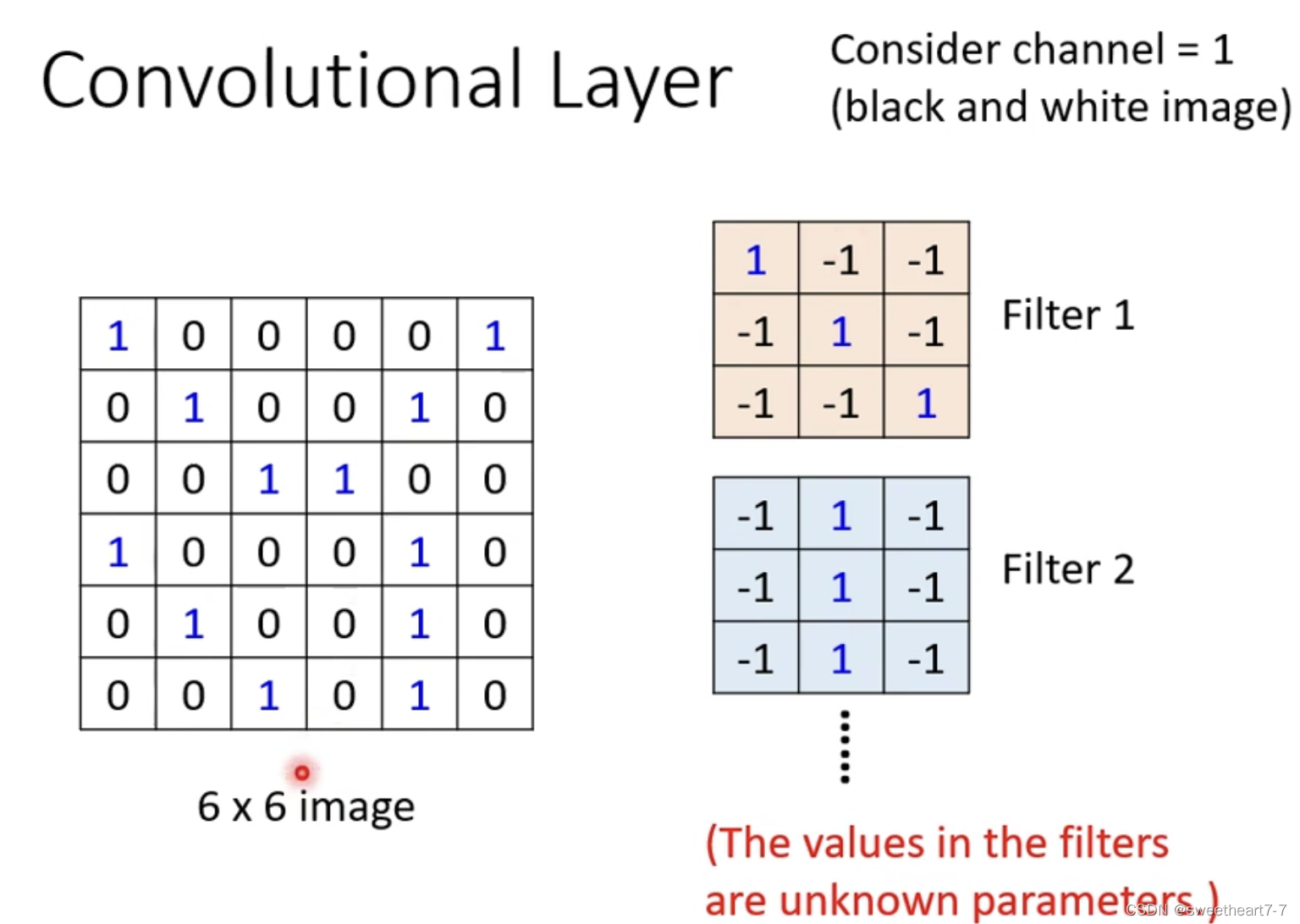
这些 filter 如何在图片上侦测 pattern?
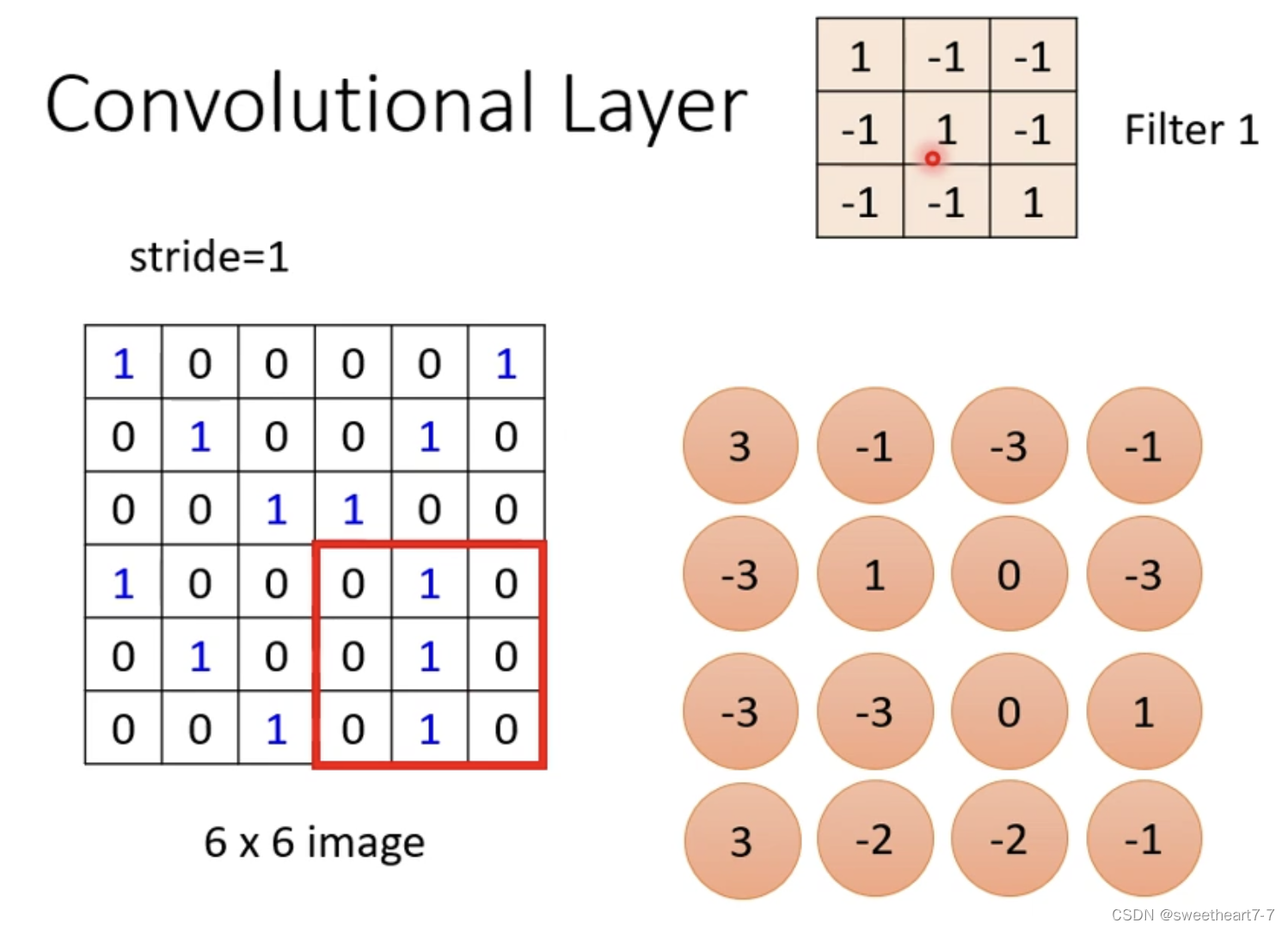
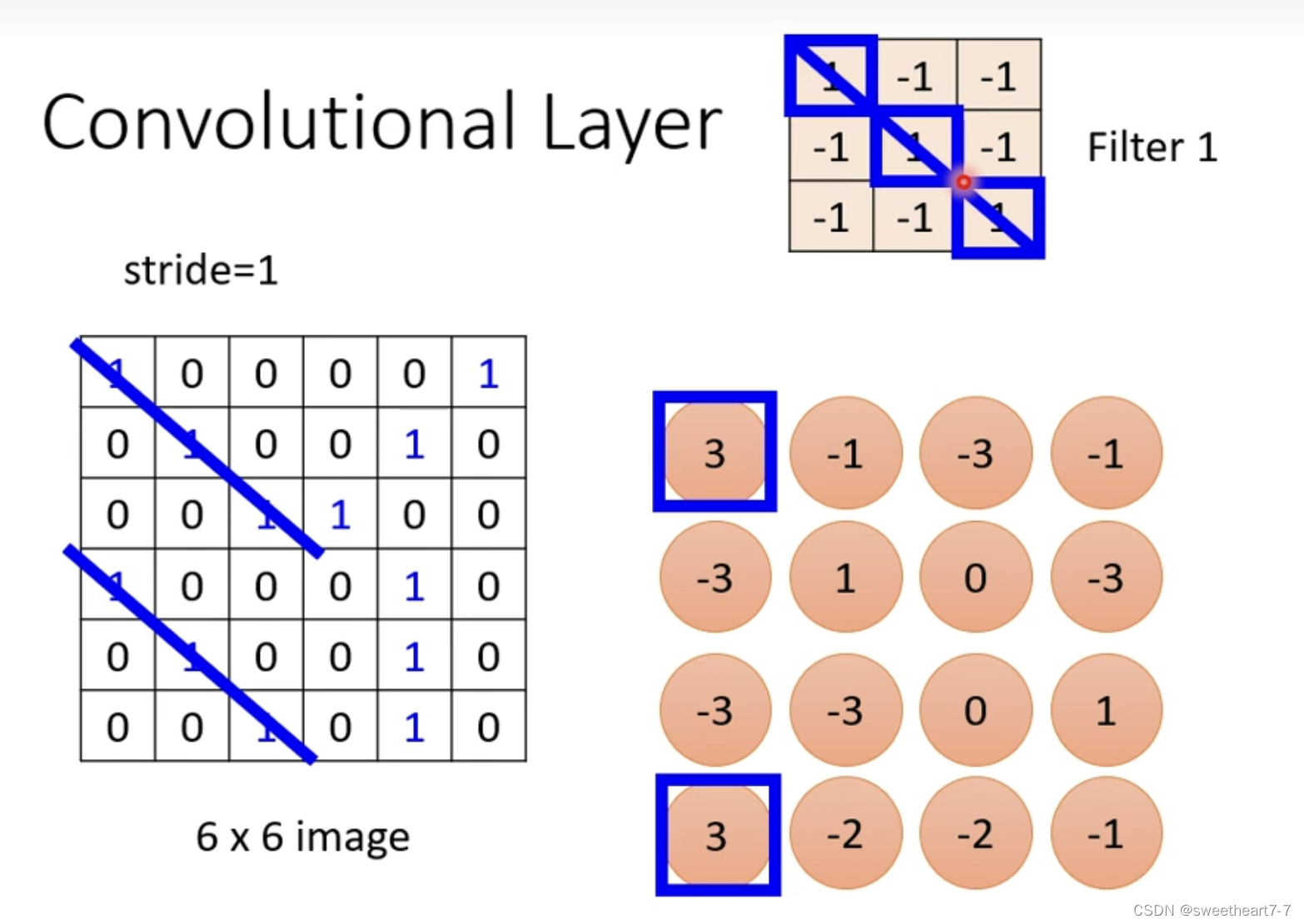
新产生的 Tensor 叫做:Feture Map
第二层的 filter 的 channel 大小是 64
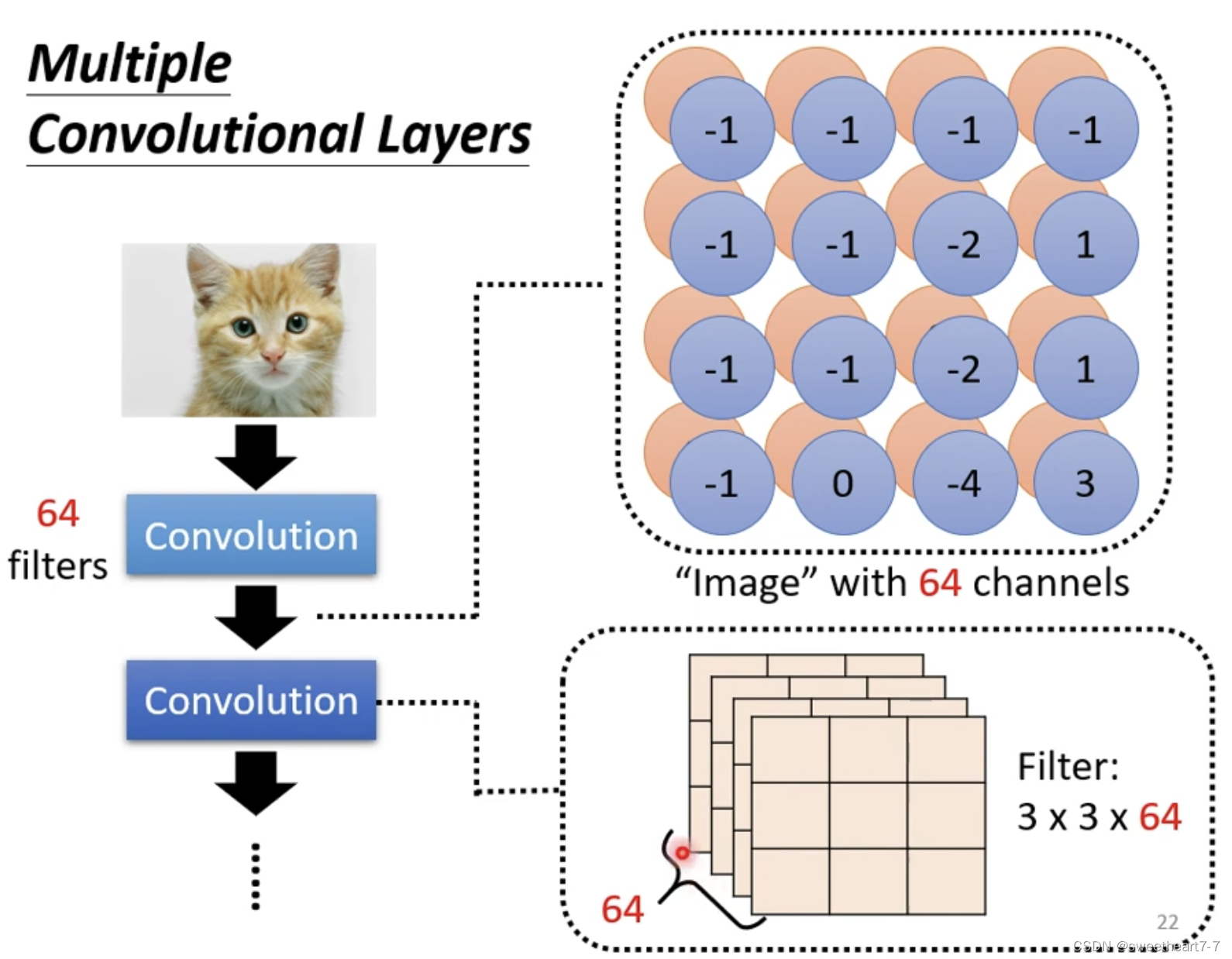
network 叠的越深,他所能看到的范围越就会来越大。
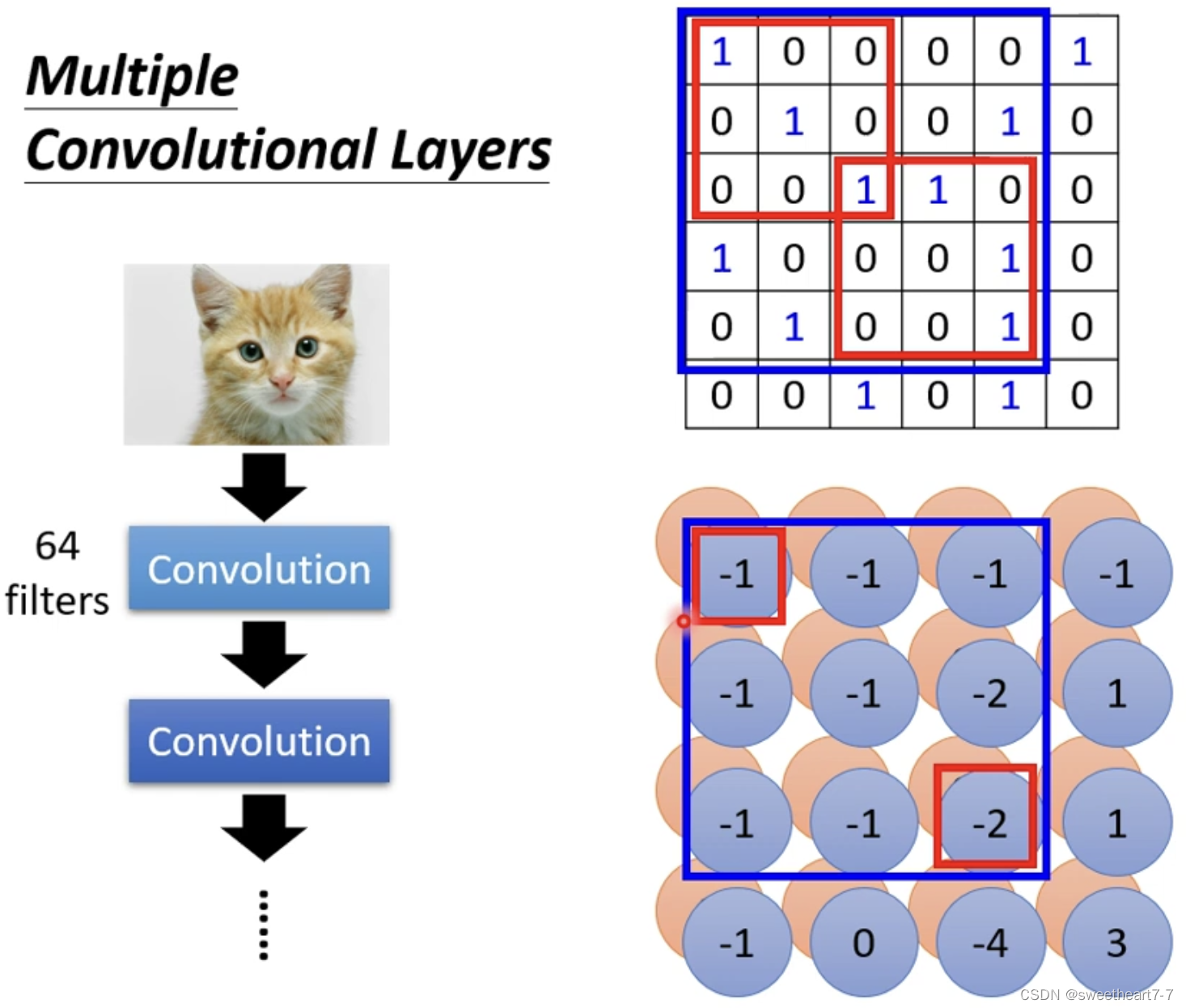
Neuron 对应的参数就是 filter 中的数值。
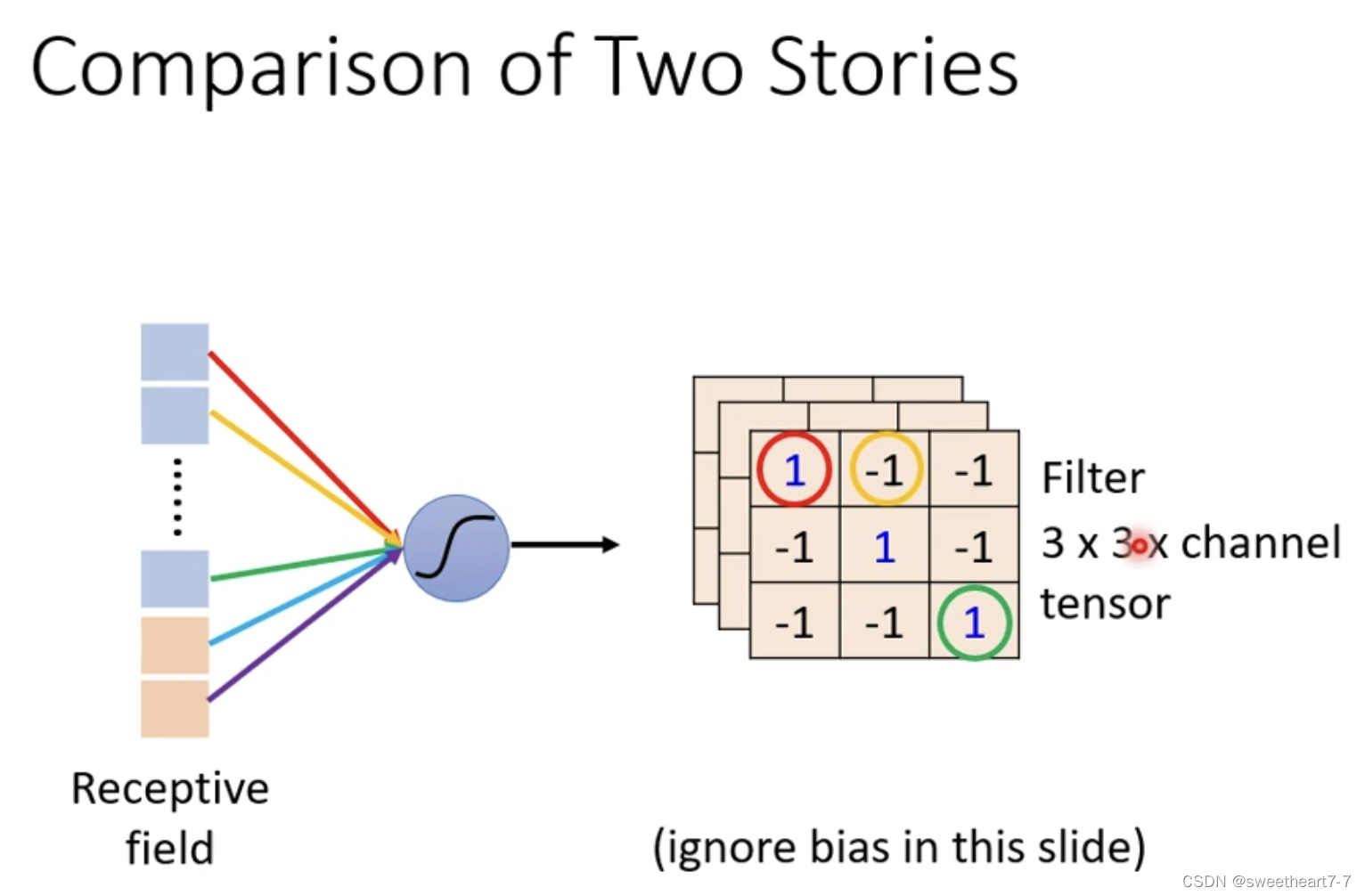
将一个 filter 扫过一张图片叫做 Convolution。而一张 filter 扫过一张图片,就相当于 Neuron 共享同一组参数。

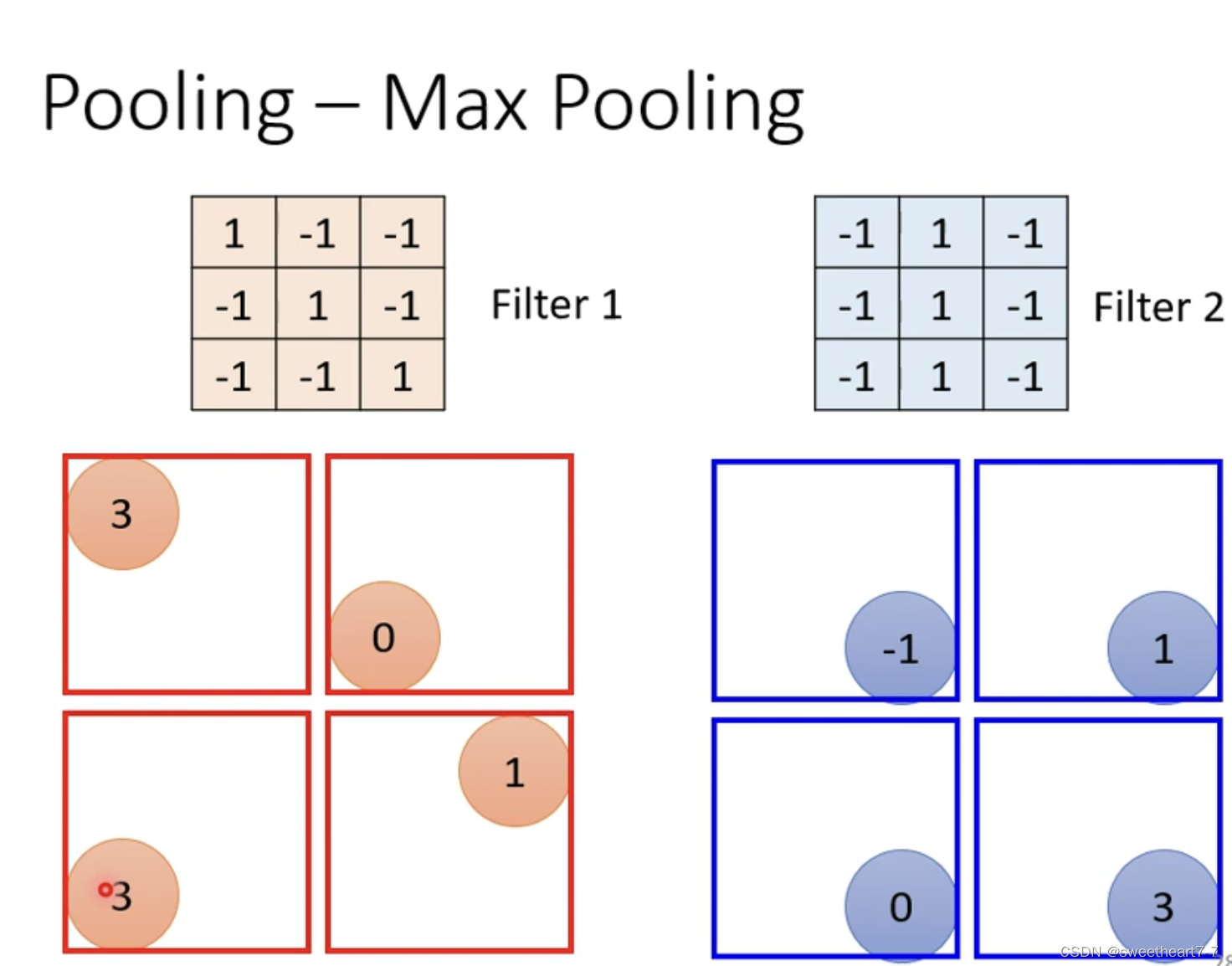
Pooling — Max Pooling
可以发现一张图片缩小(subsampling)后看,还是可以看出图片的本质。

通过 Pooling 可以到达缩小图片的效果。
目的:减少数据和运算量。
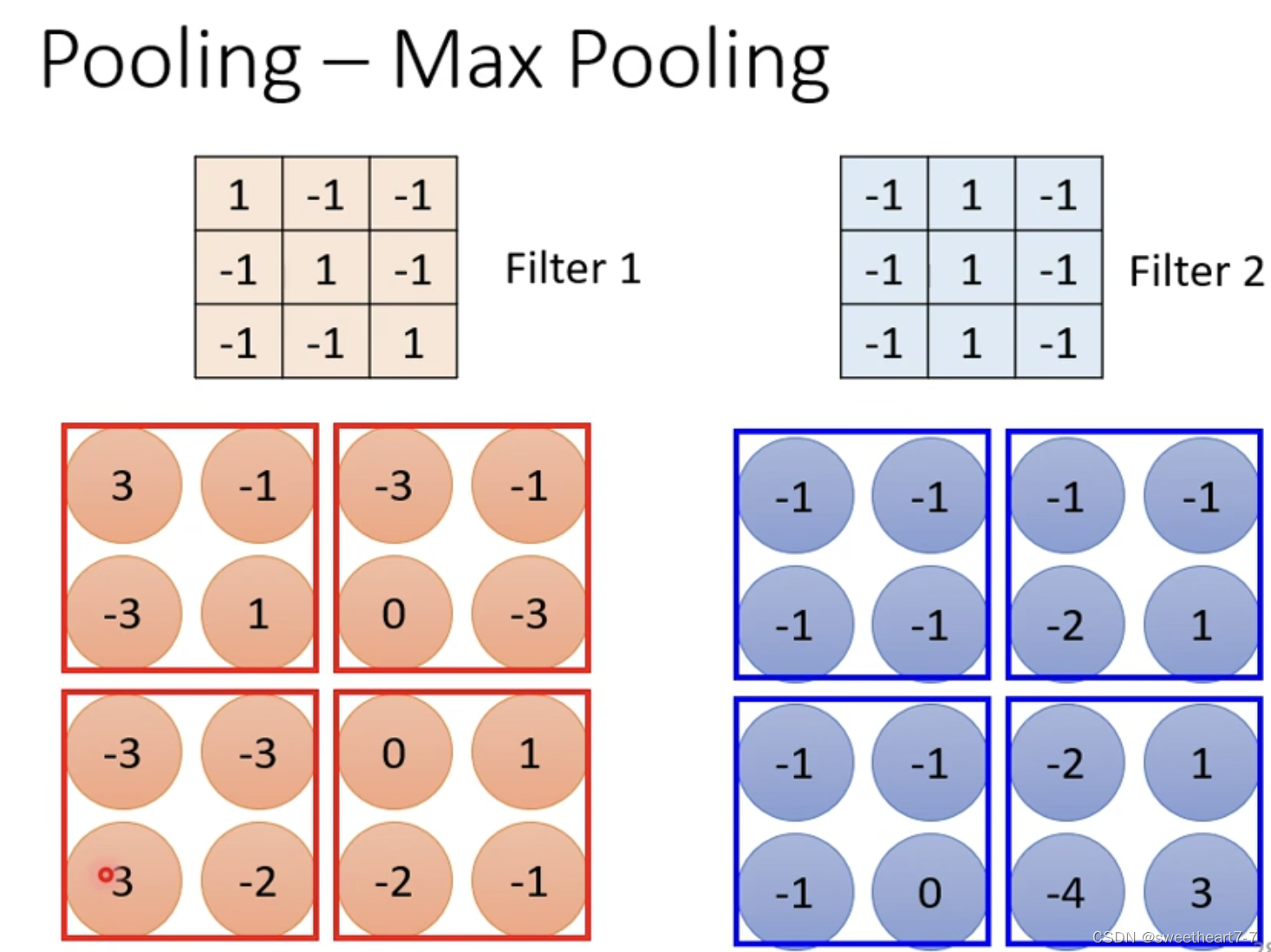
max pooling: x ∗ y x * y x∗y 的大小进行分组并选最大的。
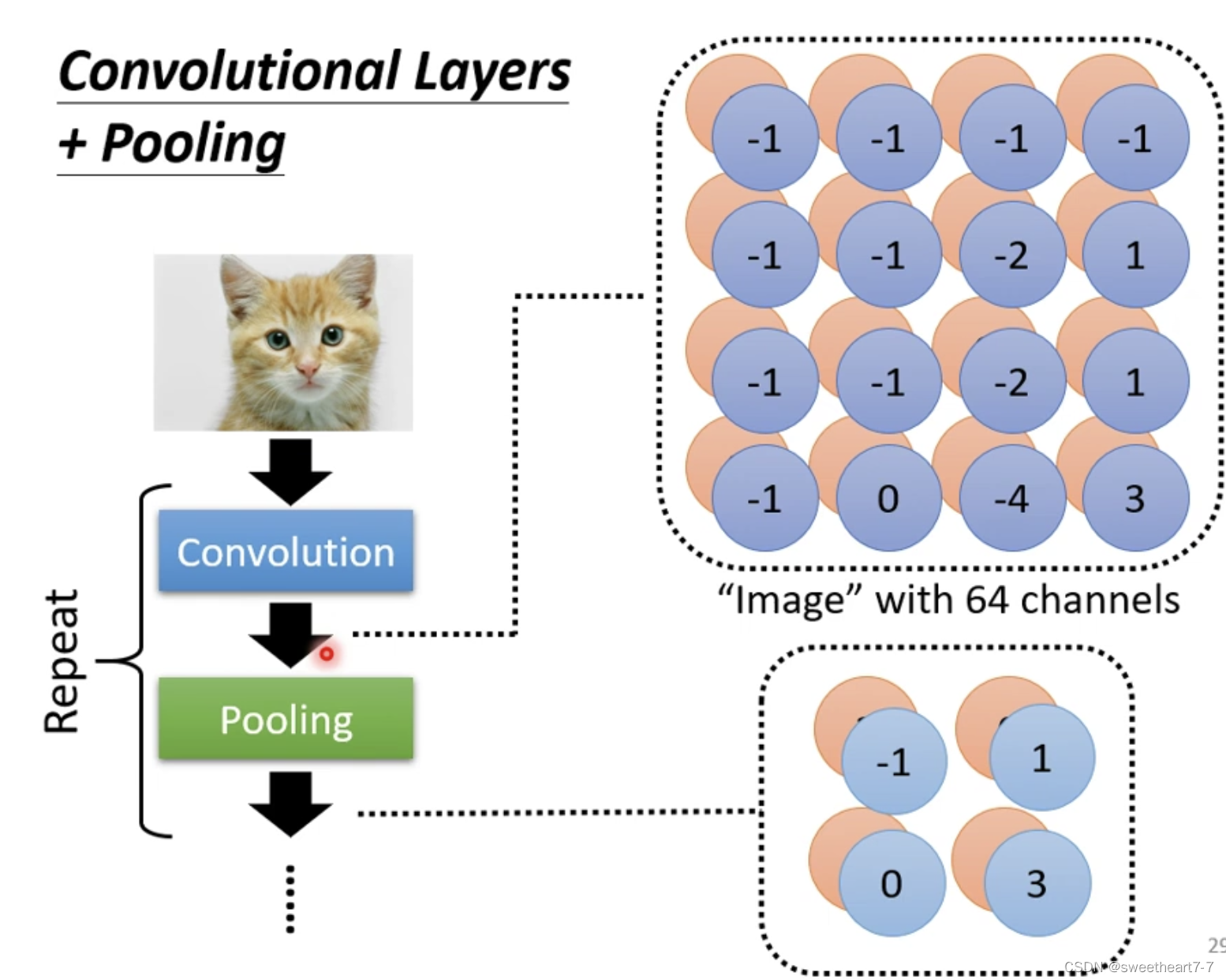
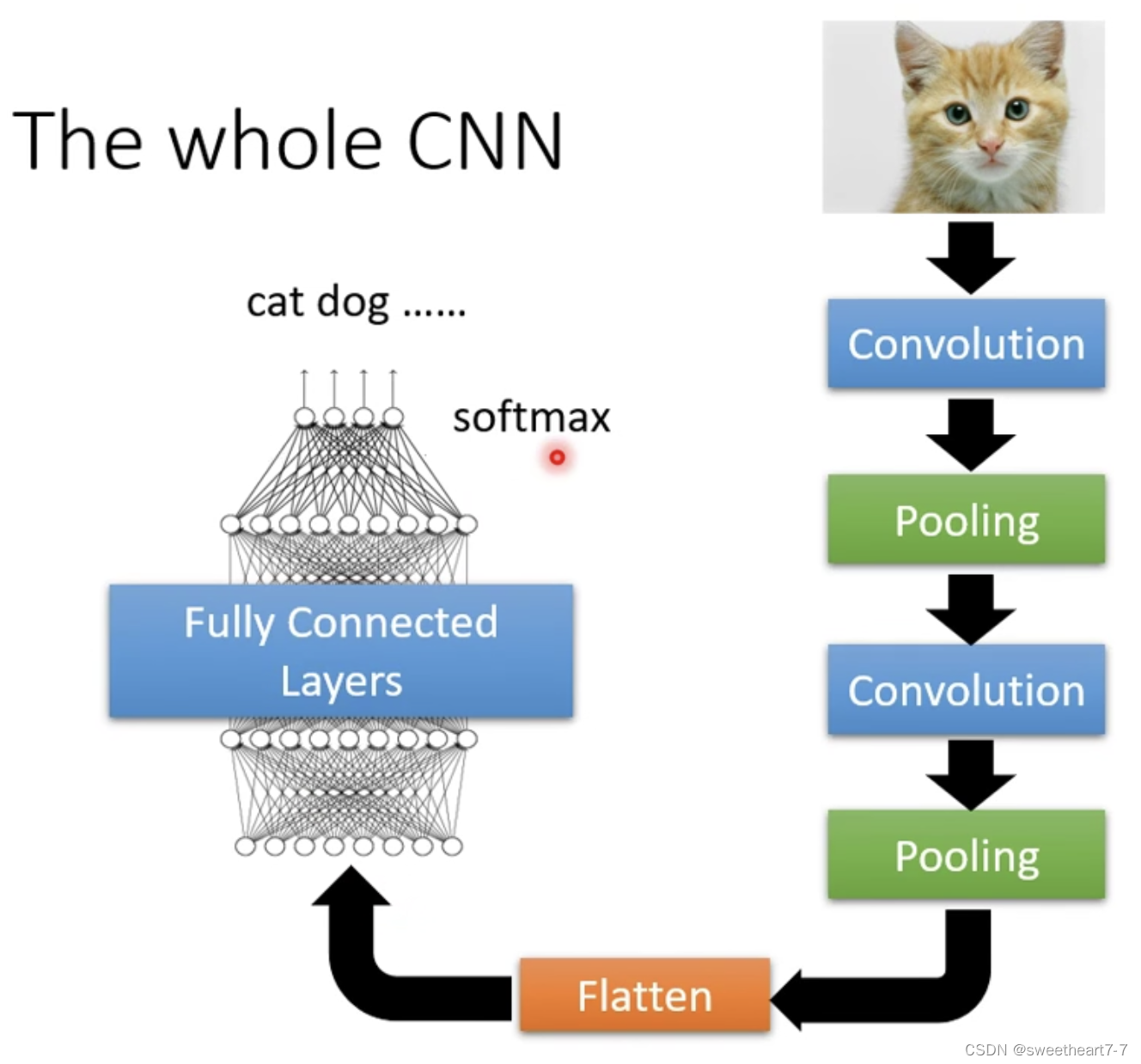
一般的 CNN 结构。
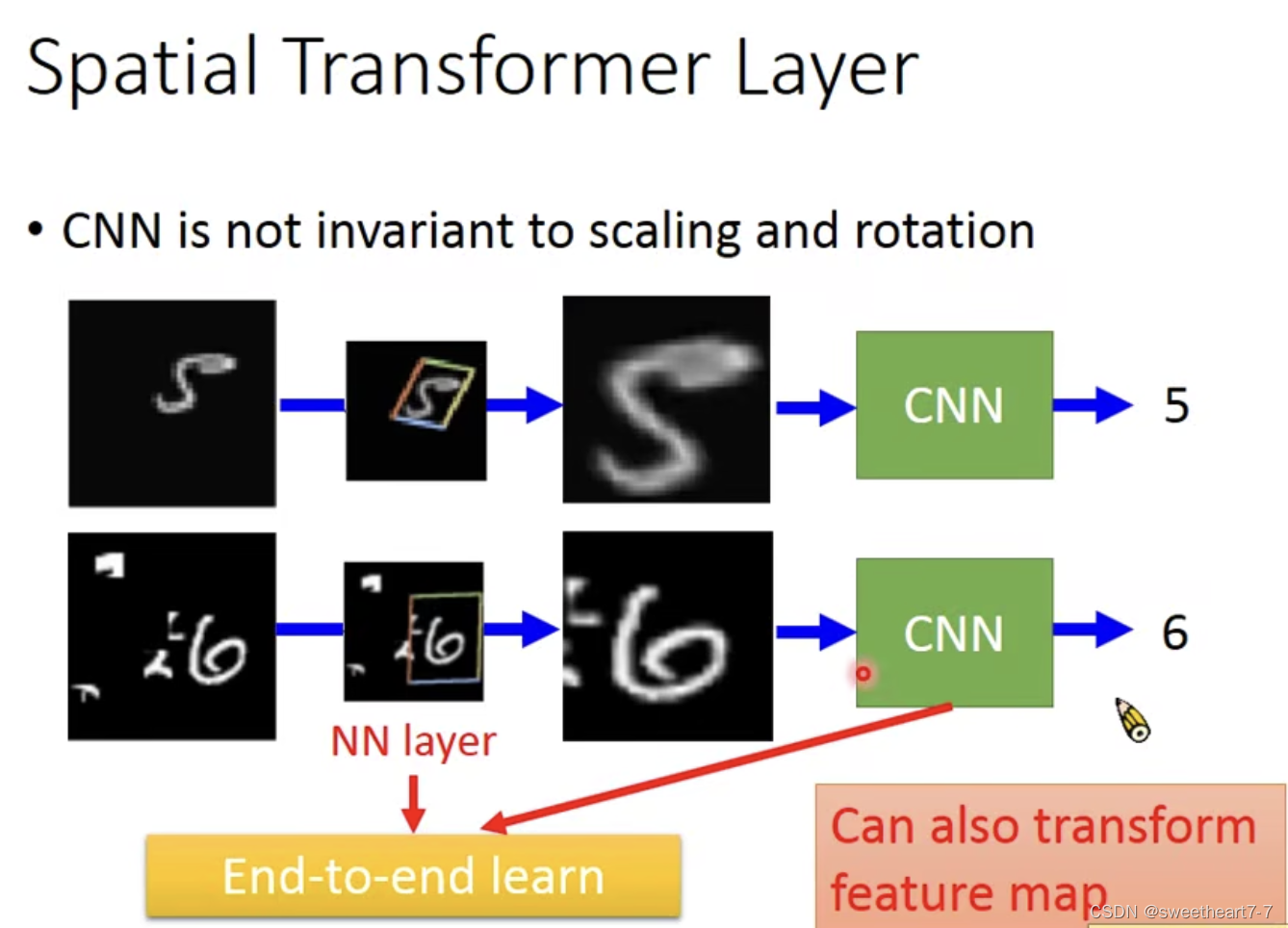
Spatial Transformer Layer
CNN is not invariant to scaling and rotation
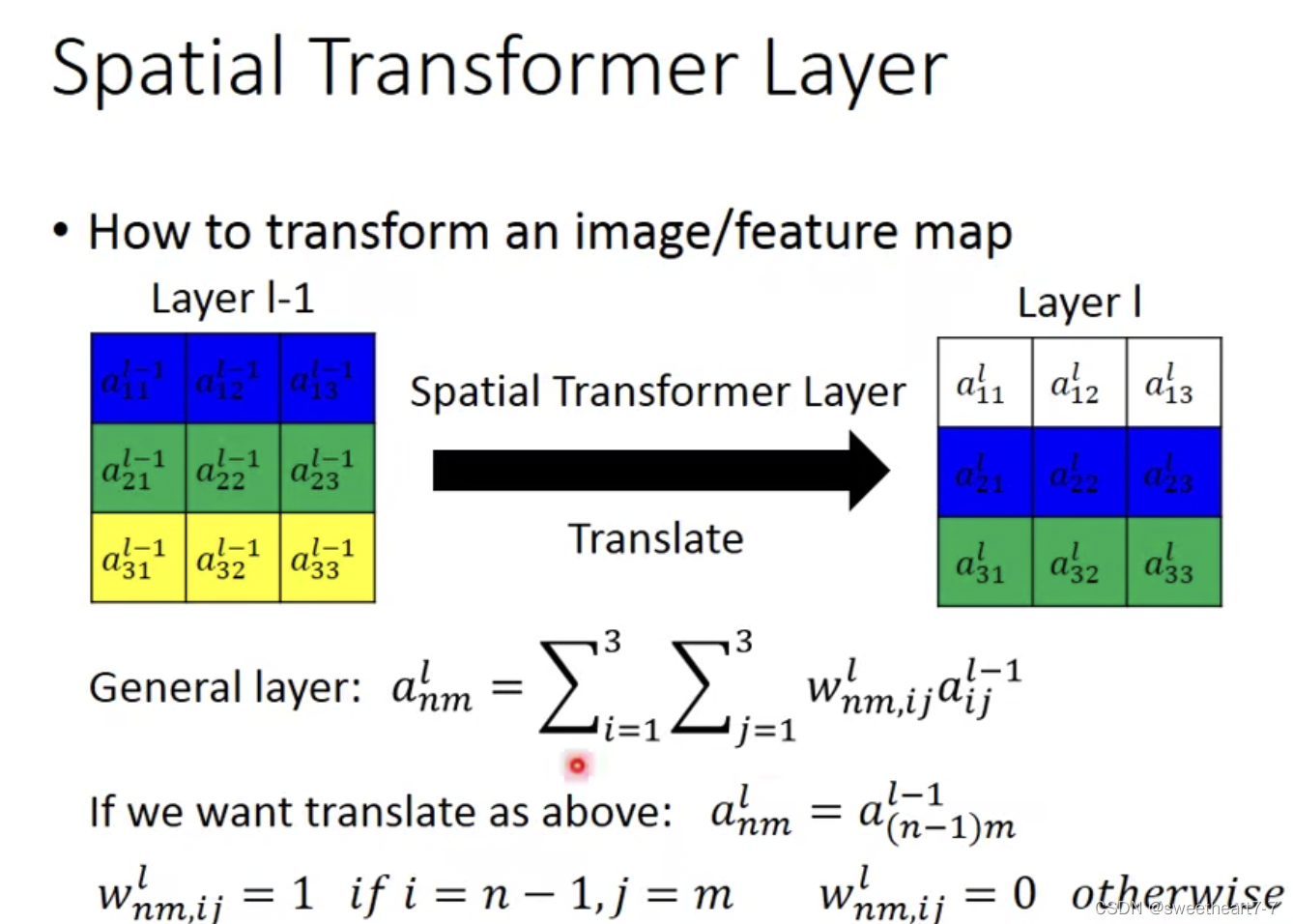
Fully connected Network 可以实现对图片进行旋转,平移,缩放(可以通过参数值来实现)。
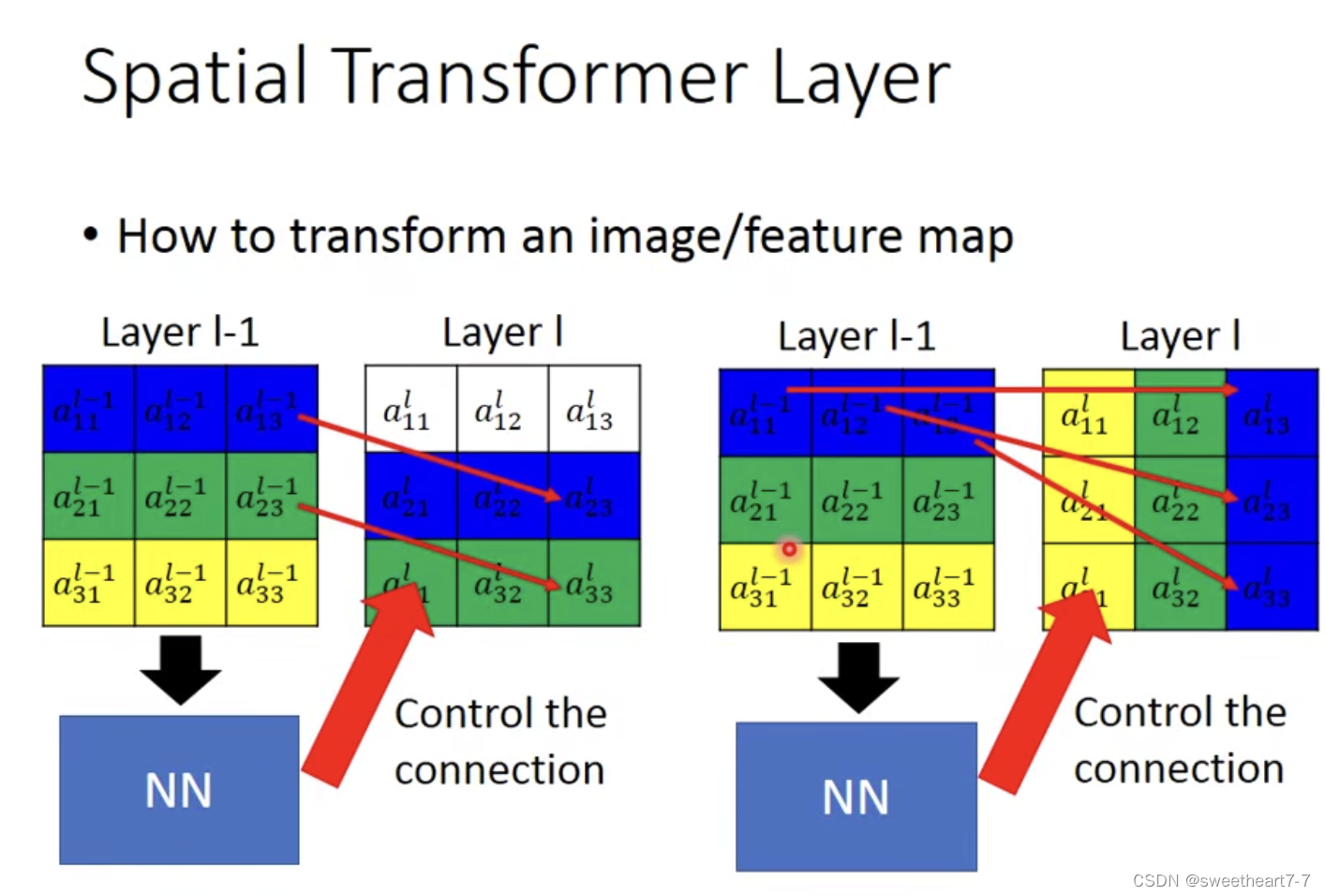
缩放/扩大
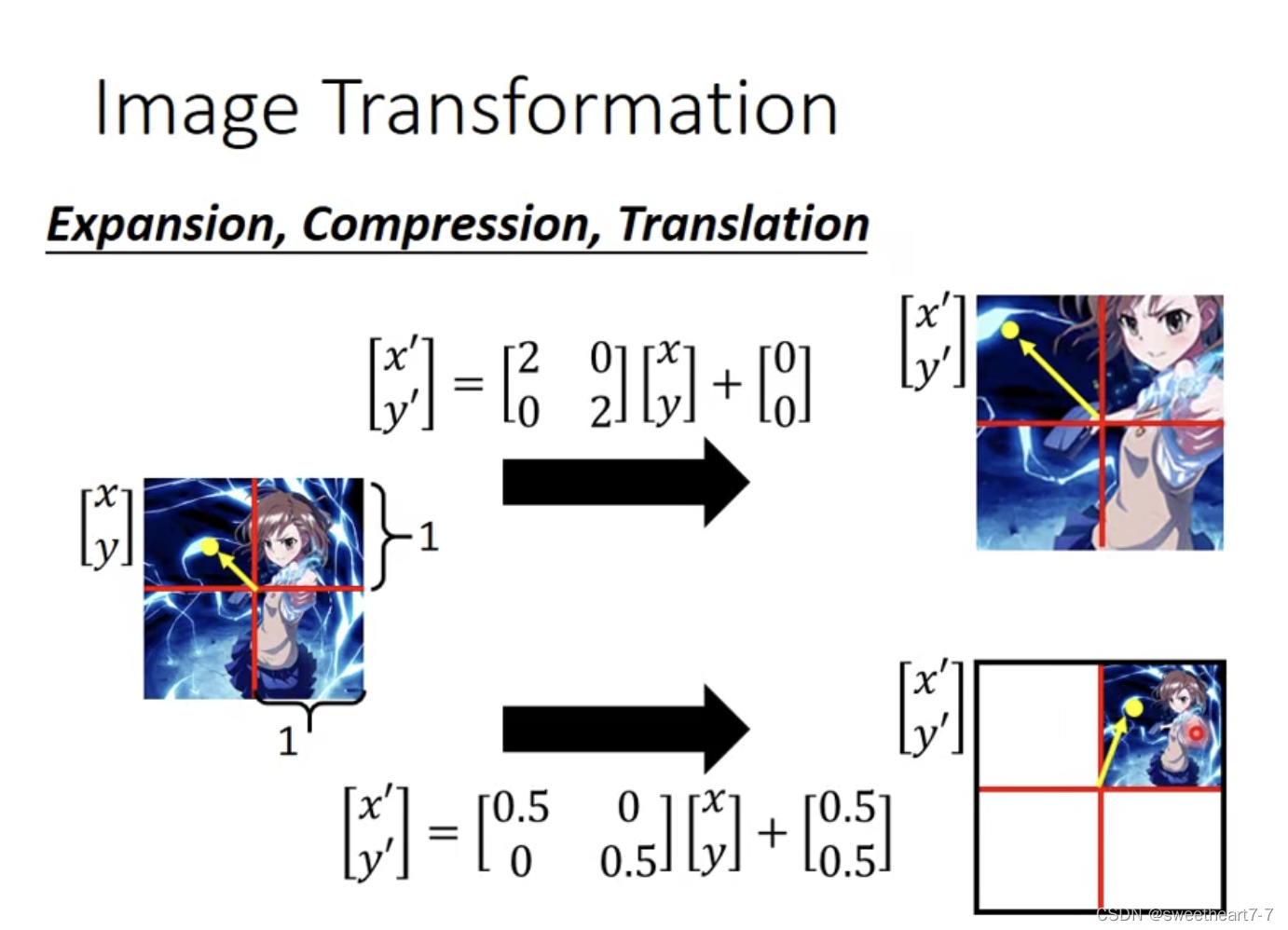
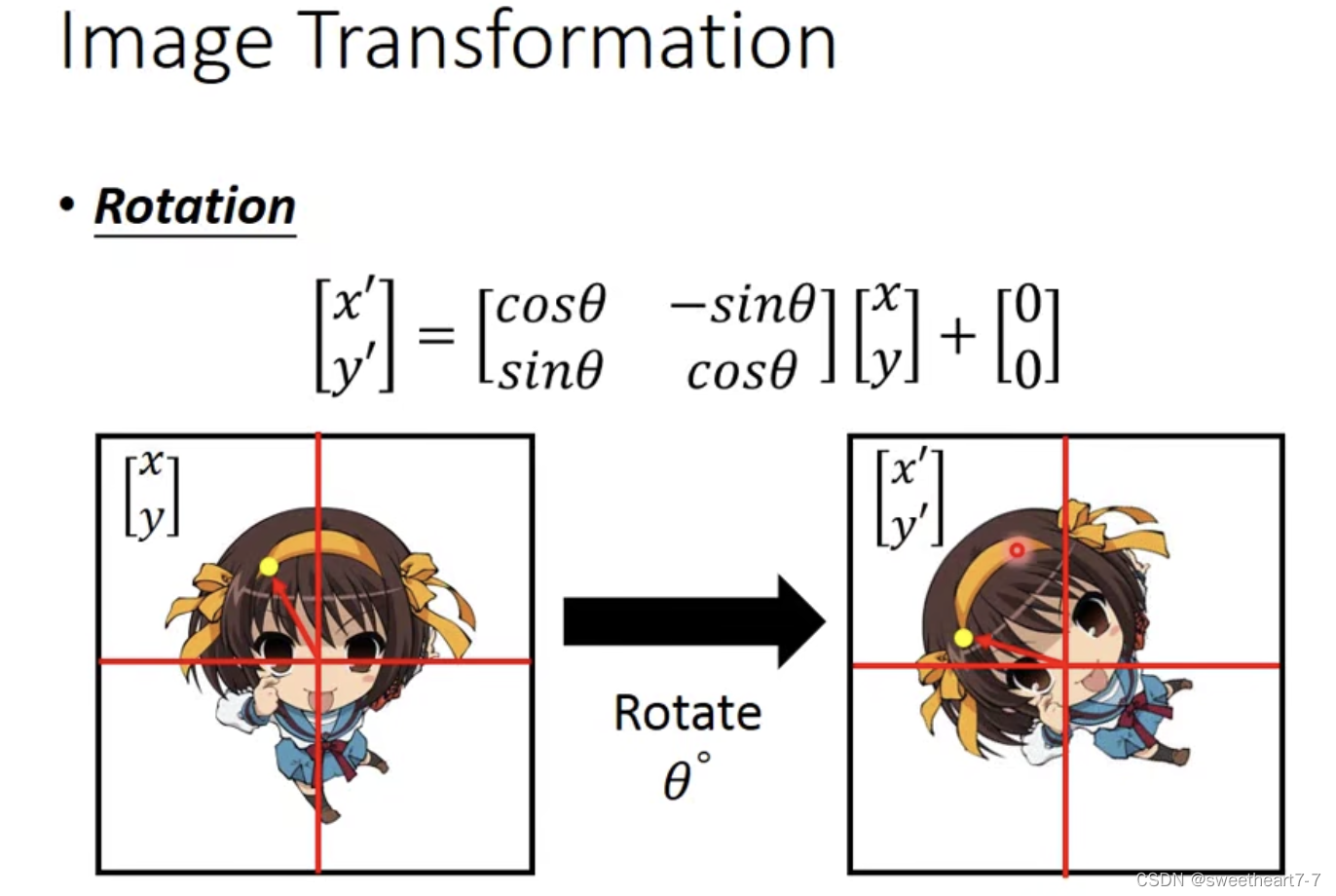
旋转