分析内存泄露的一般步骤
如果发现 Java 应用程序占用的内存出现了泄露的迹象,那么我们一般采用下面的步骤分析:
-
把 Java 应用程序使用的 heap dump 下来
-
使用 Java heap 分析工具,找出内存占用超出预期(一般是因为数量太多)的嫌疑对象
-
必要时,需要分析嫌疑对象和其他对象的引用关系。
-
查看程序的源代码,找出嫌疑对象数量过多的原因。
dump heap
如果 Java 应用程序出现了内存泄露,千万别着急着把应用杀掉,而是要保存现场。如果是互联网应用,可以把流量切到其他服务器。保存现场的目的就是为了把 运行中 JVM 的 heap dump 下来。JDK 自带的 jmap 工具,可以做这件事情。它的执行方法是:
jmap -dump:format=b,file=heap.bin <pid>
format=b 的含义是,dump 出来的文件时二进制格式。
file-heap.bin 的含义是,dump 出来的文件名是 heap.bin。
<pid>就是 JVM 的进程号。
(在 linux 下)先执行 ps aux | grep java,找到 JVM 的 pid;然后再执行 jmap -dump:format=b,file=heap.bin <pid>,得到 heap dump 文件。
analyze heap
将二进制的 heap dump 文件解析成 human-readable 的信息,自然是需要专业工具的帮助,这里推荐 Memory Analyzer 。
Memory Analyzer,简称 MAT,是 Eclipse 基金会的开源项目,由 SAP 和 IBM 捐助。巨头公司出品的软件还是很中用的,MAT 可以分析包含数亿级对 象的 heap、快速计算每个对象占用的内存大小、对象之间的引用关系、自动检测内存泄露的嫌疑对象,功能强大,而且界面友好易用。
MAT 的界面基于 Eclipse 开发,以两种形式发布:Eclipse 插件和 Eclipe RCP。MAT 的分析结果以图片和报表的形式提供,一目了然。总之个人还是非常喜欢这个工具的。下面先贴两张官方的 screenshots:
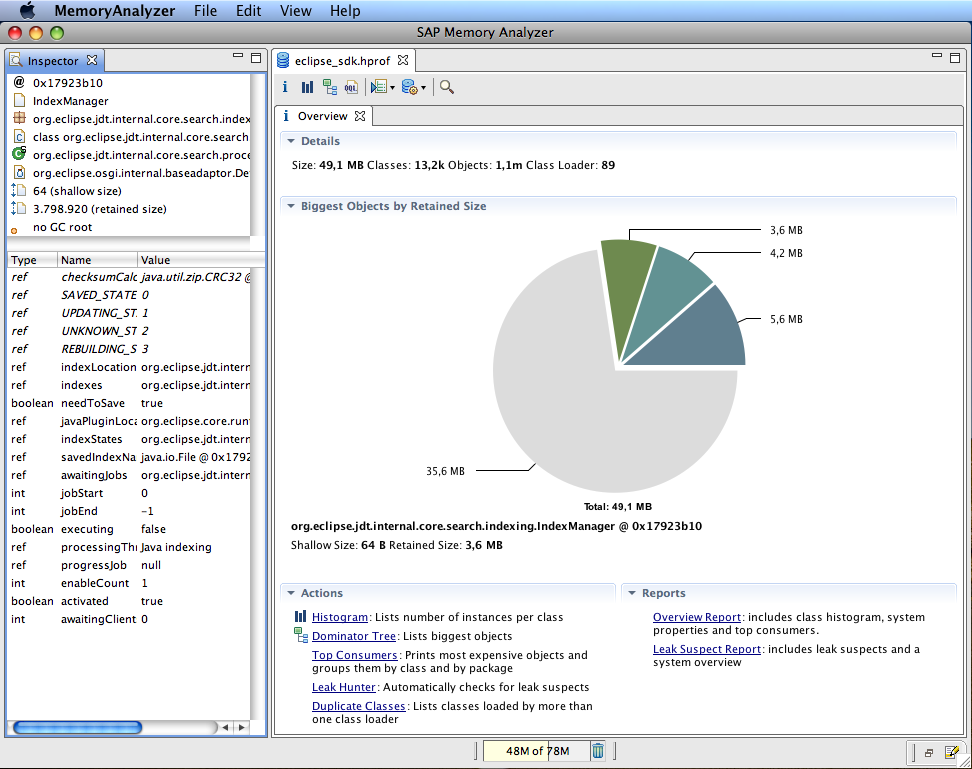
言归正传,我用 MAT 打开了 heap.bin,很容易看出,char[]的数量出其意料的多,占用 90%以上的内存 。一般来说,char[]在 JVM 确实会占用很多内存,数量也非常多,因为 String 对象以 char[]作为内部存储。但是这次的 char[]太贪婪 了,仔细一观察,发现有数万计的 char[],每个都占用数百 K 的内存 。这个现象说明,Java 程序保存了数以万计的大 String 对象 。结合程序的逻辑,这个是不应该的,肯定在某个地方出了问题。
顺藤摸瓜
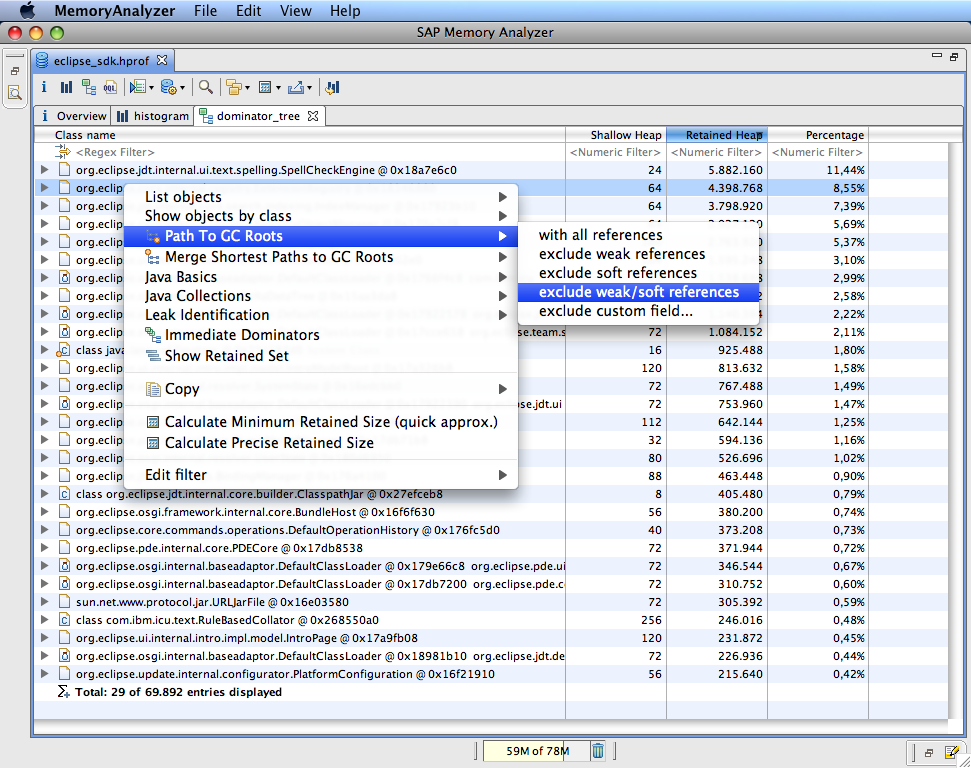
在可疑的 char[]中,任意挑了一个,使用 Path To GC Root 功能,找到该 char[]的引用路径,发现 String 对象是被一个 HashMap 中引用的 。这个也是意料中的事情,Java 的内存泄露多半是因为对象被遗留在全局的 HashMap 中得不到释放。不过,该 HashMap 被用作一个缓存,设置了缓 存条目的阈值,导达到阈值后会自动淘汰。从这个逻辑分析,应该不会出现内存泄露的。虽然缓存中的 String 对象已经达到数万计,但仍然没有达到预先设置 的阈值(阈值设置地比较大,因为当时预估 String 对象都比较小)。
但是,另一个问题引起了我的注意:为什么缓存的 String 对象如此巨大?内部 char[]的长度达数百 K。虽然缓存中的 String 对象数量还没有达到阈值,但是 String 对象大小远远超出了我们的预期,最终导致内存被大量消耗,形成内存泄露的迹象(准确说应该是内存消 耗过多) 。
就这个问题进一步顺藤摸瓜,看看 String 大对象是如何被放到 HashMap 中的。通过查看程序的源代码,我发现,确实有 String 大对象,不 过并没有把 String 大对象放到 HashMap 中,而是把 String 大对象进行 split(调用 String.split 方法),然后将 split 出 来的 String 小对象放到 HashMap 中 了。
这就奇怪了,放到 HashMap 中明明是 split 之后的 String 小对象,怎么会占用那么大空间呢?难道是 String 类的 split 方法有问题?
查看代码
带着上述疑问,我查阅了 Sun JDK6 中 String 类的代码,主要是是 split 方法的实现:
public
String[] split(String regex, int limit) {
return Pattern.compile(regex).split(this, limit);
}
可以看出,Stirng.split 方法调用了 Pattern.split 方法。继续看 Pattern.split 方法的代码:
public
String[] split(CharSequence input, int limit) {
int index = 0;
boolean matchLimited = limit > 0;
ArrayList<String> matchList = new
ArrayList<String>();
Matcher m = matcher(input);
// Add segments before each match found
while(m.find()) {
if (!matchLimited || matchList.size() < limit - 1) {
String match = input.subSequence(index,
m.start()).toString();
matchList.add(match);
index = m.end();
} else if (matchList.size() == limit - 1) { // last one
String match = input.subSequence(index,
input.length()).toString();
matchList.add(match);
index = m.end();
}
}
// If no match was found, return this
if (index == 0)
return new String[] {input.toString()};
// Add remaining segment
if (!matchLimited || matchList.size() < limit)
matchList.add(input.subSequence(index,
input.length()).toString());
// Construct result
int resultSize = matchList.size();
if (limit == 0)
while (resultSize > 0 &&
matchList.get(resultSize-1).equals(""))
resultSize--;
String[] result = new String[resultSize];
return matchList.subList(0, resultSize).toArray(result);
}
注意看第9行:Stirng match = input.subSequence(intdex, m.start()).toString();
这里的 match 就是 split 出来的 String 小对象,它其实是 String 大对象 subSequence 的结果。继续看 String.subSequence 的代码:
public
CharSequence subSequence(int beginIndex, int endIndex) {
return this.substring(beginIndex, endIndex);
}
String.subSequence有调用了String.subString,继续看:
public String
substring(int beginIndex, int endIndex) {
if (beginIndex < 0) {
throw new StringIndexOutOfBoundsException(beginIndex);
}
if (endIndex > count) {
throw new StringIndexOutOfBoundsException(endIndex);
}
if (beginIndex > endIndex) {
throw new StringIndexOutOfBoundsException(endIndex - beginIndex);
}
return ((beginIndex == 0) && (endIndex == count)) ? this :
new String(offset + beginIndex, endIndex - beginIndex, value);
}
看第 11、12 行,我们终于看出眉目,如果 subString 的内容就是完整的原字符串,那么返回原 String 对象;否则,就会创建一个新的 String 对象,但是这个 String 对象貌似使用了原 String 对象的 char[]。我们通过 String 的构造函数确认这一点:
// Package
private constructor which shares value array for speed.
String(int offset, int count, char value[]) {
this.value = value;
this.offset = offset;
this.count = count;
}
为了避免内存拷贝、加快速度,Sun JDK 直接复用了原 String 对象的 char[],偏移量和长度来标识不同的字符串内容。也就是说,subString 出的来 String 小对象 仍然会指向原 String 大对象的 char[],split 也是同样的情况 。这就解释了,为什么 HashMap 中 String 对象的 char[]都那么大。
原因解释
其实上一节已经分析出了原因,这一节再整理一下:
程序从每个请求中得到一个 String 大对象,该对象内部 char[]的长度达数百 K。
程序对 String 大对象做 split,将 split 得到的 String 小对象放到 HashMap 中,用作缓存。
Sun JDK6 对 String.split 方法做了优化,split 出来的 Stirng 对象直接使用原 String 对象的 char[]
HashMap 中的每个 String 对象其实都指向了一个巨大的 char[]
HashMap 的上限是万级的,因此被缓存的 Sting 对象的总大小=万*百 K=G 级。
G 级的内存被缓存占用了,大量的内存被浪费,造成内存泄露的迹象。
解决方案
原因找到了,解决方案也就有了。split 是要用的,但是我们不要把 split 出来的 String 对象直接放到 HashMap 中,而是调用一下 String 的拷贝构造函数 String(String original),这个构造函数是安全的,具体可以看代码:
/**
* Initializes a newly created {@code String} object so that it
represents
* the same sequence of characters as the argument; in other words,
the
* newly created string is a copy of the argument string. Unless an
* explicit copy of {@code original} is needed, use of this
constructor is
* unnecessary since Strings are immutable.
*
* @param original
* A {@code String}
*/
public String(String original) {
int size = original.count;
char[] originalValue = original.value;
char[] v;
if (originalValue.length > size) {
// The array representing the String is bigger than the new
// String itself. Perhaps this constructor is being called
// in order to trim the baggage, so make a copy of the array.
int off = original.offset;
v = Arrays.copyOfRange(originalValue, off, off+size);
} else {
// The array representing the String is the same
// size as the String, so no point in making a copy.
v = originalValue;
}
this.offset = 0;
this.count = size;
this.value = v;
}
只是,new String(string)的代码很怪异,囧。或许,subString 和 split 应该提供一个选项,让程序员控制是否复用 String 对象的 char[]。
是否 Bug
虽然,subString 和 split 的实现造成了现在的问题,但是这能否算 String 类的 bug 呢?个人觉得不好说。因为这样的优化是比较合理 的,subString 和 spit 的结果肯定是原字符串的连续子序列。只能说,String 不仅仅是一个核心类,它对于 JVM 来说是与原始类型同等重要的 类型。
JDK 实现对 String 做各种可能的优化都是可以理解的。但是优化带来了忧患,我们程序员足够了解他们,才能用好他们。
一些补充
有个地方我没有说清楚。
我的程序是一个 Web 程序,每次接受请求,就会创建一个大的 String 对象,然后对该 String 对象进行 split,最后 split 之后的 String 对象放到全局缓存中。如果接收了 5W 个请求,那么就会有 5W 个大 String 对象。这 5W 个大 String 对象都被存储在全局缓存中,因此会造成内存泄漏。我原以为缓存的是 5W 个小 String,结果都是大 String。
有同学后续建议用"java.io.StreamTokenizer"来解决本文的问题。确实是终极解决方案,比我上面提到的“new String()”,要好很多很多。

小伙伴们有兴趣想了解内容和更多相关学习资料的请点赞收藏+评论转发+关注我,后面会有很多干货。如果在阅读过程中有疑问,请留言讨论.
出处:https://club.perfma.com/article/1815828