一、ELK与EFK架构
日志主要包括系统日志、应用程序日志和安全日志。系统运维和开发人员可以通过日志了解服务器软硬件信息、检查配置过程中的错误及错误发生的原因。经常分析日志可以了解服务器的负荷,性能安全性,从而及时采取措施纠正错误。
通常,日志被分散的储存不同的设备上。如果你管理数十上百台服务器,你还在使用依次登录每台机器的传统方法查阅日志。这样是不是感觉很繁琐和效率低下。当务之急我们使用集中化的日志管理,例如:开源的syslog,将所有服务器上的日志收集汇总。
集中化管理日志后,日志的统计和检索又成为一件比较麻烦的事情,一般我们使用grep、awk和wc等Linux命令能实现检索和统计,但是对于要求更高的查询、排序和统计等要求和庞大的机器数量再去使用这些方法就比较的麻烦了。
那你们想过这种方式的问题吗?
1. 日志量太大如何归档、文本搜索太慢怎么办、如何多维度查询。
2. 应用太多,面临数十上百台应用时你该怎么办。
3. 随意登录服务器查询log对系统的稳定性及安全性肯定有影响。
4. 如果使用人员对Linux不太熟练那面对庞大的日志简直要命。
开源实时日志分析ELK平台能够完美的解决我们上述的问题。
ELK又能给我们解决哪些问题呢?
1. 日志统一收集,管理,访问。查找问题方便安全。
2. 使用简单,可以大大提高定位问题的效率。
3. 可以对收集起来的log进行分析。
4. 能够提供错误报告,监控机制。
1、核心组成
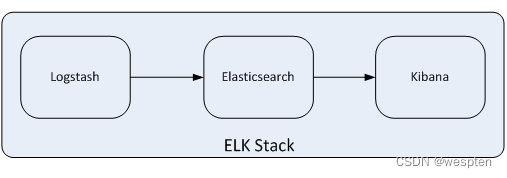
ELK是一个应用套件,由Elasticsearch、Logstash和Kibana三部分组件组成,简称ELK;它是一套开源免费、功能强大的日志分析管理系统。ELK可以将我们的系统日志、网站日志、应用系统日志等各种日志进行收集、过滤、清洗,然后进行集中存放并可用于实时检索、分析。
这三款软件都是开源软件,通常是配合使用,而且又先后归于Elastic.co公司名下,故又被简称为ELK Stack。
下图是ELK Stack的基础组成:
2、ElasticSearch简介
ElasticSearch是一个实时的分布式搜索和分析引擎,它可以用于全文搜索,结构化搜索以及分析,有点像hdfs。采用Java语言编写,可以实现数据内容存储、检索、排序、查询、报表统计、生成等功能,日志的分析以及存储全部由ElasticSearch完成。
目前,最新的版本是Elasticsearch 6.3.2,它的主要特点如下:
1)实时搜索,实时分析;
2)分布式架构、实时文件存储,并将每一个字段都编入索引;
3) 文档导向,所有的对象全部是文档;
4) 高可用性,易扩展,支持集群(Cluster)、分片和复制(Shards和Replicas);
5) 接口友好,支持JSON;
高扩展性体现在拓展非常简单,新的节点,基本无需做复杂配置自动发现节点。高可用性呢,因为这个社区是分布式的,而且是一个实时搜索平台,支持PB级的大数据搜索能力。从一个文档到这个文档被搜索到呢,只有略微的延迟,所以说他的实时性非常高。
Elasticsearch支持集群架构,典型的集群架构如下图所示:
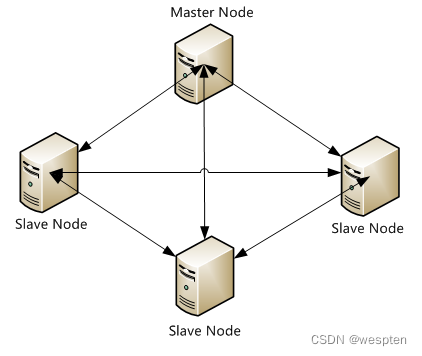
从图中可以看出,Elasticsearch集群中有Master Node和Slave Node两种角色,其实还有一种角色Client Node。
3、Logstash简介
Logstash是一款轻量级的、开源的日志收集处理框架,它可以方便的把分散的、多样化的日志搜集起来,日志内容包括内核日志、系统日志、安全日志、应用程序(Apache、Nginx、MYSQL、Redis、Tomcat)日志等,并进行自定义过滤分析处理,然后传输到指定的位置,比如某个服务器、文件,或者通过内置的ElasticSearch插件解析后输出到ES服务器中。
Logstash采用JRuby语言编写,目前最新的版本是Logstash 6.3.2,它的主要特点如下:
Logstash的理念很简单,从功能上来讲,它只做三件事情:
1)input:数据收集;
2)filter:数据加工,如过滤,改写等;
3)output:数据输出;
别看它只做三件事,但通过组合输入和输出,可以变幻出多种架构实现多种需求。Logstash内部运行逻辑如下图所示:
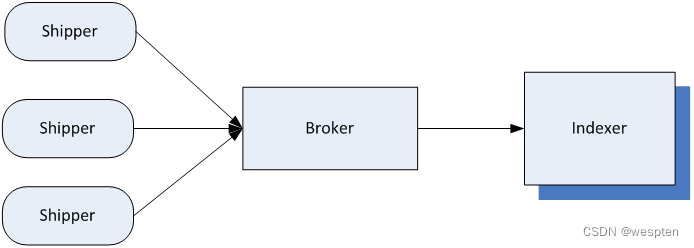
其中,每个部分含义如下:
1)Shipper:主要用来收集日志数据,负责监控本地日志文件的变化,及时把日志文件的最新内容收集起来,然后经过加工、过滤,输出到Broker。
2)Broker:相当于日志Hub,用来连接多个Shipper和多个Indexer。
3)Indexer:从Broker读取文本,经过加工、过滤,输出到指定的介质(可以是文件、网络、elasticsearch等)中。
Redis服务器是logstash官方推荐的broker,这个broker起数据缓存的作用,通过这个缓存器可以提高Logstash shipper发送日志到Logstash indexer的速度,同时避免由于突然断电等导致的数据丢失。可以实现broker功能的还有很多软件,例如kafka等。
这里需要说明的是,在实际应用中,LogStash自身并没有什么角色,只是根据不同的功能、不同的配置给出不同的称呼而已,无论是Shipper还是Indexer,始终只做前面提到的三件事。
这里需要重点掌握的是logstash中Shipper和Indexer的作用,因为这两个部分是logstash功能的核心。
4、Kibana简介
Kibana是一个开源的数据分析可视化平台,这也解决了用mysql存储带来了难以可视化的问题。主使用Kibana可以为Logstash和ElasticSearch提供的日志数据进行高效的搜索、可视化汇总和多维度分析,还可以与Elasticsearch搜索引擎之中的数据进行交互。
它提供一套WEB UI界面,可以快速创建动态仪表板,实时监控ElasticSearch的数据状态与更改,方便用户和管理人员对ES的数据进行可视化操作、配置、数据分析、统计(如果没有WEB界面,只能靠命令行操作)。
5、ELK使用场景
通过ELK组件可以对Spark作业运行状态监控,搜集Spark环境下运行的日志。经过筛选、过滤并存储可用信息,从而完成对Spark作业运行和完成状态进行监控,实时掌握集群状态,了解作业完成情况,并生成报表,方便运维人员监控和查看。
也可以通过ELK组件对系统资源状态监控,通过各类日志搜集,分析,过滤,存储并通过Kibana展现给用户,供用户实时监控系统资源、节点状态、磁盘、CPU、MEM,以及错误、警告信息等。

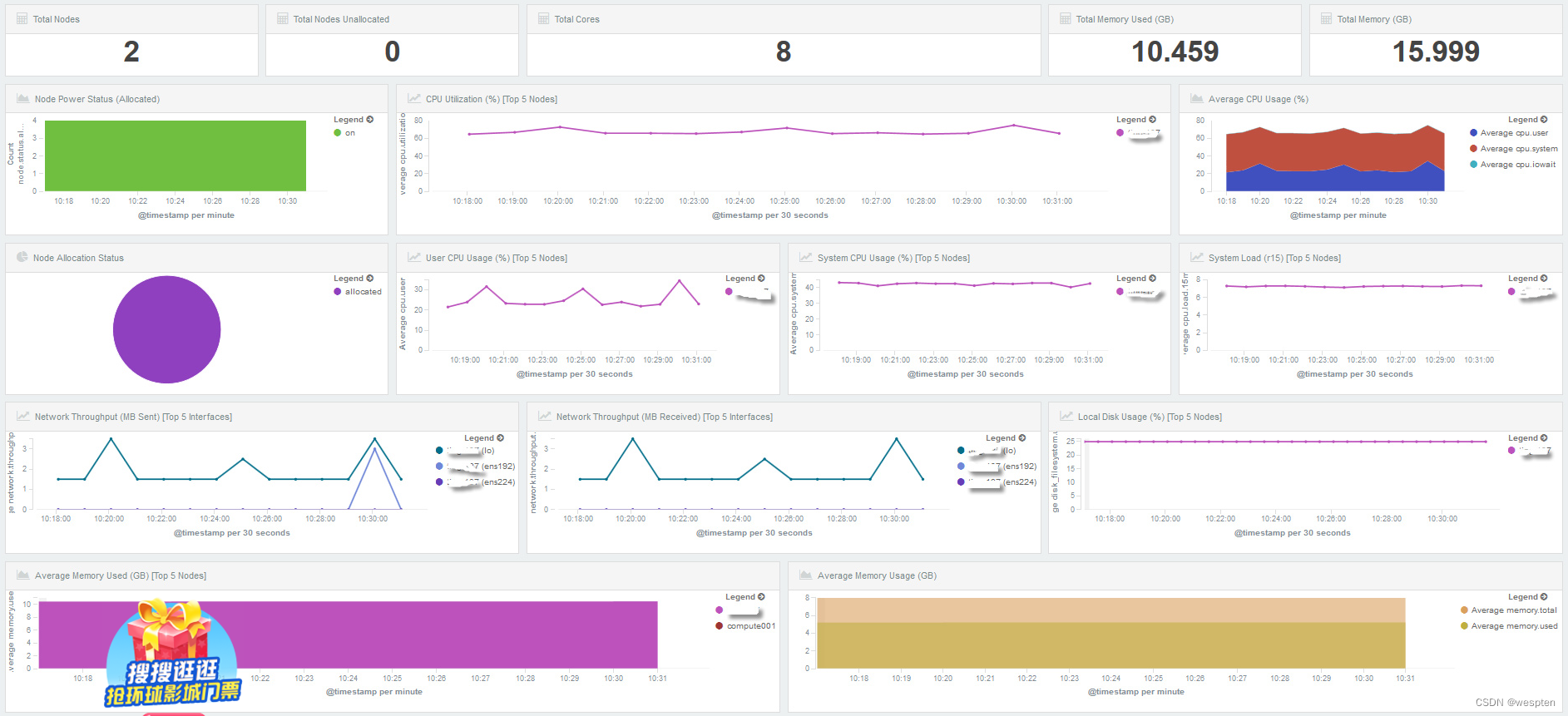
也通过ELK组件对系统负载状态监控:

还可以通过ELK组件对系统日志管理和故障排查。用户可根据故障发生时间段集中查询相关日志,可通过搜索、筛选、过滤等功能,快速定位问题,从而排查故障。另外,通过对各个应用组件的日志过滤,可快速列举出各个应用对应节点上的Error或Warning日志,从而对故障排查或者对发现产品bug提供快捷途径。
6、ELK工作流程
数据来源可以是各式各样的日志,Logstash配置文件有三个主要模块:input()输入或者说收集数据,定义数据来源;filter()对数据进行过滤,分析等操作;output()输出。
数据源搜集到后,然后通过filter过滤形成固定的数据格式。目前支持过滤的类JSON、grep、grok、geoip等,最后output到数据库,比如Redis、Kafka或者直接传送给Elasticsearch,当数据被存储于Elasticsearch之后,用户可以使用Elasticsearch所提供API来检索信息数据了.
如果通过REST API执行CURL GET请求搜索指定数据。用户也可以使用Kibana进行可视化的数据浏览。另外Kibana有时间过滤功能,运维人员可对某一时间段内数据查询并查看报表,方便快捷。
ELK工作流程图:

一般都是在需要收集日志的所有服务上部署logstash,作为logstash shipper用于监控并收集、过滤日志,接着,将过滤后的日志发送给Broker,然后,Logstash Indexer将存放在Broker中的数据再写入Elasticsearch,Elasticsearch对这些数据创建索引,最后由Kibana对其进行各种分析并以图表的形式展示。
有些时候,如果收集的日志量较大,为了保证日志收集的性能和数据的完整性,logstash shipper和logstash indexer之间的缓冲器(Broker)也经常采用kafka来实现。
在这个图中,要重点掌握的是ELK架构的数据流向,以及logstash、Elasticsearch和Kibana组合实现的功能细节。
ELK有两种安装方式:
(1) 集成环境:Logstash有一个集成包,里面包括了其全套的三个组件;也就是安装一个集成包。
(2) 独立环境:三个组件分别单独安装、运行、各司其职。(比较常用)
7、简单的ELK应用架构

此架构主要是将Logstash部署在各个节点上搜集相关日志、数据,并经过分析、过滤后发送给远端服务器上的Elasticsearch进行存储。Elasticsearch再将数据以分片的形式压缩存储,并提供多种API供用户查询、操作。用户可以通过Kibana Web直观的对日志进行查询,并根据需求生成数据报表。
此架构的优点是搭建简单,易于上手。缺点是Logstash消耗系统资源比较大,运行时占用CPU和内存资源较高。另外,由于没有消息队列缓存,可能存在数据丢失的风险。此架构建议供初学者或数据量小的环境使用。
8、典型ELK架构
引入Kafka消息队列:

引入Redis消息队列:
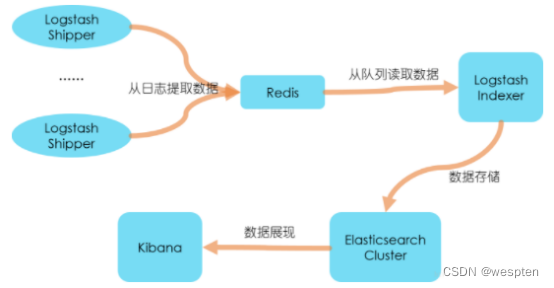
此架构主要特点是引入了消息队列机制,位于各个节点上的Logstash Agent(一级Logstash,主要用来传输数据)先将数据传递给消息队列(常见的有Kafka、Redis等),接着,Logstash server(二级Logstash,主要用来拉取消息队列数据,过滤并分析数据)将格式化的数据传递给Elasticsearch进行存储。最后,由Kibana将日志和数据呈现给用户。由于引入了Kafka(或者Redis)缓存机制,即使远端Logstash server因故障停止运行,数据也不会丢失,因为数据已经被存储下来了。
这种架构适合于较大集群、数据量一般的应用环境,但由于二级Logstash要分析处理大量数据,同时Elasticsearch也要存储和索引大量数据,因此它们的负荷会比较重,解决的方法是将它们配置为集群模式,以分担负载。
此架构的优点在于引入了消息队列机制,均衡了网络传输,从而降低了网络闭塞尤其是丢失数据的可能性,但依然存在Logstash占用系统资源过多的问题,在海量数据应用场景下,可能会出现性能瓶颈。
9、EFK集群架构
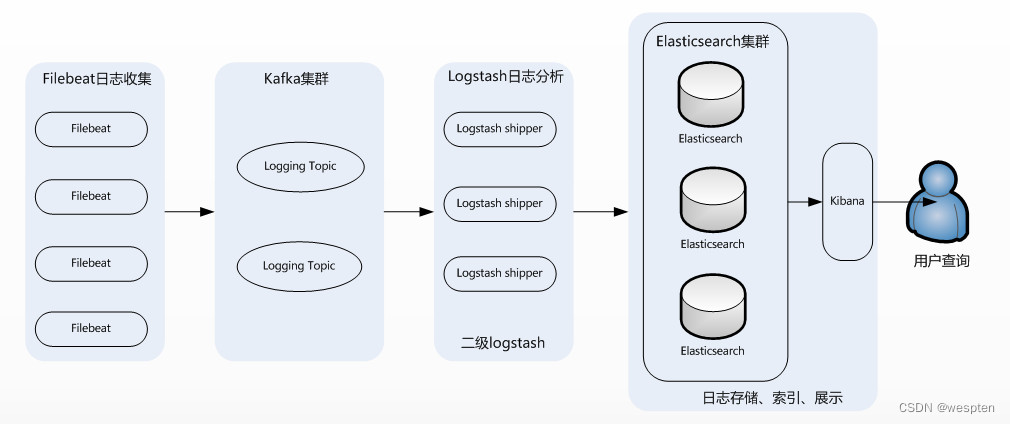
这个架构是在上面第二个架构基础上改进而来的,主要是将前端收集数据的Logstash Agent换成了filebeat,消息队列使用了kafka集群,然后将Logstash和Elasticsearch都通过集群模式进行构建,此架构适合大型集群、海量数据的业务场景,它通过将前端Logstash Agent替换成filebeat,有效降低了收集日志对业务系统资源的消耗。
经测试得出,相比Logstash,Logstash-forwarder所占用系统CPU和MEM几乎可以忽略不计。另外,Logstash-forwarder和Logstash间的通信是通过SSL加密传输,起到了安全保障。如果是较大集群,用户亦可以如结构三那样配置logstash集群和Elasticsearch集群,引入High Available机制,提高数据传输和存储安全。更主要的配置多个Elasticsearch服务,有助于搜索和数据存储效率。
同时,消息队列使用kafka集群架构,有效保障了收集数据的安全性和稳定性,而后端Logstash和Elasticsearch均采用集群模式搭建,从整体上提高了ELK系统的高效性、扩展性和吞吐量。
但在此种架构下发现Logstash-forwarder和Logstash间通信必须由SSL加密传输,这样便有了一定的限制性。
10、Beat+ELK架构
第四种架构将Logstash-forwarder替换为Beats。经测试,Beats满负荷状态所耗系统资源和Logstash-forwarder相当,但其扩展性和灵活性有很大提高。
Beats platform目前包含有Packagebeat、Topbeat和Filebeat、Metricbeat等产品,均为Apache 2.0 License,用户可根据需要进行二次开发。

这种架构原理基于第三种架构,但是更灵活,扩展性更强。同时可配置Logstash 和Elasticsearch 集群用于支持大集群系统的运维日志数据监控和查询。
不管采用上面哪种ELK架构,都包含了其核心组件,即:Logstash、Elasticsearch 和Kibana。当然这三个组件并非不能被替换,只是就性能和功能性而言,这三个组件已经配合的很完美,是密不可分的。各系统运维中究竟该采用哪种架构,可根据现实情况和架构优劣而定。
11、ELK在大数据运维系统中的应用
在海量日志系统的运维中,以下几个方面是必不可少的:
-
分布式日志数据集中式查询和管理
-
系统监控,包含系统硬件和应用各个组件的监控
-
故障排查
-
安全信息和事件管理
-
报表功能
ELK组件各个功能模块如下图所示,它运行于分布式系统之上,通过搜集、过滤、传输、储存,对海量系统和组件日志进行集中管理和准实时搜索、分析,使用搜索、监控、事件消息和报表等简单易用的功能,帮助运维人员进行线上业务的准实时监控、业务异常时及时定位原因、排除故障、程序研发时跟踪分析Bug、业务趋势分析、安全与合规审计,深度挖掘日志的大数据价值。同时Elasticsearch提供多种API(REST JAVA PYTHON等API)供用户扩展开发,以满足其不同需求。

汇总ELK组件在大数据运维系统中,主要可解决的问题如下:
-
日志查询,问题排查,上线检查
-
服务器监控,应用监控,错误报警,Bug管理
-
性能分析,用户行为分析,安全漏洞分析,时间管理
综上,ELK组件在大数据运维中的应用是一套必不可少的且方便、易用的开源解决方案。
二、Zookeeper架构
1、ZooKeeper简介
在介绍ZooKeeper之前,先来介绍一下分布式协调技术,所谓分布式协调技术主要是用来解决分布式环境当中多个进程之间的同步控制,让他们有序的去访问某种共享资源,防止造成资源竞争(脑裂)的后果。

这里首先介绍下什么是分布式系统,所谓分布式系统就是在不同地域分布的多个服务器,共同组成的一个应用系统来为用户提供服务,在分布式系统中最重要的是进程的调度,这里假设有一个分布在三个地域的服务器组成的一个应用系统,在第一台机器上挂载了一个资源,然后这三个地域分布的应用进程都要竞争这个资源,但我们又不希望多个进程同时进行访问,这个时候就需要一个协调器,来让它们有序的来访问这个资源。
这个协调器就是分布式系统中经常提到的那个“锁”。
例如"进程1"在使用该资源的时候,会先去获得这把锁,"进程1"获得锁以后会对该资源保持独占,此时其它进程就无法访问该资源,"进程1"在用完该资源以后会将该锁释放掉,以便让其它进程来获得锁。由此可见,通过这个“锁”机制,就可以保证分布式系统中多个进程能够有序的访问该共享资源。这里把这个分布式环境下的这个“锁”叫作分布式锁。这个分布式锁就是分布式协调技术实现的核心内容。
综上所述,ZooKeeper是一种为分布式应用所设计的高可用、高性能的开源协调服务,它提供了一项基本服务:分布式锁服务,同时,也提供了数据的维护和管理机制,如:统一命名服务、状态同步服务、集群管理、分布式消息队列、分布式应用配置项的管理等等。
2、ZooKeeper应用举例
这里以ZooKeeper提供的基本服务分布式锁为例进行介绍。在分布式锁服务中,有一种最典型应用场景,就是通过对集群进行Master角色的选举,来解决分布式系统中的单点故障问题。所谓单点故障,就是在一个主从的分布式系统中,主节点负责任务调度分发,从节点负责任务的处理,而当主节点发生故障时,整个应用系统也就瘫痪了,那么这种故障就称为单点故障。
解决单点故障,传统的方式是采用一个备用节点,这个备用节点定期向主节点发送ping包,主节点收到ping包以后向备用节点发送回复Ack信息,当备用节点收到回复的时候就会认为当前主节点运行正常,让它继续提供服务。而当主节点故障时,备用节点就无法收到回复信息了,此时,备用节点就认为主节点宕机,然后接替它成为新的主节点继续提供服务。
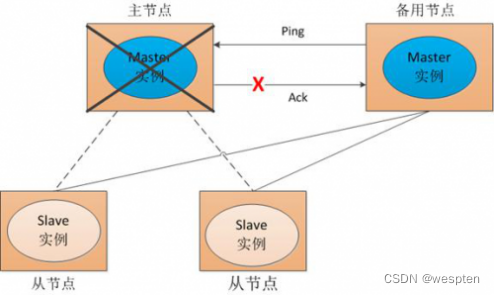
这种传统解决单点故障的方法,虽然在一定程度上解决了问题,但是有一个隐患,就是网络问题,可能会存在这样一种情况:主节点并没有出现故障,只是在回复ack响应的时候网络发生了故障,这样备用节点就无法收到回复,那么它就会认为主节点出现了故障。
接着,备用节点将接管主节点的服务,并成为新的主节点,此时,分布式系统中就出现了两个主节点(双Master节点)的情况,双Master节点的出现,会导致分布式系统的服务发生混乱。这样的话,整个分布式系统将变得不可用。为了防止出现这种情况,就需要引入ZooKeeper来解决这种问题。

3、ZooKeeper工作原理
下面通过三种情形,介绍下Zookeeper是如何进行工作的。
1) Master启动
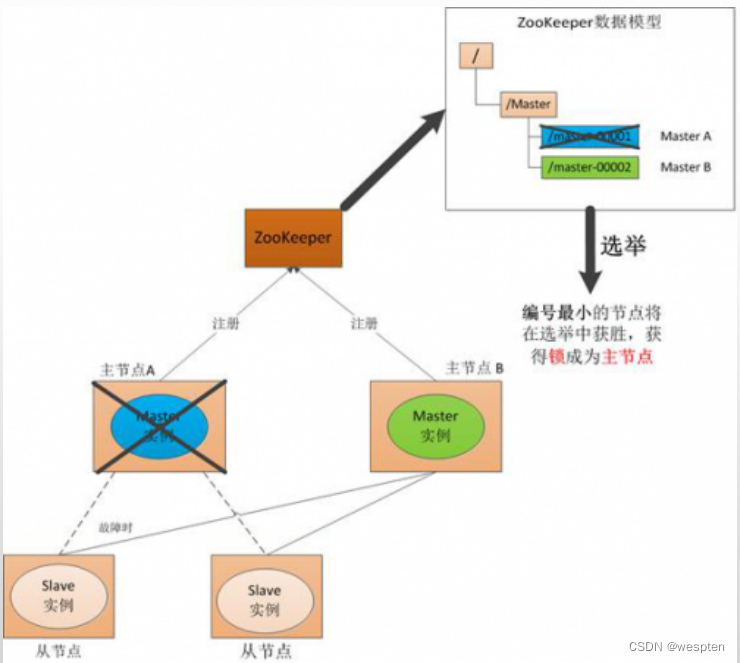
在分布式系统中引入Zookeeper以后,就可以配置多个主节点,这里以配置两个主节点为例,假定它们是"主节点A"和"主节点B",当两个主节点都启动后,它们都会向ZooKeeper中注册节点信息。
我们假设"主节点A"锁注册的节点信息是"master00001","主节点B"注册的节点信息是"master00002",注册完以后会进行选举,选举有多种算法,这里以编号最小作为选举算法,那么编号最小的节点将在选举中获胜并获得锁成为主节点,也就是"主节点A"将会获得锁成为主节点,然后"主节点B"将被阻塞成为一个备用节点。这样,通过这种方式Zookeeper就完成了对两个Master进程的调度。完成了主、备节点的分配和协作。

2) Master故障
如果"主节点A"发生了故障,这时候它在ZooKeeper所注册的节点信息会被自动删除,而ZooKeeper会自动感知节点的变化,发现"主节点A"故障后,会再次发出选举,这时候"主节点B"将在选举中获胜,替代"主节点A"成为新的主节点,这样就完成了主、被节点的重新选举。
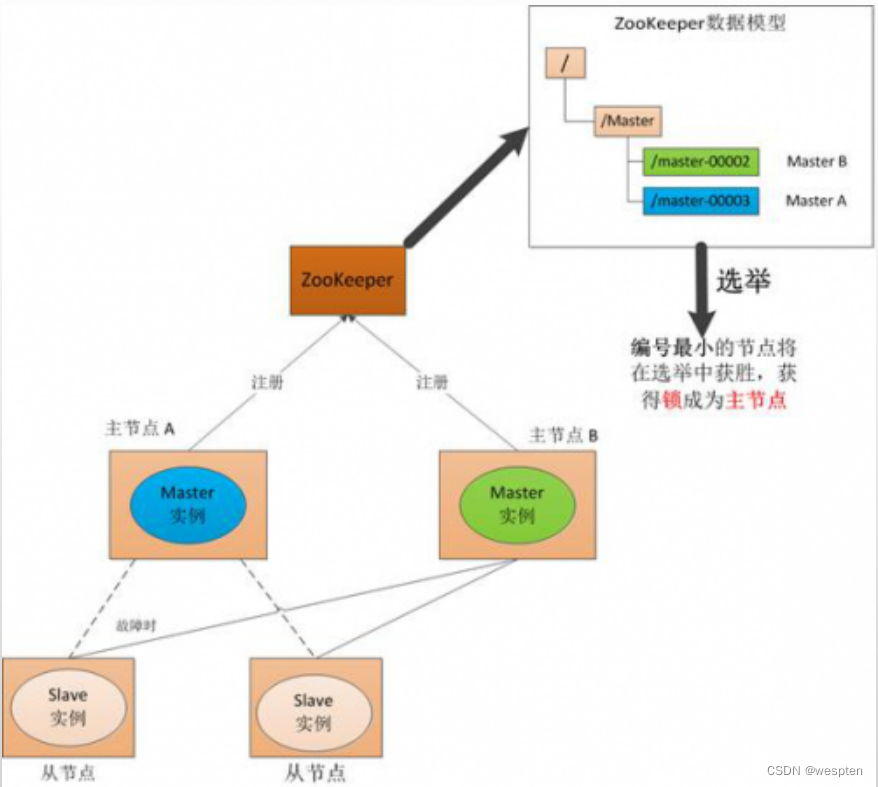
3)Master恢复
如果主节点恢复了,它会再次向ZooKeeper注册自身的节点信息,只不过这时候它注册的节点信息将会变成"master00003",而不是原来的信息。ZooKeeper会感知节点的变化再次发动选举,这时候"主节点B"在选举中会再次获胜继续担任"主节点","主节点A"会担任备用节点。
Zookeeper就是通过这样的协调、调度机制如此反复的对集群进行管理和状态同步的。
4、Zookeeper集群架构
Zookeeper一般是通过集群架构来提供服务的,下图是Zookeeper的基本架构图:
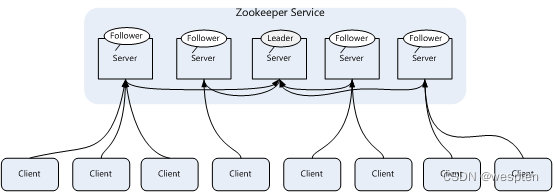
Zookeeper集群主要角色有Server和client,其中,Server又分为Leader、Follower和Observer三个角色,每个角色的含义如下:
1. Leader:领导者角色,主要负责投票的发起和决议,以及更新系统状态。
2. Follower:跟随者角色,用于接收客户端的请求并返回结果给客户端,在选举过程中参与投票。
3. Observer:观察者角色,用户接收客户端的请求,并将写请求转发给leader,同时同步leader状态,但不参与投票。 Observer目的是扩展系统,提高伸缩性。
4. Client:客户端角色,用于向Zookeeper发起请求。
Zookeeper集群中每个Server在内存中存储了一份数据,在Zookeeper启动时,将从实例中选举一个Server作为leader,Leader负责处理数据更新等操作,当且仅当大多数Server在内存中成功修改数据,才认为数据修改成功。
Zookeeper写的流程为:客户端Client首先和一个Server或者Observe通信,发起写请求,然后Server将写请求转发给Leader,Leader再将写请求转发给其它Server,其它Server在接收到写请求后写入数据并响应Leader,Leader在接收到大多数写成功回应后,认为数据写成功,最后响应Client,完成一次写操作过程。
三、Kafka架构
1、kafka基本概念
Kafka是一种高吞吐量的分布式发布/订阅消息系统,这是官方对kafka的定义,kafka是Apache组织下的一个开源系统,它的最大的特性就是可以实时的处理大量数据以满足各种需求场景:比如基于hadoop平台的数据分析、低时延的实时系统、storm/spark流式处理引擎等。kafka现在它已被多家大型公司作为多种类型的数据管道和消息系统使用。
2、kafka角色术语
在介绍架构之前,先了解下kafka中一些核心概念和各种角色。
Broker:Kafka集群包含一个或多个服务器,每个服务器被称为broker。
Topic:每条发布到Kafka集群的消息都有一个分类,这个类别被称为Topic(主题)。
Producer:指消息的生产者,负责发布消息到Kafka broker。
Consumer :指消息的消费者,从Kafka broker拉取数据,并消费这些已发布的消息。
Partition:Parition是物理上的概念,每个Topic包含一个或多个Partition,每个partition都是一个有序的队列。partition 中的每条消息都会被分配一个有序的id(称为offset)。
Consumer Group:消费者组,可以给每个Consumer指定消费者组,若不指定消费者组,则属于默认的group。
Message:消息,通信的基本单位,每个producer可以向一个topic发布一些消息。
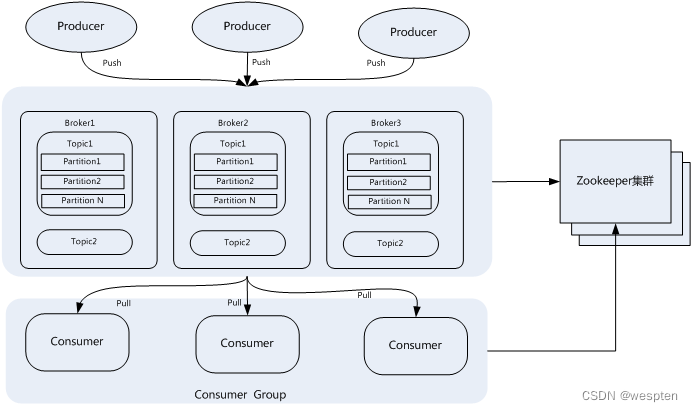
3、Kafka拓扑架构
一个典型的Kafka集群包含若干Producer,若干broker、若干Consumer Group,以及一个Zookeeper集群。Kafka通过Zookeeper管理集群配置,选举leader,以及在Consumer Group发生变化时进行rebalance。Producer使用push模式将消息发布到broker,Consumer使用pull模式从broker订阅并消费消息。
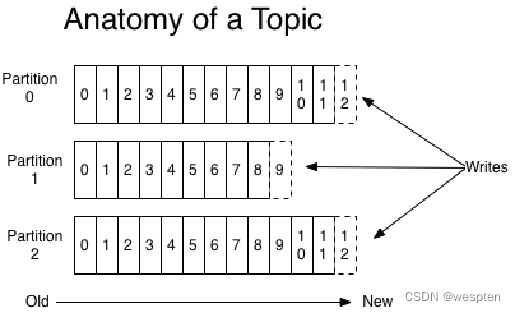
4、Topic与Partition
Kafka中的topic是以partition的形式存放的,每一个topic都可以设置它的partition数量,Partition的数量决定了组成topic的log的数量。推荐partition的数量一定要大于同时运行的consumer的数量。另外,建议partition的数量大于集群broker的数量,这样消息数据就可以均匀的分布在各个broker中。
那么,Topic为什么要设置多个Partition呢,这是因为kafka是基于文件存储的,通过配置多个partition可以将消息内容分散存储到多个broker上,这样可以避免文件尺寸达到单机磁盘的上限。
同时,将一个topic切分成任意多个partitions,可以保证消息存储、消息消费的效率,因为越多的partitions可以容纳更多的consumer,可有效提升Kafka的吞吐率。因此,将Topic切分成多个partitions的好处是可以将大量的消息分成多批数据同时写到不同节点上,将写请求分担负载到各个集群节点。
5、Kafka消息发送的机制
每当用户往某个Topic发送数据时,数据会被hash到不同的partition,这些partition位于不同的集群节点上,所以每个消息都会被记录一个offset消息号,就是offset号。消费者通过这个offset号去查询读取这个消息。
发送消息流程为:
首先获取topic的所有Patition,如果客户端不指定Patition,也没有指定Key的话,使用自增长的数字取余数的方式实现指定的Partition。这样Kafka将平均的向Partition中生产数据。如果想要控制发送的partition,则有两种方式,一种是指定partition,另一种就是根据Key自己写算法。实现其partition方法。
每一条消息被发送到broker时,会根据paritition规则选择被存储到哪一个partition。如果partition规则设置的合理,所有消息可以均匀分布到不同的partition里,这样就实现了水平扩展。同时,每条消息被append到partition中时,是顺序写入磁盘的,因此效率非常高,经验证,顺序写磁盘效率比随机写内存还要高,这是Kafka高吞吐率的一个很重要的保证。
6、Kafka消息消费机制
Kafka中的Producer和consumer采用的是push(推送)、pull(拉取)的模式,即Producer只是向broker push消息,consumer只是从broker pull消息,push和pull对于消息的生产和消费是异步进行的。pull模式的一个好处是Consumer可自主控制消费消息的速率,同时Consumer还可以自己控制消费消息的方式是批量的从broker拉取数据还是逐条消费数据。
当生产者将数据发布到topic时,消费者通过pull的方式,定期从服务器拉取数据,当然在pull数据的时候,服务器会告诉consumer可消费的消息offset。
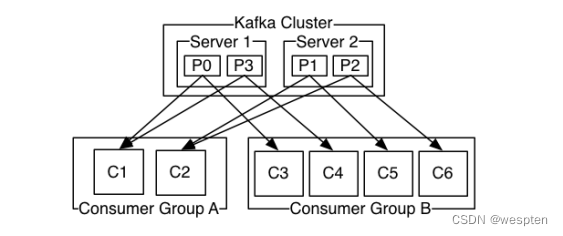
消费规则:
1. 不同 Consumer Group下的消费者可以消费partition中相同的消息,相同的Consumer Group下的消费者只能消费partition中不同的数据。
2. topic的partition的个数和同一个消费组的消费者个数最好一致,如果消费者个数多于partition个数,则会存在有的消费者消费不到数据。
3. 服务器会记录每个consumer的在每个topic的每个partition下的消费的offset,然后每次去消费去拉取数据时,都会从上次记录的位置开始拉取数据。
7、Kafka消息存储机制
在存储结构上,每个partition在物理上对应一个文件夹,该文件夹下存储这个partition的所有消息和索引文件,每个partion(目录)相当于一个巨型文件被平均分配到多个大小相等segment(段)数据文件中。
partiton命名规则为topic名称+序号,第一个partiton序号从0开始,序号最大值为partitions数量减1。
在每个partition (文件夹)中有多个大小相等的segment(段)数据文件,每个segment的大小是相同的,但是每条消息的大小可能不相同,因此segment 数据文件中消息数量不一定相等。
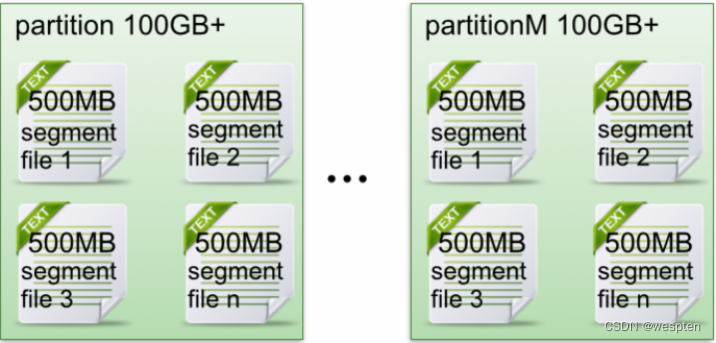
segment数据文件有两个部分组成,分别为index file和data file,此两个文件是一一对应,成对出现,后缀".index"和“.log”分别表示为segment索引文件和数据文件。

其实Kafka最核心的思想是使用磁盘,而不是使用内存,使用磁盘操作有以下几个好处:
1. 磁盘缓存由Linux系统维护,减少了程序员的不少工作。
2. 磁盘顺序读写速度超过内存随机读写。
3. JVM的GC效率低,内存占用大。使用磁盘可以避免这一问题。
4. 系统冷启动后,磁盘缓存依然可用。
四、Elasticsearch架构
Elasticsearch是个开源分布式搜索引擎,它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。
1、ElasticSearch 概念及特点
ElasticSearch是可伸缩的,一个采用RESTFUL api 标准的高扩展性和高可用性的实时数据分析的全文搜索工具。
ElasticSearch相关概念:
-
Node(节点):单个的装有Elasticsearch服务并且提供故障转移和扩展的服务器。
-
Cluster(集群)∶一个集群就是由一个或多个node组织在一起,共同工作,·共同分享整个数据具有负载均衡功能的集群。
-
Document(文档)∶一个文档是一个可被索引的基础信息单元。
-
Index(索引)∶索引就是一个拥有几分相似特征的文档的集合。
-
Type(类型)∶一个索引中,你可以定义一种或多种类型。
-
Field(列)∶Field是Elasticsearch的最小单位,相当于数据的某一列。·
-
Shards(分片)∶Elasticsearch将索引分成若干份,每个部分就是一个shard。·
-
Replicas(复制)∶Replicas是索引一份或多份拷贝。·
RESTFul 解释:
· API∶Application Programming Interface的缩写,中文意思就是应用程序接口
· XML∶可扩展标记语言,是一种程序与程序之间传输数据的标记语言·
· JSON∶英文javascript object notation的缩写,它是一种新型的轻量级数据交换格式
做运维的可能不太了解rustful,但是做开发可能会了解的多一些,从这里就可以看出来,学一门语言是不是重要的。
有了API就可以更好的调用和使用。XML为什么会被丢弃,因为XML文件格式比较庞大,而且不容易解析,不同浏览器之间解析XML又不一样,而且现在微博,等web端的应用,XML越来越跟不上时代的发展,所以现在开始用轻量级的JSON。
RESTFul 风格:
REST(Representational State Transfer,表述性状态转移)是一组架构约束条件和原则,而满足这些约束条件和原则的应用程序或设计就是 RESTful,其本质就是一种定义接口的规范。
-
基于 HTTP 。
-
使用 XML 或 JSON 的格式定义。
-
每一个 URI 代表一种资源。
-
客户端使用 GET、POST、PUT、DELETE 这 4 种表示操作方式的动词对服务端资源进行操作:
- GET:获取资源
- POST:新建资源(也可以更新资源)
- PUT:更新资源
- DELETE:删除资源
高扩展性体现在拓展非常简单,新的节点,基本无需做复杂配置自动发现节点。
高可用性因为是分布式的,而且是一个实时搜索平台,支持PB级的大数据搜索能力。
实时性则是从一个文档到这个文档被搜索,只有略微的延迟,所以说他的实时性非常高。
你可以把elasticearch当做一个数据库,来对比下与其他数据库的不同,elasticseach是非关系型数据库。

2、ElasticSearch 架构

架构说明:
gateway:elasticsearch支持的索引数据的存储格式,当这个elasticsearch关闭再启动的时候,他就会从gateway里面读取索引数据。本地的,分布式,亚马逊的S3
第二行是lucene的框架
第三行:对数据的加工处理方式,创建index模块,搜索模块,mapping,river
第四行:
左边第一块是elasticsearch自动发现节点的机制。
zen 用来实现节点自动发现的,加入master发生故障,其他的节点就会自动选举,来确定一个master。
中间,方便对查询出来的数据进行数据处理。
最右边:插件识别,中文分词插件,断点监控插件。
倒数第二层,是交互方式,默认是用httpd协议来传输的。
最顶层右边是说可以使用java语言,本身就是用java开发的。
3、ElasticSearch 安装
解压即可运行:
[root@localhost ~]# tar zxf elasticsearch-5.0.0.tar.gz
[root@localhost ~]# cd elasticsearch-5.0.0
[root@localhost elasticsearch-5.0.0]# ls
bin config lib LICENSE.txt modules NOTICE.txt README.textile
[root@localhost elasticsearch-5.0.0]#
[root@localhost elasticsearch-5.0.0]# ./bin/elasticsearch -d-d 表示让服务在后台运行。
怎么确认elasticsearch 是否启动成功呢?
我们来访问下web服务地址就可以确认了。
web服务地址:
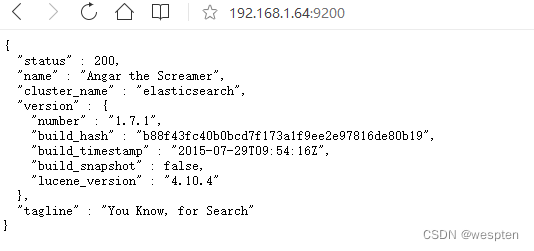
这是一个json的格式,把数据返回回来了,200说明成功了。
name:节点的名称,这个名称是美国漫威漫画角色的名字,他会随机分配一个。
只要java配对了,基本上都可以启动成功,如果启动不成功可以去log日志里面查看。
Elasticsearch启动注意:
- 如果启动在127.0.0.1的话,可以启动成功。
- 如果要跨机器通讯,需要监听在真实网卡时(自建机房的话,建议监听在内网网卡,监听在公网会被入侵)。
- 如果是云服务器的话,一定把9200和9300公网入口在安全组限制一下。
4、ElasticSearch 目录结构
接下来我们看下目录结构:

[root@localhost bin]# ls
elasticsearch elasticsearch.in.bat elasticsearch-service-mgr.exe elasticsearch-service-x86.exe plugin.bat
elasticsearch.bat elasticsearch.in.sh(做优化的时候可以用到) elasticsearch-service-x64.exe plugin service.bat
最重要的是data文件。
5、ElasticSearch 基本操作
1)Elasticsearch的概念
- ->类似于Mysql中的数据库
- ->类似于Mysql中的数据表
- ->存储数据
2)Elasticsearch的数据类型
简单数据类型:
-
字符串- text:会分词,不支持聚合(相当于 mysql 中的 sum)
- keyword:不会分词,将全部内容作为一个词条,支持聚合
-
数值
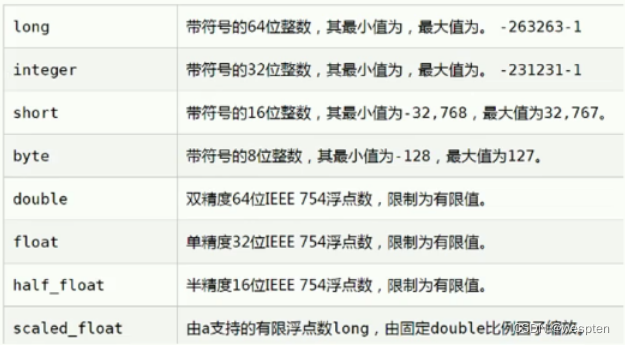
-
布尔值(boolean) -
二进制(binary) -
范围(range)- integer_range
- float_range
- long_range
- double_range
- date_range
-
日期(date)
复杂数据类型:
-
数组 [ ]:数组类型的 JSON 对象(for arrays of JSON objects) -
对象 { }:单个 JSON 对象(for single JSON objects)
3)Elasticsearch的数据操作类型
- curl操作Elasticsearch会比较难
- Kibana来操作Elasticsearch
① 操作索引
使用 Kibana:
# 添加索引
PUT 索引名称 # 或 PUT /索引名称
# 查询索引
# 查询单个索引信息
GET 索引名称
# 查询多个索引信息
GET 索引名称1,索引名称2,...
# 查询所有索引信息
GET _all # 注意:下划线开头的指令是ES内置的
# 删除索引
DELETE 索引名称
# 关闭索引
POST 索引名称/_close
# 打开索引
POST 索引名称/_open使用 RESTful 接口:
# 添加索引
PUT http://ip:端口/索引名称
# 查询索引
# 查询单个索引信息
GET http://ip:端口/索引名称
# 查询多个索引信息
GET http://ip:端口/索引名称1,索引名称2,...
# 查询所有索引信息
GET http://ip:端口/_all
# 删除索引
DELETE http://ip:端口/索引名称
# 关闭索引
POST http://ip:端口/索引名称/_close
# 打开索引
POST http://ip:端口/索引名称/_openElasticsearch增删改查案例:
创建索引: PUT /yyds
删除索引: DELETE /yyds
获取所有索引: GET /_cat/indices?v
ES插入数据:
PUT /yyds/users/1
{
"name":"xiaoming",
"age": 30
}
ES查询数据
GET /yyds/users/1
GET /yyds/_search?q=*
修改数据、覆盖
PUT /yyds/users/1
{
"name": "justdoit",
"age": 45
}
ES删除数据
DELETE /yyds/users/1
修改某个字段、不覆盖
POST /yyds/users/2/_update
{
"doc": {
"age": 29
}
}
修改所有的数据
POST /yyds/_update_by_query
{
"script": {
"source": "ctx._source['age']=30"
},
"query": {
"match_all": {}
}
}
增加一个字段
POST /yyds/_update_by_query
{
"script":{
"source": "ctx._source['city']='hangzhou'"
},
"query":{
"match_all": {}
}
}② 操作映射
对已有索引添加映射:
# 添加索引
PUT person
# 添加映射
PUT /person/_mapping
{
"properties":{ # properties 为固定开头
"name":{ # 字段名称
"type":"text" # type表示字段类型
},
"age":{
"type":"integer"
}
}
}同时创建索引和映射:
# 创建索引和映射
PUT /person1
{
"mappings": { # 注意 mappings 开头
"properties": {
"name": {
"type": "text"
},
"age": {
"type": "integer"
}
}
}
}
# 查询映射
GET person1/_mapping添加字段:
# 与添加映射的方式相同
PUT /person1/_mapping
{
"properties": {
"address": {
"type": "text"
}
}
}③ 操作文档
注意:在仅有索引的情况下也可以添加文档,且在有映射的情况下也可以新增字段。
- 添加文档(指定 id):
# 添加文档:指定 id 为 2
POST /person1/_doc/2
{
"name":"张三",
"age":18,
"address":"北京"
}
# 查询文档
GET /person1/_doc/2- 添加文档(不指定 id):
# 添加文档:不指定id
POST /person1/_doc/
{
"name":"张三",
"age":18,
"address":"北京"
}
# 使用返回的随机数id来查询文档
GET /person1/_doc/随机数id- 查询所有文档:
GET person1/_search- 删除指定 id 的文档:
DELETE /person1/_doc/2④ bulk 批量操作
# 测试数据
POST /person1/_doc/5
{
"name":"张三5号",
"age":18,
"address":"北京海淀区"
}
# bulk 批量操作(注意以下指令不可换行)
# 删除5号
# 新增8号
# 更新2号的name为2号
POST _bulk
{"delete":{"_index":"person1","_id":"5"}}
{"create":{"_index":"person1","_id":"8"}}
{"name":"八号","age":18,"address":"北京"}
{"update":{"_index":"person1","_id":"2"}}
{"doc":{"name":"2号"}}6、ElasticSearch 相关插件
ElasticSearch相关的插件(插件很多,可以在官网搜)。
1. head插件。
2. bigdesk插件。
3. Mavel插件 (收费的)但是用的还比较多。
4. head插件是一个集群管理工具,是由html5写的。
GitHub 网址获取相关信息:https://github.com/mobz/elasticsearch-head
1)head插件
进入elasticsearch bin目录下运行./plugin -install mobz/elasticsearch-head命令:
[root@localhost bin]# pwd
/root/elasticsearch-1.7.1/bin这里面的plugin就是用来装插件用的。
运行命令:
[root@localhost bin]# ./plugin -install mobz/elasticsearch-head
-> Installing mobz/elasticsearch-head...
Trying https://github.com/mobz/elasticsearch-head/archive/master.zip...
Downloading .........................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................DONE
Installed mobz/elasticsearch-head into /root/elasticsearch-1.7.1/plugins/head使用方法:
登陆网址测试:http://192.168.1.64:9200/_plugin/head/:

2)Bigdesk插件
Bigdesk插件是elasticsearch的一个集群监控工具,可以通过它来查看集群的各种状态,如∶cpu、内存使用情况,索引数据、搜索情况,http连接数等。
Github:GitHub - lukas-vlcek/bigdesk: Live charts and statistics for Elasticsearch cluster.
安装:
sudo elasticsearch/bin/plugin -install lukas-vlcek/bigdesk/2.5.0访问:
http://localhost:9200/_plugin/bigdesk/[root@localhost bin]# ./plugin -install lukas-vlcek/bigdesk/2.5.0
-> Installing lukas-vlcek/bigdesk/2.5.0...
Trying http://download.elasticsearch.org/lukas-vlcek/bigdesk/bigdesk-2.5.0.zip...
Trying http://search.maven.org/remotecontent?filepath=lukas-vlcek/bigdesk/2.5.0/bigdesk-2.5.0.zip...
Trying https://oss.sonatype.org/service/local/repositories/releases/content/lukas-vlcek/bigdesk/2.5.0/bigdesk-2.5.0.zip...
Trying https://github.com/lukas-vlcek/bigdesk/archive/2.5.0.zip...
Trying https://github.com/lukas-vlcek/bigdesk/archive/master.zip...
Downloading ........................................................................................................................................................................................................................................................DONE
Installed lukas-vlcek/bigdesk/2.5.0 into /root/elasticsearch-1.7.1/plugins/bigdesk
Identified as a _site plugin, moving to _site structure ...
[root@xuegod64 bin]#通过网页访问验证:
http://192.168.1.63:9200/_plugin/bigdesk/#nodes
点击nodes 会有很多图标,都是html5的。
主要功能有系统监控,cpu使用率,内存使用率,http的交互情况 ,io吞吐量。
3)Mavel插件
Marvel也是elasticsearch的一个管理监控工具,集head和bigdesk优点为一身。但是Marvel插件不是免费的。
官方介绍∶Monitoring:Elasticsearch 的监测与管理 | Elastic
安装∶
sudo elasticsearch/bin/plugin -install elasticsearch/marvel/latest访问∶
http://localhost:9200/_plugin/marvel/[root@localhostbin]# ./plugin -install elasticsearch/marvel/latest
-> Installing elasticsearch/marvel/latest...
Trying http://download.elasticsearch.org/elasticsearch/marvel/marvel-latest.zip...
Downloading ........................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................DONE
Installed elasticsearch/marvel/latest into /root/elasticsearch-1.7.1/plugins/marvel
[root@localhostbin]#五、Logstash架构
Logstash是一个开源的数据收集引擎,它具有备实时数据传输能力。 它可以统一过滤来自不同源的数据,并按照开发者制定的规 范输出到目的地, 支持正则表达式。
由于日志文件来源多(如:系统日志、服务器日志、tomcat 日志、nginx日志等), 且内容杂乱,不便于人类进行观察。 因此,我们可以使用 Logstash 对日志文件进行收集和统一 过滤,变成可读性高的内容。
1、Logstash安装和部署
tar zxvf logstash-7.8.0.tar.gz
ln -s logstash-7.8.0 logstash
chown -R elk:elk logstash
chown -R elk:elk logstash-7.8.0Logstash的JVM配置文件更新/usr/local/logstash-6.6.0/config/jvm.options:
-Xms200M
-Xmx200M2、Logstash启动和测试
前台启动:
/usr/local/logstash-7.8.0/bin/logstash -f /usr/local/logstash-7.8.0/config/logstash.conf后台启动:
nohup /usr/local/logstash-7.8.0/bin/logstash -f /usr/local/logstash-7.8.0/config/logstash.conf >/tmp/logstash.log 2>/tmp/logstash.log &测试标准输入和输出:
简单的案例(从控制台输入 => 控制台输出)
# -e指定配置启动
bin/logstash -e 'input {stdin{}} output{stdout{}}'
# sdtin:hello stdout:
{
"host" => "elk",
"@timestamp" => 2021-02-22T23:29:21.562Z,
"@version" => "1",
"message" => "hello"
}使用配置文件启动:
cp logstash-sample.conf logstash.conf
bin/logstash -f config/logstash.conf
配置文件内容:
input {
# 从文件读取日志信息
file {
path => "/var/log/messages"
type => "system"
start_position => "beginning"
}
}
filter {
}
output {
# 标准输出
stdout {}
}
后台启动:
vi startup.sh
#! /bin/bash
nohup /usr/local/logstash/bin/logstash -f
/usr/local/logstash/config/logstash.conf >>
/usr/local/logstash/output.log 2>&1 &3、Logstash基本语法组成
logstash之所以功能强大和流行,还与其丰富的过滤器插件是分不开的,过滤器提供的并不单单是过滤的功能,还可以对进入过滤器的原始数据进行复杂的逻辑处理,甚至添加独特的事件到后续流程中。
Logstash配置文件有如下三部分组成,其中input、output部分是必须配置,filter部分是可选配置,而filter就是过滤器插件,可以在这部分实现各种日志过滤功能。
input {
#输入插件
}
filter {
#过滤匹配插件
}
output {
#输出插件
}4、Logstash输入插件(Input)
1)读取文件(File)
logstash使用一个名为filewatch的ruby gem库来监听文件变化,并通过一个叫.sincedb的数据库文件来记录被监听的日志文件的读取进度(时间戳),这个sincedb数据文件的默认路径在 <path.data>/plugins/inputs/file下面,文件名类似于.sincedb_452905a167cf4509fd08acb964fdb20c,而<path.data>表示logstash插件存储目录,默认是LOGSTASH_HOME/data。
看下面一个事件配置文件:
input {
file {
path => ["/var/log/messages"]
type => "system"
start_position => "beginning"
}
}
output {
stdout{
codec=>rubydebug
}
}这个配置是监听并接收本机的/var/log/messages文件内容,start_position表示按时间戳记录的地方开始读取,如果没有时间戳则从头开始读取,有点类似cat命令,默认情况下,logstash会从文件的结束位置开始读取数据,也就是说logstash进程会以类似tail -f命令的形式逐行获取数据。type用来标记事件类型,通常会在输入区域通过type标记事件类型。
2)标准输入(Stdin)
stdin是从标准输入获取信息,关于stdin的使用,前面已经做过了一些简单的介绍,这里再看一个稍微复杂一点的例子,下面是一个关于stdin的事件配置文件:
input{
stdin{
add_field=>{"key"=>"iivey"}
tags=>["add1"]
type=>"test1"
}
}
output {
stdout{
codec=>rubydebug
}
}3)读取 Syslog日志
如何将rsyslog收集到的日志信息发送到logstash中,这里以centos7.5为例,需要做如下两个步骤的操作:
首先,在需要收集日志的服务器上找到rsyslog的配置文件/etc/rsyslog.conf,添加如下内容:
*.* @@172.16.213.120:5514其中,172.16.213.120是logstash服务器的地址。5514是logstash启动的监听端口。
接着,重启rsyslog服务:
[root@kafkazk1 logstash]# systemctl restart rsyslog然后,在logstash服务器上创建一个事件配置文件,内容如下:
input {
syslog {
port => "5514"
}
}
output {
stdout{
codec=>rubydebug
}
}
4)读取TCP网络数据
下面的事件配置文件就是通过"LogStash::Inputs::TCP"和"LogStash::Filters::Grok"配合实现syslog功能的例子,这里使用了logstash的TCP/UDP插件读取网络数据:
input {
tcp {
port => "5514"
}
}
filter {
grok {
match => { "message" => "%{SYSLOGLINE}" }
}
}
output {
stdout{
codec=>rubydebug
}
}其中,5514端口是logstash启动的tcp监听端口。注意这里用到了日志过滤"LogStash::Filters::Grok"功能。
5、Logstash编码插件(Codec)
其实我们就已经用过编码插件codec了,也就是这个rubydebug,它就是一种codec,虽然它一般只会用在stdout插件中,作为配置测试或者调试的工具。
编码插件(Codec)可以在logstash输入或输出时处理不同类型的数据,因此,Logstash不只是一个input-->filter-->output的数据流,而是一个input-->decode-->filter-->encode-->output的数据流。
Codec支持的编码格式常见的有plain、json、json_lines等,下面依次介绍。
1)codec插件之plain
plain是一个空的解析器,它可以让用户自己指定格式,也就是说输入是什么格式,输出就是什么格式。下面是一个包含plain编码的事件配置文件:
input{
stdin{
}
}
output{
stdout{
codec => "plain"
}
}2)codec插件之json、json_lines
如果发送给logstash的数据内容为json格式,可以在input字段加入codec=>json来进行解析,这样就可以根据具体内容生成字段,方便分析和储存。如果想让logstash输出为json格式,可以在output字段加入codec=>json,下面是一个包含json编码的事件配置文件:
input {
stdin {
}
}
output {
stdout {
codec => json
}
}
这就是json格式的输出,可以看出,json每个字段是key:values格式,多个字段之间通过逗号分隔。有时候,如果json文件比较长,需要换行的话,那么就要用json_lines编码格式了。
6、Logstash过滤器插件(Filter)
1)Grok 正则捕获
grok是一个十分强大的logstash filter插件,他可以通过正则解析任意文本,将非结构化日志数据弄成结构化和方便查询的结构。他是目前logstash 中解析非结构化日志数据最好的方式。
Grok 的语法规则是:
%{语法: 语义}“语法”指的就是匹配的模式,例如使用NUMBER模式可以匹配出数字,IP模式则会匹配出127.0.0.1这样的IP地址:
例如输入的内容为:
172.16.213.132 [07/Feb/2018:16:24:19 +0800] "GET / HTTP/1.1" 403 5039那么,%{IP:clientip}匹配模式将获得的结果为:
clientip: 172.16.213.132%{HTTPDATE:timestamp}匹配模式将获得的结果为:
timestamp: 07/Feb/2018:16:24:19 +0800而%{QS:referrer}匹配模式将获得的结果为:
referrer: "GET / HTTP/1.1"
下面是一个组合匹配模式,它可以获取上面输入的所有内容:
%{IP:clientip}\ \[%{HTTPDATE:timestamp}\]\ %{QS:referrer}\ %{NUMBER:response}\ %{NUMBER:bytes} 通过上面这个组合匹配模式,我们将输入的内容分成了五个部分,即五个字段,将输入内容分割为不同的数据字段,这对于日后解析和查询日志数据非常有用,这正是使用grok的目的。
Logstash默认提供了近200个匹配模式(其实就是定义好的正则表达式)让我们来使用,可以在logstash安装目录下,例如这里是/usr/local/logstash/vendor/bundle/jruby/1.9/gems/logstash-patterns-core-4.1.2/patterns目录里面查看,基本定义在grok-patterns文件中。
从这些定义好的匹配模式中,可以查到上面使用的四个匹配模式对应的定义规则:
匹配模式 正则定义规则
NUMBER (?:%{BASE10NUM})
HTTPDATE %{MONTHDAY}/%{MONTH}/%{YEAR}:%{TIME} %{INT}
IP (?:%{IPV6}|%{IPV4})
QS %{QUOTEDSTRING}例子:
input{
stdin{}
}
filter{
grok{
match => ["message","%{IP:clientip}\ \[%{HTTPDATE:timestamp}\]\ %{QS:referrer}\ %{NUMBER:response}\ %{NUMBER:bytes}"]
}
}
output{
stdout{
codec => "rubydebug"
}
}输入内容:
172.16.213.132 [07/Feb/2018:16:24:19 +0800] "GET / HTTP/1.1" 403 50392)时间处理(Date)
date插件是对于排序事件和回填旧数据尤其重要,它可以用来转换日志记录中的时间字段,变成LogStash::Timestamp对象,然后转存到@timestamp字段里,这在之前已经做过简单的介绍。
下面是date插件的一个配置示例(这里仅仅列出filter部分):
filter {
grok {
match => ["message", "%{HTTPDATE:timestamp}"]
}
date {
match => ["timestamp", "dd/MMM/yyyy:HH:mm:ss Z"]
}
}| 时间字段 |
字母 |
表示含义 |
| 年 |
yyyy |
表示全年号码。 例如:2018 |
| yy |
表示两位数年份。 例如:2018年即为18 |
|
| 月 |
M |
表示1位数字月份,例如:1月份为数字1,12月份为数字12 |
| MM |
表示两位数月份,例如:1月份为数字01,12月份为数字12 |
|
| MMM |
表示缩短的月份文本,例如:1月份为Jan,12月份为Dec |
|
| MMMM |
表示全月文本,例如:1月份为January,12月份为December |
|
| 日 |
d |
表示1位数字的几号,例如8表示某月8号 |
| dd |
表示2位数字的几号,例如08表示某月8号 |
|
| 时 |
H |
表示1位数字的小时,例如1表示凌晨1点 |
| HH |
表示2位数字的小时,例如01表示凌晨1点 |
|
| 分 |
m |
表示1位数字的分钟,例如5表示某点5分 |
| mm |
表示2位数字的分钟,例如05表示某点5分 |
|
| 秒 |
s |
表示1位数字的秒,例如6表示某点某分6秒 |
| ss |
表示2位数字的秒,例如06表示某点某分6秒 |
|
| 时区 |
Z |
表示时区偏移,结构为HHmm,例如:+0800 |
| ZZ |
表示时区偏移,结构为HH:mm,例如:+08:00 |
|
| ZZZ |
表示时区身份,例如Asia/Shanghai |
3)数据修改(Mutate)
① 正则表达式替换匹配字段
gsub可以通过正则表达式替换字段中匹配到的值,只对字符串字段有效,下面是一个关于mutate插件中gsub的示例(仅列出filter部分):
filter {
mutate {
gsub => ["filed_name_1", "/" , "_"]
}
}这个示例表示将filed_name_1字段中所有"/"字符替换为"_"。
② 分隔符分割字符串为数组
split可以通过指定的分隔符分割字段中的字符串为数组,下面是一个关于mutate插件中split的示例(仅列出filter部分):
filter {
mutate {
split => ["filed_name_2", "|"]
}
}这个示例表示将filed_name_2字段以"|"为区间分隔为数组。
③ 重命名字段
rename可以实现重命名某个字段的功能,下面是一个关于mutate插件中rename的示例(仅列出filter部分):
filter {
mutate {
rename => { "old_field" => "new_field" }
}
}这个示例表示将字段old_field重命名为new_field。
④ 删除字段
remove_field可以实现删除某个字段的功能,下面是一个关于mutate插件中remove_field的示例(仅列出filter部分):
filter {
mutate {
remove_field => ["timestamp"]
}
}这个示例表示将字段timestamp删除。
综合例子:
input {
stdin {}
}
filter {
grok {
match => { "message" => "%{IP:clientip}\ \[%{HTTPDATE:timestamp}\]\ %{QS:referrer}\ %{NUMBER:response}\ %{NUMBER:bytes}" }
remove_field => [ "message" ]
}
date {
match => ["timestamp", "dd/MMM/yyyy:HH:mm:ss Z"]
}
mutate {
rename => { "response" => "response_new" }
convert => [ "response","float" ]
gsub => ["referrer","\"",""]
remove_field => ["timestamp"]
split => ["clientip", "."]
}
}
output {
stdout {
codec => "rubydebug"
}
}
4)GeoIP 地址查询归类
GeoIP是最常见的免费IP地址归类查询库,当然也有收费版可以使用。GeoIP库可以根据IP 地址提供对应的地域信息,包括国别,省市,经纬度等,此插件对于可视化地图和区域统计非常有用。
下面是一个关于GeoIP插件的简单示例(仅列出filter部分):
filter {
geoip {
source => "ip_field"
}
}其中,ip_field字段是输出IP地址的一个字段。
5)filter插件综合应用实例
下面给出一个业务系统输出的日志格式,由于业务系统输出的日志格式无法更改,因此就需要我们通过logstash的filter过滤功能以及grok插件来获取需要的数据格式,此业务系统输出的日志内容以及原始格式如下:
2018-02-09T10:57:42+08:00|~|123.87.240.97|~|Mozilla/5.0 (iPhone; CPU iPhone OS 11_2_2 like Mac OS X) AppleWebKit/604.4.7 Version/11.0 Mobile/15C202 Safari/604.1|~|http://m.sina.cn/cm/ads_ck_wap.html|~|1460709836200|~|DF0184266887D0E可以看出,这段日志都是以“|~|”为区间进行分隔的,那么刚好我们就以“|~|”为区间分隔符,将这段日志内容分割为6个字段。这里通过grok插件进行正则匹配组合就能完成这个功能。
完整的grok正则匹配组合语句如下:
%{TIMESTAMP_ISO8601:localtime}\|\~\|%{IPORHOST:clientip}\|\~\|(%{GREEDYDATA:http_user_agent})\|\~\|(%{DATA:http_referer})\|\~\|%{GREEDYDATA:mediaid}\|\~\|%{GREEDYDATA:osid}调试grok正则表达式工具:Grok Debugger
7、Logstash输出插件(output)
output是Logstash的最后阶段,一个事件可以经过多个输出,而一旦所有输出处理完成,整个事件就执行完成。
一些常用的输出包括:
file: 表示将日志数据写入磁盘上的文件。
elasticsearch:表示将日志数据发送给Elasticsearch。Elasticsearch可以高效方便和易于查询的保存数据。
graphite:表示将日志数据发送给graphite,graphite是一种流行的开源工具,用于存储和绘制数据指标。
此外,Logstash还支持输出到nagios、hdfs、email(发送邮件)和Exec(调用命令执行)。
1)输出到标准输出(stdout)
stdout与之前介绍过的stdin插件一样,它是最基础和简单的输出插件,下面是一个配置实例:
output {
stdout {
codec => rubydebug
}
}stdout插件,主要的功能和用途就是用于调试,这个插件,在前面已经多次使用过。这里不再过多介绍。
2)保存为文件(file)
file插件可以将输出保存到一个文件中,配置实例如下:
output {
file {
path => "/data/log3/%{+yyyy-MM-dd}/%{host}_%{+HH}.log"
}上面这个配置中,使用了变量匹配,用于自动匹配时间和主机名,这在实际使用中很有帮助。
3)输出到elasticsearch
Logstash将过滤、分析好的数据输出到elasticsearch中进行存储和查询,是最经常使用的方法。下面是一个配置实例:
output {
elasticsearch {
host => ["172.16.213.37:9200","172.16.213.77:9200","172.16.213.78:9200"]
index => "logstash-%{+YYYY.MM.dd}"
manage_template => false
template_name => "template-web_access_log"
}
}上面配置中每个配置项含义如下:
host:是一个数组类型的值,后面跟的值是elasticsearch节点的地址与端口,默认端口是9200。可添加多个地址。
index:写入elasticsearch的索引的名称,这里可以使用变量。Logstash提供了%{+YYYY.MM.dd}这种写法。在语法解析的时候,看到以+ 号开头的,就会自动认为后面是时间格式,尝试用时间格式来解析后续字符串。这种以天为单位分割的写法,可以很容易的删除老的数据或者搜索指定时间范围内的数据。此外,注意索引名中不能有大写字母。
manage_template:用来设置是否开启logstash自动管理模板功能,如果设置为false将关闭自动管理模板功能。如果我们自定义了模板,那么应该设置为false。
template_name:这个配置项用来设置在Elasticsearch中模板的名称。
8、使用logstash收集日志信息并在kibana展示
输出到elasticsearch:
input {
# 从文件读取日志信息
file {
path => "/var/log/messages"
type => "system"
start_position => "beginning"
}
}
filter {
}
output {
elasticsearch {
hosts => ["127.0.0.1:9200"]
index => "msg-%{+YYYY.MM.dd}"
}
}
Logs:
index pattern:

discover:
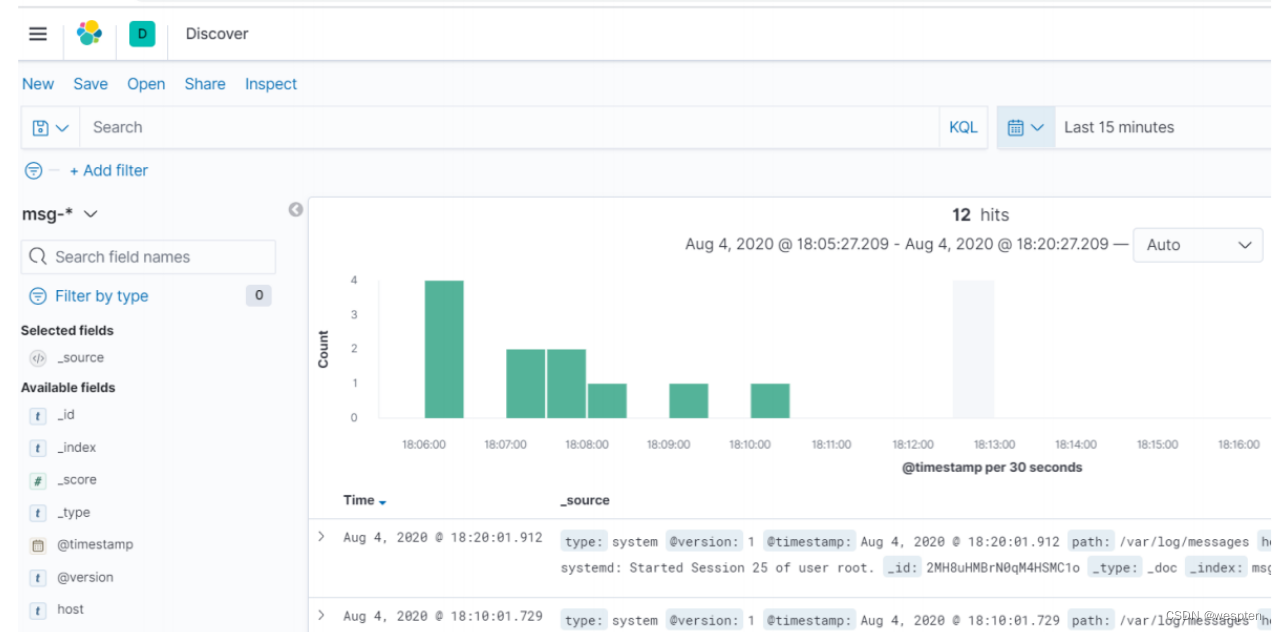
9、使用logstash收集nginx日志并在kibana展示
nginx安装:
cd /opt
tar zxvf nginx-1.18.0.tar.gz
ln -s nginx-1.18.0 nginx
chown -R elk:elk nginx
chown -R elk:elk nginx-1.18.0
cd /usr/local
wget http://jaist.dl.sourceforge.net/project/pcre/pcre/8.38/pcre-8.38.tar.gz
wget http://zlib.net/zlib-1.2.11.tar.gz
wget http://www.openssl.org/source/openssl-1.0.1j.tar.gz
tar zxvf pcre-8.38.tar.gz
ln -s pcre-8.38 pcre
tar zxvf zlib-1.2.11.tar.gz
ln -s zlib-1.2.11 zlib
tar zxvf openssl-1.0.1j.tar.gz
ln -s openssl-1.0.1j openssl
cd /opt/nginx
./configure --prefix=/usr/local/nginx --withpcre=/usr/local/pcre-8.38 --withzlib=/usr/local/zlib-1.2.11
./configure --prefix=/usr/local/nginx --with-pcre=/usr/local/pcre --with-zlib=/usr/local/zlib --with-openssl=/usr/local/openssl
--with-http_stub_status_module --with-http_gzip_static_module --with-http_realip_module --with-http_sub_module --with-http_ssl_module
make
make install启动nginx:
cd /usr/local/nginx
sbin/nginx -c conf/nginx.conf
ps -ef|grep nginx
配置logstash.conf:
input {
file {
path => "/usr/local/nginx/logs/access.log"
type => "nginxaccess"
start_position => "beginning"
}
}
filter {
grok {
match => { "message" => "%{HTTPD_COMBINEDLOG}" }
}
}
output {
elasticsearch {
hosts => ["127.0.0.1:9200"]
index => "nginx-%{+YYYY.MM.dd}"
}
}
使用内置正则表达式:
/usr/local/logstash/vendor/bundle/jruby/2.5.0/gems/logstashpatterns-core-4.1.2/patterns/httpd
HTTPD_COMBINEDLOG %{HTTPD_COMMONLOG} % {QS:referrer} %{QS:agent}
kibana展示:
索引展示:
Logs展示:

Discover展示:
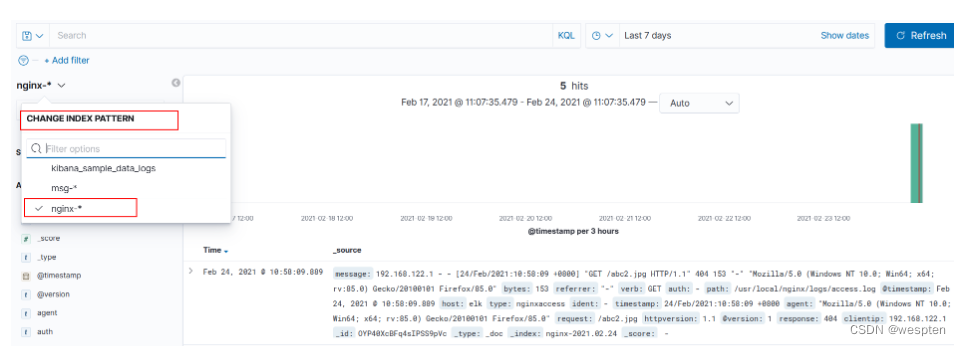
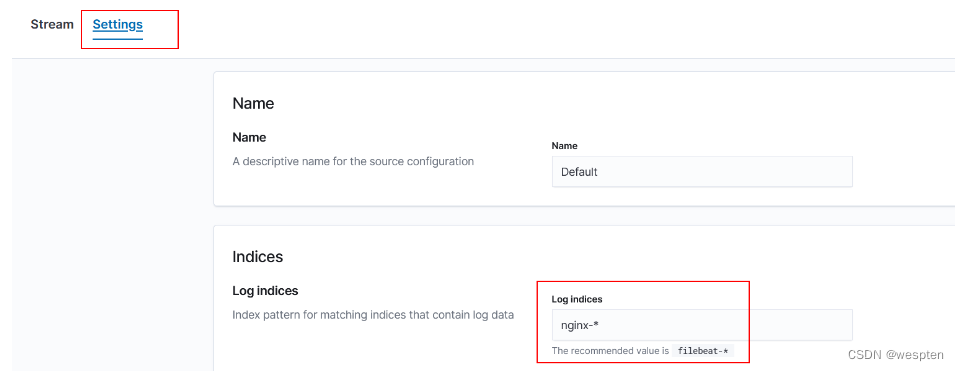
10、Logstash正则提取Nginx日志
Nginx日志说明:
192.168.237.1 - - [24/Feb/2021:17:48:47 +0800] "GET /yyds HTTP/1.1" 404 571 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36"- 访问IP地址
- 访问时间
- 请求方式(GET/POST)
- 请求URL
- 状态码
- 响应body大小
- Referer
- User Agent
Grok提取Nginx日志:
Logstash支持普通正则和扩展正则,利用Kibana的Grok学习Logstash正则提取日志。
Grok使用(?<xxx>提取内容)来提取xxx字段。
提取客户端IP:
(?<clientip>[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3})提取时间:
\[(?<requesttime>[^ ]+ \+[0-9]+)\]Grok提取Nginx日志:
(?<clientip>[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}) - - \[(?<requesttime>[^ ]+ \+[0-9]+)\] "(?<requesttype>[A-Z]+) (?<requesturl>[^ ]+) HTTP/\d.\d" (?<status>[0-9]+) (?<bodysize>[0-9]+) "[^"]+" "(?<ua>[^"]+)"Tomcat等日志使用类似的方法。
Logstash正则提取Nginx日志:
input {
file {
path => "/usr/local/nginx/logs/access.log"
}
}
filter {
grok {
match => {
"message" => '(?<clientip>[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}) - - \[(?<requesttime>[^ ]+ \+[0-9]+)\] "(?<requesttype>[A-Z]+) (?<requesturl>[^ ]+) HTTP/\d.\d" (?<status>[0-9]+) (?<bodysize>[0-9]+) "[^"]+" "(?<ua>[^"]+)"'
}
}
}
output {
elasticsearch {
hosts => ["http://192.168.237.50:9200"]
}
}注意正则提取失败的情况,Logstash正则提取出错就不输出到ES:
output{
if "_grokparsefailure" not in [tags] and "_dateparsefailure" not in [tags] {
elasticsearch {
hosts => ["http://192.168.237.50:9200"]
}
}
}Logstash配置去除不需要的字段:
去除字段可以减小ES数据库的大小,提升搜索效率。
注意,只能去除_source里的,非_source里的去除不了。
filter {
grok {
match => {
"message" => '(?<clientip>[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}) - - \[(?<requesttime>[^ ]+ \+[0-9]+)\] "(?<requesttype>[A-Z]+) (?<requesturl>[^ ]+) HTTP/\d.\d" (?<status>[0-9]+) (?<bodysize>[0-9]+) "[^"]+" "(?<ua>[^"]+)"'
}
remove_field => ["message","@version","path"]
}
}11、kibana-Discover展示时timestamp时间格式处理
使用logstash-filter-date插件:
bin/logstash-plugin list|grep date配置logstash.conf:
input {
file {
path => "/usr/local/nginx/logs/access.log"
type => "nginxaccess"
start_position => "beginning"
}
}
filter {
grok {
match => { "message" => "%{HTTPD_COMBINEDLOG}" }
}
date {
match => ["timestamp","dd/MMM/yyyy:HH:mm:ss Z"]
target => "@timestamp"
}
}
output {
stdout {
}
}
删除上次logstash记录位置:
rm /usr/local/logstash/data/plugins/inputs/file/.sincedb_d2343edad78a7252d2ea9cba15bbff6d注意@timestamp字段,在Elasticsearch内部,对时间类型字段,统一采用UTC时间,存成 long长整型。
配置logstash.conf输出到elasticsearch:
input {
file {
path => "/usr/local/nginx/logs/access.log"
type => "nginxaccess"
start_position => "beginning"
}
}
filter {
grok {
match => { "message" => "%{HTTPD_COMBINEDLOG}" }
}
date {
match => ["timestamp","dd/MMM/yyyy:HH:mm:ss Z"]
target => "@timestamp"
}
}
output {
elasticsearch {
hosts => ["127.0.0.1:9200"]
index => "nginx-%{+YYYY.MM.dd}"
}
}
默认ELK时间轴,以发送日志的时间为准,而Nginx上本身记录着用户的访问时间。
分析Nginx上的日志以用户的访问时间为准,而不以发送日志的时间:
Logstash分析所有Nginx日志:
input {
file {
path => "/usr/local/nginx/logs/access.log"
start_position => "beginning"
sincedb_path => "/dev/null"
}
}Logstash的filter里面加入配置24/Feb/2021:21:08:34 +0800:
filter {
grok {
match => {
"message" => '(?<clientip>[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}) - - \[(?<requesttime>[^ ]+ \+[0-9]+)\] "(?<requesttype>[A-Z]+) (?<requesturl>[^ ]+) HTTP/\d.\d" (?<status>[0-9]+) (?<bodysize>[0-9]+) "[^"]+" "(?<ua>[^"]+)"'
}
remove_field => ["message","@version","path"]
}
date {
match => ["requesttime", "dd/MMM/yyyy:HH:mm:ss Z"]
target => "@timestamp"
}
}统计Nginx的请求和网页显示进行对比:
cat /usr/local/nginx/logs/access.log |awk '{print $4}'|cut -b 1-19|sort |uniq -c注意,不同的时间格式,覆盖的时候格式要对应:
20/Feb/2021:14:50:06 -> dd/MMM/yyyy:HH:mm:ss
2021-08-24 18:05:39,830 -> yyyy-MM-dd HH:mm:ss,SSS六、Filebeat架构
1、什么是Filebeat
Filebeat是一个开源的文本日志收集器,它是elastic公司Beats数据采集产品的一个子产品,采用go语言开发,一般安装在业务服务器上作为代理来监测日志目录或特定的日志文件,并把它们发送到logstash、elasticsearch、redis或Kafka等。
官方地址:下载 Beats:Elasticsearch 的数据采集器 | Elastic
下载各个版本的Filebeat。
2、Filebeat架构与运行原理
Filebeat是一个轻量级的日志监测、传输工具,它最大的特点是性能稳定、配置简单、占用系统资源很少。由于依赖于Java环境,用来收集日志比较重,占用较多内存和CPU,而Filebeat相对轻量,占用服务器资源小,这也是强烈推荐Filebeat的原因。
下图是官方给出的Filebeat架构图:
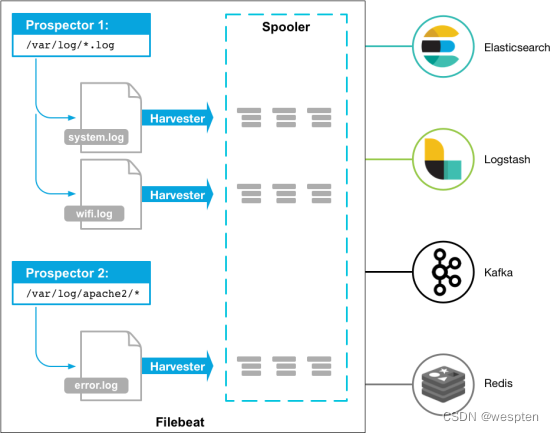
从图中可以看出,Filebeat主要由两个组件构成: prospector(探测器)和harvester(收集器)。这两类组件一起协作完成Filebeat的工作。
其中,Harvester负责进行单个文件的内容收集,在运行过程中,每一个Harvester会对一个文件逐行进行内容读取,并且把读写到的内容发送到配置的output中。当Harvester开始进行文件的读取后,将会负责这个文件的打开和关闭操作,因此,在Harvester运行过程中,文件都处于打开状态。如果在收集过程中,删除了这个文件或者是对文件进行了重命名,Filebeat依然会继续对这个文件进行读取,这时候将会一直占用着文件所对应的磁盘空间,直到Harvester关闭。
Prospector负责管理Harvster,它会找到所有需要进行读取的数据源。然后交给Harvster进行内容收集,如果input type配置的是log类型,Prospector将会去配置路径下查找所有能匹配上的文件,然后为每一个文件创建一个Harvster。
综上所述,filebeat的工作流程为:当开启filebeat程序的时候,它会启动一个或多个探测器(prospector)去检测指定的日志目录或文件,对于探测器找出的每一个日志文件,filebeat会启动收集进程(harvester),每一个收集进程读取一个日志文件的内容,然后将这些日志数据发送到后台处理程序(spooler),后台处理程序会集合这些事件,最后发送集合的数据到output指定的目的地。
3、Filebeat下载安装
源码编译安装:
cd /usr/local/src/
tar -zxf filebeat-7.4.0-linux-x86_64.tar.gz
mv filebeat-7.4.0-linux-x86_64 /usr/local/filebeat-7.4.0启动Filebeat:
前台启动:
/usr/local/filebeat-6.6.0/filebeat -e -c /usr/local/filebeat-6.6.0/filebeat.yml后台启动:
nohup /usr/local/filebeat-7.4.0/filebeat -e -c /usr/local/filebeat-7.4.0/filebeat.yml >/tmp/filebeat.log 2>&1 &RPM 安装:
[root@web01 ~]# rpm -ivh filebeat-7.4.0-x86_64.rpm启动:
systemctl enable filebeat
systemctl start filebeat4、Filebeat配置

将文件最新发生变化的内容,存入es:
cat /usr/local/filebeat-6.6.0/filebeat.yml
filebeat.inputs:
- type: log
tail_files: true
backoff: "1s"
paths:
- /usr/local/nginx/logs/access.log
enabled: true
output:
elasticsearch:
hosts: ["192.168.237.50:9200"]
setup.template.name: nginx
setup.template.pattern: nginx-*5、收集系统日志
系统日志一般指的是messages,secure,cron,dmesg,boot,ssh等日志,需要对系统日志进行统一、集中的管理。
统一日志管理作用:
- 减少无用的数据
- 调整索引名称
- 测试调整模板,设定分片
通过rsyslog收集本地所有类型的日志,然后使用filebeat对该文件进行分收集即可。
安装rsyslog:
[root@web01 ~]# yum install rsyslog -y配置rsyslog:
[root@web01 ~]# vim /etc/rsyslog.conf
#配置日志收集的方式
...
*.* /var/log/oldxu.log #将本地所有日志保存至本地/var/log/oldxu.log
...重启rsyslog:
[root@web01 ~]# systemctl enable rsyslog
[root@web01 ~]# systemctl start rsyslog测试:
root@web01 ~]# cat /etc/filebeat/filebeat.yml
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/oldxu.log
include_lines: ['^ERR', '^WARN', 'sshd'] #只看指定的日志
output.elasticsearch:
hosts: ["10.0.0.161:9200","10.0.0.162:9200","10.0.0.163:9200"]
index: "system-%{[agent.version]}-%{+yyyy.MM.dd}"
setup.ilm.enabled: false
setup.template.name: system #索引关联的模板名称
setup.template.pattern: system-*
方式一:
###设定system模板的分片数和副本数
#setup.template.settings: #定义索引分片数和副本
# index.number_of_shards: 3
# index.number_of_replicas: 1
方式二:
"number_of_routing_shards": "30",
"number_of_shards": "10",
"number_of_replicas": "1",
1.修改system模板 ---> 添加 shards 分片数数量,replicas的数量
2.删除模板关联的索引
3.删除filebeat自行指定的分片数和副本数
4.重启filebeat
5.产生新的日志6、收集nginx日志
编写配置文件:
[root@web01 nginx]# vim nginx.conf
...
log_format json '{ "time_local": "$time_local", '
'"remote_addr": "$remote_addr", '
'"referer": "$http_referer", '
'"request": "$request", '
'"status": $status, '
'"bytes": $body_bytes_sent, '
'"agent": "$http_user_agent", '
'"x_forwarded": "$http_x_forwarded_for", '
'"up_addr": "$upstream_addr",'
'"up_host": "$upstream_http_host",'
'"upstream_time": "$upstream_response_time",'
'"request_time": "$request_time"'
'}';
access_log /var/log/nginx/access.log json;
...配置nginx站点目录:
[root@web01 conf.d]# cat elk.oldxu.com.conf
server {
listen 80;
server_name elk.oldxu.com;
root /code/elk;
access_log /var/log/nginx/elk.oldxu.com.log json;
location / {
index index.html;
}
}
[root@web01 conf.d]# cat bk.oldxu.com.conf
server {
listen 80;
server_name bk.oldxu.com;
root /code/bk;
access_log /var/log/nginx/bk.oldxu.com.log json;
# error_log /var/log/nginx/blog_error.log;
location / {
index index.php index.html;
}
}
[root@web01 conf.d]# cat bs.oldxu.com.conf
server {
listen 80;
server_name bs.oldxu.com;
root /code/bs;
access_log /var/log/nginx/bs.oldxu.com.log json;
# error_log /var/log/nginx/blog_error.log;
location / {
index index.php index.html;
}
}测试,模拟产生日志:
[root@web01 conf.d]# curl -H Host:elk.oldxu.com http://10.0.0.7
elk.oldux.com
[root@web01 conf.d]# curl -H Host:bs.oldxu.com http://10.0.0.7
bs.oldux.com
[root@web01 conf.d]# curl -H Host:bk.oldxu.com http://10.0.0.7
bk.oldux.com配置filebeat:
[root@web01 filebeat]# cat filebeat.yml
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/nginx/elk.oldxu.com.log
json.keys_under_root: true
json.overwrite_keys: true
tags: ["nginx-elk-host"]
- type: log
enabled: true
paths:
- /var/log/nginx/bs.oldxu.com.log
json.keys_under_root: true
json.overwrite_keys: true
tags: ["nginx-bs-host"]
- type: log
enabled: true
paths:
- /var/log/nginx/bk.oldxu.com.log
json.keys_under_root: true
json.overwrite_keys: true
tags: ["nginx-bk-host"]
- type: log
enabled: true
paths:
- /var/log/nginx/error.log
tags: ["nginx-error"]
output.elasticsearch:
hosts: ["10.0.0.161:9200","10.0.0.162:9200","10.0.0.163:9200"]
indices:
- index: "nginx-elk-access-%{[agent.version]}-%{+yyyy.MM.dd}"
when.contains:
tags: "nginx-elk-host"
- index: "nginx-bs-access-%{[agent.version]}-%{+yyyy.MM.dd}"
when.contains:
tags: "nginx-bs-host"
- index: "nginx-bk-access-%{[agent.version]}-%{+yyyy.MM.dd}"
when.contains:
tags: "nginx-bk-host"
- index: "nginx-error-%{[agent.version]}-%{+yyyy.MM.dd}"
when.contains:
tags: "nginx-error"
setup.ilm.enabled: false
setup.template.name: nginx #索引关联的模板名称
setup.template.pattern: nginx-*7、收集Tomcat日志
安装tomcat:
#上传apache-tomcat-9.0.27.tar.gz
#解压
mkdir /soft
tar xf apache-tomcat-9.0.27.tar.gz -C /soft
ln -s apache-tomcat-9.0.27 tomcat编辑tomcat配置文件:
vim /soft/tomcat/conf/server.xml
<Host name="tomcat.oldxu.com" appBase="/code/tomcat"
unpackWARs="true" autoDeploy="true">
<Valve className="org.apache.catalina.valves.AccessLogValve" directory="logs"
prefix="tomcat.oldxu.com.log" suffix=".txt"
pattern="{"clientip":"%h","ClientUser":"%l","authenticated":"%u","AccessTime":"%t","method":"%r","status":"%s","SendBytes":"%b","Query?string":"%q","partner":"%{Referer}i","AgentVersion":"%{User-Agent}i"}" />
</Host>配置filebeat:
[root@web02 filebeat]# vim filebeat.yml
filebeat.inputs:
- type: log
enabled: true
paths:
- /soft/tomcat/logs/tomcat.oldxu.com.log.*.txt
json.keys_under_root: true #默认Flase,还会将json解析的日志存储至messages字段
json.overwrite_keys: true #覆盖默认的key,使用自定义json格式的key
tags: ["tomcat-access"]
- type:
enabled: true
paths:
- /soft/tomcat/logs/catalina.out
multiline.pattern: '^\d{2}' #匹配以2数字开头的
multiline.negate: true
multiline.match: after
multiline.max_lines: 10000 #默认最大合并行为500,可根据实际情况调整
tags: ["tomcat-error"]
output.elasticsearch:
hosts: ["10.0.0.161:9200","10.0.0.162:9200"]
indices:
- index: "tomcat-access-%{[agent.version]}-%{+yyyy.MM.dd}"
when.contains:
tags: "tomcat-access"
- index: "tomcat-error-%{[agent.version]}-%{+yyyy.MM.dd}"
when.contains:
tags: "tomcat-error"
setup.ilm.enabled: false
setup.template.name: tomcat #索引关联的模板名称
setup.template.pattern: tomcat-*Kibana上查看日志数据:
创建索引观察:
GET /xxx/_search?q=*注意:Filebeat -> ES -> Kibana只是和查看日志,不适合具体日志分析。
8、Filebeat+Logstash新框架
Filebeat和Logstash对比
- Filebeat:轻量级,但不支持正则、不能移除字段等。
- Logstash:比较重,但支持正则、支持移除字段等。
新架构说明:
单体:
Logstash -> Elasticsearch -> Kibana
Filebeat -> Elasticsearch -> Kibana
Filebeat -> Logstash -> Elasticsearch -> Kibana
集群:
Filebeat(多台)
Filebeat(多台) -> Logstash(正则) -> Elasticsearch(入库) -> Kibana展现
Filebeat(多台) Filebeat批量部署比Logstash要方便得多,Logstash监听在内网,Filebeat发送给内网的Logstash。
Filebeat配置发往Logstash:
filebeat.inputs:
- type: log
tail_files: true
backoff: "1s"
paths:
- /usr/local/nginx/logs/access.log
output:
logstash:
hosts: ["192.168.237.51:5044"]Logstash配置监听在5044端口,接收Filebeat发送过来的日志:
input {
beats {
host => '0.0.0.0'
port => 5044
}
}Kibana上查看数据:
GET /xxx/_search?q=*创建索引查看数据。
Filebeat发过来的无用字段比较多,要在Logstash上移除不必要的字段:
remove_field => ["message","@version","path","beat","input","log","offset","prospector","source","tags"]9、Json格式日志采集
原生日志需要做正则匹配,比较麻烦,Json格式的日志不需要正则能直接分段采集。
Nginx使用Json格式日志:
log_format json '{"@timestamp":"$time_iso8601",'
'"clientip":"$remote_addr",'
'"status":$status,'
'"bodysize":$body_bytes_sent,'
'"referer":"$http_referer",'
'"ua":"$http_user_agent",'
'"handletime":$request_time,'
'"url":"$uri"}';
access_log logs/access.log;
access_log logs/access.json.log json;Filebeat采集Json格式的日志:
filebeat.inputs:
- type: log
tail_files: true
backoff: "1s"
paths:
- /usr/local/nginx/logs/access.json.log
output:
logstash:
hosts: ["192.168.237.51:5044"]Logstash正则提取的配置备份:
filter {
grok {
match => {
"message" => '(?<clientip>[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}) - - \[(?<requesttime>[^ ]+ \+[0-9]+)\] "(?<requesttype>[A-Z]+) (?<requesturl>[^ ]+) HTTP/\d.\d" (?<status>[0-9]+) (?<bodysize>[0-9]+) "[^"]+" "(?<ua>[^"]+)"'
}
remove_field => ["message","@version","path","beat","input","log","offset","prospector","source","tags"]
}
date {
match => ["requesttime", "dd/MMM/yyyy:HH:mm:ss Z"]
target => "@timestamp"
}
}Logstash解析Json日志:
input {
beats {
host => '0.0.0.0'
port => 5044
}
}
filter {
json {
source => "message"
remove_field => ["message","@version","path","beat","input","log","offset","prospector","source","tags"]
}
}
output {
elasticsearch {
hosts => ["http://192.168.237.50:9200"]
}
}10、Filebeat采集多个日志配置
Filebeat默认收集单个Nginx日志,如何采集多个日志?
Filebeat采集多个日志配置:
filebeat.inputs:
- type: log
tail_files: true
backoff: "1s"
paths:
- /usr/local/nginx/logs/access.json.log
fields:
type: access
fields_under_root: true
- type: log
tail_files: true
backoff: "1s"
paths:
- /var/log/secure
fields:
type: secure
fields_under_root: true
output:
logstash:
hosts: ["192.168.237.51:5044"]Filebeat 加入一字段,Logstash使用区别字段来区分两字段:
Logstash通过type字段进行判断:
input {
beats {
host => '0.0.0.0'
port => 5044
}
}
filter {
if [type] == "access" {
json {
source => "message"
remove_field => ["message","@version","path","beat","input","log","offset","prospector","source","tags"]
}
}
}
output{
if [type] == "access" {
elasticsearch {
hosts => ["http://192.168.237.50:9200"]
index => "access-%{+YYYY.MM.dd}"
}
}
else if [type] == "secure" {
elasticsearch {
hosts => ["http://192.168.237.50:9200"]
index => "secure-%{+YYYY.MM.dd}"
}
}
}11、架构优化引入Redis
原先的架构Logstash性能不足的时候,扩容Logstash,Filebeat的配置可能会不一致。
优化架构为:
Filebeat(多台) Logstash
Filebeat(多台) -> Redis、Kafka -> Logstash(正则) -> Elasticsearch(入库) -> Kibana展现
Filebeat(多台) LogstashRedis编译安装:
yum install -y wget net-tools gcc gcc-c++ make tar openssl openssl-devel cmake
cd /usr/local/src
wget 'http://download.redis.io/releases/redis-4.0.9.tar.gz'
tar -zxf redis-4.0.9.tar.gz
cd redis-4.0.9
make
mkdir -pv /usr/local/redis/conf /usr/local/redis/bin
cp src/redis* /usr/local/redis/bin/
cp redis.conf /usr/local/redis/confRedis的启动命令:
/usr/local/redis/bin/redis-server /usr/local/redis/conf/redis.conf验证Redis服务器:
更改Redis配置(daemon、dir、requirepass),进行set、get操作:
/usr/local/redis/bin/redis-cli
auth 'yyds'
set name yyds
get nameFilebeat配置写入到Redis:
filebeat.inputs:
- type: log
tail_files: true
backoff: "1s"
paths:
- /usr/local/nginx/logs/access.json.log
fields:
type: access
fields_under_root: true
output:
redis:
hosts: ["192.168.237.51"]
port: 6379
password: 'yyds'
key: 'access'Logstash从Redis中读取数据:
input {
redis {
host => '192.168.237.51'
port => 6379
key => "access"
data_type => "list"
password => 'yyds'
}
}12、架构优化引入Kafka
kafka依赖于Zookeeper,两个都依赖于Java。
下载Zookeeper:Apache ZooKeeper
安装Zookeeper:
tar -zxf zookeeper-3.4.13.tar.gz
mv zookeeper-3.4.13 /usr/local/
cp /usr/local/zookeeper-3.4.13/conf/zoo_sample.cfg /usr/local/zookeeper-3.4.13/conf/zoo.cfg更改配置:
clientPortAddress=0.0.0.0启动Zookeeper:
/usr/local/zookeeper-3.4.13/bin/zkServer.sh start下载Kafka:Apache Kafka
安装Kafka:
cd /usr/local/src/
tar -zxf kafka_2.11-2.1.1.tgz
mv kafka_2.11-2.1.1 /usr/local/kafka_2.11Kafka的启动:
先修改kafka的配置,更改监听地址、更改连接zk的地址等。
前台启动:
/usr/local/kafka_2.11/bin/kafka-server-start.sh /usr/local/kafka_2.11/config/server.properties启动kafka:
nohup /usr/local/kafka_2.11/bin/kafka-server-start.sh /usr/local/kafka_2.11/config/server.properties >/tmp/kafka.log 2>&1 &
Filebeat日志发送到Kafka:
filebeat.inputs:
- type: log
tail_files: true
backoff: "1s"
paths:
- /usr/local/nginx/logs/access.json.log
fields:
type: access
fields_under_root: true
output:
kafka:
hosts: ["192.168.237.51:9092"]
topic: yydsLogstash读取Kafka:
input {
kafka {
bootstrap_servers => "192.168.237.51:9092"
topics => ["yyds"]
group_id => "yyds"
codec => "json"
}
}
filter {
if [type] == "access" {
json {
source => "message"
remove_field => ["message","@version","path","beat","input","log","offset","prospector","source","tags"]
}
}
}
output {
stdout {
codec=>rubydebug
}
}Kafka查看队列信息:
查看Group:
./kafka-consumer-groups.sh --bootstrap-server 192.168.237.51:9092 --list查看队列:
./kafka-consumer-groups.sh --bootstrap-server 192.168.237.51:9092 --group yyds --describe七、Kibana架构
1、Kibana下载安装
我们可以前往Elasticsearch的官网下载Kibana,下载地址为:Download Kibana Free | Get Started Now | Elastic,网页如下所示:

RPM安装包安装:
yum localinstall -y kibana-6.8.1-x86_64.rpm 源码编译安装:
cd /usr/local/src/
tar -zxf kibana-6.8.1-linux-x86_64.tar.gz
mv kibana-6.8.1-linux-x86_64 /usr/local/kibana-6.8.12、Kibana配置与启动
接下来,我们来配置以下Kibana,打开Kibana的配置文件kibana.yml,修改其中的server.port、server.host、elasticsearch.hosts以及i18n.locale,分别将其修改为5601端口、本地IP地址,Elasticsearch集群中任意一台设备的IP地址,以及zh-CN。
/usr/local/kibana-6.8.1/config/kibana.yml
server.port: 5601
server.host: "0.0.0.0"
#elasticsearch.url: "http://localhost:9200"
#elasticsearch.username: "user"
#elasticsearch.password: "pass"
i18n.locale:"zh-CN"注:rpm安装,配置文件在/etc/kibana/kibana.yml。
3、Kibana的启动和访问
rpm安装,启动方式:
systemctl start kibana源码编译安装:
前台启动:
/usr/local/kibana-6.8.1/bin/kibana后台启动Kibana:
nohup /usr/local/kibana-6.8.1/bin/kibana >/tmp/kibana.log 2>/tmp/kibana.log &需要开放5601端口:

访问Kibana,您可以通过localhost:5601/status来访问 Kibana 的服务器状态页,状态页展示了服务器资源使用情况和已安装插件列表。

4、Kibana的安全认证
在使用ELK进行日志统计的时候,由于Kibana自身并没有身份验证的功能,任何人只要知道链接地址就可以正常登录到Kibana控制界面。
由于日常的查询,添加日志和删除日志都是在同一个web 中进行,这样就有极高的安全隐患。任何人都有权限对其进行修改。
为了避免这一问题,可以使用Nginx的验证功能来代理Kibana。
如果使用云厂商,可以在安全组控制某个IP的访问。
1)Nginx编译安装
yum install -y lrzsz wget gcc gcc-c++ make pcre pcre-devel zlib zlib-devel
cd /usr/local/src
wget 'http://nginx.org/download/nginx-1.14.2.tar.gz'
tar -zxvf nginx-1.14.2.tar.gz
cd nginx-1.14.2
./configure --prefix=/usr/local/nginx && make && make installNginx环境变量设置:
export PATH=$PATH:/usr/local/nginx/sbin/2)编辑kibana的配置文件
对server.basePath进行定义,配置路径,然后重启kibana。
vim /etc/kibana/kibana.yml
修改参数如下:
server.basePath: "/kibana"
server.host: "10.0.101.100" #此配置下,如果要限制外部用户直接访问本机的5601端口,可以使用iptables进行限制(但因我的Nginx和Kibana不在同一台服务器,所以不进行限制,如果在同一台服务器上,则可以把属性值设为127.0.0.1,然后进行5601端口限制)注:如果 server.host: "127.0.0.1" ,则禁止了外部用户直接访问kibana页面。
3)Nginx两种限制
1. 限制源IP访问,比较安全,访问的IP得不变;
2. 使用用户名密码的方式,通用;
Nginx限制源IP访问:
cat /usr/local/nginx/conf/nginx.conf
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log logs/access.log main;
server {
listen 80;
server_name 172.24.115.4;
location /kibana/ {
proxy_pass http://10.0.101.100:5601/;
proxy_set_header Host $host:$server_port;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
rewrite ^/kibana/(.*)$ /$1 break;
}
}注:上面的kibana要和kibana.yml中的server.basePath属性值保持一样。
访问测试:
最终访问http://172.24.115.4/kibana/便可以访问到代理的Kibana。

观察访问日志:
/usr/local/nginx/logs/access.log
如果被拒绝了可以在日志里找到源IP。
Nginx配置使用用户名密码的方式:
准备密码文件:
// 安装工具包
yum install httpd-tools
// 生成密码,用户名 admin
htpasswd -c /usr/local/nginx/conf/kibanauser admin
# 提示输入2遍密码
New password:
Re-type new password:
Adding password for user adminhtpasswd命令参数如下:
-c 创建passwdfile.如果passwdfile 已经存在,那么它会重新写入并删去原有内容.
-n 不更新passwordfile,直接显示密码
-m 使用MD5加密(默认)
-d 使用CRYPT加密(默认)
-p 使用普通文本格式的密码
-s 使用SHA加密
-b 命令行中一并输入用户名和密码而不是根据提示输入密码,可以看见明文,不需要交互
-D 删除指定的用户修改Nginx配置文件,增加登陆认证配置,然后重启Nginx:
# cat /usr/local/nginx/conf/nginx.conf
server {
listen 80;
server_name 172.24.115.4;
location /kibana/ {
auth_basic "secret";
auth_basic_user_file /usr/local/nginx/conf/kibanauser;
proxy_pass http://10.0.101.100:5601/;
proxy_set_header Host $host:$server_port;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
rewrite ^/kibana/(.*)$ /$1 break;
}
}再次访问http://172.24.115.4/kibana/,会提示输入用户名和密码:
5、Kibana绘图展示
Kibana的真正作用是数据的可视化。
首先,我们来绘制一下标签云视图。
进入Kibana后,选择左边的“可视化”标签,然后点击中间的创建可视化,如下所示:
然后,我们创建可视化的类型,如下所示:

选择标签云图后,我们来选择索引,如下所示:
之后,我们来添加一些参数,指定绘图的一些根据,如下所示:


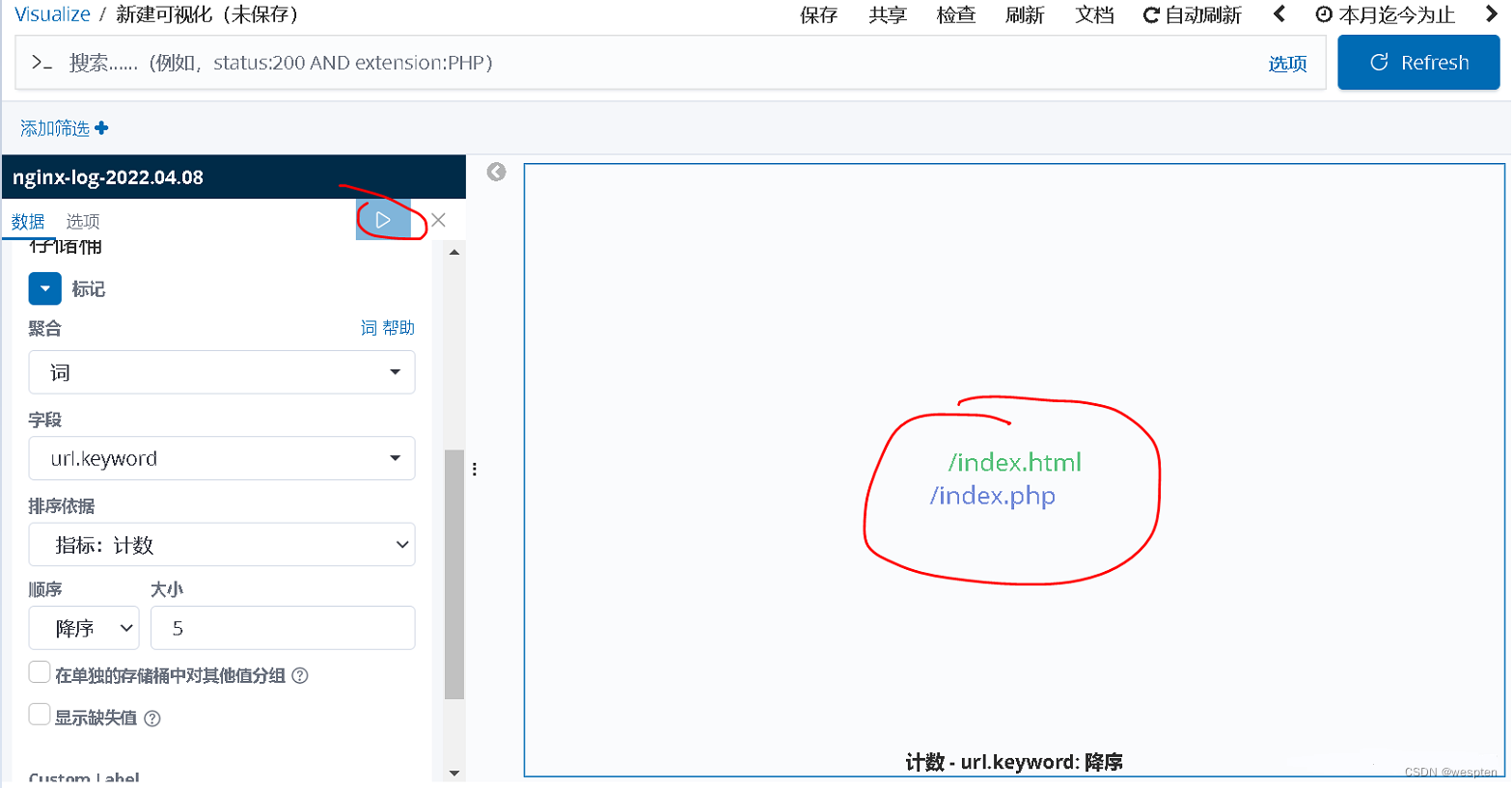
最后,我们点击右上角的蓝底白色三角符号,会生成视图的预览,如下所示:
我们觉得合适之后,点击上方的保存,即可保存我们创建的视图。
接下来,我们来绘制一下饼状图。
与标签云图的创建过程类似,我们选择好创建视图的类型和索引后,选择视图的参数,如下所示:
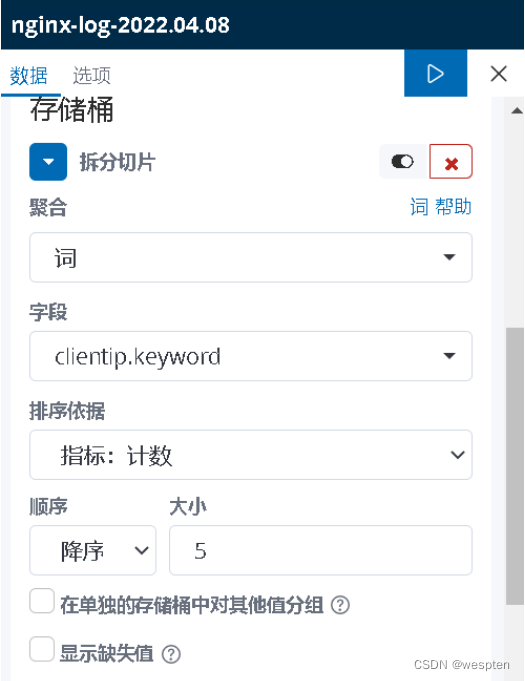
绘制处的饼状图如下所示:

接下来,我们来绘制一下日志条数图。
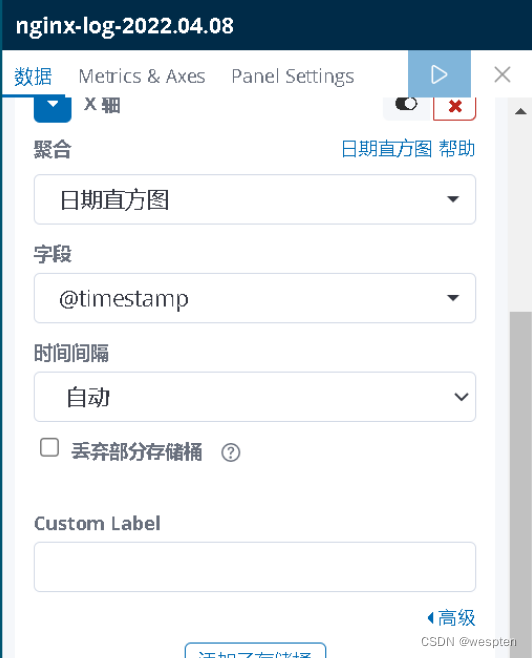
在这里,我们选择列表的类型,添加参数如下:
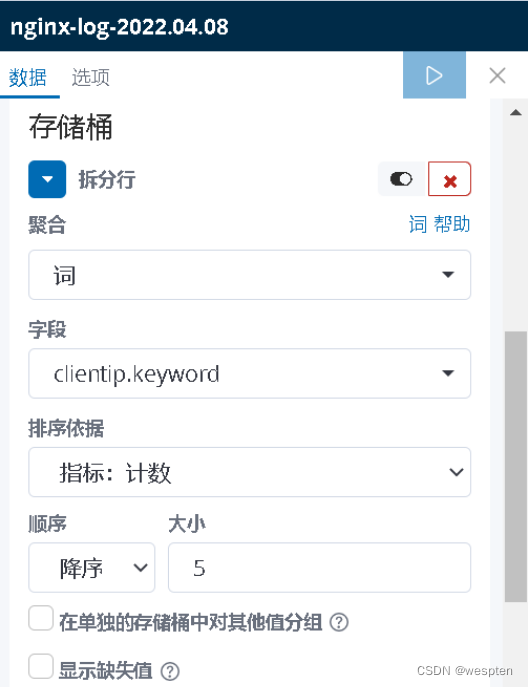
绘图结果如下:

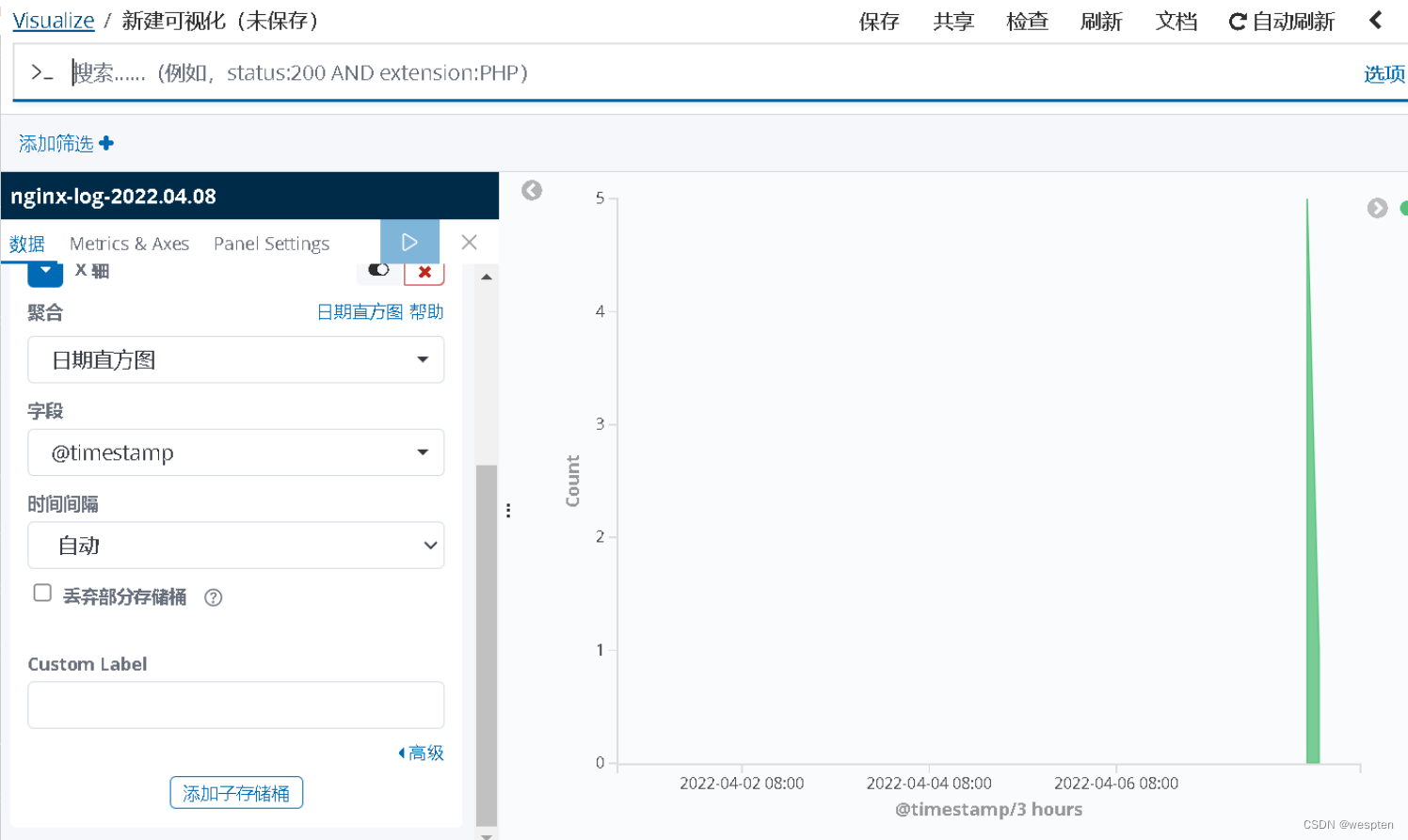
接下来,我们来绘制一下网络流量监控图。
该图的绘制与上类似,绘图参数如下:
绘图结果如下:
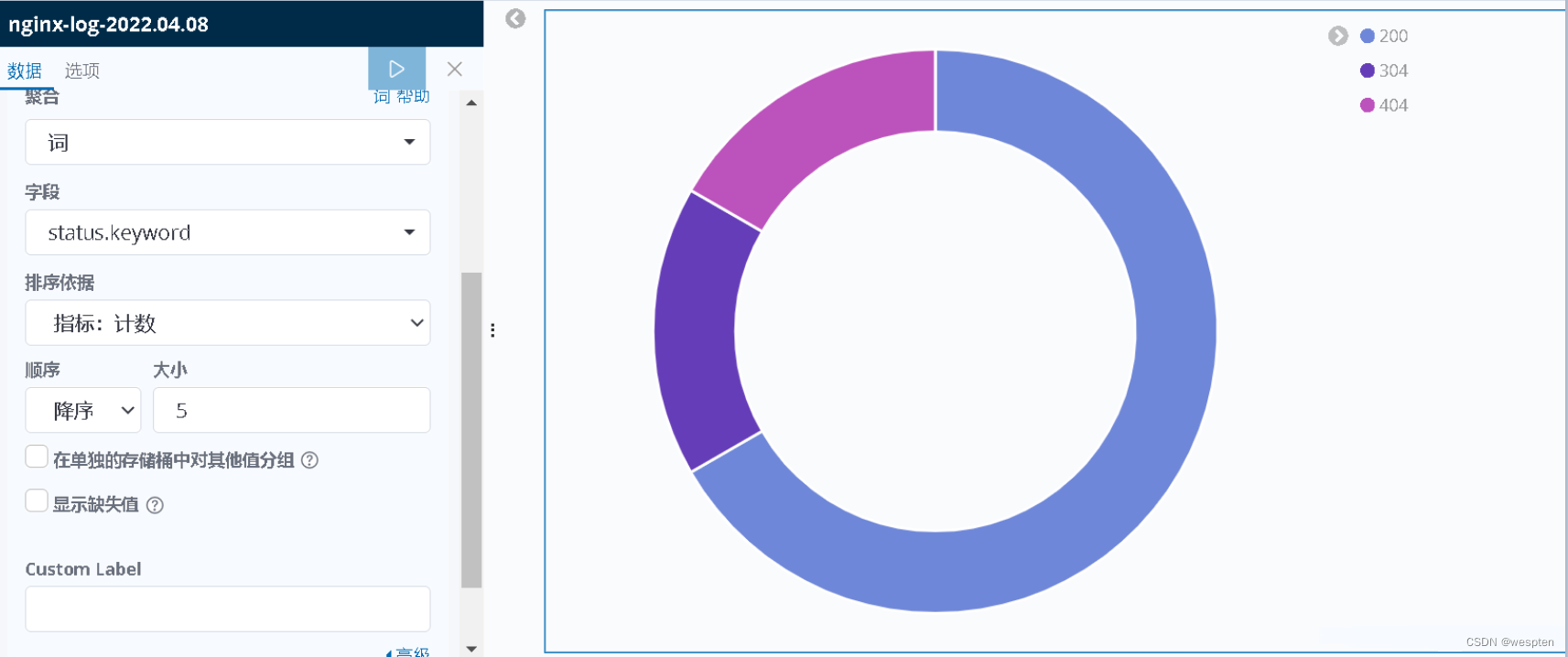
接下来,我们来绘制一下异常状态图。
绘图参数如下:
最后,我们把上述所有视图结合在一起进行展示。
点击Kibana右边的“仪表盘”页面,然后选择创建新的仪表盘,如下所示:
之后,我们选择“添加”,如下所示:
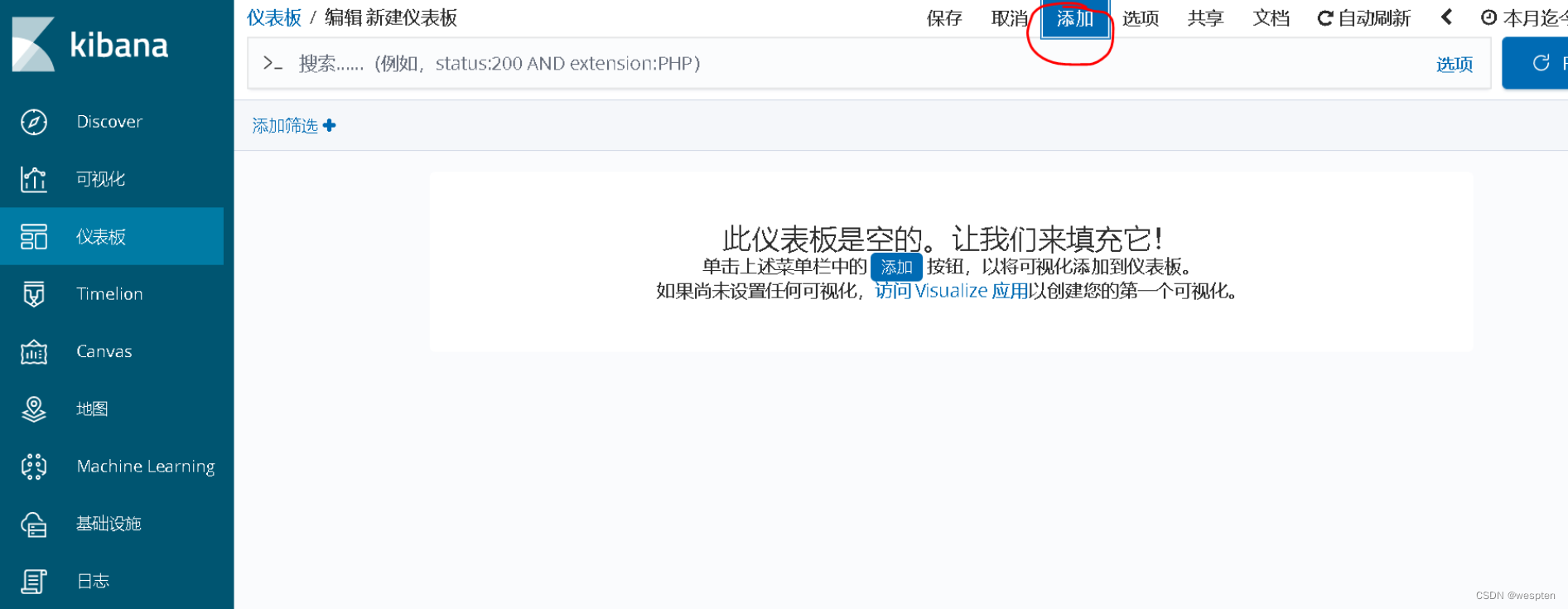
在弹出的窗口中,我们选择好要添加的视图,这些视图就是在上面我们创建的视图,如下所示:
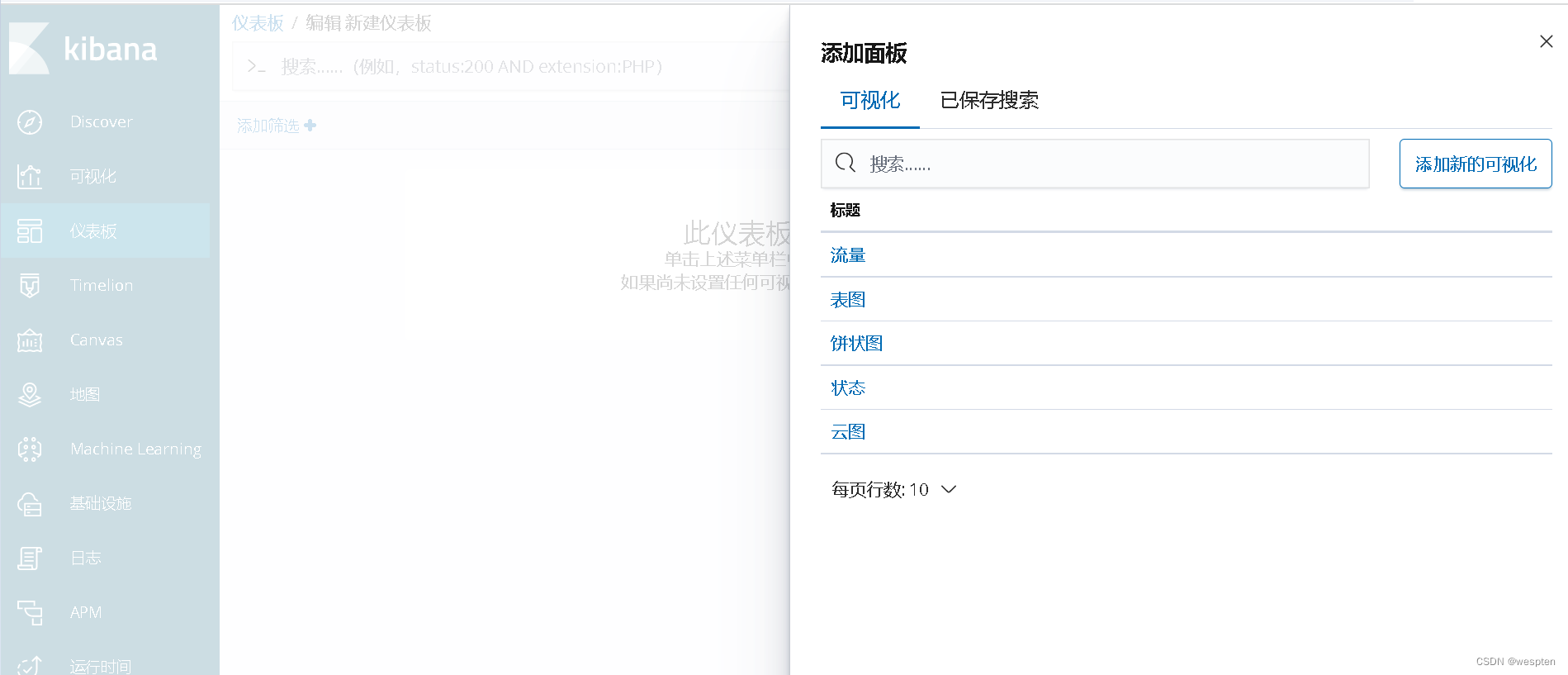
添加完成后,最终仪表盘上出现了我们创建的视图,如下所示:

注意,由于我的日志数量比较少,因此呈现出来效果较差,一个生产环境中的Kibana仪表盘结果如下所示:

使用geoip画访问地域热图:
kibana支持绘制热点地图,所谓热点地图,即根据访问日志的客户端IP地址信息,在一张地图上画出访问客户端的来源,并根据不同的来源密度给予不同的颜色。这样,就可以直观的体现我们服务的客户端地域来源。
要实现这个功能,我们就必须能够根据IP地址来得到该IP地址的地理位置。geoip就是这样一个信息库,我们可以借助geoip来实现热点地图的绘制。
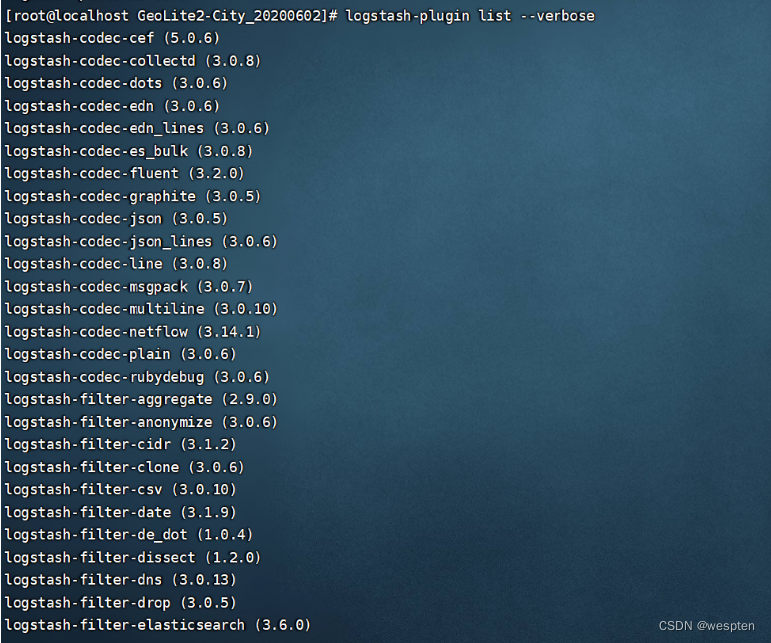
首先,我们来安装一下我们的geoip插件。首先,下载geoip的插件安装包,然后解压。进入解药后的目录后,将mmdb文件放到/etc/elasticsearch/目录下。然后,我们查看logstash的可用插件,执行命令:
logstash-plugin list --verbose执行结果如下所示:
然后,我们安装相关插件,执行命令:
logstash-plugin install logstash-filter-geoip
logstash-plugin install logstash-filter-mutate
logstash-plugin install logstash-filter-useragent执行结果如下所示:

在Logstash的插件安装完成后,接下来,我们来配置Logstash的配置文件,其内容如下所示:
input{
file{
path=>"/var/log/nginx/access.log"
type=>"geoip"
codec=>json
}
}
filter{
geoip{
source=>"clientip"
database=>"/etc/logstash/GeoLite2-City.mmdb"
fields=>["country_name","region_name","city_name","location"]
}
}
output{
elasticsearch{
hosts=>["192.168.136.101:9200"]
index=>"logstash-geoip-%{+YYYY.MM.dd}"
}
}
在上述配置中,input和output相关内容我们在前面的文章中已经详细讲解过,在这里就不过多赘述了。在filter中,我们使用了geoip的过滤插件,并只保留了国家、城市、省份、坐标这四个信息,source参数我们使用的是指定查询日志中的客户端IP地址字段的名称。
完成配置后,我们执行命令:
logstash -f /etc/elasticsearch/conf.d/geoip.conf
Kibana上得到的索引内容如下:
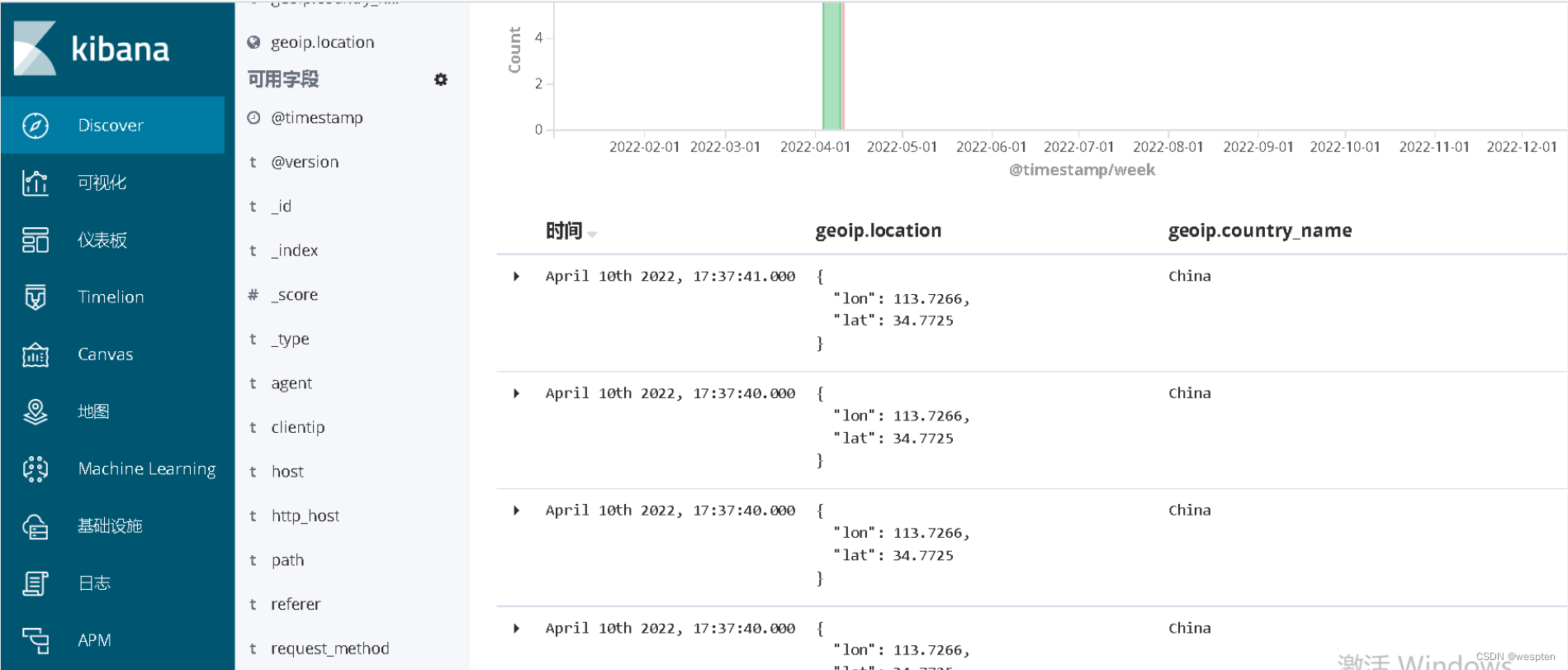
最后,我们使用Kibana来绘图展示一下效果。
首先,我们创建一个坐标地图的可视化,如下所示:
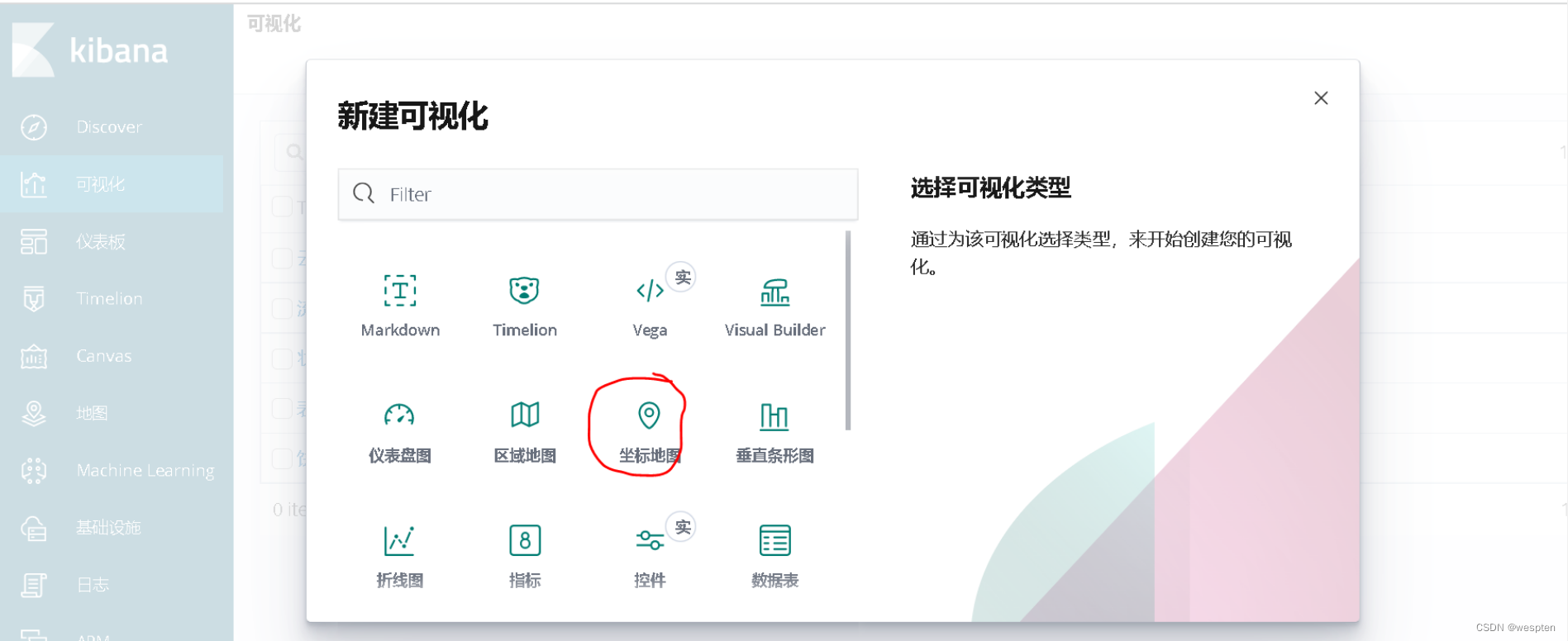
接下来,我们选择默认的数据选项,就可以得到一张地域热图了,结果如下所示:

可以看出,利用Kibana,我们可以绘制处非常绚丽的图标,实现数据可视化的需求。
更多详情,请参考官网:安装 Kibana | Kibana 用户手册 | Elastic
八、快速搭建一套稳定的ELK环境
安装过程可根据官网指导文档:免费且开放的搜索:Elasticsearch、ELK 和 Kibana 的开发者 | Elastic
Welcome to Elastic Docs | Elastic
1、基础环境介绍
系统: Centos7.1
防火墙: 关闭
Sellinux: 关闭
机器环境: 两台
elk-node1: 192.168.1.110 #master机器
elk-node2:192.168.1.111 #slave机器
说明:
master-slave模式:
master收集到日志后,会把一部分数据碎片到salve上(随机的一部分数据);同时,master和slave又都会各自做副本,并把副本放到对方机器上,这样就保证了数据不会丢失。
如果master宕机了,那么客户端在日志采集配置中将elasticsearch主机指向改为slave,就可以保证ELK日志的正常采集和web展示。
由于elk-node1和elk-node2两台是虚拟机,没有外网ip,所以访问需要通过宿主机进行代理转发实现。
2、软件下载
官方下载:Elastic 产品:搜索、分析、日志和安全 | Elastic
注意 JDK需要1.8。
3、ElasticSearch安装
[root@node1 ~]# rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
[root@node1 ~]#wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo
[root@node1 ~]# vim /etc/yum.repos.d/elasticsearch.repo
[elasticsearch-6.x]
name=Elasticsearch repository for 6.x packages
baseurl=https://artifacts.elastic.co/packages/6.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md
[root@node1 ~]# yum install -y elasticsearch安装相关测试软件:
[root@node1 ~]# yum install -y java
[root@node1 ~]# java –version #安装完java后,检测
openjdk version "1.8.0_151"
OpenJDK Runtime Environment (build 1.8.0_151-b12)
OpenJDK 64-Bit Server VM (build 25.151-b12, mixed mode)Elasticsearch配置部署:
[root@node1 ~]# vim /etc/elasticsearch/elasticsearch.yml
cluster.name: my-application # 组名(同一个组,组名必须一致)
node.name: node-1 # 节点名称,建议和主机名一致
path.data: /var/lib/elasticsearch # 数据存放的路径
path.logs: /var/log/elasticsearch # 日志存放的路径
bootstrap.memory_lock: true # 锁住内存,不被使用到交换分区去
network.host: 192.168.80.110 # 网络设置(可以为0.0.0.0监听本地所有地址)
http.port: 9200 # 监听端口启动并查看:
[root@node1 ~]# chown -R elasticsearch.elasticsearch /var/lib/elasticsearch #授权数据目录
[root@node1 ~]# systemctl start elasticsearch
[root@node1 ~]# ls /var/log/elasticsearch/my-application.log #如果启动失败可以查看日志然后通过web访问http://192.168.80.110:9200/(访问的浏览器最好用google浏览器,360有可能打不开),显示如下:
{
"name" : "node-1",
"cluster_name" : "my-application",
"cluster_uuid" : "aHZlsoFWTGCg5wDhjWbgfg",
"version" : {
"number" : "6.0.0",
"build_hash" : "8f0685b",
"build_date" : "2017-11-10T18:41:22.859Z",
"build_snapshot" : false,
"lucene_version" : "7.0.1",
"minimum_wire_compatibility_version" : "5.6.0",
"minimum_index_compatibility_version" : "5.0.0"
},
"tagline" : "You Know, for Search"
}通过命令的方式查看数据:
[root@node2 ~]# curl http://192.168.80.110:9200/_search?pretty
{
"took" : 11,
"timed_out" : false,
"_shards" : {
"total" : 0,
"successful" : 0,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 0,
"max_score" : 0.0,
"hits" : [ ]
}
}在安装过程中大家会遇到以下几个问题:
启动的时候一定要注意,如果es不可以进行root账户启动,还需要重新添加一个账户。
useradd -s /sbin/nologin elk
chown -R elk:elk /usr/local/elasticsearch-6.0.0/
su - elk -s /bin/bash
/usr/local/elasticsearch-6.0.0/bin/elasticsearch -d问题一:
max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536]解决方法:
vi /etc/security/limits.conf
user hard nofile 65536
user soft nofile 65536 问题二:
max number of threads [1024] for user [apps] is too low, increase to at least [2048]解决办法:
vi /etc/security/limits.d/90-nproc.conf
* soft nproc 1024
#修改为
* soft nproc 2048问题三:
max virtual memory areas vm.max_map_count [65530] likely too low, increase to at least [262144]解决办法:
vi /etc/sysctl.conf
添加下面配置:
vm.max_map_count=655360
并执行命令:
sysctl -p4、ElasticSearch插件安装
1)安装elastic-head插件
下载地址:https://github.com/mobz/elasticsearch-head/archive/master.zip
安装:
unzip elasticsearch-head-master.zip
curl --silent --location https://rpm.nodesource.com/setup | bash -
yum install -y nodejs
npm install grunt --save-dev
npm install进入elasticsearch-head-master 文件夹下,编辑 Gruntfile.js文件:增加hostname属性,设置为*:
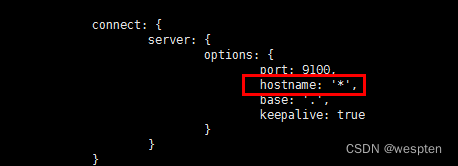
http.cors.enabled: true
http.cors.allow-origin: "*"运行:
./grunt server &2)安装X-Pack插件
[root@node1 ~]# cd /usr/share/elasticsearch/
[root@node1 elasticsearch]# ./bin/elasticsearch-plugin install x-pack
[root@node1 elasticsearch]# bin/elasticsearch
[root@node1 elasticsearch]# bin/x-pack/setup-passwords auto
Initiating the setup of reserved user elastic,kibana,logstash_system passwords.
The passwords will be randomly generated and printed to the console.
Please confirm that you would like to continue [y/N]y
Changed password for user kibana
PASSWORD kibana = Chom^7EknkyAX3bnNpYj
Changed password for user logstash_system
PASSWORD logstash_system = Wkh+xXpEP+u&N-3Q6J+M
Changed password for user elastic
PASSWORD elastic = _56pX&QM2k$eJN!Or8hz5、安装kibana
这个安装比较简单,yum安装即可:
[root@node1 ~]# rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
[root@node1 ~]# vim /etc/yum.repos.d/kibana.repo
[kibana-6.x]
name=Kibana repository for 6.x packages
baseurl=https://artifacts.elastic.co/packages/6.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md
[root@node1 ~]# yum install kibana修改配置:
安装后在kibana.yml文件中指定一下你需要读取的elasticSearch地址和可供外网访问的bind地址就可以了。
elasticsearch.url: http://localhost:9200
//如果是集群则配置master节点
server.host: 0.0.0.0详细信息配置:
[root@node1 ~]# cd /etc/kibana/
[root@node1 kibana]# cat kibana.yml|egrep -v "^#|^$"
server.port: 5601
server.host: "0.0.0.0"
elasticsearch.url: "http://192.168.80.110:9200"
kibana.index: ".kibana"
elasticsearch.username: "elastic"
elasticsearch.password: "_56pX&QM2k$eJN!Or8hz"
[root@node1 ~]# cd /usr/share/kibana/
[root@node1 kibana]# ./bin/kibana #启动kibana启动命令:
./kibana接下来我们在本机的/logs文件夹下创建一个简单的1.log文件,内容为“hello world”,然后在kibana上将logstash-* 改成 log* ,create按钮就会自动出来。
echo 'hello world' > 1.log访问:
用户名密码为前面使用bin/x-pack/setup-passwords auto生成的密码:kibana = Chom^7EknkyAX3bnNpYj
6、logstash安装
1)安装
[root@node1 ~]# rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
[root@node1 ~]# vim /etc/yum.repos.d/logstash.repo
[logstash-6.x]
name=Elastic repository for 6.x packages
baseurl=https://artifacts.elastic.co/packages/6.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md
[root@node1 ~]# yum install logstash2)bin目录下启动logstash
配置文件设置为conf/logstash.conf。
启动命令:
./logstash -f ../config/logstash.conf配置多个文件:
./logstash -f ../config 指定启动目录然后启动目录下配置多个*.conf文件,里面指定不同的logpath。
3)数据测试
在config目录建:logstash.conf。
[root@node1 ~]# cd /usr/share/logstash/
[root@node1 logstash]# mkdir conf
[root@node1 logstash]# vim conf/logstash-simple1.conf #创建配置文件
input { stdin { } }
output {
elasticsearch { hosts => ["192.168.80.110:9200"] }
stdout { codec => rubydebug }
}
[root@node1 logstash]# ./bin/logstash -f conf/logstash-simple1.conf #指定配置启动出现错误:
WARNING: Could not find logstash.yml which is typically located in $LS_HOME/config or /etc/logstash. You can specify the path using --path.settings. Continuing using the defaults解决:
cd /usr/share/logstash
ln -s /etc/logstash ./config
./bin/logstash -e 'input { stdin{} } output { stdout{} }'4)input、filter、output 模块说明
其中 input 是吸取 logs 文件下的所有log后缀的日志文件,filter是一个过滤函数,配置则可进行个性化过滤。output 配置了导入到 hosts为127.0.0.1:9200 的 elasticsearch 中,每天一个索引:
input {
file {
type => "log"
path => "/apps/svr/servers/logs/*.log"
start_position => "beginning"
}
}
output {
stdout {
codec => rubydebug { }
}
elasticsearch {
hosts => "127.0.0.1"
index => "log-%{+YYYY.MM.dd}"
}
}说明:start_position是监听的位置,默认是end,即一个文件如果没有记录它的读取信息,则从文件的末尾开始读取,也就是说,仅仅读取新添加的内容。对于一些更新的日志类型的监听,通常直接使用end就可以了;相反,beginning就会从一个文件的头开始读取。但是如果记录过文件的读取信息,则不会从最开始读取。重启读取信息不会丢失。
7、FileBeat和Logstash如何集成
Filebeat作为轻量级的logs shipper,帮助用户将无数client端上的log文件以一种轻量级的方式转发并集中日志和文件到ELK stack中,不能很好的支持过滤等个性化需求。一般可采取fileBeat收集服务器日志,发送到Logstash中进行果过滤。
集成:安装好fileBeat后只需要在logstash上面修改下input,改为从fileBeat读取即可:
input {
beats {
port => filebeat的端口号,默认为5044
}
}九、ELK与Zabbix整合
1、ELK与zabbix有什么关系
ELK大家应该比较熟悉了,zabbix应该也不陌生,那么将ELK和zabbix放到一起的话,可能大家就有疑问了?这两个放到一起是什么目的呢,听我细细道来。
ELK是一套日志收集套件,它其实有由Elasticsearch、Logstash和Kibana三个软件组成,通过ELK可以收集系统日志、网站日志、应用系统日志等各种日志数据,并且还可以对日志进行过滤、清洗,然后进行集中存放并可用于实时检索、分析。这是ELK的基础功能。
但是有些时候,我们希望在收集日志的时候,能够将日志中的异常信息(警告、错误、失败等信息)及时的提取出来,因为日志中的异常信息意味着操作系统、应用程序可能存在故障,如果能将日志中的故障信息及时的告知运维人员,那么运维就可以第一时间去进行故障排查和处理,进而也就可以避免很多故障的发生。
那么如何才能做到将ELK收集的日志数据中出现的异常信息及时的告知运维人员呢,这就需要用到zabbix了,ELK(更确切的说应该是logstash)可以实时的读取日志的内容,并且还可以过滤日志信息,通过ELK的读取和过滤功能,就可以将日志中的一些异常关键字(error、failed、OutOff、Warning)过滤出来,然后通过logstash的zabbix插件将这个错误日志信息发送给zabbix,那么zabbix在接收到这个数据后,结合自身的机制,然后发起告警动作,这样就实现了日志异常zabbix实时告警的功能了。
2、Logstash与zabbix插件的使用
Logstash支持多种输出介质,比如syslog、HTTP、TCP、elasticsearch、kafka等,而有时候我们想将收集到的日志中一些错误信息输出,并告警时,就用到了logstash-output-zabbix这个插件,此插件可以将Logstash与zabbix进行整合,也就是将Logstash收集到的数据进行过滤,将有错误标识的日志输出到zabbix中,最后通过zabbix的告警机制进行触发、告警。
logstash-output-zabbix是一个社区维护的插件,它默认没有在Logstash中安装,但是安装起来也很容易,直接在logstash中运行如下命令即可:
/usr/local/logstash/bin/logstash-plugin install logstash-output-zabbix其中,/usr/local/logstash是Logstash的安装目录。
此外,logstash-plugin命令还有多种用法,我们来看一下。
1)列出目前已经安装的插件
将列出所有已安装的插件:
/usr/local/logstash/bin/logstash-plugin list将列出已安装的插件及版本信息:
/usr/local/logstash/bin/logstash-plugin list --verbose将列出包含namefragment的所有已安装插件:
/usr/local/logstash/bin/logstash-plugin list "http" 将列出特定组的所有已安装插件( input,filter,codec,output):
/usr/local/logstash/bin/logstash-plugin list --group input2)安装插件
要安装某个插件,例如安装kafka插件,可执行如下命令:
/usr/local/logstash/bin/logstash-plugin install logstash-output-kafka要使用此命令安装插件,需要你的电脑可以访问互联网。此插件安装方法,会检索托管在公共存储库(RubyGems.org)上的插件,然后下载到本地机器并在Logstash安装之上进行自动安装。
3)更新插件
每个插件有自己的发布周期和版本更新,这些更新通常是独立于Logstash的发布周期的。因此,有时候需要单独更新插件,可以使用update子命令获得最新版本的插件。
将更新所有已安装的插件:
/usr/local/logstash/bin/logstash-plugin update 将仅更新指定的插件:
/usr/local/logstash/bin/logstash-plugin update logstash-output-kafka4)删除插件
如果需要从Logstash插件中删除插件,可执行如下命令:
/usr/local/logstash/bin/logstash-plugin remove logstash-output-kafka这样就删除了logstash-output-kafka插件。
3、logstash-output-zabbix插件的使用
logstash-output-zabbix安装好之后,就可以在logstash配置文件中使用了。
下面是一个logstash-output-zabbix使用的例子:
zabbix {
zabbix_host => "[@metadata][zabbix_host]"
zabbix_key => "[@metadata][zabbix_key]"
zabbix_server_host => "x.x.x.x"
zabbix_server_port => "xxxx"
zabbix_value => "xxxx"
}其中:
zabbix_host:表示Zabbix主机名字段名称, 可以是单独的一个字段, 也可以是 @metadata 字段的子字段, 是必需的设置,没有默认值。
zabbix_key:表示Zabbix项目键的值,也就是zabbix中的item,此字段可以是单独的一个字段, 也可以是 @metadata 字段的子字段,没有默认值。
zabbix_server_host:表示Zabbix服务器的IP或可解析主机名,默认值是 "localhost",需要设置为zabbix server服务器所在的地址。
zabbix_server_port:表示Zabbix服务器开启的监听端口,默认值是10051。
zabbix_value:表示要发送给zabbix item监控项的值对应的字段名称,默认值是 "message",也就是将"message"字段的内容发送给上面zabbix_key定义的zabbix item监控项,当然也可以指定一个具体的字段内容发送给zabbix item监控项。
4、将logstash与zabbix进行整合
这里我们仍以ELK+Filebeat+Kafka+ZooKeeper构建大数据日志分析平台一节的架构进行讲述,由于日志已经全部进入kafka集群中,所以接下来对日志的过滤,然后选择关键字进行告警的工作,就可以在logstash上完成。
先说明一下我们的应用需求:通过对系统日志文件的监控,然后去过滤日志信息中的一些关键字,例如ERR、error、ERROR、Failed、WARNING等,将日志中这些信息过滤出来,然后发送到zabbix上,最后借助zabbix的报警功能实现对系统日志中有上述关键字的告警。
对于过滤关键字,进行告警,不同的业务系统,可能关键字不尽相同,例如对http系统,可能需要过滤500、403、503等这些错误码,对于java相关的系统,可能需要过滤OutOfMemoryError、PermGen、Java heap等关键字。在某些业务系统的日志输出中,可能还有一些自定义的错误信息,那么这些也需要作为过滤关键字来使用。
1)配置logstash事件配置文件
接下来就是创建一个logstash事件配置文件,这里将配置文件分成三个部分来介绍,首先是input部分,内容如下:
input {
file {
path => ["/var/log/secure"]
type => "system"
start_position => "beginning"
}
}input部分是从/var/log/secure文件中读取数据,start_position 表示从secure文件开头读取内容。
接着是filter部分,内容如下:
filter {
grok {
match => { "message" => "%{SYSLOGTIMESTAMP:message_timestamp} %{SYSLOGHOST:hostname} %{DATA:message_program}(?:\[%{POSINT:messag
e_pid}\])?: %{GREEDYDATA:message_content}" } #这里通过grok对message字段的数据进行字段划分,这里将message字段划分了5个子字段。其中,message_content字段会在output中用到。
}
mutate {
add_field => [ "[zabbix_key]", "oslogs" ] #新增的字段,字段名是zabbix_key,值为oslogs。
add_field => [ "[zabbix_host]", "%{host}" ] #新增的字段,字段名是zabbix_host,值可以在这里直接定义,也可以引用字段变量来获取。这里的%{host}获取的就是日志数据的主机名,这个主机名与zabbix web中“主机名称”需要保持一致。
}
mutate { #这里是删除不需要的字段
remove_field => "@version"
remove_field => "message"
}
date { #这里是对日志输出中的日期字段进行转换,其中message_timestamp字段是默认输出的时间日期字段,将这个字段的值传给 @timestamp字段。
match => [ "message_timestamp","MMM d HH:mm:ss", "MMM dd HH:mm:ss", "ISO8601"]
}
}filter部分是个重点,首先有个if判断,注意这里对字段的应用方式,[fields][log_topic]这个字段是在filebeat中定义的,使用if判断可以对多个日志类别进行过滤、分析,根据不同字段的标识区分不同的任务。
在这个部分中,重点关注的是message_timestamp字段、message_content字段。
最后是output部分,内容如下:
output {
if [message_content] =~ /(ERR|error|ERROR|Failed)/ { #定义在message_content字段中,需要过滤的关键字信息,也就是在message_content字段中出现给出的这些关键字,那么就将这些信息发送给zabbix。
zabbix {
zabbix_host => "[zabbix_host]" #这个zabbix_host将获取上面filter部分定义的字段变量%{[host][name]的值
zabbix_key => "[zabbix_key]" #这个zabbix_key将获取上面filter部分中给出的值
zabbix_server_host => "172.16.213.140" #这是指定zabbix server的IP地址
zabbix_server_port => "10051" #这是指定zabbix server的监听端口
zabbix_value => "message_content" #这个很重要,指定要传给zabbix监控项item(oslogs)的值, zabbix_value默认的值是"message"字段,因为上面我们已经删除了"message"字段,因此,这里需要重新指定,根据上面filter部分对"message"字段的内容划分,这里指定为"message_content"字段,其实,"message_content"字段输出的就是服务器上具体的日志内容。
}
}
#stdout { codec => rubydebug } #这里是开启调试模式,当第一次配置的时候,建议开启,这样过滤后的日志信息直接输出的屏幕,方便进行调试,调试成功后,即可关闭。
}将上面三部分内容合并到一个文件file_to_zabbix.conf中,然后启动logstash服务:
[root@logstashserver ~]#cd /usr/local/logstash
[root@logstashserver logstash]#nohup bin/logstash -f config/file_to_zabbix.conf --path.data /data/osdata &这里的--path.data是指定此logstash进程的数据存储目录,用于在一个服务器上启动多个logstash进程的环境中。
2)zabbix平台配置日志告警
登录zabbix web平台,选择配置--->模板--->创建模板,名称定为logstash-output-zabbix。
如下图所示:

接着,在此模块下创建一个应用集,点击应用集----->创建应用集,如下图所示:
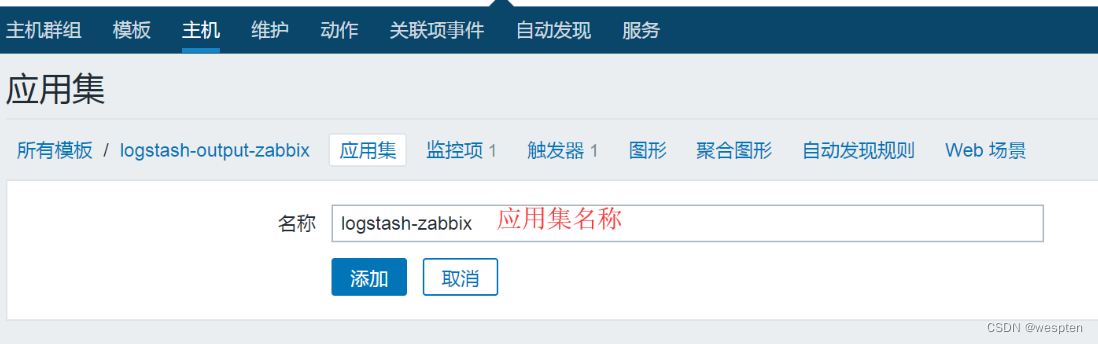
然后,在此模块下创建一个监控项,点击监控项----->创建监控项,如下图所示:

到此为止,zabbix监控logstash的日志数据配置完成。
这里我们模拟一个故障,在任意主机通过ssh登录172.16.213.157主机,然后输入一个错误密码,让系统的/var/log/secure文件产生错误日志,然后看看logstash是否能够过滤到,是否能够发送到zabbix中。
首先让系统文件/var/log/secure产生类似如下内容:
Sep 5 16:01:04 localhost sshd[27159]: pam_unix(sshd:auth): authentication failure; logname= uid=0 euid=0 tty=ssh ruser= rhost=172.16.213.127 user=root
Sep 5 16:01:06 localhost sshd[27159]: Failed password for root from 172.16.213.127 port 59913 ssh2这里面有我们要过滤的关键字Failed,因此logstash会将此内容过滤出来,发送到zabbix上。
接着,登录zabbix web平台,点击监测中----->最新数据,如果zabbix能够接收到日志,就可以看到下图的最新数据:

点击历史记录,可以查看详细内容,如下图所示:
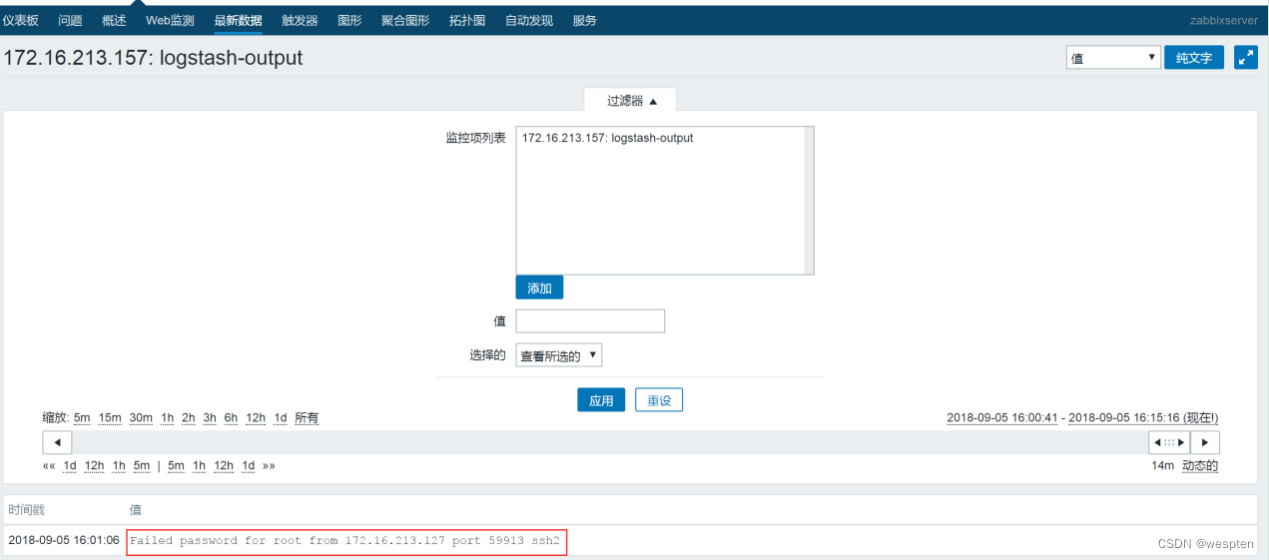
可以看到,红框中的内容就是在logstash中定义的message_content字段的内容。
到这里为止,zabbix已经可以收到logstash的发送过来的数据了,但是要实现报警,还需要在zabbix中创建一个触发器,进入配置----->模板,选择logstash-output-zabbix这个模板,然后点击上面的触发器,继续点击右上角的创建触发器,如下图所示:


这里注意触发器创建中,表达式的写法,这里触发器的触发条件是:如果接收到logstash发送过来的数据,就进行告警,也就是说接收到的数据,如果长度大于0就告警。
触发器配置完成后,如果配置正常,就会进行告警了,告警内容如下图所示:
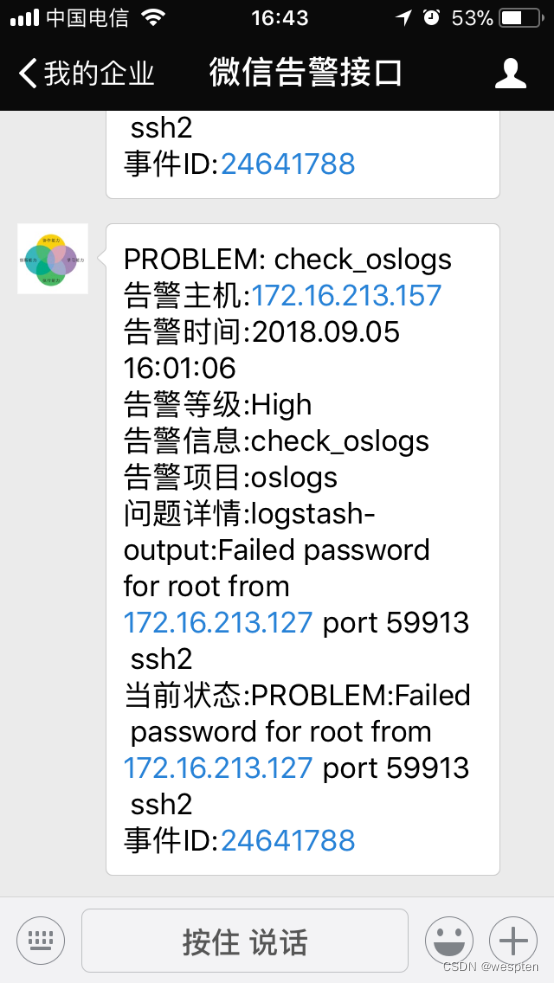
十、ELK+Filebeat+Kafka+ZooKeeper构建大数据日志分析平台案例
1、ELK应用案例

典型ELK应用架构:
此架构稍微有些复杂,因此,这里做一下架构解读。 这个架构图从左到右,总共分为5层,每层实现的功能和含义分别介绍如下:
第一层、数据采集层
数据采集层位于最左边的业务服务器集群上,在每个业务服务器上面安装了filebeat做日志收集,然后把采集到的原始日志发送到Kafka+zookeeper集群上。
第二层、消息队列层
原始日志发送到Kafka+zookeeper集群上后,会进行集中存储,此时,filbeat是消息的生产者,存储的消息可以随时被消费。
第三层、数据分析层
Logstash作为消费者,会去Kafka+zookeeper集群节点实时拉取原始日志,然后将获取到的原始日志根据规则进行分析、清洗、过滤,最后将清洗好的日志转发至Elasticsearch集群。
第四层、数据持久化存储
Elasticsearch集群在接收到logstash发送过来的数据后,执行写磁盘,建索引库等操作,最后将结构化的数据存储到Elasticsearch集群上。
第五层、数据查询、展示层
Kibana是一个可视化的数据展示平台,当有数据检索请求时,它从Elasticsearch集群上读取数据,然后进行可视化出图和多维度分析。
2、环境与角色说明
1. 服务器环境与角色
操作系统统一采用Centos7.5版本,各个服务器角色如下表所示:

2. 软件环境与版本
下表详细说明了本节安装软件对应的名称和版本号,其中,ELK三款软件推荐选择一样的版本,这里选择的是6.3.2版本。
3、安装JDK以及设置环境变量
1. 选择合适版本并下载JDK
Zookeeper 、elasticsearch和Logstash都依赖于Java环境,并且elasticsearch和Logstash要求JDK版本至少在JDK1.7或者以上,因此,在安装zookeeper、Elasticsearch和Logstash的机器上,必须要安装JDK,一般推荐使用最新版本的JDK,这里我们使用JDK1.8版本,可以选择使用Oracle JDK1.8 或者Open JDK1.8。这里我们使用Oracle JDK1.8。
从Oracle官网下载linux-64版本的JDK,下载时,选择适合自己机器运行环境的版本,oracle官网提供的JDK都是二进制版本的,因此,JDK的安装非常简单,只需将下载下来的程序包解压到相应的目录即可。
安装过程如下:
[root@localhost ~]# mkdir /usr/java
[root@localhost ~]# tar -zxvf jdk-8u152-linux-x64.tar.gz -C /usr/java/2. 设置JDK的环境变量
要让程序能够识别JDK路径,需要设置环境变量,这里我们将JDK环境变量设置到/etc/profile文件中。
添加如下内容到/etc/profile文件最后:
export JAVA_HOME=/usr/java/jdk1.8.0_152
export PATH=$PATH:$JAVA_HOME/bin
exportCLASSPATH=.:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib/dt.jar:$CLASSPATH然后执行如下命令让设置生效:
[root@localhost ~]# source /etc/profile4、安装并配置elasticsearch集群
1. elasticsearch集群的架构与角色
在ElasticSearch的架构中,有三类角色,分别是Client Node、Data Node和Master Node,搜索查询的请求一般是经过Client Node来向Data Node获取数据,而索引查询首先请求Master Node节点,然后Master Node将请求分配到多个Data Node节点完成一次索引查询。

集群中每个角色的含义介绍如下:
master node:
可以理解为主节点,主要用于元数据(metadata)的处理,比如索引的新增、删除、分片分配等,以及管理集群各个节点的状态。elasticsearch集群中可以定义多个主节点,但是,在同一时刻,只有一个主节点起作用,其它定义的主节点,是作为主节点的候选节点存在。当一个主节点故障后,集群会从候选主节点中选举出新的主节点。
data node:
数据节点,这些节点上保存了数据分片。它负责数据相关操作,比如分片的CRUD、搜索和整合等操作。数据节点上面执行的操作都比较消耗 CPU、内存和I/O资源,因此数据节点服务器要选择较好的硬件配置,才能获取高效的存储和分析性能。
client node:
客户端节点,属于可选节点,是作为任务分发用的,它里面也会存元数据,但是它不会对元数据做任何修改。client node存在的好处是可以分担data node的一部分压力,因为elasticsearch的查询是两层汇聚的结果,第一层是在data node上做查询结果汇聚,然后把结果发给client node,client node接收到data node发来的结果后再做第二次的汇聚,然后把最终的查询结果返回给用户。这样,client node就替data node分担了部分压力。
2. 安装elasticsearch与授权
elasticsearch的安装非常简单,首先从官网https://www.elastic.co/下载页面找到适合的版本,可选择zip、tar、rpm等格式的安装包下载,这里我们下载的软件包为elasticsearch-6.3.2.tar.gz。安装过程如下:
[root@localhost ~]# tar -zxvf elasticsearch-6.3.2.tar.gz -C /usr/local
[root@localhost ~]# mv /usr/local/elasticsearch-6.3.2 /usr/local/elasticsearch这里我们将elasticsearch安装到了/usr/local目录下。
由于elasticSearch可以接收用户输入的脚本并且执行,为了系统安全考虑,需要创建一个单独的用户用来运行elasticSearch,这里创建的普通用户是elasticsearch,操作如下:
[root@localhost ~]# useradd elasticsearch然后将elasticsearch的安装目录都授权给elasticsearch用户,操作如下:
[root@localhost ~]# chown -R elasticsearch:elasticsearch /usr/local/elasticsearch3. 操作系统调优
操作系统以及JVM调优主要是针对安装elasticsearch的机器。对于操作系统,需要调整几个内核参数,将下面内容添加到/etc/sysctl.conf文件中:
fs.file-max=655360
vm.max_map_count = 262144fs.file-max主要是配置系统最大打开文件描述符数,建议修改为655360或者更高,vm.max_map_count影响Java线程数量,用于限制一个进程可以拥有的VMA(虚拟内存区域)的大小,系统默认是65530,建议修改成262144或者更高。
另外,还需要调整进程最大打开文件描述符(nofile)、最大用户进程数(nproc)和最大锁定内存地址空间(memlock),添加如下内容到/etc/security/limits.conf文件中:
* soft nproc 20480
* hard nproc 20480
* soft nofile 65536
* hard nofile 65536
* soft memlock unlimited
* hard memlock unlimited最后,还需要修改/etc/security/limits.d/20-nproc.conf文件(centos7.x系统),将:
* soft nproc 4096修改为:
* soft nproc 20480或者直接删除/etc/security/limits.d/20-nproc.conf文件也行。
4. JVM调优
JVM调优主要是针对elasticsearch的JVM内存资源进行优化,elasticsearch的内存资源配置文件为jvm.options,此文件位于/usr/local/elasticsearch/config目录下,打开此文件,修改如下内容:
-Xms2g
-Xmx2g可以看到,默认JVM内存为2g,可根据服务器内存大小,修改为合适的值。一般设置为服务器物理内存的一半最佳。
5. 配置elasticsearch
elasticsearch的配置文件均在elasticsearch根目录下的config文件夹,这里是/usr/local/elasticsearch/config目录,主要有jvm.options、elasticsearch.yml和log4j2.properties三个主要配置文件。这里重点介绍elasticsearch.yml一些重要的配置项及其含义。
这里配置的elasticsearch.yml文件内容如下:
cluster.name: elkbigdata
node.name: server1
node.master: true
node.data: true
path.data: /data1/elasticsearch,/data2/elasticsearch
path.logs: /usr/local/elasticsearch/logs
bootstrap.memory_lock: true
network.host: 0.0.0.0
http.port: 9200
discovery.zen.minimum_master_nodes: 1
discovery.zen.ping.unicast.hosts: ["172.16.213.37:9300","172.16.213.78:9300"]1)cluster.name:elkbigdata
配置elasticsearch集群名称,默认是elasticsearch。这里修改为elkbigdata,elasticsearch会自动发现在同一网段下的集群名为elkbigdata的主机。
2)node.name:server1
节点名,任意指定一个即可,这里是server1,我们这个集群环境中有三个节点,分别是server1、server2和server3,记得根据主机的不同,要修改相应的节点名称。
3)node.master:true
指定该节点是否有资格被选举成为master,默认是true,elasticsearch集群中默认第一台启动的机器为master角色,如果这台服务器宕机就会重新选举新的master。
4)node.data:true
指定该节点是否存储索引数据,默认为true,表示数据存储节点,如果节点配置node.master:false并且node.data: false,则该节点就是client node。这个client node类似于一个“路由器”,负责将集群层面的请求转发到主节点,将数据相关的请求转发到数据节点。
5)path.data:/data1/elasticsearch,/data2/elasticsearch
设置索引数据的存储路径,默认是elasticsearch根目录下的data文件夹,这里自定义了两个路径,可以设置多个存储路径,用逗号隔开。
6)path.logs:/usr/local/elasticsearch/logs
设置日志文件的存储路径,默认是elasticsearch根目录下的logs文件夹。
7)bootstrap.memory_lock:true
此配置项一般设置为true用来锁住物理内存。
linux下可以通过“ulimit -l” 命令查看最大锁定内存地址空间(memlock)是不是unlimited。
8)network.host:0.0.0.0
此配置项用来设置elasticsearch提供服务的IP地址,默认值为0.0.0.0,此参数是在elasticsearch新版本中增加的,此值设置为服务器的内网IP地址即可。
9)http.port:9200
设置elasticsearch对外提供服务的http端口,默认为9200。其实,还有一个端口配置选项transport.tcp.port,此配置项用来设置节点间交互通信的TCP端口,默认是9300。
10)discovery.zen.minimum_master_nodes:1
配置当前集群中最少的master节点数,默认为1,也就是说,elasticsearch集群中master节点数不能低于此值,如果低于此值,elasticsearch集群将停止运行。在三个以上节点的集群环境中,建议配置大一点的值,推荐2至4个为好。
11)discovery.zen.ping.unicast.hosts:["172.16.213.37:9300","172.16.213.78:9300"]
设置集群中master节点的初始列表,可以通过这些节点来自动发现新加入集群的节点。这里需要注意,master节点初始列表中对应的端口是9300。即为集群交互通信端口。
6. 启动elasticsearch
启动elasticsearch服务需要在一个普通用户下完成,如果通过root用户启动elasticsearch的话,可能会收到如下错误:
java.lang.RuntimeException: can not run elasticsearch as root这是出于系统安全考虑,elasticsearch服务必须通过普通用户来启动,这里直接切换到elasticsearch用户下启动elasticsearch集群即可。分别登录到server1、server2和server3三台主机上,执行如下操作:
[root@localhost ~]# su - elasticsearch
[elasticsearch@localhost ~]$ cd /usr/local/elasticsearch/
[elasticsearch@localhost elasticsearch]$ bin/elasticsearch -d其中,“-d”参数的意思是将elasticsearch放到后台运行。
7. 验证elasticsearch集群的正确性
将所有elasticsearch节点的服务启动后,在任意一个节点执行如下命令:
[root@localhost ~]# curl http://172.16.213.77:9200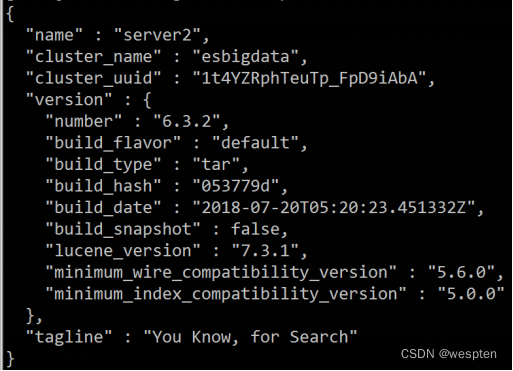
5、安装并配置ZooKeeper集群
对于集群模式下的ZooKeeper部署,官方建议至少要三台服务器,关于服务器的数量,推荐是奇数个(3、5、7、9等等),以实现ZooKeeper集群的高可用,这里使用三台服务器进行部署。
1. 下载与安装zookeeper
ZooKeeper是用Java编写的,需要安装Java运行环境,可以从zookeeper官网https://zookeeper.apache.org/获取zookeeper安装包,这里安装的版本是zookeeper-3.4.11.tar.gz。
将下载下来的安装包直接解压到一个路径下即可完成zookeeper的安装:
[root@localhost ~]# tar -zxvf zookeeper-3.4.11.tar.gz -C /usr/local
[root@localhost ~]# mv /usr/local/zookeeper-3.4.11 /usr/local/zookeeper2. 配置zookeeper
zookeeper安装到了/usr/local目录下,因此,zookeeper的配置模板文件为/usr/local/zookeeper/conf/zoo_sample.cfg,拷贝zoo_sample.cfg并重命名为zoo.cfg,重点配置如下内容:
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/data/zookeeper
clientPort=2181
server.1=172.16.213.51:2888:3888
server.2=172.16.213.109:2888:3888
server.3=172.16.213.75:2888:3888 每个配置项含义如下:
tickTime:zookeeper使用的基本时间度量单位,以毫秒为单位,它用来控制心跳和超时。2000表示2 tickTime。更低的tickTime值可以更快地发现超时问题。
initLimit:这个配置项是用来配置Zookeeper集群中Follower服务器初始化连接到Leader时,最长能忍受多少个心跳时间间隔数(也就是tickTime)。
syncLimit:这个配置项标识Leader与Follower之间发送消息,请求和应答时间长度最长不能超过多少个tickTime的时间长度。
dataDir:必须配置项,用于配置存储快照文件的目录。需要事先创建好这个目录,如果没有配置dataLogDir,那么事务日志也会存储在此目录。
clientPort:zookeeper服务进程监听的TCP端口,默认情况下,服务端会监听2181端口。
server.A=B:C:D:其中A是一个数字,表示这是第几个服务器;B是这个服务器的IP地址;C表示的是这个服务器与集群中的Leader服务器通信的端口;D 表示如果集群中的Leader服务器宕机了,需要一个端口来重新进行选举,选出一个新的 Leader,而这个端口就是用来执行选举时服务器相互通信的端口。
除了修改zoo.cfg配置文件外,集群模式下还要配置一个文件myid,这个文件需要放在dataDir配置项指定的目录下,这个文件里面只有一个数字,如果要写入1,表示第一个服务器,与zoo.cfg文本中的server.1中的1对应,以此类推,在集群的第二个服务器zoo.cfg配置文件中dataDir配置项指定的目录下创建myid文件,写入2,这个2与zoo.cfg文本中的server.2中的2对应。
Zookeeper在启动时会读取这个文件,得到里面的数据与zoo.cfg里面的配置信息比较,从而判断每个zookeeper server的对应关系。 为了保证zookeeper集群配置的规范性,建议将zookeeper集群中每台服务器的安装和配置文件路径都保存一致。
3. 启动zookeeper集群
在三个节点依次执行如下命令,启动Zookeeper服务:
[root@localhost ~]# cd /usr/local/zookeeper/bin
[root@localhost bin]# ./zkServer.sh start
[root@localhost kafka]# jps
23097 QuorumPeerMainZookeeper启动后,通过jps命令(jdk内置命令)可以看到有一个QuorumPeerMain标识,这个就是Zookeeper启动的进程,前面的数字是Zookeeper进程的PID。
有时候为了启动Zookeeper方面,也可以添加zookeeper环境变量到系统的/etc/profile中,这样,在任意路径都可以执行“zkServer.sh start”命令了,添加环境变量的内容为:
export ZOOKEEPER_HOME=/usr/local/zookeeper
export PATH=$PATH:$ZOOKEEPER_HOME/bin6、安装并配置Kafka Broker集群
这里将kafka和zookeeper部署在一起了。另外,由于是部署集群模式的kafka,因此下面的操作需要在每个集群节点都执行一遍。
1. 下载与安装Kafka
可以从kafka官网https://kafka.apache.org/downloads获取kafka安装包,这里推荐的版本是kafka_2.10-0.10.0.1.tgz,将下载下来的安装包直接解压到一个路径下即可完成kafka的安装,这里统一将kafka安装到/usr/local目录下,基本操作过程如下:
[root@localhost ~]# tar -zxvf kafka_2.10-0.10.0.1.tgz -C /usr/local
[root@localhost ~]# mv /usr/local/kafka_2.10-0.10.0.1 /usr/local/kafka这里我们将kafka安装到了/usr/local目录下。
2. 配置kafka集群
这里将kafka安装到/usr/local目录下,因此,kafka的主配置文件为/usr/local/kafka/config/server.properties,这里以节点kafkazk1为例,重点介绍一些常用配置项的含义:
broker.id=1
listeners=PLAINTEXT://172.16.213.51:9092
log.dirs=/usr/local/kafka/logs
num.partitions=6
log.retention.hours=60
log.segment.bytes=1073741824
zookeeper.connect=172.16.213.51:2181,172.16.213.75:2181,172.16.213.109:2181
auto.create.topics.enable=true
delete.topic.enable=true
每个配置项含义如下:
broker.id:每一个broker在集群中的唯一表示,要求是正数。当该服务器的IP地址发生改变时,broker.id没有变化,则不会影响consumers的消息情况。
listeners:设置kafka的监听地址与端口,可以将监听地址设置为主机名或IP地址,这里将监听地址设置为IP地址。
log.dirs:这个参数用于配置kafka保存数据的位置,kafka中所有的消息都会存在这个目录下。可以通过逗号来指定多个路径, kafka会根据最少被使用的原则选择目录分配新的parition。需要注意的是,kafka在分配parition的时候选择的规则不是按照磁盘的空间大小来定的,而是根据分配的 parition的个数多小而定。
num.partitions:这个参数用于设置新创建的topic有多少个分区,可以根据消费者实际情况配置,配置过小会影响消费性能。这里配置6个。
log.retention.hours:这个参数用于配置kafka中消息保存的时间,还支持log.retention.minutes和 log.retention.ms配置项。这三个参数都会控制删除过期数据的时间,推荐使用log.retention.ms。如果多个同时设置,那么会选择最小的那个。
log.segment.bytes:配置partition中每个segment数据文件的大小,默认是1GB,超过这个大小会自动创建一个新的segment file。
zookeeper.connect:这个参数用于指定zookeeper所在的地址,它存储了broker的元信息。 这个值可以通过逗号设置多个值,每个值的格式均为:hostname:port/path,每个部分的含义如下:
hostname:表示zookeeper服务器的主机名或者IP地址,这里设置为IP地址。
port: 表示是zookeeper服务器监听连接的端口号。
/path:表示kafka在zookeeper上的根目录。如果不设置,会使用根目录。
auto.create.topics.enable:这个参数用于设置是否自动创建topic,如果请求一个topic时发现还没有创建, kafka会在broker上自动创建一个topic,如果需要严格的控制topic的创建,那么可以设置auto.create.topics.enable为false,禁止自动创建topic。
delete.topic.enable:在0.8.2版本之后,Kafka提供了删除topic的功能,但是默认并不会直接将topic数据物理删除。如果要从物理上删除(即删除topic后,数据文件也会一同删除),就需要设置此配置项为true。
3. 启动kafka集群
在启动kafka集群前,需要确保ZooKeeper集群已经正常启动。接着,依次在kafka各个节点上执行如下命令即可:
[root@localhost ~]# cd /usr/local/kafka
[root@localhost kafka]# nohup bin/kafka-server-start.sh config/server.properties &
[root@localhost kafka]# jps
21840 Kafka
15593 Jps
15789 QuorumPeerMain这里将kafka放到后台运行,启动后,会在启动kafka的当前目录下生成一个nohup.out文件,可通过此文件查看kafka的启动和运行状态。通过jps指令,可以看到有个Kafka标识,这是kafka进程成功启动的标志。
4. kafka集群基本命令操作
kefka提供了多个命令用于查看、创建、修改、删除topic信息,也可以通过命令测试如何生产消息、消费消息等,这些命令位于kafka安装目录的bin目录下,这里是/usr/local/kafka/bin。登录任意一台kafka集群节点,切换到此目录下,即可进行命令操作。下面列举kafka的一些常用命令的使用方法。
1)显示topic列表;
2)创建一个topic,并指定topic属性(副本数、分区数等);
3)查看某个topic的状态;
4)生产消息;
5)消费消息;
6)删除topic;
7、安装并配置Filebeat
1. 为什么要使用filebeat
Logstash功能虽然强大,但是它依赖java、在数据量大的时候,Logstash进程会消耗过多的系统资源,这将严重影响业务系统的性能,而filebeat就是一个完美的替代者,filebeat是Beat成员之一,基于Go语言,没有任何依赖,配置文件简单,格式明了,同时,filebeat比logstash更加轻量级,所以占用系统资源极少,非常适合安装在生产机器上。
2. 下载与安装filebeat
由于filebeat基于go语言开发,无其他任何依赖,因而安装非常简单,可以从elastic官网https://www.elastic.co/downloads/beats/filebeat 获取filebeat安装包,这里下载的版本是filebeat-6.3.2-linux-x86_64.tar.gz。
将下载下来的安装包直接解压到一个路径下即可完成filebeat的安装。根据前面的规划,将filebeat安装到filebeatserver主机(172.16.213.157)上,这里设定将filebeat安装到/usr/local目录下,基本操作过程如下:
[root@filebeatserver ~]# tar -zxvf filebeat-6.3.2-linux-x86_64.tar.gz -C /usr/local
[root@filebeatserver ~]# mv /usr/local/filebeat-6.3.2-linux-x86_64 /usr/local/filebeat这里我们将filebeat就安装到了/usr/local目录下。
3. 配置filebeat
filebeat的配置文件目录为/usr/local/filebeat/filebeat.yml,这里仅列出常用的配置项,内容如下:
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/messages
- /var/log/secure
fields:
log_topic: osmessages
name: "172.16.213.157"
output.kafka:
enabled: true
hosts: ["172.16.213.51:9092", "172.16.213.75:9092", "172.16.213.109:9092"]
version: "0.10"
topic: '%{[fields][log_topic]}'
partition.round_robin:
reachable_only: true
worker: 2
required_acks: 1
compression: gzip
max_message_bytes: 10000000
logging.level: debug
配置项的含义介绍如下:
filebeat.inputs:用于定义数据原型。
type:指定数据的输入类型,这里是log,即日志,是默认值,还可以指定为stdin,即标准输入。
enabled: true:启用手工配置filebeat,而不是采用模块方式配置filebeat。
paths:用于指定要监控的日志文件,可以指定一个完整路径的文件,也可以是一个模糊匹配格式,例如:
- /data/nginx/logs/nginx_*.log,该配置表示将获取/data/nginx/logs目录下的所有以.log结尾的文件,注意这里有个破折号“-”,要在paths配置项基础上进行缩进,不然启动filebeat会报错,另外破折号前面不能有tab缩进,建议通过空格方式缩进。
- /var/log/*.log,该配置表示将获取/var/log目录的所有子目录中以”.log”结尾的文件,而不会去查找/var/log目录下以”.log”结尾的文件。
name: 设置filebeat收集的日志中对应主机的名字,如果配置为空,则使用该服务器的主机名。这里设置为IP,便于区分多台主机的日志信息。
output.kafka:filebeat支持多种输出,支持向kafka,logstash,elasticsearch输出数据,这里的设置是将数据输出到kafka。
enabled:表明这个模块是启动的。
host: 指定输出数据到kafka集群上,地址为kafka集群IP加端口号。
topic:指定要发送数据给kafka集群的哪个topic,若指定的topic不存在,则会自动创建此topic。注意topic的写法,在filebeat6.x之前版本是通过“%{[type]}”来自动获取document_type配置项的值。而在filebeat6.x之后版本是通过'%{[fields][log_topic]}'来获取日志分类的。
logging.level:定义filebeat的日志输出级别,有critical、error、warning、info、debug五种级别可选,在调试的时候可选择debug模式。
4. 启动filebeat收集日志
所有配置完成之后,就可以启动filebeat,开启收集日志进程了,启动方式如下:
[root@filebeatserver ~]# cd /usr/local/filebeat
[root@filebeatserver filebeat]# nohup ./filebeat -e -c filebeat.yml &这样,就把filebeat进程放到后台运行起来了。启动后,在当前目录下会生成一个nohup.out文件,可以查看filebeat启动日志和运行状态。
5. filebeat输出信息格式解读
这里以操作系统中/var/log/secure文件的日志格式为例,选取一个SSH登录系统失败的日志,内容如下:
Jan 31 17:41:56 localhost sshd[13053]: Failed password for root from 172.16.213.37 port 49560 ssh2filebeat接收到/var/log/secure日志后,会将上面日志发送到kafka集群,在kafka任意一个节点上,消费输出日志内容如下:
{"@timestamp":"2018-08-16T11:27:48.755Z",
"@metadata":{"beat":"filebeat","type":"doc","version":"6.3.2","topic":"osmessages"},
"beat":{"name":"filebeatserver","hostname":"filebeatserver","version":"6.3.2"},
"host":{"name":"filebeatserver"},
"source":"/var/log/secure",
"offset":11326,
"message":"Jan 31 17:41:56 localhost sshd[13053]: Failed password for root from 172.16.213.37 port 49560 ssh2",
"prospector":{"type":"log"},
"input":{"type":"log"},
"fields":{"log_topic":"osmessages"}
}
从这个输出可以看到,输出日志被修改成了JSON格式,日志总共分为10个字段,分别是"@timestamp"、"@metadata"、"beat"、"host"、"source"、"offset"、"message"、"prospector"、"input"和"fields"字段,每个字段含义如下:
@timestamp:时间字段,表示读取到该行内容的时间。
@metadata:元数据字段,此字段只有是跟Logstash进行交互使用。
beat:beat属性信息,包含beat所在的主机名、beat版本等信息。
host: 主机名字段,输出主机名,如果没主机名,输出主机对应的IP。
source: 表示监控的日志文件的全路径。
offset: 表示该行日志的偏移量。
message: 表示真正的日志内容。
prospector:filebeat对应的消息类型。
input:日志输入的类型,可以有多种输入类型,例如Log、Stdin、redis、Docker、TCP/UDP等
fields:topic对应的消息字段或自定义增加的字段。
通过filebeat接收到的内容,默认增加了不少字段,但是有些字段对数据分析来说没有太大用处,所以有时候需要删除这些没用的字段,在filebeat配置文件中添加如下配置,即可删除不需要的字段:
processors:
- drop_fields:
fields: ["beat", "input", "source", "offset"]这个设置表示删除"beat"、"input"、"source"、"offset" 四个字段,其中, @timestamp 和@metadata字段是不能删除的。
做完这个设置后,再次查看kafka中的输出日志,已经不再输出这四个字段信息了。
8、安装并配置Logstash服务
1. 下载与安装Logstash
可以从elastic官网https://www.elastic.co/downloads/logstash 获取logstash安装包,这里下载的版本是logstash-6.3.2.tar.gz。将下载下来的安装包直接解压到一个路径下即可完成logstash的安装。根据前面的规划,将logstash安装到logstashserver主机(172.16.213.120)上,这里统一将logstash安装到/usr/local目录下,基本操作过程如下:
[root@logstashserver ~]# tar -zxvf logstash-6.3.2.tar.gz -C /usr/local
[root@logstashserver ~]# mv /usr/local/logstash-6.3.2.tar.gz /usr/local/logstash
这里我们将logstash安装到了/usr/local目录下。
2. Logstash是怎么工作的
Logstash是一个开源的、服务端的数据处理pipeline(管道),它可以接收多个源的数据、然后对它们进行转换、最终将它们发送到指定类型的目的地。Logstash是通过插件机制实现各种功能的,可以在https://github.com/logstash-plugins 下载各种功能的插件,也可以自行编写插件。
Logstash实现的功能主要分为接收数据、解析过滤并转换数据、输出数据三个部分,对应的插件依次是input插件、filter插件、output插件,其中,filter插件是可选的,其它两个是必须插件。也就是说在一个完整的Logstash配置文件中,必须有input插件和output插件。
3. 常用的input
input插件主要用于接收数据,Logstash支持接收多种数据源,input plugin目前支持将近50种,如下表所示:

常用的有如下几种:
file:读取一个文件,这个读取功能有点类似于linux下面的tail命令,一行一行的实时读取。
syslog:监听系统514端口的syslog messages,并使用RFC3164格式进行解析。
redis:Logstash可以从redis服务器读取数据,此时redis类似于一个消息缓存组件。
kafka:Logstash也可以从kafka集群中读取数据,kafka加Logstash的架构一般用在数据量较大的业务场景,kafka可用作数据的缓冲和存储。
filebeat:filebeat是一个文本日志收集器,性能稳定,并且占用系统资源很少,Logstash可以接收filebeat发送过来的数据。
4. 常用的filter
filter插件主要用于数据的过滤、解析和格式化,也就是将非结构化的数据解析成结构化的、可查询的标准化数据。
常见的filter插件有如下几个:
grok:grok是Logstash最重要的插件,可解析并结构化任意数据,支持正则表达式,并提供了很多内置的规则和模板可供使用。此插件使用最多,但也最复杂。
mutate:此插件提供了丰富的基础类型数据处理能力。包括类型转换,字符串处理和字段处理等。
date:此插件可以用来转换你的日志记录中的时间字符串。
GeoIP:此插件可以根据IP地址提供对应的地域信息,包括国别,省市,经纬度等,对于可视化地图和区域统计非常有用。
5. 常用的output
output插件用于数据的输出,一个Logstash事件可以穿过多个output,直到所有的output处理完毕,这个事件才算结束。输出插件常见的有如下几种:
elasticsearch:发送数据到elasticsearch。
file:发送数据到文件中。
redis:发送数据到redis中,从这里可以看出,redis插件既可以用在input插件中,也可以用在output插件中。
kafka:发送数据到kafka中,与redis插件类似,此插件也可以用在Logstash的输入和输出插件中。
6. Logstash 配置文件入门
这里将kafka安装到/usr/local目录下,因此,kafka的配置文件目录为/usr/local/logstash/config/,其中,jvm.options是设置JVM内存资源的配置文件,logstash.yml是logstash全局属性配置文件,另外还需要自己创建一个logstash事件配置文件,这里介绍下logstash事件配置文件的编写方法和使用方式。
在介绍Logstash配置之前,先来认识一下logstash是如何实现输入和输出的。Logstash提供了一个shell脚本/usr/local/logstash/bin/logstash,可以方便快速的启动一个logstash进程,在Linux命令行下,运行如下命令启动Logstash进程:
[root@logstashserver ~]# cd /usr/local/logstash/
[root@logstashserver logstash]# bin/logstash -e 'input{stdin{}} output{stdout{codec=>rubydebug}}'首先解释下这条命令的含义:
-e代表执行的意思。
input即输入的意思,input里面即是输入的方式,这里选择了stdin,就是标准输入(从终端输入)。
output即输出的意思,output里面是输出的方式,这里选择了stdout,就是标准输出(输出到终端)。
这里的codec是个插件,表明格式。这里放在stdout中,表示输出的格式,rubydebug是专门用来做测试的格式,一般用来在终端输出JSON格式。
在终端输入信息。这里我们输入"Hello World",按回车,马上就会有返回结果,内容如下:
{
"@version" => "1",
"host" => "logstashserver",
"@timestamp" => 2018-01-26T10:01:45.665Z,
"message" => "Hello World"
}这就是logstash的输出格式。Logstash在输出内容中会给事件添加一些额外信息。
比如"@version"、"host"、"@timestamp" 都是新增的字段, 而最重要的是@timestamp ,用来标记事件的发生时间。由于这个字段涉及到Logstash内部流转,如果给一个字符串字段重命名为@timestamp的话,Logstash就会直接报错。另外,也不能删除这个字段。
在logstash的输出中,常见的字段还有type,表示事件的唯一类型、tags,表示事件的某方面属性,我们可以随意给事件添加字段或者从事件里删除字段。
使用-e参数在命令行中指定配置是很常用的方式,但是如果logstash需要配置更多规则的话,就必须把配置固化到文件里,这就是logstash事件配置文件,如果把上面在命令行执行的logstash命令,写到一个配置文件logstash-simple.conf中,就变成如下内容:
input { stdin { }
}
output {
stdout { codec => rubydebug }
}这就是最简单的Logstash事件配置文件。此时,可以使用logstash的-f参数来读取配置文件,然后启动logstash进程,操作如下:
[root@logstashserver logstash]# bin/logstash -f logstash-simple.conf通过这种方式也可以启动logstash进程,不过这种方式启动的进程是在前台运行的,要放到后台运行,可通过nohup命令实现,操作如下:
[root@logstashserver logstash]# nohup bin/logstash -f logstash-simple.conf &这样,logstash进程就放到了后台运行了,在当前目录会生成一个nohup.out文件,可通过此文件查看logstash进程的启动状态。
7. logstash事件文件配置实例
下面再看另一个logstash事件配置文件,内容如下:
input {
file {
path => "/var/log/messages"
}
}
output {
stdout {
codec => rubydebug
}
}如果需要监控多个文件,可以通过逗号分隔即可,例如:
path => ["/var/log/*.log","/var/log/message","/var/log/secure"]对于output插件,这里仍然采用rubydebug的JSON输出格式,这对于调试logstash输出信息是否正常非常有用。
将上面的配置文件内容保存为logstash_in_stdout.conf,然后启动一个logstash进程,执行如下命令:
[root@logstashserver logstash]# nohup bin/logstash -f logstash_in_stdout.conf &接着开始进行输入、输出测试,这里设定/var/log/messages的输入内容为如下信息(其实就是执行“systemctl stop nginx”命令后/var/log/messages的输出内容):
Aug 19 16:09:12 logstashserver systemd: Stopping The nginx HTTP and reverse proxy server...
Aug 19 16:09:12 logstashserver systemd: Stopped The nginx HTTP and reverse proxy server.然后查看logstash的输出信息,可以看到内容如下:
{
"@version" => "1",
"host" => " logstashserver",
"path" => "/var/log/messages",
"@timestamp" => 2018-08-19T08:09:12.701Z,
"message" => “Aug 19 16:09:12 logstashserver systemd: Stopping The nginx HTTP and reverse proxy server..."
}
{
"@version" => "1",
"host" => " logstashserver",
"path" => "/var/log/messages",
"@timestamp" => 2018-08-19T08:09:12.701Z,
"message" => “Aug 19 16:09:12 logstashserver systemd: Stopped The nginx HTTP and reverse proxy server."
}
接着把logstash_in_stdout.conf文件稍加修改,变成另外一个事件配置文件logstash_in_kafka.conf,内容如下:
input {
file {
path => "/var/log/messages"
}
}
output {
kafka {
bootstrap_servers => "172.16.213.51:9092,172.16.213.75:9092,172.16.213.109:9092"
topic_id => "osmessages"
}
}这个配置文件中,输入input仍然是file,重点看输出插件,这里定义了output的输出源为kafka,通过bootstrap_servers选项指定了kafka集群的IP地址和端口。特别注意这里IP地址的写法,每个IP地址之间通过逗号分隔。
另外,output输出中的topic_id选项,是指定输出到kafka中的哪个topic下,这里是osmessages,如果无此topic,会自动重建topic。
8. 配置logstash作为转发节点
上面对logstash的使用做了一个基础的介绍,现在回到本节介绍的这个案例中,在这个部署架构中,logstash是作为一个二级转发节点使用的,也就是它将kafka作为数据接收源,然后将数据发送到elasticsearch集群中,按照这个需求,新建logstash事件配置文件kafka_os_into_es.conf,内容如下:
input {
kafka {
bootstrap_servers => "172.16.213.51:9092,172.16.213.75:9092,172.16.213.109:9092"
topics => ["osmessages"]
}
}
output {
elasticsearch {
hosts => ["172.16.213.37:9200","172.16.213.77:9200","172.16.213.78:9200"]
index => " osmessageslog-%{+YYYY-MM-dd}"
}
}
9、安装并配置Kibana展示日志数据
1. 下载与安装Kibana
kibana使用JavaScript语言编写,安装部署十分简单,即下即用,可以从elastic官网https://www.elastic.co/cn/downloads/kibana 下载所需的版本,这里需要注意的是Kibana与Elasticsearch的版本必须一致,另外,在安装Kibana时,要确保Elasticsearch、Logstash和kafka已经安装完毕。
这里安装的版本是kibana-6.3.2-linux-x86_64.tar.gz。将下载下来的安装包直接解压到一个路径下即可完成kibana的安装,根据前面的规划,将kibana安装到server2主机(172.16.213.77)上,然后统一将kibana安装到/usr/local目录下,基本操作过程如下:
[root@localhost ~]# tar -zxvf kibana-6.3.2-linux-x86_64.tar.gz -C /usr/local
[root@localhost ~]# mv /usr/local/kibana-6.3.2-linux-x86_64 /usr/local/kibana2. 配置Kibana
由于将Kibana安装到了/usr/local目录下,因此,Kibana的配置文件为/usr/local/kibana/kibana.yml,Kibana配置非常简单,这里仅列出常用的配置项,内容如下:
server.port: 5601
server.host: "172.16.213.77"
elasticsearch.url: "http://172.16.213.37:9200"
kibana.index: ".kibana"其中,每个配置项的含义介绍如下:
server.port:kibana绑定的监听端口,默认是5601。
server.host:kibana绑定的IP地址,如果内网访问,设置为内网地址即可。
elasticsearch.url:kibana访问ElasticSearch的地址,如果是ElasticSearch集群,添加任一集群节点IP即可,官方推荐是设置为ElasticSearch集群中client node角色的节点IP。
kibana.index:用于存储kibana数据信息的索引,这个可以在kibanaweb界面中看到。
3. 启动Kibana服务与web配置
所有配置完成后,就可以启动kibana了,启动kibana服务的命令在/usr/local/kibana/bin目录下,执行如下命令启动kibana服务:
[root@kafkazk2 ~]# cd /usr/local/kibana/
[root@kafkazk2 kibana]# nohup bin/kibana &
[root@kafkazk2 kibana]# ps -ef|grep node
root 6407 1 0 Jan15 ? 00:59:11 bin/../node/bin/node --no-warnings bin/../src/cli
root 7732 32678 0 15:13 pts/0 00:00:00 grep --color=auto node这样,kibana对应的node服务就启动起来了。
10、调试并验证日志数据流向
经过上面的配置过程,大数据日志分析平台已经基本构建完成,由于整个配置架构比较复杂,这里来梳理下各个功能模块的数据和业务流向。
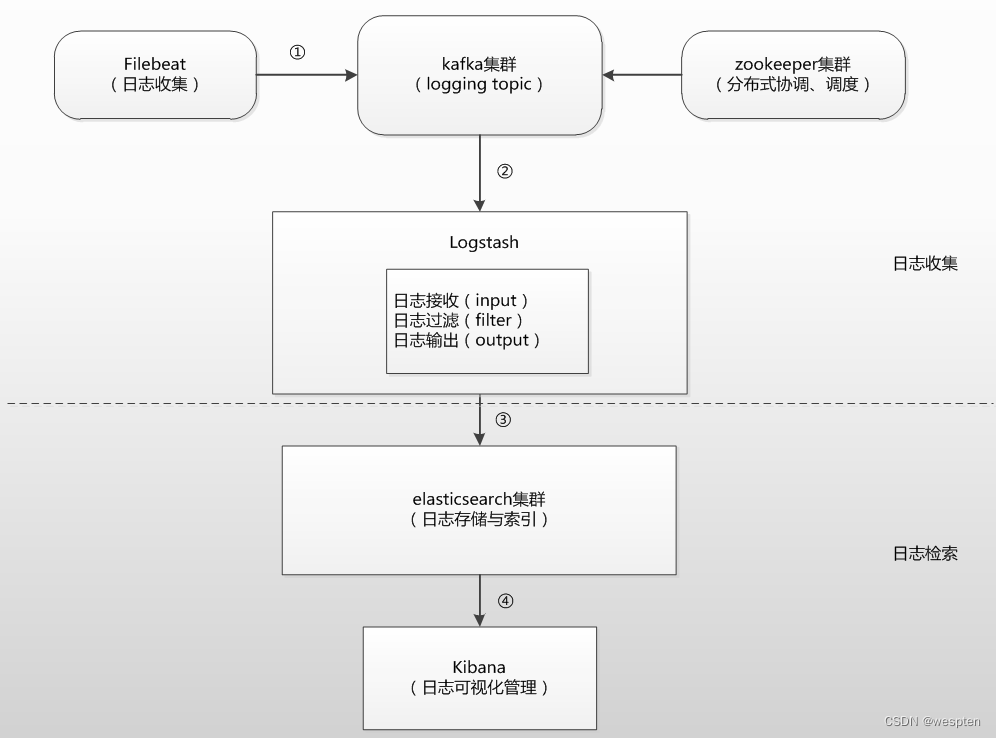
十一、ELK收集应用系统日志实战案例
1、ELK收集Apache访问日志实战案例
1)ELK收集日志的几种方式
ELK收集日志常用的有两种方式,分别是:
1. 不修改源日志的格式,而是通过logstash的grok方式进行过滤、清洗,将原始无规则的日志转换为规则的日志。
2. 修改源日志输出格式,按照需要的日志格式输出规则日志,logstash只负责日志的收集和传输,不对日志做任何的过滤清洗。
这两种方式各有优缺点,第一种方式不用修改原始日志输出格式,直接通过logstash的grok方式进行过滤分析,好处是对线上业务系统无任何影响,缺点是logstash的grok方式在高压力情况下会成为性能瓶颈,如果要分析的日志量超大时,日志过滤分析可能阻塞正常的日志输出。因此,在使用logstash时,能不用grok的,尽量不使用grok过滤功能。
第二种方式缺点是需要事先定义好日志的输出格式,这可能有一定工作量,但优点更明显,因为已经定义好了需要的日志输出格式,logstash只负责日志的收集和传输,这样就大大减轻了logstash的负担,可以更高效的收集和传输日志。另外,目前常见的web服务器,例如apache、nginx等都支持自定义日志输出格式。
因此,在企业实际应用中,第二种方式是首选方案。
2)ELK收集Apache访问日志应用架构
这里我们还是以ELK+Filebeat+Kafka+ZooKeeper构建大数据日志分析平台一节的架构进行介绍:

3)Apache的日志格式与日志变量
apache支持自定义输出日志格式,但是,apache有很多日志变量字段,所以在收集日志前,需要首先确定哪些是我们需要的日志字段,然后将日志格式定下来。要完成这个工作,需要了解apache日志字段定义的方法和日志变量的含义,在apache配置文件httpd.conf中,对日志格式定义的配置项为LogFormat,默认的日志字段定义为如下内容:
LogFormat "%h %l %u %t \"%r\" %>s %b \"%{Referer}i\" \"%{User-Agent}i\"" combined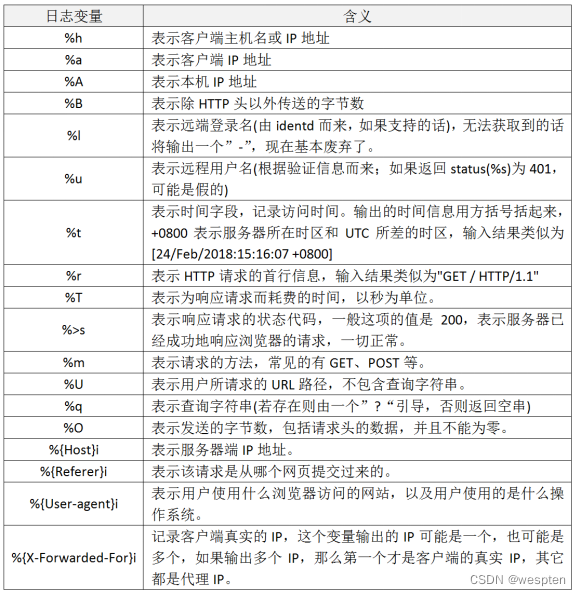
4)自定义Apache日志格式
这里定义将apache日志输出为json格式,下面仅列出apache配置文件httpd.conf中日志格式和日志文件定义部分,定义好的日志格式与日志文件如下:
LogFormat "{\"@timestamp\":\"%{%Y-%m-%dT%H:%M:%S%z}t\",\"client_ip\":\"%{X-Forwarded-For}i\",\"direct_ip\": \"%a\",\"request_time\":%T,\"status\":%>s,\"url\":\"%U%q\",\"method\":\"%m\",\"http_host\":\"%{Host}i\",\"server_ip\":\"%A\",\"http_referer\":\"%{Referer}i\",\"http_user_agent\":\"%{User-agent}i\",\"body_bytes_sent\":\"%B\",\"total_bytes_sent\":\"%O\"}" access_log_json
CustomLog logs/access.log access_log_json这里通过LogFormat指令定义了日志输出格式,在这个自定义日志输出中,定义了13个字段,定义方式为:字段名称:字段内容,字段名称是随意指定的,能代表其含义即可,字段名称和字段内容都通过双引号括起来,而双引号是特殊字符,需要转移,因此,使用了转移字符“\”,每个字段之间通过逗号分隔。此外,还定义了一个时间字段 @timestamp,这个字段的时间格式也是自定义的,此字段记录日志的生成时间,非常有用。CustomLog指令用来指定日志文件的名称和路径。
需要注意的是,上面日志输出字段中用到了body_bytes_sent和total_bytes_sent发送字节数统计字段,这个功能需要apache加载mod_logio.so模块,如果没有加载这个模块的话,需要安装此模块并在httpd.conf文件中加载一下即可。
5)验证日志输出
apache的日志格式配置完成后,重启apache,然后查看输出日志是否正常,如果能看到类似如下内容,表示自定义日志格式输出正常:
{"@timestamp":"2018-02-24T16:15:29+0800","client_ip":"-","direct_ip": "172.16.213.132","request_time":0,"status":200,"url":"/img/guonian.png","method":"GET","http_host":"172.16.213.157","server_ip":"172.16.213.157","http_referer":"http://172.16.213.157/img/","http_user_agent":"Mozilla/5.0 (Windows NT 6.3; Win64; x64; rv:58.0) Gecko/20100101 Firefox/58.0","body_bytes_sent":"1699956","total_bytes_sent":"1700218"}
{"@timestamp":"2018-02-24T16:17:28+0800","client_ip":"172.16.213.132","direct_ip": "172.16.213.84","request_time":0,"status":200,"url":"/img/logstash1.png","method":"GET","http_host":"172.16.213.157","server_ip":"172.16.213.157","http_referer":"http://172.16.213.84/img/","http_user_agent":"Mozilla/5.0 (Windows NT 6.3; Win64; x64; rv:58.0) Gecko/20100101 Firefox/58.0","body_bytes_sent":"163006","total_bytes_sent":"163266"}
{"@timestamp":"2018-02-24T17:48:50+0800","client_ip":"172.16.213.132, 172.16.213.84","direct_ip": "172.16.213.120","request_time":0,"status":200,"url":"/img/logstash2.png","method":"GET","http_host":"172.16.213.157","server_ip":"172.16.213.157","http_referer":"http://172.16.213.84/img/","http_user_agent":"Mozilla/5.0 (Windows NT 6.3; Win64; x64; rv:58.0) Gecko/20100101 Firefox/58.0","body_bytes_sent":"163006","total_bytes_sent":"163266"}在这个输出中,可以看到,client_ip和direct_ip输出的异同,client_ip字段对应的变量为“%{X-Forwarded-For}i”,它的输出是代理叠加而成的IP列表,而direct_ip对应的变量为%a,表示不经过代理访问的直连IP,当用户不经过任何代理直接访问apache时,client_ip和direct_ip应该是同一个IP。
6)配置filebeat
filebeat是安装在apache服务器上的,关于filebeat的安装与基础应用,在前面章节已经做过详细介绍了,这里不再说明,仅给出配置好的filebeat.yml文件的内容:
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/httpd/access.log
fields:
log_topic: apachelogs
filebeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
name: 172.16.213.157
output.kafka:
enabled: true
hosts: ["172.16.213.51:9092", "172.16.213.75:9092", "172.16.213.109:9092"]
version: "0.10"
topic: '%{[fields.log_topic]}'
partition.round_robin:
reachable_only: true
worker: 2
required_acks: 1
compression: gzip
max_message_bytes: 10000000
logging.level: debug这个配置文件中,是将apache的访问日志/var/log/httpd/access.log内容实时的发送到kafka集群topic为apachelogs中。需要注意的是filebeat输出日志到kafka中配置文件的写法。
7)配置logstash
下面直接给出logstash事件配置文件kafka_apache_into_es.conf的内容:
input {
kafka {
bootstrap_servers => "172.16.213.51:9092,172.16.213.75:9092,172.16.213.109:9092“ #指定输入源中kafka集群的地址。
topics => "apachelogs" #指定输入源中需要从哪个topic中读取数据。
group_id => "logstash"
codec => json {
charset => "UTF-8" #将输入的json格式进行UTF8格式编码。
}
add_field => { "[@metadata][tagid]" => "apacheaccess_log" } #增加一个字段,用于标识和判断,在output输出中会用到。
}
}filter {
if [@metadata][tagid] == "apacheaccess_log" {
mutate {
gsub => ["message", "\\x", "\\\x"] #这里的message就是message字段,也就是日志的内容。这个插件的作用是将message字段内容中UTF-8单字节编码做替换处理,这是为了应对URL有中文出现的情况。
}
if ( 'method":"HEAD' in [message] ) { #如果message字段中有HEAD请求,就删除此条信息。
drop {}
}
json { #这是启用json解码插件,因为输入的数据是复合的数据结构,只是一部分记录是json格式的。
source => "message" #指定json格式的字段,也就是message字段。
add_field => { "[@metadata][direct_ip]" => "%{direct_ip}"} #这里添加一个字段,用于后面的判断。
remove_field => "@version" #从这里开始到最后,都是移除不需要的字段,前面九个字段都是filebeat传输日志时添加的,没什么用处,所以需要移除。
remove_field => "prospector"
remove_field => "beat"
remove_field => "source"
remove_field => "input"
remove_field => "offset"
remove_field => "fields"
remove_field => "host"
remove_field => "message" #因为json格式中已经定义好了每个字段,那么输出也是按照每个字段输出的,因此就不需要message字段了,这里是移除message字段。
}
mutate {
split => ["client_ip", ","] #这是对client_ip这个字段按逗号进行分组切分,因为在多级代理情况下,client_ip获取到的IP可能是IP列表,如果是单个ip的话,也会进行分组,只不过是分一个组而已。
}
mutate {
replace => { "client_ip" => "%{client_ip[0]}" } #将切分出来的第一个分组赋值给client_ip,因为client_ip是IP列表的情况下,第一个IP才是客户端真实的IP。
}
if [client_ip] == "-" { #这是个if判断,主要用来判断当client_ip为"-"的情况下,当direct_ip不为"-"的情况下,就将direct_ip的值赋给client_ip。因为在client_ip为"-"的情况下,都是直接不经过代理的访问,此时direct_ip的值就是客户端真实IP地址,所以要进行一下替换。
if [@metadata][direct_ip] not in ["%{direct_ip}","-"] { #这个判断的意思是如果direct_ip非空。
mutate {
replace => { "client_ip" => "%{direct_ip}" }
}
} else {
drop{}
}
}
mutate {
remove_field => "direct_ip" #direct_ip只是一个过渡字段,主要用于在某些情况下将值传给client_ip,因此传值完成后,就可以删除direct_ip字段了。
}
}
}
output {
if [@metadata][tagid] == "apacheaccess_log" { #用于判断,跟上面input中[@metadata][tagid]对应,当有多个输入源的时候,可根据不同的标识,指定到不同的输出地址。
elasticsearch {
hosts => ["172.16.213.37:9200","172.16.213.77:9200","172.16.213.78:9200"] #这是指定输出到elasticsearch,并指定elasticsearch集群的地址。
index => "logstash_apachelogs-%{+YYYY.MM.dd}" #指定apache日志在elasticsearch中索引的名称,这个名称会在Kibana中用到。索引的名称推荐以logstash开头,后面跟上索引标识和时间。
}
}
}
8)配置Kibana
filebeat收集数据到kafka,然后logstash从kafka拉取数据,如果数据能够正确发送到elasticsearch,我们就可以在Kibana中配置索引了。
登录Kibana,首先配置一个index_pattern,点击kibana左侧导航中的Management菜单,然后选择右侧的Index Patterns按钮,最后点击左上角的Create index pattern。
2、ELK收集Nginx访问日志实战案例
1)ELK收集Nginx访问日志应用架构
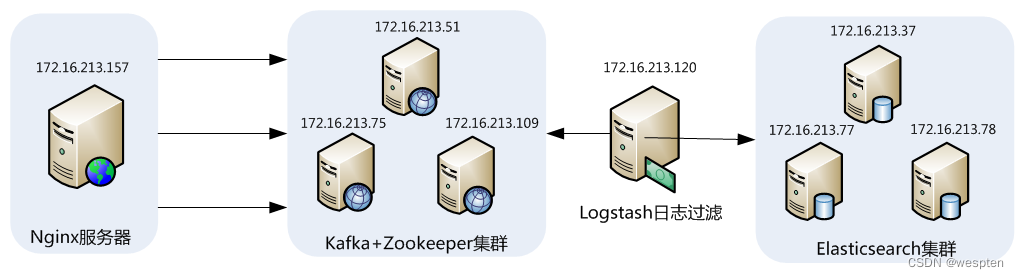
2)Nginx的日志格式与日志变量
Nginx跟Apache一样,都支持自定义输出日志格式,在进行Nginx日志格式定义前,先来了解一下关于多层代理获取用户真实IP的几个概念。
remote_addr:表示客户端地址,但有个条件,如果没有使用代理,这个地址就是客户端的真实IP,如果使用了代理,这个地址就是上层代理的IP。
X-Forwarded-For:简称XFF,这是一个HTTP扩展头,格式为 X-Forwarded-For: client, proxy1, proxy2,如果一个HTTP请求到达服务器之前,经过了三个代理 Proxy1、Proxy2、Proxy3,IP 分别为 IP1、IP2、IP3,用户真实IP为 IP0,那么按照 XFF标准,服务端最终会收到以下信息:
X-Forwarded-For: IP0, IP1, IP2
由此可知,IP3这个地址X-Forwarded-For并没有获取到,而remote_addr刚好获取的就是IP3的地址。
还要几个容易混淆的变量,这里也列出来做下说明:
$remote_addr:此变量如果走代理访问,那么将获取上层代理的IP,如果不走代理,那么就是客户端真实IP地址。
$http_x_forwarded_for:此变量获取的就是X-Forwarded-For的值。
$proxy_add_x_forwarded_for:此变量是$http_x_forwarded_for和$remote_addr两个变量之和。
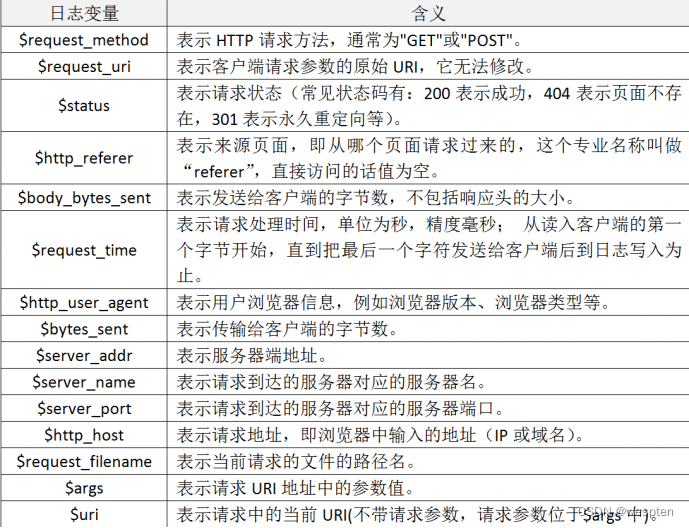
3)自定义Nginx日志格式
在掌握了Nginx日志变量的含义后,接着开始对它输出的日志格式进行改造,这里我们仍将Nginx日志输出设置为json格式,下面仅列出Nginx配置文件nginx.conf中日志格式和日志文件定义部分,定义好的日志格式与日志文件如下:
map $http_x_forwarded_for $clientRealIp {
"" $remote_addr;
~^(?P<firstAddr>[0-9\.]+),?.*$ $firstAddr;
}
log_format nginx_log_json '{"accessip_list":"$proxy_add_x_forwarded_for","client_ip":"$clientRealIp","http_host":"$host","@timestamp":"$time_iso8601","method":"$request_method","url":"$request_uri","status":"$status","http_referer":"$http_referer","body_bytes_sent":"$body_bytes_sent","request_time":"$request_time","http_user_agent":"$http_user_agent","total_bytes_sent":"$bytes_sent","server_ip":"$server_addr"}';
access_log /var/log/nginx/access.log nginx_log_json;
4)验证日志输出
{"accessip_list":"172.16.213.132","client_ip":"172.16.213.132","http_host":"172.16.213.157","@timestamp":"2018-02-28T12:26:26+08:00","method":"GET","url":"/img/guonian.png","status":"304","http_referer":"-","body_bytes_sent":"1699956","request_time":"0.000","http_user_agent":"Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36","total_bytes_sent":"1700201","server_ip":"172.16.213.157"}
{"accessip_list":"172.16.213.132, 172.16.213.120","client_ip":"172.16.213.132","http_host":"172.16.213.157","@timestamp":"2018-02-28T12:26:35+08:00","method":"GET","url":"/img/guonian.png","status":"304","http_referer":"-","body_bytes_sent":"1699956","request_time":"0.000","http_user_agent":"Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36","total_bytes_sent":"1700201","server_ip":"172.16.213.157"}
{"accessip_list":"172.16.213.132, 172.16.213.84, 172.16.213.120","client_ip":"172.16.213.132","http_host":"172.16.213.157","@timestamp":"2018-02-28T12:26:44+08:00","method":"GET","url":"/img/guonian.png","status":"304","http_referer":"-","body_bytes_sent":"1699956","request_time":"0.000","http_user_agent":"Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36","total_bytes_sent":"1700201","server_ip":"172.16.213.157"}
在这个输出中,可以看到,client_ip和accessip_list输出的异同,client_ip字段输出的就是真实的客户端IP地址,而accessip_list输出是代理叠加而成的IP列表,第一条日志,是直接访问http://172.16.213.157/img/guonian.png不经过任何代理得到的输出日志,第二条日志,是经过一层代理访问http://172.16.213.120/img/guonian.png 而输出的日志,第三条日志,是经过二层代理访问http://172.16.213.84/img/guonian.png 得到的日志输出。
Nginx中获取客户端真实IP的方法很简单,无需做特殊处理,这也给后面编写logstash的事件配置文件减少了很多工作量。
5)配置filebeat
filebeat是安装在Nginx服务器上的,这里给出配置好的filebeat.yml文件的内容:
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/nginx/access.log
fields:
log_topic: nginxlogs
filebeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
name: 172.16.213.157
output.kafka:
enabled: true
hosts: ["172.16.213.51:9092", "172.16.213.75:9092", "172.16.213.109:9092"]
version: "0.10"
topic: '%{[fields.log_topic]}'
partition.round_robin:
reachable_only: true
worker: 2
required_acks: 1
compression: gzip
max_message_bytes: 10000000
logging.level: debug
6)配置logstash
由于在Nginx输出日志中已经定义好了日志格式,因此在logstash中就不需要对日志进行过滤和分析操作了,下面直接给出logstash事件配置文件kafka_nginx_into_es.conf的内容:
input {
kafka {
bootstrap_servers => "172.16.213.51:9092,172.16.213.75:9092,172.16.213.109:9092"
topics => "nginxlogs" #指定输入源中需要从哪个topic中读取数据,这里会自动新建一个名为nginxlogs的topic
group_id => "logstash"
codec => json {
charset => "UTF-8"
}
add_field => { "[@metadata][myid]" => "nginxaccess-log" } #增加一个字段,用于标识和判断,在output输出中会用到。
}
}
filter {
if [@metadata][myid] == "nginxaccess-log" {
mutate {
gsub => ["message", "\\x", "\\\x"] #这里的message就是message字段,也就是日志的内容。这个插件的作用是将message字段内容中UTF-8单字节编码做替换处理,这是为了应对URL有中文出现的情况。
}
if ( 'method":"HEAD' in [message] ) { #如果message字段中有HEAD请求,就删除此条信息。
drop {}
}
json {
source => "message"
remove_field => "prospector"
remove_field => "beat"
remove_field => "source"
remove_field => "input"
remove_field => "offset"
remove_field => "fields"
remove_field => "host"
remove_field => "@version“
remove_field => "message"
}
}
}
output {
if [@metadata][myid] == "nginxaccess-log" {
elasticsearch {
hosts => ["172.16.213.37:9200","172.16.213.77:9200","172.16.213.78:9200"]
index => "logstash_nginxlogs-%{+YYYY.MM.dd}" #指定Nginx日志在elasticsearch中索引的名称,这个名称会在Kibana中用到。索引的名称推荐以logstash开头,后面跟上索引标识和时间。
}
}
}
这个logstash事件配置文件非常简单,没对日志格式或逻辑做任何特殊处理,由于整个配置文件跟elk收集apache日志的配置文件基本相同,因此不再做过多介绍。
所有配置完成后,就可以启动logstash了,执行如下命令:
[root@logstashserver ~]# cd /usr/local/logstash
[root@logstashserver logstash]# nohup bin/logstash -f kafka_nginx_into_es.conf &7)配置Kibana
Filebeat从nginx上收集数据到kafka,然后logstash从kafka拉取数据,如果数据能够正确发送到elasticsearch,我们就可以在Kibana中配置索引了。
十二、Beat+Kafka+ELK+Grafana实战
1、Metricbeat 简介
Metricbeat 用于收集从 CPU 到内存,从 Redis、Mysql到Nginx等应用的各项数据与性能指标,并且Metricbeat 能够以一种轻量型的方式,输送各种系统和服务统计数据。
1. 系统级监控,更简洁(轻量型指标采集器)
将 Metricbeat 部署到您所有的 Linux、Windows 和 Mac 主机,并将它连接到 Elasticsearch 就大功告成啦:您可以获取系统级的 CPU 使用率、内存、文件系统、磁盘 IO 和网络 IO 统计数据,以及获得如同系统上 top 命令类似的各个进程的统计数据。
2. 单个二进制文件提供多种模块
Metricbeat 提供多种内部模块,这些模块可从多项服务(诸如 Apache、Jolokia、NGINX、MongoDB、MySQL、PostgreSQL、Prometheus )中收集指标。安装简单,完全零依赖性。只需在配置文件中启用您所需的模块即可。
而且,如果您没有看到要找的模块,还可以自己构建。以 Go 语言编写 Metricbeat 模块,过程十分简单。
3. 不错过任何检测信号
将指标通过假脱机传输方式输送至磁盘,这样您的数据管道再也不会错过任何一个数据点,即使发生中断(例如网络问题),也勿需担心。Metricbeat 会保留传入的数据,并在重新上线后将这些指标输送至 Elasticsearch 或 Logstash。
4. 输送至 Elasticsearch 或 Logstash。在 Kibana 中实现可视化
Metricbeat 是 Elastic Stack 的一部分,因此能够与 Logstash、Elasticsearch 和 Kibana 无缝协作。无论您要使用 Logstash 转换或充实指标,还是在 Elasticsearch 中随意处理一些数据分析,亦或在 Kibana 中构建和分享仪表板,Metricbeat 都能轻松地将您的数据发送至最关键的地方。
2、EFK环境准备
在kibana查看到支持的服务模块(本案例只安装system logs):
根据需要选择:
下载并安装Filebeat:
[root@metricbeat ~]# curl -L -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.5.0-x86_64.rpm
[root@metricbeat ~]# sudo rpm -vih filebeat-7.5.0-x86_64.rpm编辑配置:
修改/etc/filebeat/filebeat.yml以设置连接信息。
[root@metricbeat ~]# vi /etc/filebeat//filebeat.yml
output.elasticsearch:
hosts: ["192.168.14.210:9200"] #ES服务器IP+端口
username: "elastic" #ES7开启了用户认证,输入用户名和密码
password: "elkpwd"
setup.kibana:
host: "192.168.14.210:5601" #Kibana服务器IP+端口启用和配置系统模块(/etc/filebeat/modules.d/system.yml文件):
[root@metricbeat ~]# filebeat modules enable system
Enabled system启动Filebeat:
#该setup命令将加载Kibana仪表板。如果已经设置了仪表板,请忽略此命令
[root@metricbeat ~]# filebeat setup
Index setup finished.
Loading dashboards (Kibana must be running and reachable)
Loaded dashboards
Loaded machine learning job configurations
Loaded Ingest pipelines
[root@metricbeat ~]# service filebeat start
Starting filebeat (via systemctl): [ OK ]点击检测数据:

检测成功,查看图形:

kibana查看自动生成的可视化图形。
可以自己添加视图,也可以使用默认:

Syslog:
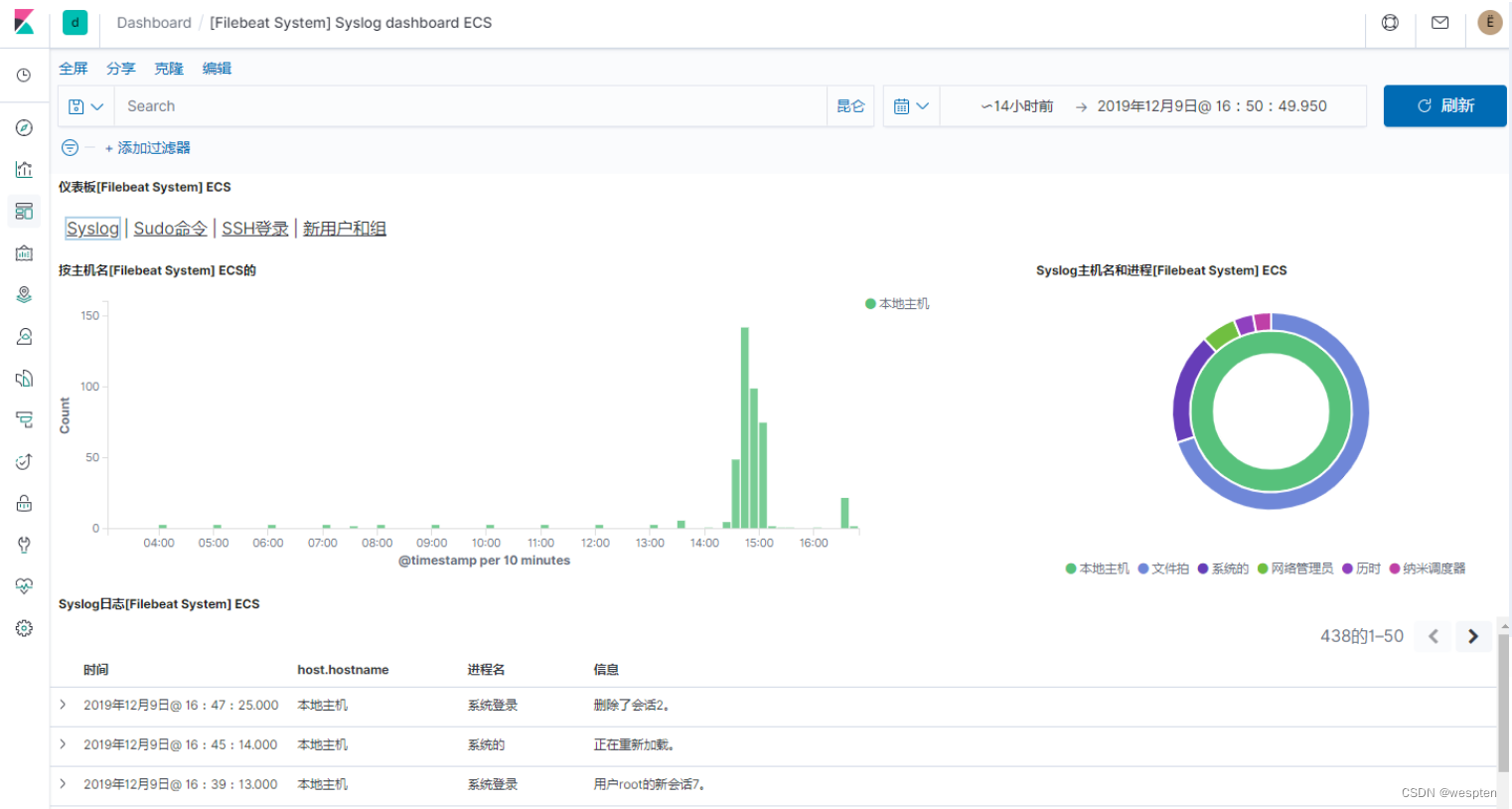
Sudo命令:

SSH登录:
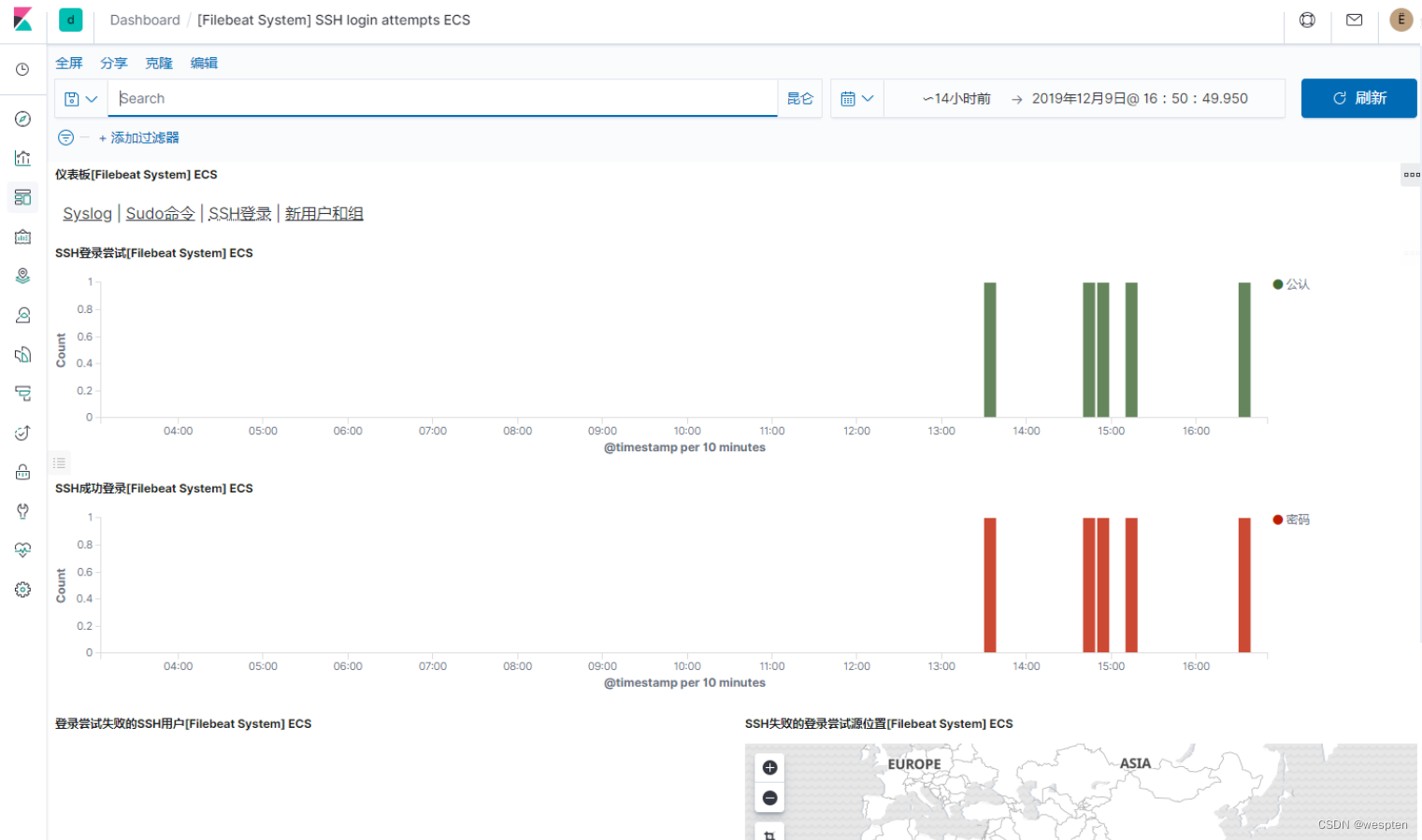
新用户和组:
3、安装metricbeat
官网下载rpm包安装:
rpm -ivh /nas/nas/softs/elk/6.5.4/metricbeat-6.5.4-x86_64.rpm默认开启了system模块使用命令查看模块:
metricbeat modules list
Enabled:
system
Disabled:
aerospike
apache
ceph
couchbase
docker
dropwizard
elasticsearch
envoyproxy
etcd
golang
graphite
haproxy
http
jolokia
kafka
kibana
kubernetes
kvm
logstash
memcached
mongodb
munin
mysql
nginx
php_fpm
postgresql
prometheus
rabbitmq
redis
traefik
uwsgi
vsphere
windows
zookeeperPS:Enabled模块为启用模块 Disabled模块为未启用模块。
配置/etc/metricbeat/metricbeat.yml:
metricbeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
setup.template.settings:
index.number_of_shards: 1
index.codec: best_compression
setup.kibana:
output.logstash:
hosts: ["xxx:5044"]系统数据收集/etc/metricbeat/modules.d/system.yml:
- module: system
period: 30s
metricsets:
- cpu
- load
- memory
- module: system
period: 30s
metricsets:
- filesystem
processors:
- drop_event.when.regexp:
system.filesystem.mount_point: '^/(sys|cgroup|proc|dev|etc|host|lib)($|/)'启动metricbeat:
systemctl restart metricbeat4、设置监控nginx性能
启用新模块命令,例如启用nginx模块:
metricbeat modules enable nginx修改配置文件监控系统CPU,内存等信息:
#包含其他模块的配置文件
metricbeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
setup.template.settings:
index.number_of_shards: 1
index.codec: best_compression
#开启dashboards
setup.dashboards.enabled: true
#输出至kibana
setup.kibana:
host: "172.16.90.24:5601"
#输出至elssticsearch
output.elasticsearch:
hosts: ["172.16.90.24:9200"]
processors:
- add_host_metadata: ~
- add_cloud_metadata: ~启动metricbeat:
systemctl start metricbeat打开kibana页面查看自动生成了一些图表:
查看hostview:

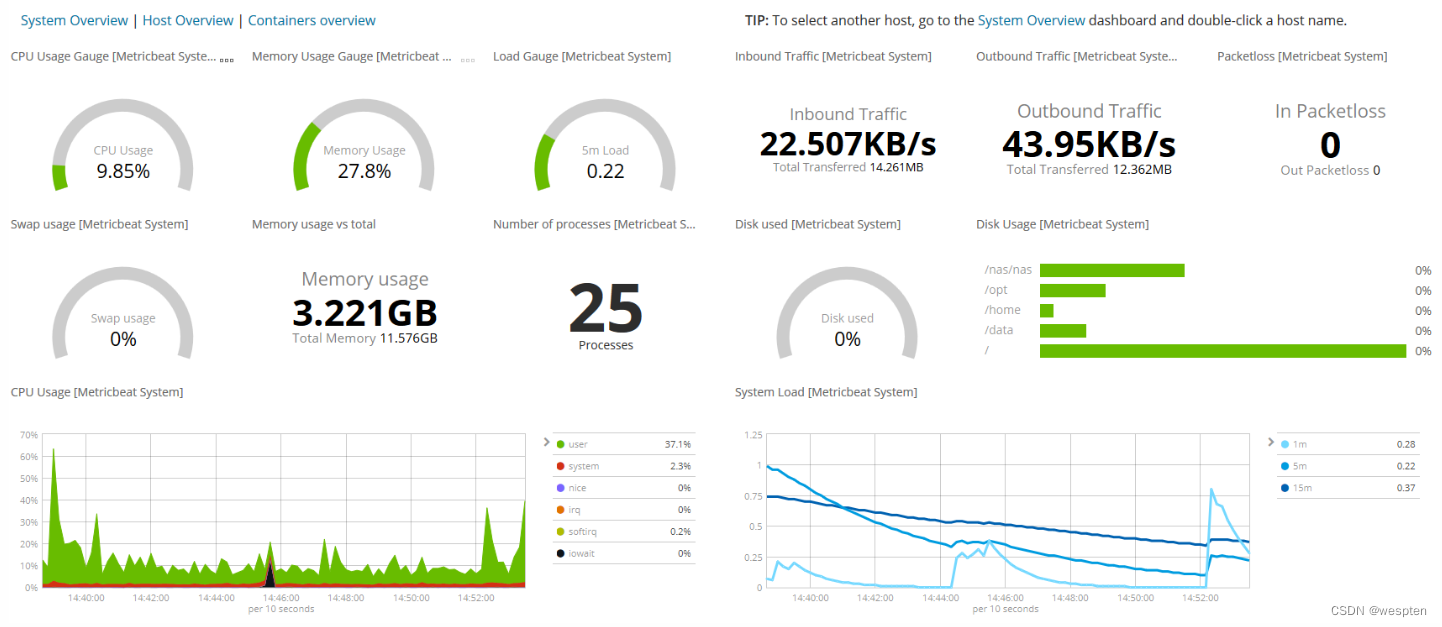
如果多个主机需要监控系统性能查看:

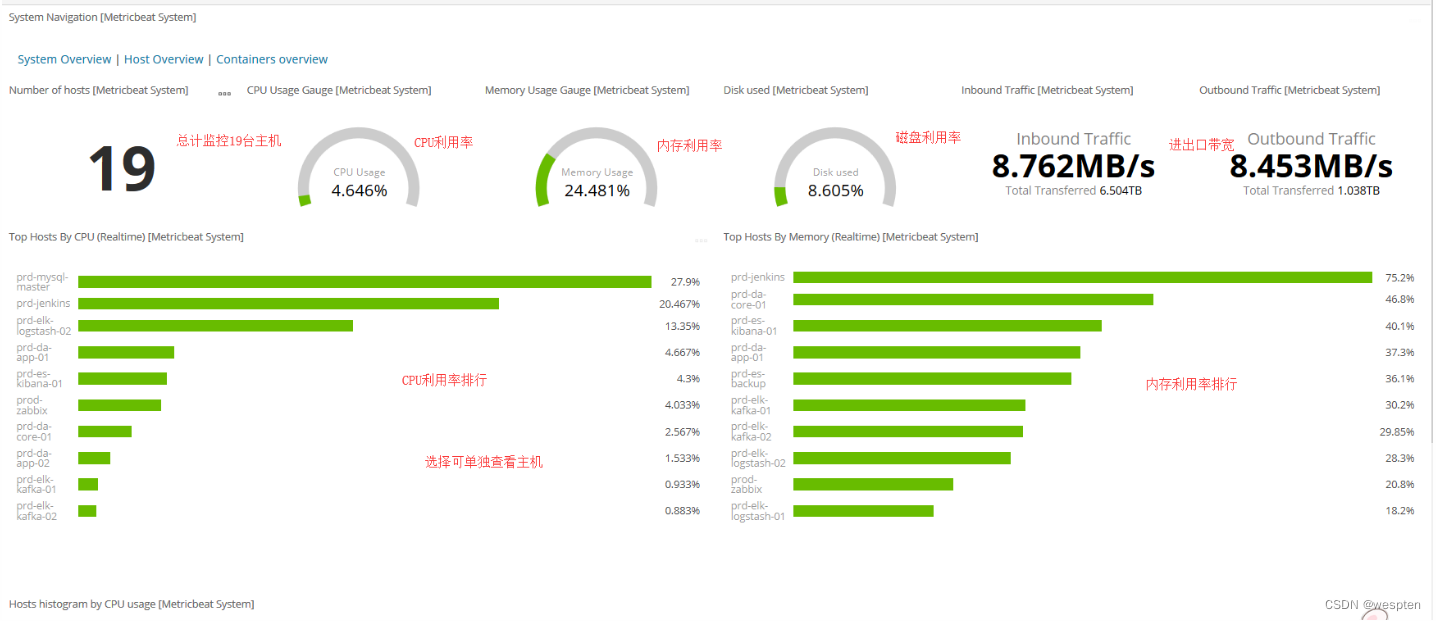
开启nginx模块:
metricbeat modules enable nginx修改metricbeat配置文件/etc/metricbeat/modules.d/nginx.yml:
- module: nginx
metricsets: ["stubstatus"]
hosts: ["http://172.16.100.132"]
#username: "user"
#password: "secret"
server_status_path: "status"PS:监控nginx前提需要开启nginx状态模块并在nginx配置下添加以下配置。
server{
listen 80;
server_name 172.16.100.132;
location /status
{
stub_status;
access_log off;
}
}配置成功在web页面可以查看到以下信息:
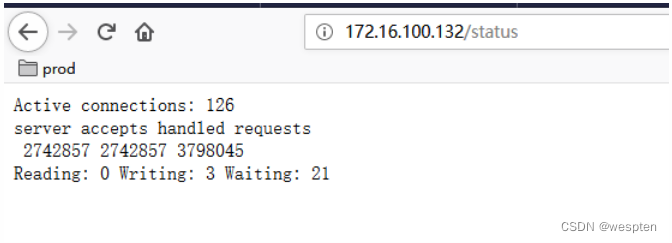
重启metricbeat查看:

5、设置监控MySQL
开启MySQL模块:
metricbeat modules enable mysql修改配置文件:
/etc/metricbeat/modules.d/mysql.yml
- module: mysql
metricsets:
- status
# - galera_status
period: 10s
# Host DSN should be defined as "user:pass@tcp(127.0.0.1:3306)/"
# The username and password can either be set in the DSN or using the username
# and password config options. Those specified in the DSN take precedence.
hosts: ["tcp(172.16.90.180:3306)/"]
# Username of hosts. Empty by default.
username: root
# Password of hosts. Empty by default.
password: secretkibana页面查看:
6、设置监控redis
开启redis模块:
metricbeat modules enable redis修改配置文件:
/etc/metricbeat/modules.d/redis.yml
- module: redis
hosts: ["172.16.90.181:6379"]
metricsets: ["info","keyspace"]
enables: true
period: 10s
password: passwordPS:如果redis没有设置认证则密码不配置
kibana查看:
7、设置监控rabbitmq
开启rabbitmq模块:
metricbeat modules enable rabbitmq修改配置文件:
/etc/metricbeat/modules.d/rabbitmq.yml
- module: rabbitmq
metricsets: ["node", "queue", "connection"]
enabled: true
period: 10s
hosts: ["172.16.90.46:15672"]
username: admin
password: passwordkibana页面查看:
8、设置监控kafka
开启kafka监控模块:
metricbeat modules enable kafka修改配置文件:
/etc/metricbeat/modules.d/kafka.yml

kibana页面查看:
9、设置监控docker
开启docker监控模块:
metricbeat modules enable docker设置生效:
metricbeat setup
登录kibana查看:


其他监控请参考:
Modules | Metricbeat Reference [8.4] | Elastic
10、架构引入Grafana
架构优点:
数字化性能数据展示更加清晰,Kibana展示日志,Grafana展示数字化数据。
安装和启动:
下载地址:Download Grafana | Grafana Labs
yum localinstall grafana-7.3.4-1.x86_64.rpm
systemctl restart grafana-server
systemctl enable grafana-server访问Grafana配置ES数据源,端口3000,默认admin/admin,登录后需要更改密码。
load展示:
metric: avg system.load.1
metric: avg system.load.5
metric: avg system.load.15
groupby: host.name.keyword
alias: {
{host.name.keyword}} {
{metric}} {
{field}}
interval: 30s
内存展示:
system.memory.actual.freeMetricbeat采集Nginx展示。
Nginx配置新增:
location /ggstatus {
stub_status on;
access_log off;
allow 10.0.0.0/8;
allow 172.16.0.0/12;
allow 192.168.0.0/16;
deny all;
}测试能否获取数据:
curl xxx/ggstatusMetricbeat支持nginx:
metricbeat modules enable nginx配置:
server_status_path: "ggstatus"Grafana查看Nginx性能:
avg(requests) _value / 30
Derivative
term by : service.address.keyword
alias: {
{service.address.keyword}} request persecond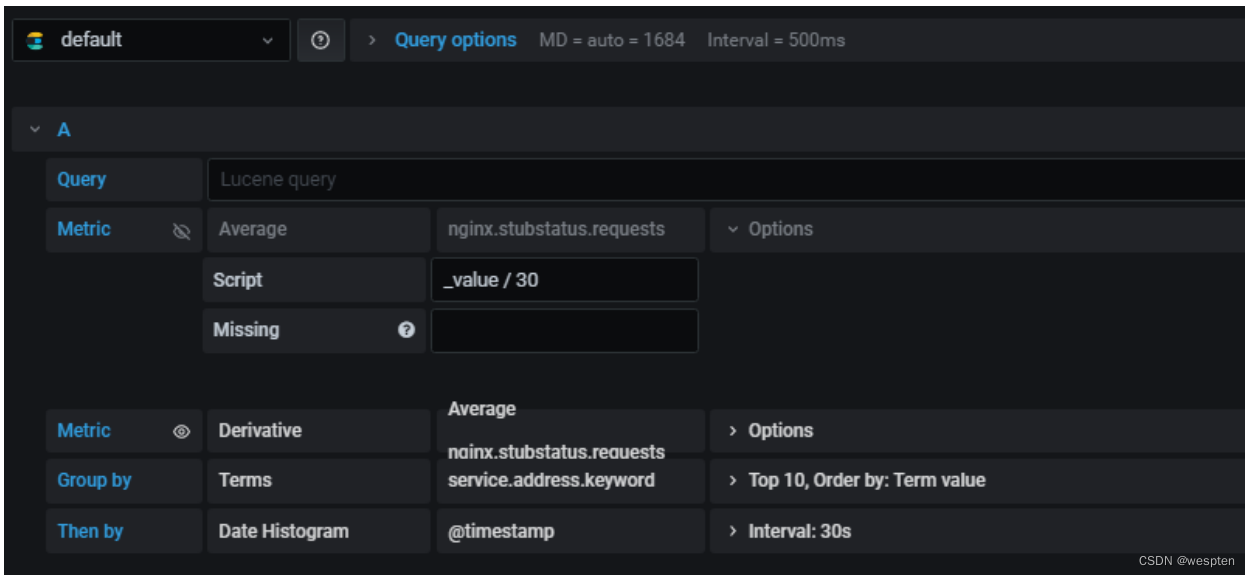
11、架构引入Kafka
Beat+Kafka+ELK架构优点:
Kafka支持集群,Logstash扩展方便。
zk集群至少需要三台机器:
下载地址:Apache ZooKeeper
tar -zxvf apache-zookeeper-3.6.0-bin.tar.gz
mv apache-zookeeper-3.6.0-bin /usr/local/zookeeper集群配置zoo.cfg:
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/usr/local/zookeeper/data
clientPort=2181
autopurge.snapRetainCount=3
autopurge.purgeInterval=1
server.1=xxx:2888:3888
server.2=xxx:2888:3888
server.3=xxx:2888:3888更改zk集群的id:
/usr/local/zookeeper/data/myid分别为1 2 3。
systemctl管理/usr/lib/systemd/system/zookeeper.service:
[Unit]
Description=zookeeper
After=network.target
[Service]
Type=forking
ExecStart=/usr/local/zookeeper/bin/zkServer.sh start
User=root
[Install]
WantedBy=multi-user.target启动zk:
systemctl enable zookeeper
systemctl restart zookeeper启动zk集群查看状态:
./zkServer.sh start
./zkServer.sh status有一个leader,其它follower就说明集群搭建成功。
验证zk集群,创建一个节点,验证数据:
./zkCli.sh
create /sjgKafka集群部署:
下载地址:Apache Kafka
安装:
tar -zxvf kafka_2.12-2.5.0.tgz -C /usr/local/Jvm内存修改/usr/local/kafka_2.12-2.5.0/bin/kafka-server-start.sh,根据实际情况修改。
修改Kafka配置server.properties:
broker.id=0
listeners=PLAINTEXT://xxx:9092
log.retention.hours=1 #根据实际情况修改
zookeeper.connect=xxx:2181,xxx:2181,xxx:2181Kafka使用systemctl管理/usr/lib/systemd/system/kafka.service:
[Unit]
Description=kafka
After=network.target
[Service]
Type=simple
ExecStart=/usr/local/kafka_2.12-2.5.0/bin/kafka-server-start.sh
/usr/local/kafka_2.12-2.5.0/config/server.properties
User=root
[Install]
WantedBy=multi-user.target
Kafka启动:
systemctl enable kafka
systemctl restart kafka创建topic,创建成功说明kafka集群搭建成功:
./kafka-topics.sh --create --zookeeper xxx:2181 --replication-factor 2 --partitions 1
--topic test
./kafka-topics.sh --describe --zookeeper xxx:2181 --topic test架构引入Kafka:
停止metricbeat,删除测试索引。
logstash获取kafka数据:
input {
kafka {
bootstrap_servers => "xxx:9092,xxx:9092"
topics => ["sjgkafka"]
group_id => "sjggroup"
codec => "json"
}
}filebeat写入kafka:
output:
kafka:
hosts: ["xxx:9092", "xxx:9092"]
topic: sjgkafkaKafka查看队列信息,验证新架构是否生效:
./kafka-consumer-groups.sh --bootstrap-server xxx:9092 --list
./kafka-consumer-groups.sh --bootstrap-server xxx:9092 --group xmgroup --
describeLOG-END-OFFSET不断增大,LAG不堆积说明架构生效。
Logstash配置保持一致,启动即可。