最近收到一个任务,任务内容如下:
指定一个目录,内含数千张图片,要求能将指定区域的数字记录下来,便于分析,图片如下所示
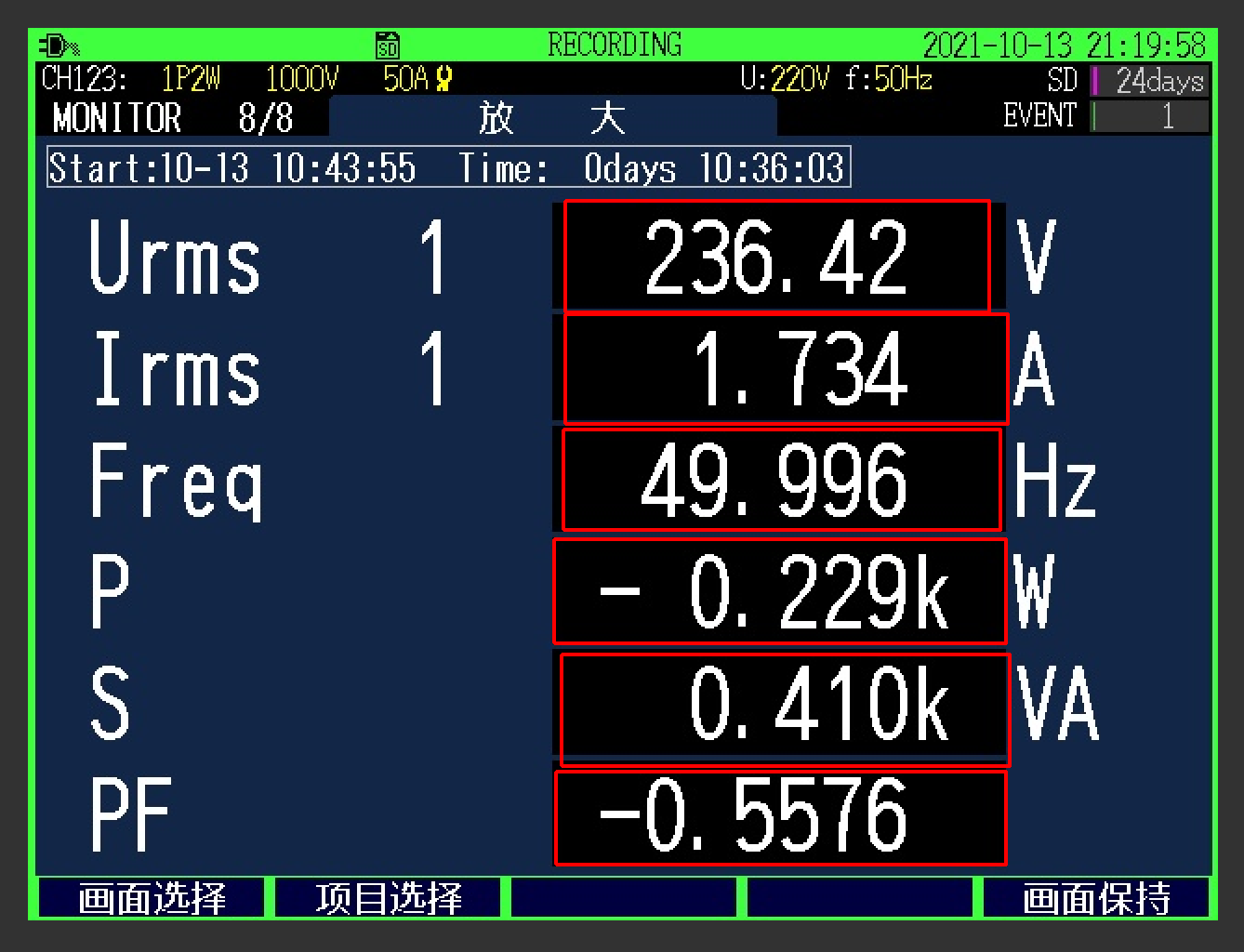
红框部分是需要识别出的区域
先分析下功能需求
1.识别指定区域的数据
2.将数据导出为excel
这里有一个很简单的方法,就是使用easyocr识别整张图片,然后检索结果,整理成excel
识别代码如下:
import easyocr
reader = easyocr.Reader(['en'])
result = reader.readtext("xx.bmp")
#打印出所有识别到的文字
print(result)
很简单的一段代码,执行完成后,就能将图片上能识别到的文字都存到result上,
我们可以先打印出来,用人肉识别出需要识别的数据坐标x,y是什么,之后写if else将信息筛选出来
下面是执行的结果
apple@MacBook-Pro ocr % python3 ocr_img.py
CUDA not available - defaulting to CPU. Note: This module is much faster with a GPU.
[([[277, 0], [355, 0], [355, 19], [277, 19]], 'FC0RI1', 0.0014008946827395506),
([[479, 0], [637, 0], [637, 19], [479, 19]], '2021-10-13,21:19:58',
0.6067788830140517),
([[5, 17], [57, 17], [57, 37], [5, 37]], 'CHI23:',
0.4357974768811839),
([[69, 17], [107, 17], [107, 37], [69, 37]], 'Ir8W', 、0.07446147501468658), ([[125, 17], [171, 17], [171, 37], [125, 37]], 'IOOO',
0.34371185302734375),
([[189, 17], [231, 17], [231, 37], [189, 37]], '5C8',
0.01371344964992317),
([[381, 17], [489, 17], [489, 37], [381, 37]], 'U:220 f:
SOHZ', 0.25379714901679773), ([[545, 19], [567, 19], [567, 37], [545, 37]], '8',
0.002208985491478424),
([[585, 21], [635, 21], [635, 39], [585, 39]], '24days',
0.36577745892357233),
([[10, 34], [86, 34], [86, 60], [10, 60]], 'MONITOR',
0.3407369661092041),
([[108, 36], [146, 36], [146, 60], [108, 60]], '8/8',
0.9650125824419508),
([[236, 34], [289, 34], [289, 63], [236, 63]], '放',
0.948400562849713),
([[296, 36], [326, 36], [326, 60], [296, 60]], '大',
0.8672227436346134), ([[521, 37], [567, 37], [567, 57], [521, 57]], '鸥ET',
0.0012719364986274106), ([[6, 62], [214, 62], [214, 88], [6, 88]], 'Btart :10-
13_10:43:5', 0.11246014436800789),
([[226, 63], [276, 63], [276, 89], [226, 89]],
'Time:', 0.9575283801158503),
([[294, 62], [442, 62], [442, 88], [294, 88]],
'Odayg_10:36:@', 0.20593363300327408),
([[25, 93], [135, 93], [135, 153], [25,
153]], 'Urms', 0.9993236064910889),
([[324, 96], [482, 96], [482, 150], [324,
150]], '236.42', 0.9945926786375755), ([[28, 158], [132, 158], [132, 210], [28,
210]], 'IrMS', 0.6551271080970764), ([[352, 156], [482, 156], [482, 212], [352, 212]], '1.734', 0.903081369161515), ([[528, 162], [552, 162], [552, 204], [528, 204]], 'A', 0.8598717599713979), ([[25, 214], [138, 214], [138, 275], [25, 275]], 'Freq', 0.9916050434112549), ([[324, 216], [482, 216], [482, 272], [324, 272]], '49.996', 0.9935817354482747), ([[523, 215], [585, 215], [585, 275], [523, 275]], 'Hz', 0.7322396318166535), ([[350, 276], [506, 276], [506, 332], [350, 332]], '0.229k', 0.8985150015324731), ([[526, 280], [558, 280], [558, 326], [526, 326]], '川', 0.04304330616733765), ([[21, 271], [86, 271], [86, 451], [21, 451]], '阼', 0.008450670474303479), ([[348, 336], [506, 336], [506, 392], [348, 392]], '0.410k', 0.9760298809799972), ([[526, 336], [582, 336], [582, 392], [526, 392]], 'VA', 0.985728575046812), ([[302, 396], [482, 396], [482, 452], [302, 452]], '-0.5576', 0.8452973534231776), ([[26, 454], [110, 454], [110, 480], [26, 480]], '画面选择', 0.22726230323314667), ([[152, 454], [236, 454], [236, 480], [152, 480]], '项目选择', 0.004154475871473551), ([[534, 454], [618, 454], [618, 480], [534, 480]], '画面保持', 0.7061346769332886)]
仔细查看数据,可以发现我们要找的第一个框的数据信息如下
([[324, 96], [482, 96], [482, 150], [324, 150]], '236.42', 0.9945926786375755)
一个元组,有三个数据,第一个数据是坐标信息,第二个是识别到的字符串,第三个是识别的准确率
4个坐标分别代表了图片的四个角
其它数据也是按这个逻辑找到,接下来,我们只需要写一个for循环,用if else将结果识别出来即可,下面是我项目的部分代码,以作参考
def ocr_img(img):
# 创建reader对象
# 读取图像
if not img.endswith("jpg"):
return
result = reader.readtext(img)
print(result)
print(len(result))
line=[]
for a in result:
s=a[1];
x=a[0][0][0]
y=a[0][0][1]
if x==479:
# print("time:"+s)
line.append(s)
if x>=300 and x<=356 and y>=90 and y<=100:
# print("Urms:"+s)
line.append(s)
if x>=300 and x<=356 and y>=145 and y<=160:
# print("Irms:"+s)
line.append(s)
if x>=300 and x<=356 and y>=200 and y<=220:
# print("Freq:"+s)
line.append(s)
if x>=300 and x<=356 and y>=270 and y<=280:
# print("P:"+s)
line.append(s)
if x>=300 and x<=356 and y>=330 and y<=340:
# print("S:"+s)
line.append(s)
if x>=300 and x<=356 and y>=390 and y<=400:
# print("PF:"+s)
line.append(s)
if len(line)==7:
print(line)
if not os.path.exists("result/"+img+".result"):
s=""
for i in range(0,len(line)):
s+=line[i]+","
open("result/"+img+".result","w").write(s)
else:
print("error:"+img,line)
for a in result:
print(a)有多张图片的话,直接for调用即可解决问题
最后会将识别到的结果以csv的格式存起来,可以用excel直接打开查看
这是第一版的程序,执行一个命令行,将那几千张图片转换成csv,任务完成
最终出来的数据,虽然有一部分不是很完整,或者有些错乱,但总体来说还是好的,至少不用费力一个个输,只需要将出错的地方修复一下,能节省大量的录入时间,perfect
第二版程序2.0,就做成了图形化界面,可以针对不同的图片进行批量的识别,如下图所示
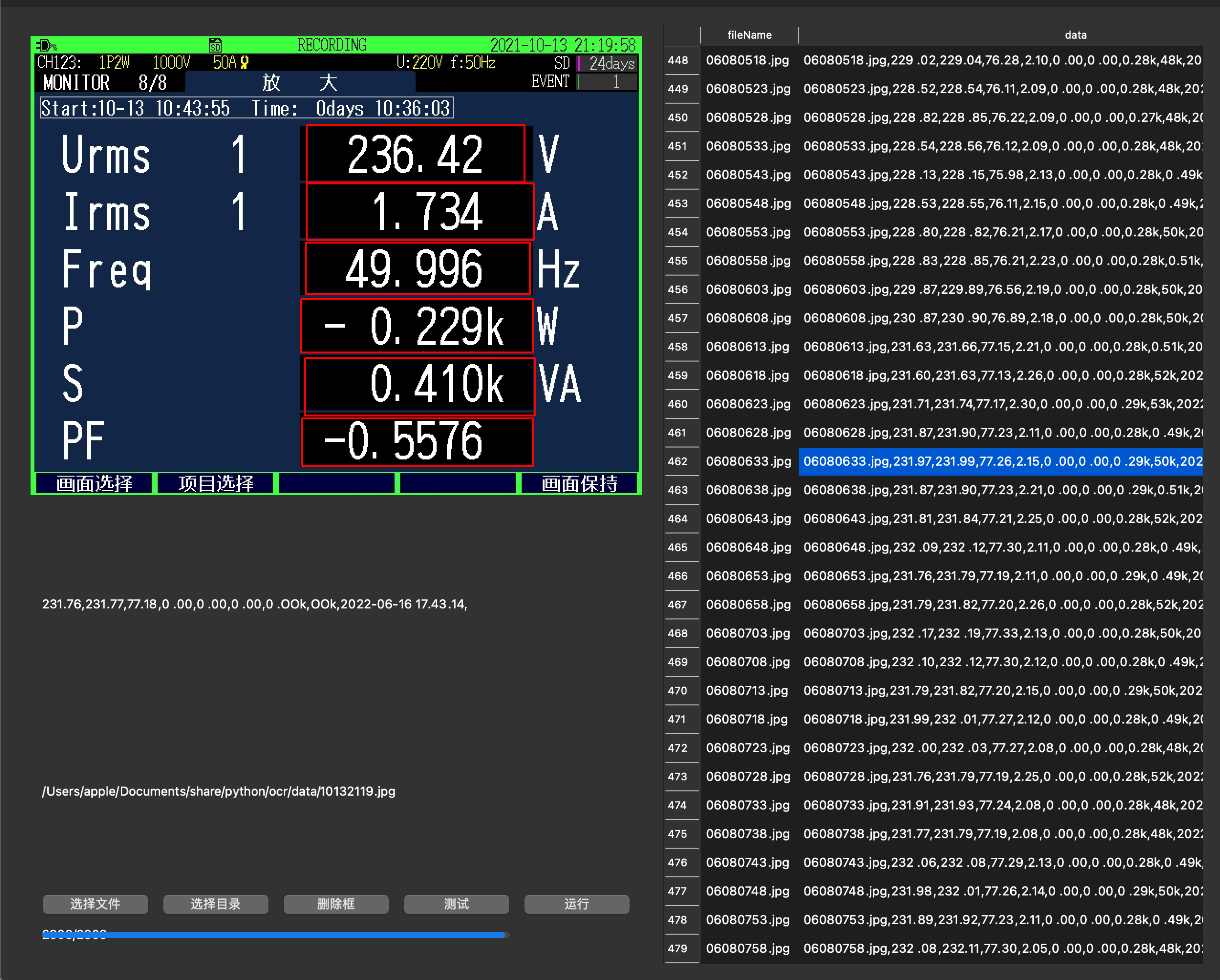
之后再有类似的任务,就是选择目录,点击运行,等个2小时,就OK了
3000张图片2小时识别完,性能还是差了点,反正是挂机的,没关系,
等哪天有空再写个3.0吧