1.数据读取和图像预处理
(1)标签文件的读取
- 首先,我们需要从frame_list文件夹的train.csv/val.csv取出图片地址和视频的名称

- 第二,从annotation取出标签,其中包括ava_train_v2.2.csv文件中的真实框标签,以及ava_train_v2.2.csv,person_box_67091280_iou90/ava_detection_train_boxes_and_labels_include_negative_v2.2.csv'提供的大于阈值的预测框标签,预测框标签提供了负类

- 然后,将第一步的视频名称和标签对应起来
- 然后再得到每个视频每一秒对应的图片帧的索引,即返回(video_idx, sec_idx, sec, sec_to_frame(sec)),video_idx代表视频索引,sec_idx代表第几秒的索引,sec代表第几秒,sec_to_frame(sec))代表这一秒对应的图片的索引,以及对应的标签

(2)图像预处理方法
首先取出video_idx, sec_idx, sec, center_idx,center_idx,center_idx指的是该秒对应的图片帧的索引,以第一个视频第1秒为例,前面的video_idx, sec_idx均为0,sec应为902,对应标签文件中开始的视频时间(902秒),center_idx应为30,因为视频在准备数据的时候做了切分,截取了第15分钟到第25分钟的视频,同时每一秒包含30帧图像
上面得到的还是标签,我们需要根据图片序列取构建数据部分,具体操作为以center_idx为中心,前后各从32张图片每两帧图片取一帧图片,得到32帧的图片序列。
需要注意的是,数据是一整个图片序列,而标签只是中间一张图片的标签。因此,这就有可能出现真实框不对应的问题。这在预测过程中也可以看到。不过,由于考虑到时间成本,这么简化也是能够可行的。对于视频中的一秒,人的位置一般不会出现太大的变化。与对每一帧图片做处理相比,这样处理在运算时间上无疑是非常简化的。
对于上面得到的图片序列,进行多尺度、随机裁剪、水平翻转、颜色抖动等预处理,并对图像进行归一化和正规化,统一到crop_size(224)大小,并处理标签超过图片边界的情况。以及制作label标签矩阵。最后,对图片进行采样,得到32张图片序列的fast图片序列输入和8张图片序列的slow图像序列输入
代码如下:
class Ava(torch.utils.data.Dataset):
"""
AVA Dataset AVA数据预处理
"""
def __init__(self, cfg, split):
self.cfg = cfg # 配置参数
self._split = split # train/val
self._sample_rate = cfg.DATA.SAMPLING_RATE # slow路径采样率,以每秒2帧为基准
self._video_length = cfg.DATA.NUM_FRAMES # 时间序列长度/32秒
self._seq_len = self._video_length * self._sample_rate # 总的图像序列长度
self._num_classes = cfg.MODEL.NUM_CLASSES # 类别
# Augmentation params. 数据增强参数
self._data_mean = cfg.DATA.MEAN # 均值
self._data_std = cfg.DATA.STD # 方差
self._use_bgr = cfg.AVA.BGR # 三通道、opencv等是B,G,R
self.random_horizontal_flip = cfg.DATA.RANDOM_FLIP # 随机图片翻转
if self._split == "train":
self._crop_size = cfg.DATA.TRAIN_CROP_SIZE # 图片大小
self._jitter_min_scale = cfg.DATA.TRAIN_JITTER_SCALES[0] # 多尺度图像大小
self._jitter_max_scale = cfg.DATA.TRAIN_JITTER_SCALES[1]
self._use_color_augmentation = cfg.AVA.TRAIN_USE_COLOR_AUGMENTATION # 色彩数据增强
self._pca_jitter_only = cfg.AVA.TRAIN_PCA_JITTER_ONLY # RGB颜色空间添加扰动
self._pca_eigval = cfg.DATA.TRAIN_PCA_EIGVAL
self._pca_eigvec = cfg.DATA.TRAIN_PCA_EIGVEC
else:
self._crop_size = cfg.DATA.TEST_CROP_SIZE
self._test_force_flip = cfg.AVA.TEST_FORCE_FLIP
self._load_data(cfg)
def _load_data(self, cfg):
"""
Load frame paths and annotations from files
Args:
cfg (CfgNode): config
"""
# Loading frame paths.
# 从frame_list文件夹中返回图片路径和视频名称
(
self._image_paths,
self._video_idx_to_name,
) = ava_helper.load_image_lists(cfg, is_train=(self._split == "train"))
# -------------------------------------------------------------------------------------------------#
# Loading annotations for boxes and labels.
# 从annotations中返回标签,其中包括ava_train_v2.2.csv文件中的真实框标签,以及ava_train_v2.2.csv,
# person_box_67091280_iou90/ava_detection_train_boxes_and_labels_include_negative_v2.2.csv'提供的大于阈值
# 的预测框标签,预测框标签提供了负类
# ---------------------------------------------------------------------------------------------------#
boxes_and_labels = ava_helper.load_boxes_and_labels(
cfg, mode=self._split
)
assert len(boxes_and_labels) == len(self._image_paths)
# 将标签对应到每个视频
boxes_and_labels = [
boxes_and_labels[self._video_idx_to_name[i]]
for i in range(len(self._image_paths))
]
#-----------------------------------------------------------------------------------------------#
# Get indices of keyframes and corresponding boxes and labels.
# 返回每个视频每一秒对应的图片帧的索引,即返回(video_idx, sec_idx, sec, sec_to_frame(sec)),video_idx代表视频索引
# sec_idx代表第几秒的索引,sec代表第几秒,sec_to_frame(sec))代表这一秒对应的图片的索引,以及对应的标签
#-----------------------------------------------------------------------------------------------#
(
self._keyframe_indices,
self._keyframe_boxes_and_labels,
) = ava_helper.get_keyframe_data(boxes_and_labels)
# Calculate the number of used boxes. 返回框的数量
self._num_boxes_used = ava_helper.get_num_boxes_used(
self._keyframe_indices, self._keyframe_boxes_and_labels
)
# 打印相关信息
self.print_summary()
def print_summary(self):
logger.info("=== AVA dataset summary ===")
logger.info("Split: {}".format(self._split))
logger.info("Number of videos: {}".format(len(self._image_paths)))
total_frames = sum(
len(video_img_paths) for video_img_paths in self._image_paths
)
logger.info("Number of frames: {}".format(total_frames))
logger.info("Number of key frames: {}".format(len(self)))
logger.info("Number of boxes: {}.".format(self._num_boxes_used))
def __len__(self):
"""
Returns:
(int): the number of videos in the dataset.
"""
return self.num_videos
@property
def num_videos(self):
"""
Returns:
(int): the number of videos in the dataset.
"""
return len(self._keyframe_indices)
def _images_and_boxes_preprocessing_cv2(self, imgs, boxes):
"""
This function performs preprocessing for the input images and
corresponding boxes for one clip with opencv as backend.
Args:
imgs (tensor): the images.
boxes (ndarray): the boxes for the current clip.
Returns:
imgs (tensor): list of preprocessed images.
boxes (ndarray): preprocessed boxes.
"""
# 框的相对坐标转化为绝对坐标,并处理框超出图片边界的情况
height, width, _ = imgs[0].shape
boxes[:, [0, 2]] *= width
boxes[:, [1, 3]] *= height
boxes = cv2_transform.clip_boxes_to_image(boxes, height, width)
# `transform.py` is list of np.array. However, for AVA, we only have
# one np.array.
boxes = [boxes]
# The image now is in HWC, BGR format.
if self._split == "train": # "train"
# 多尺度图像大小
imgs, boxes = cv2_transform.random_short_side_scale_jitter_list(
imgs,
min_size=self._jitter_min_scale,
max_size=self._jitter_max_scale,
boxes=boxes,
)
# 随机裁剪
imgs, boxes = cv2_transform.random_crop_list(
imgs, self._crop_size, order="HWC", boxes=boxes
)
# 水平翻转图像
if self.random_horizontal_flip:
# random flip
imgs, boxes = cv2_transform.horizontal_flip_list(
0.5, imgs, order="HWC", boxes=boxes
)
elif self._split == "val":
# Short side to test_scale. Non-local and STRG uses 256.
imgs = [cv2_transform.scale(self._crop_size, img) for img in imgs]
boxes = [
cv2_transform.scale_boxes(
self._crop_size, boxes[0], height, width
)
]
imgs, boxes = cv2_transform.spatial_shift_crop_list(
self._crop_size, imgs, 1, boxes=boxes
)
if self._test_force_flip:
imgs, boxes = cv2_transform.horizontal_flip_list(
1, imgs, order="HWC", boxes=boxes
)
elif self._split == "test":
# Short side to test_scale. Non-local and STRG uses 256.
imgs = [cv2_transform.scale(self._crop_size, img) for img in imgs]
boxes = [
cv2_transform.scale_boxes(
self._crop_size, boxes[0], height, width
)
]
if self._test_force_flip:
imgs, boxes = cv2_transform.horizontal_flip_list(
1, imgs, order="HWC", boxes=boxes
)
else:
raise NotImplementedError(
"Unsupported split mode {}".format(self._split)
)
# Convert image to CHW keeping BGR order.pytorch通道数在第二个维度
imgs = [cv2_transform.HWC2CHW(img) for img in imgs]
# Image [0, 255] -> [0, 1].归一化处理
imgs = [img / 255.0 for img in imgs]
# 将图片resize到224,224大小
imgs = [
np.ascontiguousarray(
# img.reshape((3, self._crop_size, self._crop_size))
img.reshape((3, imgs[0].shape[1], imgs[0].shape[2]))
).astype(np.float32)
for img in imgs
]
# Do color augmentation (after divided by 255.0).
if self._split == "train" and self._use_color_augmentation:
if not self._pca_jitter_only:
# 图像颜色抖动
imgs = cv2_transform.color_jitter_list(
imgs,
img_brightness=0.4,
img_contrast=0.4,
img_saturation=0.4,
)
# 基于PCA的颜色抖动
imgs = cv2_transform.lighting_list(
imgs,
alphastd=0.1,
eigval=np.array(self._pca_eigval).astype(np.float32),
eigvec=np.array(self._pca_eigvec).astype(np.float32),
)
# Normalize images by mean and std. 正规化
imgs = [
cv2_transform.color_normalization(
img,
np.array(self._data_mean, dtype=np.float32),
np.array(self._data_std, dtype=np.float32),
)
for img in imgs
]
# Concat list of images to single ndarray. 列表转变为图像序列矩阵:3,32,224,224
imgs = np.concatenate(
[np.expand_dims(img, axis=1) for img in imgs], axis=1
)
if not self._use_bgr:
# Convert image format from BGR to RGB.
imgs = imgs[::-1, ...]
# 对超出图像边界的框进行处理
imgs = np.ascontiguousarray(imgs)
imgs = torch.from_numpy(imgs)
boxes = cv2_transform.clip_boxes_to_image(
boxes[0], imgs[0].shape[1], imgs[0].shape[2]
)
return imgs, boxes
def _images_and_boxes_preprocessing(self, imgs, boxes):
"""
This function performs preprocessing for the input images and
corresponding boxes for one clip.
Args:
imgs (tensor): the images.
boxes (ndarray): the boxes for the current clip.
Returns:
imgs (tensor): list of preprocessed images.
boxes (ndarray): preprocessed boxes.
"""
# Image [0, 255] -> [0, 1].
imgs = imgs.float()
imgs = imgs / 255.0
height, width = imgs.shape[2], imgs.shape[3]
# The format of boxes is [x1, y1, x2, y2]. The input boxes are in the
# range of [0, 1].
boxes[:, [0, 2]] *= width
boxes[:, [1, 3]] *= height
boxes = transform.clip_boxes_to_image(boxes, height, width)
if self._split == "train":
# Train split
imgs, boxes = transform.random_short_side_scale_jitter(
imgs,
min_size=self._jitter_min_scale,
max_size=self._jitter_max_scale,
boxes=boxes,
)
imgs, boxes = transform.random_crop(
imgs, self._crop_size, boxes=boxes
)
# Random flip.
imgs, boxes = transform.horizontal_flip(0.5, imgs, boxes=boxes)
elif self._split == "val":
# Val split
# Resize short side to crop_size. Non-local and STRG uses 256.
imgs, boxes = transform.random_short_side_scale_jitter(
imgs,
min_size=self._crop_size,
max_size=self._crop_size,
boxes=boxes,
)
# Apply center crop for val split
imgs, boxes = transform.uniform_crop(
imgs, size=self._crop_size, spatial_idx=1, boxes=boxes
)
if self._test_force_flip:
imgs, boxes = transform.horizontal_flip(1, imgs, boxes=boxes)
elif self._split == "test":
# Test split
# Resize short side to crop_size. Non-local and STRG uses 256.
imgs, boxes = transform.random_short_side_scale_jitter(
imgs,
min_size=self._crop_size,
max_size=self._crop_size,
boxes=boxes,
)
if self._test_force_flip:
imgs, boxes = transform.horizontal_flip(1, imgs, boxes=boxes)
else:
raise NotImplementedError(
"{} split not supported yet!".format(self._split)
)
# Do color augmentation (after divided by 255.0).
if self._split == "train" and self._use_color_augmentation:
if not self._pca_jitter_only:
imgs = transform.color_jitter(
imgs,
img_brightness=0.4,
img_contrast=0.4,
img_saturation=0.4,
)
imgs = transform.lighting_jitter(
imgs,
alphastd=0.1,
eigval=np.array(self._pca_eigval).astype(np.float32),
eigvec=np.array(self._pca_eigvec).astype(np.float32),
)
# Normalize images by mean and std.
imgs = transform.color_normalization(
imgs,
np.array(self._data_mean, dtype=np.float32),
np.array(self._data_std, dtype=np.float32),
)
if not self._use_bgr:
# Convert image format from BGR to RGB.
# Note that Kinetics pre-training uses RGB!
imgs = imgs[:, [2, 1, 0], ...]
boxes = transform.clip_boxes_to_image(
boxes, self._crop_size, self._crop_size
)
return imgs, boxes
def __getitem__(self, idx):
"""
Generate corresponding clips, boxes, labels and metadata for given idx.
Args:
idx (int): the video index provided by the pytorch sampler.
Returns:
frames (tensor): the frames of sampled from the video. The dimension
is `channel` x `num frames` x `height` x `width`.
label (ndarray): the label for correspond boxes for the current video.
time index (zero): The time index is currently not supported for AVA.
idx (int): the video index provided by the pytorch sampler.
extra_data (dict): a dict containing extra data fields, like "boxes",
"ori_boxes" and "metadata".
"""
short_cycle_idx = None
# When short cycle is used, input index is a tupple.
if isinstance(idx, tuple):
idx, self._num_yielded = idx
if self.cfg.MULTIGRID.SHORT_CYCLE:
idx, short_cycle_idx = idx
#-------------------------------------------------------------------#
# 取出video_idx, sec_idx, sec, center_idx,center_idx,center_idx指的
# 是该秒对应的图片帧的索引,以第一个视频第1秒为例,前面的video_idx, sec_idx均为0,
# sec应为902,对应标签文件中开始的视频时间(902秒),center_idx应为30,因为视频在
# 准备数据的时候做了切分,截取了第15分钟到第25分钟的视频,同时每一秒包含30帧图像
# -------------------------------------------------------------------#
video_idx, sec_idx, sec, center_idx = self._keyframe_indices[idx]
# Get the frame idxs for current clip.
# 以center_idx为中心,前后各从32张图片每两帧图片取一帧图片,得到32帧的图片序列
seq = utils.get_sequence(
center_idx,
self._seq_len // 2,
self._sample_rate,
num_frames=len(self._image_paths[video_idx]),
)
# 对应的标签
clip_label_list = self._keyframe_boxes_and_labels[video_idx][sec_idx]
assert len(clip_label_list) > 0
# Get boxes and labels for current clip.分离box和labels
boxes = []
labels = []
for box_labels in clip_label_list:
boxes.append(box_labels[0])
labels.append(box_labels[1])
boxes = np.array(boxes)
# Score is not used.
boxes = boxes[:, :4].copy()
ori_boxes = boxes.copy()
# Load images of current clip. 读取图片序列中的图片
image_paths = [self._image_paths[video_idx][frame] for frame in seq]
imgs = utils.retry_load_images(
image_paths, backend=self.cfg.AVA.IMG_PROC_BACKEND
)
if self.cfg.AVA.IMG_PROC_BACKEND == "pytorch":
# T H W C -> T C H W.
imgs = imgs.permute(0, 3, 1, 2)
# Preprocess images and boxes.
imgs, boxes = self._images_and_boxes_preprocessing(
imgs, boxes=boxes
)
# T C H W -> C T H W.
imgs = imgs.permute(1, 0, 2, 3)
else:
# Preprocess images and boxes 图像预处理
imgs, boxes = self._images_and_boxes_preprocessing_cv2(
imgs, boxes=boxes
)
# Construct label arrays. labels矩阵
label_arrs = np.zeros((len(labels), self._num_classes), dtype=np.int32)
for i, box_labels in enumerate(labels):
# AVA label index starts from 1.
for label in box_labels:
if label == -1:
continue
assert label >= 1 and label <= 80
label_arrs[i][label - 1] = 1
# 将输出准备为张量列表。每个张量对应于独特的路径
imgs = utils.pack_pathway_output(self.cfg, imgs)
metadata = [[video_idx, sec]] * len(boxes)
extra_data = {
"boxes": boxes,
"ori_boxes": ori_boxes,
"metadata": metadata,
}
return imgs, label_arrs, idx, torch.zeros(1), extra_data2.网络结构
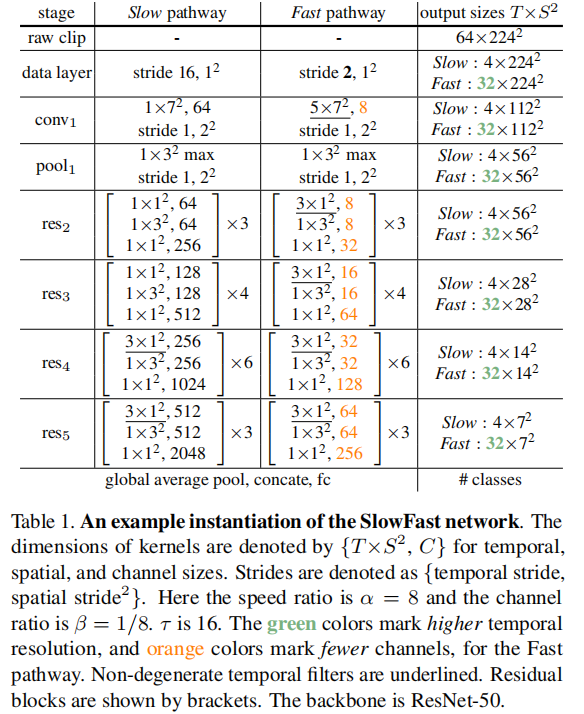
conv1+pool1
如论文中所示,第一层slow pathway和fast pathway均由相应3D卷积构成,对于slow pathway,不对时间进行降采样,在fast pathway,需要获取更多的时序信息,因此,在时间维度slowpathway k=1,而在fast pathway k=5。此外,为了进行特征融合,在h,w维度k均为7,stride保持一致。
结构如下:
VideoModelStem(
(pathway0_stem): ResNetBasicStem(
(conv): Conv3d(3, 64, kernel_size=(1, 7, 7), stride=(1, 2, 2), padding=(0, 3, 3), bias=False)
(bn): BatchNorm3d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(pool_layer): MaxPool3d(kernel_size=[1, 3, 3], stride=[1, 2, 2], padding=[0, 1, 1], dilation=1, ceil_mode=False)
)
(pathway1_stem): ResNetBasicStem(
(conv): Conv3d(3, 8, kernel_size=(5, 7, 7), stride=(1, 2, 2), padding=(2, 3, 3), bias=False)
(bn): BatchNorm3d(8, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(pool_layer): MaxPool3d(kernel_size=[1, 3, 3], stride=[1, 2, 2], padding=[0, 1, 1], dilation=1, ceil_mode=False)
)
)特征融合:
对于特征融合模块,将fast pathway的信息融合到slow pathway中,由于两个路径图像序列在时间上不一致,需要对fast pathway在时间为上进行降采样(k=7)
FuseFastToSlow(
(conv_f2s): Conv3d(8, 16, kernel_size=(7, 1, 1), stride=(4, 1, 1), padding=(3, 0, 0), bias=False)
(bn): BatchNorm3d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)resnetblock
如上图所示,接下来是连续的resnet block层,值得注意的是,在这个resnet block中,均采用3D卷积,同时,fast pathway在时间维度进行采样,slow pathway在较低的层不对时间上进行采样,在较高的层对时间上进行采样。这是作者的实验证明,这样可以提高网络性能。同时,在fast pathway中,均在时间维度进行采样。 同时,不断的将高维特征与低维特征融合。
ResStage(
(pathway0_res0): ResBlock(
(branch1): Conv3d(80, 256, kernel_size=(1, 1, 1), stride=(1, 1, 1), bias=False)
(branch1_bn): BatchNorm3d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(branch2): BottleneckTransform(
(a): Conv3d(80, 64, kernel_size=(1, 1, 1), stride=(1, 1, 1), bias=False)
(a_bn): BatchNorm3d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(a_relu): ReLU(inplace=True)
(b): Conv3d(64, 64, kernel_size=(1, 3, 3), stride=(1, 1, 1), padding=(0, 1, 1), bias=False)
(b_bn): BatchNorm3d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(b_relu): ReLU(inplace=True)
(c): Conv3d(64, 256, kernel_size=(1, 1, 1), stride=(1, 1, 1), bias=False)
(c_bn): BatchNorm3d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(relu): ReLU(inplace=True)
)全局平均池化
按照模型默认的配置文件,经过resnet block后的输出维度为,fast pathway:bs,2048,14,14;slow pathway:1,256,32,14,14.需要注意的是,对于这个任务而言,我们不需要基于一张图片预测动作,而是基于图像序列预测动作。因此,全局3D平均池化的pool_size在fast pathway为[32,1,1],在slow pathway为[8,1,1],也就是说,我们仅仅压缩汇总在时间维度上面的信息。
ROI Align:
首先,对于,输入,我们不仅输入了图片序列,还输入box,ROI Align能够根据box对特征图进行截取。并对小数进行双线性插值。通过ROI Align,能够提取到基于行人的框的特征。
输出结果:
模型的最后,将slow pathway和fast pathway进行拼接,同时用最大池化将特征进行汇总,紧跟一层线性层并用sigmoid归一化,得到动作的概率值。
代码如下:
class SlowFast(nn.Module):
"""
SlowFast model builder for SlowFast network.
Christoph Feichtenhofer, Haoqi Fan, Jitendra Malik, and Kaiming He.
"SlowFast networks for video recognition."
https://arxiv.org/pdf/1812.03982.pdf
"""
def __init__(self, cfg):
"""
The `__init__` method of any subclass should also contain these
arguments.
Args:
cfg (CfgNode): model building configs, details are in the
comments of the config file.
"""
super(SlowFast, self).__init__()
self.norm_module = get_norm(cfg)
self.cfg = cfg
self.enable_detection = cfg.DETECTION.ENABLE
self.num_pathways = 2
self._construct_network(cfg)
init_helper.init_weights(
self,
cfg.MODEL.FC_INIT_STD,
cfg.RESNET.ZERO_INIT_FINAL_BN,
cfg.RESNET.ZERO_INIT_FINAL_CONV,
)
# ---------------------------------------------------#
# 根据配置文件构建网络
# ---------------------------------------------------#
def _construct_network(self, cfg):
"""
Builds a SlowFast model. The first pathway is the Slow pathway and the
second pathway is the Fast pathway.
Args:
cfg (CfgNode): model building configs, details are in the
comments of the config file.
"""
assert cfg.MODEL.ARCH in _POOL1.keys()
pool_size = _POOL1[cfg.MODEL.ARCH]
assert len({len(pool_size), self.num_pathways}) == 1
assert cfg.RESNET.DEPTH in _MODEL_STAGE_DEPTH.keys()
(d2, d3, d4, d5) = _MODEL_STAGE_DEPTH[cfg.RESNET.DEPTH]
num_groups = cfg.RESNET.NUM_GROUPS
width_per_group = cfg.RESNET.WIDTH_PER_GROUP
dim_inner = num_groups * width_per_group
out_dim_ratio = (
cfg.SLOWFAST.BETA_INV // cfg.SLOWFAST.FUSION_CONV_CHANNEL_RATIO
)
temp_kernel = _TEMPORAL_KERNEL_BASIS[cfg.MODEL.ARCH]
self.s1 = stem_helper.VideoModelStem(
dim_in=cfg.DATA.INPUT_CHANNEL_NUM,
dim_out=[width_per_group, width_per_group // cfg.SLOWFAST.BETA_INV],
kernel=[temp_kernel[0][0] + [7, 7], temp_kernel[0][1] + [7, 7]],
stride=[[1, 2, 2]] * 2,
padding=[
[temp_kernel[0][0][0] // 2, 3, 3],
[temp_kernel[0][1][0] // 2, 3, 3],
],
norm_module=self.norm_module,
)
self.s1_fuse = FuseFastToSlow(
width_per_group // cfg.SLOWFAST.BETA_INV,
cfg.SLOWFAST.FUSION_CONV_CHANNEL_RATIO,
cfg.SLOWFAST.FUSION_KERNEL_SZ,
cfg.SLOWFAST.ALPHA,
norm_module=self.norm_module,
)
self.s2 = resnet_helper.ResStage(
dim_in=[
width_per_group + width_per_group // out_dim_ratio,
width_per_group // cfg.SLOWFAST.BETA_INV,
],
dim_out=[
width_per_group * 4,
width_per_group * 4 // cfg.SLOWFAST.BETA_INV,
],
dim_inner=[dim_inner, dim_inner // cfg.SLOWFAST.BETA_INV],
temp_kernel_sizes=temp_kernel[1],
stride=cfg.RESNET.SPATIAL_STRIDES[0],
num_blocks=[d2] * 2,
num_groups=[num_groups] * 2,
num_block_temp_kernel=cfg.RESNET.NUM_BLOCK_TEMP_KERNEL[0],
nonlocal_inds=cfg.NONLOCAL.LOCATION[0],
nonlocal_group=cfg.NONLOCAL.GROUP[0],
nonlocal_pool=cfg.NONLOCAL.POOL[0],
instantiation=cfg.NONLOCAL.INSTANTIATION,
trans_func_name=cfg.RESNET.TRANS_FUNC,
dilation=cfg.RESNET.SPATIAL_DILATIONS[0],
norm_module=self.norm_module,
)
self.s2_fuse = FuseFastToSlow(
width_per_group * 4 // cfg.SLOWFAST.BETA_INV,
cfg.SLOWFAST.FUSION_CONV_CHANNEL_RATIO,
cfg.SLOWFAST.FUSION_KERNEL_SZ,
cfg.SLOWFAST.ALPHA,
norm_module=self.norm_module,
)
for pathway in range(self.num_pathways):
pool = nn.MaxPool3d(
kernel_size=pool_size[pathway],
stride=pool_size[pathway],
padding=[0, 0, 0],
)
self.add_module("pathway{}_pool".format(pathway), pool)
self.s3 = resnet_helper.ResStage(
dim_in=[
width_per_group * 4 + width_per_group * 4 // out_dim_ratio,
width_per_group * 4 // cfg.SLOWFAST.BETA_INV,
],
dim_out=[
width_per_group * 8,
width_per_group * 8 // cfg.SLOWFAST.BETA_INV,
],
dim_inner=[dim_inner * 2, dim_inner * 2 // cfg.SLOWFAST.BETA_INV],
temp_kernel_sizes=temp_kernel[2],
stride=cfg.RESNET.SPATIAL_STRIDES[1],
num_blocks=[d3] * 2,
num_groups=[num_groups] * 2,
num_block_temp_kernel=cfg.RESNET.NUM_BLOCK_TEMP_KERNEL[1],
nonlocal_inds=cfg.NONLOCAL.LOCATION[1],
nonlocal_group=cfg.NONLOCAL.GROUP[1],
nonlocal_pool=cfg.NONLOCAL.POOL[1],
instantiation=cfg.NONLOCAL.INSTANTIATION,
trans_func_name=cfg.RESNET.TRANS_FUNC,
dilation=cfg.RESNET.SPATIAL_DILATIONS[1],
norm_module=self.norm_module,
)
self.s3_fuse = FuseFastToSlow(
width_per_group * 8 // cfg.SLOWFAST.BETA_INV,
cfg.SLOWFAST.FUSION_CONV_CHANNEL_RATIO,
cfg.SLOWFAST.FUSION_KERNEL_SZ,
cfg.SLOWFAST.ALPHA,
norm_module=self.norm_module,
)
self.s4 = resnet_helper.ResStage(
dim_in=[
width_per_group * 8 + width_per_group * 8 // out_dim_ratio,
width_per_group * 8 // cfg.SLOWFAST.BETA_INV,
],
dim_out=[
width_per_group * 16,
width_per_group * 16 // cfg.SLOWFAST.BETA_INV,
],
dim_inner=[dim_inner * 4, dim_inner * 4 // cfg.SLOWFAST.BETA_INV],
temp_kernel_sizes=temp_kernel[3],
stride=cfg.RESNET.SPATIAL_STRIDES[2],
num_blocks=[d4] * 2,
num_groups=[num_groups] * 2,
num_block_temp_kernel=cfg.RESNET.NUM_BLOCK_TEMP_KERNEL[2],
nonlocal_inds=cfg.NONLOCAL.LOCATION[2],
nonlocal_group=cfg.NONLOCAL.GROUP[2],
nonlocal_pool=cfg.NONLOCAL.POOL[2],
instantiation=cfg.NONLOCAL.INSTANTIATION,
trans_func_name=cfg.RESNET.TRANS_FUNC,
dilation=cfg.RESNET.SPATIAL_DILATIONS[2],
norm_module=self.norm_module,
)
self.s4_fuse = FuseFastToSlow(
width_per_group * 16 // cfg.SLOWFAST.BETA_INV,
cfg.SLOWFAST.FUSION_CONV_CHANNEL_RATIO,
cfg.SLOWFAST.FUSION_KERNEL_SZ,
cfg.SLOWFAST.ALPHA,
norm_module=self.norm_module,
)
self.s5 = resnet_helper.ResStage(
dim_in=[
width_per_group * 16 + width_per_group * 16 // out_dim_ratio,
width_per_group * 16 // cfg.SLOWFAST.BETA_INV,
],
dim_out=[
width_per_group * 32,
width_per_group * 32 // cfg.SLOWFAST.BETA_INV,
],
dim_inner=[dim_inner * 8, dim_inner * 8 // cfg.SLOWFAST.BETA_INV],
temp_kernel_sizes=temp_kernel[4],
stride=cfg.RESNET.SPATIAL_STRIDES[3],
num_blocks=[d5] * 2,
num_groups=[num_groups] * 2,
num_block_temp_kernel=cfg.RESNET.NUM_BLOCK_TEMP_KERNEL[3],
nonlocal_inds=cfg.NONLOCAL.LOCATION[3],
nonlocal_group=cfg.NONLOCAL.GROUP[3],
nonlocal_pool=cfg.NONLOCAL.POOL[3],
instantiation=cfg.NONLOCAL.INSTANTIATION,
trans_func_name=cfg.RESNET.TRANS_FUNC,
dilation=cfg.RESNET.SPATIAL_DILATIONS[3],
norm_module=self.norm_module,
)
if cfg.DETECTION.ENABLE:
self.head = head_helper.ResNetRoIHead(
dim_in=[
width_per_group * 32,
width_per_group * 32 // cfg.SLOWFAST.BETA_INV,
],
num_classes=cfg.MODEL.NUM_CLASSES,
pool_size=[
[
cfg.DATA.NUM_FRAMES
// cfg.SLOWFAST.ALPHA
// pool_size[0][0],
1,
1,
],
[cfg.DATA.NUM_FRAMES // pool_size[1][0], 1, 1],
],
resolution=[[cfg.DETECTION.ROI_XFORM_RESOLUTION] * 2] * 2,
scale_factor=[cfg.DETECTION.SPATIAL_SCALE_FACTOR] * 2,
dropout_rate=cfg.MODEL.DROPOUT_RATE,
act_func=cfg.MODEL.HEAD_ACT,
aligned=cfg.DETECTION.ALIGNED,
detach_final_fc=cfg.MODEL.DETACH_FINAL_FC,
)
else:
self.head = head_helper.ResNetBasicHead(
dim_in=[
width_per_group * 32,
width_per_group * 32 // cfg.SLOWFAST.BETA_INV,
],
num_classes=cfg.MODEL.NUM_CLASSES,
pool_size=[None, None]
if cfg.MULTIGRID.SHORT_CYCLE
or cfg.MODEL.MODEL_NAME == "ContrastiveModel"
else [
[
cfg.DATA.NUM_FRAMES
// cfg.SLOWFAST.ALPHA
// pool_size[0][0],
cfg.DATA.TRAIN_CROP_SIZE // 32 // pool_size[0][1],
cfg.DATA.TRAIN_CROP_SIZE // 32 // pool_size[0][2],
],
[
cfg.DATA.NUM_FRAMES // pool_size[1][0],
cfg.DATA.TRAIN_CROP_SIZE // 32 // pool_size[1][1],
cfg.DATA.TRAIN_CROP_SIZE // 32 // pool_size[1][2],
],
], # None for AdaptiveAvgPool3d((1, 1, 1))
dropout_rate=cfg.MODEL.DROPOUT_RATE,
act_func=cfg.MODEL.HEAD_ACT,
detach_final_fc=cfg.MODEL.DETACH_FINAL_FC,
cfg=cfg,
)
def forward(self, x, bboxes=None):
x = x[:] # avoid pass by reference
# stem:conv1+pool1
x = self.s1(x)
x = self.s1_fuse(x)
x = self.s2(x)
x = self.s2_fuse(x)
for pathway in range(self.num_pathways):
pool = getattr(self, "pathway{}_pool".format(pathway))
x[pathway] = pool(x[pathway])
x = self.s3(x)
x = self.s3_fuse(x)
x = self.s4(x)
x = self.s4_fuse(x)
x = self.s5(x)
if self.enable_detection:
x = self.head(x, bboxes)
else:
x = self.head(x)
return x