Pod 是可以在 Kubernetes 中创建和管理的、最小的可部署的计算单元; Pod 中会启动一个或一组紧密相关的业务容器, 各个业务容器相当于Pod 中的各个进程, 此时就可以将Pod 作为虚拟机看待; 在创建 Pod 时会启动一个init容器, 用来初始化存储和网络, 其余的业务容器都将在init容器启动后启动, 业务容器共享init容器的存储和网络; Pod 只是一个逻辑单元, 并不是真实存在的“主机”, 这种类比主机的概念可以更好的符合现有互联网中几乎所有的虚拟化设计; 像之前运行在虚拟机中的 nginx、mysql、php均可以使用对应的镜像运行出对应的容器在Pod中, 来类比虚拟机中运行这三者;
因为是要学习,所以资源清单直接编写的是pod的资源清单,而在正常生产环境中,是去编写的Deployment,DaemonSet,ReplicaSet,Service,Cronjob,Job这种控制器的资源清单去启动pod,而不是直接去编写pod的清单,一定要明确这一点,生产中不会直接去编写pod的清单,但是pod的清单是学习中必须经过的一个坎。这个坎,迈过去后面的控制器资源的清单就好写了。pod的清单是供我们学习的。
k8s中的pod在刚开始就讲了很多关于pod的东西,里面有初始化容器,初始化容器会拉取我们的文件,比如:web server业务容器和初始化容器会共享一个磁盘拉取文件,网络什么的。这就是初始化容器做的。
对于 Pod 而言, 在运行的过程中, k8s为了控制其生命周期的状态(就必须增加手段) 增加了容器探测指针、资源限额、期望状态保持、多容器结合、安全策略设定、控制器受管、故障处理策略 等;这些都是我们在pod里面单独设置的一些手段来去更好的将pod运行在k8s集群中,Pod在平时是不能够被单独创建的, 而是需要使用控制器对其创建, 这样可以时刻保持Pod的期望状态;
在k8s里,怎么编写一个web server的服务
单容器 Pod:一个pod里面只启动一个容器,1/1的角度,
容器探针
在k8s中,如何保证线上所服务的容器都是正常的状态,那需要使用k8s提供的东西-探针。
探针是由在node节点中所运行的组件kubelet去进行操作的,直接下放于kubelet进行控制,kubelet在容器里面是使用一个探测的指令或者http的请求,或者探测端口的命令,去探测容器中的服务是否正常的启动状态。
在pod里比较容易得到容器的状态。
通过查进程可以判断容器的正常与否
可以探测它的端口,在指令集里会有curl命令,包括在探测的过程中,主要操作的代理对象是在机器中所存在的kubelet
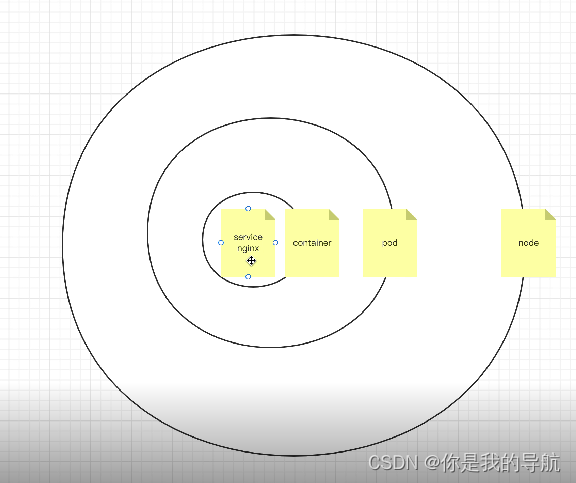
node里面运行pod,pod里面运行容器,容器里面运行服务service nginx
怎么去探测一个服务的存活性?
看状态:systemctl status nginx | grep running if [ $? -eq 0 ];then echo ok; fi
容器是启动的,里面的进程不一定是启动的,在部署tomcat的时候,启动过程中大概需要花多长时间,java的应用启动时间很长,在k8s设置探针的时候,每隔15秒种探测一次,总共探测三次,在45秒内没有启动起来,就认为是失败的,就会把它销毁,启动一个新的,但是程序启动的时间大概需要90秒钟。如果没有了解到程序启动的快或慢的情况,用45秒钟去判断,会导致无限的重启,无限的新建,无限的销毁,死循环,因为时间够不上。
在探针里使用的一般就是三种方式:
1.命令 (一般不会采用,这种方式不确定,不能过滤它的running,判断上一条指令执行的正确与否)在容器里是没有systemctl这个指令的,但容器会带有系统内建指令,which ps存在于/bin/ps,不管容器运行什么服务及打出来的镜像是什么样的,它里面肯定会有ps指令,要去找到通用性比较强的指令。用 ps -aux | grep nginx
2.可以探测它的端口,which curl 在探测过程中,主要操作的代理对象是在机器中所存在的kubelet去控制容器,但是中间又穿插着docker,docker去控制容器,在容器里运行curl,还有ps,grep。
kubelet -> docker -> contianer -> curl/ps/grep/telnet
也就是说kubelet间接性的去容器里执行指令,然后得到指令所返回的状态码,ps可以得到系统的返回码,0正确,非0为错误,对于curl会有一个状态码,400,402,403 大于等于400的状态码都是错的,
使用kubelet所在主机里的命令去探测容器的一个暴露的端口(不能在容器内部出现,外部可以使用telnet探测端口)
探测端口:ss -anptu | grep :80 telnet 并不一定会存在于系统里面,用的时候比较小心,telnet 127.0.0.1 80
探针检查的对象是容器里的服务。
livenessProbe: 指示容器是否正在运行.如果存活态探测失败,则 kubelet 会杀死容器, 并且容器将根据其重启策略决定未来.如果容器不提供存活探针, 则默认状态为 Success.
直接杀死容器,而不会动pod。
readinessProbe: 指示容器是否准备好为请求提供服务.如果就绪探测失败, 端点控制器将从与 Pod 匹配的所有服务的端点列表中删除该 Pod 的 IP 地址. 初始延迟之前的就绪的状态值默认为 Failure. 如果容器不提供就绪态探针,则默认状态为Success
会删pod,
startupProbe: 指示容器中的应用是否已经启动.如果提供了启动探针,则所有其他探针都会被禁用,直到此探针成功为止.如果启动探测失败,kubelet 将杀死容器,而容器依其重启策略进行重启. 如果容器没有提供启动探测,则默认状态为 Success。
针对启动比较慢的探针,进行探测使用的。
startup的优先级会高于readiness和liveness,三个探针一般是可以一起写的,针对java的应用一般都会先写startup的探针再写readinessProbe,startup再探测到容器已经启动起来之后,会介入readiness进行检测,对于python,go这种应用程序,它们启动的速度一般比较快,所以我们通常不会使用startup,而是使用liveness和readiness两种探针结合在一起使用。
在探针里每种探针会提供三种方法
Probe是由kubelet对容器执行的定期诊断. 要执行诊断,kubelet 调用由容器实现的Handler(处理程序).有三种类型的处理程序:
-
ExecAction: 在容器内执行指定命令.如果命令退出时返回码为 0 则认为诊断成功.
-
TCPSocketAction: 对容器的 IP 地址上的指定端口执行 TCP 检查.如果端口打开,则诊断被认为是成功的否则是失败。
-
HTTPGetAction: 对容器的 IP 地址上指定端口和路径执行 HTTP Get 请求.如果响应的状态码大于等于 200 且小于 400,则诊断被认为是成功的.