目录
系统介绍
本系统灵感源自钢铁侠的贾维斯是基于手势识别的计算机交互系统,利用OpenCV、Mediapipe识别手部关键点;利用TensorFlow搭建神经网络,以识别不同的手势;利用PyWin32等库调用Windows api操作Windows系统。
OpenCV
OpenCV是一个基于Apache2.0许可(开源)发行的跨平台计算机视觉和机器学习软件库,它轻量级而且高效——由一系列 C 函数和少量 C++ 类构成,提供了Python的接口,实现了图像处理和计算机视觉方面的很多通用算法。
这里用opencv实现调用摄像头,绘制图像等操作。
Mediapipe
Mediapipe(下面简称mp)是Google的一个开源项目,可以提供开源的、跨平台的常用机器学习方案。mp实际上是一个集成的机器学习视觉算法的工具库,包含了人脸检测、人脸关键点、手势识别、头像分割和姿态识别等各种模型。
本系统中主要用到了mp中的手部关键点检测模型MediaPipe Hands。这是一个识别效果非常优秀的模型,手掌检测中实现了95.7%的平均精度。我认为了解Mediapipe Hand的实现原理,对机器学习和深度学习有很好的启发作用。在官网上了解到,首先,mp训练的是手掌检测器而不是手部检测器,因为检测手掌和拳头等刚性物体的边界框比用关节手指检测手要简单得多。其次,由于手掌是较小的物体,因此非最大抑制算法即使在双手自遮挡的情况下(如握手)也能很好地工作。再次,可以使用方形边界框(机器学习术语中的锚点)对手掌进行建模,忽略其他纵横比,从而将锚点数量减少3-5倍。此外,编码器-解码器特征提取器用于更大的场景上下文感知,即使对于小对象也是如此(类似于RetinaNet方法)。
在整个图像上进行手掌检测后,mp随后的手部特征点模型通过回归对检测到的手部区域内的21个3D手关节坐标进行精确的关键点定位,即直接坐标预测。该模型学习一致的内部手部姿势表示,即使对部分可见的手和自我遮挡也能很好识别。
为了获得真实数据,mp手动标注了具有 21个3D坐标的 约3万张真实世界图像,如下所示(如果根据相应的坐标存在,mp从图像深度图中获取 Z 值)。为了更好地覆盖可能的手部姿势,并对手部几何体的性质提供额外的监督,mp还在各种背景上渲染高质量的合成手部模型,并将其映射到相应的3D坐标。

顶部:对齐的手部裁剪传递到追踪网络,并带有地面实况注释。底部:渲染的带有地面实况注释的合成手部图像。
TensorFlow
TensorFlow由谷歌人工智能团队谷歌大脑(Google Brain)开发和维护,是一个基于数据流编程的符号数学系统,被广泛应用于各类机器学习算法的编程实现。我们主要用到的是tensorflow.keras。Keras是用于构建和训练深度学习模型的 TensorFlow 高阶 API。利用此 API,可实现快速原型设计、先进的研究和生产。
PyWin32
是一个针对Windows平台对Python做的扩展,包装了Windows 系统的 Win32 API,能创建和使用 COM 对象和图形窗口界面。系统通过pywin32调用win32api实现电脑键鼠的操作,调用win32gui实现对电脑窗口的操作。
数据处理
要实现多种手势的识别,首先想到的就是卷积神经网络,卷积神经网络需要的训练数据比较多,并且我们需要识别某些特定的手势,在网上并没有找到理想的公开数据集。
通过mediapipe提取特征
卷积神经网络中卷积层作用就是在图片中提取特征,最后将提取出的特征,交给全连接层做出预测。于是我想到,mediapipe可以用来识别手部关键点,使用mediapipe提取出手部的关键点坐标,把关键点作为特征,取代卷积层,直接让全连接层去处理这些关键点的坐标信息,就可以把问题简化,将卷积问题转换成回归问题。
这样做将mediapipe本身的误差和神经网络中的误差叠加到一起,并且把手势识别的条件建立在识别出关键点之上。虽然会增加误差,但无疑可以简化问题,用更少的数据量解决问题,且meiapipe的识别率已经很高。所以我认为,这样的设计可以满足系统要求。

以握拳动作为例的数据采集
mediapipe的处理结果中包含多只手部信息对象,每个手部信息对象又包含21个坐标点的对象,每个坐标点对象有三个值,分别为x,y,z,是相对于图片左上角的坐标,并作了归一化处理。手部关键点数据的存储形式是以可迭代的对象进行存储的,无法用于训练,所以要先将其处理成numpy格式,我将所有数据处理为一个三维的numpy数组,其shape为(2,21,3)。2代表识别出的两只手,第一个是左手,第二个是右手;21代表每只手有21个坐标点,索引值如下图所示;3代表每个坐标点有x,y,z三个坐标。
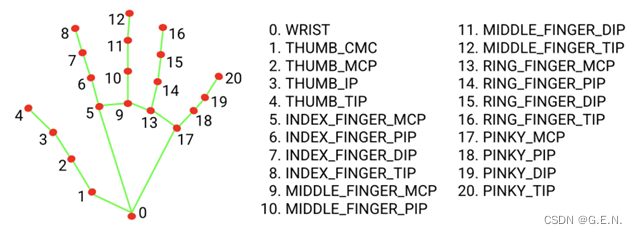
mediapipe关键点索引
def landmarks_to_numpy(results):
"""
将landmarks格式的数据转换为numpy格式的数据
numpy shape:(2, 21, 3)
:param results:
:return:
"""
shape = (2, 21, 3)
landmarks = results.multi_hand_landmarks
if landmarks is None:
# 没有检测到手
return np.zeros(shape)
elif len(landmarks) == 1:
# 检测出一只手,先判断是左手还是右手
label = results.multi_handedness[0].classification[0].label
hand = landmarks[0]
# print(label)
if label == "Left":
return np.array([np.array([[hand.landmark[i].x, hand.landmark[i].y, hand.landmark[i].z] for i in range(21)]),
np.zeros((21, 3))])
else:
return np.array([np.zeros((21, 3)),
np.array([[hand.landmark[i].x, hand.landmark[i].y, hand.landmark[i].z] for i in range(21)])])
elif len(landmarks) == 2:
# print(results.multi_handedness)
lh_idx = 0
rh_idx = 0
for idx, hand_type in enumerate(results.multi_handedness):
label = hand_type.classification[0].label
if label == 'Left':
lh_idx = idx
if label == 'Right':
rh_idx = idx
lh = np.array(
[[landmarks[lh_idx].landmark[i].x, landmarks[lh_idx].landmark[i].y, landmarks[lh_idx].landmark[i].z] for i in range(21)])
rh = np.array(
[[landmarks[rh_idx].landmark[i].x, landmarks[rh_idx].landmark[i].y, landmarks[rh_idx].landmark[i].z] for i in range(21)])
return np.array([lh, rh])
else:
return np.zeros((2, 21, 3))转化为相对坐标:
虽然我们拿到了关键点的坐标信息,但每个坐标值都是关键点相对于图片左上角的的坐标,坐标数值受手部在图片中的位置影响大,要做到实际应用中手势的灵活识别,模型就不能受手部在图片中位置的影响。为了消除位置的影响,我将手部所有的关键点的坐标数值,与手掌根部关键点(上图中的0点)相减

这样每个关键点的坐标就变成了相对与手掌根部点的相对位置,关键点由绝对坐标变成了相对坐标。将相对位置得到后,再将手掌根部的关键点丢弃,将位置对数值的影响最小化。经过这样的处理,即使训练时的数据中手部几乎都在图片中的同样位置,测试时也可以在不同的位置得到好的测试结果。
42 def relative_coordinate(arr, point):
43 """
44 转化为相对坐标
45 :param arr: numpy数组
46 :param point: 手掌根部坐标点
47 :return:
48 """
49 return arr - point
均值方差归一化(标准化):
通过相对坐标的转化,虽然位置的影响几乎消除了,但是距离对数值的影响依然存在。当手部距离摄像头近时,相对位置差值较大;当手部距离摄像头远时,相对位置差值较小;
所以要将数据进行均值方差归一化,也称为标准化。
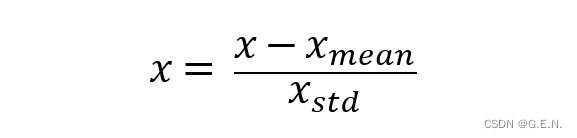
它是把所有数据归到均值为0,方差为1的分布中。即确保最终得到的数据均值为0,方差为1。如下图所示,同样的握拳姿势,在距离镜头近时,相对坐标大致分布在0.3至-0.4之间,而距离镜头远时,相对坐标大致分布在0.15至-0.15之间。经过标准化后,数据的分布被统一映射至-2至2之间,让每一个特征数据的影响力是相同的。这样就大大降低了手部与摄像头距离对数据的影响。
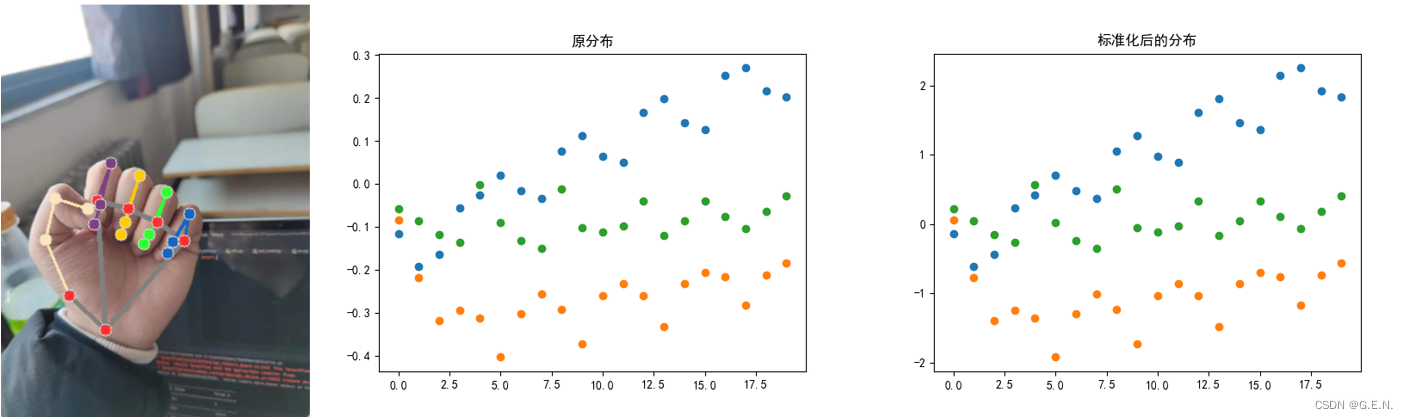
近距离握拳姿势的数据分布

远距离握拳姿势的数据分布
def standardization(hand_arr):
"""
均值方差归一化
:param hand_arr:numpy数组
:return:
"""
return (hand_arr - np.mean(hand_arr)) / np.std(hand_arr)def process_mark_data(hand_arr):
"""
处理手部坐标点信息数组
将所有点处理为相对于手掌根部点的相对位置
:param hand_arr: 手部numpy数组
:return:
"""
lh_root = hand_arr[0, 0]
rh_root = hand_arr[1, 0]
lh_marks = relative_coordinate(hand_arr[0, 1:], lh_root)
rh_marks = relative_coordinate(hand_arr[1, 1:], lh_root)
if lh_marks.all() != 0:
lh_marks = standardization(lh_marks)
if rh_marks.all() != 0:
rh_marks = standardization(rh_marks)
return np.array([lh_marks, rh_marks])测试效果:
经过以上的数据处理,转化为相对坐标大大降低了手部在图片中位置的影响,均值方差归一化(标准化)大大降低了手部距离摄像头距离的影响。这使得少量的训练数据得到充分的发挥,同样的手势数据可以适应在图片中的不同位置、不同距离。
在不使用图片数据增强的情况下,仅使用22张照片,包括16个正例和6个负例,就可以达到非常好的测试效果,可以基本满足通过手势识别操作计算机的需求。关于准确率等指标的探讨放在后面一章的神经网络中,这里只看效果。

测试握拳手势的训练集
因为只是测试阶段,这里仅仅做了一个握拳手势的识别,属于二分类问题。神经网络的输出层的激活函数为sigmoid,经过神经网络的训练后,将模型部署在电脑摄像头上。0表示步时握拳姿势,1表示握拳姿势。实际效果还是很不错的,在摄像头区域的各个位置,和较远距离的情况下,均能精准识别。

在距离摄像头不同距离和不同图片位置下的测试结果
神经网络
前面直接用mediapipe提取出了手部的关键点,接下来要用神经网络来对关键点的坐标信息进行预测。
网络结构设计
神经网络的结构如下:
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten (Flatten) (1, 60) 0
_________________________________________________________________
dense (Dense) (1, 512) 31232
_________________________________________________________________
dense_1 (Dense) (1, 512) 262656
_________________________________________________________________
dense_2 (Dense) (1, 4) 2052
=================================================================
Total params: 295,940
Trainable params: 295,940
Non-trainable params: 0
_________________________________________________________________
首先,神经网络的第一层为Flatten。这个层可以将输入的数据拉成一条向量,以便数据更好的输入神经网络。
其次就是真正发挥作用的隐藏层。这里仿照VGG,设计了两个神经元数量相同的隐藏层。理论上讲,只要神经网络的层数够深,它可以拟合任意一个函数。但神经网络的设计并不是越深越好,前面我们已经把手势识别的卷积问题,通过关键点的识别转换为了简单的回归问题,所以并不需要多么深的神经网络,过深的神经网络反而会造成过拟合、计算成本加大、梯度不稳定、网络退化等一系列问题。因为解决的问题比较简单,太宽的网络会提取过多重复特征,因此每层神经元的个数也没有选择VGG的4096,简化为512个神经元。
最后是输出层。因为要识别的是多个手势,输出层的激活函数为softmax,分别输出每个类别对应的预测概率。
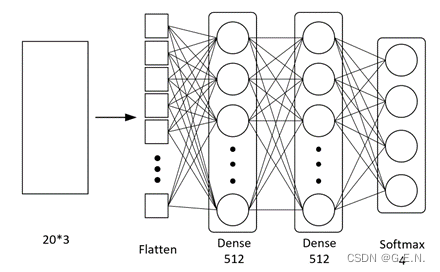
神经网络结构图
def get_model():
model = models.Sequential([
layers.Flatten(),
layers.Dense(512, activation='relu', kernel_regularizer=keras.regularizers.l2(1e-3)),
layers.Dense(512, activation='relu', kernel_regularizer=keras.regularizers.l2(1e-3)),
layers.Dense(4, activation='softmax')
])
return model激活函数
引入激活函数是为了增加神经网络模型的非线性,没有激活函数的神经网络叠加了若干层之后,还是一个线性变换,失去了多层神经网络的作用。下图很好的诠释了激活函数的作用,使用激活函数的神经网络可以将数据拟合的更好,而未使用激活函数的神经网络只能拟合一个平面。
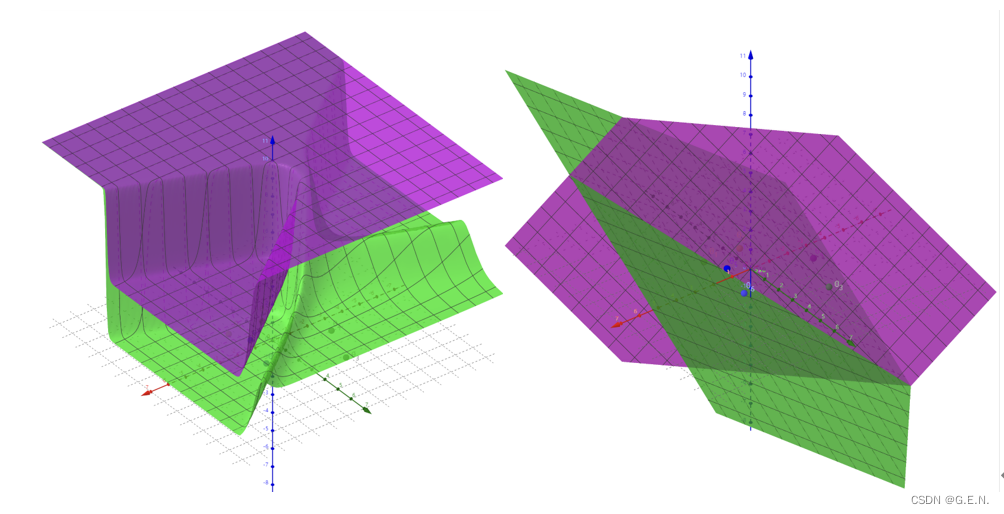
使用激活函数与未使用激活函数的神经网络函数图像对比
一开始我认为,隐藏层的第一层不应该使用流行的relu激活函数,原因是我认为特征值是相对坐标,所以有一大部分的值为负值,而relu激活函数会将负值变为0,这样会造成大部分数据的丢失。但后来我发现这样的理解是不对的,因为激活函数作用在神经元输出的位置。虽然relu会将负值变为0,但权重也可以是负数。负值的特征值与一个负值的权重参数相乘,再加上偏置参数,这才是激活函数的输入。权重参数和偏置参数是在反向传播的过程中逐步确定的。
所以特征值取值的正负对于激活函数的选择,有影响,但没有决定性作用。
那么应该如何选择合适的激活函数?
目前较为流行的激活函数是relu激活函数,它逐渐取代了一开始的sigmoid、tanh等激活函数,常被用于较深层的神经网络中。原因是sigmoid、tanh这样的函数存在饱和区,当数据靠近饱和区时,导数趋近于0,这样就会造成反向传播过程中的梯度消失,无法有效训练参数。
relu激活函数虽然目前是最流行的激活函数,但是它的劣势在于会将负数化0,会造成部分的数据丢失。况且我们的神经网络只有简单的两层,所以sigmoid与tanh这样的激活函数的效果也不一定会差。而tanh激活函数相较于sigmoid函数来说,我认为是更优的。因为sigmoid激活函数的输出是0-1的,而tanh函数的输出是-1-1的,相当于做了标准化处理。
具体到底哪个激活函数的效果比较好,只靠分析是难以确定的,因此我把激活函数也作为一个超参数,在训练时调整出最优解。
神经网络的训练过程
训练时将训练集分为多个批(batch),Keras中权重参数的默认初始化为glorot uniform(均匀分布初始化),可以理解为初始化权重参数都是随机数,每训练一批(batch)数据都会经过以下过程:
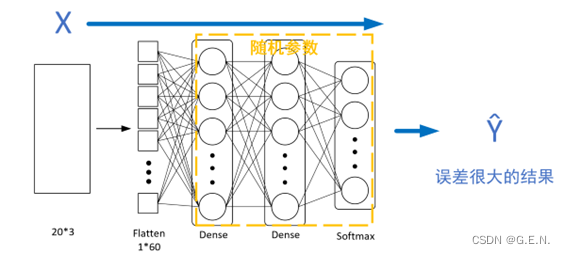
(1)正向传播(前向传播):
特征数据会按照神经网络传播的方向,输入到神经网络中,并由神经网络给出输出数据,此时神经网络中的参数是随机的,肯定会得到误差很大的结果。
(2)计算误差:
要让神经网络做的更好,就要计算出预测值与真实值之间的误差,在分类问题中,最常用的误差为交叉熵损失函数(CrossEntropy Loss)。交叉熵是信息论中的一个重要概念,主要用于度量两个概率分布间的差异性。
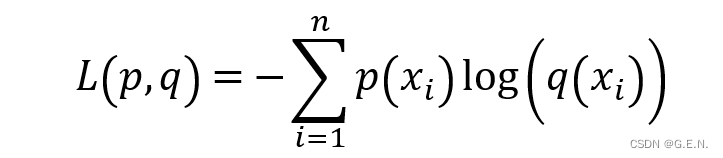
p(x)表示样本的真实分布,q(x)表示模型所预测的分布。
(3)反向传播:
计算出预测值与真实值之间的误差后,就要不断缩小二者之间的误差,才能接近真实值的预测值。
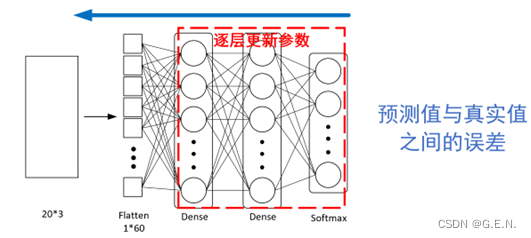
获取到误差后通过随机梯度下降,更新每层的权重参数和偏置参数。因为每层的误差是由本层的权重参数、偏置参数、本层输入决定的,而本层的输入又是上一层的输出。所以我们可以将误差反传给上一层,再通过同样的方式更新上一层的参数,直至所有权重参数和偏置参数更新完毕。
经过以上三个步骤,一批(batch)训练数据就训练完毕,当训练集所有的批(batch)训练完毕,也就是训练集的所有数据都被用作训练,成为一代(epoch),训练多少epoch作为超参数在训练模型是确定。
模型调参
一开始考虑到数据比较少,想用k折交叉验证的方式来进行训练和调参,但是后来借鉴别人的思路,写了一个截取帧数据的程序,可以很快的制造数据。并且数据比较简单,模型损失曲线可以很快收敛,准确度也比较高,所以就没必要再用k折交叉验证进行训练和调参了。
通过截取帧数据的程序,获取到了3000多个numpy数组数据(包括左右手的三个手势)作为训练数据,并随机打乱,以7:3的比例划分训练集与验证集。
训练过程中,神经网络两个隐藏层均使用relu激活函数;每个隐藏层均作L2正则化参数为1e-3;训练过程中使用Adam优化器,初始参数为1e-3;损失函数使用的是二元交叉熵损失函数;batch_size设置为64;训练50 epoch。
可能是因为数据比较简单,只是一个20*3的二维矩阵,神经网络可以很好的拟合这些数据。使用以上的超参数,训练集上的loss曲线收敛在0.05左右,验证集上的loss也收敛在0.05附近;训练集上的准确率最后达到了0.9930,验证集上的准确率也达到了0.9837。这样的准确率我认为不再需要进行别的调参,完全可以满足系统识别的需求。
以下为训练时控制台输出的部分数据。
Epoch 1/50
47/47 [==============================] - 1s 8ms/step - loss: 0.7626 - accuracy: 0.7665 - val_loss: 0.5135 - val_accuracy: 0.9199
………………
Epoch 50/50
47/47 [==============================] - 0s 4ms/step - loss: 0.0510 - accuracy: 0.9930 - val_loss: 0.0592 - val_accuracy: 0.9837
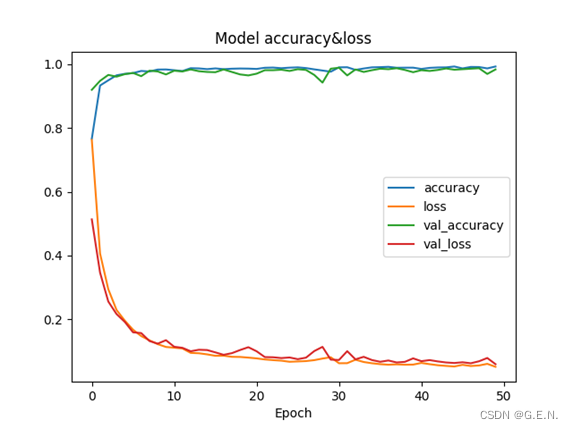
训练时各参数的变化曲线
语音唤醒
作为对语音识别领域的一次简单探索,系统加入了语音唤醒的设计。预期效果为:程序运行后,当用户对电脑说出“Hi,Jarvis!”唤醒词,系统便进入正常运行状态。
因为本系统的主要任务是手势识别,所以实现语音唤醒仅作探索,不做深入研究。但是在研究过程中产生了一些对神经网络新的理解和看法,所以将其单独作为一章将其记录下来。
监听麦克风
要实现语音唤醒,就要实时监听麦克风,获取到麦克风中的音频,这里用pyaudio获取麦克风实例。以p.open()函数获取麦克风数据流,然后读取5个CHUNK,并从中获取一个最大值,这个最大值可以理解为音量。若音量高于设定的阈值,则在数据流中读取30个CHUNK。为了保证每次获取到的音频长度相同,这里设置了固定的30个CHUNK,30个CHUNK已经足够用户说出“Hi,Jarvis!”唤醒词,而如果用户说的语音较长,将会在30个CHUNK后截断。最后将录制的30个CHUNK保存至.wav格式的文件中。
这就实现了当麦克风中出现了一个较大声音后,开始录固定时长的音频。
def monitor_mic(th, filename):
CHUNK = 512
FORMAT = pyaudio.paInt16
CHANNELS = 1
RATE = 16000 # 录音时的采样率
WAVE_OUTPUT_FILENAME = filename + ".wav"
p = pyaudio.PyAudio()
stream = p.open(format=FORMAT,
channels=CHANNELS,
rate=RATE,
input=True,
frames_per_buffer=CHUNK)
frames = []
while True:
for i in range(0, 5):
data = stream.read(CHUNK)
frames.append(data)
audio_data = np.frombuffer(data, dtype=np.short)
temp = np.max(audio_data)
if temp > th:
frames2 = []
print("detected a signal")
print('current threshold:', temp)
# 这里只录制30个CHUNK
print("recording")
for i in range(0, 30):
data2 = stream.read(CHUNK)
frames2.append(data2)
stream.stop_stream()
stream.close()
p.terminate()
wf = wave.open(WAVE_OUTPUT_FILENAME, 'wb')
wf.setnchannels(CHANNELS)
wf.setsampwidth(p.get_sample_size(FORMAT))
wf.setframerate(RATE)
wf.writeframes(b''.join(frames2))
wf.close()
break将音频读取为numpy
获取到音频数据后,要对音频数据进行分析,才能识别出用户是否说出了唤醒词。这里使用scipy.io.wavfile.read()函数读取.wav格式的音频。读取到的rate为音频的采样率,是指录音设备在一秒钟内对声音信号的采样次数,数值越大声音的还原度越高,这里不考虑这个参数。data则是numpy格式的音频数据,并进行归一化处理,归一化处理将不同振幅的波形映射到同一尺度。data包含了这段音频的所有内容,是一个一维的向量,可以用matplotlib将其绘制出来,data其实就是音频的信号特征,可以将其可视化为波形图。
def read_wav_data(filename):
rate, data = wavfile.read(filename)
data = data - np.mean(data) # 消除直流分量
data_out = data / np.max(np.abs(data)) # 幅值归一化
return fs, data_outdef wav_show(data, title='positive'):
plt.plot(data)
plt.title(title)
plt.show()
“Hi,Jarvis!”唤醒词波形图
识别判断
现在系统已经可以完成录音和读取了,接下来就是识别录制的语音是不是唤醒词。开始的思路是使用KNN这样较为简单的思路,来解问题,但考虑到音频特征较为复杂,用KNN难以解决问题,所以还是用到了神经网络。
判断是不是唤醒词,这显然是一个二分类问题,于是我训练了一个简单神经网络,两个隐藏层,神经元个数为2048,输出层为sigmoid。我的想法是直接用神经网络拟合波形图,通过拟合波形图判断用户说了什么。我录制了100个正例和100个负例用于训练。训练过程很快出现了问题。loss正常收敛,在训练集上的accuracy也很高,但是val_loss不断上升,且val_accuracy一直处在0.5左右。这种在训练集上表现很好,但是在验证集上表现很差的现象,我认为可能是出现了过拟合的问题。

语音识别神经网络训练loss与acc变化曲线
于是我在每个隐藏层的后面又加了一个BatchNormalization层,对每批的每个层都做归一化,防止过拟合。一开始效果还是不好,我认为可能是epoch较少的情况下偶然性比较大,于是我又训练了500个epoch,val_loss不稳定,且存在上升趋势,而val_acc还是稳定在0.5左右。结果还是不尽人意。

训练50epoch与500epoch的loss与acc变化曲线
特征和数据决定了机器学习的上限,而模型和算法只是尽可能逼近这个上限。所以我认为,应该是特征工程没有做到位,不能就这么直接拟合波形图。但是一定存在某种方法,可以在音频信号中解析出与说话内容相关的特征。下表中是音频中的常见特征。

常见的音频特征
我认为MFCC特征是对系统有帮助的。根据描述,MFCC是人耳对不同频率的感受程度,人的耳朵在接收信号的时候,不同的频率会引起耳蜗不同部位的震动。耳蜗就像一个频谱仪,自动在做特征提取并进行语音信号的处理。那么我认为这个特征就应该能获取人耳听到的有关于说话内容的一些指标。我尝试把从音频文件图中提取的信号特征转为MFCC,这里用到了librosa库,是一个专门用来处理音频的库。
def mfcc(file_name):
y, sr = librosa.load(file_name, sr=16000)
# 提取 MFCC feature
mfccs = librosa.feature.mfcc(y=y, sr=sr, n_mfcc=40)
# 标准化
mfccs = StandardScaler().fit_transform(mfccs)
return mfccs接下来就是把拿到的mfcc特征拉平为一条向量,输入进开始的神经网络。训练时跑了50个epoch,结果让我大吃一惊。loss与val_loss全部趋近收敛,acc与val_acc也都在接近于1的位置,在验证集上的表现非常好。经过评估,模型在测试集上的准确率可以达到0.9750(可能是因为测试集数据较少,导致准确率过高),而我做的也仅仅是更换了特征。
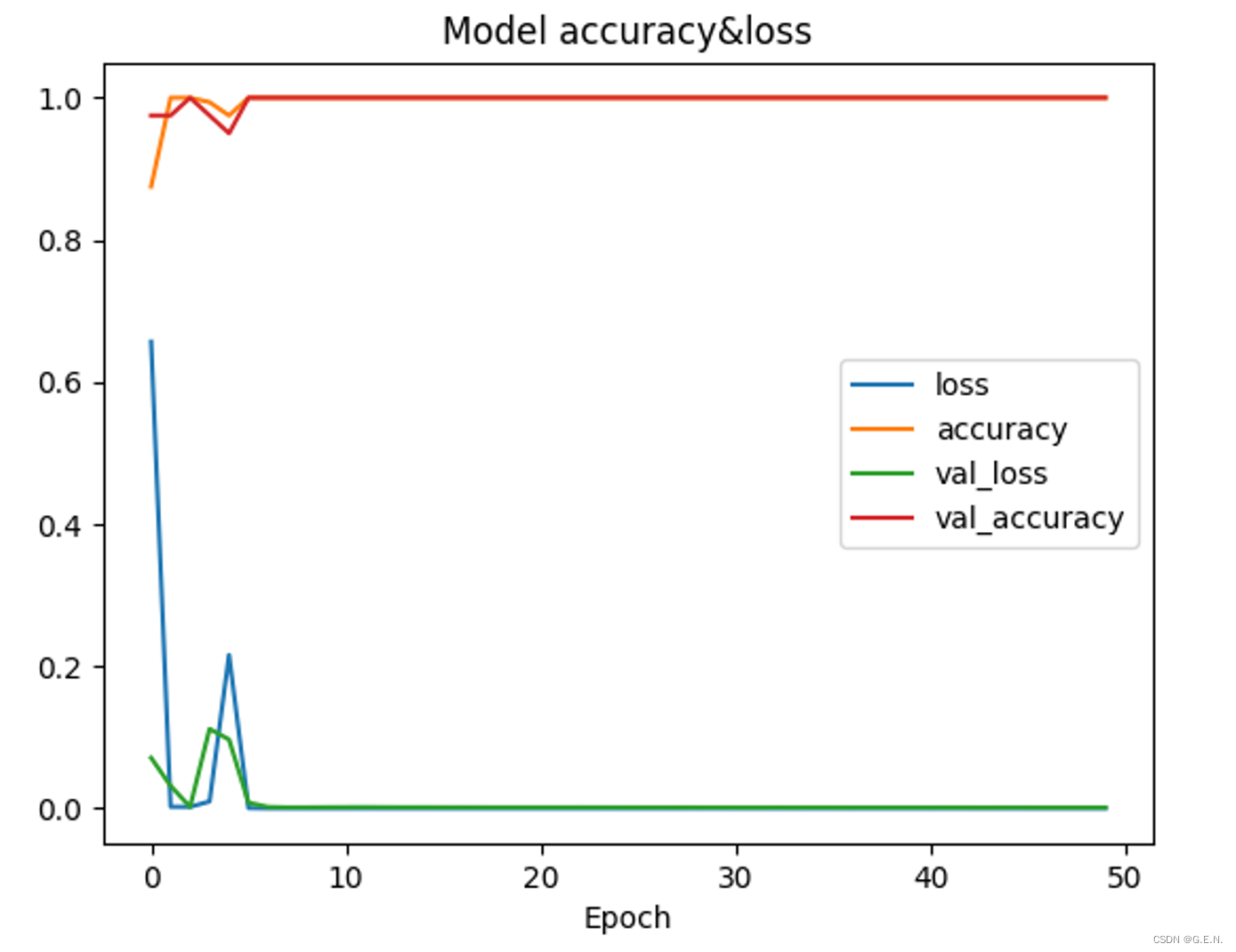
在使用MFCC作为特征后的loss与acc变化曲线
MFCC特征提取的步骤为:1.对语音信号进行分帧处理;2.用周期图(periodogram)法来进行功率谱(power spectrum)估计;3.对功率谱用Mel滤波器组进行滤波,计算每个滤波器里的能量;4.对每个滤波器的能量取log;5.进行离散余弦变换(DCT)变换;6.保留DCT的第2-13个系数,去掉其它。其中,前面两步是短时傅里叶变换,后面几步主要涉及梅尔频谱。
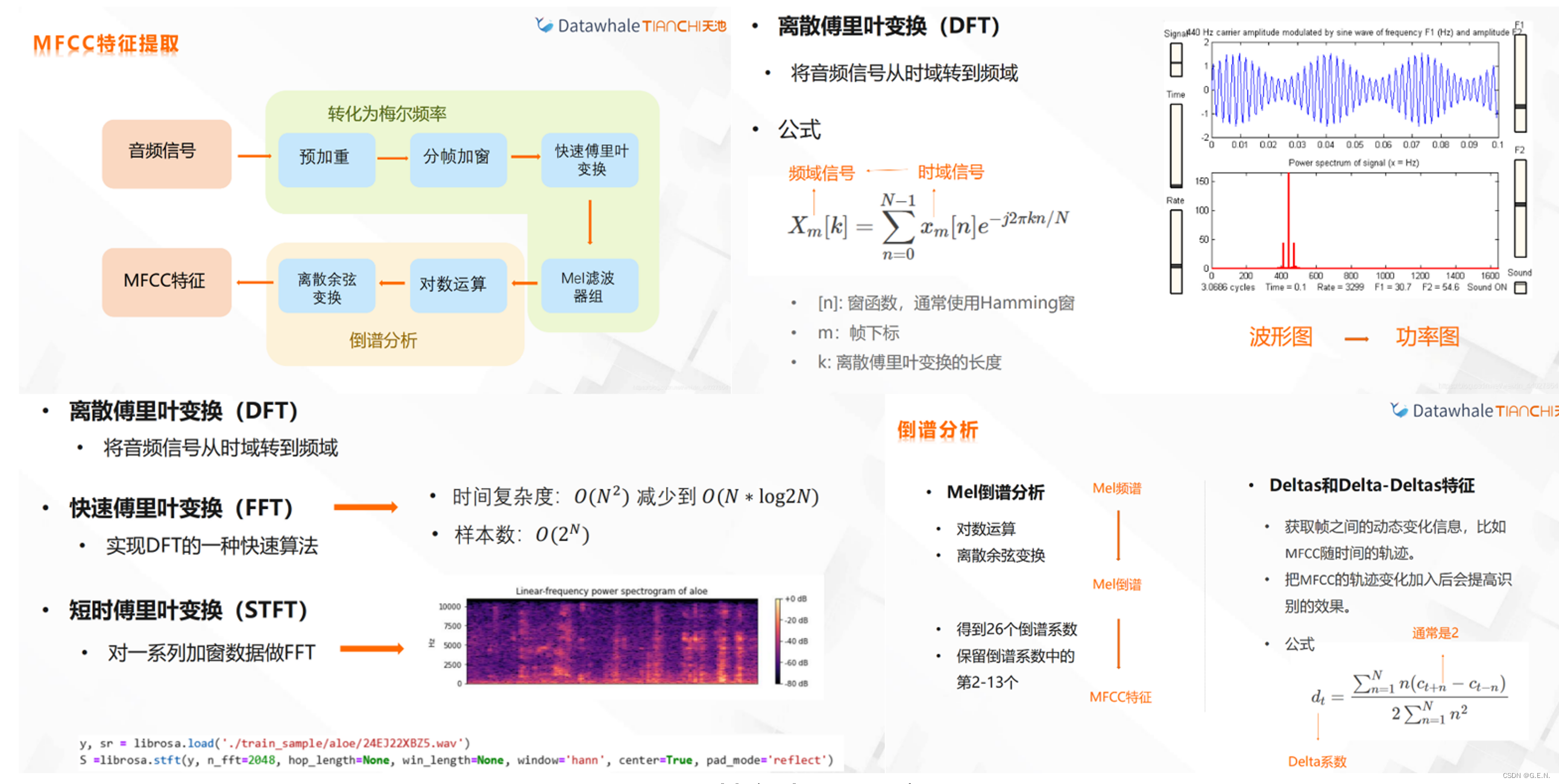
MFCC特征提取过程
从音频信号到MFCC特征的提取,是做了一系列的数学变换。数据和特征决定了机器学习的上限,而音频信号代表了这段音频的全部信息,所以它的上限应该是很高的。
理论上讲,我之前将音频信号直接输入进神经网络,应该是没有问题的。因为够深的神经网络可以拟合任意的数学函数,神经网络会自动在音频信号中提取对结果有影响的特征,给予不同的权重,输出正确的结果。我认为之前用音频信号作为特征失败的原因是,神经网络的宽度不够宽,深度不够深,神经网络的结构设计也没有加入卷积层这样提取特征的层。仅用两层2048个神经元的隐藏层,是很难将如此复杂的特征提取出来的。
因此我认为,只要神经网络够大够深,设计够合理,是完全可以在音频信号中提取出有用的特征的,但是因为硬件限制,我没有实现更大更深的神经网络。况且神经网络不能一味追求大和深,这样反而会带来训练困难、计算量过大等一系列问题。
不可否认的是,选择合适的特征为神经网络减少了大量的工作,即使简单的神经网络也可以预测出好的结果。特征工程做好了,神经网络才能以更简单的形式,实现最有利的价值。
系统设计
识别缓冲区
为了保证手势识别等操作具有一定的容错性,我们设计了一个识别缓冲区,用于缓冲识别的结果。本系统中的缓冲区并不是传统意义上的缓冲区,里面存放的并不是实际的识别结果,而是几个int型的属性和两个函数,但它实现的作用与缓冲区相同,因此我们称之为Buffer。
class Buffer:
def __init__(self, volume=20):
self.__positive = 0
self.state = False
self.__negative = 0
self.__volume = volume
self.__count = 0
def add_positive(self):
self.__count += 1
if self.__positive >= self.__volume:
self.state = True
self.__negative = 0
self.__count = 0
else:
self.__positive += 1
if self.__count > self.__volume:
self.__positive = 0
self.__count = 0
def add_negative(self):
self.__count += 1
if self.__negative >= self.__volume:
self.state = False
self.__positive = 0
else:
self.__negative += 1
if self.__count > self.__volume:
self.__positive = 0
self.__count = 0实例属性有以下几项:__positive、__negative、state、__volume、__count,函数有add_positive()与add_negative()。__positive是正例的个数(int),__negative是负例的个数(int),state是状态表示是否进入识别正常的状态(bool),__volume表示缓冲区的容量,若正例数或负例数大于容量,则确定状态为True或Flase,__count代表识别计数,是实现容错的重要属性。
模型每识别出一个正例或负例,就调用一次add_positive()或add_negative()函数,向缓冲区内添加一个正例或负例,并记一次数。若正例或负例的个数大于缓冲区容量的个数,那么就可以确定,目前是识别状态或未识别状态。缓冲区通过__count属性来实现容错,每添加一个正例或一个负例,__count就会+1,如果__count大于了容量,也就是在规定的次数中模型识别的不全为正例或负例,那么这时就会将__positive或__negative清零。举个例子,若当前的state为True,也就是说现在是识别状态,即使在识别状态中出现了几个负例,负例的个数也会在容量次数的识别后清零,并不会退出当前的识别状态。
总结来说,缓冲区的设计保证了识别状态的稳定性,使系统有一定的容错性。但是这样也造成识别状态进入的不及时,要等待缓冲区满才能进入识别状态,可以缩小缓冲区的容量来减少进入时间,但容错也会相应减少。
键鼠控制
PyWin32
系统通过pywin32库对windows进行操作。pywin32 是一个第三方模块库,主要的作用是方便 python 开发者快速调用 windows API 的一个模块库。它直接包装了几乎所有的 Windows API,可以方便地从 Python 直接调用。在安装了pwin32库之后,就可以导入需要的模块。用到的模块有win32api,win32gui,win32con等。
win32api中提供了常用的用户API,如创建虚拟设备信号(移动鼠标、点击鼠标、敲击键盘……)、向I/O设备发送消息等;
win32gui中是图形设备接口,提供了有关 windows 用户界面图形操作的API,可以对Windows的窗口进行操作。如标题获取句柄、根据句柄获取窗口位置、根据句柄置顶窗口等。
win32con模块内定义了 windows API 内的宏,即 宏常量。
识别区域的映射
鼠标的落点是由mediapipe识别出的关键点决定的,但是当手部在画面的边角时,这时手部的图像不完整,造成边角处无法识别出手部关键点。这时就需要对识别区域进行映射。原本是橙色点移动到画面的右上角,鼠标就移动到屏幕的右上角。在映射之后,橙色点移动到画面中蓝框的右上角,鼠标就可以整个屏幕的右上角。这样就有效避免了画面边缘区域识别不出关键点的情况。

识别区域的映射
在横坐标上,设坐标点在原画面上的坐标为x,这时的x是归一化后的坐标,在画面的最左侧为0,在画面的最右侧为1。蓝框左与距画面左侧的距离占画面宽度的占比为scalex,那么就可以计算出映射后点的横坐标为
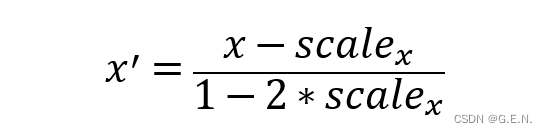
纵坐标上同理。此时坐标点在蓝框左侧的横坐标为0,在蓝框右侧的横坐标为1,再用这个坐标乘以屏幕的宽高,就可以计算出鼠标在屏幕的实际落点。
鼠标操作
鼠标的落点是通过食指指尖、中指指尖、无名指尖关键点围成三角形的中心决定的,这样做是为了使数据相对稳定。因为mdeiapipe不同帧之间识别出的关键点,位置会有少量的差异,产生一定程度的摆动,造成鼠标指针的不稳定。
开始只用食指指尖控制鼠标落点,小幅度的摆动通过鼠标映射至整个屏幕,就会使摆动幅度加大,难以控制鼠标落点。后来改为由两个关键点决定鼠标的位置,在一定程度上减轻关键点摆动造成的影响,但鼠标精度还是较差,无法稳定在小按钮处。因此改为由三个关键点决定鼠标的落点位置,三个摆动的关键点围成三角形的中心摆动幅度,,是小于等于任意一个摆动点的摆动幅度的,只会比任意一个关键点的摆动幅度小,而不会增大。三个摆动点形成互相牵制。
# 用三个坐标点决定鼠标落点
mid_point_x, mid_point_y = (hands_x[0, 8, 0] + hands_x[0, 12, 0] + hands_x[0, 16, 0]) / 3, (hands_y[0, 8, 0] + hands_y[0, 12, 0] + hands_y[0, 16, 0]) / 3为了进一步减轻摆动,还做了缓冲的设计。在三个关键点中心的基础上,再由两帧坐标的平均值决定鼠标的落点。这样做虽然减轻了鼠标的摆动,但是造成了卡顿、不跟手的现象,最后还是做了权衡,把缓冲的设计去掉。
鼠标移动问题实现之后,接下来就是鼠标的点击问题。由于时间问题,这里只实现了鼠标点击左键,系统通过右手大拇指敲击食指左侧来实现鼠标点击。由于问题比较简单,这里直接计算的手部关键点的距离,若距离小于一个阈值,则为点击。因为要考虑到手掌的大小和距摄像头的距离,这里的阈值不能是固定的值。我这里选取的阈值为食指根部点(5.INDEX_FINGER_MCP)和中指根部点(9.MIDDLE_FINGER_MCP)的1.5倍距离。
# 用于衡量手部与摄影头的距离
scale = int(math.hypot(CAM_W * (arr[1, 5, 0] - arr[1, 9, 0]),
CAM_H * (arr[1, 5, 1] - arr[1, 9, 1]),
CAM_W * (arr[1, 5, 2] - arr[1, 9, 2])))
# 用于衡量手部的旋转
dis = int(math.hypot(CAM_W * (arr[1, 4, 0] - arr[1, 5, 0]),
CAM_H * (arr[1, 4, 1] - arr[1, 5, 1]),
CAM_W * (arr[1, 4, 2] - arr[1, 5, 2])))
if dis < 1.5 * scale:
# 点击鼠标
mouse_click()但是鼠标点击又出现了一个新的问题。因为每帧的速度非常快,有时拇指敲击一下会判断成多次点击。为了解决这个问题,这里通过时间间隔来判断。如果调用mouse_click函数的时间间隔大于t,这时才执行一次点击操作。
last_time = 0
def mouse_click(t=0.15):
"""
点击鼠标
:return:
"""
global last_time
current_time = time.time()
if current_time - last_time > t:
win32api.mouse_event(MOUSEEVENTF_LEFTDOWN, 0, 0, 0, 0)
win32api.mouse_event(MOUSEEVENTF_LEFTUP, 0, 0, 0, 0)
last_time = current_time接下来就是滚轮操作。按照设想,滚轮操作是通过捏合手指上下移动来实现滚动。首先训练一个手指捏合的手势,当模型判断出当前手势是捏合状态,就判断滚轮的滚动方向。滚轮滚动是一个多帧的操作,要根据上一帧的图像判断手是上移还是下拉。这里在主循外定义了一个last_y用于保存上一帧的坐标,然后根据两帧之间坐标y的差异判断是上移还是下拉。
def mouse_wheel(up=True, speed=100):
"""
移动鼠标滚轮
:param up:
:param speed:表示每次滚动几格
:return:
"""
if up:
# -1代表页面向下,1代表页面向上
win32api.mouse_event(MOUSEEVENTF_WHEEL, 0, 0, speed)
else:
win32api.mouse_event(MOUSEEVENTF_WHEEL, 0, 0, -speed) # 右手手势2操作鼠标滚轮
elif rh_index == 2:
# 通过食指指尖的移动来判断是上移还是下拉
current_y = int(arr[1, 8, 1] * CAM_H)
# 以食指指尖和食指第三个关节的距离为缩放尺度
scale = int(math.hypot(CAM_W * (arr[1, 7, 0] - arr[1, 8, 0]),
CAM_H * (arr[1, 7, 1] - arr[1, 8, 1]),
CAM_W * (arr[1, 7, 2] - arr[1, 8, 2])))
# 计算食指指尖与大拇指指尖的距离
dis = int(math.hypot(CAM_W * (arr[1, 4, 0] - arr[1, 8, 0]),
CAM_H * (arr[1, 4, 1] - arr[1, 8, 1]),
CAM_W * (arr[1, 4, 2] - arr[1, 8, 2])))
# 手指发生了下拉
if current_y > last_y and dis < scale:
# 鼠标滚轮向上滚
mouse_wheel()
# 手指发生了上移
elif current_y < last_y and dis < scale:
# 鼠标滚轮向下滚
mouse_wheel(up=False)
# 让当前位置等于上一次的位置
last_y = current_y键盘操作
键盘的操作设想是想调用中文语音识别的接口,用语音识别取代键盘输入,但是了解到目前的实时语音识别是需要花钱的,所以就暂时不做这个。键盘的一些快捷键则由识别手势组合代替。
手势控制
手势控制主要包括控制电脑扬声器的音量,和电脑屏幕的亮度。是左手与右手手势的组合实现的。当左手识别为手掌手势时,就会调出选择菜单。并根据手掌的旋转角度来判断选择了哪个菜单。

菜单的选择
计算旋转角度
系统要通过计算手掌的旋转角度来判断选择了哪个菜单。我选择了左手中指指尖与手掌根部点之间的连线作为参考线,计算出这条线的旋转角度,就代表了手掌的旋转角度。要注意的是,OpenCV中的坐标系与平时常用的坐标系并不相同。在数学中常用的坐标系为笛卡尔坐标系,也就是常说的直角坐标系。OpenCV中的坐标系原点位于图片左上角,原点向右为x轴正方向,原点向下为y轴正方向。
在坐标系中计算最方便的是正切函数(tan)。因为有了一个点的坐标(x,y),可以很容易的计算出tanθ = y/x,然后使用反正切函数(arctan),就可以计算出角度。
# 计算tan值
tan = np.abs((arr[0, 0, 1] - arr[0, 12, 1]) / (arr[0, 0, 0] - arr[0, 12, 0]))
# 计算角度
angle = np.arctan(tan) * 180 / np.pi为了简化问题,将算出来的tan取了绝对值,这样计算出的角度是恒正的。arctan函数计算出的角度为弧度制,所以要乘180/π,将弧度制转换为角度制。
计算出角度之后,根据角度划分不同的区间,不同的区间加载不同的图片,并向不同的缓冲区内添加正例或负例,这样就实现了菜单的切换。
调节亮度和音量
调节亮度和音量的难点主要在于将一个区间内的值映射至另一区间。
这里靠调用np.interp()函数实现映射关系。interp(x, xp, fp)函数称为线性插值,x: 数组 待插入数据的横坐标,xp: 一维浮点数序列(原始数据点的横坐标),fp: 一维浮点数或复数序列(原始数据点的纵坐标)。可以理解为,x是xp区间范围内的一个点,将其映射至fp区间范围内。假设我有一个在x0~x1范围内的点x,要求出其在y0~y1范围内的映射点y。
可得

# 调节亮度
if buffer_light.state:
frame = cv2.putText(frame, 'light ready', (10, 35), cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 127, 0))
frame = draw_line(frame, arr[1, 4], arr[1, 8], thickness=5, color=(255,188,66))
if dis != 0:
# 线性插值,可以理解为将一个区间中的一个值映射到另一区间内
light = np.interp(dis, [int(500 * s), int(3000 * s)], (0, 100))
# 调节亮度
screen_change(light)
# 调节声音
elif buffer_voice.state:
frame = cv2.putText(frame, 'voice ready', (10, 35), cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 127, 0))
frame = draw_line(frame, arr[1, 4], arr[1, 8], thickness=5, color=(132,134,248))
if dis != 0:
vol = np.interp(dis, [int(500 * s), int(3000 * s)], voice_range)
# 调节音量
volume.SetMasterVolumeLevel(vol, None)