1. 公式
L o s s = y _ t r u e × − l o g ( s i g m o i d ( y _ p r e d ) ) + ( 1 − y _ t r u e ) × − l o g ( 1 − s i g m o i d ( y _ p r e d ) ) Loss\ =\ y\_true\times-log(sigmoid(y\_pred))+(1-y\_true)\times-log(1-sigmoid(y\_pred)) Loss = y_true×−log(sigmoid(y_pred))+(1−y_true)×−log(1−sigmoid(y_pred)) (这是基于y_pred是logits的情况,如果已经经过了sigmoid就不需要再用sigmoid处理了)
如果有多个batch_size,取平均值
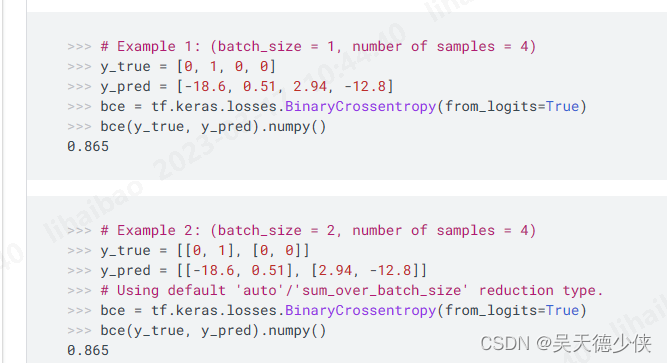
2.1 tensorflow里面的例子
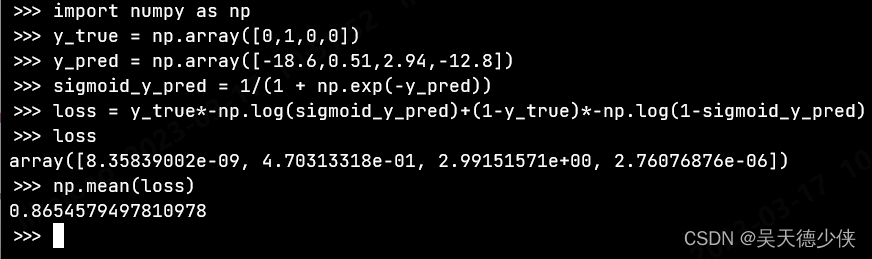
2.2 numpy实现
Example 1: (batch_size = 1 , number of samples = 4)
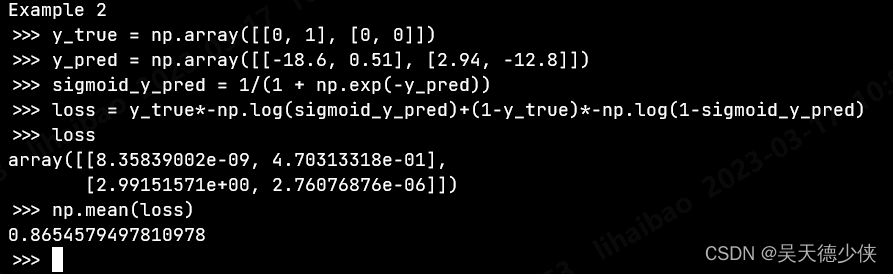
Example 2: (batch_size = 2, number of samples = 4)
3. 结论
所以在用这个损失函数用于二分类(分类、语义分割)问题的时候,标签不用进行onehot,可以直接用