目录
1 程序重定位问题
1.1 问题引入
1. 计算机的基本工作过程就是CPU在内存中不断地取出并执行指令,因此计算机对内存的使用也是由CPU带动的。假设编译和运行如下程序,

需要注意的是,这里假设call 40指令使用的是绝对寻址方式,也就是会将地址值40直接加载到EIP寄存器中,从而实现执行流的跳转。那么这段程序能够正确执行的条件,就是程序被加载到内存0地址处
但是这种要求在现实中会遇到2个困难,
① 内存0地址处一般被操作系统占用,无法被应用程序使用
② 即使内0地址处可以被应用程序使用,但是如果有多个应用程序均需要加载到该地址执行,则会产生冲突
因此合理的方式,是操作系统先在内存中找出一段空闲区域,之后将程序加载在这段内存
2. 由于程序被加载的内存地址不是由程序自己决定的,因此就需要进行程序重定位(program relocation),也就是将程序中的逻辑地址映射到实际使用的物理内存地址
对于示例程序,如果被加载到内存1000地址处,那么在跳转到main函数执行时,就需要执行call 1040指令,才能寻址到正确的内存

说明:程序中使用的是什么地址?
① 首先需要明确的是,程序中使用的地址是在编译链接阶段确定的,与程序的运行无关。程序中使用的各种标号(e.g. 函数名、变量名)在编译链接后都会被处理为地址,因此程序中的标号也被称作符号地址
② 程序中使用的地址被称作逻辑地址或链接地址,他们是同一个事物的不同侧面,是从不同的角度去理解程序中使用的地址,
逻辑地址:体现程序中使用地址的性质,该地址没有和实际的内存管理机制结合,只是在程序中使用
链接地址:体现程序中使用地址的由来,该地址在程序的链接过程中确定
③ 程序的逻辑地址或链接地址并不一定从0开始,而是可以通过链接器脚本或链接器伪指令指定
1.2 重定位方案
根据进行程序重定位时机的不同,共用如下3种方案,
1.2.1 编译时重定位
1. 编译时重定位,就是在编译程序时在逻辑地址基础上增加加载地址。对于上文的示例程序,因为是将程序加载到内存1000地址处运行,所以在编译时将所有逻辑地址加1000
2. 编译时重定位本质上只是修改了链接地址,因此还是只能加载到链接地址处才能正确运行,因此只适用于在固定位置执行固定任务的计算机系统
1.2.2 加载时重定位
1. 加载时重定位,就是操作系统在加载程序时,根据实际载入的物理地址来修改程序中的逻辑地址,因此比编译时重定位灵活
2. 但是加载时重定位有如下2个缺点,
① 修改程序中的逻辑地址是一个难点
由于程序中的数据和指令都是以二进制形式存在,如果要进行加载时重定位,则需要在加载程序的过程中分析程序,识别出其中表示逻辑地址的部分并进行修改。这项工作的难度和工作量都很大
② 不能满足进程加载后再移动的要求
如果进程被换出再换入时加载地址发生变化,则之前进行的加载时重定位将失效,需要再次重定位

1.2.3 运行时重定位
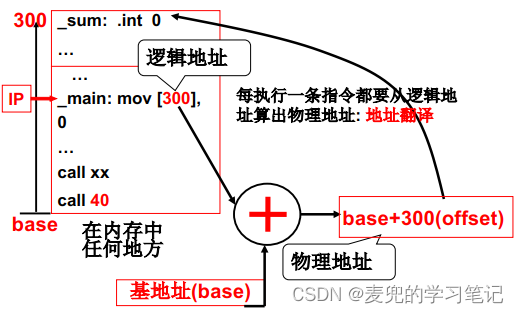
1. 运行时重定位,就是在指令执行时才将逻辑地址转换为物理地址
2. 在实现层面,操作系统在加载程序时,寻找一段空闲的内存区域将程序载入,并记录下这段区域的基地址。在程序执行过程中每次寻址时,都将逻辑地址加上基地址之后再发送到地址总线上
由于每次寻址都要进行这样的地址运算,为了提高执行效率,可以设计硬件来快速完成这个地址计算过程。而这个硬件,在X86体系结构中就是分段部件
3. 由于多进程视图的核心就是切换,因此每个进程的重定位基地址都要保存在对应的PCB中。进程切换时,从对应的PCB中取出存放的基地址并赋值给CPU基地址寄存器
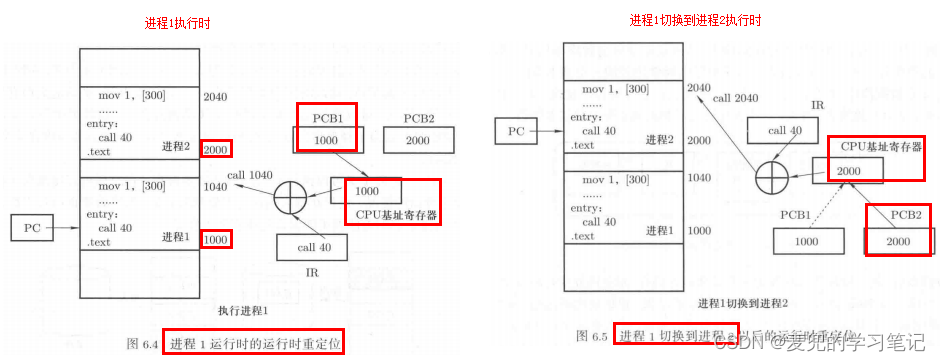
4. 因为基地址对应了一段以该基地址为起始地址的内存空间,所以基地址寄存器的切换就代表了一段地址空间的切换。至此就可以完整体现多进程视图,
① 通过切换PC指针实现执行流切换
② 通过切换基址寄存器实现进程工作内存空间的切换
5. 运行时重定位也可以满足进程加载后再移动的需求,只要在进程移动后将新分配给该进程的内存区域基地址记录在该进程的PCB中即可
说明1:在上述示例中,程序的链接地址都是从0开始,程序中使用的链接地址相当于相对于程序起始处的偏移地址。最后在运行时,通过段基址寄存器重定位到物理地址
说明2:使用加载时重定位和运行时重定位,使得程序在编译链接时可以使用统一的内存布局描述逻辑地址空间,简化了编译器与链接器的实现
这里"统一的内存布局"在上述示例中,就是程序的链接地址可以都从0地址开始
2 分段机制
2.1 为什么要分段?
在上述运行时重定位的描述中,是将整个程序作为一个整体加载到内存中。但是在实际使用中我们是将程序划分为不同的段,每个段都是从0地址开始单独编址,并且以段为单位加载到内存中,如下图所示
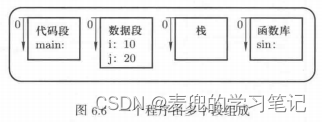
之所以将程序分段,是出于如下原因,
2.1.1 不同的段有不同的属性
1. 例如代码段是只读的,而数据段是可读写的,如果将他们混合在一起,在操作数据段时就有可能破坏代码段
2. 操作系统可以基于分段实现访问权限的控制
2.1.2 分段加载内存使用率更高
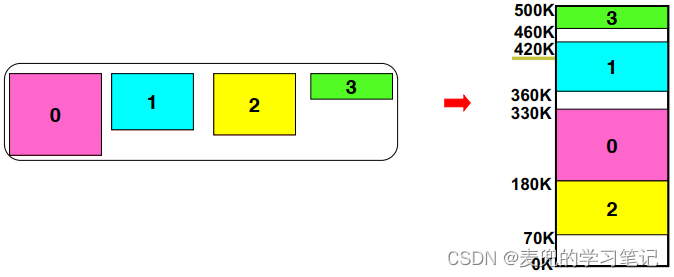
我们以上图为例说明分段加载如何提高内存使用率,
1. 由于分成多个段加载,相较于整体加载,每个段对连续内存的需求降低了,更容易找到空闲内存区域
2. 如果程序中的某个段在加载之后想要扩展(最典型的就是栈段的扩展),则只需要移动栈段,而不用移动整个程序
2.1.3 分段符合程序员视角
程序员通常将程序中用到的数据以及在这些数据上执行的操作分开考虑,这符合分治法的原则。而将程序分段,使得程序员可以独立思考每个段的构成
2.2 段表
1. 如果将程序整体加载到内存,则只需要记录一个基地址;如果将程序分段加载到内存,则需要记录每个段的基地址,而记录每个段基地址的数据结构就是段表
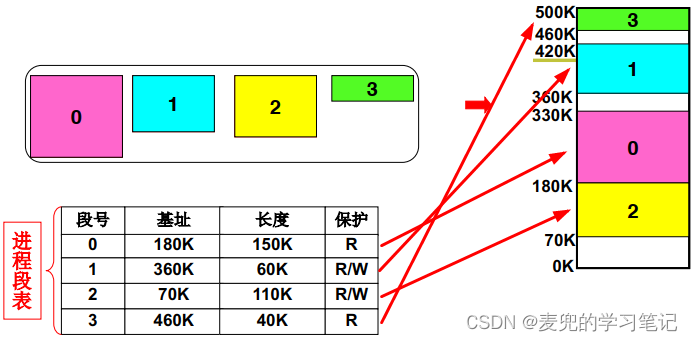
2. 段表需要记录在每个进程的PCB中,并且在进程切换时也切换段表,从而实现进程地址空间的切换
2.3 分段机制下的地址转换
2.3.1 分段机制下的寻址方式
1. 因为每个段的逻辑地址都是从0开始编址,对于分段来说,逻辑地址实际上是段内偏移
2. 由于每个段单独加载,因此在寻址时需要指定段号,构成的地址形式如下。这种形式的地址也被称作逻辑地址,这是一个二维地址
| 段号 : 段内偏移 |
说明:每个段的逻辑地址不从0开始是否可以?
如果段的逻辑地址不从0开始,那么在将其加载到内存时,也需要在分配的内存起始地址上增加相应的偏移量,否则寻址时会发生错误
假设一个段的逻辑地址从0x100开始,分配的用于加载该段的内存起始地址为0x1000,那么就需要将该段加载到内存0x1100处,否则寻址时会发生错误
2.3.2 地址转换过程
分段机制下地址转换的核心就是查找段表
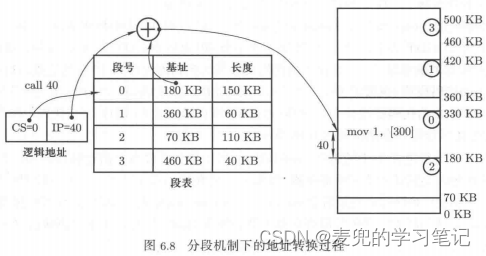
1. 根据逻辑地址中的<段号>部分查找段表,从而获取该段的基地址
2. 将查表所得的段基地址与逻辑地址中的<段内偏移>部分相加,即可寻址到相应内存
说明1:需要特别说明的是,在分段机制下,使用的仍然是运行时重定位
说明2:在分段机制下,仍然可以在程序编译链接时使用统一的内存布局描述逻辑地址空间。这里"统一的内存布局",就是程序中每个段的链接地址可以都从0地址开始
2.4 IA-32体系结构对分段机制的支持
2.4.1 相关基础设施
IA-32体系结构在硬件层面提供了GDT和LDT等机制用于支持操作系统的分段机制,相关内容在Linux 0.11内核分析05:线程切换与调度 chapter 5.1已有详细说明,本文不再赘述
2.4.2 预期使用方式
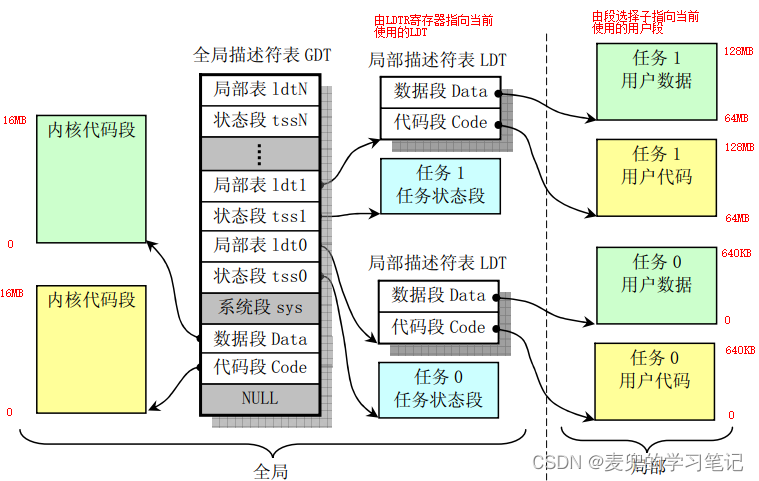
IA-32体系结构对GDT和LDT的预期使用方式如下图所示,
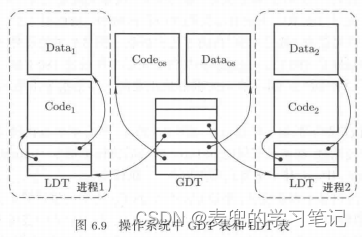
1. GDT用于描述操作系统的代码段和数据段;LDT用于描述每个进程的代码段和数据段,其中每个进程的LDT段登记在GDT中
2. 每个进程有自己的LDT表,且记录在进程的PCB中
① 当一个进程在运行时,LDTR指向当前进程的LDT,从而实现运行时重定位
② 当进程切换时,LDT表也要随之切换,将LDTR指向目标进程的LDT,从而实现进程地址空间的切换。相关内容可参考Linux 0.11内核分析05:线程切换与调度 chapter 8.4
2.5 Linux 0.11分段机制实例
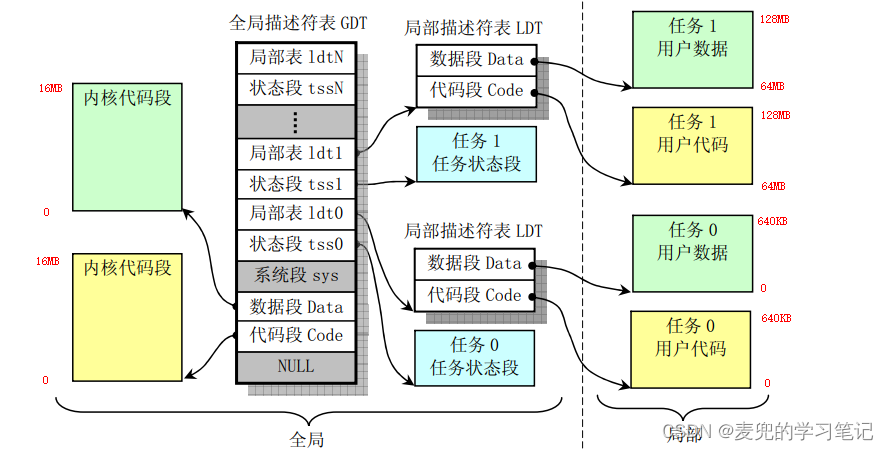
Linux 0.11对IA-32体系结构分段机制的使用基本符合预期方式,但是需要注意如下3点,
1. 内核数据段 / 代码段和进程的数据段 / 代码段均使用平坦模型
2. 共设置64个进程平分4GB线性地址空间
3. 由于64个进程使用的总的线性地址空间超过了Linux 0.11时代一般PC配置的物理内存容量(e.g. 我们的实验环境中只配置了16MB物理内存),因此需要依靠下一级的分页机制工作。如果不使能分页机制,从任务1开始的线性地址就超过了可用物理地址的范围
说明1:Linux 0.11对IA-32体系结构分段机制的使用方式有如下特点
① 通过LDT表实现进程地址空间的隔离
② 由于64个进程共使用了4GB线性地址空间,因此64个进程可以共享一个页表。当进程切换时,只需要切换LDT表,而无需切换页表
说明2:后续的Linux内核版本则进一步"绕过"了IA-32体系结构提供的分段机制,不再使用LDT表实现进程地址空间的隔离,而是每个进程都拥有4GB线性地址空间
由于每个进程的线性地址空间重叠,所以依靠页表实现进程地址空间的隔离
说明3:"绕过"分段机制其实也削弱了分段机制提供的保护功能(e.g. 分段的操作权限检查),这就需要依靠下一级分页机制提供的保护机制
个人认为平坦模型本身也是一种"绕过"分段机制的方法,只是绕得不彻底而已。更进一步的讨论,可参考后文的相关实验
3 分页机制
3.1 内存分区与内存碎片
3.1.1 固定分区与可变分区
1. 内存分区的核心是要在内存中找到一段合适的空闲区域分配给段
2. 根据对内存的管理方式不同,内存分区方式分为固定分区和可变分区
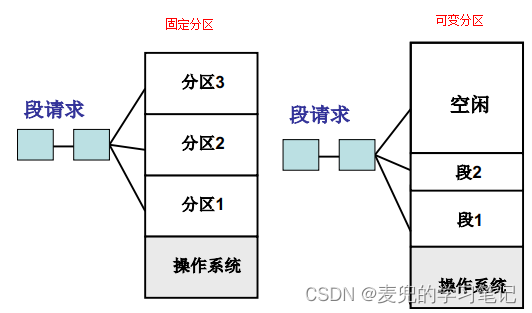
① 固定分区是在操作系统初始化阶段将内存等分为若干分区,当有段请求到来时,选择一个分区分配给段。但是由于操作系统中不同段请求的长度是大小不一的,所以固定分区方式显然难以满足需求
② 可变分区则是在系统中维护一个空闲分区表,针对一个段请求,从当前空闲内存区域中找到一个能满足请求的区域,即大于请求尺寸的内存区域,然后从该区域中分割出一段和请求尺寸大小相等的内存区域分配给段
3. 以下图为例,当进程3需要分配一个长度为100KB的段时,由于空闲内存足够,从中分割100KB内存区域分配给段

从上述示例可以看出,
① 记录着内存空闲区域信息的空闲分区表是可变分区方案中的核心数据结构
② 随着空闲分区的变化(申请或释放),空闲分区表也需要及时更新
3.1.2 可变分区的适配算法
随着系统中空闲分区的申请和释放,假设系统中空闲内存情况如下,此时有一个40KB的段内存分配请求,根据不同的适配算法会有不同的分配方案

3.1.2.1 最佳适配
1. 算法
① 选择能够满足要求且最不"浪费"(尺寸最小)的内存空闲区域
② 在示例中就是选择50KB的内存空闲区域进行分配,此时会剩余一个10KB的内存空闲区域
2. 特点
① 最佳适配会导致系统中剩余的内存空闲区域越来越小,将来分配给其他请求的可能性也就越来越小
② 分割后剩余的内存空闲区域本身不是浪费,还可以分配给其他内存请求;不能分配给任何进程的内存空闲区域才是真正的浪费
3.1.2.2 最差适配
1. 算法
① 选择能够满足要求且尺寸最大的内存空闲区域
② 在示例中就是选择150KB的内存空闲区域进行分配,此时会剩余一个110KB的内存空闲区域
2. 特点
最差适配会导致系统中剩余的内存空闲区域大小比较中等
3.1.2.3 首先适配
1. 算法
① 在空闲分区表中选择第一个满足要求的内存空闲区域
② 在实例中就是选择150KB的内存空闲区域进行分配,此时会剩余一个110KB的内存空闲区域
2. 特点
① 首先适配算法最简单,运算速度最快
② 首先适配会导致系统中剩余的内存空闲区域大小均匀随机
说明:分区适配算法没有对错之分,只有不同的特点
3.1.3 内存碎片
3.1.3.1 什么是内存碎片
1. 首先需要明确的是,所谓内存碎片是指空闲但是无法分配的内存
2. 假设有如下场景,系统中共有2块内存空闲内存区域,分别为150KB和50KB。此时有一个160KB的分段内存请求,虽然总的内存空闲区域足够,但是分散在多个位置无法分配,这就构成了内存碎片

3.1.3.2 内存碎片的解决方案
3.1.3.2.1 内存紧缩
1. 内存紧缩是处理内存碎片的直观方法,也就是将内存空闲区域合并,通过移动整理将多个零散的内存空闲区域合并为一整块内存空闲区域
在示例场景中,可以将进程3:段2的内存移动到起始地址200KB处。从而使得系统中可以有一块从300KB开始,长度为200KB的完整内存空闲区域
2. 内存紧缩的缺点非常明显,就是移动内存需要消耗大量时间,由于内存正在变动,在此期间进程不能执行任何动作
需要注意的是,此处是以段为单位进行内存移动
3.1.3.2.2 内存离散化
1. 上述问题的核心是系统难以满足对一段较长连续内存的需求,那么自然的想法就是将这种需求打散,降低对连续内存的需求
2. 内存离散化的基本思想就是将内存分割成固定大小的分片,当内存请求到达时,根据请求尺寸计算出需要的分片个数,然后在内存中的任意位置找出同样数量的内存分片分配给内存请求。这就是分页机制的基本思想,而此处的内存分片就是内存页
内存离散化在本质上是降低了对连续内存的要求,从程序段降低到固定大小的分片
3. 使用内存离散化的解决方案后,内存中就没有无法分配的内存分片,也就解决了内存碎片问题
当然,如果内存请求超过系统剩余内存分片的数量,内存分配还是会失败,但是依然没有内存碎片问题
3.2 分页机制与页表
3.2.1 分页机制原理
分页机制将内存供需双方都打散,都分割成固定大小的页,
1. 作为内存的供应方,分页机制将物理内存分割成大小相等的页框(page frame)
2. 作为内存的需求方,分页机制将请求放入物理内存的数据(e.g. 代码段)也分割成同样大小的页(page)
3. 最后将所有页都映射到页框上,实现对物理内存页框的使用

说明:分页机制下的内存浪费
① 分段机制按段所需大小分配内存,因此没有内部碎片(段内无碎片),但是有外部碎片(段外可能有无法使用的内存)
② 分页机制按固定的页大小分配内存,因此没有外部碎片(所有内存都按页组织),但是有内部碎片(页内可能有不使用的内存)
③ 一页之内最多浪费(页大小 - 1B)内存
3.2.2 页表
在将页映射到物理页框的过程中,需要记录页与页框的对应关系,这就是页表
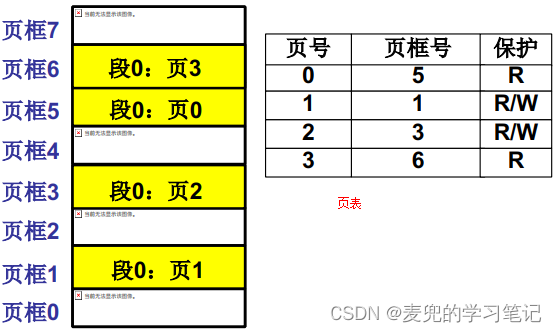
3.2.3 分页机制地址转换过程
1. 根据系统中页的大小,可以将虚拟地址划分为(页号 + 页内偏移)。如果页的大小为4KB,则页内偏移占12位,其余高位为页号

2. 根据页号查询页表,找到对应的页框号,将其与虚拟地址中的页内偏移部分组合,即可得到最终的物理地址
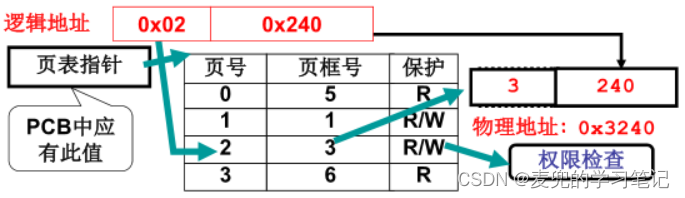
说明1:关于图示中的逻辑地址
① 由于这部分是内存管理的理论介绍,图示中更多体现的还是直接从程序的逻辑地址到物理地址
② 但是在实际的IA-32体系结构中,分页部件在分段部件之后工作,因此传递到分页部件的是经过分段部件生成的线性地址
说明2:页表物理基地址
① 在通过页表进行地址转换时,页表物理基地址需要记录在相应的系统寄存器中(e.g. X86中的CR3寄存器)
② 如果不同进程使用各自的页表,则还需要将页表物理基地址记录在进程的PCB中。在进程切换时,页表也需要随之切换
3.3 多级页表
3.3.1 分页大小与页表大小的关系
1. 如上文所述,在分页机制中是会存在页内内存碎片的。为了避免内存空间的浪费,分页尺寸应设置得较小,通常的操作系统都将分页尺寸设置为4KB
2. 如果分页尺寸设置的较小,那么页表就会较大
① 以32位体系结构为例,线性地址空间为4GB,如果分页大小为4KB,那么就有(4GB / 4KB = 2^20)个虚拟页,也就需要2^20个页表项来记录虚拟页到物理页的映射关系
② 在32位体系结构中,页表项大小一般为4B,因此每张页表需要占用(4 * 2^20 = 4MB)内存。而页表是每个进程一张,因此为存储页表需要消耗大量内存
说明:分页尺寸的大小设置还和CPU体系结构相关,操作系统所选择的分页尺寸需要体系结构支持
3.3.2 减小页表大小的方法
3.3.2.1 核心思路
1. 在80386 + Linux 0.11的时代,大多数程序所需的线性地址空间远小于4GB(所需的物理内存也远小于4GB),因此不会将2^20个虚拟页全部用到,自然也就无需为这些未使用的虚拟页存储页表项
2. 因此减小页表大小的核心思路,就是不存储使用不到的页表项
3.3.2.2 直观方法
1. 减小页表大小的直观方法,就是对于没有被存放到物理页中的逻辑页,将其对应的页表项从页表中删除。如下图所示,2号虚拟页没有被使用,因此将其对应的页表项从页表中删除,这种方法确实可以减少页表大小
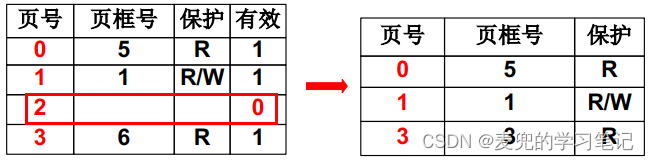
2. 但是如果采用直观方法,会导致虚拟页号不连续,那么在通过页表将虚拟地址转换为物理地址时,就不能通过虚拟页号直接索引到页表项,而是需要在页表中进行查找
① 如果页表中的虚拟页号连续,那么通过虚拟页号索引页表项的操作与通过下标索引数组元素类似,时间复杂度为O(1)
② 如果页表中的虚拟页号不连续,则需要通过线性查找或二分查找(前提是页表中虚拟页号有序),时间复杂度分别为O(n)和O(log(n)),从而增加额外的内存访问
3.3.2.3 多级页表方法
1. 根据上文分析,我们需要的方法要同时满足如下2个条件,
① 不存储使用不到的页表项,从而可以减少页表的内存占用
② 页表必须是按虚拟页号连续的,从而可以以O(1)时间复杂度索引到页表项
因此,参考书籍目录中章目录和节目录的结构,提出了多级页表方法
2. 以下图所示的两级页表结构为例,
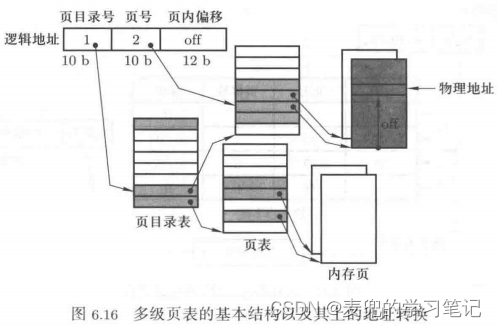
① 两级页表的基本结构是设置页目录表和页表,其中页目录表中的每个页目录项指向一张页表,而页表中的每个页表项指向一个物理页
相应地,线性地址也被划分为页目录号、页号和页内偏移共三个部分
② 在查找一个虚拟页号对应的物理页号时, 两级查找的流程如下,
- 先使用页目录号查找页目录表,找到对应的页目录项,并从中获取页表地址
- 再使用页号查找页表,找到对应的页表项,并从中获取物理页地址
③ 页目录表和页表都是连续的,因此两级查找的时间复杂度均为O(1)
3. 多级页表如何减少内存使用?
① 以上图所示的结构为例,程序需要使用0 ~ 4MB / 4MB ~ 8MB / (4GB - 4MB) ~ 4GB共3段12MB的线性地址空间。这是程序中比较典型的线性地址空间布局,其中,
- 0 ~ 4MB是代码段
- 4MB ~ 8MB是数据段
- (4GB - 4MB) ~ 4GB是栈段
② 如果使用单级页表,由于最低和最高的线性地址空间均被使用,所以中间的线性地址空间即使没有使用,为了保持页表的连续也需要保留对应的页表项空间(虽然这些页表项都是无效的),因此页表大小为4MB
③ 如果使用两级页表,只需要1张页目录表和3张页表,共计(4 * 4KB = 16KB),远小于单级页表的4MB
对于两级页表,一张页目录表是必须的,页表则是按需建立
说明1:如果程序使用了全部4GB线性地址空间,两级页表相比单级页表还要多占用4KB页目录表的内存。但是这种情况基本不会发生,因此通过多级页表减少页表内存占用的方法是有效的
说明2:每张页表所映射的内存在整个线性地址空间中是"可浮动"的,他在线性地址空间中的具体位置由指向该页表的页目录项位置决定
因此只要将页目录表中不同的页目录项指向相同的页表,就可以将一个进程中不同的线性地址映射到相同的物理页,这就是Linux中用户态与内核态之间共享物理内存的原理
说明3:如果每个进程持有自己的页表集,并且都有页目录项指向相同的页表,则可以实现进程间的内存共享
3.4 快表
3.4.1 多级页表的问题
1. 凡事皆有利弊,多级页表在引入页目录表之后,虽然可以降低存储页表的空间代价,但是会增加地址转换的时间代价
这是因为页表每增加一级,存储页表节省的内存就会更多,但是也会增加一次访问页表的次数
2. 解决该问题的核心思路,就是记录最近用到的虚拟页和物理页的对应关系。当需要进行地址转换时,先去查找记录,如果有则直接返回对应的物理页;如果没有,再去查找多级页表
3.4.2 快表的实现
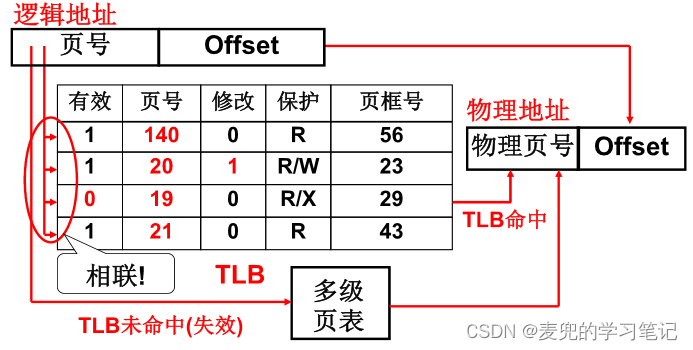
1. 俗称的快表就是地址转换后援缓冲器(Translation Lookaside Buffer,TLB)
2. TLB由硬件电路实现,可以根据线性地址直接索引到TLB表项,一次完成整个缓存页表的查找
说明1:TLB生效的原理
TLB的有效性与TLB的命中率有关,在引入TLB之后,内存的有效访问时间公式如下
| 有效访问时间 = HitR * (TLB + MA) + (1 - HitR) * (TLB + 2MA + MA) |
① 如果TLB命中率为98%,则
有效访问时间 = 98% * (20ns + 100ns) + 2% * (20ns + 300ns) = 124ns
可见要想达到近似访问内存一次的效果,TLB的命中率必须非常高
② 如果TLB命中率为10%,则
有效访问时间 = 10% * (20ns + 100ns) + 90% * (20ns + 300ns) = 300ns
③ 确保TLB命中率的基础是程序的局部性原理
从另一个方面说,如果程序在大范围内做跳转破坏局部性,就会降低TLB命中率
说明2:TLB应该多大?
① 从提高命中率的角度,TLB entry数量越多越好
② 但是TLB entry数量越多成本越高,因此需要在性能和成本之间进折中
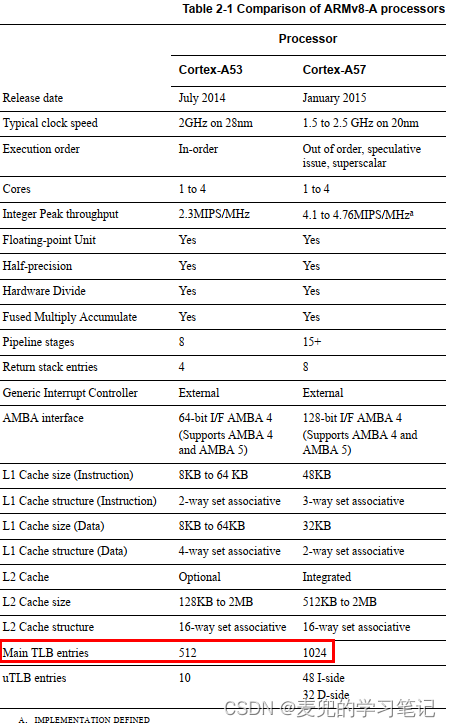
③ 基于局部性原理,TLB entry数量通常为64 ~ 1024之间。以4KB分页为例,可以覆盖256KB ~ 4MB内存
下图为ARMv8体系结构Cortex-A53和Cortex-A57的TLB数量
④ 为提高TLB entry的利用率,还需要有合理的TLB替换策略,一般使用LRU算法,而且是硬件实现
说明3:由于在引入TLB之后,进行地址翻译时是先查TLB后查页表。所以如果页表被修改,需要及时刷新TLB,否则查询TLB得到的地址转换结果就是错误的
更准确地说,是如果修改了当前有效的页表项(e.g. 修改映射关系或者使其无效),则需要刷新TLB。如果修改的页表项当前无效,则无需刷新,因为该页表项本就不在TLB中
3.4.3 多级页表与TLB组合使用的逻辑
1. 为解决内存碎片问题,将物理内存分页并以页为单位进行内存分配。分页之后,需要使用页表来记录虚拟页到物理页的映射关系
2. 如果使用单级页表,存储页表需要占用较多内存。为减少存储页表的内存开销,使用多级页表代替单级页表
3. 但是多级页表会增加地址转换的时间开销,因此引入TLB提升地址翻译速度
说明:通过多级页表和TLB的组合使用,可以达到如下效果,
① 页表占用内存少
② TLB命中时地址翻译速度很快
③ TLB不命中时查找多级页表速度也不太慢(因为多级页表是连续的,访问的时间复杂度为O(1))
从而达到了空间开销和时间开销上较好的平衡
3.5 IA-32体系结构对分页机制的支持
说明:关于IA-32体系结构分页机制的详细内容可参考保护模式下的80386及其编程03:保护虚拟地址方式 chapter 3
3.5.1 可选的分页机制
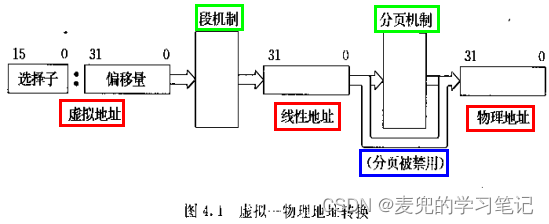
1. IA-32体系结构提供的地址转换机制分为两级,即段机制和分页机制,他们构成的地址转换关系如下图所示,
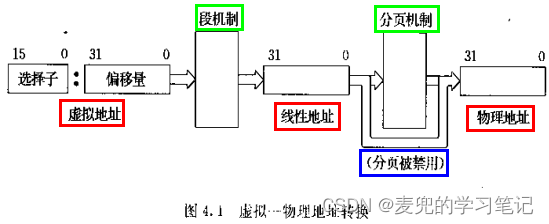
2. 其中段机制是必选的,但是分页机制是可选的,可通过CR0寄存器的PG位进行设置

3.5.2 两级分页
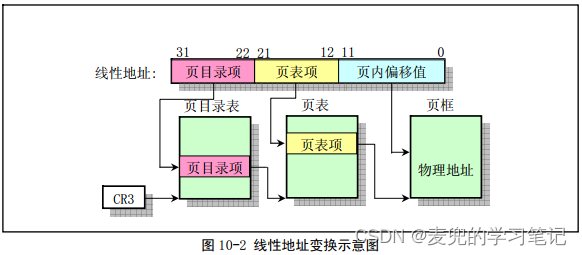
1. IA-32体系结构的内存分页管理是通过页目录表和页表所组成的两级表进行的
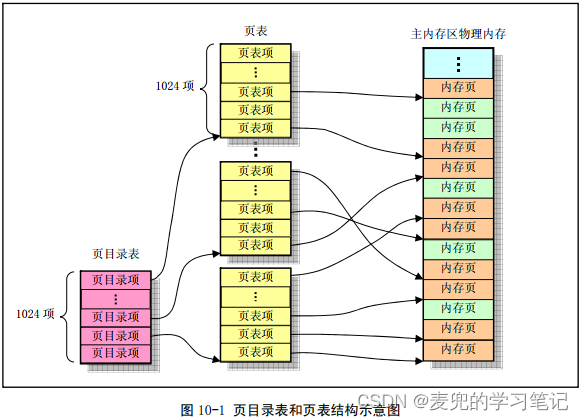
2. 如上图所示,当指定了一个页目录项和一个页表项,就可以唯一地确定所对应的物理页。因此32位的线性地址被分成了3个部分,
① 页目录索引:用来指定一个页目录项
② 页表索引:用来指定一个页表项
③ 页内偏移:对应物理内存页上的偏移地址
3.5.3 分页机制相关系统寄存器
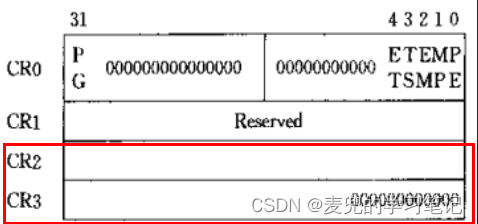
1. CR3寄存器
① 存储页目录表的物理基地址
② 一个系统中可以同时存在多个页目录表,但是在某一时刻只有一个页目录表可用,也就是当前CR3寄存器指向的页目录表
tips:但是Linux 0.11内核中只有一个页目录表
2. CR2寄存器
当发生页故障(page fault)时,处理器将引起异常的线性地址保存在CR2寄存器中,供页故障处理程序使用
4 段页式内存管理与虚拟内存
4.1 为什么要段页结合?
1. 程序希望使用段
① 将程序分为若干段,每个段分开单独处理独立编址,符合程序对内存区域的使用习惯
② 段面向用户
2. 物理内存希望使用页
① 将物理内存分页,然后在接到用户的内存使用请求以页为单位分配内存,可以避免内存碎片问题,提高物理内存利用率
② 页面向硬件
4.2 虚拟内存
4.2.1 虚拟内存的引入
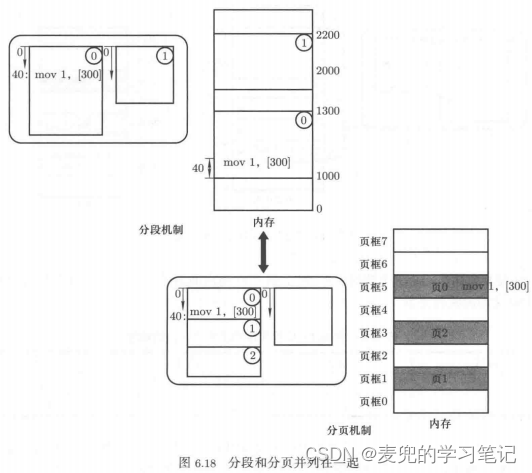
1. 段页结合的基本思路,就是引入一个中间结构,将分段机制的输出和分页机制的输入结合起来
2. 这个中间结构需要既能分割成段,也能分割成页
① 首先是程序组织为多个段,并从中间结构上分割出段并建立段表,完成分段机制
② 然后将中间结构分割成页,将这些页存储在物理内存的页框中,并建立页表,完成分页机制
3. 这个中间结构本质上是一个地址空间,因此被称作虚拟内存
4.2.2 虚拟内存结构
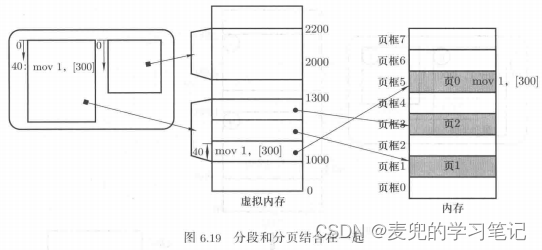
在引入虚拟内存之后,在将磁盘上的程序载入内存时,需要依次完成如下工作,
1. 分配虚拟内存建段表
在虚拟内存中分割出段,然后建立段表记录程序中段与虚拟内存中段的映射关系

2. 分配物理内存建页表
将虚拟内存分割成页,并分配物理内存中的空闲页框,将虚拟内存中的内容加载到物理内存的页框中,然后建立页表记录虚拟内存页与物理内存页的映射关系

说明1:引入虚拟地址后的地址翻译过程
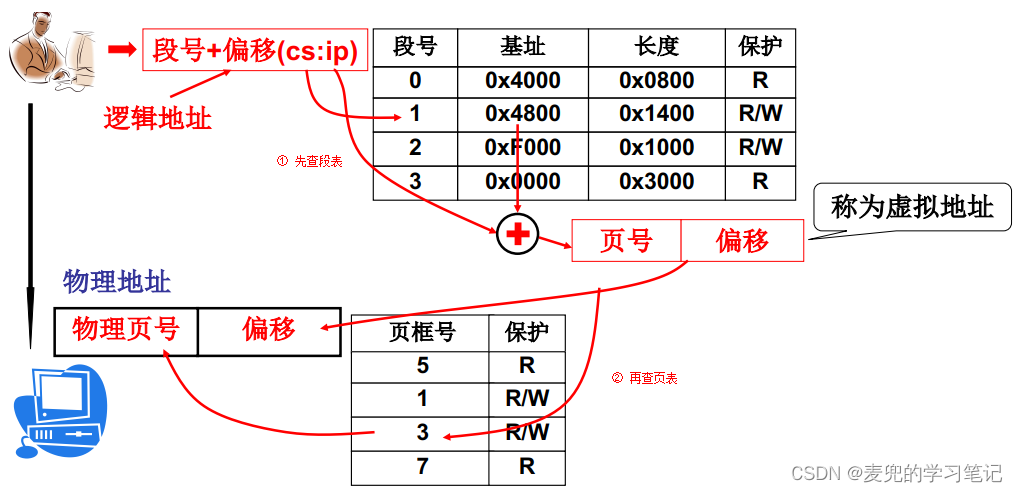
引入虚拟地址后的地址翻译过程和上文中将程序加载到内存中的操作是匹配的,
① 先查段表,将逻辑地址转换为虚拟地址(线性地址)
② 再查页表,将虚拟地址转换为物理地址
只要将特定的系统寄存器(e.g. GDTR / LDTR / CR3)设置为正确的段表和页表基地址,每次寻址时MMU都会自动完成上述地址转换过程
说明2:虚拟内存中的所谓"虚拟",是指不存在但看得见。从本质上说,虚拟地址只是一套由硬件MMU和软件设置的段表页表共同构成的地址转换关系,可以将其理解为一个函数PA = f(VA),并不是真实的内存
但是从程序的角度,内存确实是按段组织,并且使用一个完整的一维的4GB线性地址空间
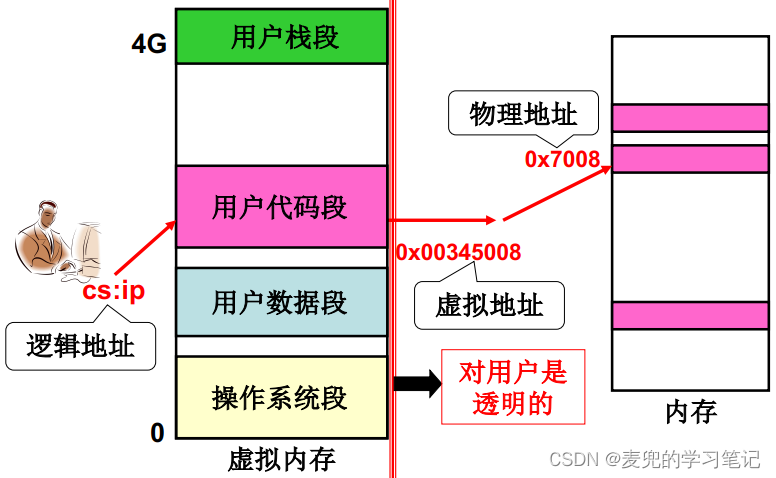
值得说明的是,上图中的"透明",是指存在但看不见。这套转换机制实际存在,但是对应用程序不可见
说明3:本章描述的段页式内存管理主要针对X86体系结构,对于没有分段机制的体系结构(e.g. ARM),没有通过段表从逻辑地址到虚拟地址(线性地址)的转换,可以认为程序是直接使用线性地址空间
在这种情况下,程序中的分段仅具有逻辑上的意义,而没有内存管理机制上的意义
4.3 Linux 0.11内核段页结合实例
Linux 0.11实际使用的段页式内存管理结构如下图所示,
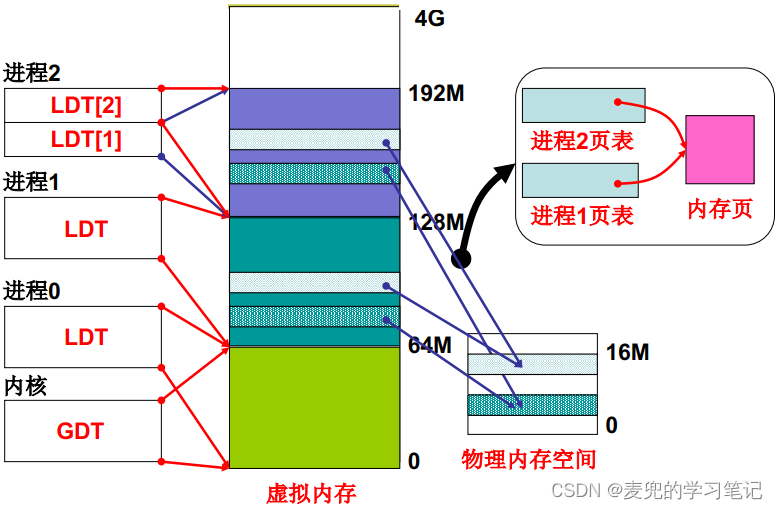
1. GDT映射的内核代码段与内核数据段范围为0 ~ 16MB(图中64MB有误)
2. 共设置64个任务平分4GB线性地址空间,每个任务64MB,通过每个任务的LDT表映射
其中0号进程的用户代码段和用户数据段范围为0 ~ 640KB(图中64MB有误)
3. 无论是GDT映射的内核代码段和内核数据段,还是LDT映射的用户代码段和用户数据段,均使用平坦模型,这就使得程序可以在统一的线性地址空间中编址规划代码段、数据段等
通过这种"绕过分段机制"的行为,在有分段机制的X86体系结构中,也可以让应用程序中的分段仅具有逻辑上的意义。这样有利于Linux兼容多种体系结构,尤其是兼容没有分段机制的体系结构
4. 由于是64个任务平分4GB线性地址空间,因此所有任务可以使用同一张页表。上图中进程1和进程2页表,更准确的理解方式是同一张页表中进程1的部分和进程2的部分
说明:有关Linux 0.11分段机制布局的详细内容,可参考05. 线程切换与调度 chapter 5.1
5 Linux 0.11内存分页管理实例
5.1 页表初始化
5.1.1 页表存储位置
1. 在设置页表及使能分页机制之前,Linux 0.11内核的启动代码已经设置了GDT表并使能了保护模式。其中设置的内核代码段和内核数据段的线性段基址均为0,段界限均为16MB
在构成的逻辑地址到线性地址的映射关系上,为恒等映射(逻辑地址从0开始,内核代码段和数据段的线性基地址也从0开始),因此逻辑地址 = 线性地址
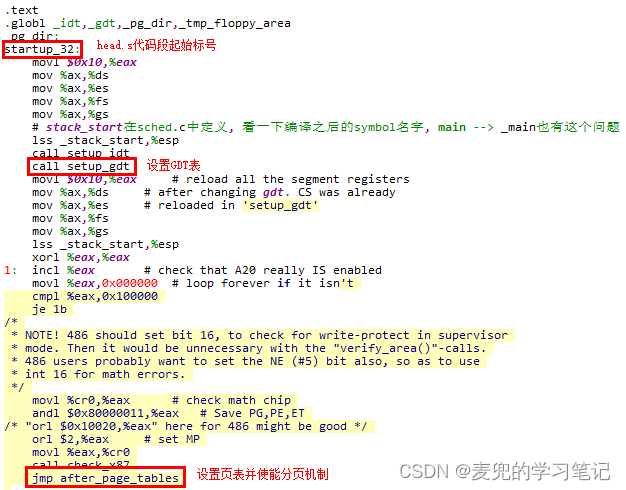
2. Linux 0.11的页目录表存储在物理0地址处,也就是head.s中的pg_dir标号
pg_dir和head.s的代码段起始标号startup_32的符号地址相同,均是从0开始。而编译后的head组件也被加载到物理0地址处,因此pg_dir标识的页目录表位于物理0地址处。相关内容可参考Linux 0.11内核分析02:系统启动 chapter 1.2.2.3
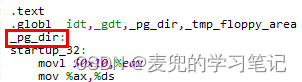
3. 在Linux 0.11的内核启动阶段,共设4张页表,分别位于物理地址0x1000 / 0x2000 / 0x3000 / 0x4000处。为便于操作,定义了pg0 / pg1 / pg2 / pg3共4个标号
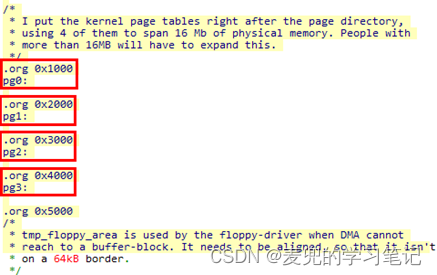
4. 最终1张页目录表和4张页表的存储位置如下图所示,

5.1.2 页表初始化目标
1. 由于每张页表可以映射4MB内存,因此4张页表可以映射16MB内存,足以覆盖实验环境中使用的物理内存
2. 在构成的线性地址到物理地址的映射关系上,也是恒等映射,因此线性地址 = 物理地址。结合之前GDT表中建立的内核代码段和内核数据段恒等映射,在内核态具有逻辑地址 = 线性地址 = 物理地址的对应关系
说明:对于Linux 0.11的用户进程,各地址映射关系如下
① 从逻辑地址到线性地址是线性映射,即逻辑地址和线性地址之间有一个固定的偏移量,而这个固定的偏移量由进程在task数组中的下标决定(注意不是进程PID)
| 线性地址 = 逻辑地址 + offset |
② 从线性地址到物理地址,则是在缺页异常中根据当前实际情况建立的映射关系,就没有简单的对应关系了
5.1.3 页表初始化流程
为了通过4张页表建立16MB的恒等映射,就需要按预设的目标也两级页表结构填页目录表和页表,总体流程如下图所示,
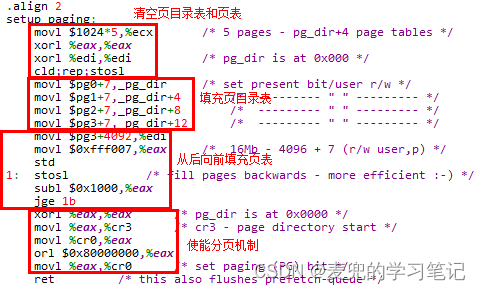
5.1.3.1 清空页目录表和页表
| // 要清空1张页目录表和4张页表 |
说明1:stosl指令
① stosl指令将EAX寄存器中的值存储到[ES:EDI]指向的内存中
② 如果EFLAGS寄存器中的DF位为0,则每次存储后EDI寄存器自增4
③ 如果EFLAGS寄存器中的DF位为1,则每次存储后EDI寄存器自减4
说明2:对于清空的页目录项和页表项,由于P位为0,表示表项无效
5.1.3.2 填充页目录表
| // 填充页目录中的4个页目录项 |
说明1:由于是要对前16MB内存进行恒等映射,所以要填充页目录表中的前4个页目录项
说明2:填充页目录项的属性值为7,也就是0b111,对应到页目录项
① P位 = 1,表示页目录项有效
② R/W位 = 1,表示对应页表映射的页都可读可写
③ U/S位 = 1,表示对应页表映射的页可以被任何特权级的程序访问
说明3:此处将内核页表的R/W位和U/S均设置为1,看似很危险,但是实际不会造成破坏,原因如下,
① 用户进程通过LDT表实现进程间的地址隔离,因此无法访问到0号进程的线性地址空间,即0 ~ 640KB。用户进程经过LDT段表转换后的线性地址都是64MB开外的
② 用户进程只能通过中断或异常陷入内核态,因此也无法随意访问内核页表
5.1.3.3 填充页表
| // edi指向最后一个页表项 |
5.1.3.4 使能分页机制
| // 将EAX寄存器清零,页目录表的物理基地址为0 |
5.1.4 如果页表的线性地址和物理地址不同怎么办?
说明:此处的讨论主要针对内核,因为内核是先被加载到物理内存,之后才在内核启动过程中建立页表。所以建立的页表需要映射到正确的物理内存,才能确保内核的正确运行
1. Linux 0.11内核页表标号pg_dir的链接地址为0;内核镜像加载到物理内存后,pg_dir标号对应的物理地址也为0。因此只要建立从0开始的恒等映射,就可以将内核镜像中使用的链接地址正确映射到物理地址,从而确保内核的正确运行
2. 如果内核页表标号的链接地址与实际加载的物理内存不一致,则需要特殊处理。以Linux 2.4内核 + 80386体系结构为例,
① 内核镜像的链接起始地址为0xC0100000

对应的内核页目录表标号swapper_pg_dir的链接地址为0xC0100000 + 0x1000 = 0xC0101000

② 如果将内核镜像加载到物理0地址处运行,那么内核页目录表标号swapper_pg_dir对应的物理地址为0x1000
3. 对于上述情况,就出现了页表线性地址和物理地址不同的情况,此时就需要建立两种映射,
① 恒等映射
- 将物理地址0 ~ 8MB映射到内核页表线性地址0 ~ 8MB
- 这是因为内核镜像在开启分页之前已经在物理0地址处运行,已经有指令被预取到流水线,这些指令的正确执行可能依赖恒等映射(e.g. 指令中包含基于PC的内存访问操作)
- 这种恒等映射仅在内核页表启动阶段使用,后续进程页表的线性地址低端映射的是用户地址空间
② 线性映射
- 将物理地址0 ~ 8MB映射到内核页表线性地址PAGE_OFFSET处,一般是0xC0000000(即3GB处)。PAGE_OFFSET的设置与进程地址空间布局有关,详情可参考编程高手必学的内存知识01:深入理解虚拟内存 chapter 5
- 这是因为内核镜像后续的地址相关操作会使用链接地址,因此需要将链接地址映射到内核镜像被加载的实际物理地址
- 通过fork系统调用创建的进程会拷贝内核页表3GB ~ 4GB的映射关系到进程页表,从而使得每个进程有相同的内核地址空间
5.2 内存初始化mem_init
5.2.1 物理内存布局
1. 在实验环境中,共设置16MB物理内存
2. 在系统启动过程中,会根据设置的物理内存大小,计算物理内存布局中的各界限值
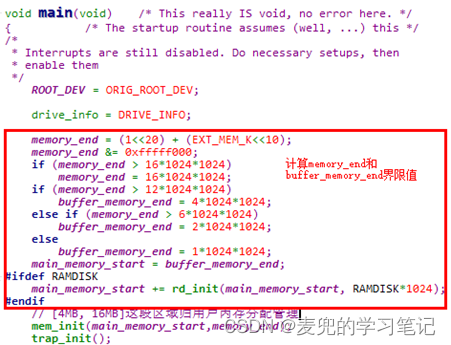
3. 最终的物理内存布局如下图所示,
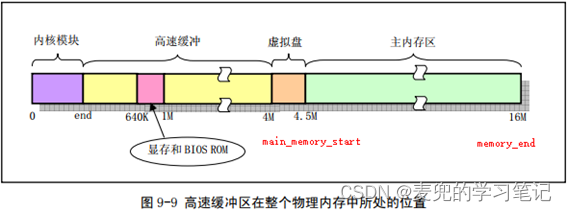
由于在当前实验环境中没有使能虚拟盘RAMDISK,因此,
① main_memory_start = 4MB
② memory_end = 16MB
也就是说,主内存区为4MB ~ 16MB范围,由内存管理模块通过分页机制进行管理分配
5.2.2 物理内存管理数据结构
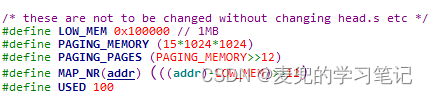
在Linux 0.11内核中使用mem_map数组以页为单位管理主内存区,相关数据结构和宏定义如下,
![]()
1. mem_map是一个unsigned char类型字节数组,其中,
① 数组成员个数为15MB / 4KB,也就是mem_map数组最多管理15MB主内存区
② 数组成员值描述一个物理内存页的占用状态,0表示对应的物理内存页空闲。当申请一页物理内存时,就将对应字节的值加1
2. MAP_NR宏用于将线性地址映射为对应物理页在mem_map数组中的下标,从映射的计算过程可见,内核模块所在的低端1MB内存不在mem_map数组管理范围内
相当于1MB ~ 16MB的范围(共15MB)可以都在mem_map数组中管理,但是根据目前的配置,有效的主内存区为4MB ~ 16MB
5.2.3 mem_init函数分析

说明1:在当前的实验环境下,mem_init函数执行后,mem_init数组状态如下图所示,

说明2:mem_init函数的初始化策略,将物理内存实际划分为4个部分,
① 低端1MB内核组件
这部分不在mem_map数组管理范围内
② 1MB到4MB(start_mem)的缓冲区
这部分在mem_map数组管理范围内,但不是主内存区,被标记为USED,不会被分配
③ start_mem ~ end_mem主内存区
这部分在mem_map数组管理范围内,是主内存区,初始化时被标记为空闲,可用于分配
④ end_mem ~ 16MB未实现内存区
这部分在mem_map数组管理范围内,但是由于实际物理内存不足16MB,因此被标记为USED,防止被错误分配
5.3 物理页分配get_free_page
5.3.1 相关指令概述
下面先说明get_free_page函数中会使用到的相关指令
5.3.1.1 scasb指令
1. scasb属于字符串扫描(scan string)指令,该指令将AL寄存器中的值与[ES:EDI]指向内存中的字节进行比较,并根据比较结果修改EFLAGS寄存器中的相关标志位。配合rep类指令前缀,可用于在字符串中寻找一个数值
2. 如果EFLAGS寄存器中的DF位为0,则每次比较后EDI自增1;如果DF位为1,则每次比较后EDI自减1
5.3.1.2 sall指令
1. sall属于算术左移(Shift Arithmetic Left)指令
2. sall指令操作的数据长度为4B
5.3.1.3 leal指令
1. leal属于获取偏移地址(Load Effective Address)指令
2. leal指令操作的数据长度为4B
5.3.2 get_free_page函数分析
| unsigned long get_free_page(void) |
说明:经过上文分析可知,get_free_page函数用于获取一个空闲页,返回值如下,
① 如果分配到空闲页,则返回该页的物理地址,同时会将该页的引用计数设置为1,并将该页清零
由于建立了恒等映射,在内核态返回的是页的物理地址,也是页的线性地址和逻辑地址
② 如果没有空闲页,则返回0
5.4 物理页释放free_page
与get_free_page函数相对应,free_page函数用于释放一个物理页,函数参数为要释放物理页的起始物理地址

5.5 建立页面映射关系put_page
通过get_free_page函数分配到一个空闲页后,并没有和某个进程的线性地址建立映射,该操作由put_page函数完成
5.5.1 两级页表索引概述
在说明put_page函数如何将空闲页物理地址和进程线性地址建立映射之前,先说明IA-32体系结构两级页表如何索引
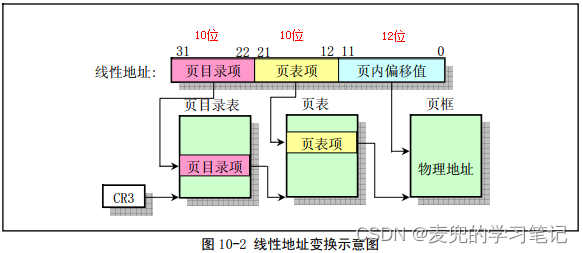
1. 线性地址右移22位 = 页目录项在页目录表中的下标
2. 线性地址右移22位再左移2位 = 页目录项在页目录表中以字节为单位的偏移量
3. 线性地址右移12位 & 0x3FF = 页表项在页表中的下标
4. 线性地址右移12位 & 0x3FF再左移2位 = 页表项在页表中以字节为单位的偏移量
5.5.2 put_page函数分析

说明1:如果不在物理页引用计数为1时建立映射,Linux 0.11内核只是打印警告信息,但是仍然会建立映射关系
说明2:计算页目录项字节偏移量的方式
① 如上文所述,计算页目录项字节偏移量的方式为线性地址右移22位再左移2位
② 此处使用右移20位代替,但是需要将低2位清零,才能确保计算结果与上面的方法一致
说明3:从页目录项获取页表物理地址
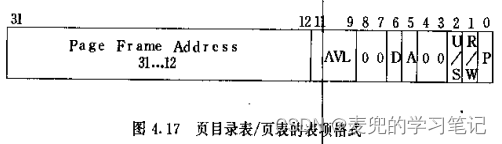
在put_page函数中,如果页目录项有效,则直接从页目录项中获取页表的物理地址,此处直接取页目录项的高20位即可
说明4:关于"no need for invalidate"注释
① 在put_page函数的最后有一行注释,说明"no need for invalidate"。我们首先来看一下Linux 0.11内核中内存管理的invalidate操作是什么
![]()
可以看出,invalidate操作就是将0写入CR3寄存器,也就是将页目录表的物理基地址写入CR3寄存器。而更新CR3寄存器的值会导致完整刷新TLB,这也就是宏名invalidate的由来
② put_page函数修改了页目录项和页表项却不需要刷新TLB,是因为put_page函数中是新增页目录项或页表项并将他们标记为有效,也就是说他们之前是无效的,那么自然也不会被缓存在TLB中(无效的地转换关系不会被缓存在TLB中)
从另一个方面说,如果修改了之前有效的页目录项或页表项,则需要调用invalidate函数刷新TLB,下面的copy_page_tables和free_page_tables函数就需要这样的操作
说明5:Linux 0.11内核中的get_empty_page函数结合了get_free_page和put_page函数的功能,在一个函数中实现空闲页的分配与映射

说明6:oom函数一般在分配内存失败时调用,标识系统中空闲内存已耗尽。该函数在打印相关信息后,会调用do_exit函数终止当前申请内存的进程,并传递exit_code为SIGSEGV

说明7:进程页表位置
① 如页表初始化小节所述,页目录表存储在物理0地址处,并在其后存储了4张页表共映射16MB物理内存,该页表供0号进程使用,也就是供内核使用
此处的页目录表和页表均属于内核镜像的一部分,位于低端1MB物理内存
② 进程的页表则是使用get_free_page函数从主内存区分配
5.6 拷贝页表copy_page_tables
5.6.1 copy_page_tables函数功能概述
1. copy_page_tables函数的调用关系如下,可见是在通过fork系统调用创建子进程时使用,用于拷贝父进程的页表
| sys_fork |
2. copy_page_tables函数用于拷贝指定线性地址和长度的内存对应的页目录项和页表,从而使得子进程和父进程共享物理内存区域,这样可以达到节约内存和加快进程创建速度的目标
3. 在拷贝页目录项和页表的过程中,还需要为写时复制机制做准备
5.6.2 copy_page_tables函数分析


说明1:copy_page_tables函数的工作过程如下图所示,主要步骤是,
① 分配页表,填充页目录项
② 拷贝父进程页表
需要注意的是,在填充子进程页目录项和页表项的过程中,会跳过父进程中无效的表项
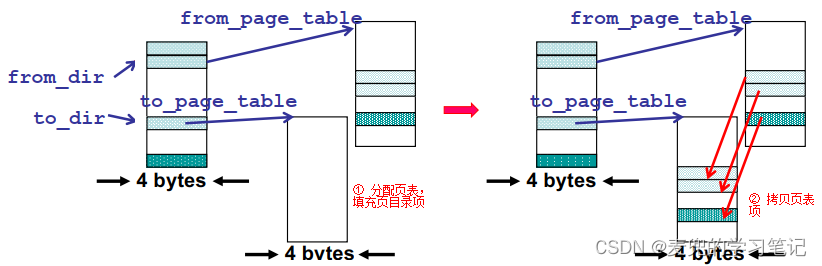
说明2:在copy_page_tables函数中,如果为子进程分配页表失败,会直接返回-1
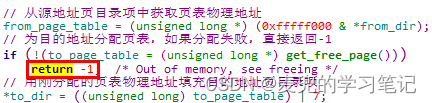
这里的操作不会导致已分配页表的内存泄露问题,因为外层的copy_mm函数在判断出copy_page_tables函数执行失败后,会调用free_page_tables函数将子进程的页表释放
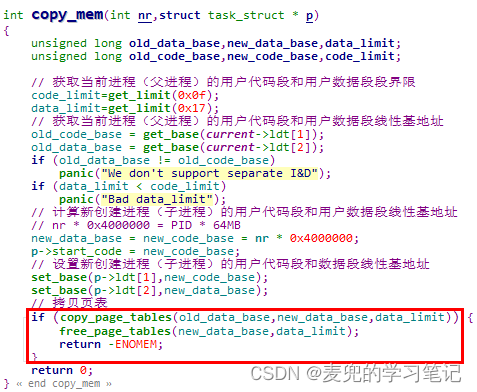
说明3:写时复制实现原理
copy_page_tables函数为写时复制做的准备主要体现在如下操作,由于父子进程对共享的物理页均没有写权限了,只要当其中一方进行写操作时就会出发page fault。在page fault的异常处理中,会为进行写操作的进程分配新的物理页面并拷贝之前共享页内的内容,同时解除共享关系

说明4:由于copy_page_tables函数修改了有效的页表项,将已有的父进程页表项设置为只读属性,因此需要调用invalidate宏刷新TLB
5.7 释放页表free_page_tables
free_page_tables用于释放指定线性地址和长度的内存对应的物理页及页表

说明:由于free_page_table函数也修改了有效的页表项,因此也需要调用invalidate宏刷新TLB
5.8 计算内存空闲页数量calc_mem
calc_mem函数在源码中没有被调用,该函数可打印系统中空闲页个数和每个页表中有效页表项个数

说明:有效页表项个数不一定等于使用的物理页个数,因为存在物理页面共享,不同的页表项可以指向相同的物理页
5.9 内核写页面验证write_verify
5.9.1 write_verify函数功能分析
write_verify函数用于在内核态进行写页面验证,判断要验证的地址是否存在页面共享的情况(也就是页目录项和页表项均有效,但是没有写权限),如果存在,则调用un_wp_page函数进行写时复制操作

说明1:进行写时复制的2个时机
① 进程在自己的线性地址范围内进行写操作时,如果操作到写时复制的共享页,则会触发page fault,并在异常处理中调用un_wp_page函数执行写时复制操作
② 当内核需要在某个进程的线性地址范围内进行写操作时(e.g. 进程调用某个系统调用,而该系统调用会将数据拷贝到进程的缓冲区),会主动调用write_verify函数判断是否有页面共享的情况存在。如果有,则执行写时复制操作
说明2:内核态为什么要调用verify_area函数进行写验证?
① 根据上文分析,write_verify函数的作用是检查内核要写入的用户态内存是否存在页面共享的情况,如果存在则进行写时复制操作解除共享
② 那么为什么不能将这个工作交由页故障异常处理函数完成,而是要内核态主动检查?这是因为写时复制依靠页表项的R/W位实现,但是内核态运行在0特权级,RW位将被忽略。因此如果在内核态直接写入存在页面共享情况的用户态地址,并不会触发页故障,也就无法进行写时复制操作
详情可参考保护模式下的80386及其编程03:保护虚拟地址方式 chapter 3.3.2

③ 如果不存在页面共享的情况,而是单纯的没有分配页,则verify_area函数不会进行额外的操作。内核后续的写入操作,则会触发缺页异常,并在缺页异常中分配内存页
5.9.2 wirte_verify函数调用分析
write_verify函数被verify_area函数调用,而verify_area函数被众多系统调用用于对进程用户态缓冲区进行写前验证,该验证以页为单位

以处理read系统调用的sys_read函数为例,会调用verify_area函数对进程的用户态缓冲区进行写前验证
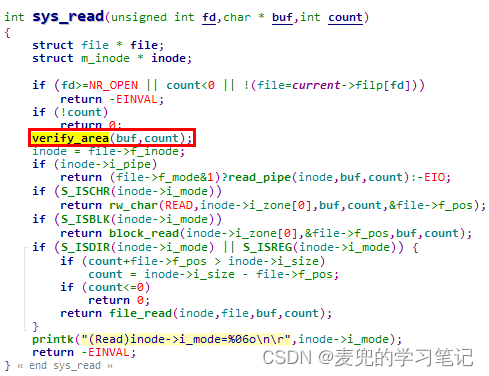
说明:传递给verify_area函数的addr是进程的逻辑地址,需要将其转换为线性地址。与此同时,write_verify函数以页为单位对用户态地址进行验证,因此需要对内存验证范围和起始地址进行调整

调整的效果如下图所示,

6 Linux 0.11进程地址空间
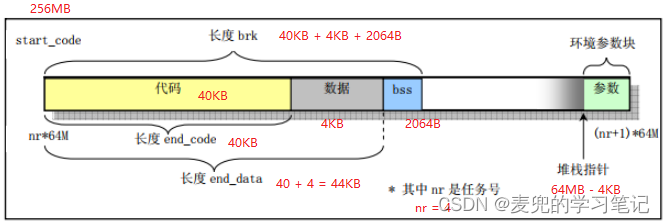
6.1 进程地址空间布局
Linux 0.11中进程的地址空间布局如下图所示,
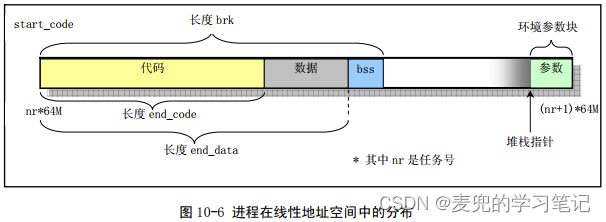
其中的start_code / end_code / end_data / brk / 用户栈指针(start_stack)均记录在task_struct结构中,

说明1:每个进程在线性地址空间中都是从nr * 64MB的地址开始,占用64MB内存,其中nr是进程在task数组中的下标
说明2:进程的逻辑地址空间与线性地址空间
① 从4GB线性地址空间的角度,上图是进程在线性地址空间中的布局
② 从单个进程的角度,上图也是进程的逻辑地址空间布局
③ 在Linux 0.11内核中,每个进程的逻辑地址空间为64MB,之后通过LDT表映射到4GB的线性地址空间中
在后续的Linux内核版本中,每个进程都有4GB的逻辑地址空间,而分段机制又通过0 ~ 4GB的平坦模型将4GB逻辑地址空间直接映射到4GB线性地址空间中。因此进程的逻辑地址空间和线性地址空间是重合的,程序在逻辑地址空间中的布局可以恒等映射到线性地址空间中
说明3:在Linux 0.11内核中,进程的命令行 / 环境变量参数被存储在进程地址空间的最高端,且最大长度为128KB,也就是32页。在本文中,我们将该区域称为环境参数块
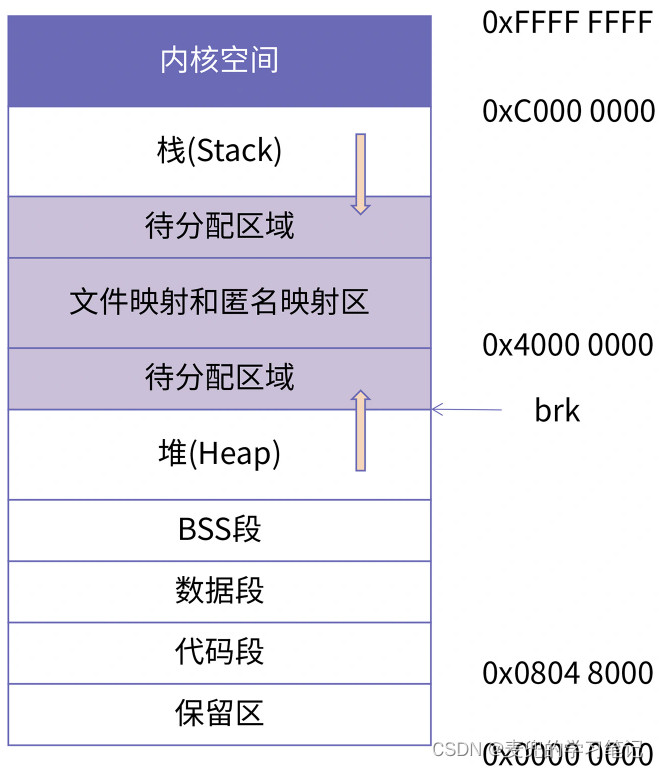
说明4:本节中说明的是Linux 0.11内核的进程地址空间布局,目前IA-32 + Linux的进程地址空间布局如下图所示
6.2 进程地址空间实验
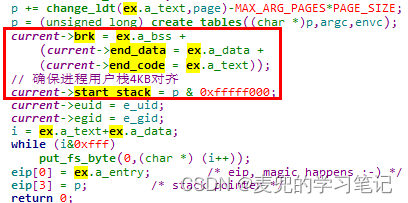
6.2.1 概述
在do_execve函数中,会根据读入的可执行文件设置当前进程的地址空间布局。我们在该函数中增加打印,验证进程地址空间布局
6.2.2 exec结构
exec结构是Linux 0.11可执行文件头结构,各字段含义如下,

说明:对于一款操作系统,需要约定可执行文件的格式(e.g. 目前Linux操作系统的可执行文件采用ELF格式),而可执行文件格式一般都带有头部结构。操作系统在加载可执行文件时,通过读取头部结构获取可执行文件信息
6.2.3 实验验证
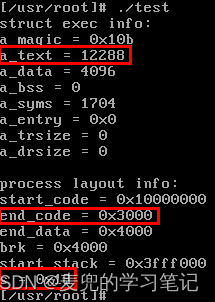
1. 在do_execve函数中打印exec结构和当前进程的地址空间布局

2. 在命令行执行ls命令,查看打印信息
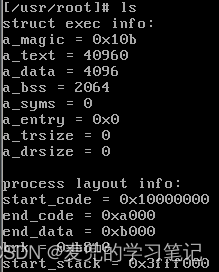
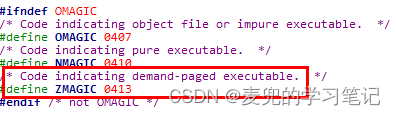
① a_magic = 0x10b = 413O
表示该文件类型为demand-paged executable
这与file命令查看的文件类型一致

② a_text = 40960 / end_code = 0xa000 = 40960
代码段长度为40KB
③ a_data = 4096 / end_data - end_code = 0x1000 = 4096
数据段长度为4KB
④ a_bss = 2064 / brk - end_data = 0x810 = 2064
BSS段长度为2064
⑤ a_entry = 0x0
可执行程序入口点
⑥ start_code = 0x10000000 = 256MB
可见该进程编号为4,进程的线性地址空间为256MB ~ 320MB
⑦ start_stack = 0x3fff000 = 65532KB
可见环境参数块占用4KB内存,之后便是进程用户栈
说明1:ls命令执行时的进程线性地址空间布局如下图所示
说明2:在process layout info中,
① start_code是在4GB线性地址空间中的地址
② end_code / end_data / brk / start_stack都在64MB逻辑地址空间内,或者说是进程内部的偏移量
6.3 进程地址空间布局字段使用分析
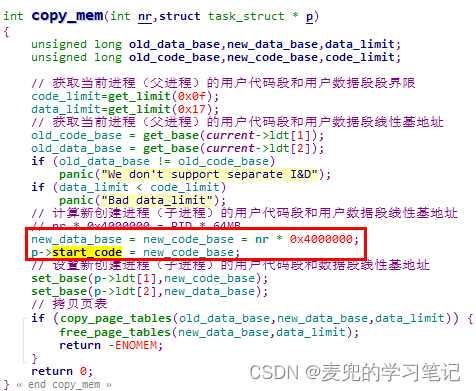
6.3.1 start_code字段的使用
1. start_code字段在创建进程时赋值,初值为(进程编号 * 64MB)
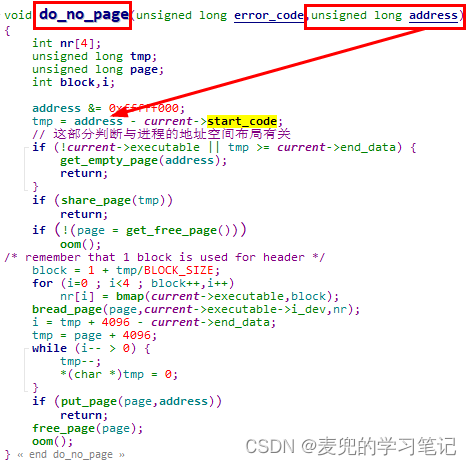
2. 在缺页异常的处理过程中,将触发异常的线性地址减去start_code,就可以得到触发异常的线性地址在64MB进程地址空间中的偏移量
3. 更进一步地说,start_code字段是用于实现4GB线性地址空间地址与64MB进程逻辑地址空间地址之间的转换
① 4GB线性地址空间地址 - current->start_code = 64MB进程逻辑地址空间地址
② 64MB进程逻辑地址空间地址 + current->start_code = 4GB线性地址空间地址
此处附上一个实例,就是CODE_SPACE宏,该宏用于判断一个4GB线性地址空间地址是否在进程的代码段范围内
![]()
6.3.2 start_stack字段的使用
1. start_stack字段在do_execve函数中被赋值为进程用户栈所在页的地址(向地址低端对齐)
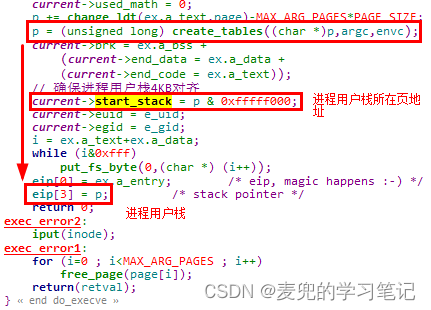
2. start_stack字段在sys_brk函数中被用于判断要设置的brk位置是否合法

说明1:在进程运行过程中,start_stack字段的值不会被修改,可见该字段主要作为一个地址比较的基准使用
说明2:从sys_brk的比较逻辑可见,进程用户栈最大可使用16KB(current->start_stack - 16384),再往低地址使用,就可能和堆区重叠
但是也可以看出,Linux 0.11内核中sys_brk的比较逻辑是很粗糙的
6.3.3 brk字段的使用
6.3.3.1 brk字段与堆空间
1. 进程在需要动态使用内存时,是通过malloc函数从堆中申请,而堆空间本质上是进程线性地址空间的一部分,是一段长度可变的连续虚拟内存
2. 无论是32位系统还是64位系统,Linux内核都会维护一个变量brk(全称为program break),该变量指向堆的顶部,所以brk的位置决定了堆的大小。以目前的Linux内核版本为例,从BSS段末尾到brk之间的线性地址区域就是堆空间

3. 进程中内存的动态分配和释放,就是改变堆空间大小,也就是改变进程brk的位置。此时分配的是线性地址空间中的虚拟页,实际的物理页分配通过缺页异常进行
4. 关于brk的上界
在进程线性地址空间中,堆空间向高地址方向发展,栈空间向低地址空间发展。因此堆空间的上限取决于堆空间之上且紧邻堆空间的线性地址区域,也就是上图中文件映射和匿名映射区的下界位置决定了堆空间上界
说明1:Linux 0.11内核的进程地址空间中的brk也是相同的含义,brk的起始值在bss段之后。随着进程中动态的内存申请和释放,brk的位置会随之移动
很显然,Linux 0.11内核中brk的上界取决于进程用户栈的下界,详见下文对sys_brk函数的分析
说明2:在目前的libc库malloc函数实现中,会根据要分配内存的大小调用brk或mmap系统调用实现功能
① 如果使用brk系统调用实现,则是在进程的堆空间中分配虚拟内存
② 如果使用mmap系统调用实现,则是在进程的文件映射区和匿名映射区中分配虚拟内存
相关验证可参考Linux操作系统原理与应用04:内存管理 chapter 2.2.4

说明3:进程用户栈是什么?
有了对进程堆空间的理解,可以加深对进程用户栈空间的理解。进程用户栈本质上也是一段连续的线性地址空间,也是依靠缺页异常分配物理页,只不过是向低地址方向发展
6.3.3.2 brk相关系统调用
6.3.3.2.1 系统调用封装例程
在Linux中有2个操作brk的系统调用封装例程,即brk和sbrk
| 所需头文件 |
#include <unistd.h> |
| 函数原型 |
void *sbrk(intptr_t increment); |
| 函数参数 |
increment:将brk在原有地址上增加从参数increment传入的大小,其中参数increment可正可负 sbrk(0)将返回当前program break的位置,对其不做改变 |
| 函数返回值 |
成功返回之前program break的位置;错误返回-1 |
| 所需头文件 |
#include <unistd.h> |
| 函数原型 |
int brk(void *addr); |
| 函数参数 |
addr:将brk设置为参数addr所指定的位置,内核内部会进行页对齐 |
| 函数返回值 |
成功返回0;错误返回-1 |
6.3.3.2.2 系统调用服务例程
brk和sbrk系统调用封装例程对应的系统调用服务例程均为sys_brk,Linux 0.11内核中的实现如下,
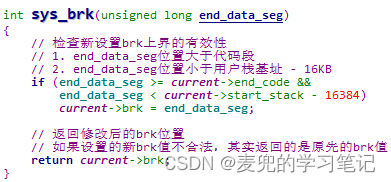
1. sys_brk函数的参数为end_data_seg,从字面意思理解,是数据段结尾。因此在进行参数合法性检查时,要求end_data_seg的值大于end_code的值,也就是在代码段之后
其实从某种意义上说,数据段、BSS段和堆都属于泛指的数据段,他们的属性相同,只是存储的内容不同
2. end_data_seg参数的上界是start_stack - 16KB,可见内核中假设进程用户栈最大为16KB
6.3.3.3 动态内存分配实验
1. 应用程序实验代码如下,在分配和释放内存前后打印brk的位置
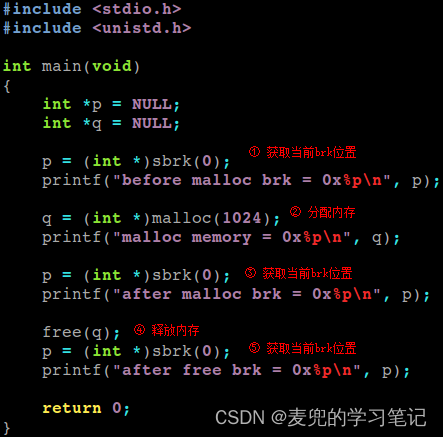
2. 在do_execve函数中打印exec结构和当前进程的地址空间布局
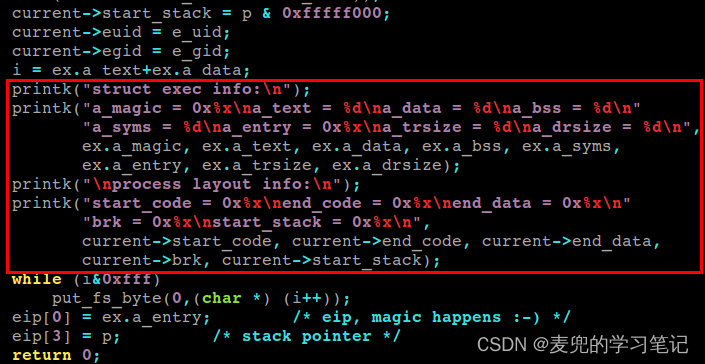
3. 实验打印如下图所示,可见应用程序通过malloc库函数进行动态内存分配,在内核中就会修改brk的位置
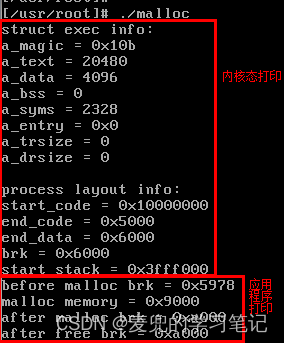
说明1:从实验结果分析,free库函数在释放动态分配的内存后,并没有立即调整brk的位置
说明2:从实验结果分析,在do_execve中brk的初始值为0x6000,但是在malloc前获取的brk值为0x5978,该值小于初始的end_data值,猜测相关修改是在程序的启动代码中进行(在main函数之前执行)
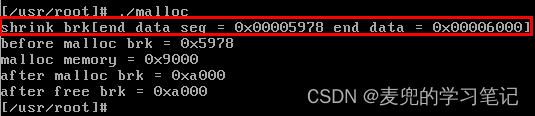
说明3:为了验证上面的猜测,在sys_brk函数中判断缩小堆空间的情况并进行打印,

实验结果印证了上述猜测,在main函数之前确实通过sys_brk系统调用缩小了堆空间,而且与后续通过sbrk(0)函数获取的值一致
同时需要注意的是,在缩小堆空间的过程中,并没有修改end_data字段的值
6.4 只读数据在哪里?
6.4.1 Linux 0.11内核处理方式
在之前的编程学习中,还有一个只读数据区(read only data)的概念,例如程序中的字符串字面值就存储在只读数据区
但是在Linux 0.11内核的进程地址空间中,只有代码段、数据段、BSS段和栈段,并没有"只读数据段",下面就通过实验来验证只读数据的存储位置
1. 实验代码如下,定义字符串字面值并打印字符串字面值的起始地址
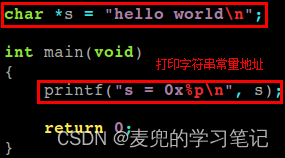
2. 实验结果如下,可见只读的字符串字面值被存储在代码段,从而达到字符串字面值只读的效果
3. 实验程序的反汇编结果如下,可见字符串字面值确实被编译链接在代码段
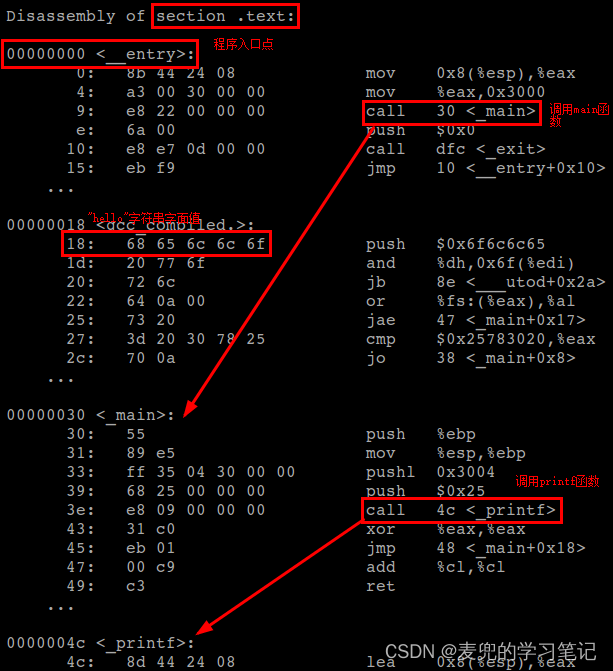
说明1:关于printf函数中的字符串字面值
① 调用printf函数时传递的格式化字符串也是一个字符串字面值,也属于只读数据,因此也应该存储在代码段

② 分析调用printf函数前压栈的参数,可见格式化字符串确实作为字符串字面值被存储在代码段,而压栈的参数是字符串字面值的起始地址0x25
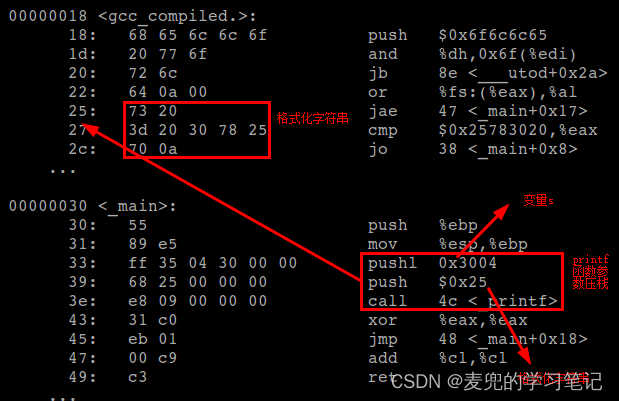
③ 另一个压栈的参数是pushl 0x3004,这是变量s的链接地址,而这条压栈指令会将变量s的值0x18入栈,也就是将"hello"字符串字面值的起始地址压栈

说明2:从对"hello"字符串字面值的传参,也可以加深对指针类型变量的理解,在char *s = "hello"中,
① s是指针类型变量,该变量的地址是0x3004
② 指针类型变量s的值为0x18,是他所指向的字符串字面值的地址,而main函数中压栈的就是指针类型变量s的值
说明3:更进一步地,在C语言中指针类型变量参数的传递也是值传递,由于main函数中压栈的是指针类型变量s的值,因此在栈上就有了变量s的一份拷贝(通过值传递在栈上新建的变量),也就是printf函数的参数。为此我们构造一个更加简单直观的实验程序进行说明,
① 实验代码如下,在main函数和func函数中分别打印指针类型变量的地址和值

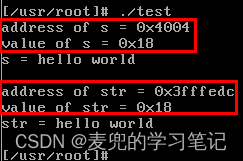
② 实验结果如下,
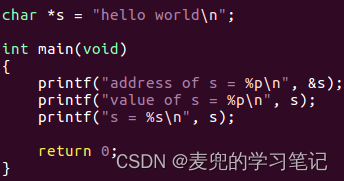
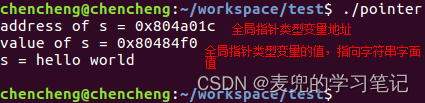
- 指针类型变量s的地址为0x4004,存储在数据段
- 指针类型变量str的地址为0x3fffedc,存储在栈段,是通过值传递创建的func函数参数
- 这2个指针类型变量的值均为0x18,指向存储在代码段的字符串字面值
③ 实验程序反汇编结果如下,
- main函数在调用func函数时,将指针类型变量s的值(即0x18)压栈
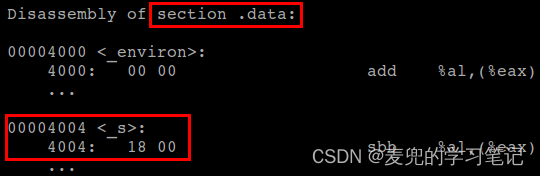

- 在func函数中先后获取指针类型变量str的地址和值,并传递给printf函数进行打印
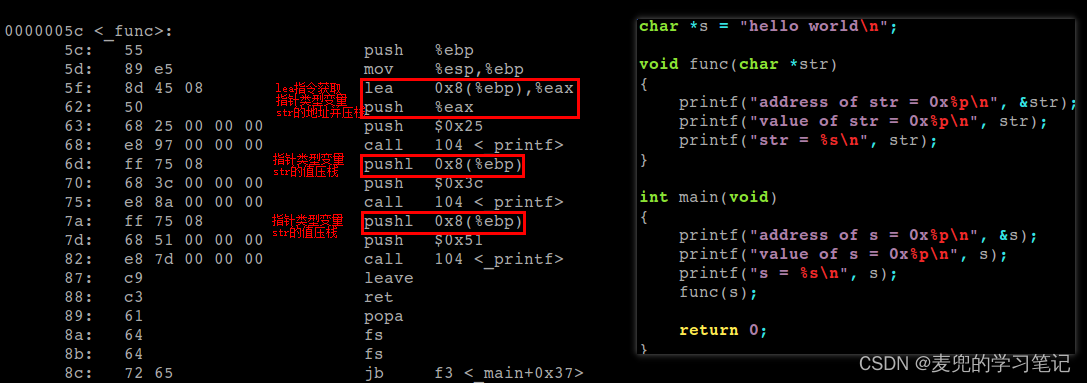
- 可以看出,在使用%s格式符打印字符串时,会自动进行一次解引用,从内存地址0x18处逐个字符进行打印
6.4.2 目前Linux操作系统处理方式
说明:实验环境为Ubuntu 16.04
1. 实验代码和运行结果如下,需要特别注意的是,在编译时增加-m32选项,生成32位的可执行程序
2. 使用readelf -S命令查看可执行程序中所有的Section信息,可见
① 全局指针类型变量在.data段
② 字符串字面值在.text段,这种处理方式与Linux 0.11内核是一致的
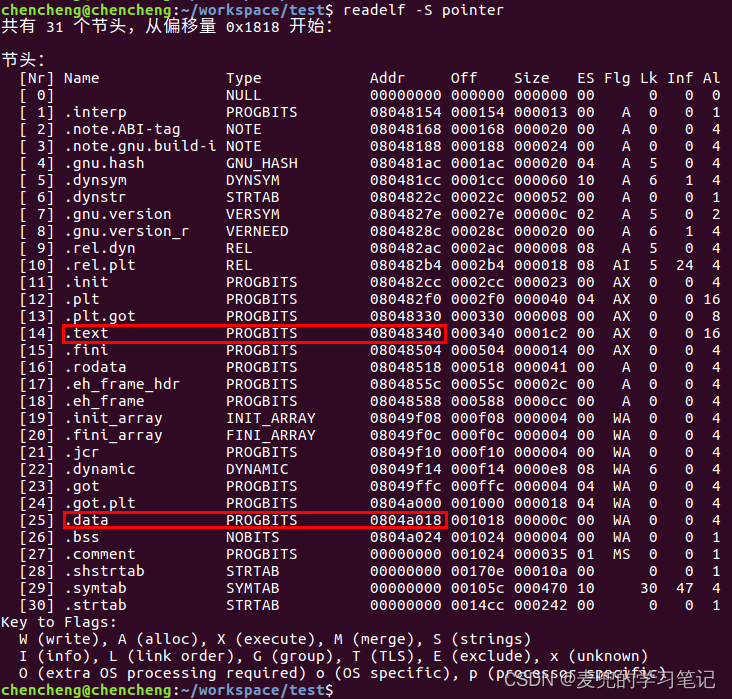
3. 使用readelf -l命令查看可执行程序加载到内存之后的Segment布局,与实验程序运行结果也是一致的
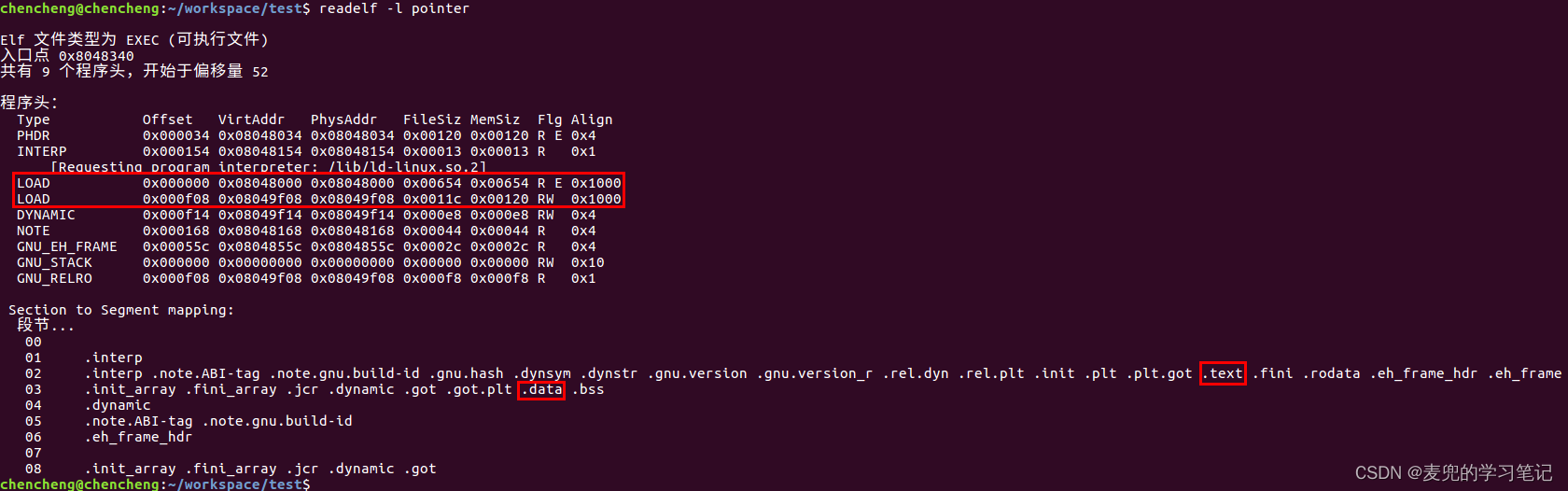
4. 将实验程序在后台运行,之后通过cat /proc/[pid]/maps命令查看进程各虚拟内存区的布局,与实验运行结果也是一致的

说明1:.rodata段存储的是什么?
根据上文分析,在目前的Linux操作系统中,字符串字面值也是存储在ELF文件的.text段中。那么ELF文件中的.rodata段中存储的是什么呢?
经过验证,.rodata段中存储的是被const关键字修饰的只读变量(经过验证,即使将变量a初始化为0,也会被存储在.rodata段,而不是.bss段)
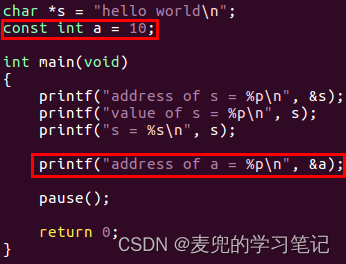
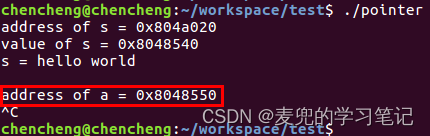

说明2:有了上面的结论,我们再反过来验证Linux 0.11内核如何存储被const关键字修饰的只读变量
可见在Linux 0.11内核中,被const关键字修饰的只读变量还是存储在代码段
![]()

7 进程操作内存相关补充
说明:有关进程操作相关函数流程的分析可参考Linux 0.11内核分析05:线程切换与调度 chapter 5,本章主要补充分析其中与内存管理相关的内容
7.1 进程创建
7.1.1 创建task_struct结构
调用get_free_page函数获取一页内存,既存储新建进程的task_struct结构体,也作为该进程的内核栈使用

7.1.2 拷贝父进程地址空间
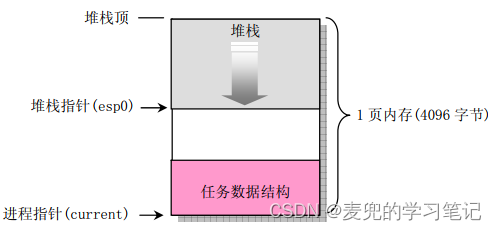
1. copy_mm函数用于拷贝父进程地址空间,如果拷贝过程中发生错误,则释放之前分配的一页内存,此次新建进程失败
2. 由于使用段页式内存管理机制,因此copy_mm函数中分别设置了新建进程的LDT表和页表

7.1.3 确立新建进程
最后通过在GDT中登记新建进程的TSS段和LDT段,确立新建进程
7.2 执行程序
7.2.1 execve系统调用概述
7.2.1.1 execve系统调用封装例程
| 所需头文件 |
#include <unistd.h> |
| 函数原型 |
int execve(const char *filename, char *const argv[], char *const envp[]); |
| 函数参数 |
filename:可执行文件路径 argv:命令行参数指针数组 envp:环境变量参数指针数组 |
| 函数返回值 |
成功不返回;失败返回-1 |
7.2.1.2 execve系统调用使用实例
1. 使用命令行参数的实验代码如下,在main函数中打印命令行参数个数及每个命令行参数

2. 将实验代码编译后直接运行,运行结果如下。可见在通过命令行直接运行时,可执行程序名会作为一个命令行参数传递给execve系统调用
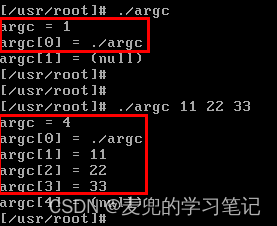
3. 在另一个实验程序中,通过execve系统调用执行上面的可执行程序,实验代码如下。在程序中通过argv指针数组组织命令行参数
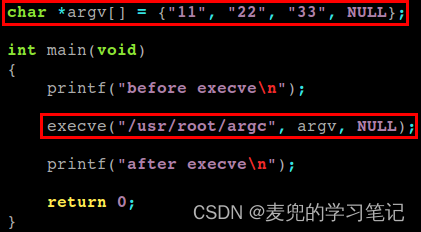
运行结果如下,可见此时命令行参数中并不包含可执行程序名。因此可以推测,在通过命令行直接运行可执行程序时,是shell程序将可执行程序名加入命令行参数
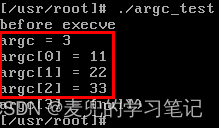
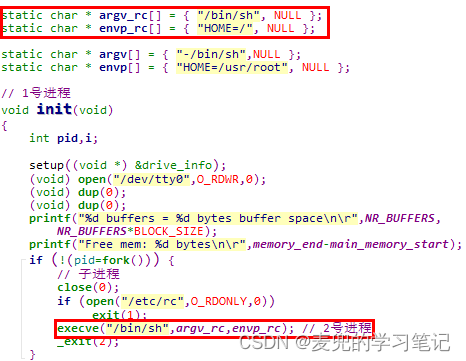
说明:Linux 0.11内核中execve系统调用使用实例
在init进程中,会调用execve系统调用启动shell程序
7.2.1.3 命令行参数的组织
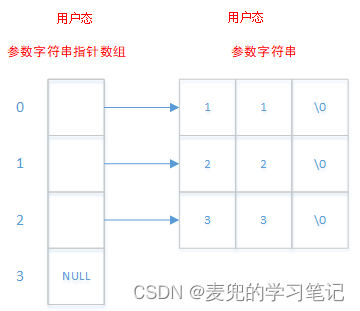
如上文的实验程序所示,命令行参数以字符串数组的方式组织,而且最后一个成员必须是NULL指针(至于这么做的原因,在分析完execve系统调用的实现后就一目了然了)
实验程序中的命令行参数,在内存中存储方式如下,

说明1:理解命令行参数组织的关键是理清字符串和字符串数组的关系
说明2:环境变量参数的组织和命令行参数相同,也是以NULL指针结尾的字符串数组
7.2.2 do_execve函数分析
do_execve函数是execve系统调用服务例程的主体,本节分析该函数中与内存管理相关的部分。do_execve函数原型如下,

7.2.2.1 计算命令行/环境变量参数个数
1. 通过count函数计算命令行 / 环境变量参数个数

2. count函数统计参数个数的逻辑,是遍历参数字符串指针数组,并以NULL指针为退出循环的条件。由于参数指针数组存储在进程用户态,因此在内核态需要通过get_fs_long函数读取

3. 根据count函数的实现逻辑,命令行 / 环境变量参数指针数组必须以NULL指针结尾,用于标识指针数组结束
7.2.2.2 拷贝命令行/环境变量参数
通过copy_strings函数拷贝命令行 / 环境变量参数,下面逐步展开说明
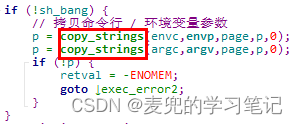
7.2.2.2.1 参数拷贝目标
参数拷贝的目标,是根据进程地址空间布局,将命令行 / 环境变量参数字符串拷贝到环境参数块,并且按照main函数所需参数构建栈帧
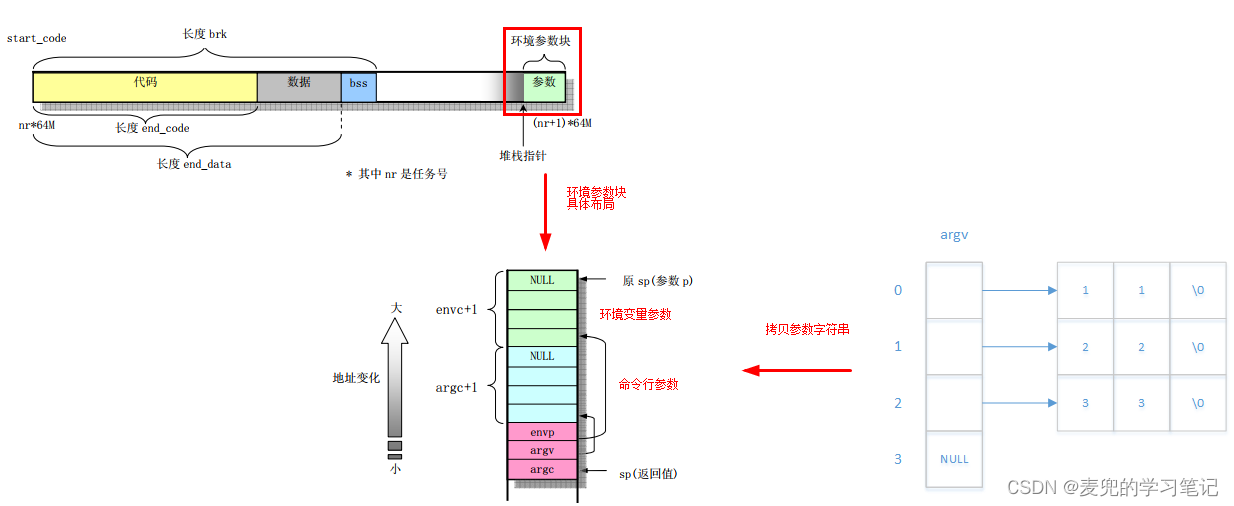
说明:拷贝什么?
① 此处是要将命令行 / 环境变量参数字符串本身拷贝到进程地址空间的环境参数块,而不只是拷贝指针
② 在将字符串本身拷贝到环境参数块之后,需要在环境参数块中创建字符串数组指向各个参数字符串
7.2.2.2.2 参数拷贝步骤概述
只有理解参数拷贝所需步骤,才能理解do_execve函数对命令行 / 环境变量参数的处理过程
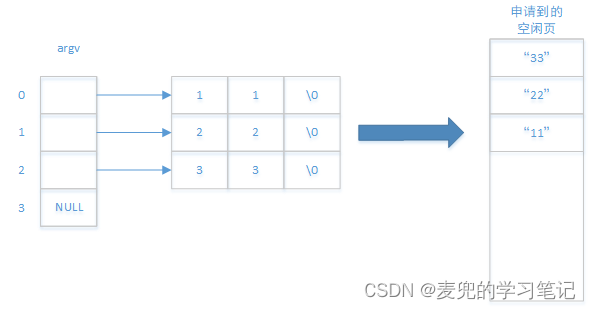
1. 拷贝参数字符串
内核首先申请空闲页,然后将命令行 / 环境变量参数字符串拷贝到申请的内存中
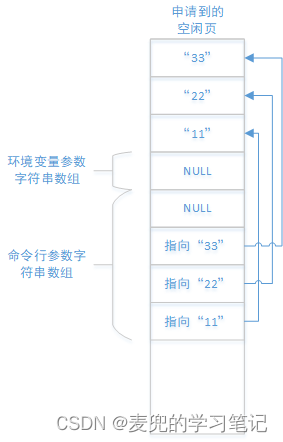
2. 构造参数字符串数组
上一步只是完成了参数字符串的拷贝,但是传递给main函数的是参数字符串数组,因此还需要构建参数字符串数组,且构建的字符串数组要以NULL结尾
3. 构造main函数参数
根据main函数的原型,构造main函数参数
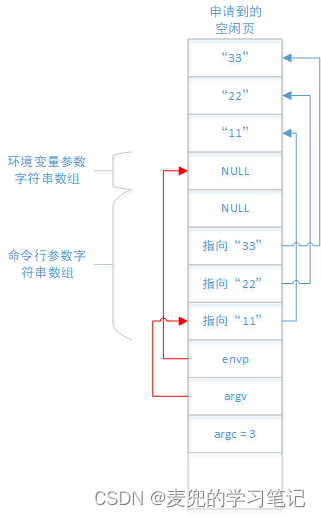
4. 与进程地址空间建立映射
上述拷贝操作在内核申请的空闲页上进行,最后将包含命令行 / 环境变量参数的内存页与进程地址空间建立映射,即可达到参数拷贝目标
说明:从汇编角度分析应用程序对命令行 / 环境变量参数的使用
① 实验代码和运行结果如下图所示,可见shell会向应用程序传递一系列命令行 / 环境变量参数


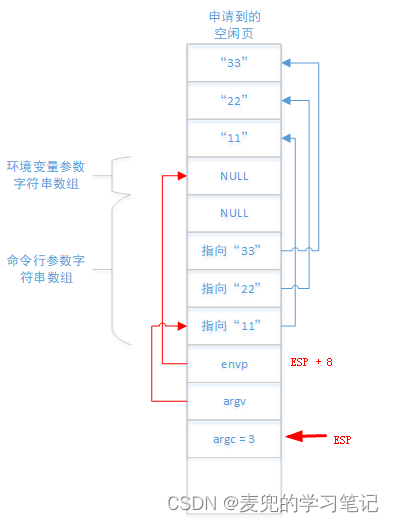
② 将环境变量参数字符串数组的地址写入environ变量,之后跳转到main函数执行


此时的进程用户栈布局如下图所示,
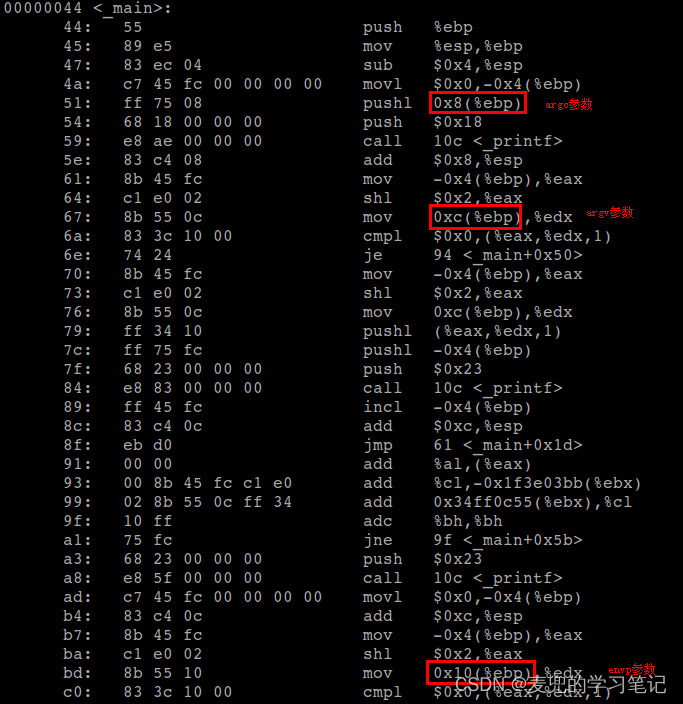
③ 在main函数中使用参数argc / argv / envp
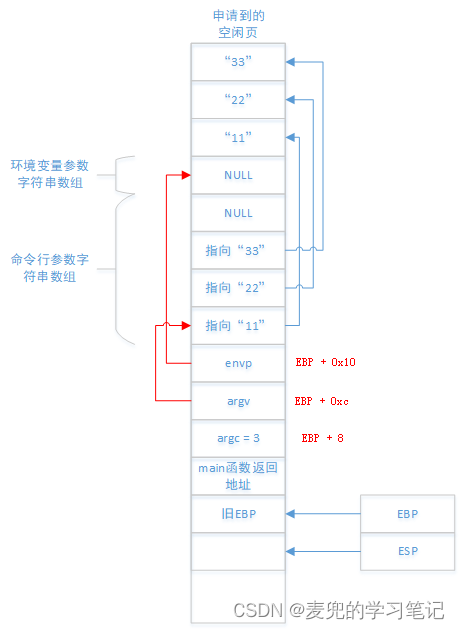
此时的进程用户栈布局如下图所示,
7.2.2.2.3 命令行/环境变量参数存储空间
1. do_execve函数中会根据拷贝命令行 / 环境变量参数所需,申请一组物理页,并通过page数组进行管理
page数组中的每个元素记录了一个分配的物理页的物理地址(也是内核态的线性地址和逻辑地址,因此内核态程序可以直接使用),而page数组元素的初始值为0,表示没有分配物理页

![]()
![]()
2. 由于page数组元素为32个,因此最多可以申请32个物理页(也就是128KB)存储命令行 / 环境变量参数,我们将这128KB称为参数环境空间
3. 为了在这128KB范围内进行索引,do_execve函数中定义了变量p,用于记录相对于参数环境空间末端的偏移量,同时也标识了当前参数环境空间中还剩余多少可用空间
4. do_execve函数中对变量p的维护
① 变量p的初始值为(4KB * 32 - 4),也就是该区域最后一个4B单元的起始地址
![]()
② 随着想参数环境空间拷贝参数字符串,变量p递减,始终用于记录偏移量

③ 在do_execve函数的最后阶段,会根据p变量中记录的偏移量计算出进程用户栈的逻辑地址

并使用该值替换当前内核栈中记录的用户栈指针值,从而实现用户栈的重建
![]()
说明1:参数环境空间中page数组和变量p的配合如下图所示
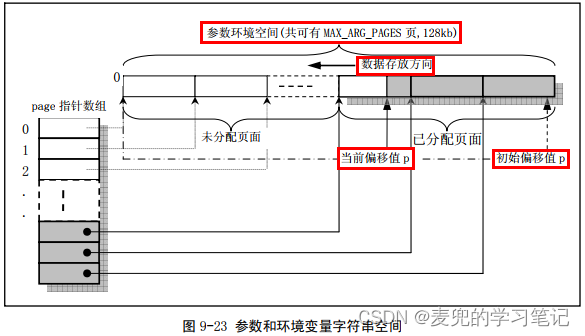
根据上图,有2个非常重要的计算关系,其中PAGE_SIZE = 4KB
① p / PAGE_SIZE = 当前偏移量p对应的page数组下标
② p % PAGE_SIZE = 当前偏移量p在当前页内的偏移量
从这里就可以看出为什么变量p的初值是(128KB - 4B),此时计算出的首个page数组下标为才是正确的31
说明2:在上述拷贝过程中,是直接将参数字符串拷贝到在内核态分配的物理页中,还没有与进程的线性地址空间建立映射关系。因此,最后还需要填充页表,将包含命令行 / 环境变量参数的物理页映射到进程线性地址空间中
7.2.2.2.4 copy_string函数分析
copy_string函数用于完成命令行 / 环境变量参数字符串的拷贝
7.2.2.2.4.1 函数原型分析
1. copy_strings的函数原型如下,

2. 下面是do_execve函数中的2处调用,先后拷贝环境变量参数和命令行参数

3. copy_string函数的其余参数比较好理解,下面重点说明from_kmem参数,该参数用于指定要拷贝的参数来源,具体值如下
| from_kmem参数值 |
拷贝参数来源 |
| 0 |
参数字符串来自用户态 参数字符串数组也来自用户态 |
| 1 |
参数字符串来自用户态 参数字符串数组来自内核态 |
| 2 |
参数字符串来自内核态 参数字符串数组也来自内核态 |
说明1:为什么需要区分参数来源?
对于不同的参数来源,需要使用不同的段选择子进行访问,
① 访问内核态数据时,需要使用内核数据段选择子
② 访问用户态数据时,需要使用用户数据段选择子
在内核态可以访问用户态的线性地址空间,并经过分页机制的转换实际访问物理内存
说明2:参数字符串和字符串数组均来自用户态
这是最常见的一种情况,用于拷贝应用程序调用execve函数时传递的命令行 / 环境变量参数
说明3:参数字符串来自用户态,参数字符串数组来自内核态
在do_execve函数中使用实例如下,此时文件名字符串来自用户态,但是filename是内核态的函数参数


说明4:参数字符串和字符串数组均来自内核态
在do_execve函数中使用实例如下,此时字符串存储在内核态的buf数组中,而指向字符串的变量i_arg & i_name也在内核态


说明5:没有参数字符串来自内核态,但参数字符串数组来自用户态的情况
7.2.2.2.4.2 函数流程分析
详细流程分析如下,其中核心要义就是,
1. 外层循环从字符串数组中读取字符串指针
2. 内存循环根据字符串指针拷贝字符串
3. 在读取字符串数组和读取字符串时,都使用get_fs_xxx系列函数,因此需要根据数据来源适时将fs指向内核数据段或用户数据段


说明:通过加载合适的fs段寄存器使得copy_string函数可以统一使用get_fs_xxx系列函数读取字符串数组和字符串,但是加载段寄存器开销较大,应只在必要时调用set_fs函数
7.2.2.3 释放进程原有页表

7.2.2.4 重新设置进程LDT表
1. 重新设置进程LDT表由change_ldt函数完成,调用方式如下,

2. change_ldt函数流程分析如下,
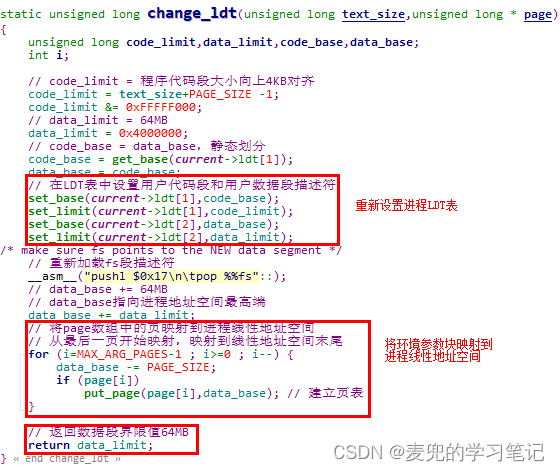
3. change_ldt函数会返回64MB,因此函数返回后p的值为(p + 64MB - 128KB),也就是将p从环境参数块内的偏移量换算为为64MB逻辑地址空间中的逻辑地址
说明1:进程LDT表的重置与内存保护
① 用户代码段的基地址为(nr * 64MB),段界限为向上4KB对齐的代码段大小
② 用户数据段的基地址为(nr * 64MB),段界限为64MB
③ 这种设置方法可以确保执行流只能在代码段范围内,超出该范围的跳转将会触发通用保护异常,这种内存保护是基于分段机制实现的
说明2:内存保护实验
① 为了验证上面的说法,我们执行如下测试程序,人为跳转到1MB处执行,该地址已经超过用户代码段
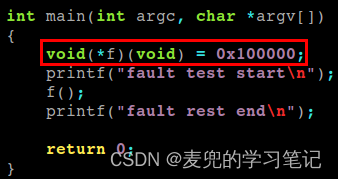
② 从程序执行结果可见,执行过程中会触发通用保护异常
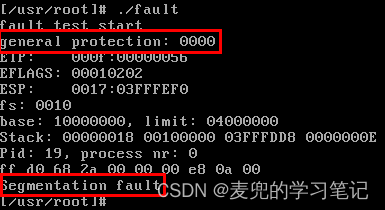
③ 从异常处理函数打印的信息分析,触发异常的指令位于[0x000f : 0x00000056]。对照可执行程序的反汇编结果,正是跳转到1MB处执行的call指令

7.2.2.5 构造main函数参数
1. 上述步骤只是将命令行 / 环境变量参数字符串拷贝到进程地址空间,但是还没有根据main函数原型构造main函数参数,该步骤由create_tables函数完成

2. create_tables函数流程分析如下,

7.2.2.6 设置进程地址空间布局
在do_execve函数的最后,设置了task_struct结构中描述进程地址空间的各个字段,这些字段将在后续的缺页异常处理过程中作为判断地址范围的标准

说明1:在设置完进程的地址空间布局后,将(a_text + a_data)之后一页内的剩余部分清零,在进程的线性地址空间中,这部分是BSS段所在区域
个人觉得这种清空BSS段的操作不是很严谨,应该按照BSS段的实际大小进行清空操作
说明2:需要注意的是,在整个do_execve函数的执行过程中,只读取了可执行文件开头的1KB(而且只是被读取到高速缓冲块,后续还被释放)。程序的代码段和数据段都没有读取到内存中,也没有填充页表建立映射
这些文件的读取操作都是由后续的缺页异常触发,例如在execve系统调用执行返回用户态时,会从程序入口点开始执行,也就是进程逻辑0地址处开始执行。此时一执行就会触发缺页异常,可执行程序的第1页将在缺页异常处理函数中被读取到内存并映射到进程的线性地址空间
7.3 进程终止
do_exit函数中与内存管理相关的操作,就是释放进程的页表

7.4 进程回收
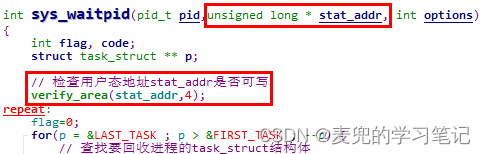
sys_waitpid函数在回收进程时,有2处操作与内存管理机制相关
7.4.1 对用户态地址stat_addr进行写验证
由于写入进程退出状态的地址stat_addr是进程用户态地址,因此需要在内核态对其进行写验证。需要注意的是,传递给sys_waitpid函数的stat_addr是进程的逻辑地址,而最终的检查需要将其转换为线性地址
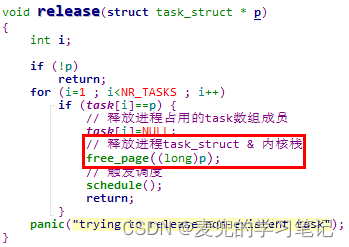
7.4.2 释放进程结构体
1. 释放进程结构体的操作由release函数完成,

2. release函数会释放进程拥有的最后资源,即task_struct结构体,至此一个进程的生命周期就结束了
8 实验1:观察地址转换过程
8.1 任务目标
使用Bochs调试工具跟踪Linux 0.11内核的地址转换过程,加深对段页式内存管理的理解
8.2 实验程序分析
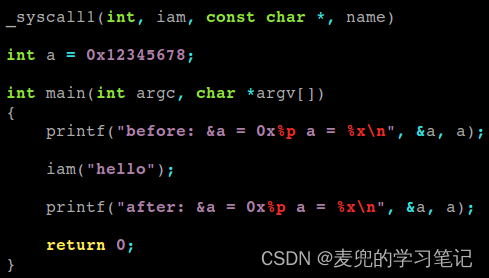
1. 第1次打印全局变量a的地址和值,用于获取变量的逻辑地址,实验中将跟踪该逻辑地址转换为线性地址和物理地址的过程
2. 调用iam系统调用是为了陷入断点,我们可以将断点设置为iam系统调用在内核态的服务例程,并在此位置跟踪地址转换过程
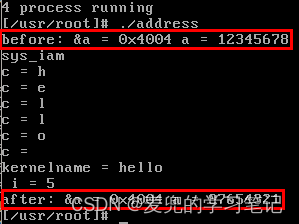
3. 在调试过程中我们会修改变量a对应的物理内存中的值,并且在实验程序中再次打印,以验证我们的分析是否正确
说明:关于iam系统调用可参考Linux 0.11内核分析03:系统调用 chapter 5
8.3 实验流程
8.3.1 陷入断点
1. 使用dbg-asm脚本启动bochs-dbg调试器
2. 确定iam系统调用服务例程线性地址
由于bochs调试器在设置断点时需要使用地址而不是函数名,因此我们通过编译内核后生成的符号表文件System.map获取iam系统调用服务例程的线性地址
![]()
3. 设置断点
使用lb(linear break)命令设置断点

4. 继续启动内核
使用c(continue)命令继续启动内核,由于启动过程中不会触发断点,因此系统可以启动完成
5. 陷入断点
在命令行运行实验程序,在打印出变量a的地址和值后陷入断点,在此基础上便可以进行调试
![]()

8.3.2 从逻辑地址到线性地址
8.3.2.1 调试思路
1. 逻辑地址经过分段机制转换为线性地址,因此需要找到当前进程的用户数据段描述符(其中包含段基址),而用户数据段描述符登记在LDT中
2. 而LDT段描述符登记在GDT中,并通过LDTR寄存器索引(LDTR寄存器值为LDT在GDT中的段选择子)
3. 在查询段表时,从GDT开始
8.3.2.2 调试过程
8.3.2.2.1 查询GDT获取LDT段描述符
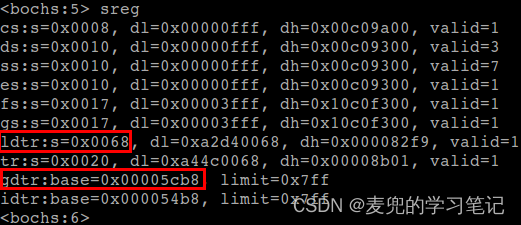
通过sreg命令获系统寄存器的值,其中,
① gdtr = 0x00005cb8
GDT表的线性基地址为0x00005cb8
② ldtr = 0x0068(0b01101 0 00)
当前进程的LDT段描述符在GDT中的索引为13(0b1101)
因此,(0x00005cb8 + 13 * 8)的线性地址处,存储的就是当前进程的LDT段描述符,

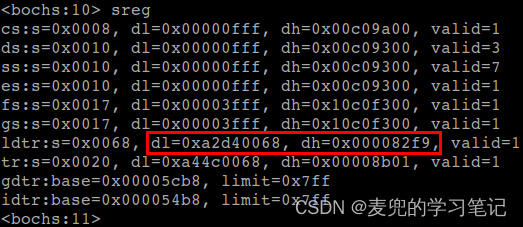
可见此处获取的LDT段描述符与LDTR寄存器高速缓存部分记录的值相同
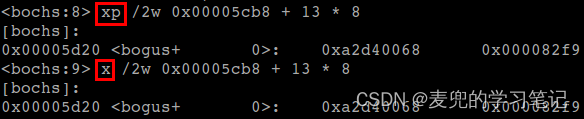
说明:此处打印内存值使用了xp(physical)命令,该指令用于打印物理地址的内容。由于当前系统中内核态的逻辑地址、线性地址和物理地址均为恒等映射,所以与使用x指令打印线性地址的内容相同
8.2.2.2.2 查询LDT获取用户数据段描述符
从LDT段描述符中可得,当前LDT段的线性基地址为0x00f9a2d4,可以使用xp命令从该地址读取LDT表

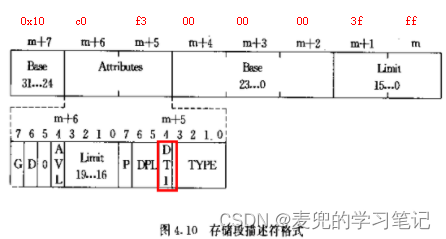
从用户数据段描述符中可得,用户数据段的线基地址为0x10000000,因此变量a的线性地址为(0x10000000 + 0x4004 = 0x10004004)
说明:线性地址正确性验证
① 可以使用x命令查看0x10004004线性地址的内容进行验证,可见分析得到的线性地址是正确的

② 此处用户数据段线性基地址为0x10000000,即256MB处。由于每个任务占用64MB线性地址空间,所以256MB对应4号任务(从0开始)。4号任务对应的用户数据段在GDT中的索引为(4 + 4 * 2 + 1 = 13),这和LDTR寄存器的值也是匹配的
8.3.3 从线性地址到物理地址
8.3.3.1 调试思路
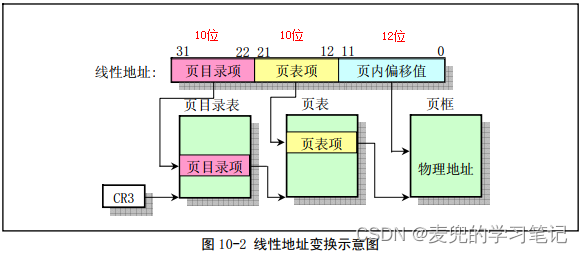
1. 线性地址经过分页机制转换为物理地址,因此需要查询页目录表和页表
2. 首先查找页目录表,找到对应的页目录项,从而得到页表的物理地址
3. 再查找页表,找到对应的页表项,从而得到页框的物理地址,再加上页内偏移即可得到变量a的物理地址
8.3.3.2 调试过程
8.3.3.2.1 获取页目录表物理基地址
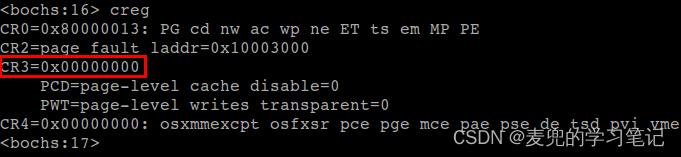
页目录表的物理基地址记录在CR3寄存器中,通过creg命令可以获取页目录表物理基地址为0x00000000
8.3.3.2.2 查询页目录表获取页表信息
由于变量a的线性地址为0x10004004,因此对应的页目录表索引为0x040(= 64)。使用xp命令可以读取对应页目录项的内容,可见该页目录项有效,且记录的页表物理地址为0x00fa9000

8.3.3.2.3 查询页表获取页框信息
由于变量a的线性地址为0x10004004,因此对应的页表索引为0x004。使用xp命令可以读取对应页表项的内容,可见该页表项有效,且记录的页框物理地址为0x00fa2000

结合线性地址中的页内偏移0x004,所以变量a的物理地址为0x00fa2004。可以使用xp命令读取该地址的内容,可见分析得到的物理地址是正确的

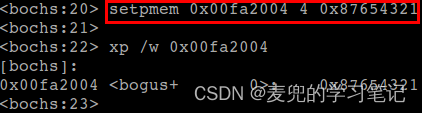
8.3.4 通过物理地址修改变量值验证
下面通过setpmem指令设置物理地址0x00fa2004处的内容,并继续运行实验程序,可见在实验程序中通过逻辑地址读取的变量值正确被修改