栈与队列:栈是限定仅在表尾进入插入和删除操作的线性表
队列是只允许在一端进行插入操作,而在另一端进行删除操作的线性表
1.1 栈的定义
1.1.1 栈的定义
栈就是类似于弹夹中的一样存储的方式,先进去的子弹要最后才可以出来,反而先进去的子弹则可以先出来这样的数据结构就被我们称作为——栈。
我们把允许插入和删除的一端称为栈顶,另一端被称为栈底,不含任何数据的元素的栈称为空栈,栈都是先进后出的线性表,简称为LIFO结构。
理解栈的定义需要注意:
首先它是一个线性表,也就是说栈元素是具有线性关系的,即前驱和后继的关系。只不过它是一种特殊的线性表,定义中说是在线性表的表尾进行插入和删除操作,这里表尾则是栈顶而不是栈底。
它的特殊之处就在于限制了这个线性表的插入和删除的位置,它始终只能在表尾进行相关操作,也就是使得栈底是固定的,最先进栈的只能在栈底。
栈的插入操作,叫作进栈,也称为压栈和入栈。类似于子弹进入弹夹。
栈的删除操作,叫做出栈,有的也叫做弹栈、如同子弹从弹夹中弹出到轨道之中。
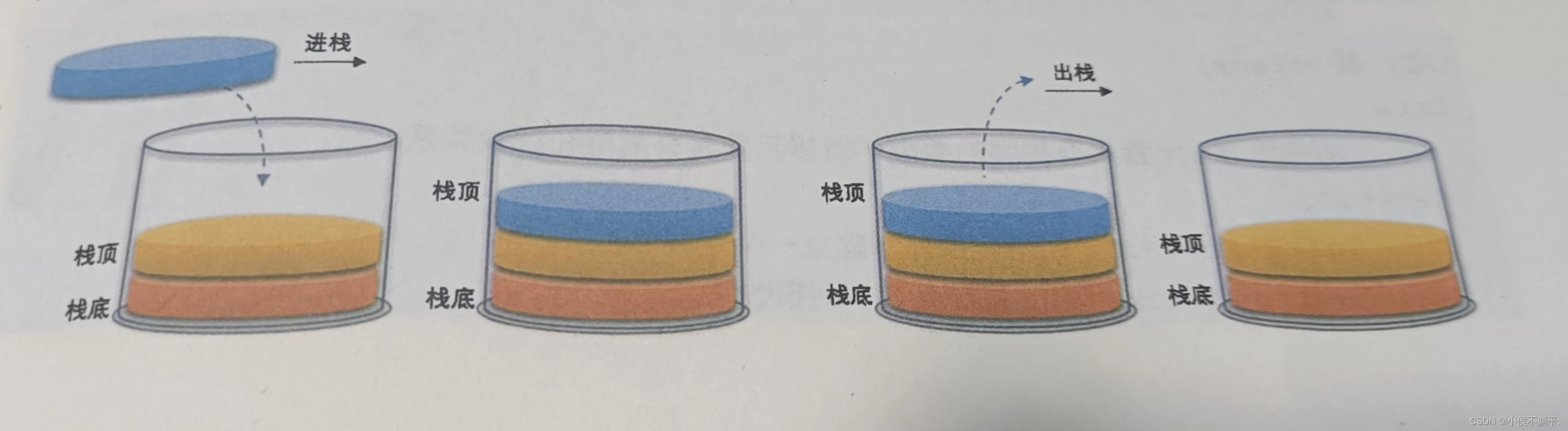
1.2 栈的顺序存储结构以及实现
1.2.1 栈的顺序存储结构
既然栈是线性表的特例,那么栈的顺序存储也就是线性表的顺序存储的一种特殊情况,我们简称为顺序栈,线性表的顺序存储是用数组来实现的,对于栈我们需要明确栈顶在数组的那一端。
我们经过对数组的一些了解,我们可以清楚的知道栈底放置在0的位置是操作最方便的。
栈的结构定义:
typedef struct
{
int data[100];
int top;
}Zhan; 如下图现在有一个栈,它的元素个数最多为5个,则栈的普通情况、空栈、满栈如下所示:
1.2.2 栈的顺序存储结构——进栈操作
对于进栈的操作,其实就是进行了下图的操作:
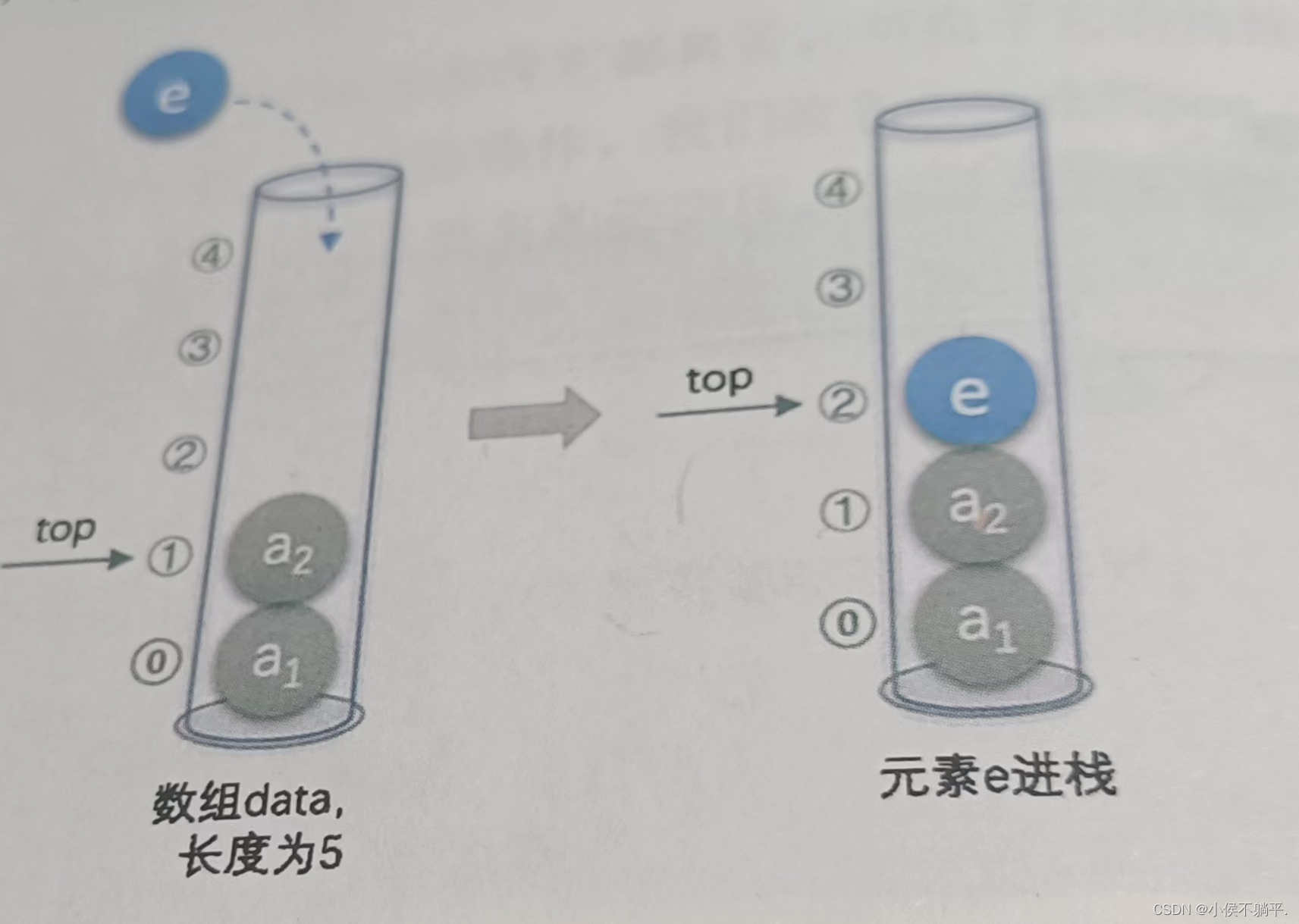
对于进栈的操作如下push函数,其代码如下:
void push(Zhan *s,int e)
{
if(s->top==5) //如果栈顶的索引超过了5则说明栈已经满了退出压栈
return ;
else
{
s->top++; //栈顶加一并且将数据存入元素的数组之中
s->data[s->top]=e;
return ;
}
}1.2.3 栈的顺序存储结构——出栈操作
出栈操作如下pop函数,代码如下:
void pop(Zhan *s,int *e)
{
if(s->top==-1) //如果索引小于0,则说明栈已经空了
return ;
else
*e=s->data[s->top]; //用一个指针存入退出栈的数据元素
s->top--; //栈顶减1方便后续操作
return ;
}1.2.4 栈的整体性应用
栈的简单的使用操作如下代码所示:
#include<iostream>
using namespace std;
typedef struct
{
int data[100];
int top;
}Zhan;
void push(Zhan *s,int e)
{
if(s->top==99)
return ;
else
{
s->top++;
s->data[s->top]=e;
return ;
}
}
void pop(Zhan *s,int *e)
{
if(s->top==-1)
return ;
else
*e=s->data[s->top];
s->top--;
return ;
}
int main()
{
int x,m;
Zhan s;
cout<<"请输入要进入栈的个数->";
cin>>m;
cout<<"请输入栈内的元素:"<<endl;
for(int i=0;i<m;i++)
{
cin>>x;
push(&s,x);
}
cout<<"请选择要退出栈元素的个数->";
cin>>m;
cout<<"退出栈的元素为:"<<endl;
for(int i=0;i<m;i++)
{
pop(&s,&x);
cout<<x<<"\t";
}
}运行之后的代码如下图所示:
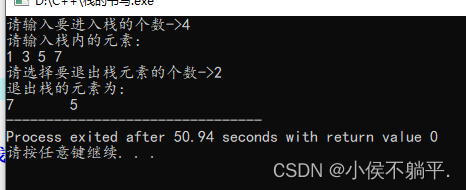
从中可以观察出先进栈的元素,会优先出栈。
1.3 两栈共享空间
其实栈的顺序存储还是很方便的,因为它只准栈顶进出元素,所以不存在线性表中在数组之间插入和删除是移动元素的问题,不过它有一个很大的缺陷,那就是必须在解决问题之前就定义这个栈的最大容纳量为多少,所以我们要尽量考虑周全。对于两个类型相同的栈我们可以做到最大限度的利用其事先开辟好的空间来进行操作。
其关键的思路就是:它们是在数组的两端,向中间靠拢。top1和top2是栈1和栈2的顶部指针,可以想象,只要它们两个指针不见面,两个栈就可以一直使用。
从这里也就可以分析出来,栈1为空时,就是top1等于-1是,而top2等于该数组的最大值时该栈2为空,那吗当top1+1=top2时该栈就会满。
两栈共享空间的结构的代码如下:
typedef struct
{
int data[40];
int top1;
int top2;
}Share;对于两栈共享空间的push方法,我们除了要将插入元素的值外,还需要明确该元素要插入的栈是栈1还是栈2。插入元素的代码如下所示:
void push(Share *s,int e,int Which) //Which是判断插入的栈是哪一个
{
if(s->top1+1==s->top2)
return ; //如果栈满的话则退出插入操作
if(Which==1)
{
s->top1++;
s->data[s->top1]=e;
}
if(Which==2)
{
s->top2--;
s->data[s->top2]=e;
}
}因为代码在开始的时候就已经判断了是否存在栈满的情况,所以后面top1+1或top2-1是不用担心溢出问题的。
对于两个栈共享空间的pop方法,参数就只是需要多一个判断退出栈的是哪一个栈即可
代码如下:
void pop(Share *s,int *e,int Which)
{
if(Which==1)
{
if(s->top1=-1)
{
cout<<"栈1已经为空了!"<<endl;
return ;
}
*e=s->data[s->top1--]; //存储退出栈元素的值
return ;
}
if(Which==2)
{
if(s->top2==40) //栈2已经空了
{
cout<<"栈2已经为空了!"<<endl;
}
*e=s->data[s->top2++];
return;
}
}事实上,使用这样的数据结构,通常都是当两个栈的空间需求有相反关系时,也就是一个栈增长时另一个栈在缩短的情况。就像买卖股票一样,你买入时,一定是有一个你不知道的人在做卖出操作。有人赚钱,就一定会有人赔钱。这样使用两栈共享空间存储的方式才有比较大的意义。
当两个栈的数据结构不同时,这种方法不仅不能更好的处理问题反而会使问题更加严重,所以我们在共享栈合并是我们需要关注两个的数据类型是否一样。
共享栈的总体代码如下所示:
#include<iostream>
using namespace std;
typedef struct
{
int data[40];
int top1;
int top2;
}Share;
void push(Share *s,int e,int Which)
{
if(s->top1+1==s->top2)
return ;
if(Which==1)
{
s->top1++;
s->data[s->top1]=e;
}
if(Which==2)
{
s->top2--;
s->data[s->top2]=e;
}
}
void pop(Share *s,int *e,int Which)
{
if(Which==1)
{
if(s->top1==-1)
{
cout<<"栈1已经为空了!"<<endl;
return ;
}
*e=s->data[s->top1--];
return ;
}
if(Which==2)
{
if(s->top2==40)
{
cout<<"栈2已经为空了!"<<endl;
}
*e=s->data[s->top2++];
return;
}
}
int main()
{
Share s;
s.top1=-1;
s.top2=40;
int x,m,Which;
cout<<"输入0时退出存入操作!"<<endl;
while(1)
{
cout<<"请输入想存入第几个栈->";
cin>>Which;
if(Which==0)
{
cout<<"欢迎下次使用存入操作!"<<endl;
break;
}
else if(Which!=0&&Which!=1&&Which!=2)
{
cout<<"存入的栈存在问题!"<<endl;
continue;
}
cout<<"请输入元素个数->";
cin>>m;
cout<<"请输入元素:"<<endl;
for(int i=0;i<m;i++)
{
cin>>x;
push(&s,x,Which);
}
}
cout<<endl;
cout<<"请输入想要栈退出的元素个数->";
cin>>m;
cout<<"请输入想从哪一个栈中取出->";
cin>>Which;
cout<<"退出栈的元素如下:"<<endl;
for(int j=0;j<m;j++)
{
pop(&s,&x,Which);
cout<<x<<"\t";
}
return 0;
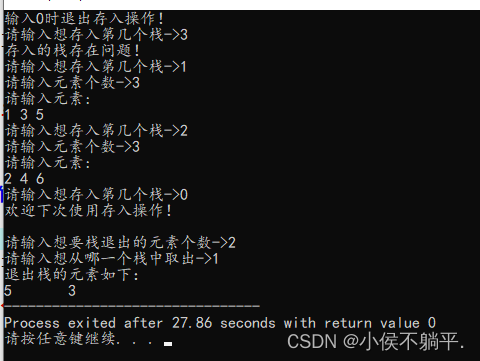
}运行的结果如下所示:
1.4 栈的练市存储结构以及实现
1.4.1 栈的链式存储结构
讲完了栈的顺序存储结构,我们现在来看看栈的链式存储结构,简称链栈。
我们在进入链栈相关学习之前,我们需要分清楚在链栈中将栈顶指针放在哪里更加方便,我们在链顶需要进行删除和插入的相关操作,如果只对于插入操作来说,放在头结点和尾结点都是可以的,但是对于删除操作来说如果将栈顶指针放在尾结点的话,我们每次的删除操作都需要进行遍历链表找到要删除结点的前驱结点才可以将其删除,所以根据上面所述我们将链栈的栈顶指针放置在头结点的位置。
链栈的结构代码如下:
typedef struct stack
{
int data;
struct stack *next;
}*LinkS,Stack;
typedef struct
{
LinkS top;
int count;
}LinkStack;大数的链栈操作和普通的链表操作一样只不过就是固定了插入和删除的位置而已
1.4.2 链式存储结构——进栈操作
对于push操作,假设元素值为e,top为栈顶指针,示意图如下所示:
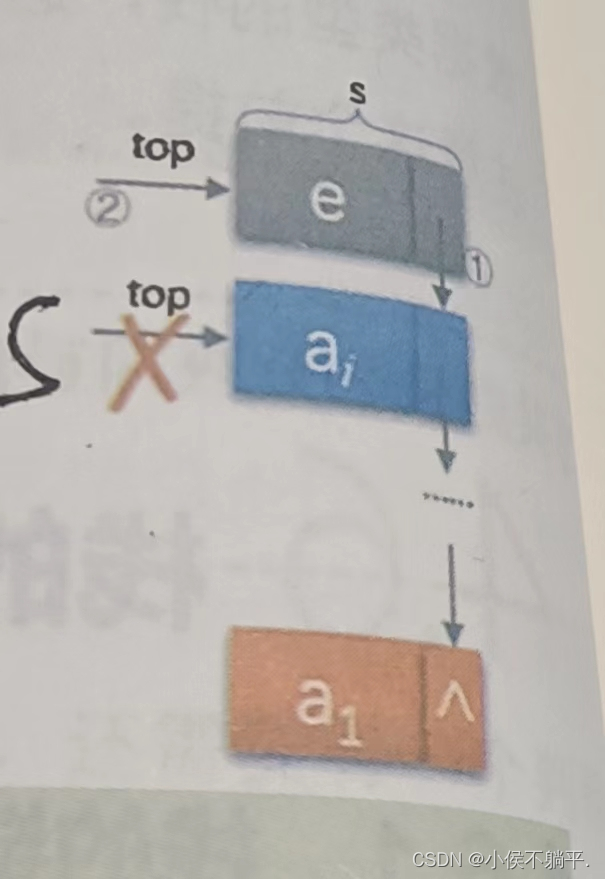
代码如下所示:
void push(LinkStack *S,int e)
{
LinkS a=(LinkS)malloc(sizeof(Stack));
a->data=e;
a->next=S->top; //把当前栈顶元素赋值给新节点的直接后继
S->top=a; //将新节点赋值给栈顶指针
S->count++;
return ;
}1.4.3 链式存储结构——出栈操作
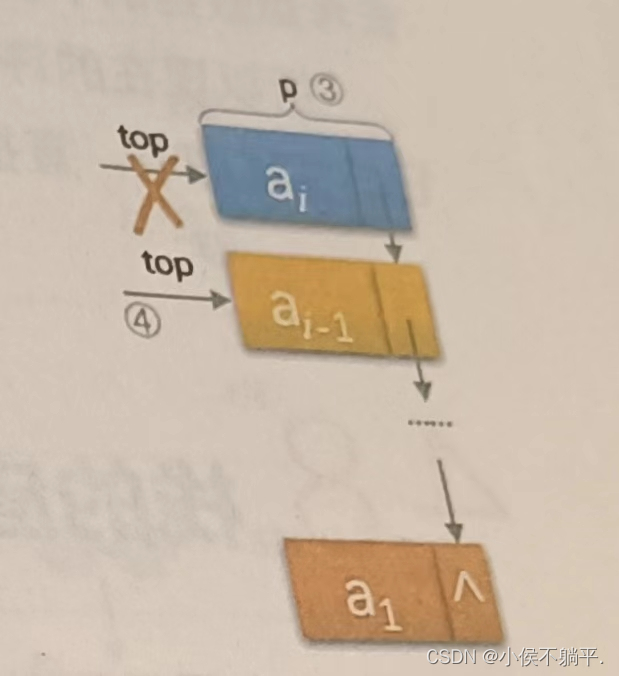
至于链栈的出栈操作与删除结点的操作相类似,先将要删除的结点保存,然后让栈顶指针指向下一个结点然后删除保存的结点即可,代码如下:
void pop(LinkStack *S,int *e)
{
LinkS p;
if(S->count==0)
return ;
*e=S->top->data;
p=S->top;
S->top=S->top->next;
free(p);
S->count--;
return ;
}链栈的进栈push和出栈pop操作都很简单,没有任何的循环操作,时间复杂度为O(1)。
对比一下顺序栈和链栈,他们在时间复杂度上是一样的,但对于空间性能来说,顺序栈需要实现确定一个固定的长度,可能会存在内存的空间浪费也可能会存在顺序栈溢出的问题,而链栈的长度是随用随变的。如果栈使用过程中元素变化不可预料,有时小,有时大,那么最好是用链栈,反之如果它的变化在可控范围内,建议使用顺序栈会更好一些。
1.4.4 链栈的操作
#include<iostream>
#include<stdlib.h>
using namespace std;
typedef struct stack
{
int data;
struct stack *next;
}*LinkS,Stack;
typedef struct
{
LinkS top;
int count;
}LinkStack;
void push(LinkStack *S,int e)
{
LinkS a=(LinkS)malloc(sizeof(Stack));
a->data=e;
a->next=S->top;
S->top=a;
S->count++;
return ;
}
void pop(LinkStack *S,int *e)
{
LinkS p;
if(S->count==0)
return ;
*e=S->top->data;
p=S->top;
S->top=S->top->next;
free(p);
S->count--;
return ;
}
int main()
{
LinkStack S;
int n,x;
cout<<"请输入要存储的元素个数->";
cin>>n;
cout<<"请输入各元素:"<<endl;
for(int i=0;i<n;i++)
{
cin>>x;
push(&S,x);
}
cout<<endl;
cout<<"请输入要出栈的个数->";
cin>>n;
cout<<"出栈的元素如下:"<<endl;
for(int i=0;i<n;i++)
{
pop(&S,&x);
cout<<x<<"\t";
}
return 0;
}运行程序后的代码如下所示:
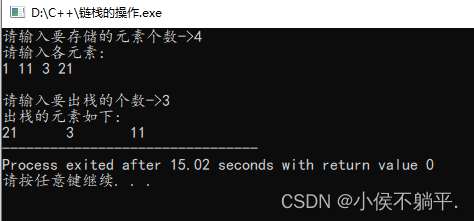
2.1 队列的定义
你们在使用电脑中也会经历过机器有时会处于疑似死机的状态,鼠标点什么地方都没有任何反应,双击任何快捷键都不动弹。就当你失去内心时,机器突然对你刚的所有操作都执行了一遍。这是因为操作系统在当时可能CPU没有忙过来。
操作系统中应用了一种数据结构来实现上述所说的问题也就是先进先出的功能,这就是队列。
队列是一种先进先出的线性表简称FIFO。允许插入的操作为队尾,允许删除的操作为队头。
就类似于最近几年的做核酸排队的操作,你在入队时是从队尾排队做核酸,做完之后是从队伍的头部做完后退出队伍。
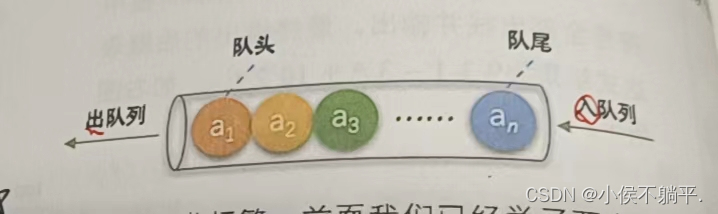
队列在程序中使用到的特别频繁。
2.2 循环队列
队列是一种特殊的线性表,同时也存在两种存储方式。也就是顺序存储和链式存储。
我们首先看顺序存储的操作。
队列的顺序存储会出现很多问题,比如前一个人出去之后,队尾的数组即不能再转到前面继续在对出去的元素处进行存储,也就是因此我们实现了一种可以循环利用空间的队列也就是循环队列,可以利用已经出队列的空间继续保存入队列的元素。
2.2.1 循环队列的定义
我们把队列的这种头尾相接的顺序存储结构称为循环队列。
下列的图片便是一些循环队列的存储图:

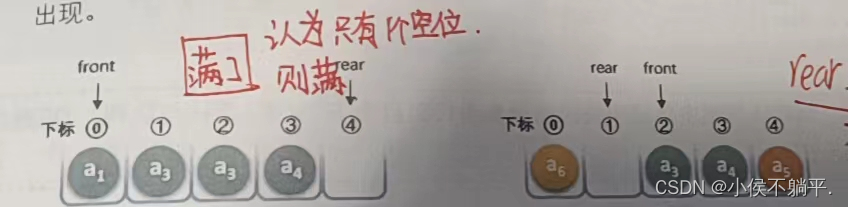
我们可以从中看出队列满的条件就是(rear+1)%MAX=front即尾指针可能和头指针差一圈也可能知识差一个数而已。
计算队列长度的公式为:(rear-front+MAX)%MAX
循环队列的顺序存储代码如下:
typedef struct
{
int data[MAX];
int front;
int rear;
};循环队列的初始化代码如下(初始化在链表和队列中是必须的)
int create(Duilie *s)
{
s->front=0;
s->rear=0;
return 0;
}循环队列求队列长度代码如下所示:
int getlength(Duilie *s)
{
return (s->rear-s->front+MAX)%MAX;
}循环队列入队的操作如下:
int push(Duilie *s,int e)
{
if((s->rear+1)%MAX==s->front)
return 0;
s->data[s->rear]=e;
s->rear=(s->rear+1)%MAX;
return 0;
}循环队列出队的操作如下:
int pop(Duilie *s,int *e)
{
if(s->front==s->rear)
return 0;
*e=s->data[s->front];
s->front=(s->front+1)%MAX;
return 0;
}从这段讲解大家可以发现,但是顺序存储,若不是循环队列,算法的时间性能是不高的,但循环队列又面临着数组可能会溢出的问题,如果我们要不担心长度问题则可以采取链式存储队列。
下面是循环队列的整体性的代码:
#include<iostream>
using namespace std;
#define MAX 10
class Duilie
{
public:
int data[MAX];
int rear;
int front;
public:
int create(Duilie *s)
{
s->front=0;
s->rear=0;
return 0;
}
int getlength(Duilie *s)
{
return (s->rear-s->front+MAX)%MAX;
}
int push(Duilie *s,int e)
{
if((s->rear+1)%MAX==s->front)
return 0;
s->data[s->rear]=e;
s->rear=(s->rear+1)%MAX;
return 0;
}
int pop(Duilie *s,int *e)
{
if(s->front==s->rear)
return 0;
*e=s->data[s->front];
s->front=(s->front+1)%MAX;
return 0;
}
};
int main()
{
Duilie s;
int x,n,i;
s.create(&s);
cout<<"退出时请在插入元素输入0"<<endl;
while(1)
{
cout<<"请输入队列中要插入元素的个数->";
cin>>n;
if(n==0)
{
cout<<"欢迎下次使用!"<<endl;
break;
}
cout<<"请输入队列中插入的元素:"<<endl;
for(i=0;i<n;i++)
{
cin>>x;
s.push(&s,x);
}
cout<<"请输入队列要退出的元素个数->";
cin>>n;
cout<<"退出队列的元素如下所示:"<<endl;
for(i=0;i<n;i++)
{
s.pop(&s,&x);
cout<<x<<"\t";
}
cout<<endl;
cout<<"队列元素个数:"<<endl;
n=s.getlength(&s);
cout<<n<<endl;
}
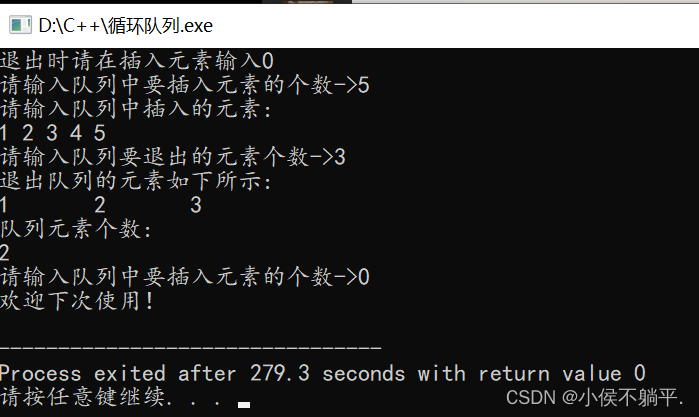
}运行程序之后的结果如下所示:
 2.3队列的链式存储结构以及实现
2.3队列的链式存储结构以及实现
队列的链式存储结构,其实就是线性表的单链表,只不过它只能尾进头出,如果是头进尾出的话在尾出时则会增加一些不必要的操作,即遍历单链表找到前驱结点。

链队列的结构如下:
typedef struct QNode
{
int data;
struct QNode *next;
}QNode,*QueuePtr;
typedef struct S
{
QueuePtr front,rear;
}LinkQueue; 特别注意如果要是用链队列时需要对链队列进行初始化操作,否则在运行程序时,存储的操作会出现问题(本人亲身经历)。
初始化操作如下:
void initQueue(LinkQueue *Q)
{
Q->front=Q->rear=new QNode;
Q->front->next=NULL;
}2.3.1 队列链式存储结构——入队操作
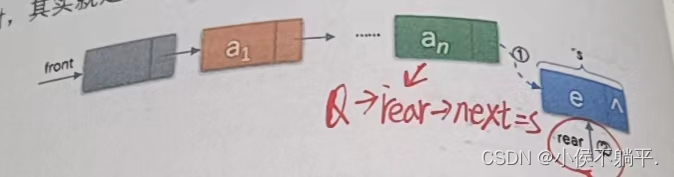
入队操作时其实就是在链表尾部插入结点,如下图所示;
其代码如下:
void pushdui(LinkQueue *Q,int e)
{
QueuePtr s=(QueuePtr)malloc(sizeof(QNode));
s->data=e;
s->next=NULL;
Q->rear->next=s; //把拥有元素的新节点存储在链表的尾部即(1)操作
Q->rear=s; //把当前的s设置为队尾的结点,rear指向s即(2)操作
}2.3.2 队列的链式存储结构——出队操作
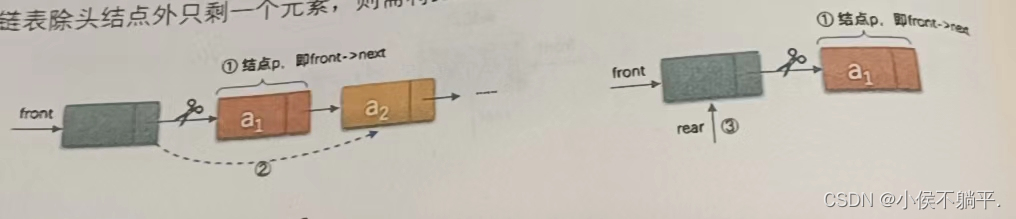
出队操作时,就是头结点的后继结点出队,将头节点后移一个结点即可。
代码如下:
void popdui(LinkQueue *Q,int *e)
{
QueuePtr p;
if(Q->front==Q->rear) //如果队列是空则退出函数
return ;
p=Q->front->next; //将要删除的元素进行存储
*e=p->data;
Q->front->next=p->next; //将头指针指向删除元素的后一个元素
if(Q->rear==p) //如果删除元素即是最后一个元素则头指针和尾指针指向同一个位置
Q->rear=Q->front;
free(p);
return ;
}对于循环队列与链队列的比较,可以从两方面来考虑,从时间上,其实他们的基本操作都是常数时间,不过循环队列是需要事先申请好空间,试用期间不可对空间进行调整会产生一些空间上的浪费。但对于链队列则不存在这个问题,在空间上的开销也就多了一个指针,但是链队列相对于循环队列来说要灵活的多。
总的来说,在可以确定队列长度的最大值的情况下,建议使用循环队列,如果你无法预料队列的长度,则使用链队列。
链队列的整体性代码如下所示:
#include<iostream>
#include<stdlib.h>
using namespace std;
typedef struct QNode
{
int data;
struct QNode *next;
}QNode,*QueuePtr;
typedef struct S
{
QueuePtr front,rear;
}LinkQueue;
void initQueue(LinkQueue *Q)
{
Q->front=Q->rear=new QNode;
Q->front->next=NULL;
}
void pushdui(LinkQueue *Q,int e)
{
QueuePtr s=(QueuePtr)malloc(sizeof(QNode));
s->data=e;
s->next=NULL;
Q->rear->next=s;
Q->rear=s;
}
void popdui(LinkQueue *Q,int *e)
{
QueuePtr p;
if(Q->front==Q->rear)
return ;
p=Q->front->next;
*e=p->data;
Q->front->next=p->next;
if(Q->rear==p)
Q->rear=Q->front;
free(p);
return ;
}
int main()
{
int m,n,x;
LinkQueue Q;
initQueue(&Q);
cout<<"请输入元素的个数->";
cin>>n;
cout<<"请输入元素:"<<endl;
for(int i=0;i<n;i++)
{
cin>>x;
pushdui(&Q,x);
}
cout<<"请输入要退出链队列的个数:"<<endl;
cin>>m;
cout<<"退出链队列的元素为:"<<endl;
for(int i=0;i<m;i++)
{
popdui(&Q,&x);
cout<<x<<"\t";
}
cout<<endl;
}运行程序以后的结果如下:
距离本人系统性讲解一个东西已经很久了,本人也已经山西古尔了所以以后会根据个人情况和学习进度来进行更新内容,大家也可以留言自己不会的内容给我,我看到也会出一篇系统讲解。