简介
语言模型(language model LM)也称为统计语言模型,而且是描述自然语言概率分布的一个模型,利用LM可以做到给定上文的条件下去对未来可能出现的词语进行概率分布的估计。有时候这种预训练模型被称为预训练的语言模型。
语言模型的基本任务是在给定词序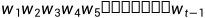 (也被称为
(也被称为 的历史)的前提条件下去去判断下一个时刻t可能出现单词的条件概率进行估计。例子如下,前面1:t-1的单词是“我 喜欢”,第t个单词是“读书”的概率可以通过极大似然估计(MLE)的方法去计算,例子如图所示。
的历史)的前提条件下去去判断下一个时刻t可能出现单词的条件概率进行估计。例子如下,前面1:t-1的单词是“我 喜欢”,第t个单词是“读书”的概率可以通过极大似然估计(MLE)的方法去计算,例子如图所示。
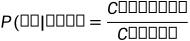
备注:C(读书)为相对应语料在语料库出现的次数(频次)
备注:这里对极大似然估计做一个简单的介绍:利用已知的样本数据去反推最大可能的模型参数值。
N元语言模型
介绍
根据上述出现的条件概率,可以进一步计算一个句子出现的概率,即为相对应单词的联合概率P(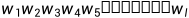 )(即为连乘),而且句子长度为l。而且通过链式法则(类似于导数求导的链式法则)分解为连乘公式。公式如下。
)(即为连乘),而且句子长度为l。而且通过链式法则(类似于导数求导的链式法则)分解为连乘公式。公式如下。
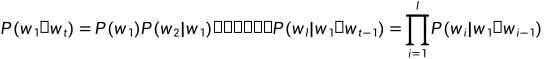
因为句子的长度可能增加,所以导致了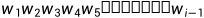 出现的次数会越来越少,甚至为0、这样导致了计算得出来的结果无意义。
出现的次数会越来越少,甚至为0、这样导致了计算得出来的结果无意义。
紧接着我们提出了马尔可夫假设(Markov Assumption)——下一个单词出现的概率只依赖于他前面的n-1个词语。这也就是N元语言模型的N,满足这种假设的模型成为N元语法或者是N元文法(N-gram)模型。

n=1,为unigram模型(下一次词语的出现跟前面单词无关,也可以理解与语序无关)
n=2,为bigram模型。(下一次词语的出现跟前面的一个单词有关)也称为一阶马尔可夫链。
n=3,为trigram模型。
备注:n值越大,考虑前面词语多,考虑的语义也就越多。
备注:为了使得前面i=1的时候P( |
|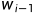 )有效,所以在句首的时候设置一个<BOS>(Begin of Sentence),在句末设置一个<EOS>(End of Sentence),即为
)有效,所以在句首的时候设置一个<BOS>(Begin of Sentence),在句末设置一个<EOS>(End of Sentence),即为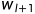 =<EOS>。
=<EOS>。
缺点
马尔可夫假设降低了句子概率出现0的可能性,但是如果出现了词语未在语料库里面出现或者n超级大的情况,仍然可能出现概率为0的情况。
数据稀疏性导致了训练数据很难覆盖到所有的N-gram,但是不代表N-gram出现概率一定没有0。(这一句有点不是很明白)
N-gram模型代码
可视化流程结构如图所示。(这里用了改进的hiddenlayer)可以显示实际的hiddenlayer输入的大小等,具体方法参考以下博客解决 HiddenLayer 可视化不显示神经网络数据流维度大小

这里主要参考了博主的代码,也是一个练手项目,此外我还多补充了用hiddenlayer可视化网络结构。
参考:https://blog.csdn.net/yqy2001/article/details/104642101
我会将此代码放入到github上供大家参考和修改。而且下文的N-gram模型是有一个给定的公式计算,所以并没有太多的神经网络层。
import numpy as np #引入numpy库
import torch #引入torch
import torch.nn as nn #torch.nn是torch的神经网络库
import torch.optim as optim #torch.optim是优化库,包含很多优化函数
from torch.autograd import Variable #现在的pytorch版本variable已经回归tensor了,直接用tensor即可
dtype = torch.FloatTensor
sentences = [ "i like dog", "i love coffee", "i hate milk"] #训练集
word_list = " ".join(sentences).split() #先用" ".join(),以空格为分隔,将sentences中的句子连接起来,再用split()以空格为分割点,将每个词分出来
word_list = list(set(word_list)) #先用set合并重复的单词,再用list创建单词列表
word_dict = {w: i for i, w in enumerate(word_list)} #单词转换为序号
number_dict = {i: w for i, w in enumerate(word_list)} #序号转换为单词
n_class = len(word_dict) # number of Vocabulary
# NNLM Parameter
n_step = 2 # n-1 in paper #步长,即根据多少个词来预测下一个词,这里是根据前两个词预测第三个词
n_hidden = 2 # h in paper #隐藏层神经元个数
m = 2 # m in paper #词向量维度
def make_batch(sentences): #作用是将训练集中的句子的最后一个词和前面的词分开
input_batch = [] #空列表,用来存放输入
target_batch = [] #存放一次输入对应的输出
for sen in sentences: #对于训练集中的每个句子
word = sen.split() #先将句子中每个单词按空格分开
input = [word_dict[n] for n in word[:-1]] #[:-1]切片,即输入是一直到最后一个词,最后一个词不要
target = word_dict[word[-1]] #target是最后一个词
input_batch.append(input) #将分离出来的input添加到输入列表
target_batch.append(target) #将分离出来的target添加到标记列表
return input_batch, target_batch #返回输入和标记列表
# Model
class NNLM(nn.Module):
def __init__(self):
super(NNLM, self).__init__()
#文章中计算式为y = b + Wx + U * tanh(d + Hx),这里设置各个参数
self.C = nn.Embedding(n_class, m) #C是词向量矩阵,行数是单词的数量,列数是词向量的维度
#H是输入层到隐层的权重矩阵,维数是(输入的个数 * 隐层单元个数),输入的个数是(输入的单词个数 * 词向量维数),即n_step * m
self.H = nn.Parameter(torch.randn(n_step * m, n_hidden).type(dtype))
#W是一个直连输入层和输出层的权重矩阵,维数是(输入的个数 * 输出层单元个数)
self.W = nn.Parameter(torch.randn(n_step * m, n_class).type(dtype))
#d是输入层到隐层的偏置常数,维数是(n_hidden * 1)
self.d = nn.Parameter(torch.randn(n_hidden).type(dtype))
#U是隐层到输出层的权重矩阵,维数是(隐层单元个数 * 输出层单元个数),要输出词典中每一个单词是下一个词的概率,输出的个数应该是单词的个数
self.U = nn.Parameter(torch.randn(n_hidden, n_class).type(dtype))
#b是隐层到输出层的偏置常数,维数是(输出层单元个数 * 1)
self.b = nn.Parameter(torch.randn(n_class).type(dtype))
def forward(self, X): #前向传播,计算公式y = b + Wx + U * tanh(d + Hx)
X = self.C(X) #输入的X是单词的序号,序号X对应的词向量是词向量矩阵C的第X行,取出此词向量
X = X.view(-1, n_step * m) #reshape矩阵X
tanh = torch.tanh(self.d + torch.mm(X, self.H)) #torch.mm是矩阵相乘
output = self.b + torch.mm(X, self.W) + torch.mm(tanh, self.U) #根据上述公式计算输出
return output
model = NNLM()
criterion = nn.CrossEntropyLoss() #损失函数为交叉熵损失函数
optimizer = optim.Adam(model.parameters(), lr=0.001) #使用Adam算法进行优化
input_batch, target_batch = make_batch(sentences) #使用make_batch从训练集中获得输入和对应的标记
input_batch = Variable(torch.LongTensor(input_batch)) #这两行是将输入变成variable,但现在的torch版本直接用tensor即可
target_batch = Variable(torch.LongTensor(target_batch))
# Training
for epoch in range(5000): #训练5000次
optimizer.zero_grad() #每次训练前清除梯度缓存
output = model(input_batch) #对模型输入input_batch,获得输出output
# output : [batch_size, n_class], target_batch : [batch_size] (LongTensor, not one-hot)
loss = criterion(output, target_batch) #使用损失函数计算loss,损失函数的输入为模型的输出output和标记target
if (epoch + 1)%1000 == 0: #每优化1000次打印一次查看cost的变化
print('Epoch:', '%04d' % (epoch + 1), 'cost =', '{:.6f}'.format(loss))
loss.backward() #反向传播、自动求导
optimizer.step() #优化、更新参数
# Predict
predict = model(input_batch).data.max(1, keepdim=True)[1] #用.max[1]挑出输出中最大的那一个
# Test
print([sen.split()[:2] for sen in sentences], '->', [number_dict[n.item()] for n in predict.squeeze()])hiddenlayer可视化代码
可视化的时候遇见的错误
RuntimeError: Expected tensor for argument #1 'indices' to have one of the following scalar types: Long, Int; but got torch.FloatTensor instead (while checking arguments for embedding)
pytorch出现IndexError: index out of range in self
解决办法
将输入改为原来我们写成的input_batch即可,是输入的时候embedding出现问题。
# 用hiddenlayer可以较好显示结构图
import hiddenlayer as hl
# x = torch.randn(3, 2).requires_grad_(True) # torch.Size([3, 2])
x = input_batch
y = NNLM()
hl_gragh = hl.build_graph(y, x)
hl_gragh.theme = hl.graph.THEMES['blue'].copy()
hl_gragh.save(path='example_n_gram_model.png', format='png')平滑(折扣法)
折扣法本质上就是从出现次数较多的N-gram里面分配一部分给N-gram里面概率较低的一部分,从而使得整体的分布较为均匀。(这里其实有点蒙,怎么分配是个问题)
这里主要涉及的是加1平滑(Add-one-Discounting)是一种折扣法,而且被称为拉普拉斯平滑(Laplace Smoothing),内容为假设所有的N-gram的频次比时间出现的平次多一次。
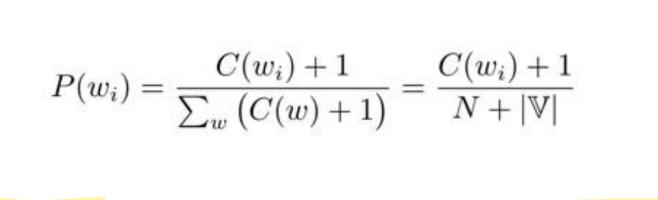
unigram模型加1平滑
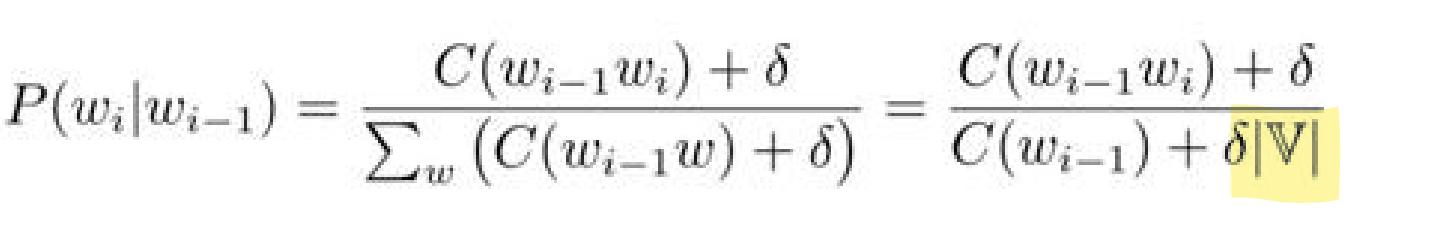
bigram模型加1平滑

bigram模型下的加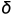 平滑
平滑
备注: 为词表大小,未登录词(未出现在词表上的词语)用<UNK>或者是一个区别其他词汇的词语标记。
为词表大小,未登录词(未出现在词表上的词语)用<UNK>或者是一个区别其他词汇的词语标记。
而且在实际应用中,跟多运用的是加平滑,内容为假设所有的时间的频次比时机出现的频次多次数,而且 。而且根据下文所提及的训练集的困惑度去解决的取值,而且将最好的应用于模型上。
。而且根据下文所提及的训练集的困惑度去解决的取值,而且将最好的应用于模型上。
缺点
引入了马尔卡夫假设,导致无法解决长度超过N的依赖关系
N过大,会导致数据稀疏性,而且会增加模型的参数,给存储和计算带来较大的挑战。
语言模型评价指标
目前用的比较多的是基于模型的困惑度(Perplexity PPL)的内部评价的方式。
定义
困惑度的定义:困惑度为给模型分配给测试集中每一个词的概率的几何平均值的倒数,而且PPL越小,证明模型能够更好地解释测试集合的数据。
备注:但是在具体运用于下游任务的时候,仍需要根据具体任务寻找其他指标进行判断模型好坏。我们一般运用的比较多的是下面的转化为对数和的形式,目的是防止概率连乘导致的浮点数下溢的问题。公式如下。
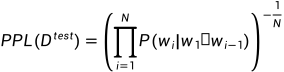
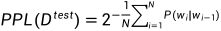
做法
将数据划分为不相交的集合,成为训练集
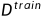 和测试集
和测试集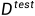 ,用于训练,优化模型的参数,该模型的计算得出来的测试集的概率P()反映了该模型的泛化能力。
,用于训练,优化模型的参数,该模型的计算得出来的测试集的概率P()反映了该模型的泛化能力。
在测试集合中,在每个开始和结束分布加上<BOS>和<EOS>的标注。