源自:自动化学报 作者:王龙, 黄锋
摘 要
近年来, 人工智能(Artificial intelligence, AI)技术在棋牌游戏、计算机视觉、自然语言处理和蛋白质结构解析与预测等研究领域取得了众多突破性进展, 传统学科之间的固有壁垒正在被逐步打破, 多学科深度交叉融合的态势变得越发明显. 作为现代智能科学的三个重要组成部分, 博弈论、多智能体学习与控制论自诞生之初就逐渐展现出一种“你中有我, 我中有你” 的关联关系. 特别地, 近年来在AI技术的促进作用下, 这三者间的交叉研究成果正呈现出一种井喷式增长的态势. 为及时反映这一学术动态和趋势, 本文对这三者的异同、联系以及最新的研究进展进行了系统梳理. 首先, 介绍了作为纽带连接这三者的四种基本博弈形式, 进而论述了对应于这四种基本博弈形式的多智能体学习方法; 然后, 按照不同的专题, 梳理了这三者交叉研究的最新进展; 最后, 对这一新兴交叉研究领域进行了总结与展望.
关键词
博弈论 多智能体学习 控制论 强化学习 人工智能
近年来, 随着人工智能(Artificial intelligence, AI)技术的飞速发展, 博弈论在社会智能[1-2]、机器智能[3]、合作智能[4]、AI安全[5-6]和AI伦理[7-8]等新兴交叉研究领域中扮演着越来越重要的角色. 特别地, 通过结合多智能体学习与控制论等理论方法, 博弈论已成为AI和自动控制领域中的一个热点研究方向.
从本质上讲, 所谓博弈论就是一类研究理性智能体(Agent)①之间策略交互的数学理论与方法[9]. 它是现代数学的一个分支, 也是运筹学的一个重要组成部分. 虽然博弈论的早期思想可以追溯到公元前, 但其作为一个独立的研究领域正式诞生的标志是von Neumann和Morgenstern于1944年合著的《博弈论与经济行为》 (Theory of Games and Economic Behavior)一书[10]. 作为多智能体系统或者分布式AI (Distributed AI)的一个研究主题[11-13], 多智能体学习主要研究多个智能体交互的策略学习问题. 从其发展历程上讲, 多智能体学习与博弈论几乎具有一样长的历史. 例如, 早在1951年, 文献[14]就提出了一类称为虚拟对弈(Fictitious play)的学习方法用于求解博弈的Nash均衡问题. 尔后, 在上世纪80年代后期, 伴随着学术界对演化计算、社会学习、交互学习和多智能体场景下的强化学习产生的广泛兴趣, 多智能体学习的研究开始在AI领域中兴起[12, 15]. 特别地, 近年来借助多智能体学习在棋牌[16-18]和视频游戏[19-21]等特定任务上取得的突破性进展, 这一方向在AI领域中再次掀起了热潮, 成为AI研究的核心内容之一. 与博弈论的发展历程相类似, 虽然人类进行自动控制的生产实践最早可以追溯到公元前[22], 但控制论作为一个独立的研究领域正式诞生的标志是Wiener于1948年撰写的《控制论》 (Cybernetics)一书[23]. 通过对比讨论 “动物智能” 与 “机器智能” 中的若干重要问题, Wiener指出“智能的首要问题是‘学习’”[24]. 综上可见, 虽然博弈论、多智能体学习与控制论分属不同的研究领域, 但究其发展根源和轨迹, 它们从来都不是相互割裂的, 而是紧密关联、相互融合的, 展现出一种 “你中有我, 我中有你” 的景象.
反映到具体的研究中, 博弈论、多智能体学习与控制论的融合通常包含在三种不同的场景设置中. 第一种设置为智能体之间完全合作. 在该设置下, 连接博弈论、多智能体学习与控制论的一种典型博弈形式是团队博弈(Team game)[25-26], 即所有博弈者具有一个相同收益函数的博弈形式. 在博弈论中, 团队博弈最初用于研究组织问题[25]. 而在多智能体学习中, 这类博弈主要用于处理多智能体的合作序贯决策问题, 也为发展合作型多智能体强化学习算法提供模型框架[27-28]. 考虑到分布式控制与团队博弈的信息结构问题[29]具有诸多相似之处, 在控制论中, 团队博弈主要用于分析团队决策问题[26]. 如果博弈的所有博弈者具有相同的(全局)信息结构, 团队博弈中的决策问题则可以转化成一个传统的集中式控制问题; 而如果每个博弈者具有不同的(局部)信息结构, 团队博弈的决策问题则可以转化成一个多智能体合作控制问题或者分布式控制问题[30-31]. 虽然团队博弈最早提出于上世纪50年代[25], 但时至今日, 它在控制领域中仍然是一个重要的研究主题[32-34]. 第二种设置为智能体之间完全竞争. 在该设置下, 连接博弈论、多智能体学习与控制论的一种典型博弈形式是零和博弈(Zero-sum game), 即两个博弈者具有零和收益关系(一个博弈者的收益是另一个博弈者的损失)的博弈形式. 在博弈论中, 零和博弈主要用于研究具有完全对立目标的博弈者间的决策问题. 而在多智能体学习中, 这类博弈主要用于处理多智能体的竞争序贯决策问题, 也为发展基于极大极小原理的多智能体强化学习算法提供模型框架[35]. 相比而言, 在控制论中, 零和博弈常用于处理含不确定因素的系统控制(鲁棒控制)问题[36-37]. 在该类问题中, 控制器(Controller)通常被视为一个最大化某一特定性能指标的博弈者; 而系统的不确定性(如干扰、噪声)则被视为另一个博弈者, 其目标是使控制器所最大化的性能指标最小化. 第三种设置为智能体之间既不完全合作又不完全竞争, 即混合设置. 在该设置下, 多智能体系统所形成的博弈是一个一般和博弈(General-sum game). 对于这类博弈, Nash均衡一般是标准的解[38]. 在多智能体学习中, 这类博弈通常用于处理一般化的多智能体序贯决策问题, 也为发展混合型的多智能体强化学习算法提供模型框架[39-40]. 相比而言, 在控制论中, 这种设置下的博弈者通常被视为是控制器, 而博弈者的策略被视为是控制律(Control law). 为了实现一个特定的任务目标, 比如收敛到一个Nash均衡, 博弈者的策略更新规则或学习算法通常需要进行额外设计[30, 41].
由于学科发展等种种原因, 博弈论和自动控制的研究对象曾经一度存在一些差异. 但借助AI和多智能体学习等技术, 它们之间的差异如今正在慢慢变小. 博弈论的研究对象一般是理性的“智能体”, 或者是具有智能的“生命体”, 比如人和动物等[9-10]; 而自动控制的研究对象一般是“机器”, 或者是无生命的“物理对象”, 比如机器人和航空航天器等[22, 42]. 然而, 近年来在AI技术和信息技术的推动作用下, 传统无生命的物理对象通过机器学习等方法正在逐渐被赋予如生命体一样的智能性. 与此同时, 自动控制的研究对象也在从单纯的物理系统逐步地转向机器、人与社会等更为复杂的融合交互系统[43]. 在这一全新的交互系统中, 机器不再被视为是一种无生命的物理对象, 而是作为一种智能的载体广泛地参与到人类社会的各种交互之中, 并呈现出一种人与人、人与机器、机器与机器的混合交互景象[1-4]. 然而, 这一全新的交互系统在促进人类社会发展的同时, 也将给人类带来一些新的挑战, 比如伦理问题和安全问题等. 考虑到这些新的挑战本身大部分是由多种研究对象所引发的, 比如人这类对象可能涉及到博弈论和社会学等, 机器这类对象可能涉及到控制论和机器学习等, 所以单一的学科或研究领域都会或多或少地存在着一些不足. 为此, 博弈论、多智能体学习与控制论的交叉融合有望在这方面发挥重要作用. 一方面, 它们交叉融合的本身可以促进各单一研究领域的发展; 另一方面, 它们涵盖的广泛理论体系可以为这一全新交互系统提供恰当的分析方法和研究工具.
当前无论是在博弈论领域、AI领域还是在自动控制领域, 博弈与多智能体学习的交叉[13, 44-50]、博弈与控制的交叉[30, 37, 51-53]、以及多智能体学习与控制的交叉[54-56]都是前沿的热点研究方向, 并且在这些主题下的相关工作和进展正呈现出一种井喷式增长的态势[57]. 然而, 据作者所知, 目前国内外已有的综述性文献主要集中讨论了这三者中的某两个特定领域[24, 30, 44, 47-52, 54-55, 58], 还没有文献宏观地从这三者的角度对它们的联系、区别以及最新的交叉研究成果进行全面的审视与梳理. 本文的主要目的是试图填补这一空白, 核心内容主要分为3节: 第1节主要介绍并讨论作为纽带连接博弈论、多智能体学习与控制论的四种基本博弈形式, 即标准式博弈(Normal-form game)、演化博弈(Evolutionary game)、随机博弈(Stochastic game)和不完全信息博弈(Incomplete-information game); 第2节主要论述对应于这四种基本博弈形式的多智能体学习方法, 即策略学习(Strategic learning)、学习动力学(Learning dynamics)、强化学习(Reinforcement learning)和鲁棒学习(Robust learning); 第3节按照不同研究专题梳理并介绍当前博弈、学习与控制的几类典型交叉研究成果. 最后, 针对这一重要
1. 基本博弈形式
本节主要介绍作为纽带连接博弈论、多智能体学习与控制论的四种基本博弈形式—标准式博弈、演化博弈、随机博弈和不完全信息博弈, 并讨论它们之间的联系与区别.
1.1 标准式博弈
标准式博弈[10], 也称为策略式博弈(Strategic-form game)[9, 59-60], 是描述博弈的一种基本形式. 一般地, 一个标准式博弈通常由以下三个基本要素构成: 1)博弈者集, 即博弈的所有参与者构成的集合; 2)博弈者的可行策略集; 3)博弈者的收益函数(也称为效用函数)或者成本函数.② 因此, 在数学上, 一个标准式博弈G通常可以表示为一个三元组
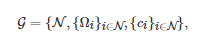
(1)
其中N表示所有博弈者的标号构成的集合, Ωi 表示博弈者i∈N 的策略集, ci:Ω→R 表示博弈者i∈N的收益函数,
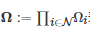
表示所有博弈者策略组合(Strategy profile)的集合. 如果集合N和Ωi , ∀i∈N是有限的(Finite), 则称标准式博弈G是有限的. 特别地, 如果一个标准式博弈只有两个博弈参与者, 即N={1,2}, 则称其为两人博弈(Two-player game). 而如果该标准式博弈具有多个博弈参与者, 则称其为多人博弈(Multi-player game). 另外, 在标准式博弈进行过程中, 博弈者的策略选择一般是“同时的” (Simultaneous-move). 但是“同时” 并不完全意味着所有博弈者的策略选择是在同一个时间点上完成的, 而更多地强调每个博弈者在策略选择过程中并不知道其他博弈者的策略.
另外, 在一些特定的情形下, 标准式博弈的一般化形式(1)可以进一步简化. 例如, 对于一个两人博弈Gm, 其通常可以用如下的一组收益矩阵来刻画
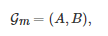
其中

分别表示博弈者11和博弈者22的收益矩阵, p和q分别表示博弈者11和博弈者22的可行策略的数目. 对于收益矩阵对(A,B), 它的一种更为形象的展示方式是将其写成如下的一张收益表
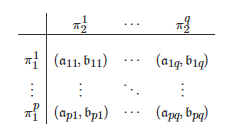
其中
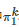
和分别表示博弈者11(行博弈者)的第k(k=1,2,⋯,p) 个策略和博弈者22(列博弈者)的第l(l=1,2,⋯,q) 个策略, 和分别表示博弈者11和博弈者22在策略组合下的收益值. 特别地, 如果博弈Gm 中的两个博弈者的角色是等同的(行和列的角色可交换), 即p=q 且A=BT , 则称Gm 是对称的(Symmetric), 此时的Gm 也称为矩阵博弈(Matrix game); 否则, 则称博弈Gm 是非对称的(Asymmetric), 此时的Gm也称为双矩阵博弈(Bi-matrix game). 由该定义可看出, 当Gm 是对称的, 它可简单地用收益矩阵A表示. 根据A中元素大小的不同, 博弈Gm 又可进一步分为多种类型. 例如, 表1以收益值akl (k,l∈{1,2})的大小关系为依据列举了几类典型的两人两策略对称博弈.

表 1 几类典型的两人两策略对称博弈
对于一个标准式博弈G, 如果该博弈只进行一次, 则称其为单次博弈(One-shot game); 否则, 如果该博弈重复地进行多次, 则称其为重复博弈(Repeated game). 另外, 根据博弈进行的总次数Ttot , 重复博弈又可分为有限次数(Finite horizon)重复博弈(Ttot<∞)和无限次数(Infinite horizon)重复博弈(Ttot=∞). 除非特别说明, 本文讨论的博弈都为无限次数的重复有限博弈(博弈者数和策略数均为有限).
一般地, 在一个标准式博弈中, 所有博弈者通常均被设定为完全理性的(Perfectly rational), 并且该设定是所有博弈者的共同知识(Common knowledge). 换句话讲, 在标准式博弈中, 每个博弈者的目标都是追求自身利益最大化或者成本最小化, 并且所有博弈者都共同地知道这一点. 由于在该设定下, 博弈者之间的利益关系是非合作的, 所以该类博弈也称为非合作博弈(Non-cooperative game)[38, 61]. 对于非合作博弈, 它的一个标准的解概念是所谓的Nash均衡[38, 61].
定义1. 对于有限的n 人标准式博弈
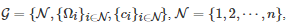
, 如果对任意的博弈者i∈N , 其策略是对所有其他博弈者−i:=(1,⋯,i−1,i+1,⋯,n)的策略组合的一个最佳响应(Best-response), 即
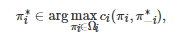
或者对任意的博弈者i∈N有
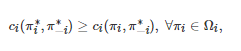
则称策略组合
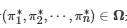
是G的一个Nash均衡.
由上述Nash均衡的定义可以看出, 当所有博弈者的策略组合处在一个Nash均衡状态时, 任何一个博弈者在给定其他博弈者策略组合的情况下, 都无法通过单方面地改变自身的策略来提高自身的收益. 因此, Nash均衡刻画了博弈者策略的一种 “稳定” 状态. 这点也是Nash均衡能够成为非合作博弈解概念的一个重要原因. 另外, 对于任意一个有限的标准式博弈, 它至少存在一个Nash均衡[38, 61]. 这点保证了Nash均衡作为非合作博弈解概念在理论上是可行的.
尽管Nash均衡作为非合作博弈的解概念在博弈论的发展历程中具有举足轻重的作用, 但它并不是十全十美的.③ 首先, Nash均衡解不仅要求博弈的参与者是完全理性的, 还要求博弈本身是完全信息的(Complete-information), 即博弈模型中的诸如策略集和收益函数等参数信息是所有博弈者的共同知识. 对于大量现实博弈场景, 这样的要求显然是苛刻的. 一个典型的例子就是人类参与的各种博弈. 一方面, 人在获取、存储、使用和回忆信息的过程中无法保证是完全准确无误的; 另一方面, 人的表达能力是有限的, 其通过文字、数字、图表或语音等形式传递消息的过程中, 无论多么努力, 最终的效果都无法保证是完美无缺的[65]. 因此, 人类作为博弈者通常无法满足完全理性这一要求. 另外, 人类作为博弈者所参与的各种博弈通常也并不是完全信息的, 因为在人类社会中, 任何一个个体都无法完全知道其他个体的所有信息. 此外, Nash均衡作为博弈的解本质上是一个 “静态的” 概念. 它只描述了在“稳定的” 策略组合状态下, 当其他博弈者不改变其自身策略时, 目标博弈者如何进行最佳的策略响应. 因此, 如果博弈本身或者博弈者的决策会随时间发生动态变化, 标准的Nash均衡则需进一步精炼才能对这种动态博弈的解进行刻画.
通过放宽上述Nash均衡的几点要求, 标准式博弈之后相继发展出了多种其他形式. 下面将逐一介绍其中的三种代表性形式, 即演化博弈、随机博弈和不完全信息博弈.
1.2 演化博弈
演化博弈是博弈论与动态演化过程相结合的一种动态博弈形式, 其起源于演化生物学家Maynard Smith和Price关于动物竞争行为的研究[66-67]. 特别地, 相比于标准式博弈, 演化博弈一般具有以下几方面的显著特征.
首先, 演化博弈在经典博弈论的基础上引入了生物学中的 “群体思维” (Population thinking)[68], 即演化博弈考虑的对象通常是一个博弈者群体, 而不仅仅是特定的几个博弈者. 因此, 演化博弈也称为群体博弈(Population game)[69-70]. 其次, 演化博弈中的博弈者通常被设定是有限理性的(Bounded rationality)[71]. 所谓有限理性是指博弈者在进行决策时, 它追求的目标是一个满意的解, 而非必须是一个最优的解. 再次, 演化博弈引入了一个称为演化稳定策略(Evolutionarily stable strategy, ESS)的新概念[66], 从而弱化了Nash均衡作为博弈解的作用. 所谓ESS是指, 如果群体中的所有博弈者采取的策略为一个ESS, 那么它可以抵御群体中充分小比例突变策略的入侵. 特别地, 因为每一个ESS都被证明是一个Nash均衡, 而该命题的反命题却不一定成立[72-74], 所以ESS是一个比Nash均衡更严格的概念. 最后, 同时也是最为显著的一点, 不同于传统的非合作博弈常立足于研究理性博弈者策略均衡的形成, 演化博弈更强调从系统论的角度出发, 着重于研究微观个体水平上的策略调整过程在宏观水平上所呈现出的群体动力学[69-70, 73]. 在演化博弈中, 驱动博弈者策略演化的 “动力” 是达尔文的 “优胜劣汰” 与 “适者生存” 的自然选择原理, 即具有高适应度(Fitness)的策略可通过个体水平上的诸如模仿、学习、复制、遗传或者传染等方式在群体中传播, 而具有低适应度的策略则倾向于在自然选择的作用下在群体中消失. 因为这些微观个体水平上的行为方式刻画了博弈者如何从一个策略更新为另一个策略, 所以在宏观群体水平上, 它们带来的一个直接结果是博弈者策略频率(即选择每个策略的博弈者数占博弈者总数的比例)的变化. 当这些策略频率在群体水平上随时间演化时, 在系统层面上, 它们将呈现出各种长期的动力学行为, 比如稳定和不稳定的平衡点、极限环、异宿环和混沌等[69-70, 75].
在演化博弈中, 因为个体水平上的策略更新方式通常具有多种不同的形式, 所以在群体水平上, 它们所呈现的演化动力学也将表现出多种不同的形式. 一般地, 如果按群体结构(即博弈者群体的空间交互结构)进行划分, 它们通常可分为无限混合均匀群体(Infinite well-mixed population, 即博弈者总数无穷大且任意两个博弈者可以随机交互的群体)、有限混合均匀群体(Finite well-mixed population, 即博弈者总数有限且任意两个博弈者可以随机交互的群体)和结构群体(Structured population, 即博弈者总数有限且每个博弈者只能与其局部邻居进行交互的群体)[74]. 然而, 如果按系统动力学进行划分, 它们一般可分为确定性演化博弈动力学和随机性演化博弈动力学. 下面将对这两类演化博弈动力学分别进行介绍.
1.2.1 确定性演化博弈动力学
无限混合均匀的群体是确定性演化博弈动力学通常采用的群体结构[75]. 根据博弈者微观策略更新规则的不同, 现有的确定性演化博弈动力学主要有复制动力学(Replicator dynamics)[76-77]、Logit动力学(Logit dynamics)[73]、BNN动力学(Brown-von Neumann-Nash dynamics)[78]和Smith动力学(Sm-ith dynamics)[79]等. 一般地, 这几个动力学系统可统一地用如下的一个常微分方程来描述[70]
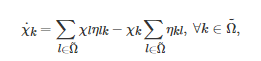
(2)
其中
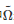
表示群体中所有博弈者的(离散且有限的)策略集, χk表示策略 在群体中的频率(即策略为k 的博弈者数占博弈者总数的比例), ηkl 表示任意一个博弈者从策略切换为策略 的期望概率. 本质上讲, 式(2)是一个博弈者群体策略演化的平均场(Mean-field)动力学, 它刻画了一个由ηkl 描述的微观策略更新过程在宏观群体水平上所呈现的策略演化动态. 式(2)等号右侧第1项表征了所有从其他策略切换为策略k 的博弈者在群体中的期望频率, 而第2项表征了所有从策略k 切换为其他策略的博弈者在群体中的期望频率. 因此, 前者减去后者刻画了群体中策略为k 的博弈者频率在单位时间内的期望变化量.
特别地, 当ηkl 描述的策略更新规则采用不同的具体形式时, 式(2)将会随之发生相应的改变. 例如, 对应于复制动力学, ηkl 描述的微观策略更新规则主要有 “成对比例模仿” (Pairwise proportional imitation)[80-81]和 “不满意驱动模仿” (Imitation driven by dissatisfaction)[70]两种形式. 具体地, 如果博弈者采用前者作为策略更新规则, 那么策略为k的博弈者将以概率ηkl=χl[hl−hk]+ 去模仿策略为l 的博弈者的策略, 其中hk 和hl 分别表示策略为k 和l 的博弈者的期望收益, [⋅]+ 表示斜坡函数算子(当中括号里的变量大于零时, 经该算子得到的值为其本身, 否则得到的值为零). 相应地, 如果博弈者采用后者作为策略更新规则, 那么策略为k 的博弈者将以概率ηkl=χl[K−hk]去模仿策略为l的博弈者的策略, 其中K 是一个常数, 表示所有博弈者期望得到的收益. 将上述两个关于ηkl 的表达式分别代入到方程(2)中, 于是有复制动力学方程为
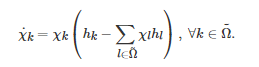
上述复制动力学是演化博弈中使用最为广泛、研究最为透彻、角色最为重要的一种确定性动力学. 它最初由生物数学家Taylor和Jonker于1978年为了研究ESS与动态系统的渐近稳定性之间的关系而引入的[76]. 后来, 由于人们发现复制动力学与群体生物学中的其他动力学之间存在着紧密的联系, 比如通过一个非线性变换, 复制动力学方程可等价为生态学中的Lotka-Volterra方程[82], 所以它在群体遗传学中的诸如性别比例演化等问题的研究中得到了广泛的应用[83]. 除此之外, 人们还发现复制动力学方程的平衡点与它对应的博弈的Nash均衡和ESS之间也存在着密切的联系[73], 比如复制动力学方程对应的博弈的每个Nash均衡都是它的一个平衡点; 复制动力学方程的每个Lyapunov稳定平衡点都是其对应的博弈的一个Nash均衡; 博弈的每个ESS都是其对应的复制动力学方程的一个渐近稳定平衡点等. 正是由于这些等价关系的存在, 复制动力学方程也被视为是一种研究博弈论的动力学方法[70, 73]. 另外, 在无穷小策略更新步长的条件下, 复制动力学方程还与强化学习具有紧密的联系. 例如, Cross学习[84]和Q学习[85-86]的算法迭代式在无穷小策略更新步长条件下将依概率收敛为一个复制动力学方程[87-89]. 特别地, 由于近年来强化学习在视频游戏[19-21, 90-91]和棋牌[16-18, 92-93]等具体博弈场景中取得了许多突破性进展, 所以目前如何将演化博弈中的复制动力学方程与机器学习中的强化学习方法进行融合已成为AI领域中的一个研究热点[94-98].
除了上述提到的与其他研究领域建立联系之外, 近年来复制动力学本身也相继发展出了一些新形式, 并在相关研究中发挥了重要作用. 例如, 为了研究合作策略演化问题, 文献[99-100]基于 “自愿参与” 机制提出了一个 “可选公共品博弈” (Optional public goods game)模型并分析了该博弈对应的复制动力学方程的性质, 而文献[101-104]提出了几类多人阈值博弈模型并分析了它们对应的复制动力学方程的性质. 文献[105-108]则提出并梳理了几类激励机制并给出了它们对应的复制动力学方程的稳定性分析. 另外, 为了将经典的复制动力学方程推广到网络结构群体中和具有随机扰动的环境中, 文献[109]和文献[110-111]分别提出了一类图(或网络)上的复制动力学和一类随机复制动力学. 基于类似的想法, 文献[112-113]则将经典的复制动力学方程从离散策略空间拓展到了连续策略空间. 除此之外, 近年来复制动力学方程还分别通过与深度学习[114]、分布式优化和控制[115]、观点动力学[116-117]、以及“环境反馈”[118]相结合相应发展出了神经复制动力学[119]、分布式复制动力学[120-121]、基于评估网络(Appraisal network)的复制动力学[122]和“博弈–环境反馈”复制动力学[123-126]等多种新颖形式.
尽管确定性演化博弈动力学在数学上具有诸多良好性质并且能为深入理解博弈者策略的演化动态提供有效的分析工具, 但该类方法通常只能处理不受随机因素影响的混合均匀群体的策略演化动态. 然而, 在现实博弈场景中, 博弈者总数通常是有限的, 并且博弈者的策略更新过程常会受到诸如噪声等随机因素的影响. 因此, 为了研究这类具有随机扰动的有限博弈者群体的策略演化动态, 学者们提出了一类称为“随机性演化博弈动力学”[127]的方法.
1.2.2 随机性演化博弈动力学
不同于确定性演化博弈动力学, 博弈者数有限的群体是随机性演化博弈动力学通常采用的群体结构[127]. 由于这一原因, 群体中博弈者的丰富度(Abundance)通常只能采用整数或者分数来描述. 另外, 由于在有限群体中, 博弈者的策略更新过程常会受到随机因素的影响, 所以博弈者的策略演化动态通常无法使用连续时间常微分方程来刻画, 而需借助随机过程这一数学工具. 除了这些差异之外, 随机性演化博弈动力学与确定性演化博弈动力学也存在着一些相似之处, 比如微观策略更新规则仍是影响宏观策略演化动态的一个关键因素. 从来源上讲, 目前主流的微观策略更新规则主要可分为两类: 一类来源于演化生物学, 另一类来源于社会学. 下面分别介绍这两类策略更新规则中的几种典型形式.
Moran过程[128]是群体遗传学中的一个经典模型, 也是随机性演化博弈动力学早期引入的一种策略更新规则[129-130]. 该过程主要借鉴了生物系统中的生死繁衍过程, 描述了一个博弈者如何从一个策略更新为另一个策略. 具体地, 在Moran过程中的每个时间步, 首先群体中的一个个体将以正比于其适应度的概率被随机地选定去产生一个后代. 随后, 在无变异存在的情况下, 该后代将完美地继承其父代的策略, 并随机地取代群体中的一个其他任意个体. 因为在这个过程中, 一个新个体产生的同时, 一个原有个体将被取代, 所以群体中的个体总数将始终保持不变. 特别地, 在上述策略更新过程中, 为了量化个体的适应度, 现有的文献通常将其定义为一个关于博弈者期望收益h的函数. 例如, 目前普遍采用的两类函数形式分别为1−β+βh [129-130]和exp(βh) [131-132], 其中β表示选择强度参数. 对于前者β∈[0,1] , 而对于后者β∈[0,+∞) . 当β=0 时, 其代表中性选择(Neutral selection). 在该情况下, 因为每个博弈者都有一个相同的背景适应度(Background fitness)或基准适应度(Baseline fitness), 所以基于Moran过程每个个体被选定的概率均是相等的. 类似地, 当β→0 时, 其代表弱选择(Weak selection)[133]. 在该情况下, 由于个体的期望收益值只轻微地影响其适应度, 所以基于Moran过程每个个体被选定的概率将接近中性选择的情况. 对于1−β+βh , 当β→1 时, 或者对于exp(βh) , 当β→+∞ 时, 其代表强选择(Strong selection). 在该情况下, 因为个体的期望收益值完全决定了其适应度, 所以基于Moran过程, 期望收益值越大的个体将总具有更大的机会产生后代, 并同时具有更大的机会传播其策略. 除了上述两个常用的适应度函数之外, 文献[134]也研究了诸如多项式函数和分段函数等其他更一般化的函数形式. 另外, 通过引入变异率参数, 文献[135-137]将上述标准的Moran过程拓展到了博弈者的策略更新过程存在变异的场景中.
不同于源自群体遗传学中的Moran过程, 对比较过程(Pairwise comparison process)[109, 127, 138]是一种基于社会学中的文化演化而提出的策略更新规则. 该规则主要刻画了“成功” 个体的策略是如何通过模仿被其他个体所复制的过程. 具体地, 对于一个有限混合均匀的博弈者群体, 基于对比较过程, 首先群体中的任意两个个体将被随机地选定, 其中一个个体作为中心博弈者(Focal player), 而另一个个体作为被模仿者(Role model). 随后, 中心博弈者将以一个正比于这两个个体收益之差的概率pr学习被模仿者个体的策略. 对于概率pr 的函数形式, 目前一种常用的选择是Fermi函数, 即pr=1/{1+exp[−β(hE−hI)]} , 其中hI 和hE 分别表示中心博弈者和被模仿者的期望收益. 除了Fermi函数之外, 文献[139-140]和文献[134]也分别研究了pr为线性函数的情形和一般化抽象函数的情形. 另外, 为了研究Moran过程中的适应度函数和对比较过程中的策略选择概率函数对策略演化结果的影响, 文献[141]提出了一个一般化形式的适应度函数和一个一般化形式的策略选择概率函数, 并给出了策略演化达到平稳状态时一个策略占优于另一个策略的充分必要条件. 受该文的启发, 文献[142]则进一步将上述一般化的函数思想推广到了网络化混合决策博弈场景中.
上述介绍的Moran过程和对比较过程都隐含地采用了有限混合均匀的群体结构假设. 然而, 通过适当的调整, 这两个策略更新规则其实也可以运用于具有网络空间结构的博弈者群体, 即所谓的复杂网络上的演化博弈[143-144]. 对应于Moran过程, 其在复杂网络上的两个典型版本分别是 “生–死” 过程(Birth-death process)和 “死–生” 过程(Death-birth process)[109, 145-146]. 具体地, 在 “生–死” 过程中, 首先群体中的一个个体将以正比于其适应度的概率被选定去产生一个后代; 随后, 该后代将随机地取代网络中其父代邻居中的一个个体. 而在“死–生” 过程中, 首先群体中的一个个体将被随机地选定去死亡; 随后, 该死亡个体的某一个邻居将以正比于其适应度的概率被选定去将其后代产生在该死亡个体的位置上. 虽然这两个策略更新规则表面上看起来只是顺序上的差异, 但在宏观动力学行为上, 它们却会产生出截然不同的结果[146-147]. 对应于对比较过程, 其在复杂网络上的版本只需在个体选择阶段进行一些微小调整. 具体地, 在对比较过程的个体选择阶段, 首先随机地选定群体中的一个个体作为中心博弈者, 随后再随机地选定该中心博弈者的一个邻居作为被模仿者. 然后, 中心博弈者将以一个正比于这两个个体收益之差的概率pr去学习被模仿者个体的策略[109, 146]. 基于上述复杂网络上的演化博弈这一研究框架, 文献[148-150]对博弈者多样性的交互行为进行了一系列研究, 并提出了行为多样性、边多样性和博弈转移等概念. 而文献[151- 152]基于现实的博弈者交互网络具有时序性这一特点提出了一类时序网络化系统, 并对其中的控制问题和演化博弈动力学问题进行了深入研究. 另外, 基于复杂网络上的演化博弈这一研究框架, 文献[153]、文献[154]和文献[155]分别研究了策略的共演化(Co-evolution)特性、策略的自适应协调特性和博弈动力学的空间周期特性.
除了上述介绍的几种典型策略更新规则之外, 相关研究也考虑了一些其他类型的策略更新规则, 比如 “以牙还牙” (Tit-for-tat)[156]、“赢留输变” (Win-stay lose-shift)[157]、模仿(Imitation)[81, 109, 146]、摄动最佳响应(Perturbed best response)[158]、Wright-Fisher过程[159-160]和最近广受关注的基于期望的(Aspiration-based)策略更新规则[161-165]等.
1.3 随机博弈
与演化博弈相类似, 随机博弈也是动态博弈的一种形式, 它最初是由Shapley于1953年提出并命名的[166]. 在AI和自动控制领域中, 随机博弈通常也称为Markov博弈[35]. 然而, 有别于演化博弈的一点是, 随机博弈引入了一个称为(博弈) “状态”的全新概念.④ 或粗略地讲, 随机博弈在每个阶段都有一个状态变量用于刻画当前所有博弈者所面临的博弈场景.
一般地, 一个随机博弈Gs 通常可以表示为一个六元组
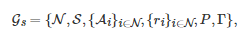
其中N 表示所有博弈者的标号构成的集合, S 表示所有博弈者所处 “环境” 或 “系统” 的状态集, Ai 表示博弈者i∈N 的行动集, ri:S×A×S→R 表示博弈者i∈N 的收益函数或回报函数(Reward function), P:S×A→Δ(S) 表示状态转移概率分布函数, Γ 表示博弈进行的时间集,⑤ A:=∏i∈NAi, Δ(S)表示集合S 上的所有概率分布构成的集合. 在随机博弈进行的每个阶段, 系统将处于状态集S 中的某一个状态s∈S. 随后, 依赖系统当前的状态s∈S , 每个博弈者i∈N 将根据它的策略(Policy) πi:S→Ai 从其有效的行动空间Ai 中选择一个行动πi(s)=ai∈Ai .⑤ 当所有博弈者执行完它们的行动之后, 博弈将会产生两方面的结果. 一方面, 取决于系统当前的状态s∈S 以及所有博弈者在当前阶段采取的行动a∈A , 系统将以概率P(s′|s,a) 从当前的状态s∈S 转移到下一阶段的另一个状态s′∈S . 另一方面, 作为所有博弈者行动和系统状态转移的结果, 每个博弈者i∈N 将从当前阶段的博弈中获得一个即时的收益值或回报值ri(s,a,s′) .
特别地, 当状态集S为一个单点集时, 随机博弈Gs 将退化为一个重复的标准式博弈. 因此, 从这点上讲, 随机博弈将von Neumann提出的标准式博弈拓展到了动态多阶段和动态多场景中[167]. 另一方面, 当博弈者集合NN只含一个博弈者时, 随机博弈Gs 将退化为一个标准的Markov决策过程(Markov decision process)[168-169]. 因此, 从这点上讲, 随机博弈又将Markov决策过程从单智能体系统拓展到了多智能体系统(见图1). 正是由于这一原因, 在AI领域中, 随机博弈也被视为是多智能体强化学习的一般性模型框架[35].
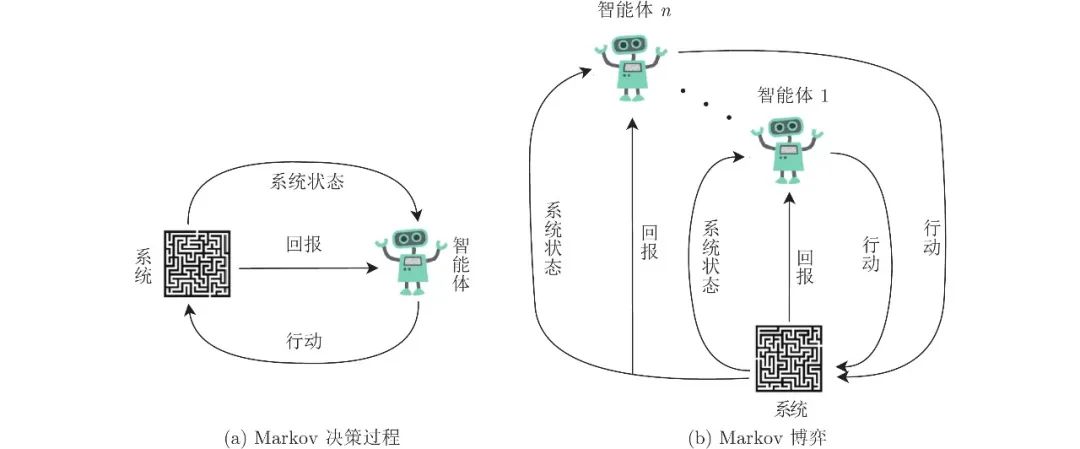
图 1 Markov决策过程和Markov博弈的示意图
对于一个n人随机博弈Gs, 此时N={1,2,⋯,n}, 当分别给定所有博弈者的策略组合π:=(π1,π2,⋯,πn)、所有博弈者的收益函数组合r:=(r1,r2,⋯,rn)和状态转移概率分布函数P时, 如果随机博弈Gs在离散时间集Γ上进行无穷轮, 那么它在时间尺度上将会诱导出一个时间序列{(st,at,rt)}t∈Γ , 其中 st∈S 表示系统在时刻 t 的状态, at:=(a1,t,a2,t,⋯,an,t) 表示所有博弈者在时刻t 的行动组合, 这里ai,tai,t表示博弈者i∈N 在时刻t 的行动, rt:=(r1,t,r2,t,⋯,rn,t) 表示所有博弈者在时刻t 的收益值组合, ri,t=ri(st,at,st+1) 表示博弈者i∈N 在时刻t的收益值. 特别地, 如果在整个博弈过程中每个博弈者都是理性的, 那么对于任意的博弈者i∈N , 它的目标将是找到一个策略πi∈Ωi 使得其长期的累积期望收益
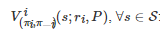
最大, 这里Ωi 表示博弈者i 的有效策略集, 表示博弈者i 之外的所有博弈者的策略组合. 一般地, 为了保证 是一个有界值函数, 其计算方式常采用如下的折扣形式⑦

(3)
其中
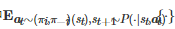
表示对 π=(πi,π−i) 和P 诱导出的随机过程{(at,st)}t≥0 求数学期望, γ∈[0,1)是一个折扣因子.⑦ 与标准Nash均衡的解概念相类似, 对于随机博弈Gs , 它的标准解是一个称为Markov完美均衡(Markov perfect equilibrium)的概念[170-171].
定义2. 对于有限的n人随机博弈
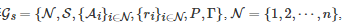
, 如果对∀i∈N 和 ∀s∈S 有
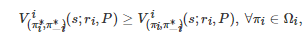
或者
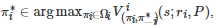
, 则称策略组合
是 Gs 的一个Markov完美均衡.
一般地, 对于一个有限的n 人随机博弈, 它的Markov完美均衡通常总是存在的[170]. 但是, 由于其计算复杂性问题的存在[172], 求解一个Markov完美均衡通常十分具有挑战性. 为此, 相关研究经常会考虑随机博弈的一些特定情形. 根据博弈者收益函数或回报函数的不同, 它们主要可分为3类[47, 49-50]: 1)完全合作, 在该设置下所有博弈者具有相等的收益函数, 即ri=rj , ∀i,j∈N , 此时的随机博弈也称为多智能体Markov决策过程[27]、团队Markov博弈[28]或团队随机博弈; 2)完全竞争, 在该设置下随机博弈只有两个博弈参与者, 并且它们的收益函数满足零和关系, 即r1=−r2 , 此时的随机博弈也称为零和随机博弈; 3)混合型, 在该设置下所有博弈者的收益函数不受其他约束条件影响, 即此时的随机博弈为一般和随机博弈[39].
1.4 不完全信息博弈
上述介绍的几类博弈形式都隐含地采用了完全信息的假设, 即博弈模型的参数信息, 比如博弈者的行动集和收益函数等, 是所有博弈者的共同先验知识. 然而, 在大量现实博弈场景中, 完全信息的假设通常是一种过于理想化的要求. 通过放宽该假设, Harsanyi提出了一类称为不完全信息博弈的模型[173]. 它为研究博弈者在具有部分模型信息条件下的决策问题提供了一套完善的数学方法与工具.
第一个成熟的不完全信息博弈模型是由Harsanyi于1967年提出并命名的Bayesian博弈[173]. 一般地, 一个n 人Bayesian博弈Gb 通常可以表示为一个五元组[174]
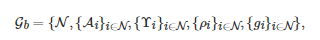
其中N={1,2,⋯,n} 表示所有博弈者的标号构成的集合, Ai 表示博弈者i∈N 的行动集, Υi 表示博弈者i∈N 的类型集,
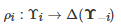
是一个条件概率分布函数, 表示博弈者i∈N在知道自己类型的情况下对其他博弈者类型的推断(Belief), 表示博弈者i∈N 的收益函数或效用函数, 。 具体地, 在Bayesian博弈进行过程中, 首先一个称为“自然” (Nature)的虚拟个体将赋予所有博弈者一个类型组合ι:=(ι1,ι2,⋯,ιn) , 其中表示博弈者i 的类型. 随后, 对于每个博弈者i∈N, “自然” 只告知属于其自身的类型ιi, 而对所有其他博弈者−i 的类型进行保密. 然后, 每个博弈者i∈N 将各自从其行动空间Ai 中选择一个行动ai∈Ai . 最后, 作为所有博弈者行动的结果, 每个博弈者i∈N 将获得一个收益值 gi(a1,a2,⋯,an;ιi) .
特别地, 在上述Bayesian博弈模型中, 依赖于类型ιi∈Υi 的收益函数gi 是最为关键的一个要素, 因为它是Bayesian博弈模型中表示不完全信息的一个核心设置. 具体来讲, 因为每个类型ιi∈Υi 都对应着博弈者ii的一个收益函数gi , 所以当博弈者i 不知道其自身的类型和其他博弈者的类型时, 它就无法明确知道其自身的收益函数和其他博弈者的收益函数. 换句话说, 当博弈者ii只知道其自身的类型时, 这等同于它只知道其自身的收益函数. 类似地, 当博弈者i对其他博弈者的类型不确定时, 这等同于它对其他博弈者的收益函数不确定. 为了从数学上刻画这种不确定性, Bayesian博弈假定所有博弈者的类型组合ι 的联合概率分布ρ(ι) 是所有博弈者的共同知识. 基于该假定, 当“自然” 告知博弈者ii其类型为ιi 时, 博弈者 i于是可根据Bayesian法则对所有其他博弈者的类型ι−i=(ι1,⋯,ιi−1,ιi+1,⋯,ιn) 进行推断, 即
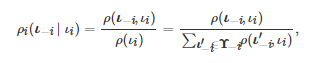
(4)
这里ρi(ι−i∣ιi) 表示博弈者i 在知道自己的类型为ιi 的情况下, 推测所有其他博弈者的类型为ι−i 的概率.
因为在Bayesian博弈中, 每个博弈者的收益函数都是类型依赖的, 所以当博弈者进行决策时, 它的行动选择也将是类型依赖的. 换句话讲, 在Bayesian博弈中, 每个博弈者的策略都是一个关于其自身类型的函数. 基于这一考虑, Harsanyi通过借鉴Nash均衡的类似定义方法, 提出了一个称为Bayesian均衡的博弈解概念, 并证明了该均衡解在有限Bayesian博弈中的存在性[173].
由上述Bayesian博弈类型推断的设定可以看出, 式(4)成立的一个关键点在于, 联合概率分布ρ(ι)ρ(ι)是所有博弈者的共同知识. 然而, 由于在大量现实博弈场景中, 共同知识的假设通常是过于理想化的, 所以该假设的合理性经常受到质疑[175-176]. 为了放宽该假设, 学者们于是提出了一些解决方案. 例如, Mertens和Zamir提出了一个称为“普遍类型空间” (Universal type space)的替代概念[177]; Holmström和Myerson提出了一类称为 “无分布均衡解” (Distribution-free equilibrium solution)的方法[178]. 相较之下, Aghassi和Bertsimas通过引入鲁棒优化[179]方法, 提出了一类称为“鲁棒博弈” (Robust game)的不完全信息博弈模型[180]. 在该模型中, 每个博弈者并不能明确地知道其收益函数, 而只能感知到其收益函数所在的一个不确定集. 借助从该不确定集得到的收益信息, 博弈者将基于鲁棒优化的方法进行行动决策, 以便获得一个“满意的”收益. 其中, “满意的” 收益是指, 每个博弈者的目标是寻找一个最优策略使得其收益值在最坏的情况(Worst-case)下能最大. 具体地, 对于一个由n个博弈者参与的鲁棒博弈, 如果用
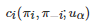
表示任意的博弈者i(i=1,2,⋯,n )在策略组合(πi,π−i) 和不确定参数uα∈Uα 下的收益函数, 那么基于鲁棒优化方法, 任意博弈者i 的目标将是寻找在不确定参数uα 最坏的情况下, 对其他博弈者策略π−i∈Ω−i 的一个最佳响应, 即
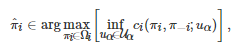
其中不确定参数uα 属于不确定集 Uα , 刻画了收益函数ci 的不确定性. 由于鲁棒博弈的不确定性是借助收益函数的不确定集刻画的, 所以它完美地规避了Bayesian博弈关于共同知识的假定. 另外, 为了分析鲁棒博弈的性质, Aghassi和Bertsimas借鉴Nash均衡的类似定义方法, 提出了一个鲁棒优化意义下的均衡解概念, 即所谓的“鲁棒优化均衡” (Robust-optimization equilibrium), 并证明了该均衡解在有限鲁棒博弈中的存在性[180].
然而, 在上述鲁棒博弈模型中, Aghassi和Bertsimas只考虑了同时行动的(Simultaneous-move)、有限的(Finite)、一轮(One-shot)博弈场景. 之后, 为了将鲁棒博弈的思想推广到随机博弈中, Kardeş等提出了一类称为“鲁棒随机博弈” (Robust stochastic game)的模型[181]. 具体地, 对于一个随机博弈
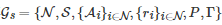
, 如果Gs 中的ri, ∀i∈N 和P不是明确给定的, 而是分别属于不确定集Ri 和P, 则称Gs 为一个鲁棒随机博弈. 与Markov完美均衡的概念相类似, 鲁棒随机博弈在鲁棒优化意义下的均衡解是一个称为“鲁棒Markov完美均衡” (Robust Markov perfect equilibrium)的概念[181].
定义3. 对于有限的n人鲁棒随机博弈
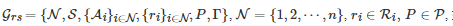
, 如果对∀i∈N 和∀s∈S 有
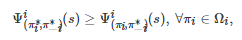
或者
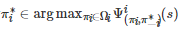
, 则称策略组合是 Grs 的一个鲁棒Markov完美均衡, 其中.
特别地, Kardeş 等发现, 当不确定集Ri 和P 是紧集时, 任意一个有限鲁棒随机博弈都至少存在一个鲁棒Markov完美均衡[181].
1.5 小结
作为第1节内容的一个小结, 图2从博弈者数、策略数、系统状态数和不完全信息的程度这四个维度展示了这节介绍的四类基本博弈形式的一个统一框架(该框架引自文献[182], 其中方框图颜色的深浅表示不完全信息程度的大小). 标准式博弈是一类传统的博弈形式, 也是现代博弈论发展的基石. 在该类博弈形式中, 一种典型的模型范式是所谓的两人两策略博弈, 比如囚徒困境博弈、雪堆博弈和猎鹿博弈等. 然而, 大量现实社会、经济和工程系统中的博弈通常都是由多个博弈者或者一个博弈者群体参与的, 比如著名的 “公共地悲剧” (The tragedy of the commons)问题[183]. 因此, 为了研究这类具有多个博弈者参与的博弈问题, 博弈的模型范式在博弈者数这个维度上就需从两人形式转变为多人形式, 比如从囚徒困境博弈转变为公共品博弈. 进一步, 如果博弈者具有多个策略, 那么在策略这个维度上, 博弈的模型范式就需从两策略转变为多策略. 然而, 由于标准式博弈本质上是一种一轮博弈, 或者说是一种 “静态的” 博弈(即没有考虑时间这个维度), 所以该类博弈形式通常无法对动态决策问题进行刻画. 因此, 如果在标准式博弈的基础上引入时间这个维度, 那么它将相应地转变为动态博弈. 进一步, 如果在动态博弈的基础上考虑群体和演化的作用, 那么在博弈形式上, 它就变成了演化博弈. 但是, 从本质上讲, 这类博弈仍然没有脱离标准式博弈的基本框架, 即一个由博弈者集、策略集和收益函数构成的三要素框架. 随机博弈通过在标准式博弈的基础上引入(博弈) “状态” 这一新维度, 一方面将重复的标准式博弈拓展到了动态多类型博弈(或状态依赖的博弈)场景中, 另一方面又将单智能体Markov决策过程拓展到了多智能体系统中. 因此, 它极大地拓宽了博弈论在多智能体场景中的适用范围. 但不足的一点是, 它仍然保留了标准式博弈关于完全信息的这一假定. 在实际的博弈中, 含有不确定因素和不完全信息的场景通常是一种更为常见的情况. 由此, 通过在标准的随机博弈的基础上引入不完全信息这个维度, 鲁棒随机博弈将完全信息博弈的模型范式拓展到了不完全信息的场景中. 综上可见, 标准式博弈是博弈论的基石, 演化博弈、随机博弈和不完全信息博弈是这基石之上分别引入群体性思维与演化、博弈状态和不确定性这三个新维度之后的发展形式.
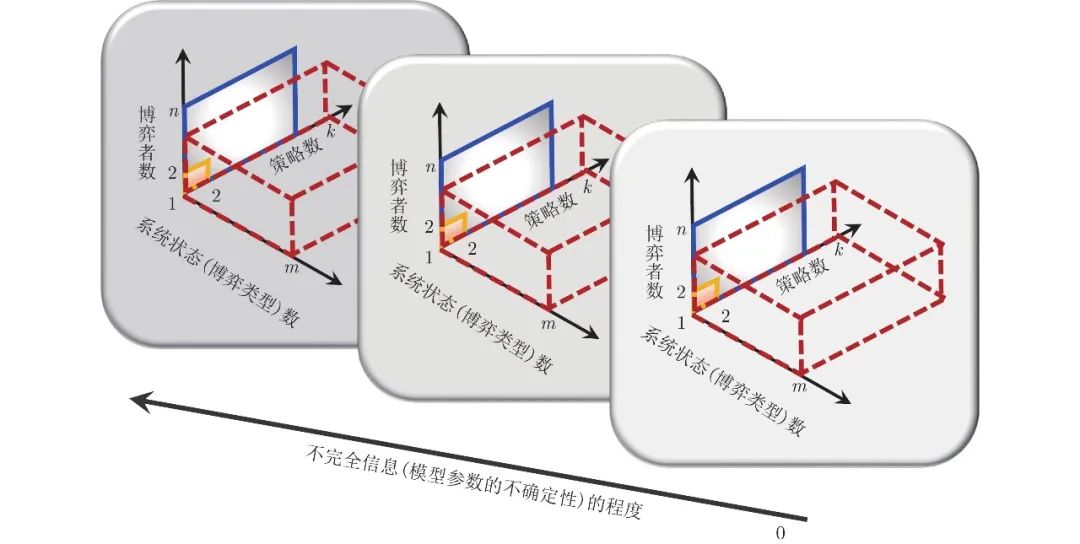
图 2 基本博弈形式的一个统一理论框架图
2. 多智能体学习方法
对应于第1节介绍的标准式博弈、演化博弈、随机博弈和不完全信息博弈, 本节将主要论述这四类博弈形式中的多智能体学习方法, 即策略学习、学习动力学、强化学习和鲁棒学习.
2.1 策略学习
策略学习是一种学习对手(Opponent)策略的方法, 它在博弈学习理论(The theory of learning in games)中是一种广泛使用的经典方法[45-46].⑨ 在该类方法中, 一个典型的例子是所谓的 “虚拟对弈” 过程[14, 184]. 该过程假定在一个重复的标准式博弈中, 每个博弈者所面临的对手都是平稳的(Stationary), 即对手的策略不随时间变化. 另外, 为了描述每个博弈者对其对手策略的学习, 该过程假定每个博弈者是通过记录其对手过去所采用行动的频率(即对手的实证策略)来作为其对手策略的推断. 具体地, 对于一个两人重复标准式博弈G={N,{Ai}i∈N,{ci}i∈N}, 这里N={1,2}, ci:A1×A2→R 为博弈者i∈N 的收益函数, 基于虚拟对弈过程, 任意的博弈者i 在第t (t≥1) 轮博弈中对其对手−i 的策略推断为
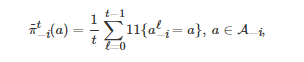
其中
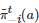
表示博弈者i 推测其对手−i 在第t 轮博弈中将采取行动a∈A−i 的概率, 表示指标函数(Indicator function). 如果对手−i 在第ℓ (ℓ≥0) 轮博弈中采取的行动为a∈A−i , 那么; 否则, . 基于该对手策略的推断, 博弈者i 在第t 轮博弈中采取的策略将为 的一个最佳响应, 即
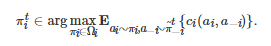
对于虚拟对弈学习过程, 一个重要的理论问题是, 博弈者的实证策略
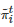
, ∀i∈N (即博弈者i 的策略推断)是否会收敛? 如果收敛, 它是否会收敛到一个Nash均衡? 这一问题也是博弈学习理论中的一个核心问题[45-46]. 对于零和博弈, Robinson发现这个问题的答案是肯定的, 即基于虚拟对弈学习过程, 所有博弈者的实证策略将收敛到零和博弈的一个Nash均衡点[184]. 虽然这一肯定的答案之后也推广到了其他的博弈场景中, 比如两人两策略非零和博弈, 但在更多情况下, 虚拟对弈通常并不能保证收敛[45, 185]. 导致这一结果的一个重要原因是, 虚拟对弈过程要求对手的策略是平稳的. 然而, 在多智能体的学习环境中, 一方面, 一个博弈者在学习的同时另一个博弈者也在学习, 所以每个博弈者面临的 “外部学习环境” 都在不断变化; 另一方面, 由于对手的策略总在不断地调整, 所以每个博弈者总是需要去跟踪学习一个不断变化的“目标”. 因而, 这就破坏了虚拟对弈所需的平稳性条件. 该问题也是多智能体学习中普遍存在的非平稳性(Non-stationarity)问题[186]. 按照复杂性程度的不同, 文献[186]对现有处理该类问题的方法进行了总结和归纳, 并把它们划分成了5类: 1)忽视(Ignore), 即忽视对手策略的非平稳性从而认为对手策略是平稳的; 2)遗忘(Forget), 即只依赖最近观察到的信息更新对手策略的推断; 3)响应目标对手(Respond to target opponent), 即对明确的目标对手采取最佳的策略响应; 4)学习对手模型(Learn opponent model), 即学习对手策略的模型并依赖该模型推导出自身的策略响应; 5)心智理论(The theory of mind), 即推测对手的策略并假定对手也在推测自己, 从而形成一个不断递归的推测过程. 另外, 针对学习对手模型的这类方法, 文献[187]将其称为对手模拟(Opponent modelling)并对该类方法进行了全面的总结和归纳, 而文献[188]从博弈者所需信息的角度给出了该类方法的一个分类框架.
由上述关于虚拟对弈的介绍可以看出, 标准的虚拟对弈过程主要适用于重复的标准式博弈. 之后, 为了将该博弈学习方法拓展到其他博弈类型中, 虚拟对弈过程也相继地发展出了一些其他的变体形式, 比如随机虚拟对弈(Stochastic fictitious pl-ay)[45]、联合策略虚拟对弈(Joint strategy fictitious play)[189]、分布式虚拟对弈(Distributed fictitious play)[190-191]、采样虚拟对弈(Sample fictitious play)[192]、神经虚拟自对弈(Neural fictitious self-play)[193]、基于零和随机博弈的虚拟对弈[194]和基于平均场博弈的虚拟对弈[195]等.
2.2 学习动力学
学习动力学是博弈学习与系统动力学相结合的一种方法, 也是从动态系统的角度去理解博弈学习过程的一种方式. 目前, 该类方法中的大部分工作都是基于演化博弈动力学与多智能体强化学习的交叉来实现的[95]. 强化学习是一种利用经验不断试错的学习方式, 它被认为是动物学习和生物智能的基石之一[196-197]. 而多智能体强化学习是该学习方式在多智能体场景(比如多人博弈)下的拓展形式. 该学习方法更为细致的介绍将在第2.3小节中呈现, 本小节主要关注其与演化博弈动力学的结合.
Cross学习[84]是针对重复的标准式博弈(也称为无状态(Stateless)的博弈)提出的一种强化学习方法, 也是强化学习与演化博弈动力学产生关联的一类早期方法[87]. 具体地, 考虑一个重复的标准式博弈G={N,A,{ci}i∈N} , 这里假定所有博弈者共享同一个行动空间A并且
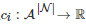
. 基于Cross学习, 每个博弈者i∈N 的策略更新方式为
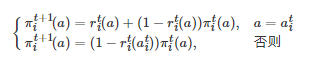
(5)
其中
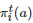
表示博弈者i∈N 在第t 轮博弈中采取行动a∈A 的概率, 是一个随机变量, 表示博弈者i∈N 在第t 轮博弈中采取行动a∈A 所获得的收益, 表示博弈者i∈N 在第t 轮博弈中采取的行动. 令 . 于是, 借助式(5), 的数学期望可计算为
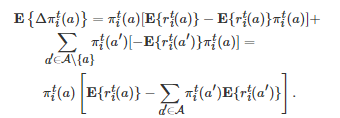
(6)
如果假定相继两轮博弈之间的时间间隔为δ∈(0,1] , 那么第t (t≥0 )轮博弈发生的时刻τ 为τ=tδ . 当δ→0 时(即在一个无穷小策略更新步长条件下), Börgers和Sarin发现式(6)将依概率收敛为如下一个确定性复制动力学方程[87]
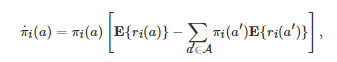
这里πi(a) 和ri(a) 分别表示博弈者i∈N 选择行动a∈A 的概率和采取行动a∈A 后获得的收益, 并且它们都是关于连续时间变量的函数.
受上述研究思路的启发, 多智能体强化学习与复制动力学的交叉研究随后分别在统计物理和AI这两个领域中开始了独立发展, 其中文献[88]和文献[89]是它们各自的早期工作. 虽然这两篇文献的作者分别隶属于不同的研究领域(前者为统计物理或复杂系统, 而后者为AI), 但他们都基于重复的标准式博弈对强化学习中的Q学习的演化动力学进行了研究, 并独立地发现了Q学习在无穷小更新步长条件下将收敛为一个复制动力学方程的事实. 基于这两项工作, 学习动力学这一交叉研究主题后续分别沿着不同的风格在统计物理和AI这两个领域中继续向前发展. 具体地, 在统计物理领域中, 后续的相关工作主要专注于研究复杂博弈场景中的长期动力学行为, 比如混沌[198-200]、分叉[201]和周期振荡[202]等. 而在AI领域中, 后续的相关工作更多地关注于多智能体强化学习算法的动力学解释和新学习算法的开发, 比如频率调整的Q学习(Frequency-adjusted Q-learning)[203]、加权策略学习者(Weighted policy learner)算法[204]和遗憾最小化(Regret minimization)算法[205]等.
目前, 虽然学习动力学的相关研究已取得了十分丰硕的成果, 并且极大地推动了多智能体强化学习与演化博弈动力学的交叉发展, 但它们也存在着一些不足之处. 例如, 目前该领域中的大部分工作所采用的博弈形式都是重复的标准式博弈(即无状态的博弈), 并且这些工作的研究范式仍然沿袭着Q学习与确定性复制动力学方程的交叉. 然而, 由上一节关于演化博弈和随机博弈的介绍可以看出: 一方面, 随机性演化博弈动力学比确定性演化博弈动力学具有更宽的适用范围; 另一方面, 随机博弈比重复的标准式博弈更具一般性. 因此, 自然地产生了这样一个问题: 多智能体强化学习是否可以在随机博弈的框架下与随机性演化博弈动力学进行融合?特别地, 如果该问题可以放在具有网络空间结构的博弈者群体中进行考虑, 那么它将变得更加一般化.
为了对该问题进行研究, 文献[206]提出了一个网络上的多人随机博弈模型. 在该模型中, 每个博弈者只有两个可供选择的行动C和D, 即所有博弈者共享同一个行动集A={C,D} . 基于博弈者群体的空间交互结构, 每个博弈者只能与其直接邻居进行交互并形成一个d 人随机博弈. 当系统处于状态s 时, 依赖当前所有博弈者的行动选择, 表2给出了任意博弈者在当前轮博弈中获得的收益. 在该表中, aȷ(s) 和bȷ(s) , ȷ=0,1,⋯,d−1 分别表示一个行动为C和D的博弈者, 当其d−1 个共同博弈者中有ȷ个个体选择行动C且系统状态为s∈S 时, 其获得的收益. 在该博弈进行过程中, 博弈者的行动决策被假定是异步的, 即在每个时间步, 群体中只有一个随机选定的博弈者更新其行动. 当该选定的博弈者进行行动更新时, 它的策略函数被设定为如下的一个Soft-max形式

表 2 d人随机博弈的收益表
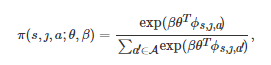
(7)
其中
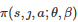
表示当系统状态为 s且 d−1 个共同博弈者中有ȷ 个个体选择行动C时, 行动更新的博弈者选择行动a∈A 的概率, β∈[0,+∞) 表示选择强度参数或适应率参数[198], 是一个L 维的列向量, 表示策略学习参数, 是一个L 维的特征向量, 刻画了当系统状态为s 且d−1 个共同博弈者中有ȷ 个个体选择行动C时, 行动更新的博弈者采取行动a∈A 的特征. 在博弈进行过程中, 式(7)中的学习参数θ将根据每轮博弈的收益结果以Actor-critic强化学习[207-208]的方式进行实时更新. 特别地, 文献[206]通过分析博弈者群体决策的长期演化结果发现, 在弱选择条件下, 群体中行动为C的博弈者比例大于行动为D的博弈者比例当且仅当存在一组依赖状态s∈S的矩阵和以及一个常系数 e使得
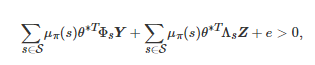
其中

|S| 表示集合 S的势,
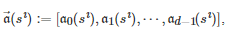
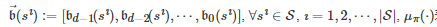
, μπ(⋅) 表示系统状态在策略π 下的平稳分布, θ∗ 是学习参数θ 在博弈进行无穷轮后的极限值(Actor-critic强化学习算法的收敛性保证了θ 极限值的存在). 此外, 通过比较有无学习机制作用下的数值仿真结果, 该文还发现, 学习机制的存在能够有效提升博弈者在动态社会困境博弈环境中的适应性.
2.3 强化学习
强化学习是人和动物普遍使用的一种学习方式, 它在不同的学科范畴内(比如认知神经科学和计算机科学)具有不同的解释和定义[197]. 但如果仅从计算的角度来讲, 一般认为强化学习的数学基础是Markov决策过程. 正如图1所示, 标准的Markov决策过程是随机博弈在单智能体场景下的退化情形. 它主要由两部分构成, 一部分称为智能体, 另一部分称为 “系统” (或“环境”). 在每一离散决策时刻t≥0 , 系统将处于状态集S 中的某一个状态st∈S . 随后, 智能体将根据它的策略π:S→A 从其行动空间A 中选择一个行动π(st)=at∈A并执行. 作为该行动的一个直接结果, 系统将以概率P(st+1∣st,at) 从当前状态st 转移到下一时刻的状态st+1 . 同时, 作为上述行动和系统状态转移的共同结果, 智能体将从当前的决策中获得一个即时的收益值或回报值r(st,at,st+1) , 其中r:S×A×S→R 是该智能体的收益函数或回报函数. 上述决策过程随着时间不断地重复进行, 从而构成了一个有限时间或者无限时间的Markov决策过程, 这里的“Markov”是指系统状态的转移具有Markov属性[169].⑩
在上述序贯决策过程中, 智能体的目标是找到一个策略π:S→A 使得其长期的累积期望收益Vπ(s) , ∀s∈S 最大化. 与式(3)相类似, 为了保证Vπ(s)是一个有界值函数, 其中一种常用计算方式为如下的折扣形式
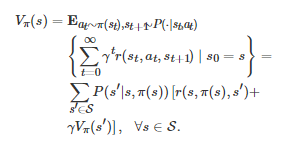
因为Vπ(s) 是一个关于初始状态s∈S 的函数, 所以在强化学习的文献中, 它也称为状态值函数. 为了找到值函数Vπ(s) 的最优策略π∗, 即π∗∈argmaxπ∈ΩVπ(s) , ∀s∈S
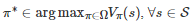
(其中Ω 是π 的可行集), 传统上一种常用的方法是动态规划方法[210]. 以该类方法中的值迭代(Value iteration)[196-197, 211]为例, 它的一个基本思路是: 首先利用一个值函数迭代过程
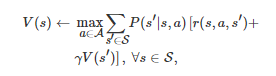
(8)
来获得最优策略π∗ 对应的值函数
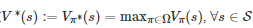
; 然后, 借助得到的V∗(s) 计算一个Q值函数Q∗(s,a):=Qπ∗(s,a), 这里Qπ∗(s,a) 是策略π∗ 对应的Q值函数, 其定义为
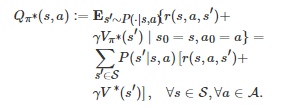
因为V∗(s)满足Bellman最优性方程[210]
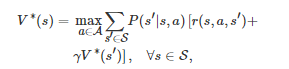
所以
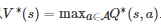
. 因此, 最优策略π∗可选取为
2.3.1 单智能体强化学习
虽然动态规划方法能有效地找到Markov决策过程的最优策略, 但由式(8)可以发现, 该类方法需要明确的模型信息, 比如回报函数r(⋅) 和状态转移概率分布函数P(⋅). 然而, 在大量工程应用, 比如自动驾驶、无人机编队和多机器人协作中, 明确的模型信息通常是一种理想化的条件. 为了弥补这一不足, 学者们于是提出了一类无模型的(Model-free)强化学习方法[197, 211-212], 即智能体利用实时与外部环境交互所获得的激励信号来学习一个最优策略. 基于算法迭代对象的不同, 目前主流的强化学习方法主要可分为两类[49-50]: 基于值函数的(Value-based)方法和基于策略的(Policy-based)方法.⑪
迭代一个Q值表Q(s,a) , ∀(s,a)∈S×A 使得其最终可以精确地或近似地收敛到Q∗(s,a) 是基于值函数方法的一个基本思想. 在该类方法中, 一个著名的算法是所谓的Q学习[85-86], 其迭代表达式为

其中α>0 为学习率参数, r(s,a,s′) 表示智能体采取行动 a并且系统状态从s 转移到s′ 后获得的收益值(它是系统(或环境)反馈给智能体的激励信号).⑪ 然而, 由于随着状态空间和行动空间的增加, Q 值表所需的存储空间和计算资源会呈指数增长, 所以该类方法通常无法处理大规模(Large-scale)决策问题. 为了弥补这一不足, 目前一种可行的方法是在基于值函数的方法中引入神经网络作为函数近似(即深度强化学习)[90, 213]或者使用Monte-Ca-rlo树搜索的方法[214-215]. 除此之外, 另一种可行的方法是基于策略的方法.
该方法的一个基本思想是, 利用参数θ 将策略函数π 参数化为 πθ 以便在整个策略空间中搜索最优的策略. 基于该思想, 一个基本的算法是梯度上升算法, 即沿着策略πθ 对应的长期累积期望回报
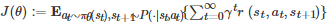
的梯度方向来搜索最优的策略
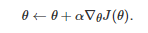
(9)
特别地, 在适当的条件下, 式(9)中的梯度∇θJ(θ)可由Sutton等推导的策略梯度定理(Policy gradient theorem)[207-208]给出, 即
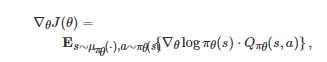
(10)
其中 μπθ(⋅) 是系统状态在策略 πθ 下的平稳分布, Qπθ(s,a) 是策略πθ 对应的Q值函数. 由于式(10)中的Qπθ(s,a) 是未知的, 所以在该算法的具体实施过程中, Qπθ(s,a) 的值通常需要借助一些近似方法来估计. 例如, 在著名的Actor-critic算法[207-208]中, Qπθ(s,a) 的值在参数θ 更新过程中是通过一个选定参数化形式的Q值函数Qω(s,a) 来估计的, 其中参数ω 的更新过程是借助时序差分学习(Temporal-difference learning)来实现的, 即
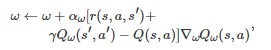
这里αω>0 表示参数ω 的学习率. 另外, 通过改进上述基于策略梯度定理的梯度上升算法, 最近的相关文献也相继提出了一些其他形式的基于策略的学习算法, 比如确定性策略梯度算法DPG[216]、深度确定性策略梯度算法DDPG[217]、信赖域策略优化算法TRPO[218]、近端策略优化算法PPO[219]、异步优势Actor-critic算法A3C[220]和软Actor-critic算法SAC[221]等.
2.3.2 多智能体强化学习
标准的Markov决策过程刻画的只是单个智能体面临的序贯决策问题. 如果实际的决策问题是由多个智能体构成, 那么这一模型框架的适用范围将受到极大限制. 有鉴于此, 目前数学上为了描述多智能体序贯决策问题, 一种普遍使用的模型框架是Markov决策过程在多智能体场景下的拓展形式, 即随机博弈(也称为Markov博弈). 相应地, 为了寻找随机博弈这类多智能体场景下的最优决策, 上述两类单智能体强化学习算法也可拓展到多智能体情形中.
对应于基于值函数的方法, 如果随机博弈中的博弈者是完全合作的, 即此时的博弈是一个团队随机博弈, 那么单智能体的Q学习运用到多智能体场景中只需将单个智能体的行动修改为所有智能体的行动组合[222-223], 即
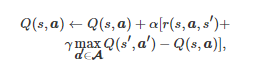
其中a 和A 分别表示所有智能体的行动组合和行动组合空间. 相较而言, 如果随机博弈中的博弈者是完全竞争的, 即此时的博弈是一个两人零和随机博弈, Minimax-Q学习是单智能体的Q学习运用到完全竞争的博弈环境中的一种拓展形式[35], 即对于博弈者11, 其Q值表的迭代表达式为
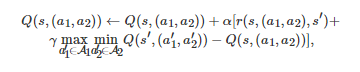
其中ai 和Ai 分别表示博弈者i (i=1,2) 的行动和行动空间. 除此之外, 如果随机博弈中的博弈者既不是完全合作的, 又不是完全竞争的, 即此时的随机博弈为一般和随机博弈, 那么单智能体的Q学习运用到多智能体场景中就需要借助非合作博弈论的结果. 例如, 在Nash-Q算法[39]中, 每个博弈者i 将维持如下一个Q值表的迭代
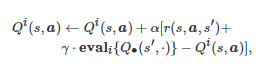
其中Qi(s,a) 表示博弈者 i 在状态 s和所有博弈者行动组合a下的Q值函
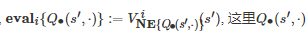
, 这里Q∙(s′,⋅) 表示系统状态为s′时的Q值表,

计算得到的Nash均衡策略, 表示当所有博弈者的策略组合为Nash均衡策略 时, 博弈者i 从初始状态s′ 出发所能获得的长期累积期望收益. 值得注意的是, 在适当的条件下, 上述三类基于值函数的多智能体强化学习算法在理论上均能保证收敛[35, 39, 222-223].
对应于基于策略的方法, 上述单智能体的梯度上升算法拓展到多智能体场景中的一个基本思路是: 首先将每个博弈者i 的策略πi 借助参数θi 参数化为πi,θi , 然后沿着每个博弈者i的长期累积期望回报
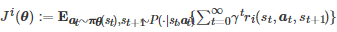
的梯度方向更新参数θi , 即
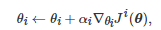
(11)
其中αi表示对应于博弈者i 的学习率参数, θ 表示所有θi 构成的参数组合, πθ 表示所有博弈者的策略πi,θi 构成的策略组合. 特别地, 在适当的条件下, 式(11)中∇θiJi(θ) 可由策略梯度定理在多智能体场景下的推广形式给出[40], 即
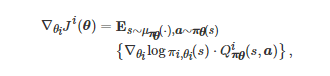
其中μπθ(⋅) 表示系统状态在策略组合πθ下的平稳分布,
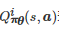
表示博弈者ii在策略组合πθ 下的Q值函数.
虽然多智能体强化学习相比于单智能体强化学习具有一些显著优势, 比如具有更宽的适用范围、更高的鲁棒性和容错性, 并且可以使用通信进行经验分享等[47, 224], 但它也面临着比单智能体强化学习更多更难的挑战, 比如维数灾难(The curse of dimensionality)和可扩展性(Scalability)问题、非平稳性(Non-stationarity)问题、部分可观性(Partial observability)和不完全信息(Incomplete information)问题、不确定性(Uncertainty)和安全性(Safety and security)问题、协调(Coordination)和异质性(Heterogeneity)问题、可解释性(Explainability)问题, 以及探索与利用之间的权衡性(Exploration-exploitation trade-off)问题等(这些问题的最新相关研究进展可参见文献[47, 49-50, 186, 225-232]).
2.4 鲁棒学习
标准的单智能体和多智能体强化学习虽然能有效地处理Markov决策过程和随机博弈描述的序贯决策问题, 但它们并没有考虑诸如参数摄动、建模误差、外界干扰和结构变化等带来的系统不确定性问题. 为了进一步处理这类含不确定性的序贯决策问题, 目前一种有效的方法是在标准的强化学习算法基础上发展鲁棒方法, 即所谓的鲁棒强化学习[233].⑬
与标准的强化学习方法相类似, 鲁棒强化学习也是一类多领域交叉的研究方法, 它与鲁棒优化、鲁棒控制和博弈论都有着紧密的联系[233-234]. 具体地, 从数学上讲, 它的模型框架是一类称为鲁棒Markov决策过程(也称为不确定Markov决策过程)的模型[235-236]. 所谓鲁棒Markov决策过程是指一类含不确定参数的Markov决策过程. 例如, 在该类模型中, 一种典型的设置是假定标准的Markov决策过程的状态转移概率分布函数PP不是给定的, 而是属于一个不确定集PP. 在该设置下, 为了获得鲁棒Markov决策过程的一个最优策略, 一种常用的方法是鲁棒优化方法[179]或者鲁棒控制方法[237], 即在不确定参数最坏的情况下求解一个最优策略. 在相关文献中, 该策略也称为鲁棒最优策略. 具体来讲, 对于一个具有不确定状态转移概率分布函数P∈P的Markov决策过程,
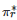
是其一个鲁棒最优策略当且仅当
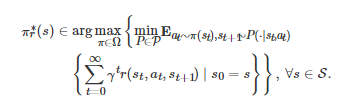
(12)
传统上, 为了找到该鲁棒最优策略, 一种常用的方法是鲁棒动态规划方法[238-239], 比如鲁棒值迭代(Robust value iteration, RVI)算法和鲁棒策略迭代(Robust policy iteration, RPI)算法[238-239]. 具体地, 对于RVI算法, 它的值函数迭代表达式为
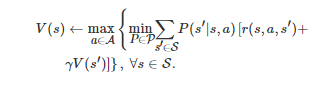
(13)
而对于RPI算法, 它的策略迭代过程主要包含两步: 第1步借助Bellman方程
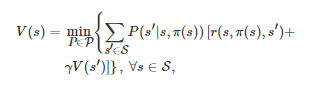
求解一个给定策略π对应的值函数V(s) , ∀s∈S (该步骤的求解可通过标准的动态规划方法来实现); 第2步利用得到的值函数V(s) 获得一个提升的策略π′ , 即
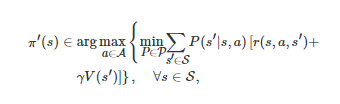
(14)
然后, 令π=π′ 并回到第1步; 最后, 当π 收敛到鲁棒最优策略时, 迭代停止. 特别地, 上述RPI算法的思想也是著名的生成对抗网络GAN[240]的基本思想. 虽然当不确定集PP满足“垂直性” (Rectangularity property)时(即对不同的状态—行动对(s,a) , P(⋅∣s,a) 所在的不确定集是相互独立的并且与历史访问的状态和行动无关), RVI算法和RPI算法都将收敛到一个鲁棒最优策略[238-239], 但它们也存在着一些不足之处. 例如, RVI算法通常收敛较慢, 而RPI算法由于需要求解Bellman方程, 计算量通常较大. 为了进一步优化这两个算法, 文献[241]提出了鲁棒修正策略迭代 (Robust modified policy iteration, RMPI)算法, 进而给出了这两个算法的一个统一形式.
由式(13)和式(14)可以发现, 鲁棒动态规划方法本质上是一种极大极小化的方法, 或者说它是一种在最坏情况下求最优解的方法. 因为这类方法只考虑在不确定参数最坏的情况下求解一个最优性能指标, 所以它是一种比较保守的(Conservative)方法. 为了弥补这一不足, 后续的相关研究在这方面进行了一些改进. 从方法论上讲, 它们主要可分为3类. 第1类为折衷(Trade-off)的方法[242-244]. 该类方法的基本思想是, 首先将不确定参数名义上的(Nominal)性能指标和最坏情况下的性能指标进行组合, 然后将组合后的结果作为最终的目标性能指标. 第2类方法主要以放宽垂直性假设为目标. 例如, 通过放宽垂直性假设, 文献[245]和文献[246]分别提出了一类k垂直性不确定集(k-rectangular uncertainty set)方法和一类因子矩阵不确定集(Factor matrix uncertainty set)方法. 第3类为分布鲁棒优化(Distributionally robust optimization)方法[247-248]. 该类方法的一个基本思想是, 在不确定参数P的概率分布Dp 属于不确定集 Ud 的情况下, 将鲁棒最优策略
所需满足的条件(12)修改为
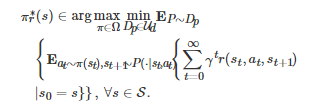
(15)
由式(15)可以看出, 分布鲁棒优化方法将最坏情况下的性能指标修改成了风险最小化(Risk minimization)或风险厌恶(Risk averse)的性能指标.
然而, 与标准的动态规划方法相类似, 一方面, 当Markov决策过程的状态空间和行动空间非常大时, 鲁棒动态规划方法同样会面临维数灾难问题; 另一方面, 鲁棒动态规划方法也需要准确的模型信息. 为了弥补这两方面的不足, 目前一种有效的方法是基于鲁棒动态规划方法发展无模型的强化学习方法. 例如, 通过引入线性函数近似, 文献[249]和文献[250]分别提出了一类鲁棒近似动态规划算法和一类鲁棒近似修正策略迭代学习算法; 而文献[251]提出了一类鲁棒最小二乘策略评估学习算法和一类鲁棒最小二乘策略迭代学习算法. 除了线性函数近似方法之外, 文献[252-254]和文献[255]通过借助深度神经网络这一非线性函数近似方法, 分别提出了一类鲁棒对抗强化学习算法和一类鲁棒最大后验策略优化算法. 另外, 为了求解分布鲁棒优化意义下的鲁棒最优策略, 文献[256]和文献[257]分别提出了一类分布鲁棒策略迭代学习算法和一类分布鲁棒离线强化学习算法.
上述介绍的几类鲁棒强化学习算法虽然能较好地弥补鲁棒动态规划方法关于模型信息要求的不足, 但它们大部分考虑的问题仍是单智能体的序贯决策问题. 与标准的Markov决策过程在多智能体场景下的随机博弈形式相类似, 鲁棒随机博弈是鲁棒Markov决策过程在多智能体场景下的拓展形式. 为了研究这类多智能体场景下的不确定序贯决策问题, 当前一些相关工作也提出了一些鲁棒多智能体强化学习算法. 例如, 为了找到鲁棒随机博弈的鲁棒Markov完美均衡, 文献[258]分别提出了一个鲁棒多智能体Q学习算法和一个鲁棒多智能体Actor-critic学习算法. 而文献[259]考虑了一类鲁棒团队随机博弈
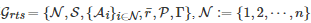
. 相较于标准的随机博弈, 该文提出的鲁棒团队随机博弈Grts 具有两方面的显著差异: 一方面, 博弈中的状态转移概率分布函数P 不是给定的, 而是属于不确定集P , 即P∈P ; 另一方面, 对于任意的博弈者i∈N , 它的决策目标是在P∈P 最坏的情况下, 最大化整个团队的平均收益的长期累积期望值, 而不是最大化其自身的收益 ri 的长期累积期望值 . 类似于的计算表达式(3), 的计算表达式为
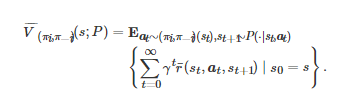
为了求解鲁棒团队随机博弈Grst 在鲁棒优化意义下的最优策略(即在不确定参数P 最坏情况下的最优团队策略), 该文定义了一个称为 “鲁棒团队最优策略” (Robust team-optimal policy)的博弈解概念, 即策略组合
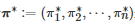
是 Grst 的一个鲁棒团队最优策略当且仅当
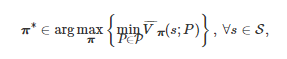
这里π:=(π1,π2,⋯,πn) . 随后, 为了找到该鲁棒团队最优策略, 该文基于“集中式学习分布式实施” (Centralized learning with decentralized execution)的算法框架提出了一个鲁棒团队策略迭代学习算法, 并在适当的条件下证明了该算法的收敛性. 特别地, 相比于RVI、RPI和RMPI算法, 该文提出的算法不仅能够利用近似计算来缓解大规模决策问题中存在的维数灾难问题, 而且还具有更快的收敛速率.
2.5 小结
对应于上节介绍的标准式博弈、演化博弈、随机博弈和不完全信息博弈, 本节主要梳理并介绍了这4类基本博弈形式下的多智能体学习方法, 即策略学习、学习动力学、强化学习和鲁棒学习. 对应于标准式博弈, 本节主要介绍了策略学习这类多智能体学习方法, 并重点对虚拟对弈学习过程进行了论述. 虚拟对弈是通过记录对手博弈者过去所采用行动的频率来推断其策略的一种学习方法. 因此, 本质上讲, 它是一类数据驱动的博弈学习方法. 然而, 由于多智能体的学习环境通常会引发非平稳性问题, 所以本节还简要地回顾了一些更为复杂的策略学习方法, 比如忽视、遗忘、响应目标对手和心智理论等. 对应于演化博弈, 本节主要讨论了学习动力学这类交叉研究方法, 并重点介绍了Cross学习和Q学习在无穷小策略更新步长条件下与复制动力学方程的等价性. 此外, 该部分还简要比较了统计物理和AI这两个领域在该主题上的不同研究风格, 并介绍了一个多智能体强化学习与随机性演化博弈动力学相结合的工作. 对应于随机博弈, 本节主要讨论了单智能体强化学习与多智能体强化学习之间的联系与异同. 考虑到Markov决策过程是随机博弈在单智能体情形下的退化形式, 这部分首先介绍了几类单智能体强化学习方法; 然后, 基于随机博弈的模型框架, 集中对这几类单智能体强化学习算法在多智能体场景下的拓展形式进行了回顾. 最后, 对于不完全信息博弈, 本节主要介绍了鲁棒Markov决策过程和鲁棒随机博弈之间的关系, 以及求解它们的鲁棒动态规划、鲁棒强化学习和鲁棒多智能体强化学习方法.
3. 博弈、学习与控制的交叉研究
由于目前博弈、学习与控制这一交叉研究领域仍处于发展初期, 不同主题之间的研究工作相对独立, 所以本节将主要按照不同专题的方式梳理并介绍其中的几类典型研究成果, 即基于最优控制的学习与博弈、博弈控制系统、基于矩阵半张量积的博弈控制论、分布式Nash均衡搜索和基于零行列式策略的收益控制.
3.1 基于最优控制的学习与博弈
最优控制[237, 260-261]是一类在特定的约束条件下, 寻找控制输入使得动态系统的性能指标达到最优的数学方法. 传统上, 该类方法的两个基本数学原理分别是Pontriagin的极大值(或者极小值)原理和Bellman的动态规划理论[262], 其中前者为最优控制问题的最优解提供了必要条件, 而后者通过求解Hamilton-Jacobi-Bellman (HJB)方程为最优控制问题的最优解提供了充分条件. 然而, 由于这些传统的方法一般都需要系统的完全信息, 所以它们通常无法处理系统动力学存在不确定性的情况. 为了弥补这一不足, 目前一种有效的方法是在最优控制问题的求解过程中引入学习的技术, 比如连续时间场景下的强化学习算法[54-55, 263]和自适应动态规划方法[264-265]等. 该研究思路也是经典的 “学习控制系统” (Learning control system)的基本思路[266].
具体地, 考虑一个连续时间动态系统⑭
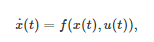
(16)
其中
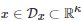
表示系统的状态, 表示系统的控制输入或控制策略, 为一向量值函数. 基于动力学约束(16), 最优控制求解的问题是, 寻找一个控制输入u(t)=μ(x(t)) 使得系统从初始状态x(t0) 出发最小化整个时间区间[t0,∞) 内的累积成本
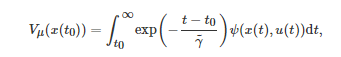
其中Vμ(x(t0)) 表示在控制策略u(t)=μ(x(t)) 下从初始状态x(t0) 出发的值函数;
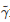
为一正常数, 表示未来成本的折现率; 对应于系统状态x(t) 和控制输入u(t) , ψ(x(t),u(t)) 表示系统在连续时间tt的即时成本. 对应于初始状态x(t0), 记上述最优控制问题的最优控制输入为u∗(t)=μ∗(x(t)) . 于是, 最优值函数V∗(x(t0)) 可写为
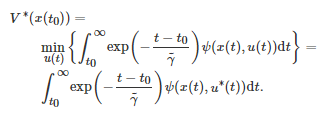
(17)
将式(17)中的积分项按时间区间[t0,t0+Δt]和[t0+Δt,∞]划分为两部分之和, 随后利用最优性原理并令Δt→0可得HJB方程为
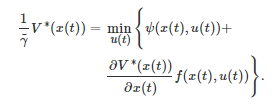
(18)
因为最优控制 u∗(t)=μ∗(x(t)) 是值函数 V∗ 对应的控制输入, 所以如果一旦知道V∗ , 那么由式(18) HJB方程可得
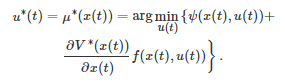
然而, 由式(18)可以看出, 获取值函数V∗需要求解一个偏微分方程, 这在数学上通常是困难的. 为了解决这一难题, 目前一种有效的做法是利用强化学习算法来获得HJB方程的一个近似解. 例如, 对于上述连续时间最优控制问题, 为了找到最优控制输入u∗(t) , 文献[263]提出了一个连续时间Actor-critic强化学习算法和一个基于值函数的梯度学习算法. 另外, 为了验证这两个算法的有效性, 该文还分别在几个连续时间控制任务上进行了数值仿真并获得了良好的效果. 特别地, 当上述最优控制问题中的
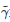
、ψ(x(t),u(t)) 和f(x(t),u(t)) 分别取为、时, 文献[267]研究了该类系统的最优调节问题(Optimal regulation problem), 即是否可以找到一个最优控制输入使得值函数最小的同时系统的状态可收敛为0, 其中0表示适当维数的全00向量, Q(x(t)) 和R分别为非负实数和正定矩阵(Q(x(t))只当 x(t)=0时才为 0), 分别表示系统的漂移动态(Drift dynamics)和输入动态(Input dynamics). 为了求解这一问题, 该文基于Actor-critic算法架构并借助神经网络作为值函数近似, 提出了一个同策略(On-policy)积分强化学习算法, 并且在适当的条件下证明了该算法的收敛性. 然而, 由于同策略的算法在训练时需要大量的数据样本, 所以在实际应用中, 该类算法的数据利用率通常较低. 为了弥补这一不足, 文献[268]在文献[267]的基础上引入了经验回放(Experience replay)技术, 提出了一个带经验回放的同策略积分强化学习算法. 而文献[269]通过引入异策略(Off-policy)方法, 提出了一个异策略积分强化学习算法.
上述连续时间最优控制问题处理的只是单个智能体面临的控制决策问题. 当系统的智能体数由单个变为多个时, 该单智能体最优控制问题可转变为一个微分博弈(Differential game)[270]问题. 一般地, 一个nn人微分博弈通常可描述为如下的一个多智能体最优控制问题[271-272]
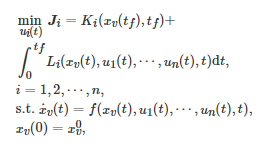
(19)
其中Ji 表示博弈者i (i=1,2,⋯,n) 的长期代价函数, ui(t)∈Rλi 表示博弈者i在连续时间t的控制输入, xv(t):=(x1(t),x2(t),⋯,xn(t)), xi(t)∈Rκi 表示博弈者i在连续时间t的状态, Ki(⋅) 和Li(⋅) 分别表示博弈者i在终止时刻tf 的代价函数(Terminal cost function)和整个时间区间[0,tf]的运行代价函数(Running cost function), 并且它们都是关于各自自变量的连续函数.
特别地, 考虑上述微分博弈的一个二次型情形, 即每个博弈者ii的长期代价函数和系统动力学分别为
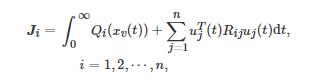
和
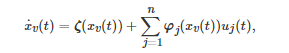
其中
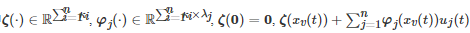
是局部Lipschitz的, 对任意的i=1,2,⋯,n , Qi(⋅) 和Rii 分别是非负实数和正定矩阵, 对于i≠j , Rij 是非负定矩阵. 对于该二次型微分博弈, 首先定义博弈者ii在控制组合(u1,u2,⋯,un) 下对应于系统状态 xv(t) 的值函数Vi(xv(t)) 为
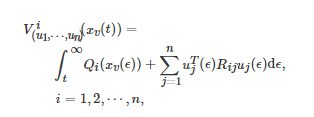
(20)
其中
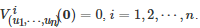
随后在式(20)等号两端分别关于t 求微分, 整理之后可得
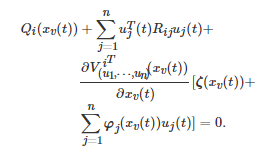
将上式等号左端的项定义为Hamiltonian函数
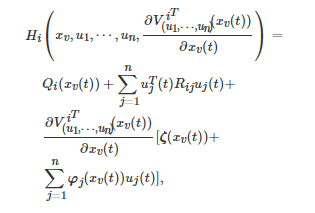
于是, 利用Pontriagin的极小值原理, 博弈者i 的最优控制输入
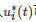
可写为
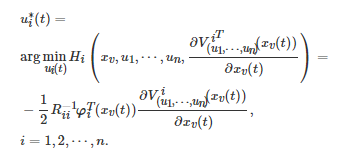
最后, 将每个博弈者i 的最优控制输入
代入到上述Hamiltonian函数中, 有耦合的Hamilton-Jacobi (HJ)方程为
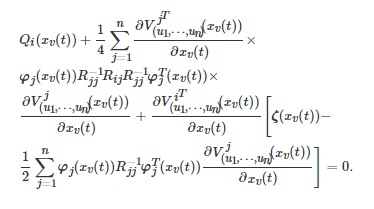
类似地, 考虑到该耦合的HJ方程为一个偏微分方程, 文献[273]基于Actor-critic算法框架提出了一个策略迭代强化学习算法用于求解其近似解, 并证明了该算法将收敛到上述二次型微分博弈的一个Nash均衡.
虽然上述标准的微分博弈模型将单智能体最优控制问题推广到了多智能体系统中, 但它并没有考虑博弈者之间的空间交互关系. 为了弥补这一不足, 文献[274-275]进一步将基于微分博弈的强化学习框架扩展到了图博弈(或网络博弈)的研究中. 另外, 考虑到在自然界和人类社会中, 智能体之间的地位和分工并不是等同的, 而是具有层级结构的, 文献[276]研究了一类单领航者多跟随者的非线性系统Stackelberg博弈, 并基于值函数迭代提出了一个用于求解该博弈均衡策略的两层积分强化学习算法.
3.2 博弈控制系统
博弈控制系统(Game-based control system, GBCS)[277-280]是由两类不同的智能体组成的一个两层控制系统, 其中上层是由单个智能体构成的宏观调控者(Regulator), 下层是由n个博弈者形成的一个非合作微分博弈. 在进行决策时, 上层宏观调控者首先进行决策, 随后下层的n个博弈者依从于上层宏观调控者的决策作出最大化自身利益的决策. 换句话讲, 上层宏观调控者并不实际地参与下层博弈者形成的博弈, 而是对下层的博弈进行调控以期达到系统能控(Controllability)和可镇定(Stabilizability)等整体控制目标. 由于每个下层博弈者在决策时都是追求自身利益最大化, 所以Nash均衡通常是下层微分博弈的一个结果.
具体地, 在该博弈控制系统中, 所有智能体状态的动力学方程为
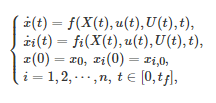
(21)
其中
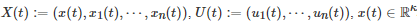
分别表示上层宏观调控者和下层博弈者i在连续时间 t 的状态, 分别表示上层宏观调控者和下层博弈者i 在连续时间t 的控制输入或控制策略. 每个下层博弈者i 在连续时间区间 [0,tf] 内的代价函数Ji 为
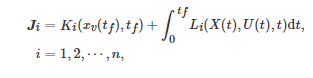
其中xv(⋅) 、Ki(⋅) 和Li(⋅) 的定义与式(19)中的定义相同.
虽然上述博弈控制系统与标准的Stackelberg博弈[281]在含义上具有一些相似之处, 但由于博弈控制系统中的上层宏观调控者是一个控制者, 而不是如同标准的Stackelberg博弈那样是一个博弈参与者, 所以本质上它们属于两类完全不同的系统[24, 278]. 特别地, 上述博弈控制系统更多地表现为一个控制系统而不仅仅是一个博弈系统. 因此, 对于这类系统, 一个基本的问题是系统能控性问题, 即宏观调控者是否可以通过控制输入u(t) 使得状态x(t) 能从任意初始状态
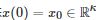
被驱动到任意目标终止状态. 为了研究这一问题, 考虑上述博弈控制系统的一个一般线性二次型情形
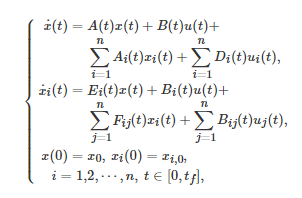
其中每个下层博弈者i在连续时间区间 [0,tf][0,tf] 内的代价函数Ji 为
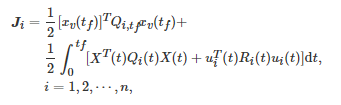
对任意的t∈[0,tf] , Ri(t)>0 、Qi(t) 和Qi,tf 是对称的, 并且系统中的所有参数矩阵都是关于时间变量tt的分段光滑的函数. 在适当的条件下, 文献[278]首次给出了该一般线性二次型博弈控制系统能控性的充分必要的代数条件.
由式(21)可以看出, 上述博弈控制系统是一类确定性的系统. 为了进一步对随机场景下的博弈控制系统进行研究, 文献[279]相应地提出了一类随机性博弈控制系统. 在该类系统中, 系统状态的动力学方程和每个下层博弈者i在连续时间区间[0,tf] 内的代价函数Ji 分别为
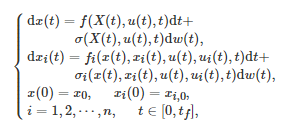
和
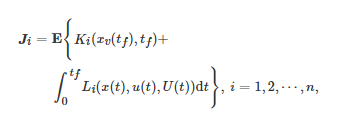
其中w(t) , t≥0 是一个标准的d 维Brownian运动. 为了研究该随机性博弈控制系统的能控性问题, 文献[279]分别提出了一个精确V-能控性(Exact V-controllability)和一个完全能控性(Total controllability)的概念. 特别地, 对于一类一般线性时变博弈控制系统, 该文给出了此类系统精确V-能控性的充分必要的代数条件, 而对于一类一般线性时不变博弈控制系统, 该文给出了此类系统完全能控性的充分必要的代数条件.
除了能控性之外, 系统是否可镇定在控制理论中也是一个十分重要的基本问题. 对于一类线性二次型微分博弈控制系统, 文献[280]首次研究了此类系统的镇定性问题, 即上层宏观调控者是否可以通过调节下层博弈者形成的Nash均衡来实现系统的镇定. 在适当的条件下, 该文首次给出了此类系统可镇定的充分必要的代数条件. 此外, 在系统参数不确定的情况下, 文献[282-284]通过结合微分博弈与随机自适应控制理论, 提出了一类随机自适应微分博弈系统, 并在适当的条件下, 给出了该类系统渐近地达到一个Nash均衡的稳定性判据.
3.3 基于矩阵半张量积的博弈控制论
矩阵半张量积(Semi-tensor product of mat-rices)[285]是对传统矩阵乘法的一般化推广. 它是由中国学者程代展先生首次提出并发展的一套数学方法. 一般地, 对于两个矩阵M1∈Mp1×q1 和M2∈Mp2×q2 , 它们的半张量积M1⋉M2 定义为如下的一个矩阵乘积形式
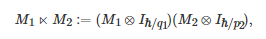
(22)
其中Mp1×q1表示所有 p1×q1 矩阵的集合, ⋉ 表示矩阵的半张量积符号, ⊗ 表示矩阵的Kronecker积符号, ℏ=lcm(q1,p2) 为q1 和p2 的最小公倍数, Ik , k∈N 表示k×k 单位矩阵. 由定义式(22)可以看出, 当q1=p2 时, M1 与M2 的半张量积将退化为通常的矩阵乘积. 特别地, 因为矩阵半张量积在数学上具有一些优良性质, 比如分配律、结合律和伪交换律等[285], 所以该方法目前在逻辑控制系统(Logical control system)[286]、有限的标准式博弈[287-288]和博弈控制论(Game-theoretic control)[58, 289]等研究领域中得到了广泛应用.
对于一个n人有限的标准式博弈, 运用矩阵半张量积方法进行研究的一个基本思路是, 首先将每个博弈者ii的策略集 Ωi 表示成一个向量形式的集合, 然后利用矩阵半张量积方法将博弈者策略的演化动态方程转化成一个逻辑控制系统. 具体来讲, 对于博弈者ii的策略πi∈Ωi , i=1,2,⋯,n , 首先令xi 为πi 的列向量表示, 这里假定策略集Ωi 的势为|Ωi|=ki . 然后, 对于k×k 单位矩阵Ik , 定义Δk:=Col(Ik) 为Ik 的所有列构成的集合. 于是, 对应于博弈者ii策略的向量表示xi , 策略集Ωi 的向量表示可写为Δki , 即xi∈Δki . 另外, 借助上述定义的符号, 博弈者i 的收益函数的向量形式可写为
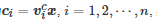
, 其中行向量称为ci 的结构向量, 为所有博弈者策略组合的向量表示. 特别地, 如果博弈者参与的博弈是一个重复博弈并且博弈者策略的演化过程是Markov型的, 那么每个博弈者策略的演化动态方程可一般化地写为
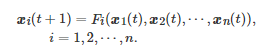
(23)
因为对任意的i∈{1,2,⋯,n} , Fi(⋅) 是一个有限集到有限集的映射, 所以存在一个对应于映射组合(F1,F2,⋯,Fn) 的唯一矩阵M 使得式(23)可进一步改写为如下的一个逻辑系统[288]
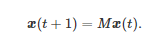
上述过程基本上展示了一个有限的标准式博弈是如何通过矩阵半张量积方法转化为一个逻辑系统的. 它也是矩阵半张量积方法应用于有限的标准式博弈的一个核心思想.
除了有限的标准式博弈之外, 势博弈(Potential game)[287, 290]是矩阵半张量积方法应用于博弈控制与优化问题的另一典型形式. 对于一个有限的标准式博弈
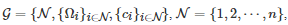
, 如果存在一个函数W:Ω→R 使得对任意的i∈N ,
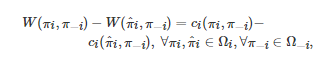
则称G 为一个势博弈, W 为该势博弈的势函数. 矩阵半张量积方法应用于势博弈的一个通常处理的问题是最大化一个总体性能指标J(π1,π2,⋯,πn) . 该问题的基本求解框架一般可分为2步: 第1步对每个博弈者的收益函数进行设计, 使得整个博弈系统成为以J(π1,π2,⋯,πn) 为势函数的势博弈; 第2步为每个博弈者设计控制策略或学习算法, 使得当每个博弈者i 最大化其自身的收益函数ci 时, 整体系统可收敛到J(π1,π2,⋯,πn) 的最大值点(也是势博弈的均衡点)[288]. 目前, 该研究框架已在多智能体系统的博弈控制问题[291]和状态依赖的博弈策略学习问题[292]中得到了成功应用.
当前, 利用矩阵半张量积方法处理博弈控制与优化问题已经取得了十分丰硕的成果, 一个更为全面的总结可参见文献[288].
3.4 分布式Nash均衡搜索
分布式Nash均衡搜索是一类利用分布式控制与优化[115, 293-294]的技术搜索博弈Nash均衡解的方法. 由于该类方法在移动传感器网络、智能电网以及无人机编队中具有广泛的应用前景, 所以吸引了大量控制领域学者的关注.
一般地, 由定义 1 可知, 求解一个n 人标准式博弈
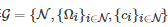
的Nash均衡点等价于寻找一个策略组合 使得对任意的i∈N ,
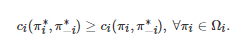
特别地, 如果每个博弈者i∈N 的策略集Ωi 依赖其对手的策略π−i , 则称上述标准的Nash均衡问题为广义Nash均衡问题(Generalized Nash equilibrium problem)[295]. 另外, 为了保证上述Nash均衡问题解的存在性, 文献中经常使用的一个假设是[37, 296]: 对任意的i∈N , Ωi 是一个非空凸紧集, 并且对任意给定的π−i∈Ω−i , ci(πi,π−i) 是一个关于πi∈Ωi 的连续可微的凸函数. 在该假设下, 求解博弈G 的一个Nash均衡解可等价为求解如下的一个变分不等式(Variational inequality)问题[296-297]
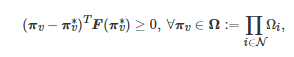
(24)
其中
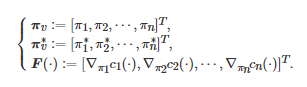
因为博弈G中的每个博弈者i 的收益函数ci(⋅)不一定是相同的, 所以F(⋅)并不是传统意义上的梯度. 因此, 为了和通常的梯度相区别, 一般称
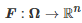
为伪梯度映射(Pseudo-gradient map). 另外, 由文献[297]中的命题1.5.81.5.8可知, 是变分不等式(24)的解当且仅当是如下方程的不动点

(25)
其中PΩ(πv)表示πv 在集合Ω上的Euclidean投影. 利用该等价性结论, 求解博弈G的Nash均衡则可转变成求解式(25)的不动点. 传统上, 为了实现该不动点的求解, 一种常用的方法是投影梯度(Projected gradient-play)算法. 具体地, 对应于离散时间k (k∈N)和连续时间t (0≤t∈R) , 该算法的离散时间版本和连续时间版本分别为
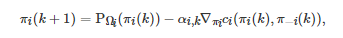
(26)
和
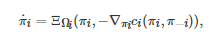
(27)
其中πi(k) 表示博弈者i 在迭代时刻k 的策略, αi,k 表示博弈者i 在迭代时刻 k的学习率,
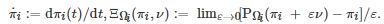
特别地, 如果伪梯度映射F是Lipschitz连续的且严格单调的(或强单调的), 上述两个投影梯度算法在理论上均可收敛到博弈G 的一个Nash均衡点[297-298].
由投影梯度算法(26)和(27)可以看出, 每个博弈者在更新自己策略的过程中不仅需要自身的收益信息而且还需要所有其他博弈者的策略信息. 这一要求在实际系统中(尤其在网络化系统中)通常是较难满足的. 为了弥补这一不足, 分布式Nash均衡搜索方法通常假定每个博弈者并不能获得所有其他博弈者的信息, 而只能通过一个通信网络来获得其直接邻居的信息. 基于这一假定, 文献[299]利用异步Gossip方法提出了一个离散时间分布式投影梯度算法, 而文献[300]利用伪梯度映射的增量无源性(Passivity)提出了一个连续时间分布式投影梯度算法. 在适当的条件下, 这两个分布式算法在理论上均能几乎必然地收敛到一个Nash均衡点[299-300]. 另外, 当博弈者的收益函数满足二阶连续可微条件时, 文献[301]基于领航者—跟随者一致性方法提出了一类连续时间分布式算法, 并利用Lyapunov稳定性理论证明了该算法的收敛性. 通过考虑每个博弈者的收益函数满足一个聚合映射(Aggregation map)并且所有博弈者的可行策略集满足一个线性耦合约束条件, 文献[302]基于投影动力学和非光滑跟踪动力学, 提出了一个连续时间分布式算法用于求解广义Nash均衡搜索问题. 受上述工作的启发, 通过考虑博弈者的可行策略集同时满足私有约束条件和耦合约束条件, 文献[303]提出了一个连续时间在线分布式原始—对偶Nash均衡搜索算法, 并在适当的条件下证明了该算法的收敛性.
虽然在特定的前提条件下, 上述分布式Nash均衡搜索算法在理论上均能保证收敛到一个Nash均衡点, 但它们绝大部分只能处理固定博弈形式(即博弈者的收益函数是时不变的)的Nash均衡搜索问题. 为了弥补这一不足, 文献[304]进一步对具有时变收益函数的广义Nash均衡搜索问题进行了研究, 并率先提出了一类在线分布式原始—对偶策略学习算法. 在通信网络满足连通性假设条件下, 该文从理论上严格证明了该算法将收敛到一个广义Nash均衡.
3.5 基于零行列式策略的收益控制
粗略地讲, 上述基于最优控制和微分博弈的博弈控制方法大部分都是通过设计或寻找使系统满足某一特定性能指标的控制输入, 来实现对博弈系统动力学的控制(即控制博弈系统动力学的演化行为). 相比之下, 基于零行列式(Zero determinant, ZD)策略[305]的博弈控制方法是一类起源于重复博弈研究, 能够实现单边控制对手期望收益的数学方法. 一般地, 依据对重复博弈的传统认识, 每个博弈者的期望收益通常会随着其对手策略的改变而改变. 然而, ZD策略的发现几乎从根本上改变了这一传统认识[306]: 在一个重复博弈中, 如果中心博弈者的策略为一个ZD策略, 那么不管其对手如何进行策略选择, 中心博弈者总是能够迫使其对手的期望收益达到一个给定的值或者满足一个线性等式关系(即控制对手的期望收益).
具体地, 考虑一个两人两策略对称重复博弈
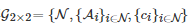
, 其中N={1,2} 为所有博弈者的标号构成的集合, Ai={C,D} , ∀i∈N 为博弈者i 的行动集, 为博弈者i∈N 的收益函数. 对于收益函数ci, ∀i∈N , 其在不同行动组合下的取值所构成的收益值表为
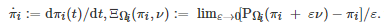
这里“行博弈者” 表示博弈者11, “列博弈者” 表示博弈者22. 在该博弈中, 假定所有博弈者的策略都为一步记忆策略, 即每个博弈者在当前轮博弈中的行动选择只依赖前一轮博弈中所有博弈者的行动组合. 基于该假设, 博弈者11和博弈者22的策略于是可分别写为向量
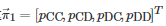
和, 其中paxay∈[0,1]和qaxay∈[0,1]分别表示博弈者11和博弈者22在前一轮博弈中的行动组合为(ax,ay), ax,ay∈A情况下, 于当前轮博弈中选择行动C的概率. 在重复博弈G2×2 进行过程中, 如果两个博弈者采用的策略分别为一步记忆策略, 那么在时间尺度上, 它们将诱导出一个定义在状态空间{CC,CD,DC,DD} 上的Markov链. 特别地, 记该Markov链的转移概率矩阵为, 其中 表示该Markov链从状态axay 转移到状态azaw 的概率.
假定该Markov链是遍历的并且令 μ为其状态的平稳分布(也是Markov链处在每个状态的平均时间的分布)构成的列向量, 即μTP=μT .⑮ 因为P 是一个行随机矩阵, 所以元素全为1的列向量y=1 是方程 (P−I)y=0的一个解, 即P′:=P−I 是奇异的. 因此, P′的行列式为0. 另外, 由Cramer法则可知, adj(P′)P′=det(P′)I=0m , 其中adj(P′) 和det(P′)分别表示矩阵P′ 的伴随矩阵和行列式, 0m 表示元素全为0的矩阵. 由上述两个等式μT(P−I)=0 和adj(P′)P′=0m 可知, adj(P′)的每一行均正比于μT. 特别地, 对于adj(P′)adj(P′)的第4行, 由伴随矩阵的定义可知

∈是任意的四维列向量,是把P′ 的第1列分别加到第2、第3列以及把P′ 的第4列替换为w 之后得到的矩阵的行列式, 即

(28)
以博弈者11和博弈者22的所有可能的收益值作为元素分别构造向量e1=[a,b,c,d] 和e2=[a,c,b,d] . 于是, 这两个博弈者在每轮博弈中所能获得的期望收益可分别计算为
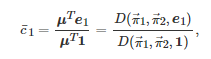
(29)
和
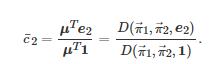
(30)
因为式(29)和式(30)的计算均具有线性性, 所以对任意一组常系数
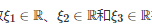
有
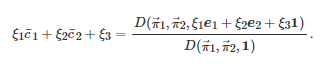
(31)
特别地, 如果博弈者11的策略向量
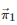
取为或者博弈者22的策略向量取为, 其中的选取需使得或者的每个分量属于[0,1], 那么由式(28)和式(31)可知
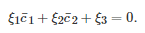
(32)
考虑到上述线性等式(32)的成立是由于策略
或者的选取使得式(28)中的行列式等于0, 文献[305]由此把满足这一特性的策略称为零行列式策略. 由式(32)可以看出, 在重复博弈G2×2中, 任意的一个博弈者都可以通过设定自己的策略来迫使其对手的期望收益满足一个等式约束关系. 例如, 对于博弈者11, 如果其选择的策略为 (即设置ξ1=0), 那么无论博弈者22如何进行策略选择, 它的期望收益将始终保持为. 特别地, 借助并利用pCC 和pDD 分别表示可进一步写为
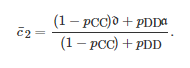
除了单边控制对手的期望收益之外, 通过设定中心博弈者(比如博弈者11)所采用的ZD策略的形式, ZD策略还可以分别实现敲诈行为(即中心博弈者获得一个不低于对手的期望收益)、慷慨行为(即中心博弈者获得一个不高于对手的期望收益)和公平行为(即中心博弈者和对手获得一个同等的期望收益)等[305, 307].
鉴于ZD策略对重复博弈研究的重要贡献, 后续关于ZD策略的讨论在演化博弈领域中掀起了一场研究热潮, 其中推动这一研究热潮的一个关键结果是所谓的Akin引理[308]. 该引理是式(28)的一般化形式, 也是判定一个策略是否为ZD策略的必要条件. 一般地, 对于一个两人两策略对称重复博弈G2×2 , Akin引理可具体地表述为: 如果博弈G2×2 的所有博弈者的策略都为一步记忆策略并且它的所有可能的行动组合{CC,CD,DC,DD} 的平稳分布为μ, 那么对任意的博弈者i∈N:={1,2} , 它的策略向量
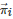
将满足
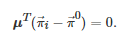
借助Akin引理的各种拓展形式, 后续的相关研究分别将ZD策略推广到了两人两策略折扣重复博弈[309]、两人连续行动空间折扣重复博弈[310]、多人两策略无折扣[311-312]和有折扣重复博弈[313]、多人多策略时变折扣重复博弈[314]等更一般化的博弈形式中. 除了这些拓展性工作之外, 一些相关的研究也讨论了ZD策略本身的一些属性, 比如文献[315]分析了ZD策略的鲁棒性(即采取ZD策略的博弈者面对策略变化的对手是否仍然可以保持期望收益最大化), 文献[307, 316-318]研究了ZD策略的演化稳定性(即ZD策略在自然选择的作用下是否能抵御其他策略的入侵), 而文献[319]则考虑了博弈者的错误认知对ZD策略形式的影响.
3.6 小结
按照不同专题的方式, 本节主要梳理并介绍了博弈、学习与控制这一交叉研究主题的几类典型成果, 即基于最优控制的学习与博弈、博弈控制系统、基于矩阵半张量积的博弈控制论、分布式Nash均衡搜索和基于零行列式策略的收益控制. 在第1部分基于最优控制的学习与博弈中, 首先介绍了一类单智能体连续时间最优控制问题, 并回顾了求解该类问题的强化学习算法; 接着, 当单智能体最优控制问题拓展到多智能体场景中时, 进一步对微分博弈以及求解该类博弈的多智能体强化学习算法进行了介绍. 博弈控制系统是一类试图将现代控制理论与微分博弈相结合的系统. 在这部分内容中, 主要对一类确定性博弈控制系统和一类随机性博弈控制系统的能控性问题进行了介绍; 另外, 为了反映该类系统的最新研究进展, 还对一类线性二次型微分博弈控制系统的镇定性问题和一类随机自适应微分博弈系统的稳定性问题进行了简要的论述. 接着, 在基于矩阵半张量积的博弈控制论这部分内容中, 主要讨论了如何运用矩阵半张量积方法研究有限的标准式博弈和势博弈中的控制与优化问题. 然后, 针对一类Nash均衡求解问题, 本节主要在变分不等式方法的基础上回顾了几类基于分布式控制与优化的搜索算法. 最后, 基于对零行列式策略的讨论, 本节主要梳理并介绍了一类能单边控制对手期望收益的方法.
4. 总结与展望
作为现代数学的一个重要分支和运筹学的一个重要组成部分, 博弈论近年来在学术界受到越来越多的关注. 特别地, 随着多智能体系统和AI等研究领域的兴起, 博弈论、多智能体学习与控制论的交叉融合目前已发展成为一个前沿热点研究方向. 为了及时反映这一学术动态和趋势, 本文从连接这三者的四类基本博弈形式出发, 系统地讨论了它们之间的联系与区别, 论述了它们对应的各类多智能体学习方法, 还回顾了当前几个博弈、学习与控制的交叉研究专题. 作为全文内容的一个总结, 图3左边子图描述了多智能体博弈、学习与控制在宏观层面上的相互联系, 右边子图展示了本文介绍的各类博弈形式、多智能体学习方法和控制论方法之间的内在关联关系(图中的数字表示本文的章节编号).
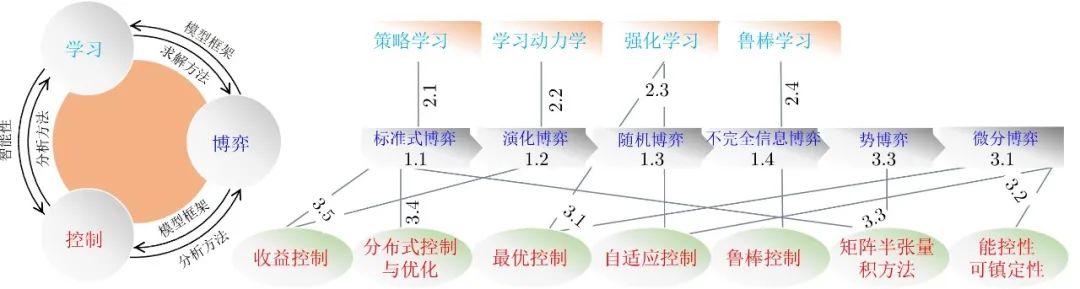
图 3 本文介绍的各类博弈形式、学习方法和控制论方法之间的内在关联关系图
目前, 虽然多智能体博弈、学习与控制这一新兴交叉研究领域已经取得了一些初步成果, 但总体而言, 它仍然处于发展初期, 还有巨大的发展空间. 从大的方向上看, 以下几方面未来还有待于进一步探索.
1)无模型的(Model-free)博弈论或数据驱动的(Data-driven)博弈论. 在博弈论的传统研究中, 大部分工作都是基于特定的博弈模型或者发展新的博弈模型来开展的. 换句话讲, 在这些研究中, 博弈模型是事先设定的并且(或部分)为博弈者所已知的. 因此, 从方法论上讲, 它们属于基于模型的(Model-based)博弈论, 即“白盒” (White-box)的方法. 然而, 在大量与博弈论相关的实际应用, 比如视频游戏、多机器人系统、自动驾驶和无人机集群中, 获取准确的模型信息通常是比较困难的. 例如, 为了实现某些实际应用中的特定任务目标, 博弈者的收益函数通常可能需要进行额外设计[41, 231, 320]. 针对这些无模型的博弈应用问题, 如果传统基于模型的博弈论方法继续被使用去求解诸如Nash均衡等博弈问题, 那么它将自然会面临一些理论困境. 为此, 这就十分有必要去发展一类无模型的或数据驱动的博弈论方法, 即利用博弈实时产生的数据或者博弈交互后的离线数据来实现对一个博弈问题的求解(也就是“黑盒” (Black-box)或者“灰盒” (Gray-box)的方法). 目前, 虽然这方面已有一些相关工作, 比如著名的虚拟对弈方法[14, 184]和多智能体强化学习方法, 但总体而言, 这一领域仍处于发展初期, 还有许多不完善之处.
2)博弈论、多智能体学习与控制论的进一步深度融合. 目前, 在自动控制领域中, 博弈、学习与控制的大部分交叉研究工作都是基于最优控制和微分博弈来开展的. 除此之外, 博弈论和控制论本质上还有许多相通之处. 例如, 如果从博弈论的角度来看控制论, 控制系统中的控制器一般可视为博弈中的决策者, 它可以改变受控系统的演化轨迹以期达到某种理想效果; 反过来, 如果从控制论的角度来看博弈论, 博弈中的博弈者一般可视为控制系统中的控制器, 它的决策目标或偏好(Preference)通常可认为是一种控制目标. 因此, 从控制论的角度上讲, 博弈论也被视为是一类研究交互控制器之间的合作与竞争的数学理论[30]. 另外, 作为现代控制论的一个重要组成部分, 鲁棒控制[237]与鲁棒优化[179]、鲁棒博弈[180]以及鲁棒学习[233]在基本思想上均有诸多相似之处. 虽然受安全AI和鲁棒AI[5-6, 321]这一研究主题的驱动, 当前鲁棒的机器学习技术在AI领域中已成为一个热点研究方向, 但鲁棒控制、鲁棒优化、鲁棒博弈和鲁棒学习间的交叉研究在自动控制领域中目前仍比较稀少.
3)建立并发展包含其他博弈形式的学习与控制的研究框架. 本文讨论的博弈形式主要涉及标准式博弈、演化博弈、随机博弈、不完全信息博弈、势博弈和微分博弈. 除了这些基本博弈形式之外, 现代博弈论中还有一些其他新颖形式, 比如扩展式博弈(Extensive-form game)[18, 322-323]、信号博弈(Signaling game)[324]、量子博弈(Quantum game)[325-327]和平均场博弈(Mean-field game)[328-329]等. 因此, 如何建立并发展一个包含其他博弈形式的学习与控制的研究框架将是一个十分值得深入探究的课题.
4)博弈论、动力系统与深度学习的结合. 演化博弈动力学是博弈论与动力系统的一种结合形式. 考虑到当前在机器学习领域中, 动力系统与深度学习的结合是一个广受关注的研究课题[330-332]. 因此, 如果演化博弈动力学可以进一步与深度学习相结合, 那么这在理论上将是十分有意义的. 尽管当前这方面已有一些探索性工作, 比如神经复制动力学[119], 但总体而言, 这一研究方向目前才刚刚兴起并且在理论上还有诸多不完善之处.
5)博弈、学习与控制的交叉研究在一些新兴领域中的应用. 博弈论自诞生以来, 已在经济学、社会学、心理学、生物学、物理学、认知科学和计算机科学等研究领域中得到了大量卓有成效的应用. 近年来, 伴随着AI技术的快速发展, 人们也见证着一些新兴交叉研究领域的兴起, 比如社会智能[1-2]、机器智能[3]、合作智能[4]、AI安全[5-6]和AI伦理[7-8]等. 考虑到这些研究主题本身具有广泛的学科交叉性. 因此, 如何将博弈、学习与控制的交叉研究成果应用于这些新兴领域是未来一个十分值得探究的课题。
本文仅用于学习交流,如有侵权,请联系删除 !!
加 V “人工智能技术与咨询” 了解更多资讯!!