Redis事务控制
1,概念:
redis事务就是一个命令执行的队列,将一系列预定义命令包装成一个整体(一个队列)。当执行时,一次性按照添加顺序依次执行,中间不会被打断或者干扰。一个队列中,一次性、顺序性、排他性的执行一系列命令
2,事务基本操作
开启事务:
multi
作用: 设定事务的开启位置,次指令执行后,后续的所有指定都加入到当前事务中。
执行事务:
exec
作用: 设置事务的结束位置,同时执行事务,exec必须与multi成对使用。在exec和multi之间的命令只是存在了一个任务队列中,实际并没有执行,只有执行了exec命令后,队列中的命令才会顺序执行
取消事务:
discard
作用: 终止当前事务的定义,发生在multi和exec之前。如果取消了事务之后再执行exec,则会报错:(error) ERR EXEC without MULTI
Redis持久化
一:Redis持久化的实现方式
1,Redis持久化是什么?
因为Redis是基于内存的数据库,一旦断电,所有的实例都会关机,因此所有的数据也会丢失,在运行期间,可以通过开启Redis持久化功能,将数据写入磁盘,供实例重启的时候,恢复数据。Redis持久化主要是通过AOF和RDB实现。
2,AOF是什么?
AOF持久化主要是在Redis修改相关的命令执行后,将执行命令添加到aof_buf缓存区(aof_buf是Redis中的SDS结构,可以理解为C语言中的字符串扩展)的末尾,然后在每次事件循环结束后,根据appendfsycn的配置(always是每次事件循环后都将aof_buf内的数据写入,everysec是每秒写入,no是根据操作系统来决定何时写入),判断是否将aof_buf写入到AOF文件。生产环境一般默认配置是:everysec。
struct redisServer {
/* AOF buffer, written before entering the event loop */
sds aof_buf;//aof_buf缓冲区其实就是Redis的一个简单动态字符串
}
struct sdshdr {
unsigned int len;
unsigned int free;
char buf[];
};
事件循环可参考:https://blog.csdn.net/MOU_IT/article/details/115430555
3,RDB是什么?
概念:
RDB是在满足一定的触发条件时(在一个时间间隔内修改命令达到一定数据 | 手动执行SAVE和BGSAVE命令),Redis对数据库内的所有键值对信息生成一个压缩文件dump.rdb,如果dump.rdb已经存在,则用新的替换旧的。Redis默认情况下,RDB开启,AOF关闭。
实现原理:
实现原理是fork一个子进程,然后对键值对进行遍历,生成rdb文件,在生成过程中,父进程会继续处理客户端发送的请求,当父进程要对数据进行修改时,会对相关的内存页进行拷贝,修改的是拷贝后的数据。(也就是COPY ON WRITE,写时复制技术,就是当多个调用者同时请求同一个资源,如内存或磁盘上的数据存储,他们会共用同一个指向资源的指针,指向相同的资源,只有当一个调用者试图修改资源的内容时,系统才会真正复制一份专用副本给这个调用者,其他调用者还是使用最初的资源,在CopyOnWriteArrayList的实现中,也有用到,添加或者插入一个新元素时过程是,加锁,对原数组进行复制,然后添加新元素,然后替代旧数组,解锁)
//CopyOnWriteArrayList的添加元素的方法
public boolean add(E e) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
Object[] newElements = Arrays.copyOf(elements, len + 1);
newElements[len] = e;
setArray(newElements);
return true;
} finally {
lock.unlock();
}
}
3,AOF和RDB的区别
AOF因为是保存了所有执行的修改命令,粒度更细,进行数据恢复时,恢复的数据更加完整,但是由于需要对所有命令执行一遍,效率比较低,同样因为是保存了所有的修改命令,同样的数据集,保存的文件会比RDB大,而且随着执行时间的增加,AOF文件可能会越来越大,所有会通过执行BGREWRITEAOF命令来重新生成AOF文件,减小文件大小。Redis服务器故障重启后,默认恢复数据的方式首选是通过AOF文件恢复,其次是通过RDB文件恢复。
RDB是保存某一个时间点的所有键值对信息,所以恢复时可能会丢失一部分数据,但是恢复效率会比较高。
4,怎么防止AOF文件原来越大
为了防止AOF文件越来越大,可以通过执行BGREWRITEAOF(bgreWriteAof)命令对AOF进行重写,Redis会fork出子进程出来,读取数据库的所有键值对信息,生成所需命令,然后写入AOF文件。
在生成期间,父进程继续处理请求,执行修改命令后,不仅会将命令写入到aof_buf区,还会写入重写aof_buf缓冲区。当新的AOF文件生成以后,子进程会给父进程发送信号,父进程会将重写aof_buf的修改命令,重新写入AOF文件中,写入完毕后,会对新的AOF文件进行改名,原子地替换掉旧的APF文件。
AOF 重写命令可以手动执行,在满足以下条件后也可以自动触发。
- 没有BGSAVE命令在执行
- 没有BGREWRITEAOF在执行
- 当前的AOF文件大小 > server.aof_rewrite_min_size(默认1MB)
- 当前AOF文件大小 >= 上次重写后的AOF文件的2倍
5,AOF文件阻塞
参考:https://blog.csdn.net/qq_39276448/article/details/113698462
二:Redis持久化策略如何选择
RDB持久化的特点是: 文件小,恢复快,不影响性能,实时性低,兼容性差(老版本的Redis不兼容新版本的RDB文件) AOF持久化的特点是: 文件大,恢复慢,性能影响大,实时性高。是目前持久化的主流(主要是当前项目开发不太能接受大量数据丢失的情况)。 需要了解的是持久化选项的开启必然会造成一定的性能消耗。
两种持久化方式的缺点:
- RDB持久化主要在于bgsave在进行fork操作时,会阻塞Redis的主线程。以及向硬盘写数据会有一定的I/O压力。
- AOF持久化主要在于将aof_buf缓冲区的数据同步到磁盘时会有I/O压力,而且向硬盘写数据的频率会高很多。其次是,AOF文件重写跟RDB持久化类似,也会有fork时的阻塞和向硬盘写数据的压力。
常见场景下的持久化方案选择场景:
1,不需要考虑数据修改的情况?
不需要考虑数据
2,单机实例情况下:
可以接受丢失十几分钟及更长时间的数据,可以选择RDB持久化,对性能影响小,如果只能接受秒级的数据丢失,只能选择AOF持久化。
3,在主从环境下:
因为主服务器在执行修改命令后,会将命令发送给从服务器,从服务进行执行后,与主服务器保持数据同步,实现数据热备份,在master宕掉后继续提供服务。同时也可以进行读写分离,分担Redis的读请求。
那么在从服务器进行数据热备份的情况下,是否还需要持久化呢? 需要持久化,因为不进行持久化,主服务器,从服务器同时出现故障时,会导致数据丢失。(例如:机房全部机器断电)。如果系统中有自动拉起机制(即检测到服务停止后重启该服务)将master自动重启,由于没有持久化文件,那么master重启后数据是空的,slave同步数据也变成了空的。应尽量避免“自动拉起机制”和“不做持久化”同时出现。
所以一般可以采用以下方案:主服务器不开启持久化,使得主服务器性能更好。
从服务器开启AOF持久化,关闭RDB持久化,并且定时对AOF文件进行备份,以及在凌晨执行bgaofrewrite命令来进行AOF文件重写,减小AOF文件大小。(当然如果对数据丢失容忍度高也可以开启RDB持久化,关闭AOF持久化)
4,异地备灾
一般性的故障(停电,关机)不会影响到磁盘,但是一些灾难性的故障(地震,洪水)会影响到磁盘,所以需要定时把单机上或从服务器上的AOF文件,RDB文件备份到其他地区的机房。
三:Redis持久化之RDB和AOF混合持久化
1,概念
redis4.0相对与3.X版本其中一个比较大的变化是4.0添加了新的混合持久化方式。前面已经详细介绍了AOF持久化以及RDB持久化,这里介绍的混合持久化就是同时结合RDB持久化以及AOF持久化混合写入AOF文件。这样做的好处是可以结合 rdb 和 aof 的优点, 快速加载同时避免丢失过多的数据,缺点是 aof 里面的 rdb 部分就是压缩格式不再是 aof 格式,可读性差。
2,配置开启
4.0版本的混合持久化默认关闭的,通过aof-use-rdb-preamble配置参数控制,yes则表示开启,no表示禁用,默认是禁用的,可通过config set修改。
3,混合持久化过程
了解了AOF持久化过程和RDB持久化过程以后,混合持久化过程就相对简单了。
混合持久化同样也是通过BGREWRITEAOF完成的,不同的是当开启混合持久化时,fork出的子进程先将共享的内存副本全量的以RDB方式写入aof文件,然后在将重写缓冲区的增量命令以AOF方式写入到文件,写入完成后通知主进程更新统计信息,并将新的含有RDB格式和AOF格式的AOF文件替换旧的的AOF文件。简单的说:新的AOF文件前半段是RDB格式的全量数据后半段是AOF格式的增量数据,如下图:
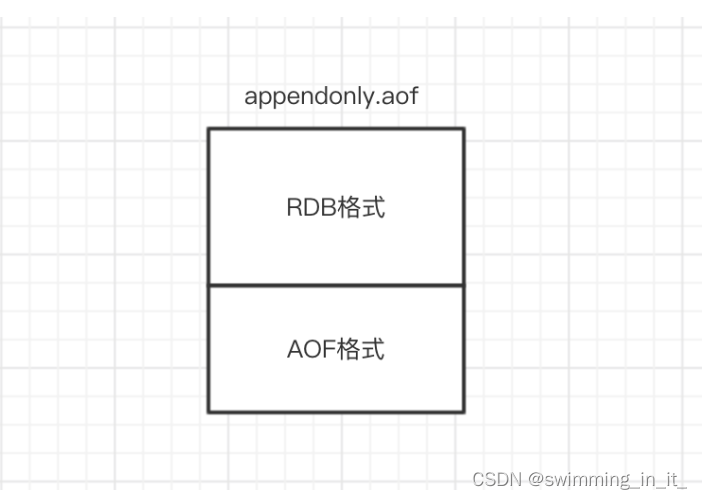
4,数据恢复
当我们开启了混合持久化时,启动redis依然优先加载aof文件,aof文件加载可能有两种情况如下:
- aof文件开头是rdb的格式, 先加载 rdb内容再加载剩余的 aof。
- aof文件开头不是rdb的格式,直接以aof格式加载整个文件。
5,优缺点
优点:混合持久化结合了RDB持久化和 AOF 持久化的优点, 由于绝大部分都是RDB格式,生成的AOF文件体积更小,加载速度快,同时结合AOF,增量的数据以AOF方式保存了,数据更少的丢失。
缺点:兼容性差,一旦开启了混合持久化,在4.0之前版本都不识别该aof文件,同时由于前部分是RDB格式,阅读性较差
Redis高可用(主从切换和哨兵机制)
Redis集群参考: https://blog.csdn.net/u013994536/article/details/124087770
http://www.redis.cn/topics/cluster-tutorial.html
https://blog.csdn.net/g6u8w7p06dco99fq3/article/details/105336857
一:Redis的主从同步是怎么实现的?
主从节点建立连接后,从节点会进行判断:
1.如果这是从节点之前没有同步过数据。属于初次复制,会进行全量重同步,那么从节点会向主节点发送PSYNC?-1 命令,请求主节点进行全量重同步。
2.如果从节点不是初次复制(例如出现掉线后重连) 这个时候从节点会将之前进行同步的Replication ID(一个随机字符串,标识主节点上的特定数据集)和offset(从服务器当前的复制偏移量)通过PSYNC id offset命令发送给主节点,主节点会进行判断,
- 如果Replication ID跟当前的Replication ID不一致(可能主节点进行了变化),或者是当前buffer缓冲区中不存在对应的offset,那么会跟上面的初次复制一样,进行全量重同步。
- 如果Replication ID跟当前的Replication ID一致并且当前buffer缓冲区中存在对应的offset,那么会进行部分重同步。(部分重同步是Redis 2.8之后的版本支持的,主要基于性能考虑,为了断线期间的小部分数据修改进行全量重同步效率比较低)
1,全量重同步
主节点会执行BGSAVE命令,fork出一个子进程,在后台生成一个RDB持久化文件,完成后,发送给从服务器,从节点接受并载入RDB文件,使得从节点的数据库状态更新至主节点执行BGSAVE命令时的状态。并且在生成RDB文件期间,主节点也会使用一个缓冲区来记录这个期间执行的所有写命令,将这些命令发送给从节点,从节点执行命令将自己数据库状态更新至与主节点完全一致。
2,部分重同步
因为此时从节点只是落后主节点一小段时间的数据修改,并且偏移量在复制缓冲区buffer中可以找到,所以主节点把从节点落后的这部分数据修改命令发送给从节点,完成同步。
3,命令传播
在执行全量重同步或者部分重同步以后,主从节点的数据库状态达到一致后,会进入到命令传播阶段。主节点执行修改命令后,会将修改命令添加到内存中的buffer缓冲区(是一个定长的环形数组,满了时就会覆盖前面的数据),然后异步地将buffer缓冲区的命令发送给从节点。
一:Redis的哨兵
1,哨兵是什么?
Redis中的哨兵服务器是一个运行在哨兵模式下的Redis服务器,核心功能是监测主节点和从节点的运行情况,在主节点出现故障后,完成自动故障转移,让某个从节点升级为主节点。
2,客户端如何接入哨兵系统
配置提供者:前者只负责存储当前最新的主从节点信息,供客户端获取。
代理:客户端所有请求都会经过哨兵节点。
首先Redis中的哨兵节点是一个配置提供者,而不是代理。因为客户端只是在首次连接时从哨兵节点获取主节点信息,后续直接与主节点进行连接,发送请求,接收请求结果。
具体流程:
String masterName = "mymaster";
Set<String> sentinels = new HashSet<>();
sentinels.add("192.168.92.128:26379");
sentinels.add("192.168.92.128:26380");
JedisSentinelPool pool = new JedisSentinelPool(masterName, sentinels); //初始化过程做了很多工作
Jedis jedis = pool.getResource();
jedis.set("key1", "value1");
pool.close();
在实际开发中,通过在客户端配置哨兵节点的地址+主节点的名称(哨兵系统可能会监控多个主从节点,名称用于区分)就可以与哨兵节点建立连接,获取到主节点信息,然后与主节点建立连接,并且订阅哨兵节点的频道,以便在主节点变化后,接受到通知。 上面的代码在底层实现是客户端向依次向哨兵节点发送"sentinel get-master-addr-by-name"命令,成功获得主节点信息就不向后面的哨兵节点发送命令。同时客户端会订阅哨兵节点的+switch-master频道,一旦主节点发送故障,哨兵服务器对主节点进行自动故障转移,会将从节点升级主节点,并且更新哨兵服务器中存储的主节点信息,会向+switch-master频道发送消息,客户端得到消息后重新从哨兵节点获取主节点信息,初始化连接池。
3,哨兵系统如何实现故障自动转移?
1.认定主节点主观下线
因为每隔2s,哨兵节点会给主节点发送PING命令,如果在一定时间间隔内,都没有收到回复,那么哨兵节点就认为主节点主观下线。
2.认定主节点客观下线
哨兵节点认定主节点主观下线后,会向其他哨兵节点发送sentinel is-master-down-by-addr命令,获取其他哨兵节点对该主节点的状态,当认定主节点下线的哨兵数量达到一定数值时(这个阀值是Sentinel配置中quorum参数的值,通常我们设置为哨兵总节点数的1/2),就认定主节点客观下线。
3.进行领导者哨兵选举
认定主节点客观下线后,各个哨兵之间相互通信,选举出一个领导者哨兵,由它来对主节点进行故障转移操作。
选举使用的是Raft算法,基本思路是所有哨兵节点A会先其他哨兵节点,发送命令,申请成为该哨兵节点B的领导者,如果B还没有同意过其他哨兵节点,那么就同意A成为领导者,最终得票超过半数以上的哨兵节点会赢得选举,如果本次投票,没有选举出领导者哨兵,那么就开始新一轮的选举,直到选举出哨兵节点(实际开发中,最先判定主节点客观下线的哨兵节点,一般就能成为领导者。)
4.领导者哨兵进行故障转移
领导者哨兵节点首先会从从节点中选出一个节点作为新的主节点。选择的规则是:
- 首先排除一些不健康的节点。(下线的,断线的,最近5s没有回复哨兵节点的INFO命令的,与旧的主服务器断开连接时间较长的)
- 然后根据优先级,复制偏移量,runid最小,来选出一个从节点作为主节点。
向这个从节点发送slaveof no one命令,让其成为主节点,通过slaveof 命令让其他从节点成为它的从节点,将已下线的主节点更新为新的主节点的从节点,将其他从节点的复制目标改完新的主节点,将旧的主服务器改为从服务器。
一:RedisCluster
1,RedisCluster是什么?
当需要存储的数据量特别大,单个Redis实例无法满足需求,所以需要分片,早期很多业务就是在业务中进行分片,通过自定义一些业务规则,将不同的数据存储在不同的Redis实例中。后来就有了官方推出的集群化方案Redis Cluster。
1)Redis Cluster的主从复制模型
Redis集群的架构就是多个主节点,每个主节点负责一部分槽位,每个主节点拥有几个从节点,一旦主节点挂掉,会挑选一个从节点成为新的主节点,负责这部分槽位。如果某个主节点和它的所有从节点都挂掉了,那么这部分槽位就不可用。
2)Redis Cluster一致性
CAP理论认为C一致性,A可用性,P分区容错性,一般最多只能满足两个,也就是只能满足CA和CP,而Redis Cluster的主从复制的模式是异步复制的模式,也就是主节点执行修改命令后,返回结果给客户端后,有一个异步线程会一直从aof_buf缓冲区里面取命令发送给从节点,所以不是一种强一致性,只满足CAP理论中的CA。
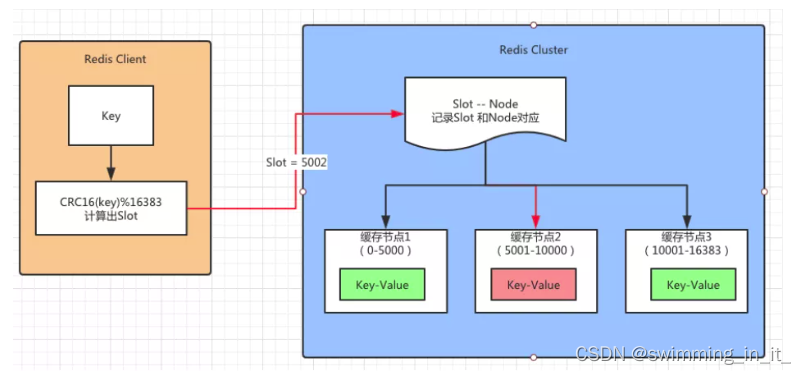
2,RedisCluster实现数据分片
首先Redis Cluster设定了有16384个槽位,然后根据启动时集群的主节点数量进行均分,每个主节点得到一定数量的槽位,为了保证每个主节点挂掉之后,服务保持高可用,一般会为每个主节点配置几个从节点,从节点保存了主节点上同步过来的数据,一旦主节点挂掉,会有一个从节点会被选为主节点。客户端在与Redis Cluster建立连接时会获取到各槽位与主节点之间的映射关系,然后缓存到本地。
客户端执行命令的流程:
假设客户端需要发送一个查询请求时,首先会对key使用CRC16算法计算得到一个hash值,然后将hash值与16384(也就是2的14次方)进行取模(下面是网上找的图,应该是CRC16(key)%16384),得到一个槽位slot,然后根据本地缓存的槽位映射关系表,找到这个槽位slot对应的主节点,发送查询命令。主节点在收到命令后会有以下几种情况:
1)这个主节点确实负责这个槽位,且不在迁移中。
直接查询到这个键值对,返回给客户端。
2)这个主节点不负责这个槽位,或者已经确定转移到其他节点上去了(Moved指令)
可能是这个槽位已经迁移了,或者是客户端将指令发送到了错误的节点,或者是客户端缓存的槽位映射关系以前过期。主节点就会给客户端返回Moved指令及正确的节点信息,Moved指令相当于是一个永久重定向指令,用于纠正客户端缓存的错误槽位信息。客户端收到后会更新本地的槽位关系表,然后向正确的节点发送查询指令。
3)这个槽位正在迁移中(ASKING指令)
如果这个槽位之前是在这个主节点上,但是目前正在迁移(槽位状态为IMPORTING),那么如果现在主节点上存在这个可以,就成功处理请求。否则就返回ASKING指令+槽位所在的新节点,ASKING指令相当于是一个临时重定向指令,客户端收到之后不会更新本地的槽位关系表,只是将本次请求发送到新节点。
3,RedisCluster的节点扩展和下线
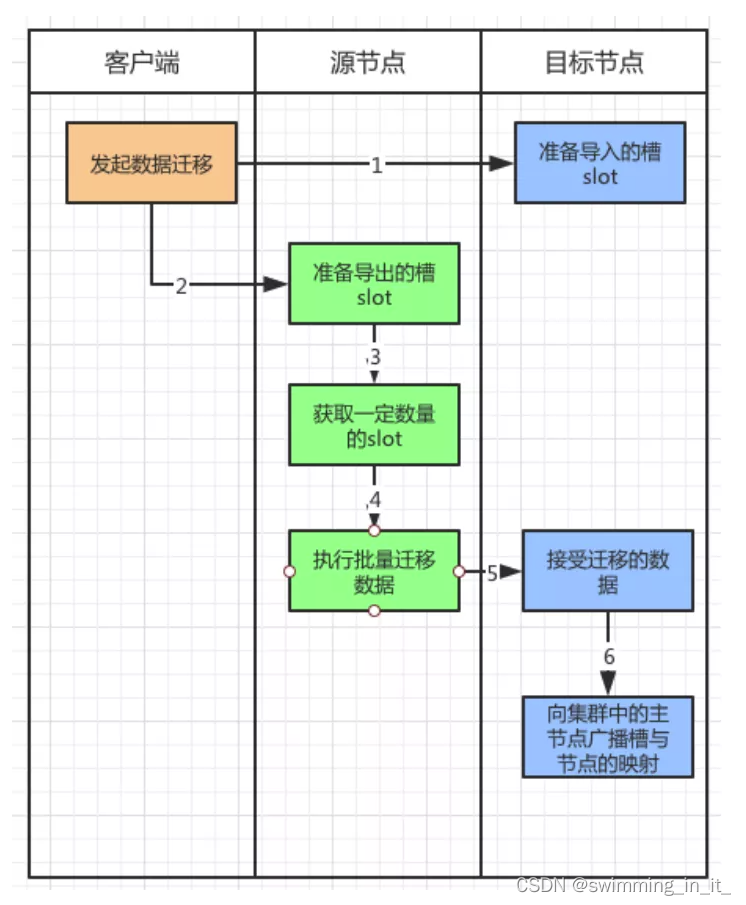
1)扩容
例如数据量太大了,原有的节点太少了,希望增加一些Redis实例,分担一些数据量。在Redis Cluster中,需要程序员手动执行命令,将节点添加到集群,并执行命令从其他的主节点上分配一些槽位到这个新节点上。
具体执行命令流程如下:
./redis-trib.rb add-node 127.0.0.1:7006 127.0.0.1:7000
可以看到.使用addnode命令来添加节点,第一个参数是新节点的地址,第二个参数是任意一个已经存在的节点的IP和端口。
新节点现在已经连接上了集群, 成为集群的一份子, 并且可以对客户端的命令请求进行转向了, 但是和其他主节点相比, 新节点还有两点区别:
- 新节点没有包含任何数据, 因为它没有包含任何哈希槽位.
- 尽管新节点没有包含任何哈希槽位, 但它仍然是一个主节点, 所以在集群需要将某个从节点升级为新的主节点时, 这个新节点不会被选中。
接下来, 只要使用 redis-trib 程序, 将集群中的某些哈希槽位移动到新节点里面, 新节点就会成为真正的主节点了。
槽位迁移需要执行的命令会比较的多,大家想了解的可以看看这篇文章:
https://www.cnblogs.com/youngchaolin/archive/2004/01/13/12034660.html
2)下线
在节点上执行 redis-trib.rb del-node{host:port} {donwNodeId} 通知其他的节点,自己下线,如果本节点是主节点,会安排对应的从节点阶梯主节点的位置。
4,RedisCluster的故障转移和发现
1)主观下线
当节点 1 向节点 2 例行发送 Ping 消息的时候,如果节点 2 正常工作就会返回 Pong 消息,同时会记录节点 1的相关信息,更新与节点2的最近通讯时间。如果节点 1的定时任务检测到与节点 2 上次通讯的时间超过了 cluster-node-timeout 的时候,就会更新本地节点状态,把节点 2 更新为主观下线。
2)客观下线:
由于 Redis Cluster 的节点不断地与集群内的节点进行通讯,下线信息也会通过 Gossip 消息传遍所有节点。
因此集群内的节点会不断收到下线报告,当半数以上持有槽的主节点标记了某个节点是主观下线时,便会认为节点2客观下线,执行后面的流程。
3)资格检查
每个从节点都会检查与主节点断开的时间。如果这个时间超过了 cluster-node-timeout*cluster-slave-validity-factor(从节点有效因子,默认为 10),那么就没有故障转移的资格。也就是说这个从节点和主节点断开的太久了,很久没有同步主节点的数据了,不适合成为新的主节点,因为成为新的主节点以后,其他的从节点回同步它的数据。
4)从节点触发选举
通过资格的从节点都可以触发选举。但是触发选举是有先后顺序的,这里按照复制偏移量的大小来判断。
这个偏移量记录了执行命令的字节数。主服务器每次向从服务器传播 N 个字节时就会将自己的复制偏移量+N,从服务在接收到主服务器传送来的 N 个字节的命令时,就将自己的复制偏移量+N。
复制偏移量越大说明从节点延迟越低,也就是该从节点和主节点沟通更加频繁,该从节点上面的数据也会更新一些,因此复制偏移量大的从节点会率先发起选举。
5)从节点发起选举
首先每个主节点会去更新配置纪元(clusterNode.configEpoch),这个值是不断增加的整数。在节点进行 Ping/Pong 消息交互时也会更新这个值,它们都会将最大的值更新到自己的配置纪元中。
这个值记录了每个节点的版本和整个集群的版本。每当发生重要事情的时候,例如:出现新节点,从节点精选。都会增加全局的配置纪元并且赋给相关的主节点,用来记录这个事件。
说白了更新这个值目的是,保证所有主节点对这件“大事”保持一致。大家都统一成一个配置纪元(一个整数),表示大家都知道这个“大事”了。更新完配置纪元以后,每个从节点会向集群内发起广播选举的消息。
6)主节点为选举投票
参与投票的只有主节点,从节点没有投票权。每个主节点在收到从节点请求投票的信息后,如果它还没有为其他从节点投票,那么就会把票投给从节点。(也就是主节点的票只会投给第一个请求它选票的从节点。)
超过半数的主节点通过某一个节点成为新的主节点时投票完成。如果在 cluster-node-timeout*2 的时间内从节点没有获得足够数量的票数,本次选举作废,进行第二轮选举。
这里每个候选的从节点会收到其他主节点投的票。在第2步领先的从节点通常此时会获得更多的票,因为它触发选举的时间更早一些。获得票的机会更大,也是由于它和原主节点延迟少,理论上数据会更加新一点。
7)选举完成
当满足投票条件的从节点被选出来以后,会触发替换主节点的操作。新的主节点别选出以后,删除原主节点负责的槽数据,把这些槽数据添加到自己节点上。并且广播让其他的节点都知道这件事情,新的主节点诞生了。