第二章预备知识
节省内存:使⽤切⽚表⽰法将操作的结果分配给先前分配的数组
Z[:] = X+Y
就可以把结果覆盖在Z的原内存上,而不是新开辟内存,就节省了内存了
处理缺失值
inputs,outputs = data.iloc[:,0:2],data.iloc[:,2] # iloc为位置索引
inputs = inputs.fillna(inputs.mean()) # 填充缺失值使用同一列的均值
维度和长度
向量或轴的维度被⽤来表⽰向量或轴的⻓度,即向量或轴的元素数量。然而,张量的维度⽤来表⽰张量具有的轴数。在这个意义上,张量的某个轴的维数就是这个轴的⻓度。
张量算法的基本性质
任何按元素的⼀元运算都不会改变其操作数的形状。同样,给定具有
相同形状的任意两个张量,任何按元素⼆元运算的结果都将是相同形状的张量。
降维运算与非降维运算
# 降维运算
A_sum_axis0 = A.sum(axis=0)
A_mean_axis0 = A.mean(axis=0)
#非降维运算
sum_A = A.sum(axis=1,keepdims=True) # 保持矩阵二维特性
cum_A = A.cumsum(axis=0) # 沿某行的累计求和
torch API
1.tensor的detach()成员
2.是否可以吧backward看作就是求导?
3.@它用于装饰器语法和矩阵乘法,在矩阵乘法中相当于dot(a,b)
课后练习题
2.2.5删除最多nan的列
def deleteMaxNa(data):
num_na = data.isna().sum()
num_dict = dict(num_na)
return data.drop(max(num_dict, key=num_dict.get), axis=1)
2.4.6

第一题代码:
注意plot实现是书上的
def f2(x):
return x **3 - 1/x
plot(x,[f2(x),4*x-4],'x','f(x)',legend=['f(x)','Tangent line (x=1)'])
切线方程自己算的
结果:
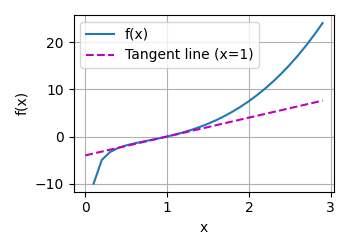
3.5.5第一题
减小batchsize,会降低性能。
其他报错记录
1.在3.6节运行evaluate_accuracy(net, test_iter)时有RuntimeError的报错,然后根据一个博客,进行if __name__ == "__main__":这个之后运行这个函数就行了
有疑问的地方
为什么代码中总是使用net[0]?这个的意思是net的第一层吗?

第二处P86页

这个问题有兴趣研究一下

不太懂y_hat[[0,1],y]怎么实现的这个索引,明白了,就是[0,1]来选择行,y来选择列,在定义交叉熵损失函数时有- torch.log(y_hat[range(len(y_hat)),y])这么一个代码,y_hat[range(len(y_hat))]也是同理
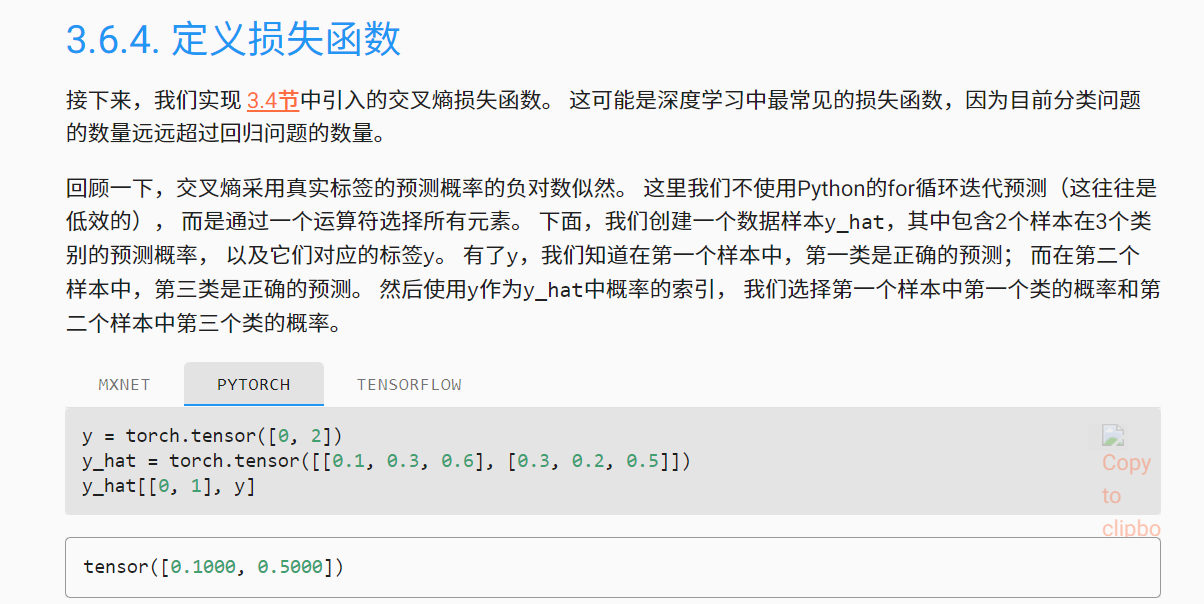
下面这句话,读着有点绕

框的这一行不是很理解,我懂了,就是add函数的定义是self.data = [a + float(b) for a, b in zip(self.data, args)],可以看作把data的每一个元素加上传入的元素。
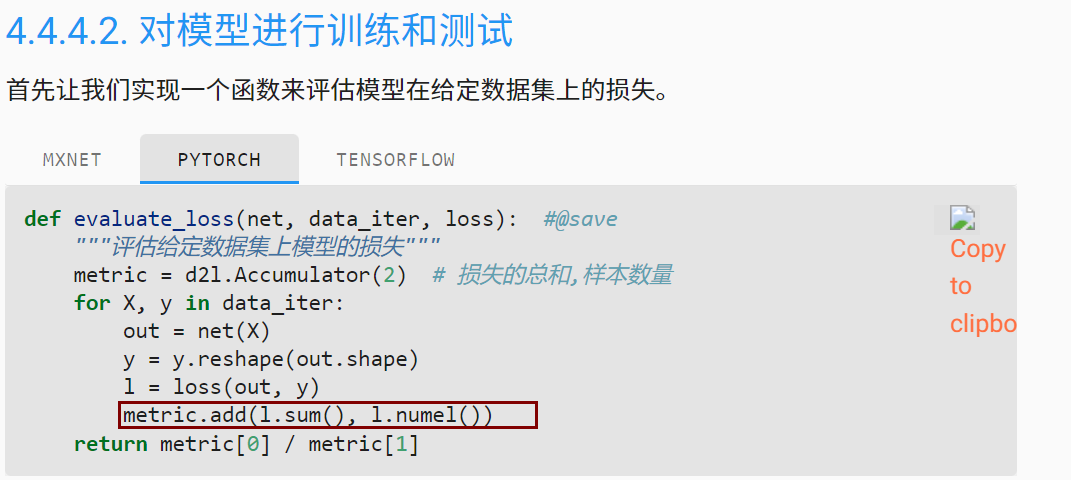
下面这个,为什么等于1?

为什么说,极大的降低了训练损失?

这个不是太懂:

6.5.1不是特别懂这段文字

6.6中,为什么要用这种方式设置:

8.3的预测部分不是很懂那个代码,还有关于K的选取不同,想要说明的事情。
8.5.4的预测部份代码,主要是这个isinstance下面那行代码,以及为什么要这么判断一下。
def grad_clipping(net,theta): #@save
"""裁剪梯度"""
if isinstance(net,nn.Module):
params = [p for p in net.parameters() if p.requires_grad]
else:
params = net.params
norm = torch.sqrt(sum(torch.sum((p.grad ** 2)) for p in params))
if norm > theta:
for param in params:
param.grad[:] *= theta / norm
9.7.6预测部份的代码, num_matches, label_subs = 0, collections.defaultdict(int)属实有点懵,这会儿饿坏了
def bleu(pred_seq, label_seq, k): #@save
"""计算BLEU"""
pred_tokens, label_tokens = pred_seq.split(' '), label_seq.split(' ')
len_pred, len_label = len(pred_tokens), len(label_tokens)
score = math.exp(min(0, 1 - len_label / len_pred))
for n in range(1, k + 1):
num_matches, label_subs = 0, collections.defaultdict(int)
for i in range(len_label - n + 1):
label_subs[' '.join(label_tokens[i: i + n])] += 1
for i in range(len_pred - n + 1):
if label_subs[' '.join(pred_tokens[i: i + n])] > 0:
num_matches += 1
label_subs[' '.join(pred_tokens[i: i + n])] -= 1
score *= math.pow(num_matches / (len_pred - n + 1), math.pow(0.5, n))
return score
在1.2.1.3的晏森不等式中,第一个式子不懂
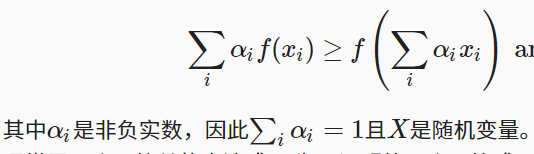
在11.5.1中有段代码:
不是特别了解
# 乘法和加法作为单独的操作(在实践中融合)
gigaflops = [2/i for i in timer.times]
print(f'performance in Gigaflops: element {
gigaflops[0]:.3f}, '
f'column {
gigaflops[1]:.3f}, full {
gigaflops[2]:.3f}')
14.2.1不太懂这个D=1是什么玩意,噢噢意思好像是正样本的意思

- 11.4.3没看
- 11.3.2没看
- 11.6.3没看
- 11.11没看