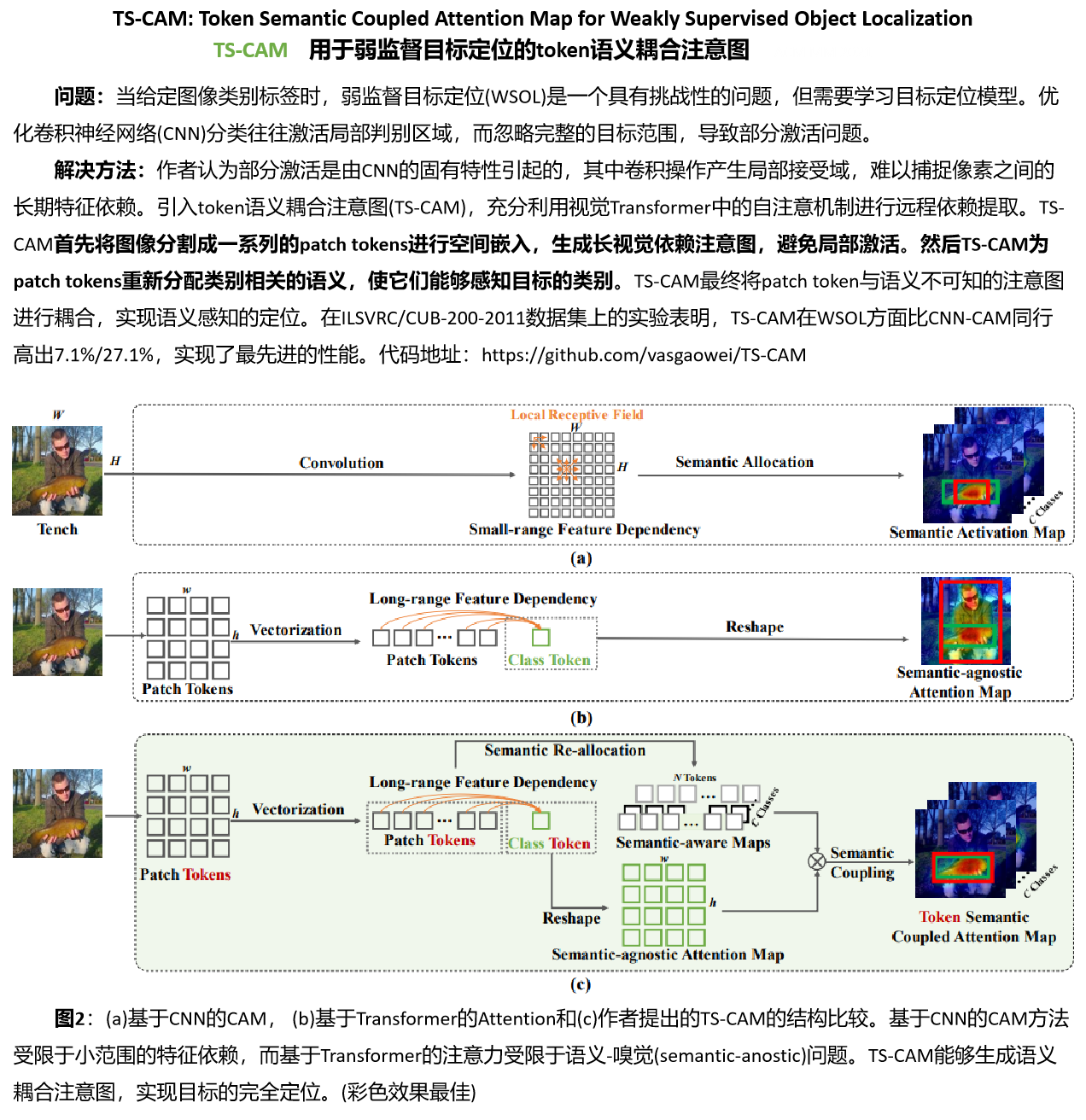
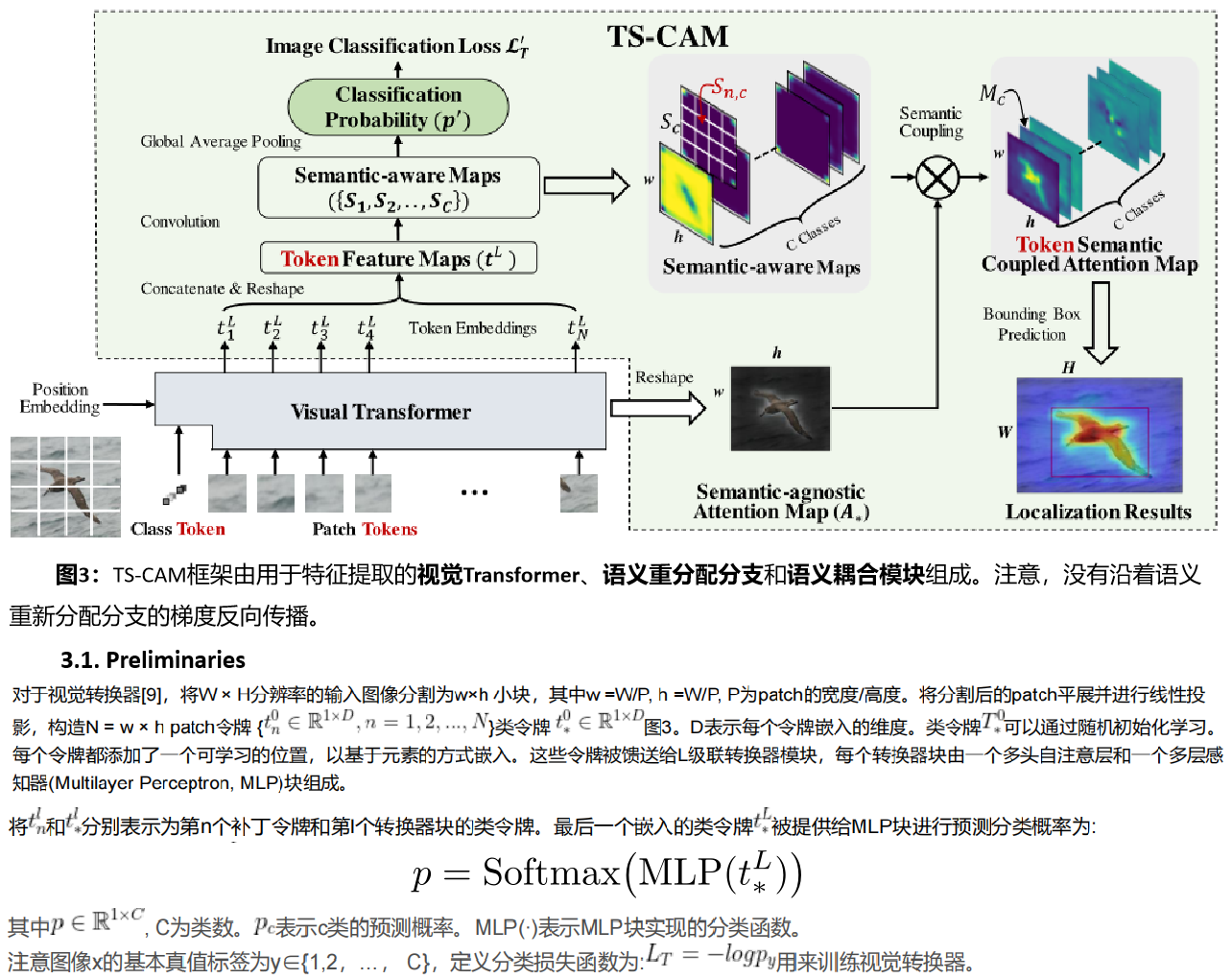
关于论文<TS-CAM: Token Semantic Coupled Attention Map for Weakly Supervised Object Localization>学习笔记
总结:这里就像是vision transformer,做一个分类任务。然后引入分类loss。


总结:
得到197×768大小的class token+patch token矩阵, 将图像块的特征向量即patch token部分取出来,记作x_patch,我们将它按照在图像中的位置进行reshape,操作如下图所示:
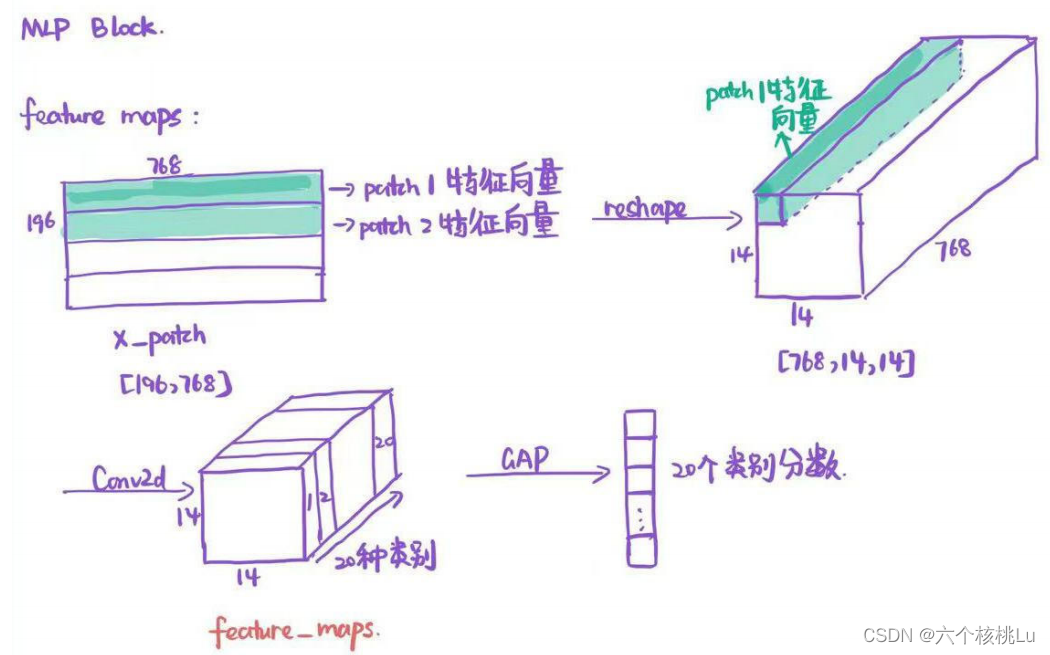
然后经过一个卷积层,将通道数变为类别数,再由全局平均池化得到最终的类别分数。卷积层之后的特征层论文中记为feature_maps。作者在文中提 到,这个feature_maps富含语义信息,可以和不含语义信息的注意力图相乘得到类别激活图。注意力图由我们在每个transformer block(一共12个)得到 的attention matrix获得。具体做法如下图:
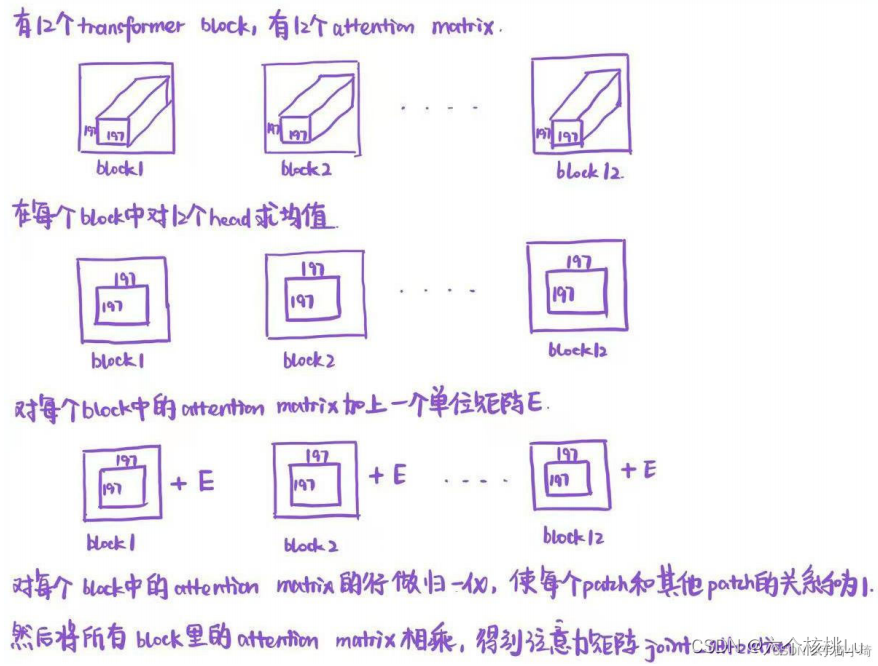
在得到注意力矩阵joint_attention后,作者只取了第一行(第一行第一列的元素也不要)向量,叫做class token的注意力向量,将这个向量按照patch在图像中的位置进行reshape操作,得到cams_re, 如下图所示:

