TorchScript简介与应用
TorchScript简介
TorchScript是PyTorch模型推理部署的中间表示,可以在高性能环境libtorch(C ++)中直接加载,实现模型推理,而无需Pytorch训练框架依赖。 torch.jit是torchscript Python语言包支持,支持pytorch模型快速,高效,无缝对接到libtorch运行时,实现高效推理。
TorchScript应用
TorchScript模型部署
将PyTorch模型转换为Torch脚本
将PyTorch模型转换为Torch脚本的方法有两种:
第一种方法是跟踪机制,通过使用示例输入对模型的结构进行一次评估,并记录这些输入在模型中的流转,从而捕获模型的结构。这适用于有限使用控制流的模型。
第二种方法是在模型中添加显式批注,以告知Torch Script编译器可以根据Torch Script语言施加的约束直接解析和编译模型代码。
方法1:通过跟踪转换为Torch脚本
要将PyTorch模型通过跟踪转换为Torch脚本,必须将模型的实例以及示例输入传递给torch.jit.trace函数。这将产生一个torch.jit.ScriptModule对象。
import torch
import torchvision
# 你模型的一个实例.
model = torchvision.models.resnet18()
# 您通常会提供给模型的forward()方法的示例输入。
example = torch.rand(1, 3, 224, 224)
# 使用`torch.jit.trace `来通过跟踪生成`torch.jit.ScriptModule`
traced_script_module = torch.jit.trace(model, example)
方法2:通过注释转换为Torch脚本
在某些情况下,例如,如果模型采用特定形式的控制流,则可能需要直接在Torch脚本中编写模型并相应地注释模型。例如,假设您具有以下 vanilla Pytorch模型:
import torch
class MyModule(torch.nn.Module):
def __init__(self, N, M):
super(MyModule, self).__init__()
self.weight = torch.nn.Parameter(torch.rand(N, M))
def forward(self, input):
if input.sum() > 0:
output = self.weight.mv(input)
else:
output = self.weight + input
return output
因为此模块的前向方法使用取决于输入的控制流,所以它不适合跟踪。相反,我们可以将其转换为ScriptModule。为了将模块转换为ScriptModule,需要使用torch.jit.script编译模块,如下所示:
class MyModule(torch.nn.Module):
def __init__(self, N, M):
super(MyModule, self).__init__()
self.weight = torch.nn.Parameter(torch.rand(N, M))
def forward(self, input):
if input.sum() > 0:
output = self.weight.mv(input)
else:
output = self.weight + input
return output
my_module = MyModule(10,20)
sm = torch.jit.script(my_module)
如果您需要在nn.Module中排除某些方法,因为它们使用了TorchScript尚不支持的Python功能,则可以使用@torch.jit.ignore对其进行注释。
my_module是ScriptModule的实例,可以序列化。
将脚本模块序列化为文件
一旦有了ScriptModule(通过跟踪或注释PyTorch模型),您就可以将其序列化为文件了。假设我们要序列化先前在跟踪示例中显示的ResNet18模型,则执行以下命令:
traced_script_module.save("traced_resnet_model.pt")
这将在您的工作目录中生成traced_resnet_model.pt文件。
如果您还想序列化my_module,请调用:
my_module.save("my_module_model.pt")
在C ++中加载脚本模块
要在C ++中加载序列化的PyTorch模型,您的应用程序必须依赖于PyTorch C ++ API(也称为LibTorch)。LibTorch发行版包含共享库,头文件 和CMake构建配置文件的集合。虽然CMake不是依赖LibTorch的要求,但它是推荐的方法,并且将来会得到很好的支持。在example-app文件夹下编写example-app.cpp和CMakeLists.txt两个文件:
example-app/
CMakeLists.txt
example-app.cpp
example-app.cpp:
include <torch/script.h> // One-stop header.
#include <iostream>
#include <memory>
int main(int argc, const char* argv[]) {
if (argc != 2) {
std::cerr << "usage: example-app <path-to-exported-script-module>\n";
return -1;
}
torch::jit::script::Module module;
try {
// 使用以下命令从文件中反序列化脚本模块: torch::jit::load().
module = torch::jit::load(argv[1]);
}
catch (const c10::Error& e) {
std::cerr << "error loading the model\n";
return -1;
}
std::cout << "ok\n";
}
<torch/script.h>标头包含运行示例所需的LibTorch库中的所有相关包含。我们的应用程序接受序列化的PyTorch ScriptModule的文件路径 作为其唯一的命令行参数,然后使用torch::jit::load()函数继续对该模块进行反序列化,该函数将此文件路径作为输入。作为返回,我们 收到一个Torch::jit::script::Module对象。
CMakeLists.txt:
cmake_minimum_required(VERSION 3.0 FATAL_ERROR)
project(custom_ops)
find_package(Torch REQUIRED)
add_executable(example-app example-app.cpp)
target_link_libraries(example-app "${TORCH_LIBRARIES}")
set_property(TARGET example-app PROPERTY CXX_STANDARD 11)
从PyTorch网站的下载页面上获取最新的LibTorch稳定版本。 如果下载并解压缩最新的归档文件,则应收到具有以下目录结构的文件夹:
libtorch/
bin/
include/
lib/
share/
- lib/ 文件夹包含您必须链接的共享库,
- include/ 文件夹包含程序需要包含的头文件,
- share/ 文件夹包含必要的CMake配置,以启用上面的简单
find_package(Torch)命令。
运行以下命令从example-app/文件夹中构建应用程序:
mkdir build
cd build
cmake -DCMAKE_PREFIX_PATH=/path/to/libtorch ..
make
/path/to/libtorch应该是解压缩的LibTorch发行版的完整路径。如果一切顺利,它将看起来像这样:
root@4b5a67132e81:/example-app# mkdir build
root@4b5a67132e81:/example-app# cd build
root@4b5a67132e81:/example-app/build# cmake -DCMAKE_PREFIX_PATH=/path/to/libtorch ..
-- The C compiler identification is GNU 5.4.0
-- The CXX compiler identification is GNU 5.4.0
-- Check for working C compiler: /usr/bin/cc
-- Check for working C compiler: /usr/bin/cc -- works
-- Detecting C compiler ABI info
-- Detecting C compiler ABI info - done
-- Detecting C compile features
-- Detecting C compile features - done
-- Check for working CXX compiler: /usr/bin/c++
-- Check for working CXX compiler: /usr/bin/c++ -- works
-- Detecting CXX compiler ABI info
-- Detecting CXX compiler ABI info - done
-- Detecting CXX compile features
-- Detecting CXX compile features - done
-- Looking for pthread.h
-- Looking for pthread.h - found
-- Looking for pthread_create
-- Looking for pthread_create - not found
-- Looking for pthread_create in pthreads
-- Looking for pthread_create in pthreads - not found
-- Looking for pthread_create in pthread
-- Looking for pthread_create in pthread - found
-- Found Threads: TRUE
-- Configuring done
-- Generating done
-- Build files have been written to: /example-app/build
root@4b5a67132e81:/example-app/build# make
Scanning dependencies of target example-app
[ 50%] Building CXX object CMakeFiles/example-app.dir/example-app.cpp.o
[100%] Linking CXX executable example-app
[100%] Built target example-app
在C ++中执行脚本模块
成功用C ++加载了序列化的ResNet18之后,我们现在只需执行几行代码即可!让我们将这些行添加到C ++应用程序的main()函数中:
// 创建输入向量
std::vector<torch::jit::IValue> inputs;
inputs.push_back(torch::ones({
1, 3, 224, 224}));
// 执行模型并将输出转化为张量
at::Tensor output = module.forward(inputs).toTensor();
std::cout << output.slice(/*dim=*/1, /*start=*/0, /*end=*/5) << '\n';
前两行设置了我们模型的输入。我们创建一个torch::jit::IValue的向量(类型为type-erased的值Script::Module方法接受并返回), 并添加单个输入。要创建输入张量,我们使用torch::ones(),等效于C ++ API中的torch.ones。然后,我们运行script::Module的 forward方法,并向其传递我们创建的输入向量。作为回报,我们得到一个新的IValue,通过调用toTensor()将其转换为张量。
通过重新编译我们的应用程序并以相同的序列化模型运行它来进行尝试:
root@4b5a67132e81:/example-app/build# make
Scanning dependencies of target example-app
[ 50%] Building CXX object CMakeFiles/example-app.dir/example-app.cpp.o
[100%] Linking CXX executable example-app
[100%] Built target example-app
root@4b5a67132e81:/example-app/build# ./example-app traced_resnet_model.pt
-0.2698 -0.0381 0.4023 -0.3010 -0.0448
[ Variable[CPUFloatType]{
1,5} ]
Eager、TorchScript、ONNX对比
- Eager 模式:Python + Python runtime。这种模式是更 Pythonic 的编程模式,可以让用户很方便的使用 python 的语法来使用并调试框架,就像我们刚认识 pytorch 时它的样子,自带 eager 属性。
- Script 模式:TorchScript + PyTorch JIT。这种模式会对 eager 模式的模型创建一个中间表示(intermediate representation,IR),这个 IR 经过内部优化的,并且由Torch Script编译器理解, 编译和序列化,不再依赖 python runtime,也可以使用 C++ 加载运行。
- ONNX 模式:将Pytorch模型转换为ONNX模型,并使用ONNX Runtime进行推理。
在此Github中,作者探索不同的方法来优化 PyTorch 模型以进行推理,尝试了经典的 PyTorch eager-mode、TorchScript和ONNX Runtime并比较了它们的性能。结果如下图:
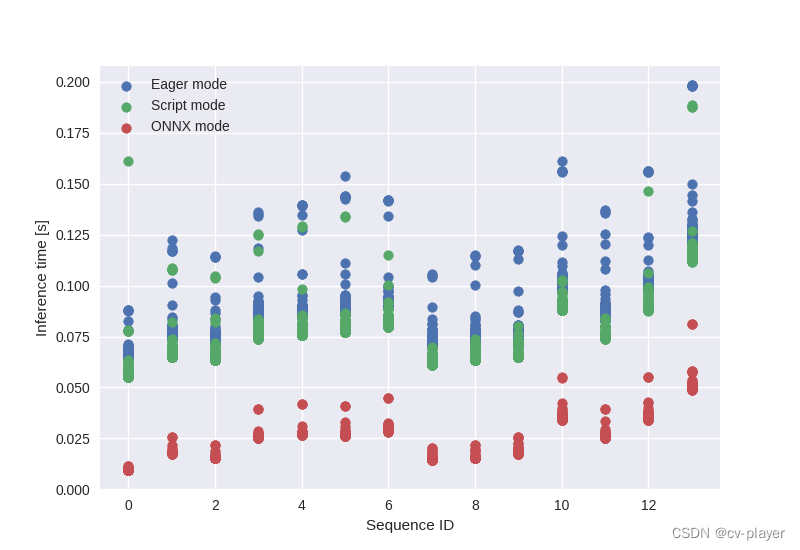
从图中可以看出,ONNX模式的推理时间显著少于Eager和Script两个模式。