前面一篇文章介绍了通过gensim操作单词向量的demo,有兴趣的同学可以移步这里。这一篇将给大家介绍该算法背后的原理。说起原理,我们实际上很难真正理解和解释那些词义(word meaning/semantics)、词形(morphology)、词性(part of speech)等信息是如何被编码到这些高维实数向量中的。但是我们实际上已然做到这一点。这种“我们不理解,但是却做到了”的情况,在现实生活中其实并不鲜见。比如我们直到1777年拉瓦锡提出氧化学说,才真正把握了燃烧的本质,但这并不妨碍我们的祖先对火的使用。我们本文中所谓的原理,其实指的是一种实现的方法。首先让我们来了解以下如何在计算机中表示单词的词义。
1 词义的表示
1.1 WordNet
WordNet是一个大型英语字典(lexicon)。包含单词的同义词(synonym)集合和上位词(hypernym)集合。
举例:
“good”的同义词集合:
noun: good
noun: good, goodness
noun: commodity, trade_good, good
adj: good
adj: full, good
...
如果两个单词A和B,如果可以说A is a B,那么我们说B是A的上位词。例如:panda is a mammal.(熊猫是一种哺乳动物。)我们可以说,mammal是panda的上位词。
举例:
“panda”的上位词集合:
procyonid
carnivore
placental
mammal
vertebrate
chordate
animal
...
WordNet的缺点:
没办法准确描述同义词之间的细微差异,只是把有相同含义的单词简单放在一起。有些同义词之间含义基本一致,但另一些同义词之间仅仅在非常有限的语境下意思才能一样。
单词的含义在实际生活中不断演变,而WordNet不可能做到紧跟单词在现实中的演化。
WordNet中的单词的表示需要消耗大量的人力才能更新。
因为依靠人力进行维护,因此不可避免受到维护的人员的个人认知的影响。
无法定量计算单词之间的相似程度。
1.2 独热向量(One-hot Vectors)
传统的NLP技术(一般指2012年及以前的NLP技术)中,一般通过离散式的标志来标识单词的含义,即针对每一个单词使用单独的标识来标记其含义。这种标识法也成为“本地主义标识”(localist representation)。在这种情况下,要将单词作为神经网络的输入,一般做法是使用独热向量 (one-hot vectors)来表示每一个单词。这样可以确保任意两个单词之间的含义在数学上为正交关系(orthogonal,用人话说就是没关系)。例如:
motel = (0,0,0,0,0,0,1,0,0,0)
hotel = (0,0,0,1,0,0,0,0,0,0)
使用独热向量来表示词义有以下缺点:
向量的维度等于词汇表的大小,由于每个英文单词都有多种变形,一个实用的英文词汇表可以轻松突破100万个词汇。这意味着必须使用一个100万维的向量来表示一个单词。
无法表示和计算单词之间的关系,任何两个单词的词义都是正交关系。
1.3 单词向量(Word Vectors / Word Embedding)

You shall know a word by the company it keeps. (J. R. Firth)
一个单词的含义,由经常出现在其周围的其他单词决定。在一段文本中,单词w的上下文(context),就是那些出现在w前后一定距离之内的单词。我们可以通过一定数量的上下文,来表示单词w的含义。
单词banking的上下文:
...govenment debt problems turning into banking crises as happened in 2009...
...saying that Europ needs unified banking regulation to replace the hodgepodge...
... India has just given its banking system a shot in the arm...
我们将单词w的上下文进行编码为一个高维向量,称为单词向量(word vector),也称为单词嵌入(word embedding):

2 Word2vec
2.1 核心思想
前面介绍One-hot向量的时候说到,传统NLP技术一般指2012年及以前的NLP技术。在2013年由Tomas Mikolov 等人提出的一个能够有效学习获取高质量单词向量的算法Word2vec,对NLP领域的研究产生了重大影响。
Word2vec算法的核心思想:
输入包含大量语料文本;
遍历文本中所有位置t,提取该位置上的单词c,称为核心词;提取该位置前后与c距离不大于m的单词o,称为上下文(或外围词)。
词汇表中的每个单词,都由2个高维向量v,u表示。v表示单词作为核心词的向量,u是单词作为外围词的向量。
通过单词向量,计算出核心词c和所有上下文o共同出现的似然值L。
不断修改单词向量,使L值最大化。
2.2 Skip-gram (SG) 模型
2.2.1 似然函数(Likehood)
Skip-gram模型的核心思想就是通过给定核心词,预测特定上下文单词出现的概率。
给定语料中的单词数量为T, 是所有单词的单词向量的集合,也是该似然函数的参数。似然函数就是计算给定语料中所有位置t=1,2,...,T上的核心词
是所有单词的单词向量的集合,也是该似然函数的参数。似然函数就是计算给定语料中所有位置t=1,2,...,T上的核心词 ,以m为窗口大小的上下文单词出现的似然值。具体公式如下:
,以m为窗口大小的上下文单词出现的似然值。具体公式如下:

其中看起来像这样子:

计算窗口为2的上下文条件概率计算的示意图:

2.2.2目标函数(Objective Function)
为了便于计算,我们将似然函数进行转化。成为可用于优化算法的关于参数的目标函数 。
。

由于似然函数中包含了大量点乘操作,我们在似然函数 前增加有对数操作符号
前增加有对数操作符号 ,可以把点乘操作转化为加法操作。另外还在前面增加了
,可以把点乘操作转化为加法操作。另外还在前面增加了 ,作用是使该目标函数的结果与语料的大小无关。通过上式可以知道,当且仅当为最大值时,最小。我们的目标就是找到参数使得全局最小。目标函数有时也称为损失函数(loss function/ cost function)。
,作用是使该目标函数的结果与语料的大小无关。通过上式可以知道,当且仅当为最大值时,最小。我们的目标就是找到参数使得全局最小。目标函数有时也称为损失函数(loss function/ cost function)。
我们把代入目标函数之后可以得到:

上面的式子中, 代表的是上下文单词,也可以表示为o,代表的是核心词,也可以表示为c。现在我们的问题就转变为,如何计算
代表的是上下文单词,也可以表示为o,代表的是核心词,也可以表示为c。现在我们的问题就转变为,如何计算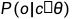 的值。
的值。
先直接给结论再解释:

现在我们来解释一下上边这个式子,这个式子最重要的部分是包在括号里的 。
。
我们可以把它看成是两个向量的点积。
向量点积的几何意义为其中一个向量在另一个向量上投影的长度和被投影的向量的长度之积。如果两个单词o,c的相关性越强,那么其单词向量之间的投影就越大,单词向量之间的点积就会越大。下边给出二维平面上的向量点积的示意图(其中v的长度为单位长度1)。


我们把两个单词向量点积的结果取自然指数,主要是为了使点积的结果全部转为正实数。然后除以Z的作用是将计算的结果归一化,使整个概率分布之和为1。Z是词汇表中所有单词的向量与核心词c的向量点积之后取自然指数之和。

我们把Z代入上边的式子可得:

我们将使用x替代,可得到softmax函数的形式:

由softmax函数的特性可知,该函数有助于从词汇表中挑选出与 相关性最高的上下文单词,因为经过exp操作之后,相对较大的数会变得更大,同时为相关性次高的单词保留一定的概率值。
相关性最高的上下文单词,因为经过exp操作之后,相对较大的数会变得更大,同时为相关性次高的单词保留一定的概率值。
最后,我们可以把目标函数转化为:

如果我们把softmax函数的具体内容也写出来,那么就是:

下一步,我们只需要针对这个目标函数进行优化就可以了。
2.2.3 模型参数的优化
优化算法是一个十分庞大的领域,这里只介绍最基本的梯度下降法。
首先,计算关于核心词 的梯度。
的梯度。





然后,计算关于上下文 的梯度。
的梯度。









针对每一个参数,按照以下公式进行迭代优化。

其中 称为步进因子,用于调节学习速度。
称为步进因子,用于调节学习速度。
2.3 Continuous Bag of Word(CBOW)模型
另一个属于Word2vec模型是Continuous Bag of Word (CBOW)。该模型是Skip-gram模型的反转,主要思想是:基于上下文的单词,来预测核心词的概率值。
3 其他模型
3.1 词袋模型(Bag of Word/Count Vectors)
词袋模型,也称为计数向量模型,是一种非常直观的文本特征的表示方式。假设现在有n个文档 ,
, 是所有文档的词汇表,
是所有文档的词汇表, 是中的词汇,
是中的词汇, 为词汇个数。词袋模型可以表示为一个二维表格,横轴为词汇表中的每一个词,纵轴为文档,表格中的每个单元,表示某个词在某个文档中出现的次数。如下表所示:
为词汇个数。词袋模型可以表示为一个二维表格,横轴为词汇表中的每一个词,纵轴为文档,表格中的每个单元,表示某个词在某个文档中出现的次数。如下表所示:
|
|
|
|
... |
|
|
|
2 |
1 |
1 |
0 |
... |
0 |
|
1 |
0 |
0 |
2 |
... |
1 |
... |
... |
... |
... |
... |
... |
... |
|
0 |
1 |
2 |
1 |
... |
2 |








横轴的值就是文档的特征向量,纵轴可以理解为单词的单词向量。上边这个表中的内容为计数值,可以根据需要转化为浮点数。例如,可以表示为按横轴加总为1的概率分布。这种模型比较常见的应用场景在于潜在语义分析(latent semantic analysis)。
这种基于计数的模型,有一些问题需要解决。例如高频词:a, and, the等等。特定领域专业词汇高频出现。矩阵巨大且稀疏等等。
3.2 基于窗口的共现矩阵 (Shallow Window Based Co-occurrence Matrix)
词袋模型中的单词向量,已经可以看成是一种基本的单词共现矩阵,其描述的是单词在给定文档中出现的频率,并以此来表示文档的含义。基于这种思路,我们可以对单词向量做进一步的优化。
给定大小为T的语料库V,给定一个窗口大小m(通常为5-10),依次扫描语料中的每一个词作为核心词c,然后获取核心词前后距离为m以内的单词作为上下文o。累计单词c与o共同出现的次数并形成一张T*T的表,就叫做基于窗口的共现矩阵。
|
|
|
|
... |
|
|
|
2 |
1 |
1 |
0 |
... |
0 |
|
1 |
0 |
0 |
2 |
... |
1 |
... |
... |
... |
... |
... |
... |
... |
|
0 |
1 |
2 |
1 |
... |
2 |








在这个共现矩阵中,每个单词的词义可以通过每一行组成的向量来表示。这也是单词向量的一种表示方式。
高频词、稀疏性等问题同样存在于这个模型当中。
3.3 GloVe: Global Vectors for Word Representation
GloVe模型结合了基于概率的模型(例如SG模型)与基于计数的模型(例如窗口共现矩阵)的思想。基于上文提到的窗口共现矩阵,我们用 表示核心单词
表示核心单词 的上下文窗口范围内,上下文单词
的上下文窗口范围内,上下文单词 出现的次数。
出现的次数。 表示表中每一行所有元素的累加值,即
表示表中每一行所有元素的累加值,即 。我们可以算出上下文单词出现在核心单词的上下文窗口范围内的实际观察到的概率为:
。我们可以算出上下文单词出现在核心单词的上下文窗口范围内的实际观察到的概率为:
 。
。
给定模型参数,其中 为单词作为核心单词时的单词向量,
为单词作为核心单词时的单词向量, 为单词作为上下文单词时的单词向量。该模型下预测上下文单词出现在核心单词的上下文窗口范围内的似然值为:
为单词作为上下文单词时的单词向量。该模型下预测上下文单词出现在核心单词的上下文窗口范围内的似然值为:
 。
。
使用以单词对共现计数为权重的加权最小二乘法来获得目标函数:

由于对 ,
, 的计算涉及到全单词表扫描,是一个非常耗时的操作,为了加快计算,我们使用未归一的结果:
的计算涉及到全单词表扫描,是一个非常耗时的操作,为了加快计算,我们使用未归一的结果: ,
, 。而使用未归一的值带来一个副作用就是可能存在非常大的P值,我们可以计算P和Q的log值的方差。因而目标函数可以优化为:
。而使用未归一的值带来一个副作用就是可能存在非常大的P值,我们可以计算P和Q的log值的方差。因而目标函数可以优化为:

由于优化结果受到a,the等高频词的干扰较大,Pennington等人发现将权重 放在一个权重函数
放在一个权重函数 里。该权重函数的定义如下:
里。该权重函数的定义如下:

给定 的情况下,该权重函数的图像如下图:
的情况下,该权重函数的图像如下图:

现在目标函数变成:
 。
。
在此基础上增加两个偏移量 ,
, ,用于吸收从和,到
,用于吸收从和,到 和
和 的转变造成的一些失真。最终的目标函数为:
的转变造成的一些失真。最终的目标函数为:

4 模型的补丁
4.1 Negative Sampling
Negative sampling算法主要是为了解决梯度下降过程中,梯度函数中 计算成本过高的问题。因为其中包含了对整个词汇表的遍历操作。为了避免遍历整个词汇表,随机选择几个未被观察到的上下文词并使目标函数选中这些词的似然值尽可能低。在Skig-gram模型中应用Negative sampling,目标函数修改为:
计算成本过高的问题。因为其中包含了对整个词汇表的遍历操作。为了避免遍历整个词汇表,随机选择几个未被观察到的上下文词并使目标函数选中这些词的似然值尽可能低。在Skig-gram模型中应用Negative sampling,目标函数修改为:

其中, 为选择未观察到的上下文单词的数量。
为选择未观察到的上下文单词的数量。 为sigmoid函数。
为sigmoid函数。
4.2 Stochastic Gradient Descent (SGD)
SGD也是为了解决每次遍历整个语料库的问题。其主要思想是:每次计算梯度时,仅从语料库中选取一定数量的样本,然后使用这些样本来进行梯度计算。
4.3 Singular Value Decomposition(SVD)
我们可以通过SVD算法来实现矩阵降维,将稀疏矩阵压缩成一个密集矩阵。
对于一个mxn的矩阵 ,我们可以将其分解为:
,我们可以将其分解为: 。
。

 称为奇异值(singular values)并且
称为奇异值(singular values)并且 。我们可以只保留前k个奇异值,把后边的奇异值抛弃掉,从而重新构建一个mxk的满秩矩阵。也就是说,从而把n维向量空间向量,压缩成k维。
。我们可以只保留前k个奇异值,把后边的奇异值抛弃掉,从而重新构建一个mxk的满秩矩阵。也就是说,从而把n维向量空间向量,压缩成k维。
4.4 处理共现表中的计数值
有一大堆方法用来说明如何处理单词共现表中的计数值X并取得进展,例如:
前文已经提到的利用一个权重函数
来调整作为权重的X值:

对X值取自然对数。
将X值取大于0小于1的幂。